في المقال ، سوف أخبرك كيف تناولنا مسألة التسامح مع الخطأ في PostgreSQL ، ولماذا أصبح هذا الأمر مهمًا بالنسبة لنا ، وما حدث في النهاية.
لدينا خدمة عالية التحميل: 2.5 مليون مستخدم في جميع أنحاء العالم ، و 50 ألف مستخدم نشط كل يوم. توجد الخوادم في منطقة Amazone في منطقة واحدة من أيرلندا: يوجد أكثر من 100 خادم مختلف قيد التشغيل ، منها 50 قاعدة بيانات تقريبًا.
الواجهة الخلفية بالكامل عبارة عن تطبيق Java كبير الحجم ومتكامل يحافظ على اتصال websocket المستمر للعميل. من خلال العمل المتزامن لعدة مستخدمين على لوحة واحدة ، سيرون جميعهم التغييرات في الوقت الفعلي ، لأننا نسجل كل تغيير في قاعدة البيانات. لدينا ما يقرب من 10 آلاف استعلامات في الثانية الواحدة إلى قواعد البيانات الخاصة بنا. في ذروة الحمل في Redis ، نكتب على 80-100K استعلامات في الثانية الواحدة.

لماذا تحولنا من Redis إلى PostgreSQL
في البداية ، عملت خدمتنا مع Redis ، وهو مستودع ذو قيمة رئيسية يخزن جميع البيانات في ذاكرة الوصول العشوائي للخادم.
إيجابيات Redis:
- ارتفاع معدل الاستجابة ، كما يتم تخزين كل شيء في الذاكرة.
- راحة النسخ الاحتياطي والتكرار.
سلبيات Redis بالنسبة لنا:
- لا توجد معاملات حقيقية. حاولنا محاكاة لهم على مستوى طلبنا. لسوء الحظ ، لم ينجح هذا دائمًا بشكل جيد ويتطلب كتابة رمز معقد جدًا.
- كمية البيانات محدودة بحجم الذاكرة. كلما زادت كمية البيانات ، ستنمو الذاكرة ، وفي النهاية ، سوف نواجه خصائص المثيل المحدد ، الأمر الذي يتطلب في AWS إيقاف خدمتنا لتغيير نوع المثيل.
- من الضروري الحفاظ باستمرار على مستوى الكمون المنخفض ، كما لدينا عدد كبير جدا من الطلبات. مستوى التأخير الأمثل هو 17-20 مللي ثانية. على مستوى 30-40 مللي ثانية ، نحصل على إجابات طويلة لطلبات طلبنا وتدهور الخدمة. لسوء الحظ ، حدث هذا معنا في سبتمبر 2018 ، عندما حصلت إحدى حالات Redis لسبب ما على زمن وصول أعلى مرتين من المعتاد. لحل المشكلة ، أوقفنا الخدمة في منتصف اليوم للصيانة غير المجدولة واستبدلنا مثيل Redis الإشكالي.
- من السهل الحصول على عدم تناسق البيانات حتى مع وجود أخطاء بسيطة في التعليمات البرمجية ثم قضاء وقت طويل في كتابة التعليمات البرمجية لإصلاح هذه البيانات.
أخذنا في الاعتبار العيوب وأدركنا أننا بحاجة إلى الانتقال إلى شيء أكثر ملاءمة ، مع المعاملات العادية والاعتماد أقل على الكمون. أجرى دراسة ، حلل العديد من الخيارات واختار PostgreSQL.
لقد تم الانتقال إلى قاعدة بيانات جديدة لمدة 1.5 عام ، وقمنا بنقل جزء صغير فقط من البيانات ، لذلك نحن نعمل الآن بشكل متزامن مع Redis و PostgreSQL. تمت كتابة المزيد من المعلومات حول مراحل نقل البيانات وتبديلها بين قواعد البيانات في
مقالة كتبها زميلي .
