تحية! اسمي Vitaliy Kostousov ، أعمل في فريق Global Tech Heroes ، وسأخبرك اليوم عن الدعم - أحد أهم المكونات في أي خدمة. يمكنك إنشاء تطبيق رائع مع صور رائعة وفي بعض الأحيان تمزيق برامج الدردشة. يمكنك تفريغ علنا ، في البداية تقدم للعملاء خدمة منخفضة التكلفة. يمكنك استئجار صندوق SMM رائع لن تشعر بالخجل له ولن يتوجب عليك تغييره كمحاسب في التسعينيات.
ولكن كل هذا يمكن أن يتعثر بشكل جيد في حالة عدم وجود دعم عاقل لخدمتك. والدعم بالمعنى الشامل - من حل مشكلات المستخدم إلى ضمان وظائف البرامج والأجهزة. حسنًا ، بجدية ، كم من الوقت سوف يستخدم الناس التطبيق ، الذي كان غبيًا لبضعة أسابيع ، وما زال المطورون لم يستجيبوا بشكل طبيعي للمشاكل ، خدمة الدعم غير مُشتَقة بالإجابات الآلية ، وفي مركز الاتصال يمكنك الاستماع إلى الموسيقى الكلاسيكية مجانًا لساعات؟

نظرًا لأن لدينا كل شيء مرتب ، ما نستخدمه في عملنا للكشف عن المشاكل وحلها ، وكم منا وكل شيء آخر قيد التشغيل.
نعمل الآن في 3 دول: روسيا والمملكة المتحدة وإسرائيل ، ولدينا مئات الآلاف من المستخدمين النشطين ، عملاء الشركات بمفردهم أكثر من 20،000. هناك طلبات يومية كافية إلى طلباتنا. وهناك سائقين وطلبات منهم. وكذلك النظم الداخلية والمراقبة. كل هذا يجب أن تعمل ، وتعمل بشكل جيد. للقيام بذلك ، لدينا فريق دعم فني عالمي يسمى داخل "Tech Heroes" - فرق البحث والتطوير ومشغلي التصعيد والمهندسين ، وكذلك مدير الحوادث العالمي. وهذا ما يواجهونه في عملهم.
فريق والمستخدمين
قم بالحجز على الفور بأن المستخدمين النهائيين لفريقنا لا يعنيون فقط العملاء والسائقين الذين هم في الأولوية (الخاصة والشركات) ، ولكن أيضًا التسويق وخدمات الدعم والإدارات الداخلية لدينا. بطبيعة الحال ، يكتبون لدعم إما باستخدام التطبيق ، أو على الشبكات الاجتماعية. إذا كانت المشكلة ذات طبيعة فنية ، فإن المهمة داخل SalesForce تذهب إلينا على الفور. يمكنهم الكتابة ليس فقط حول التطبيق وجودة عمله ككل أو بعض الوظائف بشكل خاص ، ولكن أيضًا عن أداء الخدمات الداخلية للشركة. يوجد أكثر من 1000 موظف من Gett يقومون بطرح أسئلة حول البرامج العملية وتنظيم العمليات.
يتكون فريقنا من 8 أشخاص موزعين في ثلاث دول - إسرائيل وبريطانيا العظمى وروسيا. يعمل متخصص من روسيا عن بعد ، وتشمل مسؤولياته العمل مع العمليات التشغيلية: مراقبة وإجراء تغييرات على خدماتنا الرئيسية. يشارك السبعة الباقون في مشكلات تشغيلية ، والعديد من الأمور الأخرى: الاختبار ، الأخطاء ، المواصفات ، حل المكالمات بسرعة التي تأتي من المتخصصين التشغيليين والمديرين ، وأيضًا مراقبة جميع قواعد البيانات والخدمات والخدمات المصغرة الخاصة بنا. يعالج هذا الفريق جميع التذاكر ، من أي بلد يصلون إليه. بالنسبة للجزء الأكبر ، يتعين عليك التعامل مع المشكلات المحلية ، لكن يحدث أن يكون هناك بعض الأخطاء الخطيرة في عمل الخدمات العالمية ، ثم ينتقل العمل إلى الوضع العالمي.
