ما هو المهم لفريق التطوير الذي بدأ للتو في بناء نظام التعلم الآلي؟ الهندسة المعمارية ، والمكونات ، وقدرات الاختبار باستخدام التكامل واختبارات وحدة ، وجعل النموذج الأولي والحصول على النتائج الأولى. وكذلك لتقييم مدخلات العمل وتخطيط التطوير والتنفيذ.
سوف تركز هذه المقالة على النموذج الأولي. الذي تم إنشاؤه بعض الوقت بعد التحدث مع مدير المنتج: لماذا لا "نلمس" تعلم الآلة؟ على وجه الخصوص ، البرمجة اللغوية العصبية وتحليل المشاعر؟
"لماذا لا؟" أجبت. ومع ذلك ، كنت أقوم بتطوير الواجهة الخلفية لأكثر من 15 عامًا ، أحب العمل مع البيانات وحل مشاكل الأداء. لكن ما زلت مضطرًا إلى معرفة "مدى عمق حفرة الأرنب".
حدد المكونات
من أجل تحديد مجموعة المكونات التي تنفذ منطق ML لدينا بطريقة أو بأخرى ، دعونا نلقي نظرة على مثال بسيط لتنفيذ تحليل المشاعر ، واحدة من العديد من المتاحة على GitHub.
مثال واحد لتحليل المشاعر في بيثونimport collections import nltk import os from sklearn import ( datasets, model_selection, feature_extraction, linear_model ) def extract_features(corpus): '''Extract TF-IDF features from corpus'''
تحليل مثل هذه الأمثلة هو تحدٍ منفصل للمطور.
فقط 45 سطرًا من التعليمات البرمجية و 4 (أربعة ، Karl!) كتل منطقية دفعة واحدة:
- تنزيل البيانات للتدريب النموذجي (الأسطر 25-26)
- إعداد البيانات التي تم تحميلها - استخراج الميزة (الأسطر 31-34)
- إنشاء وتدريب نموذج (خطوط 36-39)
- اختبار نموذج المدربين ونتائج إخراج (خطوط 41-45)
كل نقطة من هذه النقاط تستحق مقالة منفصلة. وبالتأكيد يتطلب التسجيل في وحدة منفصلة. على الأقل لتلبية احتياجات وحدة الاختبار.
بشكل منفصل ، يجدر تسليط الضوء على مكونات إعداد البيانات والتدريب النموذجي.
في كل طريقة لجعل النموذج أكثر دقة ، يتم استثمار مئات الساعات من العمل العلمي والهندسي.
لحسن الحظ ، من أجل البدء بسرعة في البرمجة اللغوية العصبية (NLP) ، يوجد حل جاهز -
مكتبات NLTK و
TextBlob . والثاني عبارة عن غلاف على NLTK يقوم بالأعمال الروتينية - يجعل استخراج الميزة من مجموعة التدريب ، ثم يدرب النموذج على طلب التصنيف الأول.
ولكن قبل تدريب النموذج ، تحتاج إلى إعداد البيانات لذلك.
إعداد البيانات
تحميل البيانات
إذا تحدثنا عن النموذج الأولي ، فسيكون تحميل البيانات من ملف CSV / TSV أساسيًا. يمكنك ببساطة استدعاء وظيفة
read_csv من مكتبة الباندا:
import pandas as pd data = pd.read_csv(data_path, delimiter)
لكن لن تكون البيانات جاهزة للاستخدام في النموذج.
أولاً ، إذا تجاهلنا تنسيق ملف بتنسيق csv قليلاً ، فمن السهل أن نتوقع أن يزود كل مصدر البيانات بخصائصه الخاصة ، وبالتالي نحتاج إلى نوع من إعداد البيانات المعتمدة على المصدر. حتى بالنسبة لأبسط الحالات في ملف CSV ، لتحليلها فقط ، نحتاج إلى معرفة المحدد.
