
منذ بعض الوقت ، فعلنا رصد Agentless وإنذارات لذلك. هذا هو تناظرية CloudWatch في AWS مع API متوافق. الآن نحن نعمل على الموازن والمقياس التلقائي. ولكن بينما لا نقدم مثل هذه الخدمة ، فإننا نقدم لعملائنا القيام بذلك بأنفسهم ، وذلك باستخدام المراقبة والعلامات الخاصة بنا (AWS Resource Tagging API) كاكتشاف خدمة بسيط كمصدر للبيانات. سنبين كيفية القيام بذلك في هذا المنشور.
مثال على الحد الأدنى من البنية التحتية لخدمة ويب بسيطة: DNS -> 2 موازنات -> 2 الواجهة الخلفية. يمكن اعتبار هذه البنية الأساسية الحد الأدنى الضروري للتشغيل والصيانة التي تتحمل الأخطاء. لهذا السبب ، لن "نضغط" هذه البنية التحتية أكثر ، تاركًا ، على سبيل المثال ، واجهة واحدة فقط. لكنني أرغب في زيادة عدد خوادم الواجهة الخلفية وتقليص عدد خوادمها. ستكون هذه مهمتنا. جميع الأمثلة متوفرة في المستودع .
البنية التحتية الأساسية
لن نتحدث بالتفصيل عن تكوين البنية التحتية المذكورة أعلاه ، وسوف نظهر فقط كيفية إنشائها. نحن نفضل نشر البنية التحتية باستخدام Terraform. يساعد على إنشاء كل ما تحتاج إليه بسرعة (VPC ، الشبكة الفرعية ، مجموعة الأمان ، VMs) وتكرار هذا الإجراء مرارًا وتكرارًا.
البرنامج النصي لرفع البنية التحتية الأساسية:
main.tfvariable "ec2_url" {} variable "access_key" {} variable "secret_key" {} variable "region" {} variable "vpc_cidr_block" {} variable "instance_type" {} variable "big_instance_type" {} variable "az" {} variable "ami" {} variable "client_ip" {} variable "material" {} provider "aws" { endpoints { ec2 = "${var.ec2_url}" } skip_credentials_validation = true skip_requesting_account_id = true skip_region_validation = true access_key = "${var.access_key}" secret_key = "${var.secret_key}" region = "${var.region}" } resource "aws_vpc" "vpc" { cidr_block = "${var.vpc_cidr_block}" } resource "aws_subnet" "subnet" { availability_zone = "${var.az}" vpc_id = "${aws_vpc.vpc.id}" cidr_block = "${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}" } resource "aws_security_group" "sg" { name = "auto-scaling" vpc_id = "${aws_vpc.vpc.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } ingress { from_port = 8080 to_port = 8080 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } } resource "aws_key_pair" "key" { key_name = "auto-scaling-new" public_key = "${var.material}" } resource "aws_instance" "compute" { count = 5 ami = "${var.ami}" instance_type = "${count.index == 0 ? var.big_instance_type : var.instance_type}" key_name = "${aws_key_pair.key.key_name}" subnet_id = "${aws_subnet.subnet.id}" availability_zone = "${var.az}" security_groups = ["${aws_security_group.sg.id}"] } resource "aws_eip" "pub_ip" { instance = "${aws_instance.compute.0.id}" vpc = true } output "awx" { value = "${aws_eip.pub_ip.public_ip}" } output "haproxy_id" { value = ["${slice(aws_instance.compute.*.id, 1, 3)}"] } output "awx_id" { value = "${aws_instance.compute.0.id}" } output "backend_id" { value = ["${slice(aws_instance.compute.*.id, 3, 5)}"] }
يبدو أن جميع الكيانات الموصوفة في هذا التكوين يجب أن يفهمها المستخدم العادي للغيوم الحديثة. يتم نقل المتغيرات الخاصة بالسحابة الخاصة بنا ولمهمة محددة إلى ملف منفصل - terraform.tfvars:
terraform.tfvars ec2_url = "https://api.cloud.croc.ru" access_key = "project:user@customer" secret_key = "secret-key" region = "croc" az = "ru-msk-vol51" instance_type = "m1.2small" big_instance_type = "m1.large" vpc_cidr_block = "10.10.0.0/16" ami = "cmi-3F5B011E"
إطلاق Terraform:
تطبيق terraform yes yes | terraform apply -var client_ip="$(curl -s ipinfo.io/ip)/32" -var material="$(cat <ssh_publick_key_path>)"
رصد الإعداد
تتم مراقبة VMs التي تم إطلاقها أعلاه تلقائيًا بواسطة السحابة الخاصة بنا. ستكون بيانات المراقبة هذه هي مصدر المعلومات لعملية التعيين الذاتي المستقبلية. بالاعتماد على مقاييس معينة ، يمكننا زيادة أو تقليل الطاقة.