عندما بدأنا للتو في التحرك ، عمل تطبيقنا مباشرة مع قاعدة البيانات وانتقل إلى معالج Redis و PostgreSQL. تتكون كتلة PostgreSQL من نسخة متماثلة رئيسية وغير متزامنة. هكذا بدا مخطط تشغيل قاعدة البيانات:
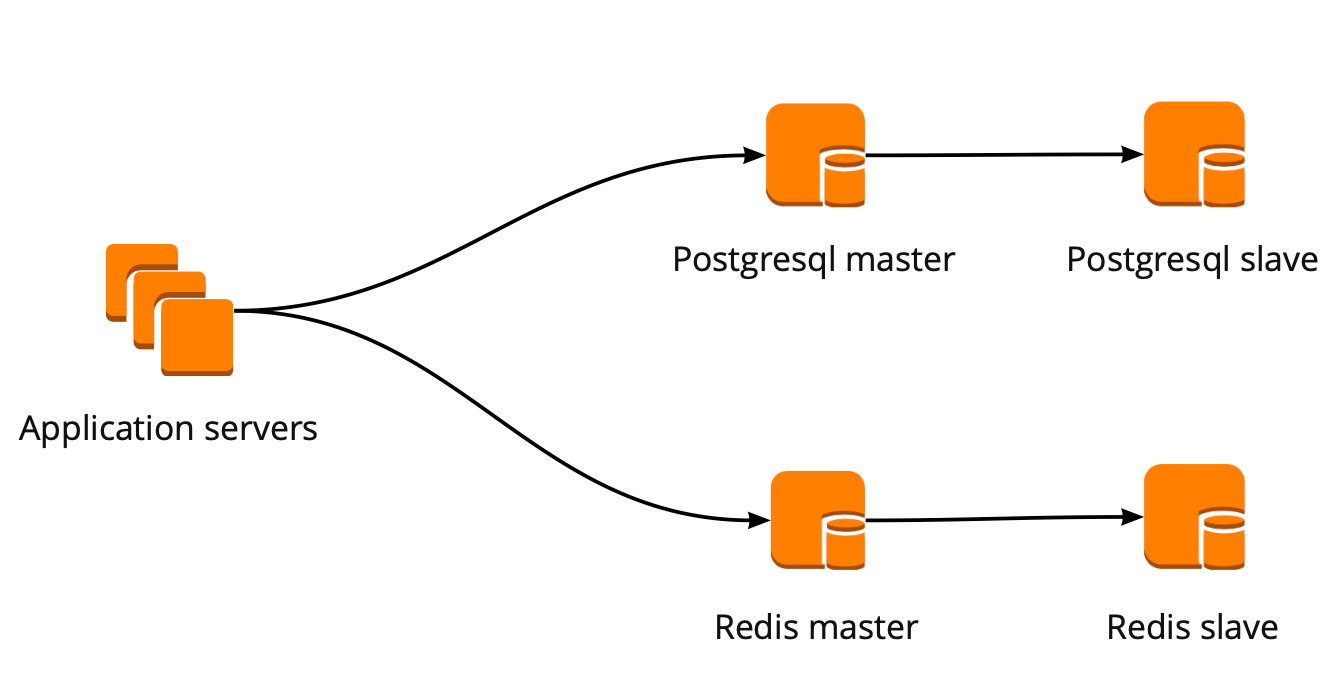
PgBouncer النشر
أثناء تنقلنا ، تم تطوير المنتج أيضًا: زاد عدد المستخدمين وعدد الخوادم التي عملت مع PostgreSQL ، وبدأنا نفتقد الاتصالات. ينشئ PostgreSQL عملية منفصلة لكل اتصال ويستهلك الموارد. يمكنك زيادة عدد الاتصالات حتى نقطة معينة ، وإلا فهناك فرصة للحصول على تشغيل قاعدة البيانات غير الأمثل. الخيار المثالي في هذه الحالة هو اختيار مدير الاتصال الذي سيقف أمام القاعدة.
كان لدينا خياران لمدير الاتصال: Pgpool و PgBouncer. لكن الأول لا يدعم وضع المعاملات للعمل مع قاعدة البيانات ، لذلك اخترنا PgBouncer.
لقد قمنا بإعداد نظام العمل التالي: يصل تطبيقنا إلى PgBouncer واحد ، متبوعًا بـ Masters PostgreSQL ، وخلف كل رئيسي ، نسخة متماثلة واحدة غير متزامنة.

في الوقت نفسه ، لم نتمكن من تخزين كامل كمية البيانات في PostgreSQL ، وكانت سرعة العمل مع قاعدة البيانات مهمة بالنسبة لنا ، لذلك بدأنا في مشاركة PostgreSQL على مستوى التطبيق. يعتبر المخطط الموضح أعلاه مناسبًا نسبيًا لذلك: عند إضافة قسم PostgreSQL جديد ، يكفي تحديث تكوين PgBouncer ويمكن للتطبيق العمل على الفور مع الأداة الجديدة.
PgBouncer خطأ التسامح
يعمل هذا المخطط حتى توفي مثيل PgBouncer الوحيد. نحن موجودون في AWS ، حيث يتم تشغيل جميع الحالات على الأجهزة التي تموت بشكل دوري. في مثل هذه الحالات ، ينتقل المثيل ببساطة إلى الأجهزة الجديدة ويعمل مرة أخرى. حدث هذا مع PgBouncer ، لكنه أصبح غير متوفر. كانت نتيجة هذا الخريف عدم إمكانية الوصول إلى خدماتنا لمدة 25 دقيقة. توصي AWS باستخدام التكرار من جانب المستخدم لمثل هذه الحالات ، والتي لم يتم تنفيذها معنا في ذلك الوقت.
