يعرف مستخدمو ClickHouse أن ميزته الرئيسية هي سرعة معالجة الاستعلامات التحليلية. ولكن كيف يمكننا أن نجعل مثل هذه التصريحات؟ يجب أن يكون هذا معتمدًا من خلال اختبارات الأداء الموثوقة. سنتحدث عنهم اليوم.
بدأنا إجراء مثل هذه الاختبارات في عام 2013 ، قبل وقت طويل من توفر المنتج في المصادر المفتوحة. كما هو الحال الآن ، فقد كنا مهتمين جدًا بسرعة خدمة بيانات Yandex.Metrica. لقد قمنا بالفعل بتخزين البيانات في ClickHouse منذ يناير 2009. تمت كتابة جزء من البيانات إلى قاعدة البيانات منذ عام 2012 ، وجزء - تم
تحويله من
OLAPServer و Metrage - هياكل البيانات التي تم استخدامها في Yandex.Metrica من قبل. لذلك ، بالنسبة للاختبارات ، أخذنا أول مجموعة فرعية متاحة من 1 مليار صفحة من مشاهدات الصفحة. لم تكن هناك استفسارات في Metric حتى الآن ، وتوصلنا إلى استفسارات هي الأكثر إثارة للاهتمام بالنسبة لنا بأنفسنا (جميع أنواع التصفية والتجميع والفرز).
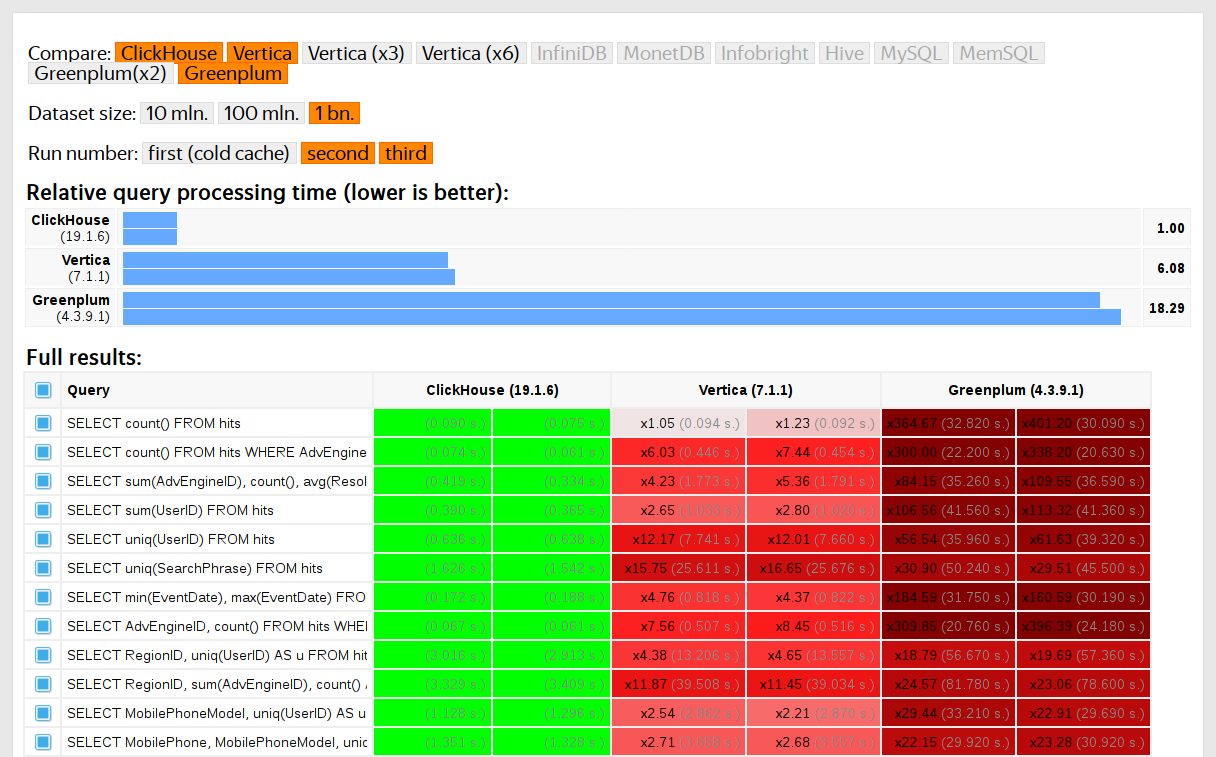
تم اختبار ClickHouse بالمقارنة مع أنظمة مماثلة ، على سبيل المثال ، Vertica و MonetDB. لكي نكون صادقين ، تم إجراؤه بواسطة موظف لم يكن من قبل مطور ClickHouse ، ولم يتم تحسين حالات معينة في التعليمات البرمجية حتى يتم الحصول على النتائج. وبالمثل ، حصلنا على مجموعة بيانات للاختبارات الوظيفية.
