يمكن العثور على الدورة الكاملة باللغة الروسية على هذا الرابط .
دورة اللغة الإنجليزية الأصلية متاحة على هذا الرابط .

ومن المقرر محاضرات جديدة كل 2-3 أيام.
محتوى
- مقابلة مع سيباستيان ترون
- مقدمة
- الكلاب والقطط مجموعة البيانات
- صور من مختلف الأحجام
- الصور الملونة. الجزء 1
- الصور الملونة. الجزء 2
- عملية الالتواء على الصور الملونة
- تشغيل أخذ العينات من خلال الحد الأقصى للقيمة في الصور الملونة
- CoLab: القطط والكلاب
- Softmax و السيني
- تفتيش
- تمديد الصورة
- استثناء
- CoLab: الكلاب والقطط. تكرار
- تقنيات أخرى لمنع إعادة التدريب
- التمرين: تصنيف صورة ملونة
- النتائج
Softmax و السيني
استخدمنا في CoLab الأخير التدريب العملي على بنية الشبكة العصبية التلافيفية التالية:
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
يرجى ملاحظة أن الطبقة الأخيرة (المصنف الخاص بنا) تتكون من طبقة متصلة بالكامل مع اثنين من الخلايا العصبية softmax تنشيط softmax :
tf.keras.layers.Dense(2, activation='softmax')
هناك طريقة شائعة أخرى لحل مشكلات التصنيف الثنائي وهي استخدام المصنف ، والذي يتكون من طبقة متصلة تمامًا مع sigmoid تنشيط الخلايا العصبية sigmoid تنشيط sigmoid :
tf.keras.layers.Dense(1, activation='sigmoid')
كلا الخيارين سيعمل بشكل جيد في مشكلة التصنيف الثنائي. ومع ذلك ، ما يجب مراعاته إذا قررت استخدام sigmoid التنشيط sigmoid في المصنف الخاص بك ، ستحتاج أيضًا إلى تغيير وظيفة الخسارة في طريقة model.compile() من sparse_categorical_crossentropy إلى binary_crossentropy كما في المثال أدناه:
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
التحقق من صحة
في الفصول الماضية ، درسنا دقة شبكاتنا العصبية التلافيفية باستخدام مقياس accuracy في مجموعة بيانات الاختبار. عندما قمنا بتطوير شبكة عصبية تلافيفية لتصنيف الصور من مجموعة بيانات FASHION MNIST ، حصلنا على دقة 97 ٪ على مجموعة بيانات التدريب و 92 ٪ فقط من الدقة في مجموعة بيانات الاختبار. حدث كل هذا بسبب إعادة تدريب نموذجنا. بمعنى آخر ، بدأت شبكتنا العصبية التلافيفية في تذكر مجموعة بيانات التدريب. ومع ذلك ، لم نتمكن من معرفة كيفية إعادة التدريب إلا بعد قيامنا بتدريب واختبار النموذج على البيانات المتاحة من خلال مقارنة دقة مجموعة بيانات التدريب ومجموعة بيانات الاختبار.
لتجنب هذه المشكلة ، نستخدم غالبًا مجموعة بيانات للتحقق من الصحة:
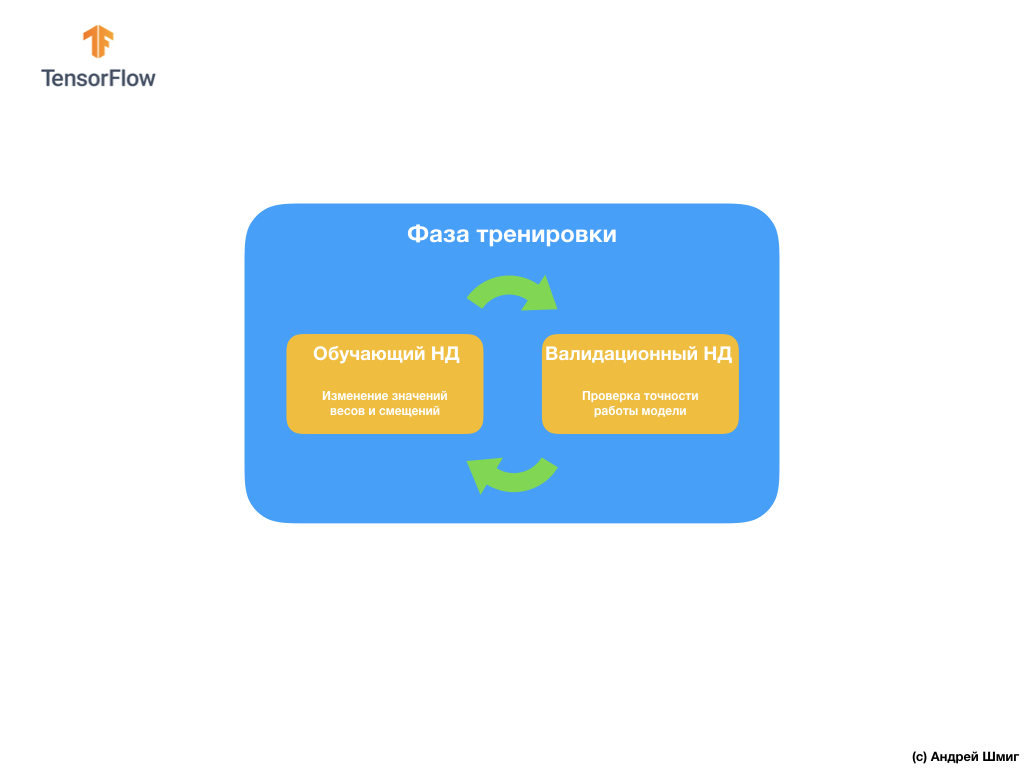
أثناء التدريب ، لا ترى "شبكتنا العصبية التلافيفية" سوى مجموعة بيانات التدريب وتتخذ قرارات بشأن كيفية تغيير قيم المعلمات الداخلية - الأوزان والتشريد. بعد كل تكرار تدريب ، نتحقق من حالة النموذج من خلال حساب قيمة وظيفة الخسارة في مجموعة بيانات التدريب وفي مجموعة بيانات التحقق من الصحة. تجدر الإشارة إلى الاهتمام الخاص بحقيقة أن البيانات من مجموعة التحقق من الصحة لا يتم استخدامها في أي مكان بواسطة النموذج لضبط قيم المعلمات الداخلية. التحقق من دقة النموذج على مجموعة بيانات التحقق من الصحة فقط يخبرنا إلى أي مدى يعمل نموذجنا على مجموعة البيانات نفسها هذه. وبالتالي ، فإن نتائج النموذج على مجموعة بيانات التحقق من الصحة تخبرنا إلى أي مدى تعلم نموذجنا تعميم البيانات التي تم الحصول عليها وتطبيق هذا التعميم على مجموعة بيانات جديدة.