بعد ذلك ، فكرنا جديا في التسامح مع الخطأ في مجموعات PgBouncer و PostgreSQL ، لأنه قد يحدث موقف مماثل مرة أخرى مع أي مثيل في حساب AWS الخاص بنا.
لقد صممنا نظام التسامح مع الخطأ PgBouncer على النحو التالي: جميع خوادم التطبيقات تصل إلى Network Load Balancer ، والتي يوجد خلفها PgBouncer. ينظر كل من PgBouncer إلى نفس PostgreSQL الرئيسي لكل قشرة. في حالة تعطل مثيل AWS مرة أخرى ، تتم إعادة توجيه كل حركة المرور من خلال PgBouncer آخر. توفر موازنة حمل الشبكة للتسامح مع الأخطاء AWS.
يسمح لك هذا المخطط بإضافة خوادم PgBouncer الجديدة بسهولة.

إنشاء مجموعة تجاوز الفشل PostgreSQL
في حل هذه المشكلة ، درسنا خيارات مختلفة: فشل مكتوب ذاتيًا ، repmgr ، AWS RDS ، Patroni.
مخطوطات مكتوبة ذاتيا
يمكنهم مراقبة عمل السيد ، وفي حالة سقوطه ، الترويج للنسخة المتماثلة إلى الرئيسي وتحديث تكوين PgBouncer.
مزايا هذا النهج هي البساطة القصوى ، لأنك أنت نفسك تكتب النصوص وتفهم بالضبط كيف تعمل.
سلبيات:
- قد لا يموت السيد ؛ وبدلاً من ذلك ، قد يحدث فشل في الشبكة. سيقوم تجاوز الفشل ، دون معرفة ذلك ، بترقية النسخة المتماثلة إلى الرئيسية ، وسيستمر العمل في الإصدار القديم. نتيجةً لذلك ، لدينا خادمين في دور master ولا نعرف أي منهما لديه أحدث البيانات الفعلية. هذا الموقف يسمى أيضا انقسام الدماغ.
- لقد تركنا دون نسخة طبق الأصل. في التكوين الخاص بنا ، الرئيسية والنسخة المتماثلة ، بعد تبديل النسخة المتماثلة ، ينتقل إلى الرئيسية ولم يعد لدينا نسخ متماثلة ، لذلك يتعين علينا إضافة نسخة متماثلة جديدة يدويًا ؛
- نحتاج إلى مراقبة إضافية لعملية تجاوز الفشل ، بينما لدينا 12 مشاركة من PostgreSQL ، مما يعني أنه يجب علينا مراقبة 12 مجموعة. إذا قمت بزيادة عدد القطع ، فلا يزال عليك تذكر تحديث الفشل.
يبدو الفشل المكتوب ذاتيًا معقدًا جدًا ويتطلب دعمًا غير تافه. مع مجموعة PostgreSQL واحدة ، سيكون هذا هو الخيار الأسهل ، لكنه لا يتغير ، لذلك فهو غير مناسب لنا.
Repmgr
مدير النسخ المتماثل لمجموعات PostgreSQL ، والتي يمكنها إدارة تشغيل مجموعة PostgreSQL. في الوقت نفسه ، لا يوجد أي عطل تلقائي "خارج الصندوق" ، لذلك للعمل ستحتاج إلى كتابة "غلافك" أعلى الحل النهائي. لذلك يمكن أن يصبح كل شيء أكثر تعقيدًا من البرامج النصية المكتوبة ذاتيًا ، لذلك لم نجرب Repmgr.
AWS RDS
وهو يدعم كل ما تحتاجه لنا ، ويعرف كيفية عمل نسخة احتياطية ويدعم تجمع اتصال. يحتوي على التبديل التلقائي: عند وفاة الرئيسي ، تصبح النسخة المتماثلة الرئيسية الجديدة ، وتغير AWS سجل نظام أسماء النطاقات إلى الرئيسي الجديد ، في حين أن النسخ المتماثلة يمكن أن تكون في AZ مختلفة.
وتشمل عيوب عدم وجود إعدادات خفية. كمثال على الضبط: في حالاتنا ، توجد قيود على اتصالات tcp ، والتي ، للأسف ، لا يمكن القيام بها في RDS:
net.ipv4.tcp_keepalive_time=10 net.ipv4.tcp_keepalive_intvl=1 net.ipv4.tcp_keepalive_probes=5 net.ipv4.tcp_retries2=3
بالإضافة إلى ذلك ، يكون سعر AWS RDS أعلى مرتين تقريبًا من سعر المثيل العادي ، والذي كان السبب الرئيسي لرفض هذا القرار.