بعد انضمام ClickHouse إلى المصدر المفتوح في عام 2016 ، كان هناك المزيد من الأسئلة للاختبارات.
مساوئ الاختبارات على بيانات الملكية
اختبارات الأداء:
- لا يمكن استنساخها من الخارج ، لأن إطلاقها يتطلب بيانات مغلقة لا يمكن نشرها. للسبب نفسه ، لا تتوفر بعض الاختبارات الوظيفية للمستخدمين الخارجيين.
- لا تتطور. هناك حاجة لتوسعة كبيرة في مجموعتهم ، بحيث يمكن التحقق بطريقة معزولة من التغيرات في سرعة الأجزاء الفردية للنظام.
- لا يعملون على نحو ملائم لطلبات التجميع ، ولا يمكن للمطورين الخارجيين التحقق من الشفرة الخاصة بهم من أجل تراجع الأداء.
يمكنك حل هذه المشكلات - التخلص من الاختبارات القديمة وإجراء اختبارات جديدة بناءً على البيانات المفتوحة. من بين البيانات المفتوحة ، يمكنك أخذ
بيانات عن الرحلات الجوية إلى الولايات المتحدة الأمريكية أو
ركوب سيارات الأجرة في نيويورك أو استخدام معايير جاهزة TPC-H أو TPC-DS أو
Star Schema Benchmark . الإزعاج هو أن هذه البيانات بعيدة عن بيانات Yandex.Metrica ، وأود حفظ طلبات الاختبار.
من المهم استخدام البيانات الحقيقية.
تحتاج إلى اختبار أداء الخدمة فقط على البيانات الحقيقية من الإنتاج. دعونا نلقي نظرة على بعض الأمثلة.
مثال 1افترض أنك ملء قاعدة بيانات بأرقام عشوائية مزورة موزعة بالتساوي. في هذه الحالة ، لن يعمل ضغط البيانات. لكن ضغط البيانات يعد خاصية مهمة لنظام إدارة قواعد البيانات التحليلية. يعد اختيار خوارزمية الضغط الصحيحة والطريقة الصحيحة لدمجها في النظام مهمة غير تافهة لا يوجد فيها حل واحد صحيح ، لأن ضغط البيانات يتطلب حلاً وسطًا بين سرعة الضغط وضغط الضغط ونسبة الضغط المحتملة. الأنظمة التي لا تعرف كيفية ضغط البيانات تفقد مضمونة. ولكن إذا استخدمنا الأرقام العشوائية الكاذبة الموزعة بشكل موحد للاختبارات ، فلن يتم أخذ هذا العامل في الاعتبار ، وسيتم تشويه جميع النتائج الأخرى.
الخلاصة: يجب أن تحتوي بيانات الاختبار على نسبة ضغط واقعية.
حول تحسين خوارزميات ضغط البيانات في ClickHouse التي تحدثت عنها في منشور
سابق .
مثال 2دعنا نهتم بسرعة استعلام SQL:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
هذا هو طلب نموذجي ل Yandex.Metrica. ما هو المهم لسرعته؟
- كيف يتم تنفيذ GROUP BY ؟
- ما هي بنية البيانات التي يتم استخدامها لحساب الوظيفة الإجمالية uniq.
- كم من معرف المناطق المختلفة ومقدار ذاكرة الوصول العشوائي التي تتطلبها كل حالة من وظائف uniq.
ولكن من المهم أيضًا أن يتم توزيع كمية البيانات للمناطق المختلفة بشكل غير متساو. (ربما ، يتم توزيعها وفقًا لقانون الطاقة. لقد قمت بإنشاء رسم بياني في مقياس سجل السجل ، لكنني لست متأكدًا.) وإذا كان الأمر كذلك ، فمن المهم بالنسبة لنا أن حالات الدالة التجميعية uniq مع عدد صغير من القيم تستخدم القليل من الذاكرة. عندما يكون هناك العديد من مفاتيح التجميع المختلفة ، ينتقل العدد إلى وحدات البايت. كيفية الحصول على البيانات التي تم إنشاؤها التي تحتوي على كل هذه الخصائص؟ بالطبع ، من الأفضل استخدام البيانات الحقيقية.