تتيح لك المراقبة في السحابة الخاصة بنا تكوين أجهزة الإنذار وفقًا للظروف المختلفة للمقاييس المختلفة. انها مريحة جدا. لا نحتاج إلى تحليل المقاييس في أي فواصل زمنية واتخاذ قرار - سيتم ذلك عن طريق المراقبة السحابية. في هذا المثال ، سوف نستخدم أجهزة الإنذار الخاصة بمقاييس وحدة المعالجة المركزية ، ولكن في المراقبة الخاصة بنا يمكن أيضًا تكوينها لمقاييس مثل: استخدام الشبكة (السرعة / نقطة في الثانية) ، واستخدام القرص (السرعة / iops).
سحابة وضع متري إنذار export CLOUDWATCH_URL=https://monitoring.cloud.croc.ru for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm \ --alarm-name "scaling-low_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average \ --period 60 --evaluation-periods 3 --threshold 15 --comparison-operator LessThanOrEqualToThreshold; done for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm\ --alarm-name "scaling-high_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average\ --period 60 --evaluation-periods 3 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold; done
وصف بعض المعلمات التي قد تكون غير مفهومة:
--profile - ملف تعريف إعدادات aws-cli ، الموصوف في ~ / .aws / config. عادة ، يتم تعيين مفاتيح وصول مختلفة في ملفات تعريف مختلفة.
- أبعاد - تحدد المعلمة المورد الذي سيتم إنشاء المنبه ، في المثال أعلاه - للمثيل ذي المعرف من المتغير $ مثيل _.
- مساحة الاسم - مساحة الاسم التي سيتم تحديد مقياس المراقبة منها.
- اسم متري - اسم قياس الرصد.
- إحصائي - اسم طريقة تجميع القيمة المترية.
- فترة - الفاصل الزمني بين رصد أحداث جمع القيمة.
- فترات التقييم - عدد الفواصل الزمنية اللازمة لإطلاق إنذار.
- العتبة - قيمة العتبة المترية لتقييم حالة الإنذار.
- المقارنة - عامل - طريقة يتم استخدامها لتقييم قيمة المقياس بالنسبة إلى قيمة العتبة.
في المثال أعلاه ، يتم إنشاء جهازي إنذار لكل مثيل الواجهة الخلفية. سيتم تشغيل القياس المنخفض <instance-id> في حالة الإنذار عند تحميل وحدة المعالجة المركزية أقل من 15٪ لمدة 3 دقائق. سيتم تشغيل القياس - <instance-id> - المرتفع في حالة الإنذار عند تحميل وحدة المعالجة المركزية أكثر من 80٪ لمدة 3 دقائق.
تخصيص العلامة
بعد إعداد المراقبة ، نواجه المهمة التالية - اكتشاف الحالات وأسمائها (اكتشاف الخدمة). نحتاج أن نفهم بطريقة ما عدد الحالات الخلفية التي أطلقناها الآن ، ونحتاج أيضًا إلى معرفة أسمائهم. في عالم خارج السحابة ، على سبيل المثال ، سيكون قالب القنصل والقنصل مناسبًا لتكوين موازن. ولكن هناك علامات في سحابة لدينا. ستساعدنا العلامات في تصنيف الموارد. عن طريق طلب معلومات لعلامة معينة (وصف العلامات) ، يمكننا أن نفهم عدد الحالات التي لدينا حاليا في المجمع وما هو معرف لديهم. افتراضيًا ، يتم استخدام معرف مثيل فريد كاسم مضيف. بفضل DNS الداخلي الذي يعمل داخل VPC ، يتم حل أسماء الهوية / المضيفات هذه على مثيلات IP الداخلية.