تحتاج أيضًا إلى التفكير في أن لدينا الكثير من عملاء b2b حول العالم - يحتوي النظام على إعدادات مرنة للغاية وإمكانية تكامل الأعمال مع خدمات الشركة. أي أن هناك فئات سيارات أكثر بكثير مما يراه المستخدمون الخاصون بالخدمة. من المهم أن نفهم أن كل هذا يؤثر على كل من تشغيل الخدمات وعدد عمليات المعاملات. يمكن للجزء B2B استخدام حساب شخصي على موقع الشركة.
ناعم
هناك عدة أنظمة للعمل مع التذاكر في السوق والتي أثبتت بالفعل فائدتها: LiveAgent و ZenDesk و ZohoDesk وغيرها. يمكنك الاختيار وفقًا للراحة ، يمكنك الخروج عن العادة ، يمكنك - بدءًا من نوع البرامج التي يعمل معها زملاؤك ، حتى لا يتم حظر مجموعة من الطبقات والعكازات (والتي يجب أيضًا دعمها وإنهائها). لذلك ، نحن نعمل لصالح SalesForce ، حيث يتم استخدامه من قبل المناطق التشغيلية الرئيسية للشركة (المبيعات والدعم). يتيح لك هذا تتبع حالة كل حالة من جانب منشئها. هناك أولوية تلقائية للحالات بناءً على موضوعات الاستئناف. يتم دمج SalesForce أيضًا في Jira ، وإذا تم إنشاء مهمة أو إدخال خطأ في التطوير ، فسيتم عرض حالتها أيضًا في هذه الحالة. هذه هي الطريقة التي نحقق بها اتصالات شفافة بين الدعم والتطوير.
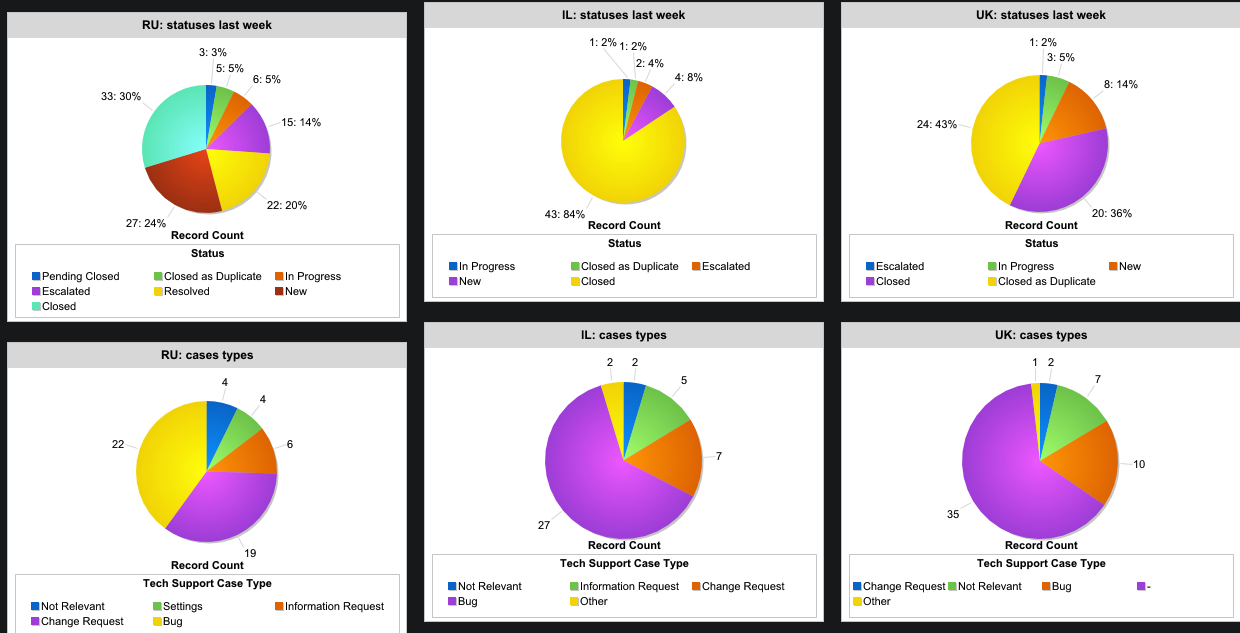 SalesForce ، قابلة للنقر
SalesForce ، قابلة للنقريسمح لك نظام تطبيق مخصص بتتبع SLA لكل تذكرة تصل إلينا.