تقوم العديد من نظم إدارة قواعد البيانات بتطبيق بنية بيانات HyperLogLog لحساب تقريبي لـ COUNT (DISTINCT) ، ولكنها تعمل جميعها بشكل سيئ نسبياً لأن بنية البيانات هذه تستخدم مقدارًا ثابتًا من الذاكرة. ويحتوي ClickHouse على وظيفة تستخدم
مجموعة من ثلاثة هياكل بيانات مختلفة ، اعتمادًا على حجم المجموعة.
الخلاصة: يجب أن تمثل بيانات الاختبار خصائص توزيع القيم في البيانات الأساسية (عدد القيم في الأعمدة) والأصالة المتبادلة بين عدة أعمدة مختلفة.
مثال 3حسنًا ، دعونا نختبر أداء نظام تحليل قواعد البيانات ClickHouse التحليلي ، ولكن لشيء أكثر بساطة ، على سبيل المثال ، جداول التجزئة. بالنسبة لجداول التجزئة ، يعد اختيار دالة التجزئة الصحيحة أمرًا مهمًا للغاية. بالنسبة إلى std :: unordered_map ، فإنه أقل أهمية قليلاً ، لأنه جدول تجزئة قائم على سلسلة ، ويتم استخدام رقم أولي بحجم الصفيف. في تطبيق المكتبة القياسي في gcc و clang ، يتم استخدام دالة هاش تافهة كدالة تجزئة افتراضية لأنواع رقمية. لكن std :: unordered_map ليس الخيار الأفضل عندما نريد الحصول على أقصى سرعة. عند استخدام جداول تجزئة العنونة المفتوحة ، يصبح الاختيار الصحيح لوظيفة البعثرة عاملاً حاسماً ، ولا يمكننا استخدام دالة التجزئة التافهة.
من السهل العثور على اختبارات أداء جدول التجزئة على بيانات عشوائية ، دون النظر في وظائف التجزئة المستخدمة. من السهل أيضًا العثور على اختبارات دالة التجزئة مع التركيز على سرعة الحساب وبعض معايير الجودة ، ومع ذلك ، بمعزل عن هياكل البيانات المستخدمة. ولكن الحقيقة هي أن جداول التجزئة و HyperLogLog تتطلب معايير جودة مختلفة لوظائف التجزئة.
اقرأ المزيد عن هذا في التقرير
"كيفية ترتيب جداول التجزئة في ClickHouse" . لقد عفا عليه الزمن بعض الشيء لأنه لا يعتبر
الجداول السويسرية .
مهمة
نريد الحصول على البيانات لاختبار الأداء حسب الهيكل ، مثل بيانات Yandex.Metrica ، التي يتم تخزين جميع الخصائص المهمة للمعايير ، ولكن حتى لا يتم ترك آثار لزوار الموقع الحقيقي في هذه البيانات. بمعنى ، يجب أن تكون البيانات مجهولة المصدر ، ويجب تخزين ما يلي:
- نسب الضغط
- أصل (عدد القيم المختلفة) ،
- العلاقات المتبادلة بين عدة أعمدة مختلفة ،
- خصائص توزيعات الاحتمالية التي يمكنك من خلالها محاكاة البيانات (على سبيل المثال ، إذا اعتقدنا أن المناطق موزعة وفقًا لقانون الطاقة ، فيجب أن تكون معلمة الأس - التوزيع - للبيانات المصطنعة مماثلة للواقع الحقيقي).
وما هو المطلوب للبيانات أن يكون لها نسبة ضغط مماثلة؟ على سبيل المثال ، إذا تم استخدام LZ4 ، فيجب تكرار الأسس الفرعية في البيانات الثنائية على مسافات متساوية تقريبًا ويجب أن تكون التكرار بنفس الطول تقريبًا. بالنسبة إلى ZSTD ، تتم إضافة مطابقة إنتروبيا.
الهدف الأقصى: إتاحة أداة للأشخاص الخارجيين ، بحيث يمكن للجميع إخفاء هوية مجموعة البيانات الخاصة بهم للنشر. حتى نتمكن من تصحيح الأداء واختباره على بيانات الأشخاص الآخرين المشابهة لبيانات الإنتاج. وأود أن تكون مثيرة للاهتمام لمشاهدة البيانات التي تم إنشاؤها.
