في هذه المقالة ، سأتحدث عن كيفية تحول المشروع الذي أعمل فيه من متراصة كبيرة إلى مجموعة من الخدمات المصغرة.
بدأ المشروع تاريخه منذ وقت طويل ، في أوائل عام 2000. تمت كتابة الإصدارات الأولى في Visual Basic 6. بمرور الوقت ، أصبح من الواضح أن التطوير في هذه اللغة في المستقبل سيكون من الصعب دعمه ، حيث أن IDE واللغة نفسها غير متطورة. في أواخر العقد الأول من القرن العشرين ، تقرر التحول إلى C # واعدة أكثر. تمت كتابة الإصدار الجديد بالتوازي مع تحسين النسخة القديمة ، وكان المزيد والمزيد من التعليمات البرمجية على .NET بشكل تدريجي. ركز Backend in C # في البداية على بنية الخدمة ، ومع ذلك ، أثناء التطوير ، تم استخدام مكتبات مشتركة ذات منطق ، وتم إطلاق الخدمات في عملية واحدة. اتضح التطبيق ، الذي أطلقنا عليه "خدمة متراصة".
إحدى المزايا القليلة لهذه الحزمة هي قدرة الخدمات على الاتصال ببعضها البعض من خلال واجهة برمجة تطبيقات خارجية. كانت هناك متطلبات مسبقة واضحة للانتقال إلى خدمة أكثر صحة ، وفي المستقبل ، بنية الخدمات المصغرة.
بدأنا عملنا التحلل حوالي عام 2015. لم نصل بعد إلى حالة مثالية - فهناك أجزاء من مشروع كبير يصعب الاتصال به متجانسة ، لكنها لا تشبه الخدمات الميكروية أيضًا. ومع ذلك ، فإن التقدم كبير.
سأتحدث عنه في المقال.
محتوى
العمارة ومشاكل الحل القائم
في البداية ، بدا التصميم على النحو التالي: UI هو تطبيق منفصل ، الجزء المكتوب في Visual Basic 6 ، والتطبيق في .NET كان عبارة عن مجموعة من الخدمات ذات الصلة التي تعمل مع قاعدة بيانات كبيرة إلى حد ما.
عيوب الحل السابقنقطة واحدة من الفشلكان لدينا نقطة فشل واحدة: تطبيق .NET يعمل في عملية واحدة. في حالة تعطل أي من الوحدات النمطية ، فشل التطبيق بأكمله ، وكان عليك إعادة تشغيله. نظرًا لأننا نقوم بأتمتة عدد كبير من العمليات لمستخدمين مختلفين ، بسبب فشل في أحدهم ، لم يتمكن البعض من العمل لبعض الوقت. ومع وجود خطأ في البرنامج ، لم يساعد التكرار أيضًا.
تشكيلة التحسيناتهذا الخلل هو التنظيمية إلى حد ما. يحتوي تطبيقنا على العديد من العملاء ، وهم يريدون جميعًا وضع اللمسات الأخيرة عليه في أقرب وقت ممكن. في السابق ، كان من المستحيل القيام بذلك بالتوازي ، وكان جميع العملاء يقفون في طابور. تسببت هذه العملية في تأثير سلبي على العمل ، لأنهم كانوا بحاجة لإثبات أن مهمتهم كانت قيمة. وقضى فريق التطوير وقتًا في تنظيم هذه التشكيلة. استغرق هذا الكثير من الوقت والجهد ، والمنتج نتيجة لذلك لا يمكن أن يتغير بالسرعة التي كان عليها منه.
استخدام غير مناسب للمواردعند وضع الخدمات في عملية واحدة ، نقوم دائمًا بنسخ التكوين بالكامل من خادم إلى خادم. لقد أردنا أن نضع الخدمات الأكثر تحميلًا بشكل منفصل حتى لا نضيع الموارد ونحصل على إدارة أكثر مرونة لمخطط النشر الخاص بنا.
من الصعب تقديم التكنولوجيا الحديثةمشكلة مألوفة لدى جميع المطورين: هناك رغبة في إدخال التقنيات الحديثة في المشروع ، ولكن لا يوجد أي احتمال. مع حل متراصة كبير ، فإن أي تحديث للمكتبة الحالية ، ناهيك عن الانتقال إلى واحد جديد ، يتحول إلى مهمة غير تافهة. يستغرق الأمر وقتًا طويلاً لإثبات قائد الفريق أنه سيجلب مكافآت أكثر من الأعصاب المستنفدة.
صعوبة إصدار التغييراتكانت هذه أخطر مشكلة - أصدرنا إصدارات كل شهرين.
تحول كل إصدار إلى كارثة حقيقية للبنك ، على الرغم من الاختبارات وجهود المطورين. فهم رجال الأعمال أنه في بداية الأسبوع ، لن تعمل بعض الوظائف له. وفهم المطورين أنهم كانوا ينتظرون لمدة أسبوع من الحوادث الخطيرة.
كل شخص لديه الرغبة في تغيير الوضع.
توقعات Microservice
تسليم المكونات عند توافرها. تسليم المكونات عندما تصبح متاحة بسبب تحلل الحل وفصل العمليات المختلفة.
