تحية ، الخبروفيت! تم إعداد ترجمة المقالة التالية خصيصًا لطلاب
دورة البنية التحتية لمنصة Kubernetes ، والتي ستبدأ الدراسة غدا. لنبدأ.

الفحص الذاتي في Kubernetes
يتيح لك القياس التلقائي زيادة أعباء العمل وتقليلها تلقائيًا حسب استخدام الموارد.
Kubernetes autoscaling له بعدان:
- Cluster Autoscaler ، المسؤولة عن تحجيم العقد ؛
- أفقي Pod Autoscaler (HPA) ، الذي يقيس تلقائيا عدد الموقد في نشر أو مجموعة النسخ المتماثلة.
يمكن استخدام التحجيم التلقائي للكتلة مع التحجيم التلقائي للموقد الأفقي للتحكم ديناميكيًا في موارد الحوسبة ودرجة التزامن النظام المطلوبة للامتثال لاتفاقات مستوى الخدمة (SLAs).
تعتمد عملية التعيين التلقائي للكتلة اعتمادًا كبيرًا على إمكانيات موفر البنية التحتية السحابية التي تستضيف المجموعة ، ويمكن أن تعمل HPA بشكل مستقل عن مزود IaaS / PaaS.
تطوير HPA
خضع التحجيم التلقائي للموقد الأفقي لتغيرات كبيرة منذ إدخال Kubernetes v1.1. الإصدار الأول من HPA تحجيم القلوب بناءً على استهلاك وحدة المعالجة المركزية المقاسة ، وبعد ذلك بناءً على استخدام الذاكرة. قدم Kubernetes 1.6 واجهة برمجة تطبيقات جديدة تسمى Custom Metrics ، والتي وفرت وصول HPA إلى المقاييس المخصصة. أضاف Kubernetes 1.7 مستوى التجميع الذي يسمح لتطبيقات الجهات الخارجية بتوسيع واجهة برمجة تطبيقات Kubernetes من خلال التسجيل كوظائف إضافية لـ API.
بفضل واجهة برمجة تطبيقات Custom Metrics ومستوى التجميع ، يمكن لأنظمة المراقبة مثل Prometheus توفير مقاييس خاصة بالتطبيق لوحدة التحكم HPA.
يتم تطبيق القياس التلقائي للموقد الأفقي كحلقة تحكم تستعلم بشكل دوري واجهة برمجة تطبيقات Resource Metrics (API قياسات المورد) للمقاييس الرئيسية ، مثل وحدة المعالجة المركزية واستخدام الذاكرة ، وواجهة برمجة التطبيقات للقياسات المخصصة (API للقياسات المخصصة) لمقاييس تطبيق محددة.
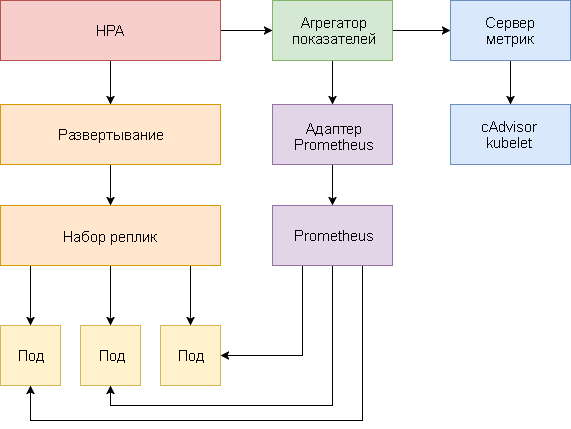
يوجد أدناه دليل تفصيلي لتكوين HPA v2 لـ Kubernetes 1.9 والإصدارات الأحدث.
- تثبيت Metrics Server الوظيفة الإضافية ، والذي يوفر قياسات المفتاح.
- قم بتشغيل التطبيق التجريبي لمعرفة كيفية عمل التحجيم التلقائي في الموقد استنادًا إلى استخدام وحدة المعالجة المركزية والذاكرة.
- نشر بروميثيوس وخادم API المخصص. تسجيل خادم API مخصص على مستوى التجميع.
- قم بتكوين HPA باستخدام مقاييس مخصصة يوفرها التطبيق التجريبي.