هذا هو بيان غير رسمي للمشكلة. ومع ذلك ، لا أحد كان على وشك الإدلاء ببيان رسمي.
محاولات لحلها
لا ينبغي المبالغة في أهمية هذه المهمة بالنسبة لنا. في الواقع ، لم يكن ذلك في الخطط ولم يكن أحد يفعل ذلك. أنا فقط لم أتخلى عن الأمل في أن يتوصل شيء ما إلى نفسه ، وفجأة سيكون لدي مزاج جيد والكثير من الأشياء التي يمكن تأجيلها إلى وقت لاحق.
النماذج الاحتمالية الصريحة
الفكرة الأولى هي اختيار مجموعة من توزيعات الاحتمالية التي تصممها لكل عمود في الجدول. بعد ذلك ، استنادًا إلى إحصائيات البيانات ، حدد معلمات ملائمة النموذج وإنشاء بيانات جديدة باستخدام التوزيع المحدد. يمكنك استخدام مولد الأرقام العشوائية المزيفة مع بذرة محددة مسبقًا للحصول على نتيجة قابلة للتكرار.
بالنسبة لحقول النص ، يمكنك استخدام سلاسل Markov - وهو نموذج يمكن فهمه يمكنك من خلاله تنفيذ فعال.
صحيح ، بعض الحيل مطلوبة:
- نريد الحفاظ على استمرارية السلسلة الزمنية - مما يعني أنه بالنسبة لبعض أنواع البيانات ، من الضروري ألا تصمم القيمة نفسها ، بل الفرق بين الأنواع المجاورة.
- من أجل محاكاة العلاقة الشرطية للأعمدة (على سبيل المثال ، عادة ما يكون هناك عدد قليل من عناوين IP لكل معرف زائر) ، ستحتاج أيضًا إلى تدوين التبعيات بين الأعمدة بشكل صريح (على سبيل المثال ، لإنشاء عنوان IP ، يتم استخدام تجزئة من معرف الزائر ، ولكن أيضًا تتم إضافة بعض البيانات العشوائية الزائفة).
- من غير الواضح كيفية التعبير عن التبعية التي يقوم بها زائر واحد في نفس الوقت تقريبًا بزيارات لعناوين URL ذات النطاقات المتطابقة.
يتم تقديم كل هذا في شكل برنامج يتم فيه ترميز جميع التوزيعات والاعتمادات الصلبة - ما يسمى "C ++ script". ومع ذلك ، لا تزال تُحسب طرز Markov من مجموع الإحصاءات ، وتنعيم وتلطيف الضوضاء. بدأت في كتابة هذا السيناريو ، لكن لسبب ما ، بعد أن كتبت صراحة النموذج لعشرة أعمدة ، أصبح فجأة مملًا بشكل لا يطاق. وفي جدول الزيارات في Yandex.Metrica مرة أخرى في عام 2012 كان هناك أكثر من 100 عمود.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
كان هذا النهج للمهمة فشل. إذا اقتربت منها بجد أكثر ، فمن المؤكد أن البرنامج النصي سيكون مكتوبًا.
المزايا:
العيوب:
- تعقيد التنفيذ ،
- الحل المطبق مناسب لنوع واحد فقط من البيانات.
أود الحصول على حل أكثر عمومية - بحيث يمكن تطبيقه ليس فقط على بيانات Yandex.Metrica ، ولكن أيضًا لتعتيم أي بيانات أخرى.
ومع ذلك ، التحسينات ممكنة هنا. لا يمكنك تحديد النماذج يدويًا ، ولكن تطبيق كتالوج من النماذج واختيار الأفضل بينها (أفضل ملاءمة + نوع من التنظيم). أو ربما يمكنك استخدام نماذج Markov لجميع أنواع الحقول ، وليس فقط للنص. التبعيات بين البيانات يمكن أيضا أن يفهم تلقائيا. للقيام بذلك ، تحتاج إلى حساب
الانتماءات النسبية (الكمية النسبية من المعلومات) بين الأعمدة ، أو ببساطة أكثر ، الكاردينالات النسبية (شيء مثل "عدد القيم المختلفة في المتوسط لقيمة B الثابتة") لكل زوج من الأعمدة. سيوضح ذلك ، على سبيل المثال ، أن URLDomain يعتمد كليا على عنوان URL ، وليس العكس.
