مرحبا يا هبر! اسمي ساشا وأنا مطور خلفية. في وقت فراغي أدرس ML واستمتع ببيانات hh.ru.
تتناول هذه المقالة كيفية أتمتة عملية تعيين المهام الروتينية للمختبرين الذين يستخدمون التعلم الآلي.
لدى Hh.ru خدمة داخلية يتم إنشاؤها من أجلها المهام في Jira (داخل الشركة يطلق عليها HHS) إذا كان شخص ما لا يعمل أو يعمل بشكل غير صحيح. علاوة على ذلك ، يتم التعامل مع هذه المهام يدويًا من قِبل قائد فريق ضمان الجودة أليكسي وتعيينها للفريق الذي يتضمن مجال مسؤوليته خللًا. يعرف ليشا أن المهام المملة يجب أن يؤديها الإنسان الآلي. لذلك ، التفت إلي للحصول على المساعدة فيما يتعلق ML.

يوضح الرسم البياني أدناه مقدار HHS في الشهر. نحن تنمو وعدد المهام آخذ في الازدياد. يتم إنشاء المهام بشكل رئيسي خلال ساعات العمل ، وعدد قليل في اليوم ، وهذا يجب أن يصرف باستمرار.
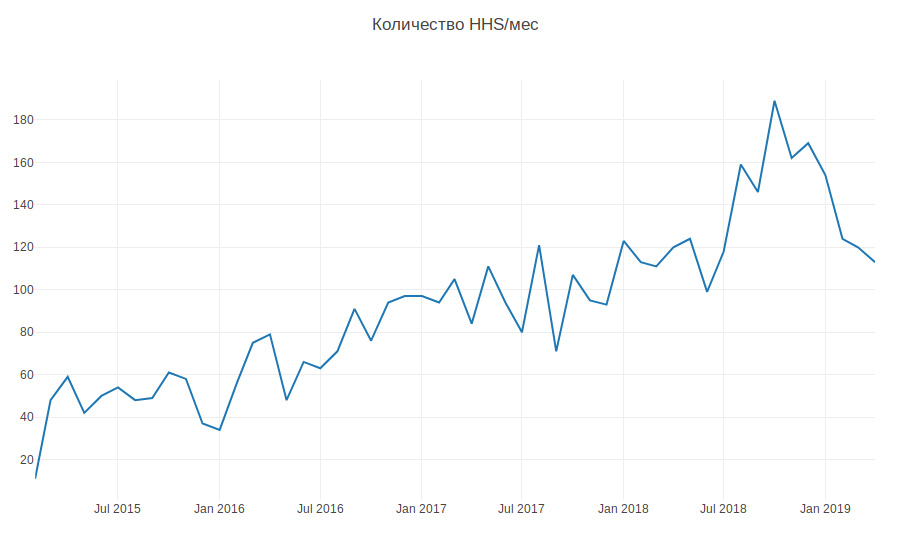
لذلك ، وفقًا للبيانات التاريخية ، من الضروري معرفة كيفية تحديد فريق التطوير الذي ينتمي إليه HHS. هذه مهمة تصنيف متعددة الفئات.
معطيات
في مهام التعلم الآلي ، أهم شيء هو جودة البيانات. نتائج حل المشكلة يعتمد عليها. لذلك ، يجب أن تبدأ أي مهام للتعلم الآلي في دراسة البيانات. منذ بداية عام 2015 ، جمعنا حوالي 7000 مهمة تحتوي على المعلومات المفيدة التالية:
- ملخص - العنوان ، وصف قصير
- الوصف - وصف كامل للمشكلة
- التسميات - قائمة العلامات المتعلقة بالمشكلة
- المراسل هو اسم خالق HHS. هذه الميزة مفيدة لأن الأشخاص يعملون مع مجموعة محدودة من الوظائف.
- تاريخ الإنشاء - تاريخ الإنشاء
- المحال إليه هو الشخص الذي تم تعيين المهمة إليه. سيتم إنشاء المتغير الهدف من هذه السمة.