الفكرة هي أنه نظرًا لأننا لا نستخدم مجموعة بيانات التحقق من الصحة عند تدريب النموذج ، فإن اختبار النموذج على مجموعة التحقق من الصحة سيتيح لنا أن نفهم ما إذا كان النموذج قد تم إعادة تدريبه أم لا.
لنلقِ نظرة على مثال.
في CoLab ، التي أجريناها بضع نقاط أعلاه ، قمنا بتدريب شبكتنا العصبية لمدة 15 تكرارًا.
Epoch 15/15 10/10 [===] - loss: 1.0124 - acc: 0.7170 20/20 [===] - loss: 0.0528 - acc: 0.9900 - val_loss: 1.0124 - val_acc: 0.7070
إذا نظرنا إلى دقة التنبؤات حول مجموعات بيانات التدريب والتحقق من الصحة في التكرار التدريبي الخامس عشر ، يمكننا أن نرى أننا حققنا دقة عالية في مجموعة بيانات التدريب ومؤشر منخفض بشكل كبير على مجموعة بيانات التحقق من الصحة - 0.9900 مقابل 0.7070 .
هذه علامة واضحة على إعادة التدريب. تذكرت الشبكة العصبية مجموعة بيانات التدريب ، وبالتالي فهي تعمل بدقة لا تصدق على بيانات الإدخال منها. ومع ذلك ، بمجرد أن يتحقق الأمر من دقة مجموعة بيانات التحقق من الصحة التي "لم يرها" النموذج ، يتم تقليل النتائج بشكل كبير.
تتمثل إحدى طرق تجنب إعادة التدريب في إجراء دراسة دقيقة للرسم البياني لقيم وظيفة الخسارة في مجموعات بيانات التدريب والتحقق من الصحة في جميع عمليات تكرار التدريب:
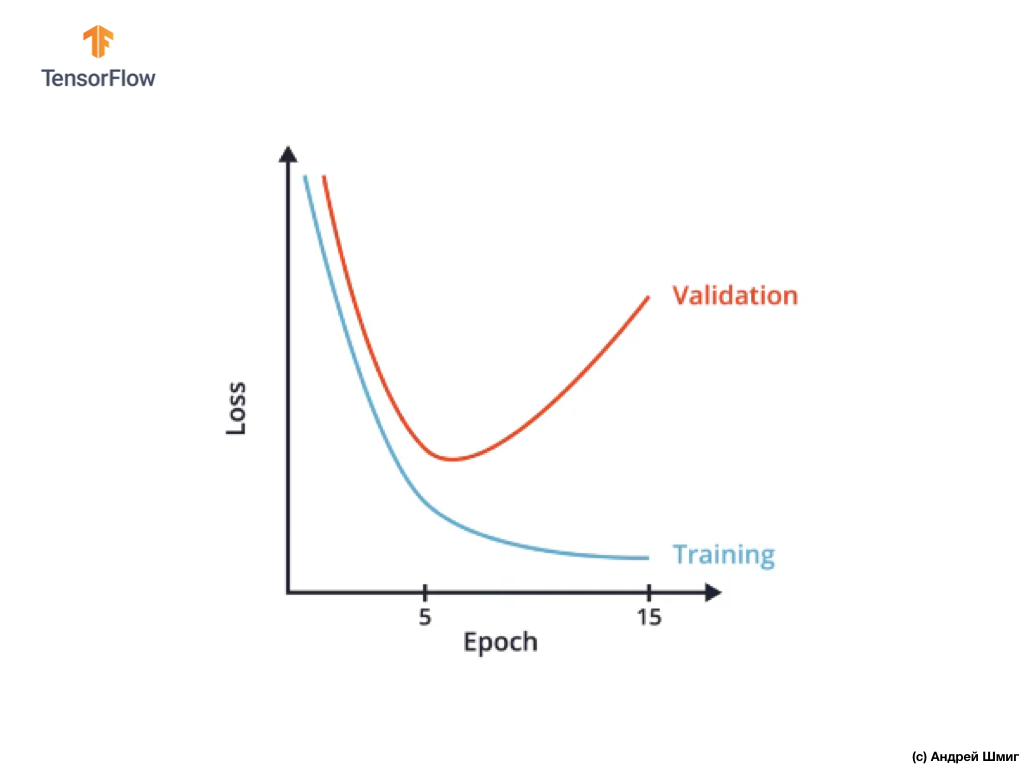
في CoLab ، قمنا ببناء رسم بياني مماثل وحصلنا على شيء مشابه للرسم البياني أعلاه لاعتماد وظيفة الخسارة على تكرار التدريب.