لكنني رفضت هذه الفكرة أيضًا ، لأن هناك العديد من الخيارات لما يجب مراعاته ، وسوف يستغرق وقتًا طويلاً للكتابة.
الشبكات العصبية
قلت بالفعل مدى أهمية هذه المهمة بالنسبة لنا. لم يفكر أحد في صنع أي تزحف إلى تنفيذه. لحسن الحظ ، عمل الزميل إيفان بوزيريفسكي كمدرس في HSE وفي الوقت نفسه كان يعمل على تطوير جوهر YT. سأل عما إذا كان لدي أي مهام مثيرة للاهتمام يمكن تقديمها للطلاب كموضوع دبلوم. عرضت عليه هذا وأكد لي أنه مناسب. لذلك أعطيت هذه المهمة لشخص جيد "من الشارع" - شريف Anvardinov (تم توقيع NDA للعمل مع البيانات).
أخبره بكل أفكاره ، لكن الأهم من ذلك هو أنه يمكن حل المشكلة بأي شكل من الأشكال. وسيكون الخيار الجيد هو استخدام تلك الأساليب التي لا أفهمها مطلقًا: على سبيل المثال ، إنشاء ملف تفريغ بيانات نصية باستخدام LSTM. بدا الأمر مشجعًا بفضل
مقالة "الفعالية غير المعقولة للشبكات العصبية المتكررة" التي لفتت انتباهي بعد ذلك.
الميزة الأولى للمهمة هي أنك تحتاج إلى إنشاء بيانات منظمة ، وليس فقط النص. لم يكن واضحًا ما إذا كانت الشبكة العصبية المتكررة ستتمكن من توليد البيانات باستخدام البنية المطلوبة. هناك طريقتان لحل هذا. الأول هو استخدام نماذج منفصلة لإنشاء الهيكل ولحشو "الحشو": يجب على الشبكة العصبية توليد القيم فقط. ولكن تم تأجيل هذا الخيار إلى وقت لاحق ، وبعد ذلك لم يفعلوا. الطريقة الثانية هي ببساطة إنشاء ملف تفريغ TSV كنص. أوضحت الممارسة أنه في النص ، لن يتوافق جزء من الخطوط مع البنية ، ولكن يمكن طرح هذه الأسطر عند التحميل.
الميزة الثانية - شبكة عصبية متكررة تولد سلسلة من البيانات ، والتبعيات في البيانات يمكن أن تتبع فقط في ترتيب هذا التسلسل. ولكن في بياناتنا ، ربما يتم عكس ترتيب الأعمدة فيما يتعلق بالتبعية بينهما. لم نفعل أي شيء مع هذه الميزة.
نحو الصيف ، ظهر أول سيناريو بيثون يعمل على توليد البيانات. للوهلة الأولى ، جودة البيانات لائقة:
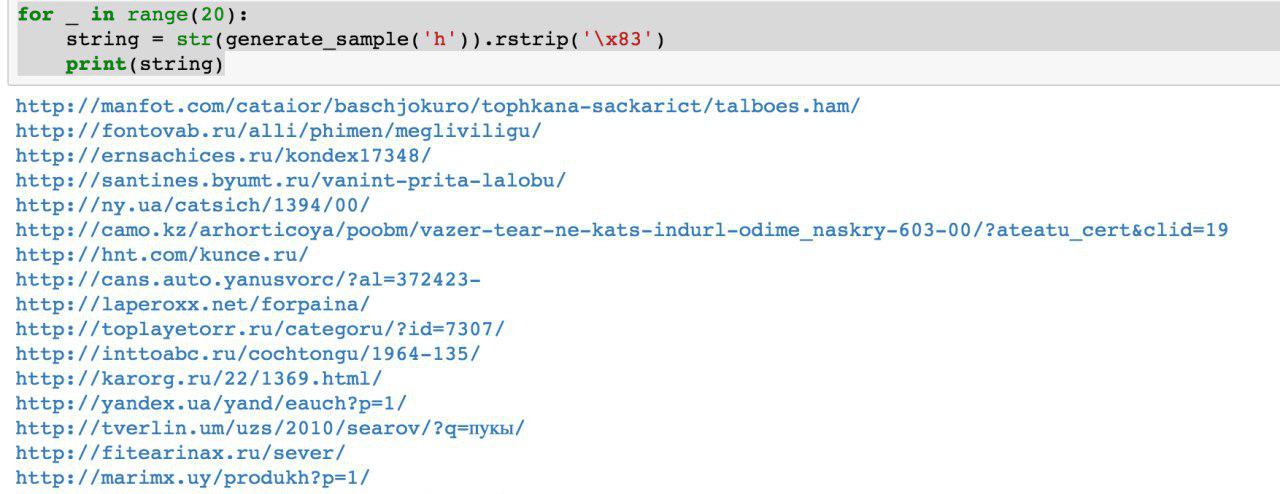
صحيح ، تم الكشف عن الصعوبات:
- حجم النموذج هو حوالي غيغابايت. لقد حاولنا إنشاء نموذج للبيانات التي كان حجمها بترتيب عدة غيغابايت (بالنسبة للمبتدئين). حقيقة أن النموذج الناتج كبير للغاية يثير المخاوف: فجأة سيكون من الممكن الحصول على بيانات حقيقية منه تم تدريبه عليها. على الأرجح لا. لكنني لا أفهم التعلم الآلي والشبكات العصبية ولم أقرأ شفرة بيثون من هذا الشخص ، فكيف يمكنني أن أتأكد؟ ثم كانت هناك مقالات حول كيفية ضغط الشبكات العصبية دون فقدان الجودة ، ولكن هذا ترك دون تنفيذ. من ناحية ، لا يبدو هذا مشكلة - يمكنك رفض نشر النموذج ونشر البيانات التي تم إنشاؤها فقط. من ناحية أخرى ، في حالة إعادة التدريب ، قد تحتوي البيانات التي تم إنشاؤها على جزء من البيانات المصدر.
