في المدرسة ، عندما حللنا المعادلات أو نظرنا في الصيغ ، حاولنا تقليلها عدة مرات أولاً ، على سبيل المثال ، Z = X - (Y + X) تقليل Z = X - (Y + X) إلى Z = -Y . في المجمعات الحديثة ، هذه مجموعة فرعية من ما يسمى بالتحسينات ثقب الباب ، والتي ، من خلال الحديث تقريبا ، مجموعة من الأنماط ، ونحن تقليل التعبيرات ، واستبدال التعليمات بتعليمات أسرع لمعالج معين ، الخ في هذه المقالة ، قمت بتجميع مجموعة من هذه التحسينات التي تم العثور عليها في مصادر LLVM و GCC و .NET Core (CoreCLR).
لنبدأ بأمثلة بسيطة:
X * 1 => X -X * -Y => X * Y -(X - Y) => Y - XX * Z - Y * Z => Z * (X - Y)
تحقق من المثال الأخير في C ++ وفي C #:
int Test(int x, int y, int z) { return x * z - y * z;
وانظر إلى المجمّع من Clang (LLVM) و GCC و MSVC و .NET Core:

جميع برامج التحويل البرمجي C ++ الثلاثة (GCC و Clang و MSVC) خفضت عملية الضرب واحدة (نرى تعليمة imul واحدة فقط). C # لم يفعل هذا مع RyuJIT ، لكن لا تتعجل لتوبيخه من أجل ذلك ، إنه فقط أن فئة التحسينات هذه متوفرة بتكوين محدود هناك. لجعلك تفهم ، فإن تنفيذ تحويل InstCombine بأكمله في LLVM يستغرق أكثر من 30 ألف سطر من التعليمات البرمجية (+ 20k أسطر على DAGCombiner.cpp) ، علاوة على ذلك ، غالباً ما يؤدي هذا التحول إلى تجميع طويل. بالمناسبة ، الموقع المسؤول عن هذا التحسين موجود. يحتوي مجلس التعاون الخليجي على خط المشترك الرقمي (DSL) الخاص الذي يصف فتحة التحسين ، فيما يلي مقتطف ).
قررت ، من أجل المقالة ، محاولة تنفيذ هذا التحسين في C # JIT (اضغط على البيرة الخاصة بي):
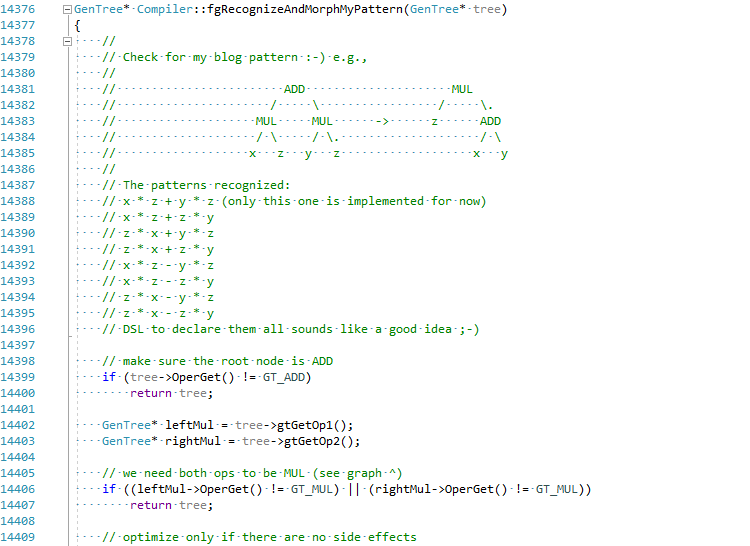
يمكن رؤية الالتزام الكامل هنا EgorBo / coreclr . دعنا نتحقق من تحسني الآن (في Visual Studio 2019 + Disasmo:
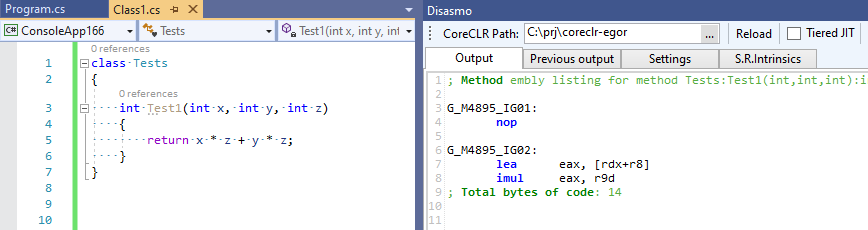
إنه يعمل! lea + imul بدلاً من imul imul add .