قد تلاحظ أنه بعد تكرار تدريب معين ، تبدأ قيمة وظيفة الخسارة في مجموعة بيانات التحقق من الصحة في الازدياد ، بينما تستمر قيمة وظيفة الخسارة في مجموعة بيانات التدريب في الانخفاض.
في نهاية التكرار التدريبي 15 ، نلاحظ أن قيمة وظيفة الخسارة في مجموعة بيانات التحقق من الصحة عالية للغاية ، وأن قيمة وظيفة الخسارة في مجموعة بيانات التدريب صغيرة للغاية. في الواقع ، هذا هو مؤشر إعادة تدريب الشبكة العصبية.
من خلال النظر في الرسم البياني بعناية ، يمكنك أن تفهم أنه بعد بضع دورات تدريبية ، تبدأ شبكتنا العصبية ببساطة في تخزين بيانات التدريب ، مما يعني أن قدرة النموذج على التعميم تقل ، مما يؤدي إلى تدهور في دقة مجموعة بيانات التحقق من الصحة.
كما ربما تكون قد فهمت بالفعل ، فإن مجموعة بيانات التحقق من الصحة تسمح لنا بتحديد عدد التكرارات التدريبية التي يتعين القيام بها حتى تكون شبكتنا العصبية التلافيفية دقيقة وفي الوقت نفسه لا تعاد تدريبها.
يمكن أن يكون هذا النهج مفيدًا للغاية إذا كان لدينا خيار من بين العديد من بنى الشبكات العصبية التلافيفية:

على سبيل المثال ، إذا قررت عدد الطبقات في شبكة عصبية تلافيفية ، يمكنك إنشاء العديد من بنى الشبكات العصبية ثم مقارنة دقتها باستخدام مجموعة بيانات للتحقق من الصحة.
بنية الشبكة العصبية التي تتيح لك تحقيق الحد الأدنى لقيمة وظيفة الخسارة وستكون الأفضل لحل مهمتك.
والسؤال التالي الذي قد تكون لديكم هو سبب إنشاء مجموعة بيانات التحقق من الصحة إذا كان لدينا بالفعل مجموعة بيانات اختبار؟ هل يمكننا استخدام مجموعة بيانات اختبار للتحقق من الصحة؟
المشكلة هي أنه على الرغم من حقيقة أننا لا نستخدم مجموعة التحقق من الصحة في عملية تدريب النموذج ، فإننا نستخدم نتائج العمل على مجموعة بيانات الاختبار لتحسين دقة النموذج ، مما يعني أن مجموعة بيانات الاختبار تؤثر على الأوزان والتحيزات في العصبية الشبكة.
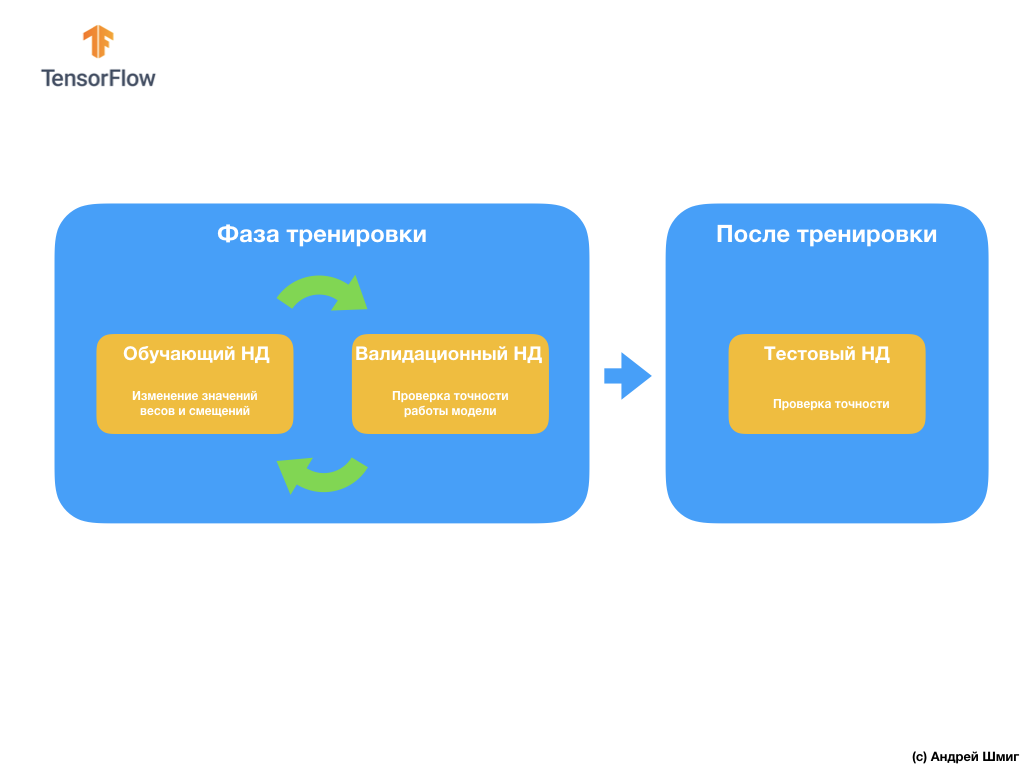
ولهذا السبب نحتاج إلى مجموعة بيانات تحقق لم يسبق أن شاهدها نموذجنا من قبل للتحقق بدقة من أدائها.