فرق الطعام الصغيرة. هذا مهم لأنه كان من الصعب إدارة فريق كبير يعمل على متراصة قديمة. تم إجبار مثل هذا الفريق على العمل وفقًا لعملية صارمة ، لكنني أردت المزيد من الإبداع والاستقلال. الفرق الصغيرة فقط هي التي تستطيع تحمله.
عزل الخدمات في عمليات منفصلة. من الناحية المثالية ، أردت عزلها في حاويات ، ولكن هناك عدد كبير من الخدمات المكتوبة في .NET Framework تعمل فقط تحت Windows. هناك الآن خدمات على .NET Core ، لكنها قليلة حتى الآن.
نشر المرونة. أرغب في الجمع بين الخدمات التي نحتاجها ، وليس كقواعد الكود.
استخدام التكنولوجيات الجديدة. هذا مثير للاهتمام لأي مبرمج.
مشاكل الانتقال
بالطبع ، إذا كان من السهل تقسيم متراصة إلى خدمات مجهرية ، فلن تضطر إلى التحدث عنها في المؤتمرات وكتابة المقالات. في هذه العملية ، هناك العديد من المزالق ، وسوف أصف أهمها التي تدخلت معنا.
المشكلة الأولى هي نموذجية لمعظم متراصة: تماسك منطق الأعمال. عندما نكتب متراصة ، نريد إعادة استخدام فصولنا حتى لا نكتب شفرة إضافية. وعند التبديل إلى خدمات micros ، تصبح هذه مشكلة: كل الكود متصل بإحكام ، ومن الصعب فصل الخدمات.
في وقت بدء العمل ، كان لدى المستودع أكثر من 500 مشروع وأكثر من 700 ألف سطر من الأكواد. هذا هو حل كبير إلى حد ما
والمشكلة الثانية . لم يكن من الممكن أخذها وتقسيمها إلى خدمات ميكروية.
المشكلة الثالثة هي عدم وجود البنية التحتية اللازمة. في الواقع ، لقد شاركنا في نسخ التعليمات البرمجية المصدر يدويًا إلى الخوادم.
كيفية التبديل من متراصة إلى الخدمات الصغيرة
توزيع خدمات ميكروسيرفيسأولاً ، قررنا لأنفسنا على الفور أن فصل الخدمات المجهرية هو عملية تكرارية. لقد طلبنا دائمًا إجراء تطوير مهام العمل بشكل متوازٍ. كيف سنقوم بتنفيذ هذا من الناحية الفنية هو بالفعل مشكلتنا. لذلك ، كنا نستعد للعملية التكرارية. لن يعمل بشكل مختلف إذا كان لديك تطبيق كبير ، ولن يكون جاهزًا لإعادة كتابته من البداية.
ما هي الطرق التي نستخدمها لعزل الخدمات الصغيرة؟
الطريقة الأولى هي نقل الوحدات النمطية الحالية كخدمات. في هذا الصدد ، كنا محظوظين: كانت هناك بالفعل خدمات رسمية عملت على بروتوكول WCF. تم نشرها في مجالس منفصلة. نقلناها بشكل منفصل ، مضيفًا قاذفة صغيرة لكل مجموعة. تمت كتابته باستخدام مكتبة Topshelf الرائعة ، والتي تتيح لك تشغيل التطبيق كخدمة وكوحدة تحكم. هذا مناسب لتصحيح الأخطاء ، حيث لا توجد مشاريع إضافية مطلوبة في الحل.
تم توصيل الخدمات وفقًا لمنطق الأعمال ، نظرًا لاستخدامها للتجميعات الشائعة والعمل مع قاعدة بيانات مشتركة. كان من الصعب أن نطلق عليهم خدمات ميكروية في شكلها النقي. ومع ذلك ، يمكننا إصدار هذه الخدمات بشكل منفصل ، في عمليات مختلفة. هذا سمح بالفعل للحد من تأثيرها على بعضها البعض ، والحد من مشكلة التنمية الموازية ونقطة واحدة من الفشل.
بناء مع مضيف هو مجرد سطر واحد من التعليمات البرمجية في فئة البرنامج. نحن اختبأ Topshelf في فئة المساعد.
namespace RBA.Services.Accounts.Host { internal class Program { private static void Main(string[] args) { HostRunner<Accounts>.Run("RBA.Services.Accounts.Host"); } } }
الطريقة الثانية لعزل الخدمات الصغيرة: إنشائها لحل المشاكل الجديدة. إذا لم ينمو المتراصة في نفس الوقت ، فهذا أمر ممتاز بالفعل ، مما يعني أننا نتحرك في الاتجاه الصحيح. لحل المشاكل الجديدة ، حاولنا القيام بخدمات منفصلة. إذا كانت هناك مثل هذه الفرصة ، فقمنا بإنشاء المزيد من الخدمات "المتعارف عليها" التي تتحكم بالكامل في نموذج البيانات الخاص بها ، وهي قاعدة بيانات منفصلة.