التذاكر والطلبات
على وجه التحديد ، يشارك فريقنا في عمل التطبيق نفسه (لكل من السائقين والركاب) ، والخدمات المصغرة التي يعمل معها المتخصصون التشغيليون ، وكذلك الاختبار والمراقبة. بالإضافة إلى ذلك ، هناك دائمًا طلبات للحصول على تقارير ومراقبة جديدة ، والتي قد تكون مفيدة للزملاء من الإدارات الأخرى. في الوقت نفسه ، يكون هناك بعض المراقبة الصارمة لفريقنا ، إذا كانت تتعلق حصريًا بالمعلمات التقنية للخدمات وقواعد البيانات. يرسل جزء من المراقبة تنبيهات إلينا ، إلى الفريق المسؤول والدعم. إذا كانت المشكلة متصلة ، على سبيل المثال ، مع تطبيق برنامج التشغيل ، فسيستجيب الدعم بشكل أسرع ويبلغ السائقين إذا لزم الأمر. وبالتالي ، يتم تقليل توقيت المعلومات إلى بضع دقائق.
مراقبة
لدينا الكثير من المراقبة. بمجرد أن يعمل أحدهما ، سواء كان newrelic (خدمات النظام أعلى) ، grafana (مراقبة سيناريوهات محددة) ، datadog (وقت تشغيل البنية التحتية) ، نتلقى على الفور إشعارًا في Slack ونتلقى مكالمة بدورنا (بفضل pagerduty). ولفترة زمنية معينة يتم تعيين شخص واحد. نظرًا لأن هذا يحدث تلقائيًا ، فمن المحتمل أن هذا الشخص المعين غير متوفر حاليًا أو ببساطة لم يرد ، ثم سيتم إعادة توجيه المكالمة على طول السلسلة.
عندما يتم تشغيل التنبيهات ، نقوم بإعادة فحص أداء الأنظمة ومعرفة سبب الفشل (أو الحمل المتزايد ، أو عدد كبير من الأحداث أو المكالمات ، التي ستطير هنا). إذا فهمنا أن هذه مشكلة ويجب حلها ، فسنرسل خطابًا إلى مجموعات التوزيع الخاصة للمتخصصين في العمليات.
لذلك ، نحن دائما على الانترنت.
إدارة الحوادث
إذا كانت شركتك تقدم خدمات ، فإن إدارة الحوادث لن تكون موجودة. نحن نعمل وفقًا لهذا المخطط:
- الكشف في الوقت المناسب من المشاكل.
- الإخطار بمشكلة الأشخاص المسؤولين.
- إخطار أصحاب المصلحة على جميع المستويات. أي أننا نتحدث عن مشكلة العمل ، بحيث يفهم الجميع هناك بالضبط كيف تؤثر هذه المشكلات على الشركات والأرباح.
- الحفاظ على أقصى قدر من الشفافية في العمل.
- تحليل السبب الجذري الإلزامي. بعد كل شيء ، لديها أصول المشكلة ، ويمكن منع المشكلة التالية. هذا هو أسرع وأكثر فائدة من حلها مرة أخرى في الجولة الثانية.