بالإضافة إلى ذلك ، يجب عليك تحديد الإدخالات الإيجابية والسالبة. بالطبع ، تتم الإشارة إلى هذه المعلومات في التعليق التوضيحي على مجموعات البيانات التي نريد استخدامها. ولكن الحقيقة هي أنه في إحدى الحالات تكون علامة pos / neg هي 0 أو 1 ، وفي الحالة الأخرى تكون True / False منطقية ، وفي الحالة الثالثة تكون عبارة عن سلسلة pos / neg ، وفي بعض الحالات ، مجموعة من الأعداد الصحيحة من 0 إلى 5 هذا الأخير ذو صلة بحالة التصنيف متعدد الطبقات ، لكن من قال إن مجموعة البيانات هذه لا يمكن استخدامها للتصنيف الثنائي؟ تحتاج فقط إلى تحديد حدود القيم الإيجابية والسلبية بشكل كاف.
أرغب في تجربة النموذج على مجموعات بيانات مختلفة ، ويلزم أن يقوم النموذج بعد التدريب بإرجاع النتيجة بتنسيق واحد. ولهذا الغرض ، ينبغي إحضار بياناتها غير المتجانسة إلى نموذج واحد.
لذلك ، هناك ثلاث وظائف نحتاجها في مرحلة تحميل البيانات:
- الاتصال بمصدر البيانات خاص بـ CSV ، في حالتنا يتم تنفيذه داخل وظيفة read_csv ؛
- دعم لميزات الشكل ؛
- إعداد البيانات الأولية.
هذه هي الطريقة التي تبدو بها في الكود.
import numpy as np
تم إجراء الفئة
CsvSentimentDataLoader ، والتي يتم من خلالها في المُنشئ تمرير المسار إلى csv ، الفاصل ، أسماء النص والتصنيف ، بالإضافة إلى قائمة القيم التي تنصح بالقيمة الإيجابية للنص.
يحدث التحميل نفسه في طريقة
load_data .
نقسم البيانات إلى مجموعات اختبار وتدريب
حسنًا ، لقد حمّلنا البيانات ، لكننا ما زلنا بحاجة إلى تقسيمها إلى مجموعات التدريب والاختبار.
يتم ذلك باستخدام الدالة
train_test_split من مكتبة
sklearn . يمكن أن تأخذ هذه الوظيفة الكثير من المعلمات كمدخلات ، حيث تحدد بالضبط كيف سيتم تقسيم مجموعة البيانات هذه إلى تدريب واختبار. تؤثر هذه المعلمات بشكل كبير على مجموعات التدريب والاختبار الناتجة ، ومن المحتمل أن يكون من المناسب بالنسبة لنا إنشاء فصل (دعنا نسميه SimpleDataSplitter) يقوم بإدارة هذه المعلمات وتجميع الاستدعاء لهذه الوظيفة.
from sklearn.model_selection import train_test_split
تشتمل هذه الفئة الآن على أبسط تطبيق ، والذي ، عند تقسيمه ، سيأخذ بعين الاعتبار معلمة واحدة فقط - النسبة المئوية للسجلات التي يجب أن تؤخذ على أنها مجموعة اختبار.
قواعد البيانات
لتدريب النموذج ، استخدمت مجموعات البيانات المتاحة مجانًا بتنسيق CSV:
ولجعله أكثر ملاءمة ، بالنسبة لكل مجموعة من مجموعات البيانات ، قمت بإنشاء فصل يقوم بتحميل البيانات من ملف CSV المقابل ويقسمها إلى مجموعات تدريب واختبار.
import os import collections import logging from web.data.loaders import CsvSentimentDataLoader from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter log = logging.getLogger() class AmazonAlexaDataset(): def __init__(self): self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv')) self.delim = '\t' self.text_attr = 'verified_reviews' self.rate_attr = 'feedback' self.pos_rates = [1] self.data = None self.train = None self.test = None def load_data(self): loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates) splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3) self.data = loader.load_data() x_train, x_test, y_train, y_test = splitter.split_data(self.data) self.train = [x for x in zip(x_train, y_train)] self.test = [x for x in zip(x_test, y_test)]
نعم ، بالنسبة لتحميل البيانات ، اتضح أن ما يزيد قليلاً عن 5 سطور من التعليمات البرمجية في المثال الأصلي.