دعنا نعود إلى C ++ وتتبع هذا التحسين في Clang. للقيام بذلك ، اطلب من clang أن تعطينا LLVM IR الأولي عبر -emit-llvm -g0 ، ثم -emit-llvm -g0 إلى LLVM إلى المُحسِّن ، باستخدام -O2 -print-before-all -print-after-all أجل التقاط اللحظة الدقيقة للتحول يزيل الضرب من مجموعة -O2 (كل هذا يمكن رؤيته على الموارد الرائعة godbolt.org ):
; *** IR Dump Before Combine redundant instructions *** define dso_local i32 @_Z5Case1iii(i32, i32, i32) { %4 = mul nsw i32 %0, %2 %5 = mul nsw i32 %1, %2 %6 = sub nsw i32 %4, %5 ret i32 %6 } ; *** IR Dump After Combine redundant instructions *** define dso_local i32 @_Z5Case1iii(i32, i32, i32) { %4 = sub i32 %0, %1 %5 = mul i32 %4, %2 ret i32 %5 }
يمكنك أيضًا الاستمتاع على godbolt باستخدام أدوات LLVM - opt (optimizer) و llc (لتجميع LLVM IR إلى asm):

العودة إلى الأمثلة. لقد وجدت هذا المثال الجميل في دول مجلس التعاون الخليجي.
X == C - X => false if C is odd
وهذا صحيح: إذا كان 4 == 8 - 4 . ولكن إذا كنت تكتب أي رقم غريب بدلاً من 8 ، فلن تتمكن من العثور على علامة X بحيث تتحقق المساواة:
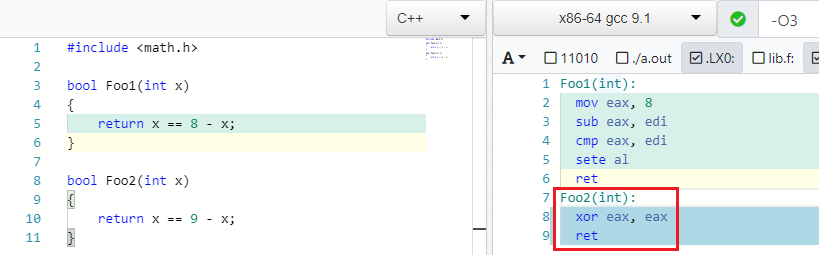
IEEE754 الإضرابات العودة
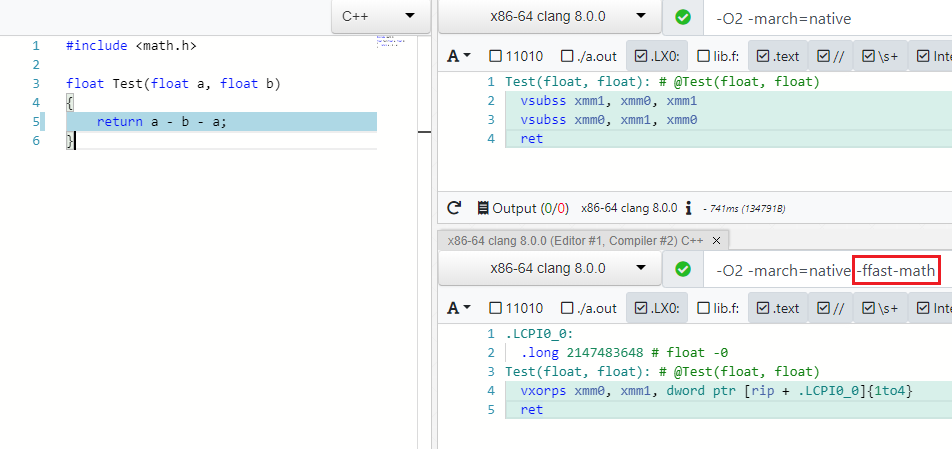
تعمل العديد من التحسينات لأنواع مختلفة من البيانات ، على سبيل المثال ، byte ، int ، unsigned ، float ، double . مع هذا الأخير ، الأمور ليست بهذه البساطة ويتم التعامل مع التحسينات من خلال مواصفات IEEE754 ، والتي ستصبح مجنونة إذا قمت بتقليل A - B - A إلى - -B أو (A * B) * C إعادة ترتيبها إلى A * (B * C) t. أ. العمليات ليست النقابي. ولكن هناك وضعًا خاصًا في برامج التحويل البرمجي الحديثة التي تتيح لك إهمال المواصفات والقيم الحدودية (NaN و + -Inf و + -0.0) في مثل هذه الحالات وأداء تحسينات بأمان - هذا هو Fast Math (يمكن العثور على طلب العلاقات العامة (My PR) لإضافة مثل هذا الوضع إلى C # هنا ).