نحن نضع علامات على مثيلات الواجهة الخلفية والموازنات:
ec2 إنشاء العلامات export EC2_URL="https://api.cloud.croc.ru" aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "<awx_instance_id>" \ --tags Key=env,Value=auto-scaling Key=role,Value=awx for i in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=backend ; done; for i in <haproxy_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=haproxy; done;
حيث:
--resources - قائمة بمعرفات الموارد التي سيتم تعيين العلامات لها.
- العلامات هي قائمة بأزواج القيمة الرئيسية.
يتوفر مثال لوصف العلامات في وثائق CROC Cloud.
إعداد التحجيم التلقائي
الآن بعد أن أصبحت السحابة تراقب ، ونعرف كيفية التعامل مع العلامات ، يمكننا فقط استقصاء حالة الإنذارات التي تم تكوينها للتشغيل. نحتاج هنا إلى كيان سيشارك في مهام المراقبة والرصد الدورية لإنشاء / حذف الحالات. يمكن تطبيق أدوات التشغيل الآلي المختلفة هنا. سوف نستخدم AWX. AWX هو إصدار مفتوح المصدر لبرج Ansible التجاري ، وهو منتج لإدارة البنية الأساسية Ansible مركزيًا. وتتمثل المهمة الرئيسية في إطلاق playbook لدينا ansible بشكل دوري.
مثال على نشر AWX متاح على صفحة الويكي في المستودع الرسمي. تم وصف تكوين AWX أيضًا في وثائق Ansible Tower. لكي تبدأ AWX في تشغيل قواعد التشغيل المخصصة ، يجب عليك تكوينها عن طريق إنشاء الكيانات التالية:
- أوراق اعتماد من ثلاثة أنواع:
- أوراق اعتماد AWS - لتخويل العمليات المتعلقة بسحابة CROC.
- بيانات اعتماد الجهاز - مفاتيح ssh للوصول إلى الحالات التي تم إنشاؤها حديثًا.
- أوراق اعتماد SCM - للحصول على إذن في نظام التحكم في الإصدار. - Project هو كيان سيدفع مستودع git من playbook.
- البرامج النصية - البرنامج النصي المخزون الديناميكي ل ansible.
- الجرد هو كيان يقوم باستدعاء البرنامج النصي للمخزون الديناميكي قبل بدء تشغيل playbook.
- قالب - تكوين مكالمة playbook معينة ، ويتألف من مجموعة من أوراق الاعتماد وجرد وقواعد اللعبة من Project.
- سير العمل - سلسلة من المكالمات playbooks
يمكن تقسيم عملية autoscaling إلى قسمين:
- scale_up - إنشاء مثيل عند تشغيل إنذار واحد على الأقل ؛
- scale_down - إنهاء مثيل إذا كان هناك إنذار منخفض يعمل عليه.
كجزء من الجزء scale_up ، ستحتاج إلى:
- استجواب خدمة المراقبة السحابية حول وجود أجهزة الإنذار العالية في حالة "المنبه" ؛
- إيقاف scale_up قبل الموعد المحدد إذا كانت جميع الإنذارات العالية في حالة "موافق" ؛
- إنشاء مثيل جديد بالسمات اللازمة (العلامة ، الشبكة الفرعية ، security_group ، إلخ) ؛
- إنشاء إنذارات عالية ومنخفضة لمثيل قيد التشغيل ؛
- تكوين تطبيقنا داخل مثيل جديد (في حالتنا ، سيكون مجرد nginx مع صفحة اختبار) ؛
- قم بتحديث تكوين haproxy ، وقم بإعادة تحميل بحيث تبدأ الطلبات في الانتقال إلى المثيل الجديد.