ولكن أصبح من الممكن الآن إنشاء مجموعات بيانات جديدة عن طريق تجميع مصادر البيانات وخوارزميات إعداد مجموعة التدريب.
بالإضافة إلى ذلك ، تعد المكونات الفردية أكثر ملاءمة لاختبار الوحدات.
نحن ندرب النموذج
كان النموذج يتعلم لبعض الوقت. ويجب أن يتم ذلك مرة واحدة ، في بداية التطبيق.
لهذه الأغراض ، تم تصنيع غلاف صغير يتيح لك تنزيل البيانات وإعدادها ، بالإضافة إلى تدريب النموذج في وقت تهيئة التطبيق.
class TextBlobWrapper(): def __init__(self): self.log = logging.getLogger() self.is_model_trained = False self.classifier = None def init_app(self): self.log.info('>>>>> TextBlob initialization started') self.ensure_model_is_trained() self.log.info('>>>>> TextBlob initialization completed') def ensure_model_is_trained(self): if not self.is_model_trained: ds = SentimentLabelledDataset() ds.load_data()
أولاً نحصل على بيانات التدريب والاختبار ، ثم نقوم باستخراج الميزات ، وأخيراً نقوم بتدريب المصنف ونتحقق من دقة مجموعة الاختبار.
تجريب
عند التهيئة ، نحصل على سجل ، نحكم من خلاله ، تم تنزيل البيانات وتم تدريب النموذج بنجاح. ومدربة مع دقة جيدة جدا (للمبتدئين) - 0.8878.
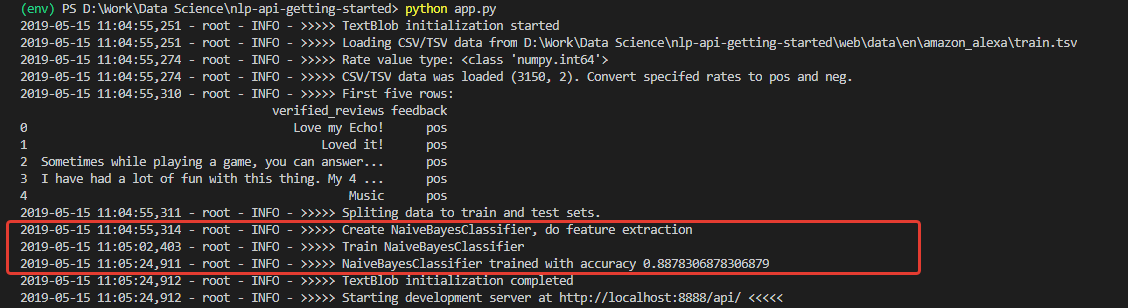
بعد تلقي هذه الأرقام ، كنت متحمسًا للغاية. لكن فرحي ، لسوء الحظ ، لم يكن طويلاً. النموذج المدرب على هذه المجموعة هو متفائل لا يمكن اختراقه ، ومن حيث المبدأ ، لا يستطيع التعرف على التعليقات السلبية.
السبب في ذلك هو في بيانات مجموعة التدريب. عدد المراجعات الإيجابية في المجموعة تجاوز 90٪. وفقًا لذلك ، بدقة نموذجية تبلغ حوالي 88٪ ، تندرج المراجعات السلبية ببساطة في 12٪ المتوقعة من التصنيفات غير الصحيحة.
بمعنى آخر ، مع مجموعة التدريب هذه ، من المستحيل ببساطة تدريب النموذج على التعرف على التعليقات السلبية.