كما ترون في -ffast-math لم يعد هناك اثنان vsubss :
بالإضافة إلى التعبيرات ، يأخذ المُحسِّنون أيضًا في الاعتبار التوفيق بين الدوال الرياضية والرياضيات من math.h ، على سبيل المثال ، منتج وحدات الرقم X يساوي منتج الرقم X:
abs(X) * abs(X) => X * X
الجذر التربيعي هو دائما إيجابية:
sqrt(X) < Y => false, if Y is negative. sqrt(X) < 0 => false
لماذا تحسب الجذر ، إذا كان من الممكن في مرحلة التجميع حساب مربع الثابت على اليمين؟:
sqrt(X) > C => X > C * C

المزيد من عمليات الجذر:
sqrt(X) == sqrt(Y) => X == Y sqrt(X) * sqrt(X) => X sqrt(X) * sqrt(Y) => sqrt(X * Y) logN(sqrt(X)) => 0.5*logN(X)
بعض الرياضيات أكثر المدرسة:
expN(X) * expN(Y) -> expN(X + Y)
والتحسين المفضل لدي:
sin(X) / cos(X) => tan(X)

الكثير من عمليات البت والعمليات المنطقية المملة:
((a ^ b) | a) -> (a | b) (a & ~b) | (a ^ b) --> a ^ b ((a ^ b) | a) -> (a | b) (X & ~Y) |^+ (~X & Y) -> X ^ Y A - (A & B) into ~B & A X <= Y - 1 equals to X < Y A < B || A >= B -> true ... !
تحسينات المستوى المنخفض
هناك مجموعة من التحسين ، والتي لا تبدو للوهلة الأولى منطقية مع t.z. علماء الرياضيات ، ولكن أكثر ودية للحديد.
X / 2 => X * 0.5
استبدال القسمة بضرب:

تشغيل الضرب الأسطول عادة ما يكون أفضل خصائص زمن الوصول / الإنتاجية من الانقسام. على سبيل المثال ، فيما يلي خيارات Intel Haswell:

في الوضع غير السريع للرياضيات ، يمكن استخدامه فقط إذا كان الثابت قوة لاثنين.
بالمناسبة ، حاولت مؤخرًا إضافة هذا التحسين في C #. أي على سبيل المثال ، إذا كنت بحاجة إلى فتح ملف بنموذج ثلاثي الأبعاد وتقليل جميع الإحداثيات بمقدار 10 مرات ، فسوف تتعامل * 0.1 مع هذا أسرع بنسبة 20-100 ٪ ، مما قد يكون مهمًا.