لنبدأ مع المتغير الهدف. أولا ، كل فريق لديه مجالات المسؤولية. في بعض الأحيان تتقاطع ، وأحيانًا يتقاطع فريق ما في عملية التطوير مع فريق آخر. سوف يستند القرار إلى افتراض أن المحال إليه ، الذي ظل مهمًا في وقت الإغلاق ، مسؤولاً عن الحل. لكننا بحاجة إلى التنبؤ ليس بشخص بعينه ، بل بفريق. لحسن الحظ ، يتم الاحتفاظ بجميع الفرق في جيرا ويمكن تعيينها. لكن هناك عددًا من المشكلات في تعريف الفريق من قِبل الشخص:
- ليست كل HHS مرتبطة بالمشكلات الفنية ، ونحن مهتمون فقط بتلك المهام التي يمكن تكليفها بفريق التطوير. لذلك ، تحتاج إلى التخلص من المهام حيث لا يكون المحال من الإدارة الفنية
- في بعض الأحيان تتوقف الفرق عن الوجود. تتم إزالتها أيضًا من مجموعة التدريب.
- لسوء الحظ ، لا يعمل الأشخاص إلى الأبد في الشركة ، وأحيانًا ينتقلون من فريق إلى آخر. لحسن الحظ ، تمكنا من الحصول على تاريخ من التغييرات في تكوين جميع الفرق. بعد تاريخ إنشاء HHS والمحال إليه ، يمكنك العثور على الفريق الذي شارك في المهمة في وقت محدد.
بعد تصفية البيانات غير ذات الصلة ، تم تخفيض عينة التدريب إلى 4900 مهمة.
لنلقِ نظرة على توزيع المهام بين الفرق:
يجب توزيع المهام بين 22 فريق.
الأعراض:
الملخص والوصف حقول نصية.
أولاً ، يجب تنظيفها من الأحرف الزائدة. بالنسبة إلى بعض المهام ، من المنطقي أن أترك في السطور أحرفًا تحمل معلومات ، على سبيل المثال + و # ، للتمييز بين c ++ و c # ، لكن في هذه الحالة قررت ترك الأحرف والأرقام فقط ، لأن لم تجد المكان الذي قد تكون فيه الشخصيات الأخرى مفيدة.
الكلمات تحتاج إلى أن تطفأ. Lemmatization هو اختزال كلمة إلى lemma ، شكلها الطبيعي (المفردات). على سبيل المثال ، القطط → القط. حاولت أيضًا أن تنبع ، ولكن مع الليمات كانت الجودة أعلى قليلاً. Stamming هي عملية العثور على أساس الكلمة. هذا الأساس يرجع إلى الخوارزمية (في تطبيقات مختلفة فهي مختلفة) ، على سبيل المثال ، عن طريق القطط → القطط. معنى الأول والثاني هو juxtapose نفس الكلمات في أشكال مختلفة. لقد استخدمت المجمع بيثون
لياندكس Mystem .
علاوة على ذلك ، يجب محو النص من كلمات التوقف التي لا تحمل حمولة. على سبيل المثال ، "كان" ، "أنا" ، "بعد". توقف الكلمات التي عادة ما
آخذها من
NLTK .
هناك طريقة أخرى أحاول القيام بها في مهام العمل باستخدام النص وهي تجزئة الكلمات على أساس الأحرف. على سبيل المثال ، هناك "بحث". إذا قسمتها إلى مكونات مكونة من 3 أحرف ، فستحصل على الكلمات "poi" و "ois" و "دعوى قضائية". هذا يساعد على الحصول على اتصالات إضافية. لنفترض أن هناك كلمة "بحث". لا يؤدي Lemmatization إلى "البحث" و "البحث" بشكل عام ، ولكن القسم المكون من 3 أحرف سيسلط الضوء على الجزء المشترك - "المطالبة".
لقد صنعت رمزين. Tokenizer هي طريقة تستقبل النص عند الإدخال ، ويحتوي الإخراج على قائمة الرموز - مكونات النص. أول يسلط الضوء على الكلمات والأرقام lemmatized. ثاني فقط يسلط الضوء على الكلمات lemmatized ، والتي تنقسم إلى 3 أحرف ، أي في الإخراج ، لديه قائمة الرموز الثلاثة أحرف.