لقد اكتشفنا للتو كيف يمكن لمجموعة البيانات التي تم التحقق منها أن تساعدنا في تجنب إعادة التدريب. في الأجزاء التالية ، سوف نتحدث عن توسيع البيانات (ما يسمى زيادة) وانفصال (ما يسمى التسرب) من الخلايا العصبية - طريقتين شائعتين يمكن أن تساعدنا أيضا في تجنب إعادة التدريب.
امتداد الصورة (تكبير)
في تدريب الشبكات العصبية على تحديد كائنات فئة معينة ، نريد من شبكتنا العصبية أن تجد هذه الكائنات ، بغض النظر عن موقعها وحجمها في الصورة.
على سبيل المثال ، لنفترض أننا نريد تدريب شبكتنا العصبية للتعرف على الكلاب في الصور:

لذلك ، نريد من شبكتنا العصبية أن تحدد وجود كلب في الصورة ، بغض النظر عن حجم الكلب وفي أي جزء من الصورة ، سواء كان جزء من الكلب مرئيًا أم الكلب بأكمله. نريد التأكد من أن شبكتنا العصبية يمكنها معالجة كل هذه الخيارات أثناء التدريب.
إذا كنت محظوظًا بما فيه الكفاية ولديك مجموعة كبيرة من بيانات التدريب ، فيمكننا القول بثقة أنك محظوظ ومن غير المرجح أن تقوم شبكتك العصبية بإعادة التدريب. ومع ذلك ، ما يحدث في كثير من الأحيان ، يتعين علينا العمل مع مجموعة محدودة من الصور (بيانات التدريب) ، والتي بدورها ستقود شبكتنا العصبية التلافيفية مع وجود احتمال كبير لإعادة التدريب وتقليل قدرتها على تعميم وإنتاج النتيجة المرجوة على البيانات التي لا تقوم بها "رأى" في وقت سابق.
يمكن حل هذه المشكلة باستخدام تقنية تسمى "ملحق" (تكبير الصورة). يعمل توسيع الصور (البيانات) من خلال إنشاء (إنشاء) صور جديدة للتدريب من خلال تطبيق التحويلات التعسفية للمجموعة الأصلية من الصور من مجموعة التدريب.
على سبيل المثال ، يمكن أن نأخذ إحدى الصور المصدر من مجموعة بيانات التدريب الخاصة بنا وتطبيق العديد من التحولات التعسفية عليها - اقلبها بدرجة X ، وقم بعكس الصورة أفقياً ، وقم بزيادة تعسفية.

بإضافة الصور التي تم إنشاؤها إلى مجموعة بيانات التدريب الخاصة بنا ، فإننا مقتنعون بأن شبكتنا العصبية "ستشاهد" عددًا كافًا من الأمثلة المختلفة للتدريب. نتيجة لمثل هذه الإجراءات ، ستعمل شبكتنا العصبية التلافيفية على تعميم البيانات التي لم تراها بعد بشكل أفضل وستعمل على تجنب إعادة التدريب.
في الجزء التالي ، سوف نتعرف على ما هو التسرب (إيقاف التشغيل) - طريقة أخرى لمنع تحليق النموذج.
استثناء (التسرب)
في هذا الجزء ، سوف نتعلم تقنية جديدة - التسرب ، والتي ستساعدنا أيضًا في تجنب الإفراط في تدريب النموذج. كما نعلم بالفعل من الأجزاء المبكرة ، تعمل الشبكة العصبية على تحسين المعلمات الداخلية (الأوزان والتشريد) لتقليل وظيفة الفقد.
إحدى المشكلات التي يمكن مواجهتها أثناء تدريب الشبكة العصبية هي القيم الضخمة في جزء من الشبكة العصبية والقيم الصغيرة في الجزء الآخر من الشبكة العصبية.

نتيجة لذلك ، اتضح أن الخلايا العصبية ذات الأوزان الأعلى تلعب دورًا أكبر في عملية التعلم ، في حين أن الخلايا العصبية ذات الأوزان المنخفضة تتوقف عن أن تكون مهمة وتكون أقل وأقل عرضة للتغيير. طريقة واحدة لتجنب هذا هو استخدام التسرب التعسفي من الخلايا العصبية.
الإغلاق (التسرب) - عملية الإغلاق الانتقائي للخلايا العصبية في عملية التعلم.
