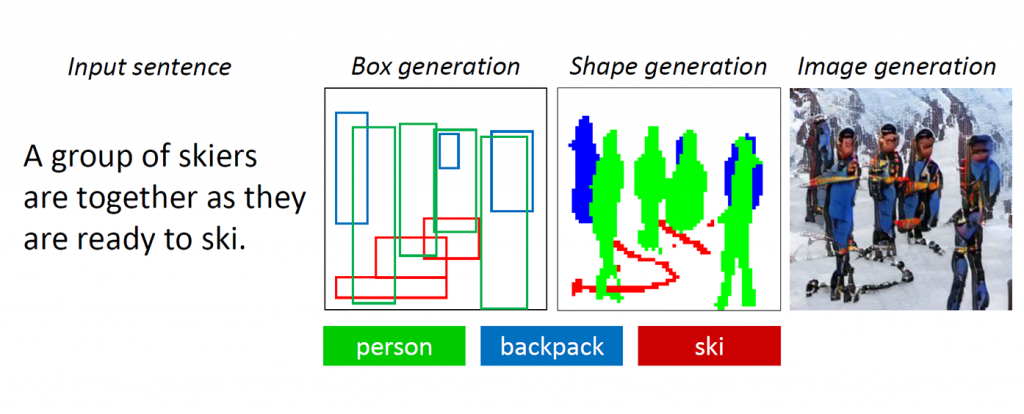
إذا طُلب منك رسم صورة لعدة أشخاص في معدات التزلج ، والوقوف في الثلج ، فمن المحتمل أن تبدأ بمخطط يتكون من ثلاثة أو أربعة أشخاص يتمركزون بشكل معقول في وسط اللوحة ، ثم رسم في الزحافات أسفل قدم. على الرغم من أنه لم يتم تحديد ذلك ، إلا أنك قد تقرر إضافة حقيبة تحمل على الظهر لكل من المتزلجين للتنبؤ بتوقعات المتزلجين الرياضية. أخيرًا ، ستملأ التفاصيل بعناية ، وربما ترسم ملابسها باللون الأزرق والأوشحة باللون الوردي ، وكل ذلك على خلفية بيضاء ، مما يجعل هؤلاء الأشخاص أكثر واقعية وتضمن تطابق محيطهم مع الوصف. أخيرًا ، لجعل المشهد أكثر حيوية ، يمكنك رسم بعض الحجارة البنية التي تبرز عبر الثلج لتوحي بأن هؤلاء المتزلجين في الجبال.
الآن هناك روبوت يمكنه فعل كل ذلك.
تقنية AI الجديدة التي يتم تطويرها في Microsoft Research AI يمكنها فهم وصف اللغة الطبيعية ، ورسم تخطيط للصورة ، وتوليف الصورة ، ثم تحسين التفاصيل بناءً على التصميم والكلمات الفردية المقدمة. بمعنى آخر ، يمكن لهذا الروبوت إنشاء صور من أوصاف نصية تشبه التسمية التوضيحية للمشاهد اليومية. أنتجت هذه الآلية المتعمدة تعزيزًا كبيرًا في جودة الصورة التي تم إنشاؤها مقارنةً بأحدث التقنيات في وقت سابق لإنشاء تحويل النص إلى صورة للمشاهد اليومية المعقدة ، وفقًا لنتائج الاختبارات المعيارية في الصناعة والمذكورة في " نص يحركه الكائن" لتوليف الصورة من خلال التدريب على الخصوم ، الذي سيتم نشره هذا الشهر في لونج بيتش ، كاليفورنيا في مؤتمر IEEE لعام 2019 حول رؤية الكمبيوتر والتعرف على الأنماط (CVPR 2019). هذا مشروع تعاون بين Pengchuan Zhang و Qiuyuan Huang و Jianfeng Gao من Microsoft Research AI و Lii Zhang من Microsoft و Xiaodong He من JD AI Research و Wenbo Li و Siwei Lyu من الجامعة في Albany و SUNY (بينما كان Wenbo Li يعمل في متدرب في شركة Microsoft Research AI).