يتم استخدام
الرموز المميزة في
TfidfVectorizer ، والذي يستخدم لتحويل البيانات النصية (وليس فقط) إلى تمثيل متجه يستند إلى
tf-idf . يتم تغذية قائمة من الصفوف بها عند الإدخال ، وفي المخرجات نحصل على مصفوفة M بواسطة N ، حيث M هو عدد الصفوف و N هو عدد العلامات. كل ميزة هي استجابة تردد لكلمة في وثيقة ، حيث يتم تغريم التردد إذا حدثت الكلمة عدة مرات في جميع الوثائق. بفضل المعلمة ngram_range TfidfVectorizer ، أضفت bigrams و trigrams كسمات.
لقد حاولت أيضًا استخدام زخارف الكلمات التي تم الحصول عليها باستخدام Word2vec كميزات إضافية. التضمين هو تمثيل متجه للكلمة. بالنسبة لكل نص ، قمت بتوسيط زخارف كل كلماته. لكن هذا لم يعط أي زيادة ، لذلك رفضت هذه العلامات.
للتسميات ، تم استخدام
CountVectorizer . يتم تغذية الصفوف ذات العلامات إلى المدخلات ، وعند الإخراج لدينا مصفوفة حيث تتوافق الصفوف مع المهام وتتوافق الأعمدة مع العلامات. تحتوي كل خلية على عدد مرات تواجد العلامة في المهمة. في حالتي ، هو 1 أو 0.
جاء
LabelBinarizer لمراسل. يقوم بترميز السمات الفردية. يمكن أن يكون هناك منشئ واحد فقط لكل مهمة. عند مدخل LabelBinarizer ، يتم تقديم قائمة بمنشئي المهام ، والإخراج عبارة عن مصفوفة ، حيث تمثل الصفوف مهام وتتوافق الأعمدة مع أسماء منشئي المهام. اتضح أنه في كل سطر يوجد "1" في العمود المقابل للمنشئ ، وفي الباقي - "0".
بالنسبة إلى Created ، يتم اعتبار الفرق في الأيام بين تاريخ إنشاء المهمة والتاريخ الحالي.
نتيجة لذلك ، تم الحصول على العلامات التالية:
- tf-idf للملخص في الكلمات والأرقام (4855 ، 4593)
- tf-idf لملخص على أقسام مكونة من ثلاثة أحرف (4855 ، 15518)
- tf-idf for Description في الكلمات والأرقام (4855 ، 33297)
- tf-idf for Description على أقسام ثلاثية الأحرف (4855 ، 75359)
- عدد إدخالات التصنيفات (4855 ، 505)
- العلامات الثنائية لمراسل (4855 ، 205)
- عمر المهمة (4855 ، 1)
يتم دمج كل هذه العلامات في مصفوفة واحدة كبيرة (4855 ، 129478) ، والتي سيتم تنفيذها على التدريب.
بشكل منفصل ، تجدر الإشارة إلى أسماء العلامات. لأن يمكن لبعض نماذج التعلم الآلي تحديد الميزات التي يكون لها أكبر تأثير على التعرف على الصف ، تحتاج إلى استخدام هذا. لدى TfidfVectorizer و CountVectorizer و LabelBinarizer طرق get_feature_names التي تعرض قائمة من الميزات التي يتوافق ترتيبها مع أعمدة مصفوفات البيانات.
اختيار نموذج التنبؤ
في كثير من الأحيان
XGBoost يعطي نتائج جيدة. وبدأ معها. لكني قمت بإنشاء عدد كبير من الميزات ، يتجاوز عددها بشكل ملحوظ حجم عينة التدريب. في هذه الحالة ، فإن احتمال إعادة تدريب XGBoost مرتفع. النتيجة ليست جيدة جدا. يتم هضم البعد العالي
LogisticRegression . لقد أظهرت جودة أعلى.
لقد حاولت أيضًا كتمرين لبناء نموذج على شبكة عصبية في Tensorflow باستخدام
هذا البرنامج التعليمي الممتاز ، لكنه اتضح أنه أسوأ من الانحدار اللوجستي.