Patroni
هذا هو قالب بيثون لإدارة PostgreSQL مع وثائق جيدة ، الفشل التلقائي ورمز github المصدر.
إيجابيات Patroni:
- كل معلمة التكوين رسمت ، فمن الواضح كيف يعمل.
- يعمل الفشل التلقائي من خارج منطقة الجزاء ؛
- هو مكتوب في بيثون ، وبما أننا نكتب الكثير في بيثون بأنفسنا ، سيكون من الأسهل بالنسبة لنا التعامل مع المشاكل ، وربما حتى المساعدة في تطوير المشروع ؛
- إنه يتحكم بشكل كامل في PostgreSQL ، ويسمح لك بتغيير التكوين على جميع عقد المجموعة في وقت واحد ، وإذا كانت إعادة تشغيل الكتلة مطلوبة لتطبيق التكوين الجديد ، فيمكن القيام بذلك مرة أخرى باستخدام Patroni.
سلبيات:
- من الوثائق ، ليس من الواضح كيفية العمل مع PgBouncer. على الرغم من أنه من الصعب أن نسميها ناقص ، لأن مهمة Patroni هي إدارة PostgreSQL ، وكيف ستكون الاتصالات بـ Patroni هي مشكلتنا ؛
- هناك أمثلة قليلة على تطبيق Patroni على أحجام كبيرة ، في حين أن العديد من أمثلة التنفيذ من الصفر.
نتيجة لذلك ، لإنشاء مجموعة تجاوز الفشل ، اخترنا Patroni.
عملية تنفيذ المستفيد
قبل Patroni ، كان لدينا 12 مشاركة من PostgreSQL في التهيئة ، وسيد واحد ونسخة متماثلة متماثلة غير متزامنة. وصلت خوادم التطبيقات إلى قواعد البيانات من خلال Network Load Balancer ، والتي كانت وراءها حالتان مع PgBouncer ، وخلفهما كانت جميع خوادم PostgreSQL.
لتنفيذ Patroni ، نحتاج إلى تحديد مستودع تكوين نظام المجموعة الموزع. يعمل Patroni مع أنظمة تخزين التكوين الموزعة مثل etcd و Zookeeper و القنصل. لدينا فقط مجموعة قنصليات كاملة على المنتجات التي تعمل مع Vault ولم نعد نستخدمها بعد الآن. سبب كبير لبدء استخدام القنصل لغرضه المقصود.
كيف يعمل Patroni مع القنصل
لدينا مجموعة قنصل ، تتكون من ثلاث عقد ، ومجموعة Patroni ، والتي تتكون من قائد ونسخة متماثلة (في Patroni ، يُطلق على الرئيسي اسم زعيم الكتلة ، ويسمى العبيد النسخ المتماثلة). كل مثيل من كتلة Patroni يرسل باستمرار معلومات حالة الكتلة إلى القنصل. لذلك ، من القنصل يمكنك دائمًا معرفة التكوين الحالي لمجموعة Patroni ومن هو القائد في الوقت الحالي.

لتوصيل Patroni بالقنصل ، يكفي دراسة الوثائق الرسمية ، التي تنص على أنك تحتاج إلى تحديد المضيف بتنسيق http أو https ، اعتمادًا على كيفية تعاملنا مع القنصل ، ومخطط الاتصال ، اختياريًا:
host: the host:port for the Consul endpoint, in format: http(s)://host:port scheme: (optional) http or https, defaults to http
تبدو بسيطة ، ولكن هنا تبدأ المزالق. مع القنصل ، نعمل على اتصال آمن عبر https وسيظهر تكوين الاتصال لدينا كما يلي:
consul: host: https://server.production.consul:8080 verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
لكن هذا لا يعمل. في البداية ، لا يمكن لـ Patroni الاتصال بالقنصل ، لأنه يحاول متابعة http على أي حال.
ساعد كود المصدر لـ Patroni في التعامل مع المشكلة. شيء جيد هو مكتوب في الثعبان. اتضح أن المعلمة المضيف لا يتم تحليلها على الإطلاق ، ويجب تحديد البروتوكول في المخطط. هنا كتلة تكوين العمل للعمل مع القنصل معنا:
consul: host: server.production.consul:8080 scheme: https verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
القنصل قالب
لذلك ، اخترنا التخزين للحصول على التكوين. أنت الآن بحاجة إلى فهم كيفية تبديل PgBouncer لتكوينه عند تغيير الرائد في مجموعة Patroni. الوثائق لا تجيب على هذا السؤال ، لأن هناك ، من حيث المبدأ ، لم يتم وصف العمل مع PgBouncer.
