حول المادة
هذا المنشور هو ملاحظة قصيرة للمبرمجين الذين يرغبون في معرفة المزيد حول كيفية معالجة GPU للفروع. يمكنك اعتباره مقدمة لهذا الموضوع. أوصي ببدء النظر في [
1 ] و [
2 ] و [
8 ] للحصول على فكرة عن كيف يبدو نموذج تنفيذ GPU بشكل عام ، لأننا سننظر في تفاصيل منفصلة واحدة فقط. للقراء الفضوليين ، هناك كل الروابط في نهاية المنشور. إذا وجدت أخطاء ، اتصل بي.
محتوى
- حول المادة
- محتوى
- قاموس
- كيف هو جوهر GPU مختلفة عن وحدة المعالجة المركزية الأساسية؟
- ما هو الاتساق / التناقض؟
- أمثلة على معالجة قناع التنفيذ
- ISA الخيالية
- AMD GCN ISA
- AVX512
- كيفية التعامل مع التناقض؟
- مراجع
قاموس
- GPU - وحدة معالجة الرسومات ، GPU
- تصنيف فلين
- SIMD - تعليمات واحدة بيانات متعددة ، دفق تعليمات واحدة ، دفق بيانات متعددة
- SIMT - تعليمات متعددة المواضيع واحد ، تيار تعليمات واحدة ، مواضيع متعددة
- Wave (SIM) - دفق يتم تنفيذه في وضع SIMD
- الخط (الخط) - دفق بيانات منفصل في نموذج SIMD
- SMT - تزامن متعدد الخيوط ، تعدد مؤشرات ترابطية متزامنة (إنتل Hyper-threading) [ 2 ]
- مؤشرات الترابط متعددة مشاركة الموارد الحوسبة الأساسية
- IMT - ترابط متعدد الخيوط ، وتعدد مؤشرات ترابط [ 2 ]
- تشارك مؤشرات الترابط المتعددة إجمالي موارد الحوسبة في kernel ، ولكن واحدة فقط
- BB - كتلة أساسية ، كتلة أساسية - سلسلة خطية من التعليمات مع قفزة واحدة في النهاية
- ILP - مستوى التدريس التوازي ، التوازي في مستوى التعليم [ 3 ]
- ISA - مجموعة هندسة التدريس ، هندسة مجموعة التعليمات
في مشاركتي ، سألتزم بهذا التصنيف المبتكر. يشبه تقريبا كيفية تنظيم GPU الحديثة.
:
GPU -+
|- 0 -+
| |- 0 +
| | |- 0
| | |- 1
| | |- ...
| | +- Q-1
| |
| |- ...
| +- M-1
|
|- ...
+- N-1
* - SIMD
:
+
|- 0
|- ...
+- N-1
أسماء أخرى:
- قد يسمى جوهر CU ، SM ، الاتحاد الأوروبي
- يمكن أن تسمى موجة واجهة الموجة ، مؤشر ترابط الأجهزة (مؤشر ترابط HW) ، الاعوجاج ، سياق
- يمكن استدعاء سطر مؤشر ترابط البرنامج (مؤشر ترابط SW)
كيف هو جوهر GPU مختلفة عن وحدة المعالجة المركزية الأساسية؟
أي جيل حالي من نوى GPU أقل قوة من المعالجات المركزية: ILP / multi-issue [
6 ] والإعداد المسبق [
5 ] ، لا تنبؤات أو تنبؤات بالانتقالات / العوائد. كل هذا ، إلى جانب مخابئ صغيرة ، يحرر مساحة كبيرة إلى حد ما على الرقاقة ، المليئة بالعديد من النوى. آليات تحميل / تخزين الذاكرة قادرة على التعامل مع عرض القناة بترتيب أكبر من الحجم (لا ينطبق هذا على وحدات معالجة الرسومات المدمجة / المتنقلة) من وحدات المعالجة المركزية التقليدية ، ولكن عليك أن تدفع مقابل ذلك مع الكمون العالية. لإخفاء زمن الوصول ، يستخدم GPU SMT [
2 ] - في حين أن موجة واحدة خامدة ، يستخدم آخرون موارد الحوسبة المجانية للنواة. عادةً ما يعتمد عدد الموجات التي تتم معالجتها بواسطة قلب واحد على السجلات المستخدمة ويتم تحديده ديناميكيًا عن طريق تخصيص ملف سجل ثابت [
8 ]. التخطيط لتنفيذ التعليمات هجين - ديناميكي ثابت [
6 ] [
11 4.4]. تحقق نواة SMT المنفذة في وضع SIMD قيم FLOPS عالية (عمليات النقطة العائمة في الثانية ، يتخبط ، عدد عمليات الفاصلة العائمة في الثانية).