اختيار hyperparameters
لقد لعبت أيضًا مع متغيرات XGBoost و Tensorflow ، ولكني أتركها خارج المنشور ، لأن لم يتم تجاوز نتيجة الانحدار اللوجستي. في الماضي أنا ملتوية كل الأقلام التي يمكن أن تكون. ظلت جميع المعلمات كنتيجة افتراضية ، باستثناء اثنين: solver = 'liblinear' و C = 3.0
المعلمة الأخرى التي يمكن أن تؤثر على النتيجة هي حجم عينة التدريب. لأن أنا أتعامل مع البيانات التاريخية ، وعلى مدار عدة سنوات ، يمكن أن يتغير التاريخ بشكل خطير ، على سبيل المثال ، يمكن للمسؤولية عن شيء ما الانتقال إلى فريق آخر ، ثم قد تكون البيانات الأحدث أكثر فائدة ، ويمكن للبيانات القديمة أن تخفض الجودة. في هذا الصدد ، توصلت إلى الاستدلال - كلما كانت البيانات أقدم ، قلت المساهمة التي ينبغي أن يقدموها في التدريب النموذجي. اعتمادًا على العمر ، يتم ضرب البيانات بمعامل معين ، مأخوذ من الوظيفة. لقد قمت بإنشاء العديد من الوظائف لتخفيف البيانات واستخدمت الوظيفة التي أعطت أكبر زيادة في الاختبار.
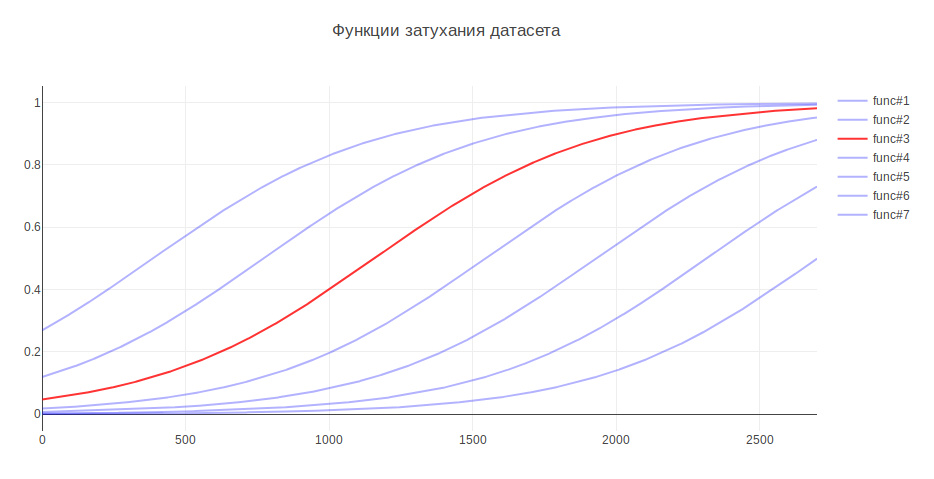
نتيجة لهذا ، زادت جودة التصنيف بنسبة 3٪
تقييم الجودة
في مشاكل التصنيف ، نحتاج إلى التفكير فيما هو أكثر أهمية بالنسبة لنا -
الدقة أم الاكتمال ؟ في حالتي ، إذا كانت الخوارزمية خاطئة ، فلا حرج ، فلدينا معرفة جيدة بين الفريقين وسيتم نقل المهمة إلى المسؤولين ، أو إلى الفريق الرئيسي في ضمان الجودة. بالإضافة إلى أن الخوارزمية لا ترتكب أخطاء بشكل عشوائي ، ولكنها تعثر على أمر قريب من المشكلة. لذلك ، تقرر أن تأخذ 100 ٪ للتأكد من اكتمالها. ولقياس الجودة ، تم اختيار مقياس الدقة - نسبة الإجابات الصحيحة ، والتي كانت للطراز النهائي 76٪.
كآلية تحقق ، استخدمت أولاً التحقق من الصحة - عندما يتم تقسيم العينة إلى أجزاء N ويتم فحص الجودة على جزء واحد ، ويتم التدريب على الباقي ، وهكذا N مرات ، حتى يتم اختبار كل جزء. ثم يتم حساب متوسط النتيجة. ولكن في حالتي ، فإن هذا النهج لم يصلح ، لأن يتغير ترتيب البيانات ، وكما أصبحت معروفة بالفعل ، تعتمد الجودة على حداثة البيانات. لذلك ، درست طوال الوقت على القديم ، وتم التحقق من صحة على جديدة.