بحثًا عن حل ، وجدنا مقالًا (لا أتذكر الاسم ، لسوء الحظ) ، حيث كتب أن قالب القنصل ساعد كثيرًا في توصيل PgBouncer و Patroni. هذا دفعنا إلى دراسة عمل القنصل.
اتضح أن قالب القنصل يراقب باستمرار تكوين مجموعة PostgreSQL في القنصل. عندما يتغير الزعيم ، يقوم بتحديث تكوين PgBouncer ويرسل أمرًا لإعادة تشغيله.
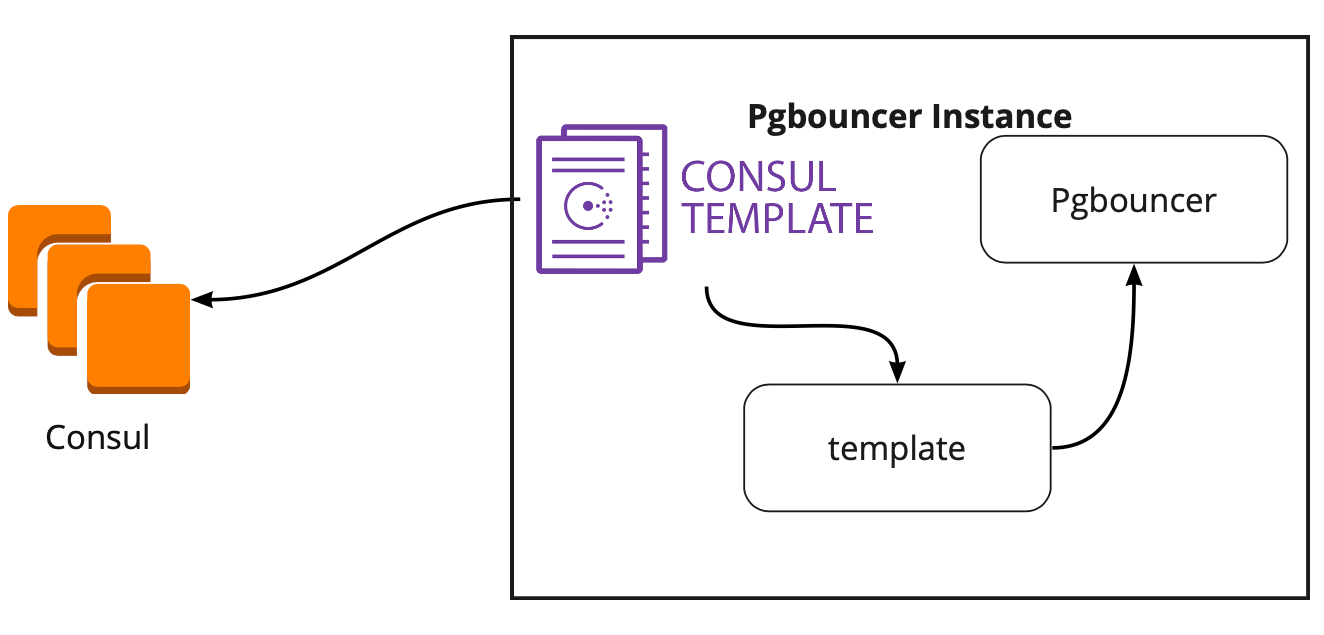
الإضافة الكبيرة للقالب هي أنه يتم تخزينه ككود ، لذلك عند إضافة شارد جديد ، يكفي إنشاء التزام جديد وتحديث القالب في الوضع التلقائي ، ودعم مبدأ البنية التحتية كرمز.
العمارة الجديدة مع Patroni
نتيجة لذلك ، حصلنا على مخطط العمل هذا:

تتحول جميع خوادم التطبيقات إلى الموازن - يوجد مثيلان PgBouncer وراءهما → في كل حالة يتم إطلاق قالب onsul ، الذي يراقب حالة كل مجموعة من مجموعات Patroni ويرصد أهمية تكوين PgBouncer ، الذي يرسل الطلبات إلى البادئة الحالية لكل مجموعة.
الاختبار اليدوي
قبل إطلاق البرنامج ، أطلقنا هذه الدائرة في بيئة اختبار صغيرة وتحققنا من تشغيل التبديل التلقائي. فتحوا اللوحة ، ونقلوا الملصق وفي تلك اللحظة "قتلوا" زعيم الكتلة. في AWS ، فقط أوقف تشغيل المثيل من خلال وحدة التحكم.