لقد بدأنا ، مثل كثيرين ، بخدمات المصادقة والترخيص. فهي مثالية لهذا الغرض. أنها مستقلة ، وكقاعدة عامة ، لديهم نموذج بيانات منفصل. هم أنفسهم لا يتفاعلون مع المتراصة ، فقط يلجأ إليهم لحل بعض المشاكل. في هذه الخدمات ، يمكنك البدء في الانتقال إلى بنية جديدة ، وتصحيح البنية التحتية عليها ، وتجربة بعض الأساليب المتعلقة بمكتبات الشبكة ، إلخ. في منظمتنا ، لا توجد فرق لا يمكنها إنشاء خدمة مصادقة.
الطريقة الثالثة لعزل الخدمات المصغرة التي نستخدمها هي نوعًا ما بالنسبة لنا. هذا هو سحب منطق العمل من طبقة واجهة المستخدم. لدينا تطبيق سطح المكتب الرئيسي UI ، مثل الواجهة الخلفية ، مكتوب في C #. ارتكب المطورون أخطاء بشكل دوري ونفذوا على أجزاء واجهة المستخدم من المنطق التي كان يجب أن توجد في الواجهة الخلفية وإعادة استخدامها.
إذا نظرت إلى مثال حقيقي من رمز جزء واجهة المستخدم ، يمكنك أن ترى أن معظم هذا الحل يحتوي على منطق عمل حقيقي ، وهو أمر مفيد في العمليات الأخرى ، وليس فقط لبناء نموذج واجهة المستخدم.
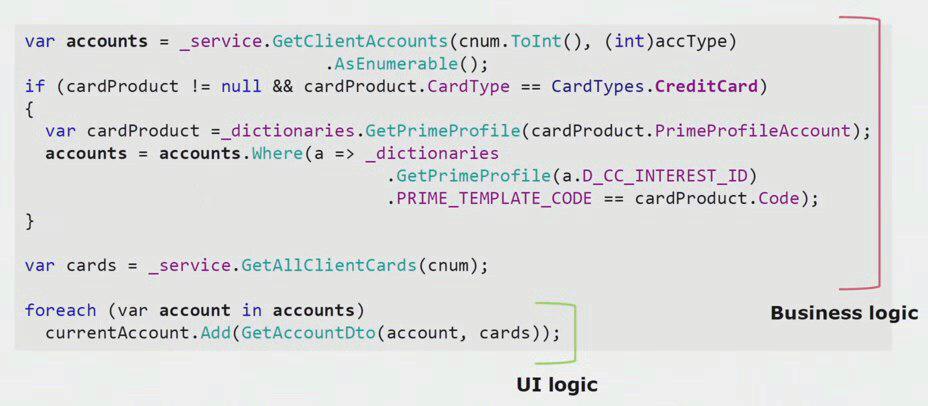
منطق واجهة المستخدم الحقيقي هناك فقط بضعة خطوط. قمنا بنقلها إلى الخادم حتى نتمكن من إعادة استخدامها ، وبالتالي تقليل واجهة المستخدم وتحقيق الهيكل الصحيح.
الطريقة الرابعة والأكثر أهمية لعزل الخدمات الصغيرة ، والتي تسمح لك بتقليل
المتراصة ، هي إزالة الخدمات الحالية من خلال المعالجة. عندما نأخذ الوحدات النمطية الموجودة كما هي ، فإن النتيجة لن تكون دائمًا ممتعة للمطورين ، وقد تصبح عملية الأعمال منذ وقت إنشاء الوظيفة قديمة. بفضل إعادة التوطين ، يمكننا دعم عملية تجارية جديدة لأن متطلبات العمل تتغير باستمرار. يمكننا تحسين شفرة المصدر ، وإزالة العيوب المعروفة ، وإنشاء نموذج بيانات أفضل. هناك الكثير من المزايا.
يرتبط قسم خدمات المعالجة ارتباطًا وثيقًا بمفهوم السياق المحدود. هذا هو مفهوم من تصميم موضوع المنحى. يعني قسم نموذج مجال يتم فيه تعريف جميع مصطلحات لغة واحدة بشكل فريد. النظر في سياق التأمين والفواتير كمثال. لدينا تطبيق متراصة ، ومن الضروري العمل مع الحساب في التأمين. نتوقع من المطور العثور على فئة "الحساب" الموجودة في مجموعة أخرى ، وإنشاء رابط إليها من فئة "التأمين" ، وسنحصل على رمز عمل. سيتم احترام مبدأ DRY ، وسيتم تنفيذ المهمة من خلال استخدام الكود الموجود بشكل أسرع.
نتيجة لذلك ، اتضح أن سياقات الحسابات والتأمين مرتبطة. عندما تنشأ متطلبات جديدة ، سوف يتداخل هذا الاتصال مع التطوير ، مما يزيد من تعقيد منطق الأعمال المعقدة بالفعل. لحل هذه المشكلة ، تحتاج إلى العثور على الحدود بين السياقات في التعليمات البرمجية وإزالة انتهاكاتها. على سبيل المثال ، في سياق التأمين ، من الممكن أن يكون رقم الحساب المكون من 20 رقمًا للبنك المركزي وتاريخ فتح الحساب كافيين.