الهدف هو معرفة المشكلات في مراحل الصفر. هذا هو عندما كنت أنت الذي اكتشف المشكلة كموظف يوفر القدرة على العمل. ليس عندما أبلغك العميل عنها. لذلك ، نحن نستخدم مجموعة أدوات APM (مراقبة أداء التطبيق) بنشاط. سأعبر عنهم مرة أخرى.
NewRelic- مراقبة جميع الخدمات والبوابات المصغرة الخاصة بنا
- أخطاء 50x ، 4xx
- ريديس apdex
- DBs Apdex
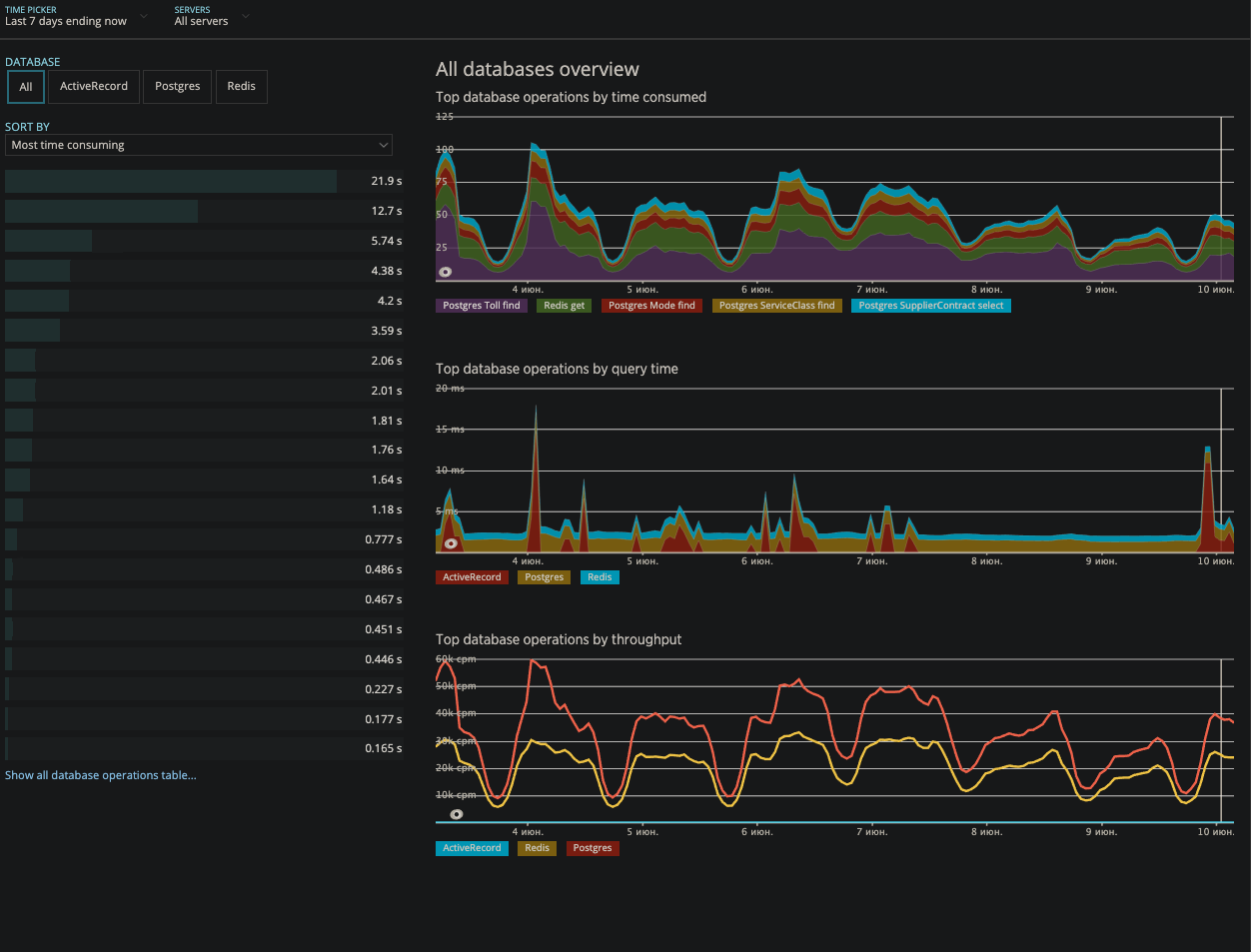 NewRelic ، قابلة للنقرGrafana
NewRelic ، قابلة للنقرGrafana . مراقبة الأحداث (توضح ما هو بالضبط توقف العمل أو السلوك يختلف عن الطبيعي).