عاد الملصق مرة أخرى في غضون 10-20 ثانية ، ثم بدأ التحرك مرة أخرى بشكل طبيعي. هذا يعني أن مجموعة Patroni عملت بشكل صحيح: لقد غيرت القائد ، وأرسلت المعلومات إلى القنصل ، وقبَل القنصل فورًا هذه المعلومات ، واستبدل تكوين PgBouncer وأرسل الأمر لإعادة التحميل.
كيفية البقاء على قيد الحياة تحت عبء كبير والحفاظ على الحد الأدنى من التوقف؟
كل شيء يعمل بشكل رائع! لكن أسئلة جديدة تثار: كيف ستعمل تحت عبء كبير؟ كيف بسرعة وبأمان لفة كل شيء في الإنتاج؟
تساعدنا بيئة الاختبار التي نجري فيها اختبار الحمل في الإجابة على السؤال الأول. إنه مطابق تمامًا للإنتاج في الهندسة المعمارية وقد أنتج بيانات اختبار ، والتي تتساوى تقريبًا في الحجم مع الإنتاج. قررنا "قتل" أحد معالجات PostgreSQL أثناء الاختبار ومعرفة ما يحدث. ولكن قبل ذلك ، من المهم التحقق من التدحرج التلقائي ، لأنه في هذه البيئة لدينا العديد من أسهم PostgreSQL ، لذلك سوف نحصل على اختبار ممتاز لنصوص التكوين قبل البيع.
كلتا المهمتين تبدو طموحة ، لكن لدينا PostgreSQL 9.6. ربما سنقوم على الفور للترقية إلى 11.2؟
قررنا القيام بذلك على مرحلتين: الترقية الأولى إلى 11.2 ، ثم إطلاق Patroni.
تحديث بوستجرس
لترقية إصدار PostgreSQL بسرعة ، يجب عليك استخدام الخيار
-k ، الذي ينشئ رابطًا ثابتًا على القرص ولا توجد حاجة لنسخ بياناتك. على أساس 300-400 جيجابايت ، يستغرق التحديث ثانية واحدة.
لدينا الكثير من القطع ، لذلك يجب إجراء التحديث تلقائيًا. للقيام بذلك ، كتبنا Ansible playbook ، الذي ينفذ عملية التحديث بالكامل بالنسبة لنا:
/usr/lib/postgresql/11/bin/pg_upgrade \ <b>--link \</b> --old-datadir='' --new-datadir='' \ --old-bindir='' --new-bindir='' \ --old-options=' -c config_file=' \ --new-options=' -c config_file='
من المهم أن نلاحظ هنا أنه قبل بدء الترقية ، من الضروري تنفيذها مع المعلمة -
check للتأكد من إمكانية الترقية. نصنا أيضا يجعل استبدال التكوينات للترقية. النص الذي أكملناه في 30 ثانية ، هذه نتيجة ممتازة.
إطلاق Patroni
لحل المشكلة الثانية ، مجرد إلقاء نظرة على تكوين Patroni. في المستودع الرسمي ، يوجد تكوين مثال مع initdb ، وهو المسؤول عن تهيئة قاعدة بيانات جديدة عند إطلاق Patroni لأول مرة. ولكن نظرًا لوجود قاعدة بيانات جاهزة ، فقد قمنا بحذف هذا القسم من التكوين.
عندما بدأنا تثبيت Patroni على مجموعة PostgreSQL الجاهزة وتشغيلها ، واجهنا مشكلة جديدة: بدأ كلا الخادمين كقائد. لا يعرف Patroni أي شيء عن الحالة المبكرة للكتلة ويحاول بدء تشغيل كلا الخادوم كمجموعتين منفصلتين بنفس الاسم. لحل هذه المشكلة ، احذف دليل البيانات على العبد:
rm -rf /var/lib/postgresql/
يجب أن يتم ذلك فقط على الرقيق!عند توصيل نسخة متماثلة نظيفة ، يقوم Patroni بتصنيع زعيم basebackup واستعادته إلى النسخة المتماثلة ، ثم اللحاق بالحالة الحالية عن طريق سجلات الدخول.
صعوبة أخرى واجهناها هي أن جميع مجموعات PostgreSQL تسمى الرئيسية افتراضيًا. عندما لا تعرف كل مجموعة أي شيء عن الآخر ، فهذا أمر طبيعي. ولكن عندما تريد استخدام Patroni ، يجب أن يكون لجميع المجموعات اسم فريد. الحل هو تغيير اسم الكتلة في تكوين PostgreSQL.