إنشاء instance.yaml --- - name: get alarm statuses describe_alarms: region: "croc" alarm_name_prefix: "scaling-high" alarm_state: "alarm" register: describe_alarms_query - name: stop if no alarms fired fail: msg: zero high alarms in alarm state when: describe_alarms_query.meta | length == 0 - name: create instance ec2: region: "croc" wait: yes state: present count: 1 key_name: "{{ hostvars[groups['tag_role_backend'][0]].ec2_key_name }}" instance_type: "{{ hostvars[groups['tag_role_backend'][0]].ec2_instance_type }}" image: "{{ hostvars[groups['tag_role_backend'][0]].ec2_image_id }}" group_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_security_group_ids }}" vpc_subnet_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_subnet_id }}" user_data: | #!/bin/sh sudo yum install epel-release -y sudo yum install nginx -y cat <<EOF > /etc/nginx/conf.d/dummy.conf server { listen 8080; location / { return 200 '{"message": "$HOSTNAME is up"}'; } } EOF sudo systemctl restart nginx loop: "{{ hostvars[groups['tag_role_backend'][0]] }}" register: new - name: create tag entry ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc state: present resource: "{{ item.id }}" tags: role: backend loop: "{{ new.instances }}" - name: create low alarms ec2_metric_alarm: state: present region: croc name: "scaling-low_{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: "<=" threshold: 15 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}" - name: create high alarms ec2_metric_alarm: state: present region: croc name: "scaling-high_{{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: ">=" threshold: 80.0 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}"
في create-example.yaml ، ما يحدث هو: إنشاء مثيل مع المعلمات الصحيحة ووضع علامات على هذا المثيل وإنشاء الإنذارات اللازمة. يتم تمرير البرنامج النصي لتثبيت وتكوين nginx أيضًا من خلال بيانات المستخدم. تتم معالجة بيانات المستخدم بواسطة خدمة cloud-init ، والتي تتيح التكوين المرن للمثيل أثناء بدء التشغيل دون اللجوء إلى أدوات التشغيل الآلي الأخرى.
في update-lb.yaml ، يتم إعادة إنشاء ملف /etc/haproxy/haproxy.cfg على مثيل haproxy وخدمة إعادة تحميل haproxy:
التحديث lb.yaml - name: update haproxy configs template: src: haproxy.cfg.j2 dest: /etc/haproxy/haproxy.cfg - name: add new backend host to haproxy systemd: name: haproxy state: restarted
حيث haproxy.cfg.j2 هو قالب ملف تكوين خدمة haproxy:
haproxy.cfg.j2 # {{ ansible_managed }} global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy stats timeout 30s user haproxy group haproxy daemon defaults log global mode http option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 frontend loadbalancing bind *:80 mode http default_backend backendnodes backend backendnodes balance roundrobin option httpchk HEAD / {% for host in groups['tag_role_backend'] %} server {{hostvars[host]['ec2_id']}} {{hostvars[host]['ec2_private_ip_address']}}:8080 check {% endfor %}
نظرًا لتعريف خيار httpchk في قسم الواجهة الخلفية لتكوين haproxy ، ستقوم خدمة haproxy باستقصاء حالات مثيلات الخلفية وحركة المرور الموازنة فقط بين الفحوصات الصحية السابقة.
في جزء التدرج الذي تحتاجه:
- تحقق ناقوس الخطر دولة منخفضة.
- إنهاء المسرحية قبل الأوان إذا لم يكن هناك إنذارات منخفضة في حالة "المنبه" ؛
- إنهاء جميع الحالات التي يكون فيها التنبيه المنخفض في فئة الإنذار ؛
- حظر إنهاء آخر زوج من الحالات ، حتى لو كانت إنذاراتهم في حالة الإنذار ؛
- إزالة الحالات التي أزلناها من تكوين موازن التحميل.