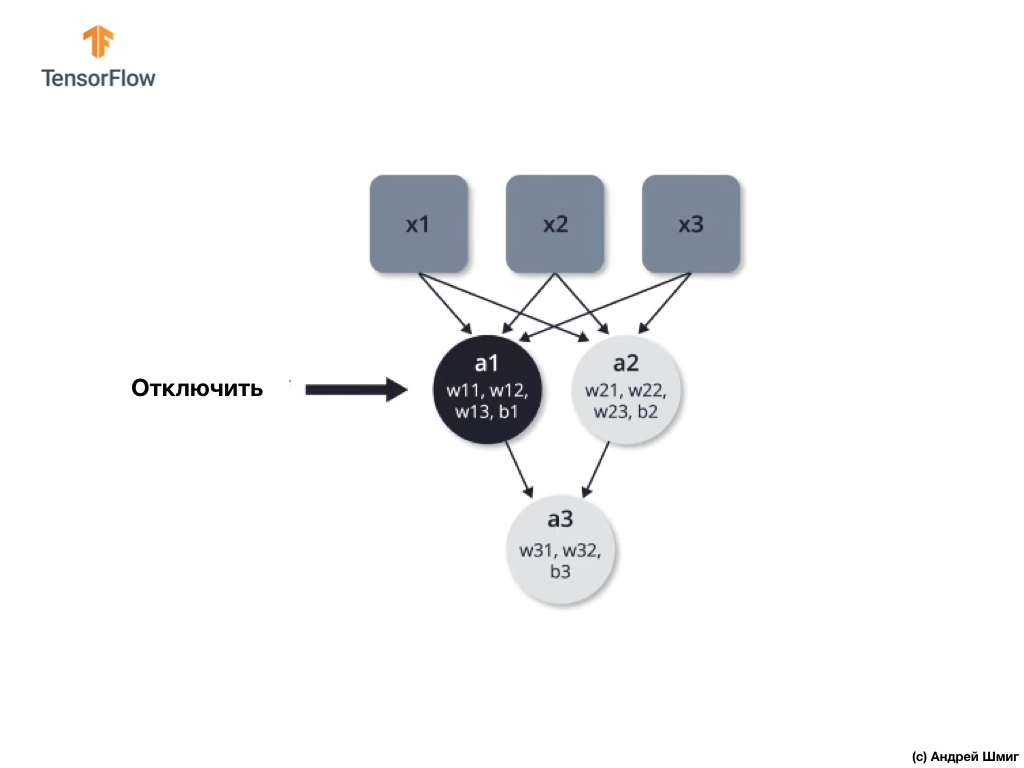
يسمح لك الإغلاق الانتقائي لبعض الخلايا العصبية في عملية التعلم بمشاركة الخلايا العصبية الأخرى بنشاط في التعلم. أثناء تكرار التكرار ، نقوم بتعطيل بعض الخلايا العصبية بشكل تعسفي.
لنلقِ نظرة على مثال. تخيل أننا عند التكرار التدريبي الأول ، نغلق اثنين من الخلايا العصبية المميزة باللون الأسود:
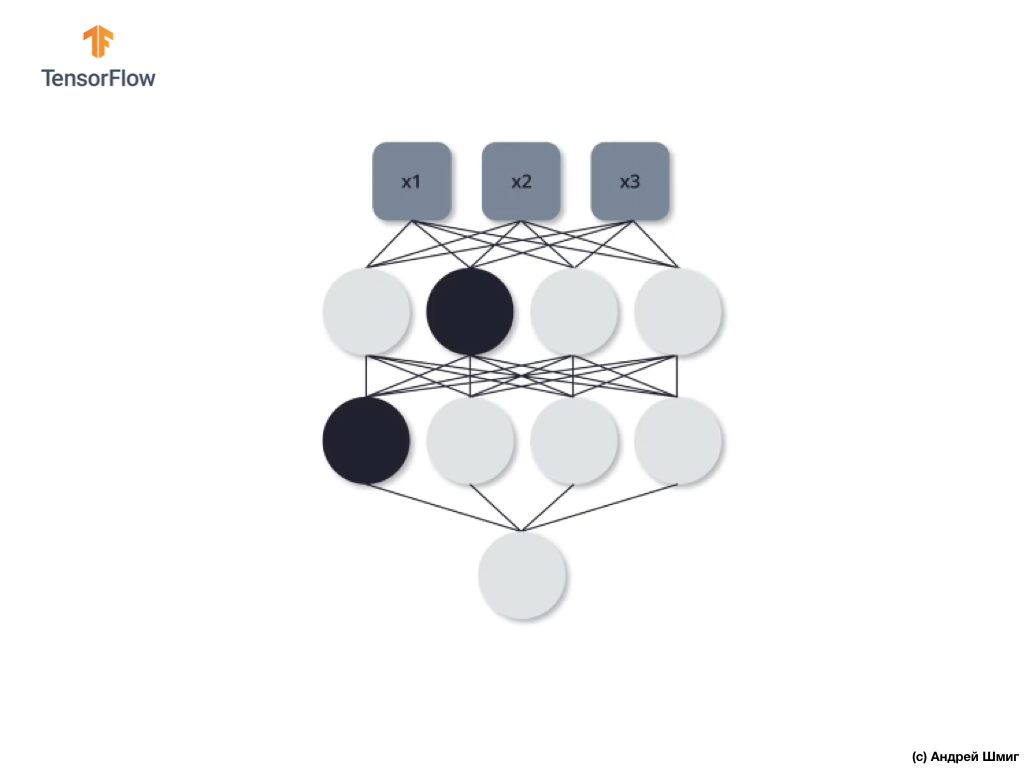
تحدث عمليات الانتشار المباشر وانتشار الظهر دون استخدام اثنين من الخلايا العصبية المعزولة.