دعونا نرى أي الأوامر الخوارزمية في كثير من الأحيان يخلط بين:

في المقام الأول هي التسويق وبندورا. هذا ليس مستغربا منذ ذلك الحين نما الفريق الثاني من الأول وتحمل مسؤولية العديد من الوظائف. إذا كنت تفكر في باقي أعضاء الفريق ، يمكنك أيضًا رؤية الأسباب المرتبطة بالمطبخ الداخلي للشركة.
للمقارنة ، أريد أن أنظر إلى نماذج عشوائية. إذا قمت بتعيين شخص مسؤول بشكل عشوائي ، فستكون الجودة حوالي 5٪ ، وإذا كانت الفئة الأكثر شيوعًا ، فعندئذ - 29٪
أهم العلامات
LogisticRegression لكل فئة بإرجاع معاملات السمة. كلما زادت القيمة ، زادت المساهمة التي قدمتها هذه السمة لهذه الفئة.
تحت المفسد ، خرج الجزء العلوي من العلامات. تشير البادئات إلى مصدر الإشارات:
- sum - tf-idf لملخص في الكلمات والأرقام
- sum2 - tf-idf لملخص عن انشقاقات ثلاثية الأحرف
- تنازلي - tf-idf لوصف في الكلمات والأرقام
- desc2 - tf-idf for Description على الأقسام المكونة من ثلاثة أحرف
- مختبر - حقل التسميات
- مندوب مجال المراسل
دليلفريق العمل: sum_site (1.28) ، lab_responses_and_invitations (1.37) ، lab_failure_to إلى صاحب العمل (1.07) ، lab_makeup (1.03) ، sum_work (1.59) ، lab_hhs (1.19) ، lab_feedback (1.06) ، rep_name (1.16) ، sum_ window (1.13) ، sum_ break (1.04) ، rep_name_1 (1.22) ، lab_responses_seeker (1.0) ، lab_site (0.92)
واجهة برمجة التطبيقات: lab_delete_account (1.12) ، sum_comment_resume (0.94) ، rep_name_2 (0.9) ، rep_name_3 (0.83) ، rep_name_4 (0.89) ، rep_name_5 (0.91) ، lab_measurements_managers (0.87) ، lab_comments_to_result (1.6) ، account6 ) ، sum_view (0.91) ، desc_comment (1.02) ، rep_name_6 (0.85) ، desc_resume (0.86) ، sum_api (1.01)
Android: sum_android (1.77) ، lab_ios (1.66) ، sum_application (2.9) ، sum_hr_mobile (1.4) ، lab_android (3.55) ، sum_hr (1.36) ، lab_mobile_application (3.33) ، sum_mobile (1.4) ، rep_name_2 (1.34) ، sum2_ril (1.27) ) ، sum_android_application (1.28) ، sum2_pril_rilo (1.19) ، sum2_pril_ril (1.27) ، sum2_ril_log (1.19) ، sum2_ril_log_ (1.19)
الفوترة: rep_name_7 (3.88) ، تنازلي (3.23) ، rep_name_8 (3.15) ، lab_billing_wtf (2.46) ، rep_name_9 (4.51) ، rep_name_10 (2.88) ، sum_account (3.16) ، lab_billing (2.41) ، rep_name_11 (2.27) ، rep_name_11 ) ، sum_service (2.33) ، lab_payment_services (1.92)، sum_act (2.26)، rep_name_12 (1.92)، rep_name_13 (2.4)
البراندي: تقييم lab_talent (2.17) ، rep_name_14 (1.87) ، rep_name_15 (3.36) ، lab_clickme (1.72) ، rep_name_16 (1.44) ، rep_name_17 (1.63) ، rep_name_18 (1.29) ، sum_page (1.24) ، sum_brand (1.39) lab ) ، sum_constructor (1.59) ، lab_brand من الصفحة (1.33) ، sum_description (1.23) ، sum_description_of the company (1.17)، lab_article (1.15)