هناك نوعان من التحديات الرئيسية في مشكلة روبوت الرسم المستندة إلى الوصف. الأول هو أنه يمكن أن تظهر أنواع كثيرة من الكائنات في المشاهد اليومية ويجب أن يكون الروبوت قادرًا على فهمها ورسمها جميعًا. تستخدم طرق إنشاء النص إلى الصورة السابقة أزواجًا من الصور التوضيحية التي توفر فقط إشارة إشراف خشنة جدًا لتوليد كائنات فردية ، مما يحد من جودة إنشاء الكائنات. في هذه التقنية الجديدة ، يستخدم الباحثون مجموعة بيانات COCO التي تحتوي على تسميات وخرائط تجزئة لـ1.5 مليون مثيل كائن عبر 80 فئة كائن مشتركة ، مما يتيح للبوت معرفة كلا من مفهوم وظهور هذه الأشياء. تعمل هذه الإشارة الخاضعة للإشراف الدقيق لتوليد الكائنات على تحسين جودة التوليد لفئات الكائنات الشائعة هذه.
يكمن التحدي الثاني في فهم وتوليد العلاقات بين كائنات متعددة في مشهد واحد. لقد تحقق نجاح كبير في إنشاء صور تحتوي فقط على كائن رئيسي واحد لعدة مجالات محددة ، مثل الوجوه والطيور والكائنات الشائعة. ومع ذلك ، لا يزال إنشاء مشاهد أكثر تعقيدًا تحتوي على كائنات متعددة ذات علاقات ذات دلالة معبرة عبر تلك الكائنات يمثل تحديًا كبيرًا في تقنية إنشاء تحويل النص إلى صورة. تعلمت روبوت الرسم الجديد هذا إنشاء تخطيط للكائنات من أنماط التواجد المشترك في مجموعة بيانات COCO لإنشاء صورة مشروطة بالتخطيط المسبق.
وجوه يحركها توليد صورة اليقظة
في قلب روبوت الرسم الخاص بـ Microsoft Research AI ، تُعرف هذه التقنية باسم شبكة الخصوم التوليدية أو GAN. تتكون GAN من نموذجين للتعلم الآلي - مولد يولد صورًا من أوصاف النص ، ومميزًا يستخدم أوصافًا نصية للحكم على صحة الصور التي تم إنشاؤها. يحاول المولد الحصول على صور مزيفة عبر أداة التمييز. المتسابق من ناحية أخرى لا يريد أن ينخدع. من خلال العمل معًا ، يدفع المُميّز المولد نحو الكمال.
تم تدريب روبوت الرسم على مجموعة من 100000 صورة ، تحتوي كل منها على ملصقات كائنات بارزة وخرائط تجزئة وخمس تسميات توضيحية مختلفة ، مما يسمح للنماذج بتصور كائنات فردية وعلاقات دلالة بين الكائنات. على سبيل المثال ، تتعلم GAN كيف ينبغي أن يبدو الكلب عند مقارنة الصور مع أو بدون أوصاف للكلاب.

الشكل 1: مشهد معقد مع كائنات متعددة وعلاقات.
تعمل شبكات GAN بشكل جيد عند إنشاء صور تحتوي على كائن بارز واحد فقط ، مثل وجه بشري أو طيور أو كلاب ، لكن الجودة راكدة بمشاهد يومية أكثر تعقيدًا ، مثل هذا المشهد الموصوف باسم "امرأة ترتدي خوذة ترتدي حصانًا" (انظر الشكل 1.) لأن هذه المشاهد تحتوي على أشياء متعددة (امرأة ، خوذة ، حصان) وعلاقات دلالة غنية بينهما (امرأة ترتدي خوذة ، امرأة ركوب الخيل). يجب على الروبوت أولاً فهم هذه المفاهيم ووضعها في الصورة بتخطيط ذي معنى. بعد ذلك ، هناك حاجة إلى إشارة أكثر إشرافًا قادرة على تدريس إنشاء الكائن وإنشاء تخطيط لإنجاز هذه المهمة لفهم اللغة وتوليد الصور.