 مخطط أسطورة. أسود - غير نشط ، أبيض - نشط ، رمادي - إيقاف ، أزرق - خمول ، أحمر - معلقالشكل 1. 4: 2 تاريخ التنفيذ
مخطط أسطورة. أسود - غير نشط ، أبيض - نشط ، رمادي - إيقاف ، أزرق - خمول ، أحمر - معلقالشكل 1. 4: 2 تاريخ التنفيذتُظهر الصورة محفوظات قناع التنفيذ ، حيث يُظهر المحور السيني الوقت الذي يمتد من اليسار إلى اليمين ، بينما يُظهر المحور ص مُعرّف الخط الذي ينتقل من الأعلى إلى الأسفل. إذا كنت لا تزال لا تفهم هذا ، فعد إلى الرسم بعد قراءة الأقسام التالية.
هذا مثال على كيفية ظهور سجل تنفيذ GPU الأساسي في شكل وهمي: تشترك أربع موجات في عينة واحدة واثنين من وحدات ALU. يقوم مخطط الموجة في كل دورة بإصدار تعليميين من موجتين. عندما تكون الموجة في وضع الخمول عند إجراء الوصول إلى الذاكرة أو تشغيل ALU طويل ، ينتقل المجدول إلى زوج آخر من الأمواج ، بسبب أن ALU مشغولة باستمرار بنسبة 100٪ تقريبًا.
الشكل 2. 4: 1 تاريخ التنفيذمثال مع الحمل نفسه ، ولكن هذه المرة في كل دورة من التعليمات مشاكل موجة واحدة فقط. لاحظ أن ALU الثاني يتضورون جوعًا.
الشكل 3. تاريخ التنفيذ 4: 4هذه المرة ، يتم إصدار أربعة تعليمات في كل دورة. لاحظ أن هناك الكثير من الطلبات إلى ALU ، لذلك تنتظر موجتان دائمًا تقريبًا (في الواقع ، هذا خطأ في خوارزمية التخطيط).
تحديث لمزيد من المعلومات حول صعوبات التخطيط لتنفيذ التعليمات ، انظر [
12 ].
في العالم الواقعي ، تحتوي وحدات معالجة الرسومات (GPU) على تكوينات أساسية مختلفة: يمكن أن يحتوي بعضها على ما يصل إلى 40 موجة لكل قلب و 4 وحدات (وحدات) ، والبعض الآخر لديه 7 موجات ثابتة و 2 وحدة (وحدات). كل هذا يعتمد على العديد من العوامل ويتم تحديده بفضل عملية مضنية لمحاكاة الهندسة المعمارية.
بالإضافة إلى ذلك ، قد يكون للوحدات SIMD الحقيقية عرض أضيق من الموجات التي تخدمها ، ومن ثم يستغرق الأمر عدة دورات لمعالجة تعليمات واحدة صادرة ؛ يسمى العامل طول "الرنين" [
3 ].