Clickme: desc_act (0.73) ، sum_adv_hh (0.65) ، sum_adv_hh_ru (0.65) ، sum_hh (0.77) ، lab_hhs (1.27) ، lab_bs (1.91) ، rep_name_19 (1.17) ، rep_name_20 (1.29) ، rep_name_21 (1.9) ) ، sum_advertising (0.67) ، sum_placing (0.65)، sum_adv (0.65)، sum_hh_ua (0.64)، sum_click_31 (0.64)
التسويق: lab_region (0.9) ، lab_site_site (1.23) ، sum_mail (1.32) ، lab_managers_of الشواغر (0.93) ، sum_calender (0.93) ، rep_name_22 (1.33) ، lab_queries (1.25) ، rep_name_6 (1.53) ، lab_product_1.55 (repa1_5) ) ، sum_yandex (1.26) ، sum_distribution_vacancy (0.85) ، sum_distribution (0.85) ، sum_category (0.85)، sum_error_function (0.83)
الزئبق: lab_services (1.76) ، sum_captcha (2.02) ، lab_search_services (1.89) ، lab_lawyers (2.1) ، lab_authorization_worker (1.68) ، lab_proforientation (2.53) ، lab_ready_summary (2.21) ، rep_name_24 (1.7725_mail) ) ، sum_user (1.57) ، rep_name_26 (1.43) ، lab_moderation_of الشواغر (1.58) ، desc_password (1.39) ، rep_name_27 (1.36)
Mobile_site: sum_mobile_version (1.32) ، sum_version_site (1.26) ، lab_application (1.51) ، lab_statistics (1.32) ، sum_mobile_version_site (1.25) ، lab_mobile_version (5.1) ، sum_version (1. ) ، lab_jtb (1.07) ، rep_name_16 (1.12) ، rep_name_29 (1.05) ، sum_site (0.95) ، rep_name_30 (0.92)
TMS: rep_name_31 (1.39) ، lab_talantix (4.28) ، rep_name_32 (1.55) ، rep_name_33 (2.59) ، sum_valuation_talantix (0.74) ، lab_search (0.57) ، lab_search (0.63) ، rep_name_34 (0.64) ) ، lab_tms (0.74) ، استجابة sum_hh (0.57) ، lab_mailing (0.64) ، sum_talantix (0.6) ، sum2_po (0.56)
Talantix: sum_system (0.86) ، rep_name_16 (1.37) ، sum_talantix (1.16) ، lab_mail (0.94) ، lab_xor (0.8) ، lab_talantix (3.19) ، rep_name_35 (1.07) ، rep_name_18 (1.33) ، lab_personal_data (0.79) ) ، sum_talantics (0.89) ، sum_proceed (0.78) ، lab_mail (0.77) ، sum_response_stop_view (0.73) ، rep_name_6 (0.72)
WebServices: sum_vacancy (1.36)، desc_pattern (1.32)، sum_archive (1.3)، lab_patterns (1.39)، sum_number_phone (1.44)، rep_name_36 (1.28)، lab_lawyers (2.1)، lab_invitation (1.27)، lab_invitation (2) ) ، lab_selected_summages (1.2) ، lab_key_keys (1.22) ، sum_find (1.18) ، sum_phone (1.16) ، sum_folder (1.17)
iOS: sum_application (1.41) ، desc_application (1.13) ، lab_andriod (1.73) ، rep_name_37 (1.05) ، lab_mobile_application (1.88) ، lab_ios (4.55) ، rep_name_6 (1.41) ، rep_name_38 (1.35) ، sum_mobile_application ) ، sum_mobile (0.98) ، rep_name_39 (0.74) ، sum_resum_hide (0.88) ، rep_name_40 (0.81) ، lab_Duplication of الشواغر (0.76)
العمارة: sum_statistics_response (1.1) ، rep_name_41 (1.4) ، lab_graphics_views_and_responses_ الشواغر (1.04) ، lab_creation_of الشواغر (1.16) ، lab_quotas (1.0) ، sum_special Offer (1.02) ، rep_name_42 (1.33) 1.01_0101 ) ، rep_name_43 (1.09) ، sum_dependent (0.83) ، sum_statistics (0.83) ، lab_responses_worker (0.76)، sum_500ka (0.74)