اختبار الحمل
أطلقنا اختبارًا يحاكي عمل المستخدمين على اللوحات. عندما وصل الحمل إلى متوسط قيمنا اليومية ، كررنا نفس الاختبار بالضبط ، فقمنا بإيقاف تشغيل مثيل واحد مع زعيم PostgreSQL. لقد عمل تجاوز الفشل التلقائي كما توقعنا: قام Patroni بتغيير القائد ، وقام القنصل بتحديث تكوين PgBouncer وأرسل الأمر لإعادة التحميل. وفقًا للرسوم البيانية الخاصة بنا في Grafana ، كان من الواضح أن هناك تأخيرًا يتراوح من 20 إلى 30 ثانية وكمية صغيرة من الأخطاء من الخوادم المتعلقة بالاتصال بقاعدة البيانات. هذا هو الوضع الطبيعي ، مثل هذه القيم صالحة لعطلنا ، وبالتأكيد أفضل من توقف الخدمة.
إنتاج Patroni إلى الإنتاج
نتيجة لذلك ، حصلنا على الخطة التالية:
- نشر قالب القنصل على خادم PgBouncer وإطلاقه ؛
- تحديثات PostgreSQL إلى الإصدار 11.2 ؛
- تغيير اسم الكتلة
- بدء كتلة Patroni.
في الوقت نفسه ، يسمح لك مخططنا بإجراء العنصر الأول في أي وقت تقريبًا ، ويمكننا أن نتناوب على إزالة كل PgBouncer من العمل وتنفيذ عملية نشر عليه وإطلاق قالب القنصل. هكذا فعلنا.
للتداول السريع ، استخدمنا Ansible ، نظرًا لأننا فحصنا بالفعل جميع قواعد اللعبة في بيئة اختبار ، وكان وقت تنفيذ النص الكامل من 1.5 إلى دقيقتين لكل قشرة. يمكننا طرح كل شيء بالتناوب لكل قشرة دون إيقاف خدمتنا ، ولكن سيتعين علينا إيقاف تشغيل كل PostgreSQL لبضع دقائق. في هذه الحالة ، لن يتمكن المستخدمون الذين توجد بياناتهم على هذه القطعة من العمل بشكل كامل في هذا الوقت ، وهذا غير مقبول لنا.
كان مخرج هذه الحالة هو الصيانة المخطط لها ، والتي تتم كل 3 أشهر. هذه نافذة للعمل المجدول عندما نقوم بإيقاف تشغيل خدماتنا وتحديث مثيلات قاعدة البيانات تمامًا. بقي أسبوع واحد حتى النافذة التالية ، وقررنا الانتظار والاستعداد. خلال فترة الانتظار ، تأكدنا أيضًا من: بالنسبة لكل قشرة PostgreSQL ، قمنا بإصدار نسخة متماثلة احتياطية في حالة الفشل من أجل حفظ أحدث البيانات ، وأضفنا مثيلًا جديدًا لكل قشرة ، والتي يجب أن تصبح نسخة طبق الأصل جديدة في مجموعة Patroni حتى لا يتم تنفيذ أمر لحذف البيانات . كل هذا ساعد في تقليل خطر الخطأ.

لقد استأنفنا خدمتنا ، كل شيء يعمل كما ينبغي ، واصل المستخدمون العمل ، ولكن على الرسوم البيانية لاحظنا وجود حمولة عالية بشكل غير طبيعي على خادم القنصل.
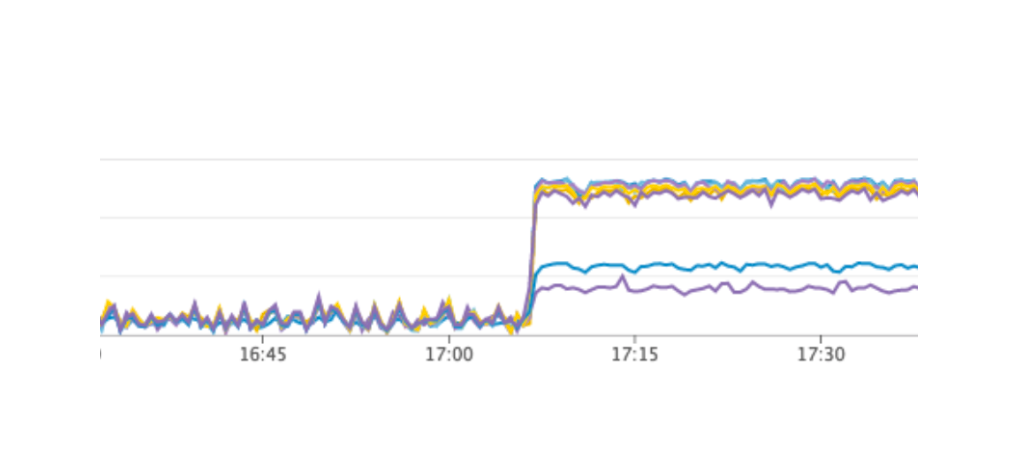
لماذا لم نراها في بيئة الاختبار؟ توضح هذه المشكلة جيدًا أنه من الضروري اتباع مبدأ البنية التحتية كرمز وتحسين البنية التحتية بالكامل ، بدءًا من بيئات الاختبار وانتهاء بالإنتاج. خلاف ذلك ، من السهل جدًا الحصول على نوع المشكلة التي واجهناها. ماذا حدث ظهر القنصل أولاً في الإنتاج ، ثم في بيئات الاختبار ، ونتيجة لذلك ، في بيئات الاختبار ، كان إصدار القنصل أعلى من الإنتاج. فقط في أحد الإصدارات ، تم حل تسرب وحدة المعالجة المركزية عند العمل باستخدام قالب القنصل. لذلك ، قمنا فقط بتحديث القنصل ، وبالتالي حل المشكلة.