قبل أن تبدأ ، يجب عليك تثبيت الإصدار 1.8 من Go (أو الأحدث) واستنساخ
مستودع k8s-prom-hpa في
GOPATH :
cd $GOPATH git clone https:
1. إعداد خادم المقاييس
خادم Kubernetes
Metrics Server هو مجمع بيانات استخدام موارد نظام المجموعة الذي يستبدل
Heapster . يقوم خادم المقاييس بجمع معلومات استخدام وحدة المعالجة المركزية والذاكرة للعقد
kubernetes.summary_api من
kubernetes.summary_api . واجهة برمجة تطبيقات الملخص هي واجهة برمجة تطبيقات فعالة من حيث الذاكرة لنقل مقاييس بيانات Kubelet / cAdvisor إلى الخادم.
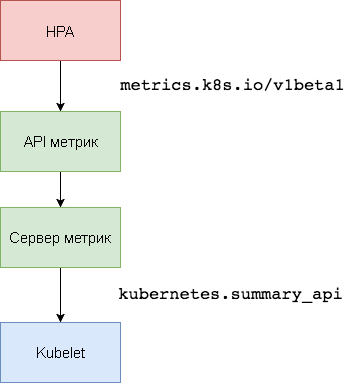
في الإصدار الأول من HPA ، كانت هناك حاجة إلى مجمع Heapster للحصول على وحدة المعالجة المركزية والذاكرة. في HPA v2 و Kubernetes 1.8 ، لا يتطلب الأمر سوى خادم متري مع تمكين
horizontal-pod-autoscaler-use-rest-clients الأفقيين. يتم تمكين هذا الخيار افتراضيًا في Kubernetes 1.9. يأتي GKE 1.9 مع خادم مقاييس مثبت مسبقًا.
قم بتوسيع خادم المقاييس في مساحة اسم
kube-system :
kubectl create -f ./metrics-server
بعد دقيقة واحدة ، سيبدأ
metric-server في نقل البيانات حول استخدام وحدة المعالجة المركزية والذاكرة بواسطة العقد والقرون.
عرض مقاييس العقدة:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
عرض مؤشرات معدل ضربات القلب:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2. التحجيم التلقائي على أساس استخدام وحدة المعالجة المركزية والذاكرة
لاختبار القياس التلقائي الأفقي للموقد (HPA) ، يمكنك استخدام تطبيق ويب صغير يستند إلى Golang.
قم بتوسيع
podinfo في مساحة الاسم
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
اتصل بـ
podinfo باستخدام خدمة NodePort على
http://<K8S_PUBLIC_IP>:31198 .
حدد HPA التي ستخدم ما لا يقل عن نسختين متماثلتين وحجم إلى عشرة نسخ متماثلة إذا تجاوز متوسط استخدام وحدة المعالجة المركزية 80٪ أو إذا كان استهلاك الذاكرة أعلى من 200 ميجابايت:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi
إنشاء HPA:
kubectl create -f ./podinfo/podinfo-hpa.yaml
بعد بضع ثوانٍ ، ستتصل وحدة تحكم HPA بالخادم المتري وتتلقى معلومات حول استخدام وحدة المعالجة المركزية والذاكرة:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
لزيادة استخدام وحدة المعالجة المركزية ، قم بإجراء اختبار تحميل باستخدام rakyll / hey:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http:
يمكنك مراقبة أحداث HPA كما يلي:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
أزل podinfo مؤقتًا (سيتعين عليك إعادة نشره في إحدى الخطوات التالية في هذا الدليل).
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3. إعداد خادم القياسات المخصصة
للتحجيم استنادًا إلى المقاييس المخصصة ، يلزم وجود مكونين. الأولى - قاعدة بيانات سلسلة وقت
بروميثيوس - تجمع مقاييس التطبيق وتحفظها.
يكمل المكون الثاني -
k8s-prometheus-adapter - Kubernetes API المخصص للقياسات مع المقاييس التي يوفرها المنشئ.
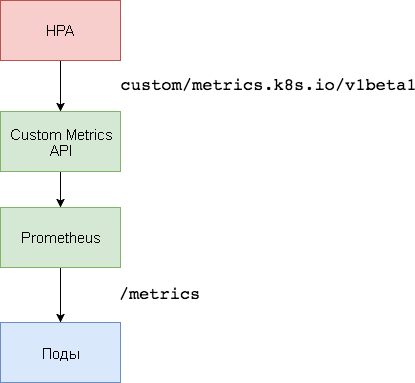
يتم استخدام مساحة اسم مخصصة لنشر Prometheus والمحول.