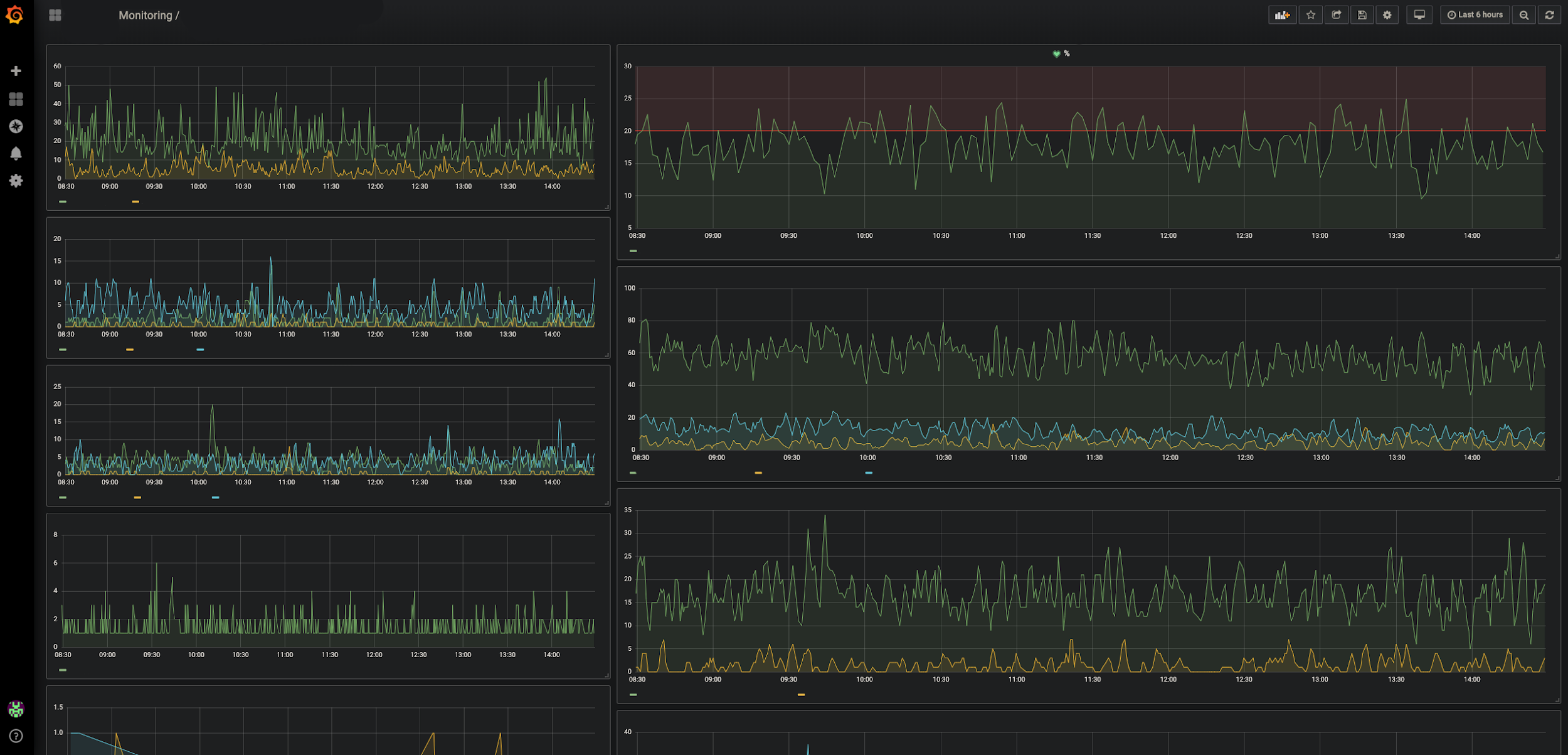 غرافانا ، قابلة للنقرDataDog
غرافانا ، قابلة للنقرDataDog . مراقبة مكونات الأجهزة لنظامنا (قواعد البيانات ، موازن التحميل).