في التكرار التدريبي الثاني ، قررنا عدم استخدام الخلايا العصبية الثلاثة التالية - إيقافها:

كما في الحالة السابقة ، في عمليات الانتشار المباشر والعكس ، لا نستخدم هذه الخلايا العصبية الثلاثة. في التكرار الأخير ، التدريب الثالث ، قررنا عدم استخدام هاتين العصبتين:
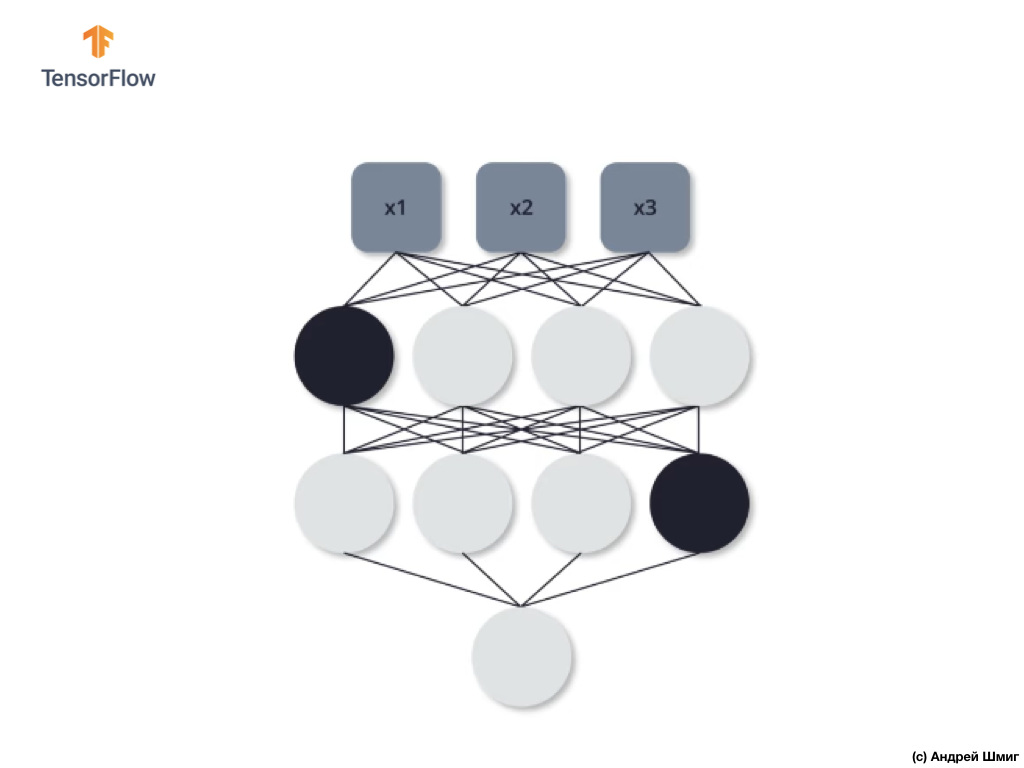
وفي هذه الحالة ، لا نستخدم الخلايا العصبية المنفصلة في عمليات الانتشار المباشر والعكس. و هكذا.
من خلال تدريب شبكتنا العصبية بهذه الطريقة يمكننا تجنب إعادة التدريب. يمكننا القول أن شبكتنا العصبية أصبحت أكثر استقرارًا ، لأنه مع هذا النهج ، لا يمكنها الاعتماد على جميع الخلايا العصبية تمامًا لحل المشكلة. وهكذا ، تبدأ الخلايا العصبية الأخرى في القيام بدور أكثر نشاطًا في تكوين قيمة الإخراج المطلوبة ، وكذلك البدء في التعامل مع المهمة.
في الممارسة العملية ، يتطلب هذا النهج الإشارة إلى احتمال القضاء على كل من الخلايا العصبية في أي تكرار التدريب. يرجى ملاحظة أن الإشارة إلى احتمال أننا قد نجد أنفسنا في موقف حيث يتم قطع بعض الخلايا العصبية في كثير من الأحيان أكثر من غيرها ، والبعض الآخر قد لا يتم قطع الاتصال على الإطلاق. ومع ذلك ، هذه ليست مشكلة ، لأنه يتم تنفيذ هذه العملية عدة مرات ، وفي المتوسط يمكن فصل كل خلية عصبية لها نفس الاحتمال.
الآن دعونا نطبق المعرفة النظرية المكتسبة في الممارسة وصقل المصنف الخاص بنا من صور القطط والكلاب.
CoLab: الكلاب والقطط. تكرار
CoLab باللغة الإنجليزية متاح على هذا الرابط .
CoLab باللغة الروسية متاح على هذا الرابط .
القطط VS الكلاب: تصنيف الصورة مع التمديد
في هذا البرنامج التعليمي ، سنناقش كيفية تصنيف صور القطط والكلاب. سنقوم بتطوير مصنف الصورة باستخدام نموذج tf.keras.Sequential ، ونستخدم tf.keras.Sequential لتحميل البيانات.
الأفكار المراد تغطيتها في هذا الجزء:
سنكتسب خبرة عملية في تطوير مصنف ونطور فهمًا بديهيًا للمفاهيم التالية:
- بناء نموذج لتدفق البيانات ( خطوط أنابيب إدخال البيانات ) باستخدام فئة
tf.keras.preprocessing.image.ImageDataGenerator (كيفية العمل بكفاءة مع البيانات الموجودة على القرص التي تتفاعل مع النموذج؟) - إعادة التدريب - ما هو وكيفية تحديد ذلك؟
- تعد زيادة البيانات وطريقة التسرب من التقنيات الأساسية في مكافحة إعادة التدريب في مهام التعرف على الأنماط التي سننفذها في عملية التدريب النموذجية لدينا.
سنتبع النهج الأساسي في تطوير نماذج التعلم الآلي:
- استكشاف وفهم البيانات
- تكوين تيار المدخلات
- بناء نموذج
- نموذج القطار
- نموذج الاختبار
- تحسين نموذج / كرر العملية
قبل أن نبدأ ...