تدمير-instance.yaml - name: look for alarm status describe_alarms: region: "croc" alarm_name_prefix: "scaling-low" alarm_state: "alarm" register: describe_alarms_query - name: count alarmed instances set_fact: alarmed_count: "{{ describe_alarms_query.meta | length }}" alarmed_ids: "{{ describe_alarms_query.meta }}" - name: stop if no alarms fail: msg: no alarms fired when: alarmed_count | int == 0 - name: count all described instances set_fact: all_count: "{{ groups['tag_role_backend'] | length }}" - name: fail if last two instance remaining fail: msg: cant destroy last two instances when: all_count | int == 2 - name: destroy tags for marked instances ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc resource: "{{ alarmed_ids[0].split('_')[1] }}" state: absent tags: role: backend - name: destroy instances ec2: region: croc state: absent instance_ids: "{{ alarmed_ids[0].split('_')[1] }}" - name: destroy low alarms ec2_metric_alarm: state: absent region: croc name: "scaling-low_{{ alarmed_ids[0].split('_')[1] }}" - name: destroy high alarms ec2_metric_alarm: state: absent region: croc name: "scaling-high_{{ alarmed_ids[0].split('_')[1] }}"
في إتلاف-مثيل. yaml ، يتم حذف الإنذارات ، ويتم إنهاء المثيل وعلامة التمييز الخاصة به ، ويتم فحص الشروط التي تحظر إنهاء الحالات الأخيرة.
نحذف العلامات بشكل صريح بعد حذف المثيلات نظرًا لحقيقة أنه بعد حذف مثيل ، يتم حذف العلامات المرتبطة به ومتاحة لمدة دقيقة أخرى.
AWX.
تحديد المهام والقوالب
ستقوم مجموعة المهام التالية بإنشاء الكيانات اللازمة في AWX:
AWX-configure.yaml --- - name: Create tower organization tower_organization: name: "scaling-org" description: "scaling-org organization" state: present - name: Add tower cloud credential tower_credential: name: cloud description: croc cloud api creds organization: scaling-org kind: aws state: present username: "{{ croc_user }}" password: "{{ croc_password }}" - name: Add tower github credential tower_credential: name: ghe organization: scaling-org kind: scm state: present username: "{{ ghe_user }}" password: "{{ ghe_password }}" - name: Add tower ssh credential tower_credential: name: ssh description: ssh creds organization: scaling-org kind: ssh state: present username: "ec2-user" ssh_key_data: "{{ lookup('file', 'private.key') }}" - name: Add tower project tower_project: name: "auto-scaling" scm_type: git scm_credential: ghe scm_url: <repo-name> organization: "scaling-org" scm_branch: master state: present - name: create inventory tower_inventory: name: dynamic-inventory organization: "scaling-org" state: present - name: copy inventory script to awx copy: src: "{{ role_path }}/files/ec2.py" dest: /root/ec2.py - name: create inventory source shell: | export SCRIPT=$(tower-cli inventory_script create -n "ec2-script" --organization "scaling-org" --script @/root/ec2.py | grep ec2 | awk '{print $1}') tower-cli inventory_source create --update-on-launch True --credential cloud --source custom --inventory dynamic-inventory -n "ec2-source" --source-script $SCRIPT --source-vars '{"EC2_URL":"api.cloud.croc.ru","AWS_REGION": "croc"}' --overwrite True - name: Create create-instance template tower_job_template: name: "create-instance" job_type: "run" inventory: "dynamic-inventory" credential: "cloud" project: "auto-scaling" playbook: "create-instance.yaml" state: "present" register: create_instance - name: Create update-lb template tower_job_template: name: "update-lb" job_type: "run" inventory: "dynamic-inventory" credential: "ssh" project: "auto-scaling" playbook: "update-lb.yaml" credential: "ssh" state: "present" register: update_lb - name: Create destroy-instance template tower_job_template: name: "destroy-instance" job_type: "run" inventory: "dynamic-inventory" project: "auto-scaling" credential: "cloud" playbook: "destroy-instance.yaml" credential: "ssh" state: "present" register: destroy_instance - name: create workflow tower_workflow_template: name: auto_scaling organization: scaling-org schema: "{{ lookup('template', 'schema.j2')}}" - name: set scheduling shell: | tower-cli schedule create -n "3min" --workflow "auto_scaling" --rrule "DTSTART:$(date +%Y%m%dT%H%M%SZ) RRULE:FREQ=MINUTELY;INTERVAL=3"
سينشئ المقتطف السابق نموذجًا لكل من كتب اللعب المرئية المستخدمة. يقوم كل قالب بتكوين تشغيل playbook مع مجموعة من بيانات الاعتماد والمخزون المحددة.