ما هو الاتساق / التناقض؟
دعنا نلقي نظرة على مقتطف الشفرة التالي:
مثال 1
uint lane_id = get_lane_id(); if (lane_id & 1) {
نرى هنا مجموعة من التعليمات التي يعتمد مسار التنفيذ فيها على معرف الخط الذي يتم تنفيذه. من الواضح أن الخطوط المختلفة لها معان مختلفة. ماذا سيحدث؟ هناك طرق مختلفة لحل هذه المشكلة [
4 ] ، ولكن في النهاية يفعلون جميعًا نفس الشيء. أحد هذه الأساليب هو قناع التنفيذ ، الذي سأغطيه. وقد استخدم هذا النهج في نفيديا GPUs قبل فولتا وفي وحدات معالجة الرسومات AMD GCN. النقطة الرئيسية في قناع التنفيذ هي أننا نخزن قليلاً لكل سطر في الموجة. إذا كانت بتة تنفيذ السطر المقابل هي 0 ، فلن تتأثر أي سجلات بالتعليمات التالية الصادرة. في الواقع ، يجب ألا يشعر الخط بتأثير التعليمة المنفذة بالكامل ، لأن بت التنفيذ الخاص به هو 0. يعمل هذا على النحو التالي: تنتقل الموجة عبر الرسم البياني لتدفق التحكم في ترتيب البحث العميق ، مما يوفر محفوظات الانتقالات المحددة حتى يتم ضبط البتات. أعتقد أنه من الأفضل إظهار ذلك بمثال.
افترض أن لدينا موجات بعرض 8. فيما يلي شكل قناع التنفيذ الخاص بجزء التعليمات البرمجية:
مثال 1. تاريخ قناع التنفيذ
الآن النظر في أمثلة أكثر تعقيدا:
مثال 2
uint lane_id = get_lane_id(); for (uint i = lane_id; i < 16; i++) {
مثال 3
uint lane_id = get_lane_id(); if (lane_id < 16) {
قد تلاحظ أن التاريخ ضروري. عند استخدام نهج قناع التنفيذ ، عادة ما تستخدم المعدات نوعًا من المكدس. تتمثل الطريقة الساذجة في تخزين مجموعة من المجموعات (exec_mask ، العنوان) وإضافة إرشادات التقارب التي تسترجع القناع من المكدس وتغيير مؤشر التعليمات للموجة. في هذه الحالة ، سيكون للموجة معلومات كافية لتجاوز CFG بالكامل لكل سطر.
فيما يتعلق بالأداء ، لا يستغرق الأمر سوى بضع حلقات لمعالجة تعليمة تدفق التحكم بسبب كل تخزين البيانات هذا. ولا تنس أن المكدس له عمق محدود.
التحديث. بفضل
craigkolb ، قرأت مقالة [
13 ] ، تشير إلى أن تعليمات شوكة / صلة AMD GCN تحدد أولاً مسارًا من عدد أقل من سلاسل العمليات [
11 4.6] ، مما يضمن أن عمق كومة القناع يساوي log2.
التحديث. من الواضح ، أنه من الممكن دائمًا تقريبًا تضمين كل شيء في تظليل / بنية CFG في تظليل ، وبالتالي تخزين السجل الكامل لأقنعة التنفيذ في السجلات والتخطيط لتجاوز / دمج CFG بشكل ثابت [
15 ]. بعد النظر إلى الواجهة الخلفية لـ LLVM لـ AMDGPU ، لم أجد أي دليل على معالجة المكدس الصادرة باستمرار عن المترجم.
دعم الأجهزة وقت التشغيل قناع
الآن نلقي نظرة على هذه الرسوم البيانية تدفق التحكم من ويكيبيديا:
الشكل 4. بعض أنواع الرسوم البيانية التحكم في التدفقما هو الحد الأدنى لمجموعة إرشادات التحكم في القناع التي نحتاجها للتعامل مع جميع الحالات؟ إليك ما يبدو عليه في ISA المعياري الاصطناعي الخاص بي مع التوازي الضمني والتحكم الواضح في القناع والتزامن الديناميكي الكامل لتعارضات البيانات:
push_mask BRANCH_END ; Push current mask and reconvergence pointer pop_mask ; Pop mask and jump to reconvergence instruction mask_nz r0.x ; Set execution bit, pop mask if all bits are zero ; Branch instruction is more complicated ; Push current mask for reconvergence ; Push mask for (r0.x == 0) for else block, if any lane takes the path ; Set mask with (r0.x != 0), fallback to else in case no bit is 1 br_push r0.x, ELSE, CONVERGE
دعنا نلقي نظرة على القضية د).