قبل بدء تشغيل الشفرة في المحرر ، نوصي بإعادة تعيين جميع الإعدادات في Runtime -> إعادة تعيين الكل في القائمة العلوية. سيساعد مثل هذا الإجراء على تجنب مشاكل نقص الذاكرة ، إذا كنت تعمل بشكل متوازٍ أو كنت تعمل مع العديد من المحررين.
استيراد الحزم
لنبدأ باستيراد الحزم التي تحتاجها:
os - قراءة الملفات وهياكل الدليل؛numpy - بالنسبة لبعض عمليات المصفوفة خارج TensorFlow ؛matplotlib.pyplot - التخطيط وعرض الصور من مجموعة بيانات الاختبار والتحقق.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
استيراد TensorFlow :
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
تحميل البيانات
نبدأ في تطوير مصنفنا عن طريق تحميل مجموعة بيانات. مجموعة البيانات التي نستخدمها هي نسخة مُفلترة من مجموعة بيانات Dogs vs Cats من خدمة Kaggle (في النهاية ، يتم توفير مجموعة البيانات هذه بواسطة Microsoft Research).
في الماضي ، استخدمت CoLab وأنا مجموعة بيانات من وحدة TensorFlow Dataset نفسها ، وهي ملائمة للغاية للعمل والاختبار. ومع ذلك ، في tf.keras.preprocessing.image.ImageDataGenerator ، tf.keras.preprocessing.image.ImageDataGenerator فئة tf.keras.preprocessing.image.ImageDataGenerator لقراءة البيانات من القرص. لذلك ، نحتاج أولاً إلى تنزيل مجموعة بيانات Dog VS Cats وفك ضغطها.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
تحتوي مجموعة البيانات التي قمنا بتنزيلها على البنية التالية:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
للحصول على القائمة الكاملة للمديرين ، يمكنك استخدام الأمر التالي:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
الإخراج (عند البدء من CoLab):
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
الآن تعيين المسارات الصحيحة إلى الدلائل مع مجموعات البيانات للتدريب والتحقق من صحة للمتغيرات:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
فهم البيانات وهيكلها
دعونا نرى عدد الصور من القطط والكلاب لدينا في مجموعات بيانات الاختبار والتحقق (الدلائل).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
الاستنتاج:
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
تحديد معلمات النموذج
للراحة ، سنضع تثبيت المتغيرات التي نحتاجها لمزيد من معالجة البيانات والتدريب النموذجي في إعلان منفصل:
BATCH_SIZE = 100
امتداد البيانات
تحدث إعادة التدريب عادةً عندما يكون هناك عدد قليل من أمثلة التدريب في مجموعة البيانات الخاصة بنا. إحدى طرق القضاء على نقص البيانات هي توسيعها لتشمل العدد الصحيح من الحالات والتغيرات الصحيحة. امتداد البيانات هو عملية توليد البيانات من المثيلات الموجودة عن طريق تطبيق تحويلات متنوعة على مجموعة البيانات الأصلية. الغرض من هذه الطريقة هو زيادة عدد حالات الإدخال الفريدة التي لن يراها النموذج مرة أخرى ، والتي بدورها ستسمح للنموذج بتعميم بيانات الإدخال بشكل أفضل وإظهار قدر أكبر من الدقة في مجموعة بيانات التحقق من الصحة.
باستخدام tf.keras يمكننا تنفيذ مثل هذه التحويلات العشوائية وإنشاء صور جديدة من خلال فئة ImageDataGenerator . سيكون كافيا بالنسبة لنا لتمرير في شكل معلمات التحولات المختلفة التي نود أن تطبق على الصور ، وسوف يعتني الفصل نفسه الباقي خلال التدريب النموذجي.
أولاً ، لنكتب وظيفة تعرض الصور التي تم الحصول عليها نتيجة للتحولات العشوائية. ثم سنبحث بمزيد من التفصيل التحولات المستخدمة في عملية توسيع مجموعة البيانات الأصلية.
def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show()
اقلب الصورة أفقيا
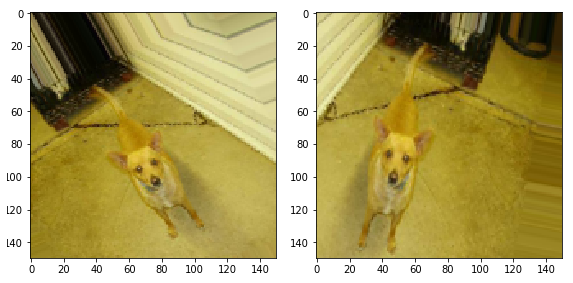
يمكننا أن نبدأ مع تحويل بسيط - صورة أفقي التقليب. دعونا نرى كيف سيبدو هذا التحول مطبقًا على الصور المصدر لدينا. horizontal_flip=True ImageDataGenerator .
image_gen = ImageDataGenerator(rescale=1./255, horizontal_flip=True) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
. ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5 ):
. 45.
image_gen = ImageDataGenerator(rescale=1./255, rotation_range=45) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
— 5 . ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5):

— 50%.
image_gen = ImageDataGenerator(rescale=1./255, zoom_range=0.5) train_data_gen = image_gen.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE))
:
Found 2000 images belonging to 2 classes.
, — 5 . ( ) .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5 ):

, , , ImageDataGenerator .
— , 45 , , , .
image_gen_train = ImageDataGenerator( rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest' ) train_data_gen = image_gen_train.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE, IMG_SHAPE), class_mode='binary')
:
Found 2000 images belonging to 2 classes.
, .
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
(2 5):

, , , . , , .
image_gen_val = ImageDataGenerator(rescale=1./255) val_data_gen = image_gen_val.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, target_size=(IMG_SHAPE, IMG_SHAPE), class_mode='binary')
4 .