- على جهاز واحد مع وحدة المعالجة المركزية ، يبلغ معدل توليد البيانات حوالي 100 سطر في الثانية. كان لدينا مهمة - لتوليد ما لا يقل عن مليار خطوط. أظهر الحساب أنه لا يمكن القيام بذلك قبل الدفاع عن الدبلوم. واستخدام الأجهزة الأخرى غير عملي ، لأنه كان لدي هدف - إتاحة أداة إنشاء البيانات للاستخدام على نطاق واسع.
حاول شريف دراسة جودة البيانات من خلال مقارنة الإحصاءات. على سبيل المثال ، حسبت التردد الذي تظهر به الرموز المختلفة في المصدر وفي البيانات التي تم إنشاؤها. كانت النتيجة مذهلة - الشخصيات الأكثر شيوعًا هي Ð و Ñ.
لا تقلق - لقد دافع عن شهادته تمامًا ، وبعدها نسينا بأمان هذا العمل.
تحويل البيانات المضغوطة
لنفترض أن بيان المشكلة قد تم تقليله إلى نقطة واحدة: تحتاج إلى إنشاء بيانات تكون نسب الضغط فيها مطابقة تمامًا للبيانات الأصلية ، بينما يجب توسيع البيانات بنفس السرعة تمامًا. كيف نفعل ذلك؟ تحتاج إلى تحرير بايت من البيانات المضغوطة مباشرة! ثم لن يتغير حجم البيانات المضغوطة ، لكن البيانات نفسها ستتغير. نعم ، وكل شيء سوف يعمل بسرعة. عندما ظهرت هذه الفكرة ، أردت على الفور تنفيذها ، على الرغم من أنها تحل بعض المشكلات الأخرى بدلاً من المشكلة الأصلية. هذا يحدث دائما.
كيفية تحرير ملف مضغوط مباشرة؟ لنفترض أننا مهتمون فقط بـ LZ4. تتكون البيانات المضغوطة باستخدام LZ4 من نوعين من التعليمات:
- حرفية: انسخ البايتات N التالية كما هي.
- المطابقة (المطابقة ، الحد الأدنى لطول التكرار هو 4): كرر N بايت التي كانت في الملف على مسافة M.
مصدر البيانات:
Hello world Hello .
البيانات المضغوطة (المشروطة):
literals 12 "Hello world " match 5 12 .
في الملف المضغوط ، اترك المطابقة كما هي ، وفي القيم الحرفية سنغير قيم البايت. نتيجة لذلك ، بعد إلغاء الضغط ، نحصل على ملف يتم فيه أيضًا تكرار كل التتابعات المتكررة التي لا يقل طولها عن 4 مرات ، وتتكرر في نفس المسافات ، ولكن في نفس الوقت تتكون من مجموعة مختلفة من البايتات (تحدث مجازيًا ، لم يتم أخذ بايت واحد من الملف الأصلي في الملف المعدل ).