A: br_push r0.x, C, D B: C: mask_nz r0.y jmp B D: ret
أنا لست متخصصًا في تحليل تدفقات التحكم أو تصميم ISA ، لذلك أنا متأكد من أن هناك حالة لا يمكن لـ ISA المعياري التعامل معها ، لكن هذا ليس مهمًا ، لأن CFG المهيكل يجب أن يكون كافياً للجميع.
التحديث. اقرأ المزيد عن دعم GCN لتعليمات تدفق التحكم هنا: [
11 ] الفصل 4 ، وتنفيذ LLVM هنا: [
15 ].
الاستنتاج:
- الاختلاف - الفرق الناتج في المسارات التي تختارها خطوط مختلفة من نفس الموجة
- الاتساق - لا يوجد تباين.
أمثلة على معالجة قناع التنفيذ
ISA الخيالية
قمت بتجميع مقتطفات الشفرة السابقة في ISA الاصطناعي الخاص بي وتشغيلها على جهاز محاكاة في SIMD32. انظر كيف يتعامل مع قناع التنفيذ.
التحديث. لاحظ أن المحاكاة الاصطناعية تختار دائمًا المسار الحقيقي ، وهذه ليست الطريقة الأفضل.
مثال 1
 الشكل 5. تاريخ المثال 1
الشكل 5. تاريخ المثال 1هل لاحظت منطقة سوداء؟ هذا الوقت يضيع. بعض الخطوط تنتظر الآخرين لإكمال التكرار.
مثال 2
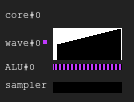 الشكل 6. تاريخ المثال 2
الشكل 6. تاريخ المثال 2مثال 3
mov r0.x, lane_id lt.u32 r0.y, r0.x, u(16)
 الشكل 7. تاريخ المثال 3
الشكل 7. تاريخ المثال 3AMD GCN ISA
التحديث. تستخدم GCN أيضًا معالجة القناع الصريح ، ويمكن الاطلاع على المزيد حول هذا الأمر هنا: [
11 4.x]. قررت أن أعرض بعض الأمثلة من ISA ، وبفضل
ملعب التظليل ، من السهل القيام بذلك. ربما في يوم من الأيام سأجد محاكيًا وأتمكن من الحصول على المخططات.
ضع في اعتبارك أن المترجم ذكي ، بحيث يمكنك الحصول على نتائج أخرى. حاولت خداع المحول البرمجي حتى لا يعمل على تحسين فروعي من خلال وضع حلقات مؤشر ثم تنظيف رمز المجمّع ؛ أنا لست متخصصًا في GCN ، لذا قد يتم تخطي بضع
nop مهمة.
لاحظ أيضًا أنه لا يتم استخدام إرشادات S_CBRANCH_I / G_FORK و S_CBRANCH_JOIN في هذه الأجزاء لأنها بسيطة ولا يدعمها المترجم. لذلك ، لسوء الحظ ، لم يكن من الممكن التفكير في كومة الأقنعة. إذا كنت تعرف كيفية إجراء معالجة مكدس مشكلة برنامج التحويل البرمجي ، فيرجى إخبارنا بذلك.
التحديث. تحقق من هذا
@ SiNGUL4RiTY الحديث عن تنفيذ تدفق التحكم
الموجه في LLVM الخلفية المستخدمة من قبل AMD.