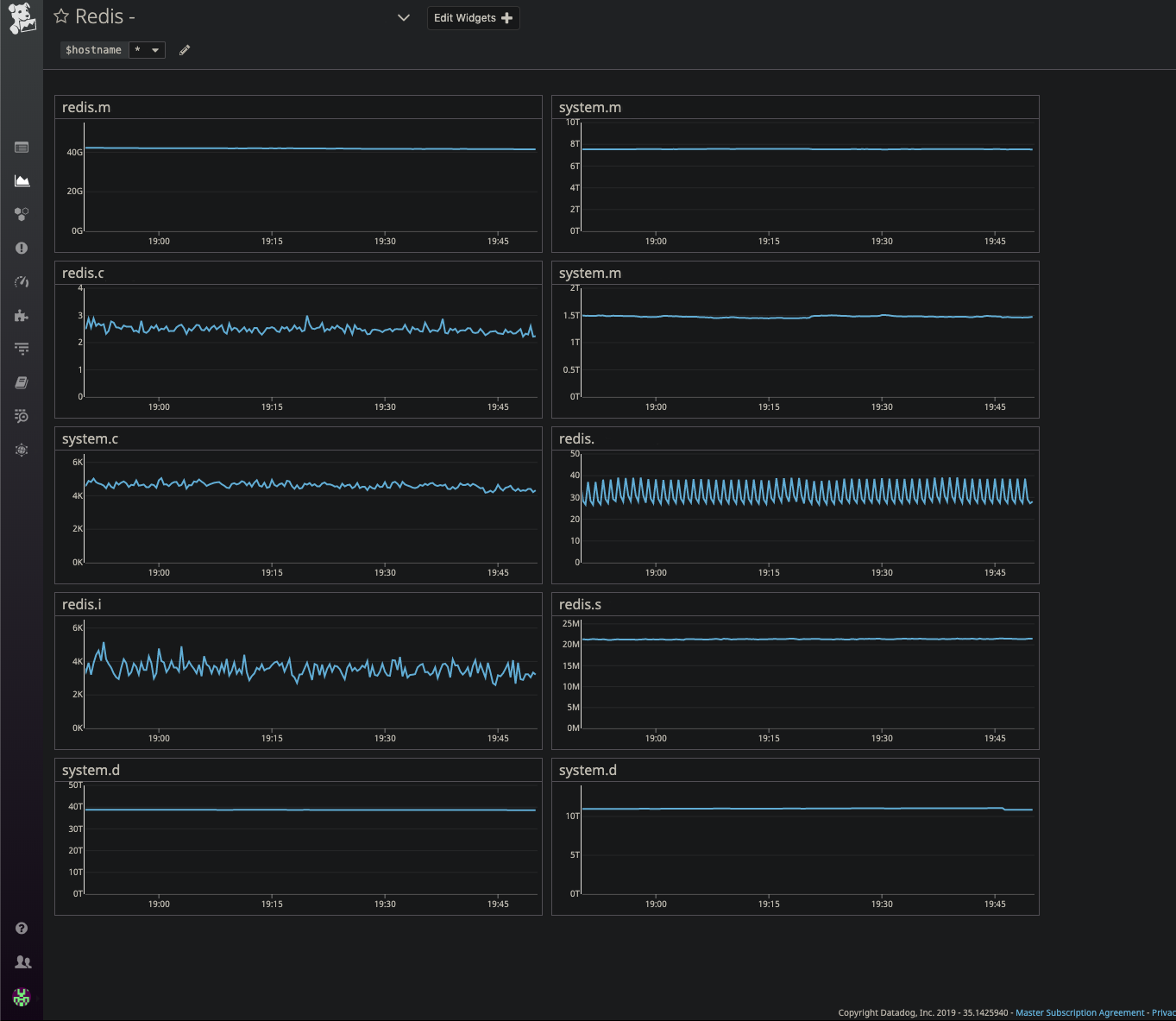 DataDog ، قابلة للنقرو Airbrake
DataDog ، قابلة للنقرو Airbrake . استثناءات التعليمات البرمجية للتطبيقات / الخدمات الصغيرة (هناك قائمة من الاستثناءات ، على سبيل المثال ، عند تنفيذ التعليمات البرمجية أو الاستعلامات في قاعدة البيانات ، إذا حدث خطأ ما وكان مدرجًا في القائمة - نحن نتتبعه).
Kibana - مراقبة سجلات microservice / التطبيق (برنامج التشغيل / العميل).
ولكي يعمل كل شيء ليس فقط للكشف ، ولكن أيضًا
للإعلام في الوقت المناسب (على الفور ، كلما كان ذلك أسرع - كلما كان ذلك أفضل) ، كل هذا مرتبط بعدد من قنوات الإعلام ، من Slack و
PagerDuty إلى إعلامات البريد الإلكتروني القديمة الجيدة. لذلك ، سيتعرف الفريق بالكامل على الفور على أي حالات شاذة. يمكن إرسال التنبيهات إلى قنوات مختلفة. تقوم المراقبة المهمة لتشغيل التطبيقات دائمًا بإرسال التنبيهات إلى فريق الدعم الفني وبشكل انتقائي إلى قنوات فرق التطوير المسؤولة عن ميزة / خدمة محددة. كل هذا يساعد على تحسين وقت الاستجابة.