ولكن كيف لتغيير البايت؟ هذا غير واضح لأنه ، بالإضافة إلى أنواع الأعمدة ، تحتوي البيانات أيضًا على هيكلها الداخلي الضمني ، الذي نود الحفاظ عليه. على سبيل المثال ، يتم تخزين النص غالبًا بترميز UTF-8 - ونريد UTF-8 صالحًا في البيانات التي تم إنشاؤها أيضًا. أدليت به ارشادي بسيط لتلبية عدة شروط:
- تم تخزين البايتات الفارغة وأحرف التحكم ASCII كما هي ،
- بعض علامات الترقيم استمرت ،
- تمت ترجمة ASCII إلى ASCII ، وبالنسبة للباقي ، تم حفظ البتة الأكثر أهمية (أو يمكنك كتابة صراحة إذا تم ضبطها على أطوال UTF-8 مختلفة). بين فئة واحدة من بايت ، يتم تحديد قيمة جديدة بشكل عشوائي بالتساوي.
- وأيضًا لحفظ أجزاء من
https:// وما شابه ذلك ، وإلا يبدو كل شيء سخيفًا للغاية.
خصوصية هذا النهج هو أن البيانات الأولية نفسها بمثابة نموذج للبيانات ، مما يعني أنه لا يمكن نشر النموذج. يسمح لك بإنشاء كمية البيانات لا يزيد عن الأصل. للمقارنة ، في الطرق السابقة كان من الممكن إنشاء نموذج وإنشاء كمية غير محدودة من البيانات على أساسها.
مثال لعنوان URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
لقد أسعدتني النتيجة - كان من المثير للاهتمام أن ننظر إلى البيانات. ولكن لا يزال ، كان هناك شيء خاطئ. لا تزال عناوين URL منظمة ، لكن في بعض الأماكن كان من السهل جدًا تخمين yandex أو avito. صنع ارشادي في بعض الأحيان يعيد ترتيب بعض وحدات البايت في بعض الأماكن.
اعتبارات أخرى قلقة. على سبيل المثال ، يمكن تمثيل المعلومات الحساسة في عمود من النوع FixedString في شكل ثنائي ، ولسبب ما يتكون من أحرف تحكم ASCII وعلامات الترقيم التي قررت حفظها. وأنا لا أعتبر أنواع البيانات.
مشكلة أخرى: إذا تم تخزين بيانات من النوع "طول ، قيمة" في عمود واحد (هذه هي الطريقة التي يتم بها تخزين أعمدة نوع السلسلة) ، فكيف تضمن بقاء الطول صحيحًا بعد الطفرة؟ عندما حاولت إصلاحه ، أصبحت المهمة على الفور غير مهمة.
التباديل العشوائي
لكن المشكلة لم تحل. لقد أجرينا العديد من التجارب ، وقد ازداد الأمر سوءًا. يبقى فقط عدم القيام بأي شيء وقراءة الصفحات العشوائية على الإنترنت ، لأن الحالة المزاجية تفسدت بالفعل. لحسن الحظ ، كان في إحدى هذه الصفحات
تحليل الخوارزمية لتقديم مشهد وفاة بطل الرواية في لعبة Wolfenstein 3D.

الرسوم المتحركة الجميلة - تملأ الشاشة بالدم. يشرح المقال أن هذا هو في الواقع تقليب عشوائي الزائفة. التقليب العشوائي - تحويل واحد إلى واحد تم اختياره عشوائيًا للمجموعة. بمعنى ، عرض المجموعة الكاملة التي لا تتكرر فيها نتائج الوسائط المختلفة. بمعنى آخر ، هذه طريقة للتكرار على كل عناصر مجموعة بترتيب عشوائي. إنها عملية تظهر في الصورة - فنحن نرسم على كل بكسل ، يتم اختياره عشوائيًا من الجميع ، دون تكرار. إذا اخترنا فقط بكسل عشوائي في كل خطوة ، فسيستغرق الأمر وقتًا طويلاً للرسم على الخطوة الأخيرة.