لإنشاء توجيه للمكالمات إلى playbooks سوف يسمح قالب سير العمل. فيما يلي إعداد سير العمل للترميز التلقائي:
schema.j2 - failure_nodes: - id: 101 job_template: {{ destroy_instance.id }} success_nodes: - id: 102 job_template: {{ update_lb.id }} id: 103 job_template: {{ create_instance.id }} success_nodes: - id: 104 job_template: {{ update_lb.id }}
يعرض القالب السابق مخطط سير العمل ، أي تسلسل تنفيذ القالب. في سير العمل هذا ، سيتم تنفيذ كل خطوة تالية (success_nodes) فقط إذا تم إكمال الخطوة السابقة بنجاح. يتم عرض تمثيل رسومي لسير العمل في الصورة:
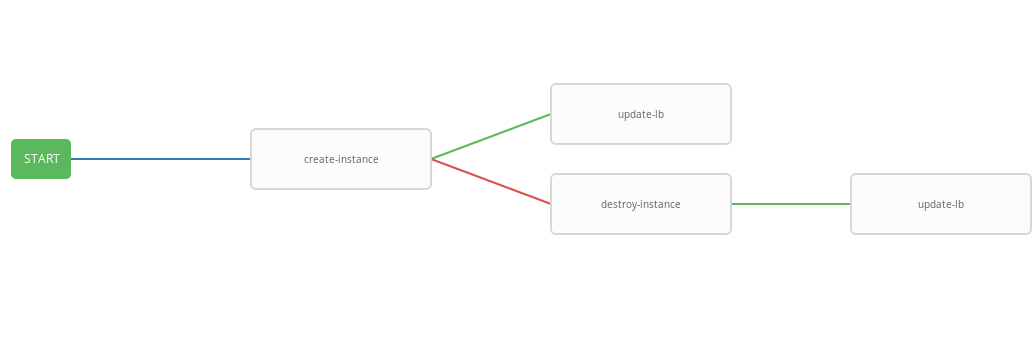
كنتيجة لذلك ، تم إنشاء سير عمل معمم ينفذ كتاب قواعد إنشاء و / أو بناءً على حالة التنفيذ وكتب التشغيل المدمرة و / أو التحديث - رطل. سير العمل المتكامل مناسب للعمل وفق جدول محدد. ستبدأ عملية القياس التلقائي كل ثلاث دقائق ، حيث تبدأ وتنتهي الحالات حسب حالة الإنذار.
اختبار العمل
تحقق الآن من تشغيل النظام المكوّن. أولاً ، قم بتثبيت الأداة المساعدة wrk لقياس http.