من أجل فصل هذه السياقات المحدودة عن بعضها البعض والبدء في عملية استخراج الخدمات المصغرة من حل مترابط ، استخدمنا طريقة مثل إنشاء واجهات برمجة التطبيقات الخارجية داخل التطبيق. إذا علمنا أن وحدة ما يجب أن تصبح خدمة ميكروية ، فستتغير بطريقة ما داخل العملية ، ثم قمنا على الفور بإجراء مكالمات إلى المنطق ، الذي ينتمي إلى سياق آخر محدود ، من خلال مكالمات خارجية. على سبيل المثال ، من خلال REST أو WCF.
قررنا لأنفسنا أننا لن نتجنب الكود الذي يتطلب المعاملات الموزعة. في حالتنا ، اتضح أنه من السهل جدًا الامتثال لهذه القاعدة. ما زلنا لم نواجه مثل هذه المواقف عندما تكون هناك حاجة فعلية للمعاملات الموزعة بشدة - الاتساق النهائي بين الوحدات يكفي.
النظر في مثال محدد. لدينا مفهوم الأوركسترا - الناقل ، الذي يعالج جوهر "التطبيق". انه يتناوب إنشاء عميل وحساب وبطاقة مصرفية. إذا تم إنشاء العميل والحساب بنجاح ، وفشل إنشاء البطاقة ، فلن يدخل التطبيق في الحالة "بنجاح" ويظل في الحالة "البطاقة لم يتم إنشاؤها". في المستقبل ، سيقوم نشاط الخلفية باستلامه وإنهائه. النظام في حالة من التناقض لبعض الوقت ، لكن هذا ، بشكل عام ، يناسبنا.
ومع ذلك ، إذا نشأ موقف عندما يكون من الضروري حفظ جزء من البيانات باستمرار ، فسنذهب على الأرجح إلى توسيع الخدمة من أجل معالجة هذا في عملية واحدة.
دعنا نفكر في مثال لتخصيص خدمات microservice. كيف يمكن إنتاجها بأمان نسبيًا؟ في هذا المثال ، لدينا جزء منفصل من النظام - وحدة خدمة المرتبات ، أحد أقسام الكود الذي نرغب في تقديمه لخدمات microservice.
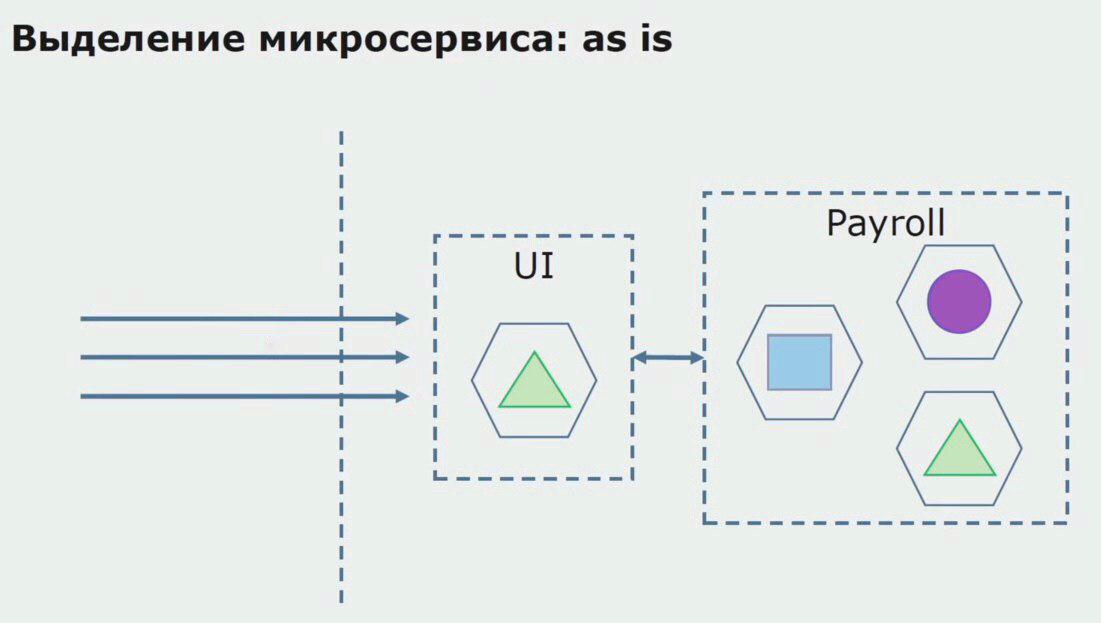
بادئ ذي بدء ، نقوم بإنشاء خدمة microservice بإعادة كتابة الكود. نحسن بعض النقاط التي لا تناسبنا. نحن ندرك متطلبات العمل الجديدة من العميل. نضيف إلى الحزمة بين واجهة المستخدم وواجهة API الخلفية ، والتي ستوفر إعادة توجيه الاتصال.