بنك الراتب: lab_500 (1.18) ، lab_authorization (0.79) ، sum_500 (1.04) ، rep_name_44 (0.85) ، sum_500_site (1.03) ، lab_site (1.54) ، lab_visibility_resume (1.54) ، lab_price list (1.26)، lab_setting_visibility_7_resume sum_error (0.79) ، lab_delivered_orders (1.33) ، rep_name_43 (0.74) ، sum_ie_11 (0.69) ، sum_500_error (0.66)، sum2_site_ite (0.65)
منتجات الجوال: lab_mobile_application (1.69) ، lab_responses (1.65) ، sum_hr_mobile (0.81) ، lab_applicant (0.88) ، lab_employer (0.84) ، sum_mobile (0.81) ، rep_name_45 (1.2) ، desc_d0 (0.87) ، rep_name_46 (1.rr) 0.79) ، sum_incorrect_search_work (0.61) ، desc_application (0.71) ، rep_name_47 (0.69) ، rep_name_28 (0.61) ، sum_work_search (0.59)
باندورا: sum_receive (2.68) ، desc_receive (1.72) ، lab_sms (1.59) ، sum_ letter (2.75) ، sum_notification_response (1.38) ، sum_password (1.52) ، lab_recover_password (1.52) ، lab_mail_mail (1.31 ، mail ، mail (1.91) ) ، lab_mail (1.72) ، lab_mail (3.37) ، desc_mail (1.69) ، desc_mail (1.47) ، rep_name_6 (1.32)
الفلفل: lab_saving_summary (1.43) ، sum_summing (2.02) ، sum_oron (1.57) ، sum_oron_vacancy (1.66) ، desc_resum (1.19) ، lab_summing (1.39) ، sum_code (1.2) ، lab_applicant (1.34) ، sum_index ) ، lab_creation_summary (1.28) ، rep_name_45 (1.82) ، sum_civilness (1.47) ، sum_save_summum (1.18) ، lab_invital_index (1.13)
Search-1: sum2_poi_is_search (1.86) ، sum_loop (3.59) ، lab_questions_o_search (3.86) ، sum2_poi (1.86) ، desc_overs (2.49) ، lab_observing_summary (2.2) ، lab_observer (2.32) ، lab_loop (4.3oopropo_1) (1.62) ، sum_synonym (1.71) ، sum_sample (1.62) ، sum2_isk (1.58) ، sum2_is_isk (1.57) ، lab_auto-update_sum (1.57)
Search-2: rep_name_48 (1.13)، desc_d1 (1.1)، lab_premium_in_search (1.02)، lab_views_of الشواغر (1.4)، sum_search (1.4)، desc_d0 (1.2)، lab_show_contacts (1.17)، rep_name_49 (1.12950، lab13) (1.05) ، lab_search_of الشواغر (1.62) ، lab_responses_and_invitations (1.61) ، sum_response (1.09) ، lab_selected_results (1.37) ، lab_filter_of_responses (1.08)
المنتجات الفائقة: lab_contact_information (1.78) ، desc_address (1.46) ، rep_name_46 (1.84) ، sum_address (1.74) ، lab_selected_resumes (1.45) ، lab_reviews_worker (1.29) ، sum_right_shot (1.29) ، sum_right_range (1.29) ) ، sum_error_position (1.33) ، rep_name_42 (1.32) ، sum_quota (1.14) ، desc_address_office (1.14) ، rep_name_51 (1.09)
علامات تعكس تقريبا ما تفعله الفرق.
استخدام النموذج
على هذا ، يتم الانتهاء من بناء النموذج ومن الممكن بناء برنامج على أساسه.