إعادة تشغيل الكتلة Patroni
ومع ذلك ، واجهنا مشكلة جديدة لم نكن على دراية بها. عند تحديث القنصل ، نقوم ببساطة بإزالة عقدة القنصل من المجموعة باستخدام أمر مغادرة القنصل → يتصل Patroni بخادم قنصل آخر → يعمل كل شيء. ولكن عندما وصلنا إلى المثيل الأخير من مجموعة القنصل وأرسلنا أمر مغادرة القنصل إليه ، تم إعادة تشغيل كل مجموعات Patroni ببساطة ، وفي السجلات شاهدنا الخطأ التالي:
ERROR: get_cluster Traceback (most recent call last): ... RetryFailedError: 'Exceeded retry deadline' ERROR: Error communicating with DCS <b>LOG: database system is shut down</b>
لم تتمكن مجموعة Patroni من الحصول على معلومات حول نظامها وإعادة تشغيله.
لإيجاد حل ، اتصلنا بمؤلفي Patroni من خلال إصدار على github. اقترحوا تحسينات على ملفات التكوين الخاصة بنا:
consul: consul.checks: [] bootstrap: dcs: retry_timeout: 8
تمكنا من تكرار المشكلة في بيئة اختبار واختبار هذه المعلمات هناك ، لكن لسوء الحظ ، لم تنجح.
المشكلة لا تزال دون حل. نخطط لتجربة الحلول التالية:
- استخدام القنصل وكيل في كل مثيل من الكتلة Patroni.
- حل المشكلة في الكود.
نحن نتفهم المكان الذي حدث فيه الخطأ: ربما تكون المشكلة هي استخدام المهلة الافتراضية ، والتي لا يتم تجاوزها من خلال ملف التكوين. عند إزالة خادم القنصل الأخير من الكتلة ، تتجمد مجموعة القنصل بأكملها لأكثر من ثانية ، وبسبب هذا Patroni لا يمكن الحصول على حالة الكتلة وإعادة تشغيل المجموعة بالكامل بالكامل.
لحسن الحظ ، لم نواجه أي أخطاء أخرى.
نتائج استخدام Patroni
بعد الإطلاق الناجح لـ Patroni ، أضفنا نسخة متماثلة إضافية في كل مجموعة. يوجد الآن في كل مجموعة تشابه من النصاب القانوني: قائد واحد واثنين من النسخ المتماثلة - للتأمين ضد حالة انقسام الدماغ عند التبديل.
تعمل شركة Patroni في الإنتاج منذ أكثر من ثلاثة أشهر. خلال هذا الوقت ، تمكن بالفعل من مساعدتنا. في الآونة الأخيرة ، توفي زعيم واحدة من المجموعات في AWS ، عملت الفشل التلقائي ، واستمر المستخدمون في العمل. أكمل Patroni مهمته الرئيسية.
ملخص صغير لاستخدام Patroni:- سهولة تغيير التكوين. يكفي تغيير التكوين في مثيل واحد وسيتم سحبه على المجموعة بالكامل. إذا كانت إعادة التشغيل مطلوبة لتطبيق التكوين الجديد ، فسيقوم Patroni بالإبلاغ عن هذا. يمكن لـ Patroni إعادة تشغيل المجموعة بالكامل باستخدام أمر واحد ، وهو أيضًا مريح للغاية.
- يعمل الفشل التلقائي وقد نجح بالفعل في مساعدتنا.
- تحديث PostgreSQL دون توقف التطبيق. يجب أولاً ترقية النسخ المتماثلة إلى الإصدار الجديد ، ثم تغيير الرائد في نظام مجموعة Patroni وتحديث الإصدار القديم. في هذه الحالة ، يحدث الاختبار الضروري للتجاوز التلقائي.