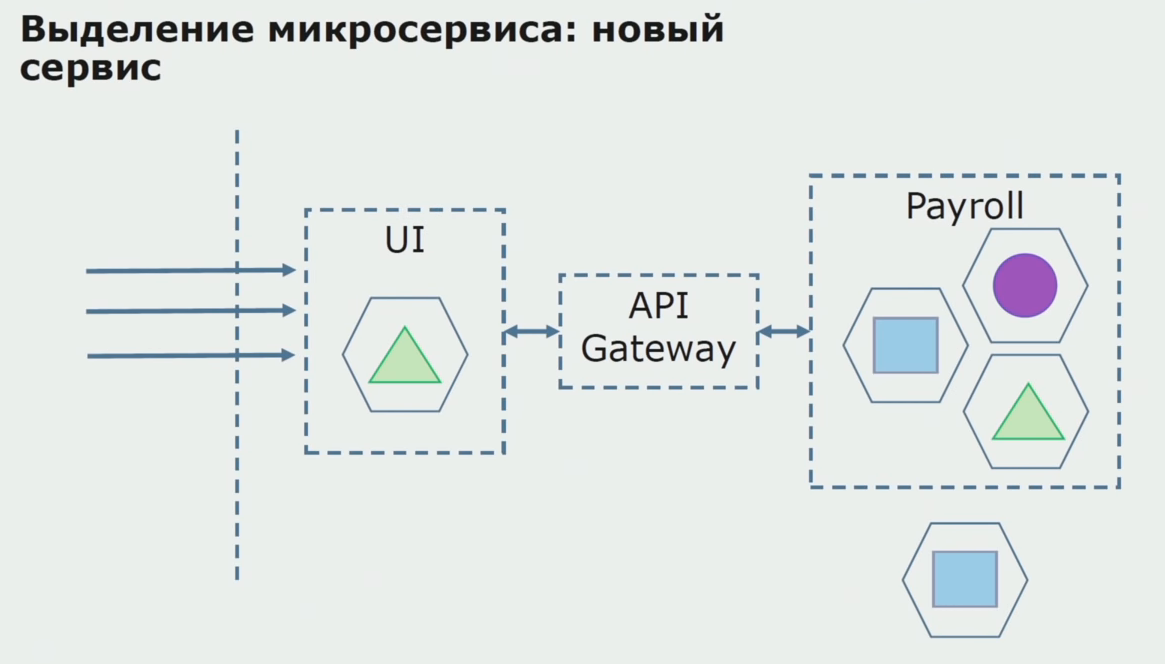
بعد ذلك ، أطلقنا هذا التكوين حيز التنفيذ ، ولكن في حالة الإصدار التجريبي. لا يزال معظم مستخدمينا يعملون مع العمليات التجارية القديمة. بالنسبة للمستخدمين الجدد ، نقوم بتطوير إصدار جديد من تطبيق متجانسة لم تعد هذه العملية تحتوي عليه. في الواقع ، لدينا مجموعة من الخدمات المتجانسة و microservice تعمل في شكل طيار.
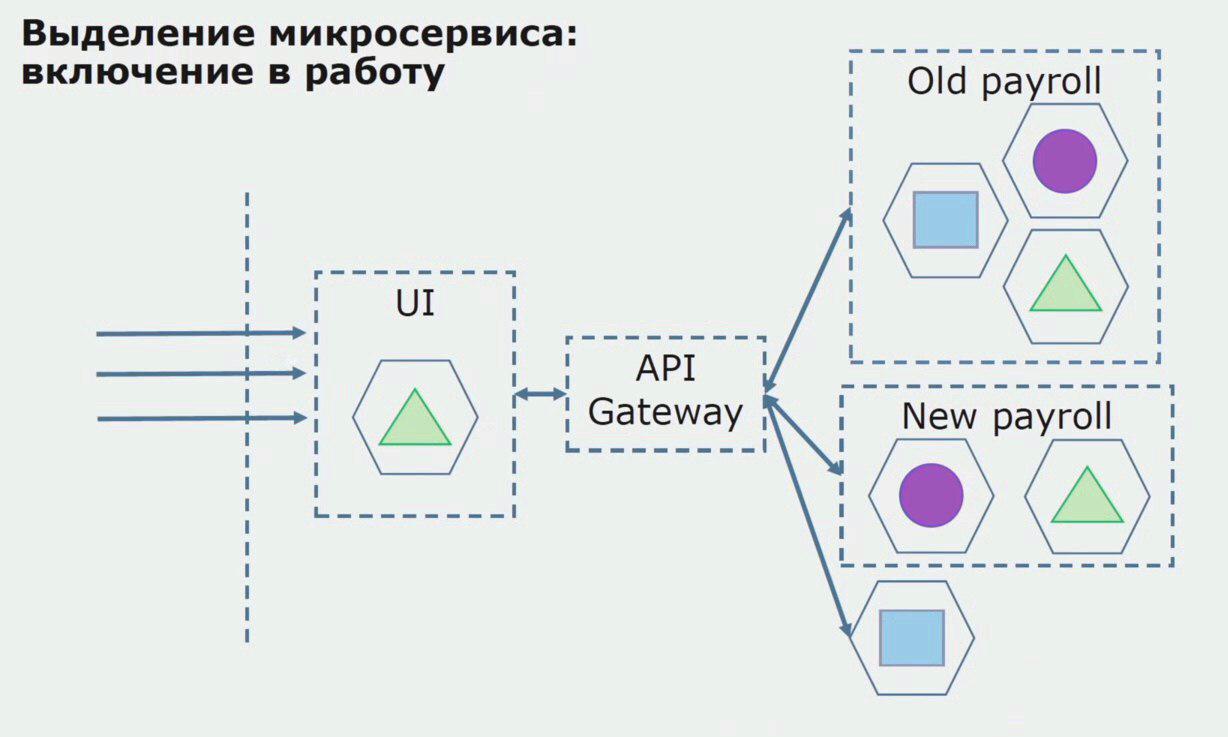
من خلال تجربة ناجحة ، نحن نفهم أن التكوين الجديد يعمل بالفعل ، يمكننا إزالة المتراصة القديمة من المعادلة وترك التكوين الجديد في مكان الحل القديم.