إنشاء مساحة اسم
monitoring :
kubectl create -f ./namespaces.yaml
قم بتوسيع Prometheus v2 في مساحة اسم
monitoring :
kubectl create -f ./prometheus
قم بإنشاء شهادات TLS المطلوبة لمحول Prometheus:
make certs
نشر محول Prometheus لواجهة برمجة التطبيقات للقياسات المخصصة:
kubectl create -f ./custom-metrics-api
الحصول على قائمة المقاييس الخاصة المقدمة من قبل بروميثيوس:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
ثم استخراج بيانات استخدام نظام الملفات لجميع القرون في مساحة اسم
monitoring :
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4. لصناعة السيارات في التوسع على أساس مقاييس مخصصة
قم
podinfo خدمة NodePort
podinfo ونشرها على مساحة الاسم
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
podinfo تطبيق
podinfo بتمرير
http_requests_total المتري الخاص. سيقوم محول Prometheus بإزالة اللاحقة
_total ووضع علامة على هذا القياس كعداد.
احصل على إجمالي عدد الاستعلامات في الثانية من واجهة برمجة تطبيقات القياسات المخصصة:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] }
الحرف
m يعني
milli-units ، لذلك ، على سبيل المثال ،
901m هو 901 مللي ثانية.
قم بإنشاء HPA لتوسيع نشر podinfo إذا كان عدد الطلبات يتجاوز 10 طلبات في الثانية:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10
قم بتوسيع
podinfo HPA في مساحة الاسم
default :
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
بعد بضع ثوانٍ ، ستحصل HPA على قيمة
http_requests من واجهة برمجة التطبيقات للقياسات:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m
قم بتطبيق الحمل لخدمة podinfo مع 25 طلبًا في الثانية:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http:
بعد بضع دقائق ، سيبدأ HPA في توسيع نطاق النشر:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
مع العدد الحالي للطلبات في الثانية الواحدة ، لن يصل النشر أبدًا إلى 10 قرون كحد أقصى. ثلاثة نسخ متماثلة كافية للتأكد من أن عدد الطلبات في الثانية لكل جراب أقل من 10.
بعد الانتهاء من اختبارات الحمل ، ستقوم HPA بتقليل نطاق النشر إلى العدد الأولي من النسخ المتماثلة:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
ربما لاحظت أن أداة القياس التلقائي لا تستجيب فورًا للتغيرات في المقاييس. بشكل افتراضي ، تتم مزامنتها كل 30 ثانية. بالإضافة إلى ذلك ، يحدث التحجيم فقط في حالة عدم وجود زيادة أو نقصان في أعباء العمل خلال آخر 3-5 دقائق. هذا يساعد على منع القرارات المتعارضة ويترك الوقت للاتصال المتسلق التلقائي الكتلة.
استنتاج
لا تستطيع جميع الأنظمة فرض التزام SLA استنادًا إلى وحدة المعالجة المركزية أو استخدام الذاكرة (أو كليهما). تحتاج معظم خوادم الويب وخوادم الهواتف المحمولة التي تتعامل مع طفرات المرور إلى إجراء الترميز التلقائي بناءً على عدد الطلبات في الثانية.
بالنسبة لتطبيقات ETL (من تحميل استخراج اللغة الإنجليزية - "الاستخراج والتحويل والتحميل") ، يمكن تشغيل القياس التلقائي ، على سبيل المثال ، عندما يتم تجاوز طول عتبة قائمة انتظار المهمة المحدد.
في جميع الحالات ، تتيح لك تطبيقات الأجهزة التي تستخدم بروميثيوس وتسليط الضوء على المؤشرات اللازمة لإجراء الفحص الذاتي تحسين التطبيقات لتحسين معالجة طفرات المرور وضمان توافر البنية التحتية بشكل كبير.
الأفكار والأسئلة والتعليقات؟ انضم إلى المناقشة في
Slack !
هنا هذه المواد. نحن في انتظار تعليقاتكم ونراكم في
الدورة !