بينما يرسم البشر هذه المشاهد المعقدة ، نقرر أولاً الكائنات الرئيسية لرسم وعمل تخطيط من خلال وضع مربعات محاطة لهذه الكائنات على قماش الرسم. ثم نركز على كل كائن ، من خلال التحقق المتكرر من الكلمات المطابقة التي تصف هذا الكائن. وللتقاط هذه الصفة الإنسانية ، ابتكر الباحثون ما أطلقوا عليه اسم GAN اليقظ الذي يحركه الكائن ، أو ObjGAN ، لنمذجة سلوك الإنسان للعناية المركزة. يقوم ObjGAN بهذا عن طريق تقسيم نص الإدخال إلى كلمات فردية ومطابقة هذه الكلمات مع كائنات محددة في الصورة.
يفحص البشر عادةً جانبين لتحسين الرسم: واقعية الكائنات الفردية وجودة تصحيحات الصور. يحاكي ObjGAN هذا السلوك أيضًا عن طريق تقديم اثنين من أدوات التمييز - أحد أدوات التمييز من حيث الحكمة ومميز من نوع من أدوات التصحيح. يحاول أداة تمييز الكائن تحديد ما إذا كان الكائن الذي تم إنشاؤه واقعيًا أم لا وما إذا كان الكائن متوافقًا مع وصف الجملة. يحاول أداة تمييز التصحيح تحديد ما إذا كان هذا التصحيح واقعيًا أم لا وما إذا كان هذا التصحيح متوافقًا مع وصف الجملة.
الأعمال ذات الصلة: تصور القصة
يمكن لطرازات الجيل الأخير من تحويل النص إلى صورة إنشاء صور واقعية للطيور بناءً على وصف جملة واحدة. ومع ذلك ، يمكن أن يؤدي إنشاء تحويل النص إلى صورة إلى أبعد من تجميع صورة واحدة بناءً على جملة واحدة. في " StoryGAN: GAN شرطي متسلسل لتصور القصة " ، جيان فنغ قاو من Microsoft Research ، إلى جانب Zhe Gan و Jingjing Liu و Yu Cheng من Microsoft Dynamics 365 AI Research و Yitong Li و David Carlson و Lawrence Carin من جامعة Duke و Yelong Shen من Tencent AI Research و Yuexin Wu من جامعة كارنيجي ميلون يخطيان خطوة أبعد ويقترحان مهمة جديدة ، تدعى Story Visualization. بالنظر إلى فقرة متعددة الجمل ، يمكن تصور قصة كاملة ، مما ينتج عنه سلسلة من الصور ، واحدة لكل جملة. هذه مهمة صعبة ، حيث أن روبوت الرسم ليس مطلوبًا فقط لتخيل سيناريو يناسب القصة ، ونمذجة التفاعلات بين الشخصيات المختلفة التي تظهر في القصة ، ولكن يجب أن تكون أيضًا قادرة على الحفاظ على الاتساق العام عبر المشاهد والشخصيات الديناميكية. لم يتم مواجهة هذا التحدي بأي من طرق إنشاء صورة أو فيديو واحد.