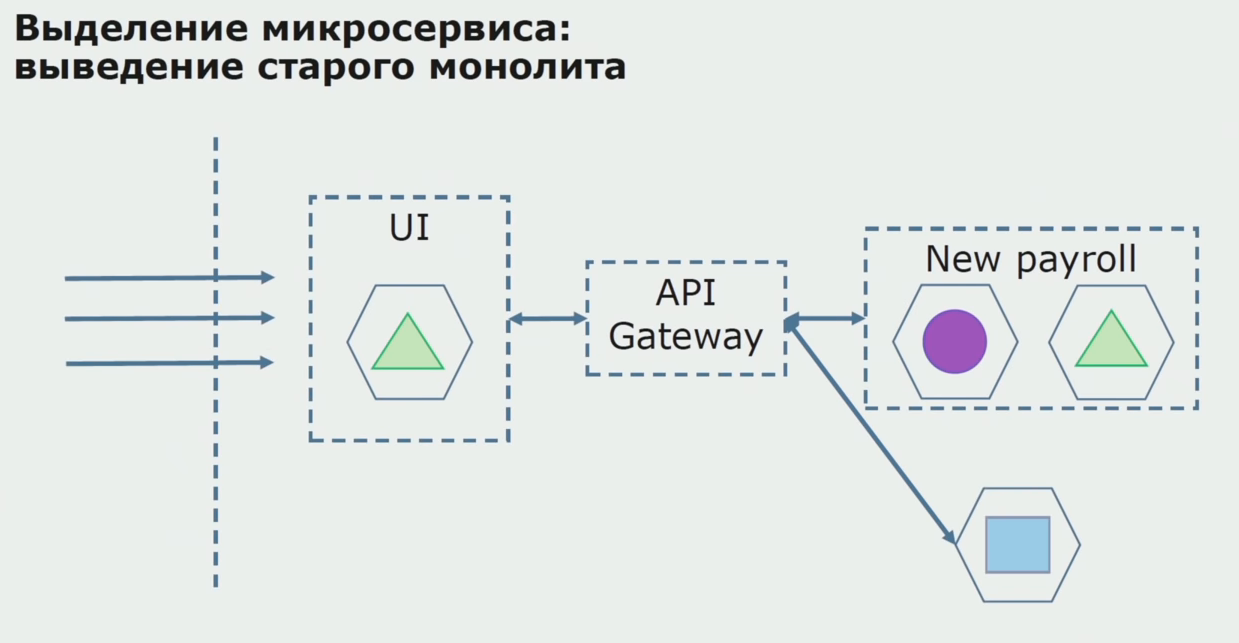
إجمالًا ، نستخدم جميع الطرق الموجودة تقريبًا لفصل شفرة مصدر متراصة. جميعها تسمح لنا بتقليل حجم أجزاء التطبيق ونقلها إلى مكتبات جديدة ، مما يجعل شفرة المصدر أفضل.
العمل مع DB
يمكن تقسيم قاعدة البيانات بشكل أسوأ من الكود المصدري ، حيث لا تحتوي فقط على المخطط الحالي ، ولكن أيضًا على البيانات التاريخية المتراكمة.
قاعدة البيانات لدينا ، مثلها مثل العديد من الآخرين ، كان لها عيب آخر مهم - حجمها الضخم. تم تصميم قاعدة البيانات هذه وفقًا لمنطق العمل المعقد الخاص بمجموعة متراصة ، وقد تراكمت الروابط بين جداول مختلف السياقات المحدودة.
في حالتنا ، لإكمال جميع المشكلات (قاعدة بيانات كبيرة ، علاقات كثيرة ، وأحيانًا حدود غير مفهومة بين الجداول) ، نشأت مشكلة في العديد من المشاريع الكبيرة: باستخدام قالب قاعدة البيانات المشتركة. تم نقل البيانات من الجداول إلى العرض ، من خلال النسخ المتماثل ، وشحنها إلى الأنظمة الأخرى حيث تكون هذه النسخ المتماثل مطلوبة. نتيجة لذلك ، لم نتمكن من إخراج الجداول في مخطط منفصل ، لأنها كانت تستخدم بنشاط.
يساعدنا الفصل في التفريق إلى سياقات محدودة في الكود. عادة ما يعطينا فكرة جيدة عن كيفية تقسيم البيانات على مستوى قاعدة البيانات. نحن نتفهم الجداول التي تتعلق بسياق محدود والتي تتعلق بسياق آخر.
طبقنا طريقتين عالميتين لتقسيم قاعدة البيانات: تقسيم الجداول الموجودة والتقسيم باستخدام المعالجة.