مثال 1
مثال 2
مثال 3
AVX512
التحديث. أوضحت ليtom_forsyth أن امتداد AVX512 يحتوي أيضًا على معالجة قناع واضحة ، لذا إليك بعض الأمثلة. يمكن العثور على مزيد من التفاصيل حول هذا في [
14 ] ، 15.x و 15.6.1. ليس بالضبط GPU ، ولكن لا يزال لديه SIMD16 حقيقي مع 32 بت. تم إنشاء مقتطفات الشفرة باستخدام godbolt ISPC (–target = avx512knl-i32x16) وتم إعادة تصميمها بشكل كبير ، لذا فقد لا تكون صحيحة بنسبة 100٪.
مثال 1
مثال 2
مثال 3
كيفية التعامل مع التناقض؟
حاولت إنشاء توضيح بسيط ولكنه كامل لكيفية نشوء عدم الكفاءة من خلال الجمع بين الخطوط المتباعدة.
تخيل قطعة بسيطة من الكود:
uint thread_id = get_thread_id()
لنقم بإنشاء 256 موضوعًا وقياس وقت تنفيذها:
الشكل 8. مدة المواضيع المتباينةالمحور س هو معرف دفق البرنامج ، المحور ص هو دورات الساعة ؛ تُظهر الأعمدة المختلفة مقدار الوقت المهدر عند تجميع التدفقات بأطوال موجية مختلفة مقارنة بالتنفيذ المفرد.
وقت تشغيل الموجة يساوي وقت التشغيل الأقصى بين الخطوط الموجودة فيه. يمكنك أن ترى أن الأداء ينخفض بشكل كبير بالفعل مع SIMD8 ، والتوسع الإضافي يجعله أسوأ قليلاً.
الشكل 9. وقت التشغيل من المواضيع متسقةيتم عرض نفس الأعمدة في هذا الشكل ، ولكن في هذه المرة يتم فرز عدد التكرارات حسب معرفات الدفق ، أي ، يتم نقل التدفقات ذات عدد مماثل من التكرار إلى موجة واحدة.
في هذا المثال ، قد يتم تسريع التنفيذ بمقدار النصف تقريبًا.
بالطبع ، المثال بسيط للغاية ، لكنني آمل أن تفهم النقطة: التناقض في التنفيذ ينبع من تباين البيانات ، لذلك يجب أن تكون CFGs بسيطة وأن تكون البيانات متسقة.
على سبيل المثال ، إذا كنت تكتب جهاز تتبع للأشعة ، فقد تستفيد من تجميع الأشعة بنفس الاتجاه والموضع ، لأنها على الأرجح ستخضع لنفس العقد في BVH. انظر [
10 ] والمقالات الأخرى ذات الصلة لمزيد من التفاصيل.
تجدر الإشارة أيضًا إلى أن هناك تقنيات للتعامل مع التناقضات على مستوى الأجهزة ، على سبيل المثال ، Dynamic Warp Formation [
7 ] والتنفيذ المتوقع للفروع الصغيرة.
مراجع
[1]
رحلة عبر خط أنابيب الرسومات[2]
كيفون فتاهاليان: الحوسبة المتوازية[3]
هندسة الكمبيوتر والنهج الكمي[4]
التقارب بين كومة SIMT بأقل تكلفة[5]
تشريح التسلسل الهرمي للذاكرة GPU من خلال وضع العلامات المصغرة[6]
تشريح بنية معالج الجرافيك NVIDIA Volta عبر ترميز Microbenchmarking[7]
التكوين الديناميكي للالتفاف والجدولة لكفاءة تدفق التحكم GPU[8]
موريزيو سيراتو: GPU Architectures[9]
لعبة محاكاة GPU[10]
تقليل تباعد الفروع في برامج GPU[11]
"Vega" مجموعة تعليمات الهندسة المعمارية[12]
جوشوا Barczak: محاكاة تنفيذ شادر ل GCN[13]
ناقلات المماس: انحدار على الاختلاف[14]
دليل مطور Intel 64 و IA-32 ArchitecturesSoftware[15]
تحويل التحكم في التدفق المتباين لتطبيقات SIMD