نشأت صعوبات في الخطوة التالية ، عندما بعد العثور على مشكلة ، يجب عليك إخطار الشخص المسؤول عن الخدمة بسرعة. وهذا ليس بالأمر السهل جدًا إذا كان هناك الكثير من العمليات والخدمات المصغرة ، مما يعني أنه لا توجد عمليات أقل مسؤولية. ويمكن أن يصل التنبيه في وقت متأخر من الليل ، عندما تريد أي شيء ، لكنك لا تفصل من المسؤول عن ماذا.
لذلك ، أنشأنا دليلًا مناسبًا يسرد جميع مالكي الخدمات (عمومًا في الشركة). كما أظهرت الممارسة ، ساعدنا هذا وحده في تقليل الوقت اللازم لحل كل حادث بنسبة 20٪ تقريبًا.
أفضل وصفة لكارثة مستمرة في هذه الحالة هو ترك الحادث دون وجود شخص مسؤول.
هناك شخص مميز ، مدير الحوادث العالمي ، يعمل كمركز للحوادث الخطيرة. يشارك في مراقبة وتغيير النظم الأساسية للتخلص من الأخطاء التي يمكن أن تؤدي إلى عظام الشركة ، وهو مسؤول أمام كبار المسؤولين في الشركة ، ويزودهم بتقارير مفصلة عن تحليل الأسباب الجذرية.
لذلك ، باختصار ، تبدو عملية إدارة الحوادث نفسها كما يلي:
- نحدد أسباب الحادث.
- نجد الشخص المسؤول.
- نحن ننسق الجهود معه لحل المشكلة في أسرع وقت ممكن.
- نتخذ جميع القرارات اللازمة خلال الحادث.
- نحن نبلغ الشركة بهذا ، ونقدم لهم جميع المشاكل.