يعد فصل الجداول الحالية طريقة جيدة الاستخدام إذا كانت بنية البيانات عالية الجودة وتفي بمتطلبات العمل وتناسب الجميع. في هذه الحالة ، يمكننا تحديد الجداول الموجودة في مخطط منفصل.
هناك حاجة إلى قسم المعالجة عندما يتغير نموذج العمل كثيرًا ولم تعد الجداول ترضينا تمامًا.
افصل بين الجداول الموجودة. نحن بحاجة إلى تحديد ما سوف نفصل. بدون هذه المعرفة ، لن يأتي شيء منها ، وهنا يساعدنا الفصل بين السياقات المحدودة في الكود. كقاعدة عامة ، إذا كان من الممكن فهم حدود السياقات في الكود المصدري ، يصبح من الواضح الجداول التي يجب تضمينها في قائمة الفصل.
تخيل أن لدينا حلاً تتفاعل فيه وحدتان مترابطتان مع قاعدة بيانات واحدة. نحن بحاجة إلى التأكد من أن وحدة واحدة فقط تتفاعل مع جزء من الجداول المنفصلة ، والآخر يبدأ التفاعل معها من خلال API. بالنسبة للمبتدئين ، يكفي إدخال إدخال فقط من خلال واجهة برمجة التطبيقات. هذا شرط ضروري حتى نتمكن من التحدث عن استقلالية الخدمات الصغيرة. يمكن أن تظل روابط القراءة حتى توجد مشكلة كبيرة.

كخطوة تالية ، يمكننا بالفعل اختيار قسم الكود الذي يعمل مع الجداول القابلة للفصل مع أو بدون المعالجة في خدمة ميكروية منفصلة وتشغيلها في عملية منفصلة ، حاوية. ستكون هذه خدمة منفصلة مع التواصل مع قاعدة البيانات متراصة وتلك الجداول التي لا ترتبط مباشرة بها. متراصة لا يزال يتفاعل مع الجزء للانفصال للقراءة.

سنقوم في وقت لاحق بإزالة هذا الاتصال ، أي أن قراءة بيانات التطبيق المترابط من الجداول المنفصلة سيتم نقلها أيضًا إلى واجهة برمجة التطبيقات.
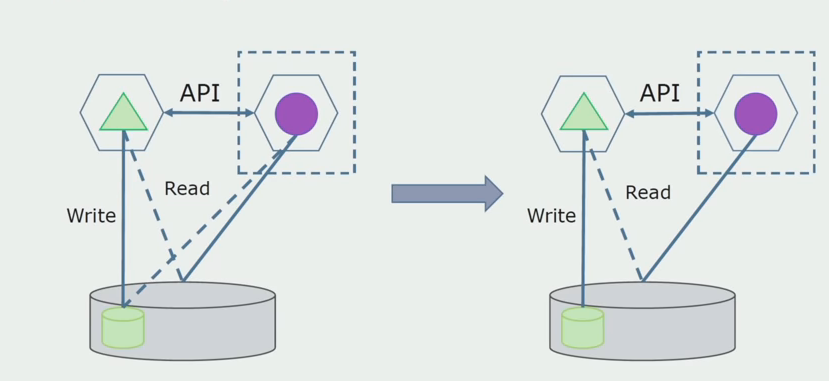
بعد ذلك ، نختار من قاعدة البيانات العامة الجداول التي تعمل بها فقط الخدمات المجهرية الجديدة. يمكننا وضع الجداول في مخطط منفصل أو حتى في قاعدة بيانات فعلية منفصلة. كان هناك اتصال للقراءة بين microservice وقاعدة البيانات متراصة ، ولكن لا يوجد شيء يدعو للقلق ، في هذا التكوين يمكن أن يعيش لفترة طويلة.
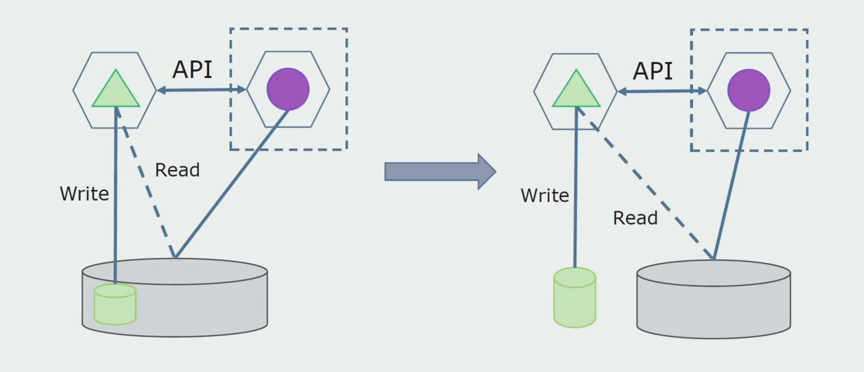
الخطوة الأخيرة هي إزالة جميع الاتصالات بالكامل. في هذه الحالة ، قد نحتاج إلى ترحيل البيانات من قاعدة البيانات الرئيسية. في بعض الأحيان نريد إعادة استخدام بعض البيانات أو الدلائل التي يتم نسخها نسخًا متماثلاً من الأنظمة الخارجية في قواعد بيانات متعددة. نلتقي بشكل دوري هذا.