تثبيت wrk ssh -A ec2-user@<aws_instance_ip> sudo su - cd /opt yum groupinstall 'Development Tools' yum install -y openssl-devel git git clone https://github.com/wg/wrk.git wrk cd wrk make install wrk /usr/local/bin exit
سنستخدم المراقبة السحابية لمراقبة استخدام موارد المثيل أثناء التحميل:
مراقبة function CPUUtilizationMonitoring() { local AWS_CLI_PROFILE="<aws_cli_profile>" local CLOUDWATCH_URL="https://monitoring.cloud.croc.ru" local API_URL="https://api.cloud.croc.ru" local STATS="" local ALARM_STATUS="" local IDS=$(aws --profile $AWS_CLI_PROFILE --endpoint-url $API_URL ec2 describe-instances --filter Name=tag:role,Values=backend | grep -i instanceid | grep -oE 'i-[a-zA-Z0-9]*' | tr '\n' ' ') for instance_id in $IDS; do STATS="$STATS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch get-metric-statistics --dimensions Name=InstanceId,Value=$instance_id --namespace "AWS/EC2" --metric CPUUtilization --end-time $(date --iso-8601=minutes) --start-time $(date -d "$(date --iso-8601=minutes) - 1 min" --iso-8601=minutes) --period 60 --statistics Average | grep -i average)"; ALARMS_STATUS="$ALARMS_STATUS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch describe-alarms --alarm-names scaling-high-$instance_id | grep -i statevalue)" done echo $STATS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t echo $ALARMS_STATUS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t } export -f CPUUtilizationMonitoring watch -n 60 bash -c CPUUtilizationMonitoring
يأخذ البرنامج النصي السابق مرة كل 60 ثانية معلومات حول متوسط قيمة قياس CPUUtilization للدقيقة الأخيرة ويستقصي حالة الإنذارات لمثيلات الخلفية.
يمكنك الآن تشغيل wrk وإلقاء نظرة على استخدام موارد مثيلات الواجهة الخلفية تحت الحمل:
ركض المدى ssh -A ec2-user@<awx_instance_ip> wrk -t12 -c100 -d500s http://<haproxy_instance_id> exit
سيُطلق الأمر الأخير المعيار لمدة 500 ثانية ، باستخدام 12 موضوعًا وفتح 100 اتصال HTTP.
بمرور الوقت ، يجب أن يظهر البرنامج النصي للمراقبة أن القيمة الإحصائية لمقياس CPUUtilization تزداد خلال المؤشر حتى تصل إلى 300٪. بعد 180 ثانية من بدء الاختبار ، يجب أن تحول إشارة StateValue إلى حالة الإنذار. مرة واحدة كل دقيقتين ، يبدأ سير العمل autoscaling. افتراضيًا ، يحظر التنفيذ المتوازي لسير العمل نفسه. وهذا هو ، كل دقيقتين ، ستتم إضافة مهمة لتنفيذ سير العمل إلى قائمة الانتظار وسيتم تشغيلها فقط بعد الانتهاء من سابقتها. وبالتالي ، أثناء عمل wrk ، ستكون هناك زيادة مستمرة في الموارد حتى تدخل الإنذارات العالية لجميع الحالات الخلفية إلى الحالة "موافق". عند الانتهاء ، يقوم سير عمل scale_down wrk بإنهاء جميع مثيلات الواجهة الخلفية باستثناء حالتين.
مثال على إخراج البرنامج النصي للمراقبة:
نتائج الرصد # start test i-43477460 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # start http load i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 111.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # alarm state i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 282.0 i-43477460 |i-AC5D9EE0 "StateValue": "alarm"| "StateValue": "alarm" # two new instances created i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "Average": 185.0 | "Average": 215.0 | "Average": 245.0 | i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "StateValue": "insufficient_data"| "StateValue": "insufficient_data"| "StateValue": "alarm"| "StateValue": "alarm" # only two instances left after load has been stopped i-935BAB40 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-935BAB40 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok"
أيضا في CROC Cloud ، يمكنك عرض الرسوم البيانية المستخدمة في منشور المراقبة في صفحة المثيل في علامة التبويب المقابلة.
عرض الإنذارات متاح في صفحة المراقبة في علامة تبويب الإنذارات.
استنتاج
يعد Autoscaling سيناريو شائعًا إلى حد ما ، لكن لسوء الحظ ، ليس في سحابة لدينا حتى الآن (ولكن الآن فقط). ومع ذلك ، لدينا الكثير من واجهات برمجة التطبيقات القوية للقيام بأشياء مماثلة وأشياء أخرى كثيرة ، باستخدام أدوات شائعة ، شبه قياسية ، مثل Terraform و ansible و aws-cli وغيرها.