- عندما ينتشر الغبار ، نبدأ في تحليل السبب الجذري ، RCA (تحليل السبب الجذري).
نقوم ببناء تقارير الحوادث في جيرا ، وهناك وحدة المقابلة ،
والحوادث ، قمنا بإضافة عدد من الحقول الإضافية هناك.
لا يوجد سوى ثلاث مراحل من RCA.
1. RCA الأوليهذا هو وصف المستوى الأعلى لسبب المشكلة (سواء كانت مشكلة في قاعدة البيانات ، أو مع البنية التحتية ، أو مع الكود). يتم إعداد هذا التقرير من قبل ضابط الدعم الذي أدار الحادث. يجب إكمال التقرير في غضون 24 ساعة بعد الانتهاء من الحادث.
2. r & d rcaيجب إكمال الجزء الأكثر أهمية من العملية في غضون 48 ساعة بعد الانتهاء من الحادث. إليك بالفعل تحليل تقني كامل للسبب الجذري - لماذا حدث ذلك ، ولماذا لم يتم العثور عليه (تم التغاضي عن الاختبار أو عدم وجود مراقبة مناسبة) ، هل هناك فرصة لحدوث ذلك مرة أخرى ، وما يجب فعله لمنع حدوث ذلك مرة أخرى.
3. الإجراءاتبناءً على الفقرة الثانية ، يتم تكوين المهام الفرعية المقابلة ، يظل الحادث مفتوحًا حتى يتم إغلاق آخر هذه المهام الفرعية. لا أحد يريد هذه المهمة أن تأخذ kanban لفترة طويلة ، لذلك هذا يحفز على حل كل شيء بشكل أسرع.
هذه هي الطريقة التي نعمل بها في Gett مع الحوادث.
الأرقام والتقنيات
نحن نعمل ، بالطبع ، على مدار الساعة طوال أيام الأسبوع من خلال اتفاقية مستوى الخدمة 99.99٪. المكدس الرئيسي لدينا على GoLang / Ruby ، وهذا يعطي السرعة اللازمة لمعالجة الخوارزميات المعقدة. هناك أكثر من 150 خدمة ميكروية في المجموع ، وجميعها موجودة أيضًا على GoLang و Ruby. نحن نستخدم MySQL و Postgres و Presto كقواعد بيانات. لدينا تخزين على AWS.
يقع أخطر الحمل على خدماتنا في عطلة رأس السنة الجديدة والأسبوعين السابقين. تؤثر حالة المنافسين أيضًا ، على سبيل المثال ، قام أحدهم بإسقاط التطبيق ، مما يعني أنه سيتم استدعاء آلاتنا في كثير من الأحيان.
هناك أيضًا قمم في العمل الداخلي تؤثر على المستخدمين النهائيين. على سبيل المثال ، عندما نقوم بتحديث قاعدة البيانات أو القيام بأعمال فنية إلى جانب الموردين والبائعين ، أو نشر خدمات جديدة للإنتاج (ليس يوم الجمعة ، نعم) ، أو نقوم بتفويض ميزات تؤثر فورًا على عدد كبير من المستخدمين أو المعاملات.
نحن أشخاص أيضًا ، وأحيانًا يحدث أن الإعدادات غير الصحيحة أو التدخل اليدوي تؤدي إلى أخطاء تشغيلية ، لذلك قمنا بتطوير خطة لهذه الحالة:

لا ليس هذا. هنا:
- نحن نتحقق من البيانات في الخدمات والسجلات والمراجعات.
- نحن اختبار وتنفيذ عمليات التحديث على سكروم.
- نقوم بإعداد مهمة للفريق ومراقبة تنفيذ المهمة على الإنتاج.
إذا كنت مهتمًا بأي تفاصيل ، ولا تتردد في طرح الأسئلة في التعليقات ، فسنقوم بالإجابة إما هنا أو في منشور تفصيلي منفصل.