للتأكد من ذلك حقًا ، قمت بإجراء اختبار للوحدة يقوم بإجراء التصنيف بشكل منفصل عن 100 جملة إيجابية و 100 جملة سلبية من مجموعة بيانات أخرى - للاختبار ، أخذت
مجموعة بيانات Sent Sented Labeled Sentences من جامعة كاليفورنيا.
@loggingtestcase.capturelogs(None, level='INFO') def test_classifier_on_separate_set(self, logs): tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset ds = SentimentLabelledDataset() # Test dataset ds.load_data() # Check poisitives true_pos = 0 data = ds.data.to_numpy() seach_mask = np.isin(data[:, 1], ['pos']) data = data[seach_mask][:100] for e in data[:]: # Model train will be performed on first classification call r = tb.do_sentiment_classification(e[0]) if r == e[1]: true_pos += 1 self.assertLessEqual(true_pos, 100) print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
خوارزمية اختبار تصنيف القيم الإيجابية هي كما يلي:
- تحميل بيانات الاختبار
- خذ 100 وظيفة الموسومة "نقاط البيع"
- نحن ندير كل منهم من خلال النموذج ونحسب عدد النتائج الصحيحة
- عرض النتيجة النهائية في وحدة التحكم.
وبالمثل ، يتم إجراء عدد للتعليقات السلبية.
كما هو متوقع ، تم اعتبار جميع التعليقات السلبية إيجابية.
وإذا قمت بتدريب النموذج على مجموعة البيانات المستخدمة للاختبار -
المعنويات المسمى ؟ هناك ، توزيع التعليقات السلبية والإيجابية هو بالضبط 50 إلى 50.
تغيير الرمز والاختبار ، تشغيل شيء بالفعل. الدقة الفعلية لـ 200 إدخال من مجموعة خارجية هي 76٪ ، بينما دقة تصنيف التعليقات السلبية هي 79٪.
بالطبع ، 76 ٪ سوف تفعل لنموذج أولي ، ولكن ليس بما فيه الكفاية للإنتاج. هذا يعني أنه ستكون هناك حاجة إلى تدابير إضافية لتحسين دقة الخوارزمية. لكن هذا موضوع لتقرير آخر.
النتائج
أولاً ، حصلنا على تطبيق به أكثر من عشرة فصول و 200 سطر من التعليمات البرمجية ، وهو أكثر قليلاً من المثال الأصلي بـ 30 سطرًا. ويجب أن تكون صادقا - فهذه مجرد تلميحات في الهيكل ، أول توضيح لحدود التطبيق في المستقبل. النموذج.
وقد مكّن هذا النموذج الأولي من إدراك مدى المسافة بين النهج المتبعة في الكود من وجهة نظر المتخصصين في التعلم الآلي ومن وجهة نظر مطوري التطبيقات التقليدية. وهذا ، في رأيي ، هو الصعوبة الرئيسية للمطورين الذين يقررون تجربة تعلم الآلة.
الشيء التالي الذي يمكن أن يضع المبتدئين في ذهول - البيانات لا تقل أهمية عن النموذج المحدد. وقد تم عرض هذا بوضوح.
علاوة على ذلك ، لا يزال هناك دائمًا احتمال أن يظهر نموذج تم تدريبه على بعض البيانات نفسه بشكل غير مناسب على الآخرين ، أو في وقت ما ستبدأ دقته في الانخفاض.
وفقًا لذلك ، يتعين على المقاييس مراقبة حالة النموذج والمرونة عند العمل مع البيانات والقدرات التقنية لضبط التعلم أثناء التنقل. و هكذا.
بالنسبة لي ، كل هذا يجب أن يؤخذ في الاعتبار عند تصميم العمارة وعمليات تطوير المبنى.
بشكل عام ، لم يكن "ثقب الأرنب" عميقًا جدًا فحسب ، بل كان أيضًا ذكيًا للغاية. ولكن الأمر الأكثر إثارة للاهتمام بالنسبة لي ، كمطور ، لدراسة هذا الموضوع في المستقبل.