نفس الأساس المنطقي ل:
X * 2 => X + X
المقارنة مع الصفر ( test ) أفضل من المقارنة مع الوحدة ( cmp ) - بلدي العلاقات العامة للتفاصيل هو dotnet / coreclr # 25458 :
X >= 1 => X > 0 X < 1 => X <= 0 X <= -1 => X >= 0 X > -1 => X >= 0
وكيف تحب هذا:
pow(X, 0.5) => sqrt(x) pow(X, 0.25) => sqrt(sqrt(X)) pow(X, 2) => X * X ; 1 mul pow(X, 3) => X * X * X ; 2 mul

ما رأيك ، كم عدد عمليات الضرب التي تحتاجها لحساب mod(X, 4) أو X * X * X * X ؟
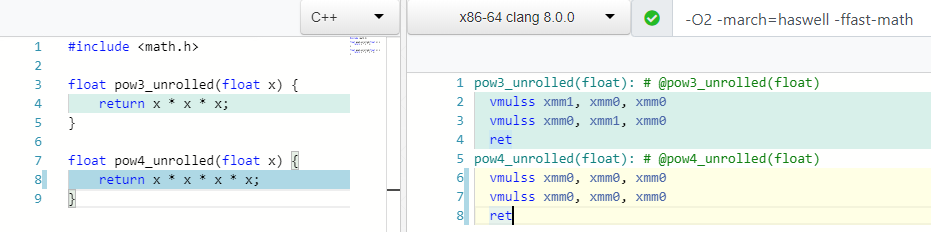
اثنين! وكذلك لحساب الدرجة الثالثة ، وفي الحالة 4 نستخدم سجل واحد فقط xmm0 .
تدعم العديد من المعالجات تعليمات خاصة (FMA) ، والتي تسمح لك بإجراء الضرب والإضافة في وقت واحد ، مع الحفاظ على الدقة أثناء الضرب:
X * Y + Z => fmadd(X, Y, Z)

هناك مثالان آخران من الأمثلة المفضلة لدي هما إمكانية طي بعض الخوارزميات في تعليمة واحدة (إذا كان المعالج يدعمها):
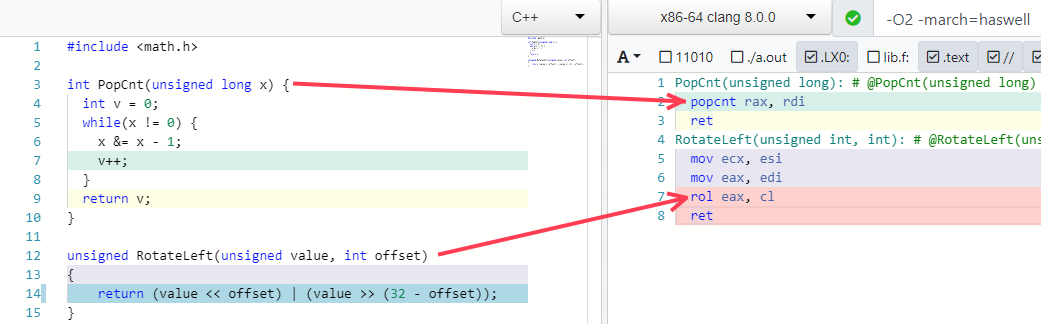
الفخاخ الأمثل
أعتقد أن الجميع يفهم أنه لا يمكنك التعجيل وتقليل التعبيرات لثلاثة أسباب:
- يمكنك كسر الشفرة في بعض القيم الحدودية ، أو تجاوز السعة ، أو الآثار الجانبية المخفية ، إلخ. ... يحتوي Bugzilla LLVM على العديد من أخطاء InstCombine.
- من الناحية المثالية ، يجب أن تعمل التحسينات معًا في تسلسل محدد.