0.5. , 50% 0. .
512 relu . — — softmax .
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Dropout(0.5), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
adam . sparse_categorical_crossentropy . , accuracy metrics :
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
summary :
model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ dropout (Dropout) (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0 _________________________________________________________________
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
:
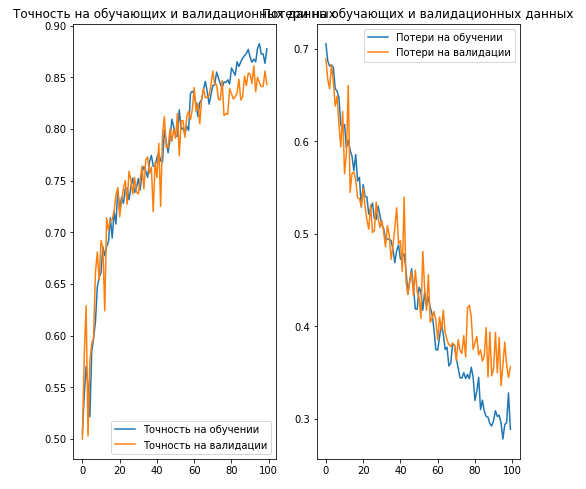
, :
- : ( ).
- (.. augmentation) : .
- / (.. dropout) : ( , ).
, . .
:
CoLab .
CoLab .
. CoLab . CoLab . CoLab , .
CoLab. CoLab , , .
!
# tf.keras
CoLab . tf.keras.Sequential , ImageDataGenerator .
. os , numpy python- numpy- , , matplotlib.pyplot .
from __future__ import absolute_import, division, print_function, unicode_literals import os import numpy as np import glob import shutil import matplotlib.pyplot as plt
TODO: TensorFlow Keras-
TensorFlow tf Keras- , . , ImageDataGenerator - Keras .
— . .
.
_URL = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz" zip_file = tf.keras.utils.get_file(origin=_URL, fname="flower_photos.tgz", extract=True) base_dir = os.path.join(os.path.dirname(zip_file), 'flower_photos')
, , 5 :
:
classes = ['', '', '', '', '']
, , :
flower_photos |__ diasy |__ dandelion |__ roses |__ sunflowers |__ tulips
. . , .
2 train val 5 - ( ). , 80% , 20% . :
flower_photos |__ diasy |__ dandelion |__ roses |__ sunflowers |__ tulips |__ train |______ daisy: [1.jpg, 2.jpg, 3.jpg ....] |______ dandelion: [1.jpg, 2.jpg, 3.jpg ....] |______ roses: [1.jpg, 2.jpg, 3.jpg ....] |______ sunflowers: [1.jpg, 2.jpg, 3.jpg ....] |______ tulips: [1.jpg, 2.jpg, 3.jpg ....] |__ val |______ daisy: [507.jpg, 508.jpg, 509.jpg ....] |______ dandelion: [719.jpg, 720.jpg, 721.jpg ....] |______ roses: [514.jpg, 515.jpg, 516.jpg ....] |______ sunflowers: [560.jpg, 561.jpg, 562.jpg .....] |______ tulips: [640.jpg, 641.jpg, 642.jpg ....]
, , . .
for cl in classes: img_path = os.path.join(base_dir, cl) images = glob.glob(img_path + '/*.jpg') print("{}: {} ".format(cl, len(images))) train, val = images[:round(len(images)*0.8)], images[round(len(images)*0.8):] for t in train: if not os.path.exists(os.path.join(base_dir, 'train', cl)): os.makedirs(os.path.join(base_dir, 'train', cl)) shutil.move(t, os.path.join(base_dir, 'train', cl)) for v in val: if not os.path.exists(os.path.join(base_dir, 'val', cl)): os.makedirs(os.path.join(base_dir, 'val', cl)) shutil.move(v, os.path.join(base_dir, 'val', cl))
:
train_dir = os.path.join(base_dir, 'train') val_dir = os.path.join(base_dir, 'val')
, , , . — (.. augmentation) . . , , — , . .
tf.keras , — ImageDataGenerator . .
. — () batch_size , IMG_SHAPE .
TODO:
100 batch_size 150 IMG_SHAPE :
batch_size = IMG_SHAPE =
TODO:
ImageDataGenerator , , . .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip(images_arr, axes): ax.imshow(img) plt.tight_layout() plt.show() augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator 45 . .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator 50%. .flow_from_directory . , , , .
image_gen = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
, ImageDataGenerator :
flow_from_directory . , , , .
image_gen_train = train_data_gen =
5 :
augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
TODO:
. , , ImageDataGenerator , . flow_from_directory . , , . .
image_gen_val = val_data_gen =
TODO:
, 3 — . 16 , — 32 , — 64 . 33. 22.
Flatten , 512 . 5 , softmax . relu . , , 20%.
model =
TODO:
, adam sparse_categorical_crossentropy . , compile(...) .
TODO:
, fit_generator fit , . fit_generator ImageDataGenerator . 80 , fit_generator -.
epochs = history =
TODO: /
, :
acc = val_acc = loss = val_loss = epochs_range =
TODO:
( + ) 512 . . . , , .. , ImageDataGenerator — . , .
?
.
RGB- :
- : , ( );
- : 3D-;
- RGB- : 3 : , ;
- : (). , (). — .
- : . , .
- : . , .
:
. , . .
… call-to-action — , share :)
YouTube
برقية
فكونتاكتي