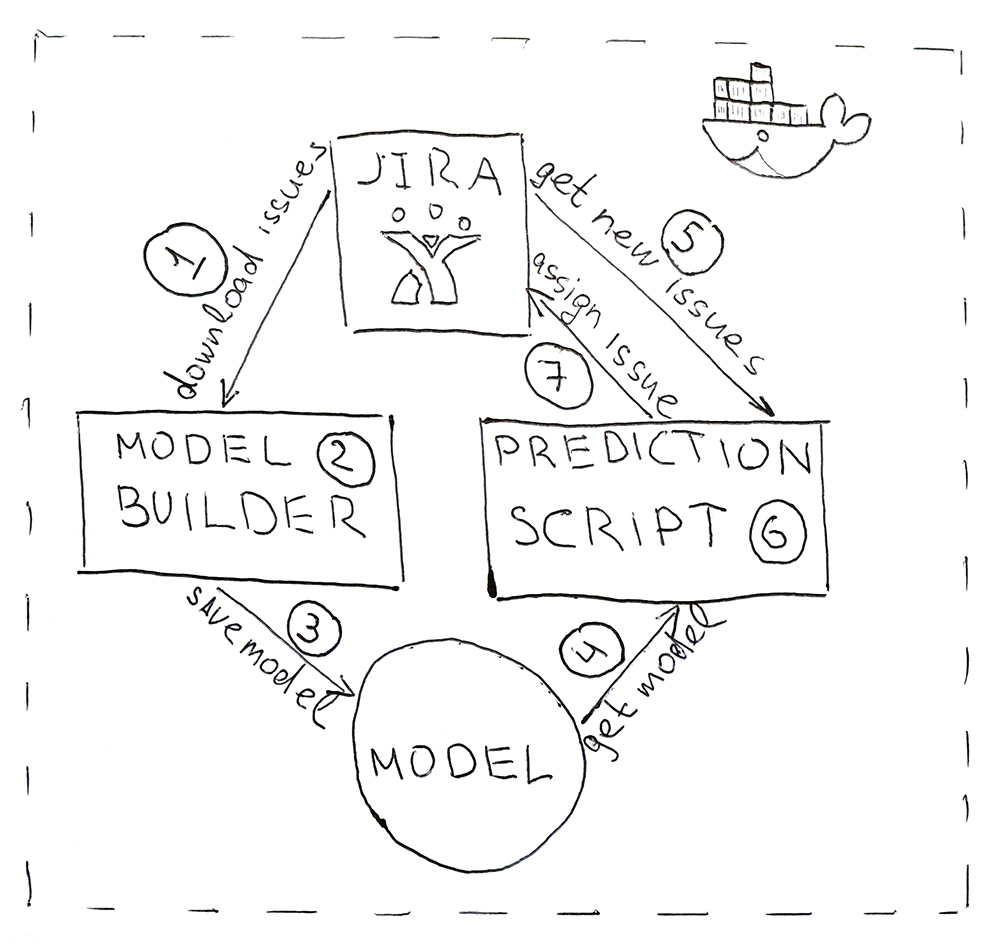
يتكون البرنامج من مخطوطين بيثون. الأول يبني نموذجًا ، والثاني يصنع التنبؤات.
- يوفر Jira واجهة برمجة تطبيقات يمكنك من خلالها تنزيل المهام المكتملة بالفعل (HHS). مرة واحدة يوميًا ، يتم تشغيل البرنامج النصي وتنزيله.
- يتم تحويل البيانات التي تم تنزيلها إلى علامات. أولاً ، يتم ضرب البيانات للتدريب والاختبار وتقديمها إلى نموذج ML للتحقق من الصحة ، لضمان أن الجودة لا تبدأ في الانخفاض من البداية إلى البداية. ثم في المرة الثانية يتم تدريب النموذج على جميع البيانات. العملية كلها تستغرق حوالي 10 دقائق.
- يتم حفظ النموذج المدربين على القرص الصلب. لقد استخدمت الأداة المساعدة dill لتسلسل الكائنات. بالإضافة إلى النموذج نفسه ، من الضروري أيضًا حفظ جميع الكائنات التي تم استخدامها للحصول على الخصائص. هذا هو الحصول على علامات في نفس المكان ل HHS الجديد.
- باستخدام نفس الشبت ، يتم تحميل النموذج في البرنامج النصي للتنبؤ ، والذي يعمل مرة واحدة كل 5 دقائق.
- انتقل إلى Jira للحصول على HHS الجديد.
- نحصل على العلامات ونمررها إلى النموذج ، والذي سيعود لكل فئة من فئات HHS - اسم الفريق.
- نجد الشخص المسؤول عن الفريق ونسند إليه مهمة من خلال واجهة برمجة تطبيقات Jira. يمكن أن يكون اختبارًا ، إذا لم يكن لدى الفريق اختبار ، فسيكون ذلك بمثابة قيادة الفريق.
لجعل البرنامج مناسبًا للنشر وله نفس إصدارات المكتبة كما هو الحال أثناء التطوير ، يتم حزم البرامج النصية في حاوية Docker.
نتيجة لذلك ، أتمتة العملية الروتينية. دقة 76 ٪ ليست كبيرة جدا ، ولكن في هذه الحالة يخطئ ليست حرجة. تجد جميع المهام أداءها ، والأهم من ذلك ، أنك لم تعد بحاجة إلى تشتيت انتباهك عدة مرات يوميًا لفهم جوهر المهام والبحث عن المسؤولين. كل شيء يعمل تلقائيا! الصيحة!