- قد يتم استخدام التعبير أو أجزاء منه التي تريد تقليلها في مكان آخر وسيؤدي تقليلها إلى تدهور الأداء.
دعنا فقط نلقي نظرة على مثال للفقرة الأخيرة (تجسست في مقالة "الاتجاهات المستقبلية لتحسين المترجمين" ).
تخيل أن لدينا هذا الكود:
int Foo1(int a, int b) { int na = -a; int nb = -b; return na + nb; }
نحن بحاجة إلى القيام بثلاث عمليات: 0 - a ، 0 - b ، و na + nb . ولكن محسن بالنسبة لنا يقلل هذا إلى اثنين - return -(a + b); :
define dso_local i32 @_Z4Foo1ii(i32, i32) { %3 = add i32 %0, %1 ; a + b %4 = sub i32 0, %3 ; 0 - %3 ret i32 %4 }
الآن تخيل أننا نحتاج إلى كتابة القيم المتوسطة na و nb للمتغيرات العالمية:
int x, y; int Foo2(int a, int b) { int na = -a; int nb = -b; x = na; y = nb; return na + nb; }
لا يزال المُحسّن يجد هذا النمط ويزيل العمليات غير الضرورية (من وجهة نظره) 0 - a و 0 - b ، ولكن في الحقيقة اتضح أنها ضرورية! نكتب نتائج هذه العمليات "غير الضرورية" في المتغيرات العالمية! هذا يؤدي إلى هذا الكود:
define dso_local i32 @_Z4Foo2ii(i32, i32) { %3 = sub nsw i32 0, %0 ; 0 - a %4 = sub nsw i32 0, %1 ; 0 - b store i32 %3, i32* @x, align 4, !tbaa !2 store i32 %4, i32* @y, align 4, !tbaa !2 %5 = add i32 %0, %1 ; a + b %6 = sub i32 0, %5 ; 0 - %5 ret i32 %6 }
أربع عمليات رياضية بدلا من ثلاثة! لقد أخفقنا مُحسِّننا ولم يكن مقتنعًا بأن التعبيرات الوسيطة التي قام بتحسينها كانت لا تزال مطلوبة من قبل شخص ما. الآن دعونا نلقي نظرة على إخراج C # RuyJIT ، حيث لا يوجد مثل هذا التحسين الذكي:
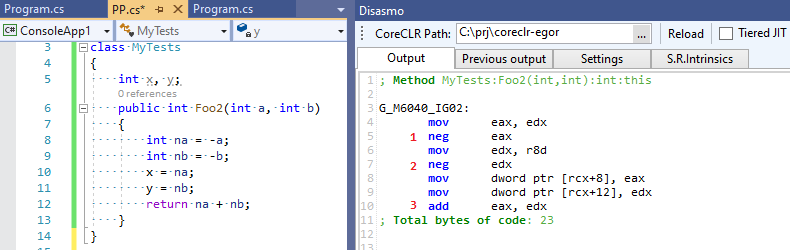
ثلاث عمليات بدلاً من أربعة - تحولت C # إلى أن تكون أسرع من C ++ :-)!.
هل هذه التحسينات مطلوبة؟
أنت لا تعرف أبدًا كيف سيبدو الكود بعد أن يقوم المحول البرمجي بتضمين كل ما في وسعها وما إذا كان يمكن طيها بشكل مستمر أو نسخها أو نشرها أو تطويرها أو استخدامها. - صورة مختلفة تماما سوف تفتح له. لا يرتبط LLVM IR و .NET IL بلغة برمجة محددة ، ولا يمكنك التأكد من أن PL / محددة جديدة يمكنها ترجمة نفسها بشكل فعال إلى IR. حسنًا ، لماذا تتحدث عن ذلك إذا كان يمكنك اختبار أداء InstCombine وإيقاف تشغيله في تطبيق معين ؛-). من غير المرجح أن يكون هذا فرقًا مثيرًا للإعجاب ، ولكن من يدري.