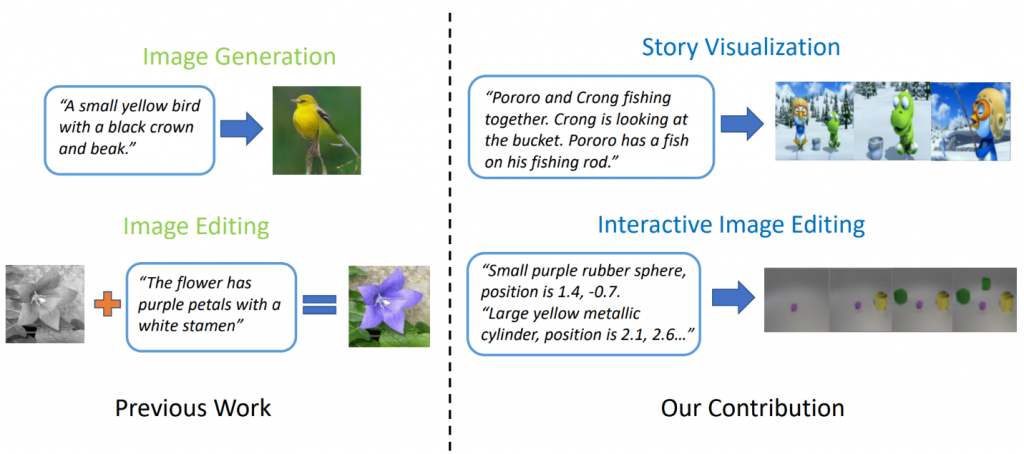
الشكل 2: تصور القصة مقابل جيل صورة بسيطة.
ابتكر الباحثون نموذجًا جديدًا لتوليد قصة إلى تسلسل ، StoryGAN ، استنادًا إلى إطار GAN الشرطي المتسلسل. هذا النموذج فريد من نوعه لأنه يتكون من سياق سياق عميق يتتبع تدفق القصة بشكل حيوي ، واثنان من أدوات التمييز على مستويات القصة والصور في تعزيز جودة الصورة واتساق التسلسل الذي تم إنشاؤه. يمكن أيضًا توسيع StoryGAN بشكل طبيعي لتحرير الصور التفاعلية ، حيث يمكن تحرير صورة إدخال بالتسلسل بناءً على التعليمات النصية. في هذه الحالة ، سيكون تسلسل تعليمات المستخدم بمثابة إدخال "القصة". وفقًا لذلك ، قام الباحثون بتعديل مجموعات البيانات الحالية لإنشاء مجموعات بيانات CLEVR-SV و Pororo-SV ، كما هو موضح في الشكل 2.
التطبيقات العملية - قصة حقيقية
يمكن أن تجد تقنية إنشاء النص إلى صورة تطبيقات عملية تعمل كمساعد رسم للرسامين والمصممين الداخليين ، أو كأداة لتحرير الصور التي يتم تنشيطها بالصوت. مع مزيد من القوة الحاسوبية ، يتخيل الباحثون التكنولوجيا التي تولد أفلام الرسوم المتحركة على أساس سيناريو ، مما يزيد من العمل الذي يقوم به صناع الأفلام المتحركة عن طريق إزالة بعض العمل اليدوي المعني.
في الوقت الحالي ، لا تزال الصور التي تم إنشاؤها بعيدة عن الصورة الواقعية. تكشف الكائنات الفردية دائمًا عن عيوب ، مثل الوجوه غير الواضحة و / أو الحافلات ذات الأشكال المشوهة. هذه العيوب هي إشارة واضحة إلى أن الكمبيوتر ، وليس الإنسان ، قام بإنشاء الصور. ومع ذلك ، فإن جودة صور ObjGAN أفضل بكثير من صور GAN السابقة الأفضل في فئتها وهي بمثابة علامة فارقة على الطريق نحو ذكاء عام يشبه الإنسان يعزز القدرات البشرية.
لكي تتقاسم الذكاء الاصطناعي والبشر نفس العالم ، يجب أن يكون لكل منهم وسيلة للتفاعل مع الآخر. اللغة والرؤية هما الطريقتان الأكثر أهمية بالنسبة للبشر والآلات للتفاعل مع بعضهم البعض. يعد إنشاء تحويل النص إلى صورة إحدى المهام المهمة التي تعمل على تطوير أبحاث الذكاء متعدد الوسائط الخاصة بالرؤية اللغوية.
يتطلع الباحثون الذين ابتكروا هذا العمل المثير إلى مشاركة هذه النتائج مع الحضور في CVPR في لونج بيتش وسماع رأيك. في غضون ذلك ، لا تتردد في التحقق من الكود المفتوح المصدر الخاص بـ ObjGAN و StoryGAN على GitHub