تستخدم اللعبة خوارزمية بسيطة للغاية للتحول العشوائي الزائف -
LFSR (سجل تحويل الملاحظات الخطي). مثل مولدات الأرقام العشوائية المزيفة ، فإن التباديل العشوائي ، أو بالأحرى عائلاتهم ، والمعلمة بالمفتاح ، يمكن أن تكون قوية من الناحية المشفرة - وهذا هو بالضبط ما نحتاجه لتحويل البيانات. رغم أنه قد يكون هناك تفاصيل غير واضحة. على سبيل المثال ، يمكن تشفير التشفير القوي للبايتات N إلى البايتات N بمفتاح ثابت مسبقًا وناقل التهيئة ، كما يمكن استخدامه ، كالتشكيل العشوائي الزائف للعديد من سلاسل البايتات N. في الواقع ، مثل هذا التحول هو واحد لواحد ويبدو عشوائي. ولكن إذا استخدمنا نفس التحويل لجميع بياناتنا ، فقد تكون النتيجة قابلة للتحليل ، لأن نفس متجه التهيئة والقيم الرئيسية يتم استخدامها عدة مرات. هذا مشابه لوضع تشفير كتلة
Codebook الإلكترونية .
ما هي طرق الحصول على التقليب العشوائي الزائف؟ يمكنك إجراء تحويلات بسيطة فردية وتجميع وظيفة معقدة إلى حد ما منها تبدو عشوائية. اسمحوا لي أن أقدم لكم مثالًا على بعض التحولات المفضلة لدي:
- الضرب بعدد فردي (على سبيل المثال ، عدد كبير) في حساب مكمل للاثنين ،
- xor-shift:
x ^= x >> N ، - CRC-N ، حيث N هو عدد بتات الوسيطة.
لذلك ، على سبيل المثال ، من ثلاث عمليات الضرب وعمليات عمليتي تحويل xor ، يتم
تجميع أداة إنهاء
murmurhash . هذه العملية هي التقليب العشوائي الزائف. لكن فقط في الحالة ، لاحظت أن وظائف التجزئة ، حتى N Nits في N bits ، لا يجب أن تكون فريدة من نوعها.
أو إليك
مثال آخر مثير للاهتمام
من نظرية الأعداد الأولية من موقع Jeff Preshing.
كيف يمكننا استخدام التباديل العشوائي المزيف لمهمتنا؟ يمكنك تحويل جميع الحقول الرقمية التي تستخدمها. عندها سيكون من الممكن الحفاظ على جميع العناصر الأساسية والأصالة المتبادلة لجميع مجموعات الحقول. وهذا يعني أن COUNT (DISTINCT) سيعود بنفس القيمة كما كان قبل التحويل ، ومع أي GROUP BY.
تجدر الإشارة إلى أن الحفاظ على جميع العناصر الأساسية يتناقض قليلاً مع بيان مشكلة إخفاء البيانات. , , , 10 , . 10 — , . , , , — , , . . , , , Google, , - Google. — , , ( ) ( ). , ,
.
, . , 10, . ?
, size classes ( ). size class , . 0 1 . 2 3 1/2 1/2 . 1024..2047 1024! () . و هكذا. .
, . , -. , .
, , , .
— , . . . Fabien Sanglard c
Hackers News , .
Redis — . ,
.
. — , . , .
- :
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - . xor :
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
, F 4 , .
: , , — , , !
. , , , . :
- , , Electronic Codebook mode of operation;
- ( ) , , .
. , LZ4 , , .
, , , . — . , , , . ( , ). ?
-, : , 256^10 10 , , . -, , .
, . , , . , . , - .
, — , N . N — . , N = 5, «» «». Order-N.
P( | ) = 0.9
P( | ) = 0.05
P( | ) = 0.01
.... ( vesna.yandex.ru). LSTM, N, , . — , . : , , .
Title:
— . — , . , , — .@Mail.Ru — — - . ) — AUTO.ria.ua
, , . () , — . 0 N, N N − 1).
. , 123456 URL, . . -. . , .
: URL, , -. :
https://www.yandex.ru/images/cats/?id=xxxxxx . , URL, , . :
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . - , 8 .
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ..., . :
- | . -
- — .: Lore - dfghf — . - ) 473682 -
- ! » - —
- ! » ,
- . c @Mail.Ru -
- , 2010 | .
- ! : 820 0000 ., -
- - DoramaTv.ru - . - ..
- . 2013 , -> 80 .
- - (. , ,
- . 5, 69, W* - ., , World of Tanks
- , . 2 @Mail.Ru
- , .
يؤدي
, - , - . , . clickhouse obfuscator, : (, CSV, JSONEachRow), ( ) ( , ). .
clickhouse-client, Linux. , ClickHouse. , MySQL PostgreSQL , .
clickhouse obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse obfuscator --help
, . , ? , , . , , . , (
--help ) .
, .
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzClickHouse. , ClickHouse .