ماذا عن C #؟
كما قلت ، غالبًا ما تكون تحسينات التعبيرات التي درسناها غائبة في C #. ولكن عندما أقول C # أعني أن وقت التشغيل الأكثر شعبية هو CoreCLR و RyuJIT. لكن إلى جانب CoreCLR ، هناك أوقات تشغيل أخرى ، بما في ذلك تلك التي تستخدم LLVM كخلفية: Mono (انظر تغريدة ) ، و Unity Burst ، و IL2CPP (عبر clang) و LILLC - هنا يمكنك مقارنة نتائج C ++ بأمان مع clang. الرجال من الوحدة حتى إعادة كتابة رمز C ++ الداخلية في C # دون أي خسارة في الأداء ، دليل !
فيما يلي بعض فتحات التحسين التي يمكن العثور عليها في ملف morph.cpp في شفرة مصدر morph.cpp من التعليقات (من الواضح أن هناك أكثر قليلاً):
*(&X) => X X % 1 => 0 X / 1 => X X % Y => X - (X / Y) * Y X ^ -1 => ~x X >= 1 => X > 0 X < 1 => X <= 0 X + 1 == C2 => X == C2 - C1 ((X + C1) + C2) => (X + (C1 + C2)) ((X + C1) + (Y + C2)) => ((X + Y) + (C1 + C2))
يمكن العثور على عدد قليل آخر في lowering.cpp (المستوى المنخفض) ، ولكن بشكل عام ، من الواضح أن RyuJIT يخسر هنا إلى المترجمين C ++. لدى RyuJIT أولويات مختلفة قليلاً - قبل ظهور Tiering Compilation ، كان يحتاج إلى توفير سرعة تجميع مقبولة ، وهو ما يفعله بشكل جيد للغاية على عكس مجمعي C ++ (تذكر حول مسار InstCombine المكون من 30 سطرًا في LLVM وقراءة المنشور المثير للاهتمام بشكل عام " الحديث "C ++ Lamentations" وهو أكثر فائدة لتطوير التحسينات في مجال إضفاء الطابع الافتراضي على المكالمة ، والقضاء على الملاكمة والتخصيصات (نفس تخصيص Stack Object ) ، كل هذا ، بكل تأكيد ، أكثر أهمية بكثير من تقليل تقسيم جيب الجيب إلى جيب التمام.
ربما مع ظهور Tiering Compilation ، مع مرور الوقت ، سيكون هناك العديد من التحسينات الجديدة غير الحاسمة لوقت التجميع للمستوى 1 أو حتى المستوى 2. ربما حتى مع واجهة برمجة تطبيقات الوظيفة الإضافية و DSL - لقد قرأت للتو هذه المقالة ، حيث أضاف Prathamesh Kulkarni تحسين التعبير في دول مجلس التعاون الخليجي في بضع سطور DSL فقط:
(simplify (plus (mult (SIN @0) (SIN @0)) (mult (COS @0) (COS @0))) (if (flag_unsafe_math_optimizations)1. { build_one_cst (TREE_TYPE (@0))
لهذا التعبير من كتاب الرياضيات ؛-):
cos^2(X) + sin^2(X) equals to 1
روابط مفيدة
- "الاتجاهات المستقبلية لتحسين المترجمين" ، Nuno P. Lopes و John Regehr
- "كيف LLVM يحسن وظيفة" ، جون Regehr
- "الذكاء المدهش للمترجمين الحديثين" دانيال لومير
- "إضافة ثقب الباب الأمثل لدول مجلس التعاون الخليجي" ، Prathamesh Kulkarni
- "1. C ++ ، C # و Unity" ، لوكاس ماير
- "الحديث + C الرثاء" ، أراس Pranckevičius
- "تحسينات على نحو صحيح من خلال ثقب الباب مع Alive" و Nuno P. Lopes و David Menendez و Santosh Nagarakatte و John Regehr