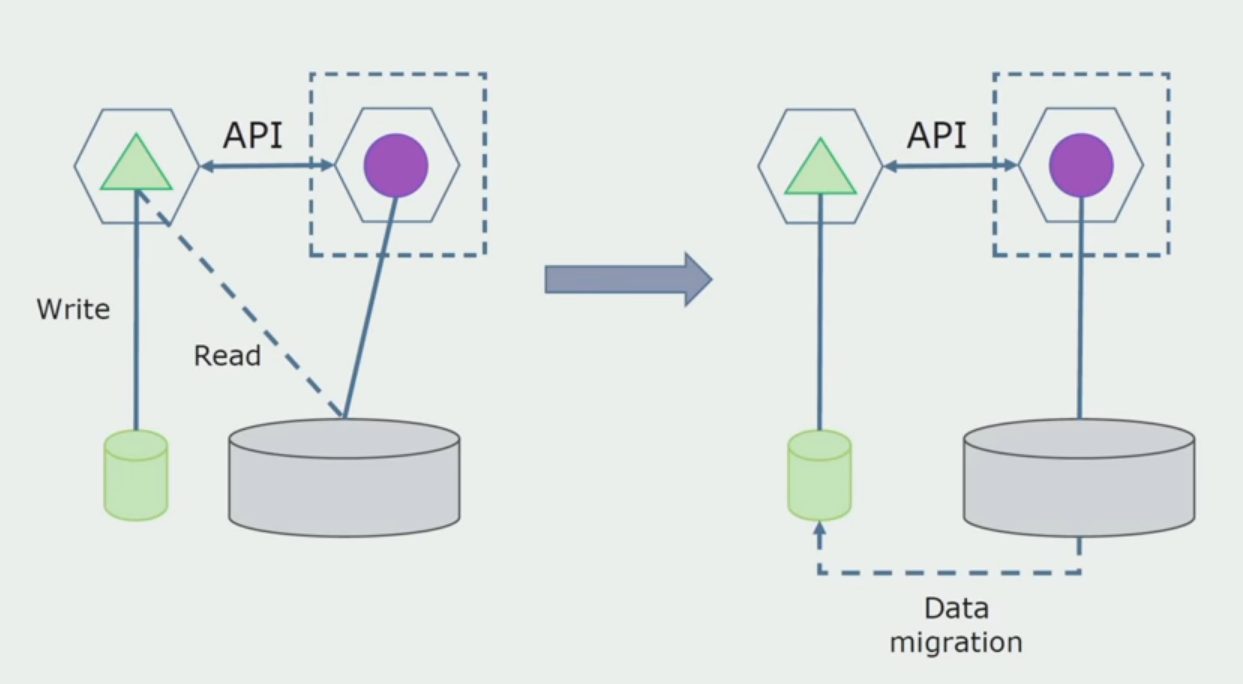 قسم المعالجة.
قسم المعالجة. هذه الطريقة تشبه إلى حد كبير الأولى ، يذهب فقط في الترتيب العكسي. لدينا على الفور قاعدة بيانات جديدة و microservice جديد يتفاعل مع متراصة من خلال API. ولكن في الوقت نفسه ، لا تزال هناك مجموعة من جداول قواعد البيانات التي نريد حذفها في المستقبل. لن نحتاج إليها بعد الآن ، في النموذج الجديد استبدلناها.
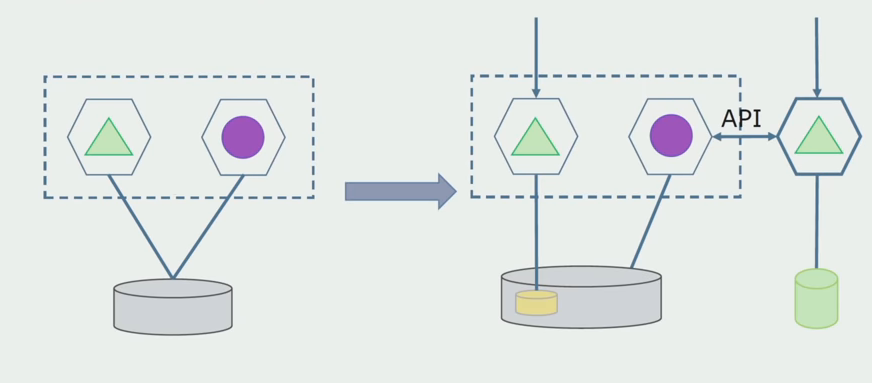
لكي ينجح هذا المخطط ، سنحتاج على الأرجح إلى فترة انتقالية.
هناك طريقتان ممكنتان.
أولاً : نقوم بتكرار جميع البيانات في قواعد البيانات الجديدة والقديمة. في هذه الحالة ، لدينا تكرار البيانات ، قد تكون هناك مشاكل في المزامنة. ولكن بعد ذلك يمكننا أن نأخذ عميلين مختلفين. واحد سيعمل مع الإصدار الجديد ، والآخر مع القديم.
ثانيًا : نشارك البيانات وفقًا لبعض الخصائص التجارية. على سبيل المثال ، في نظامنا ، كان هناك 5 منتجات مخزنة في قاعدة البيانات القديمة. السادس كجزء من مهمة تجارية جديدة ، وضعنا في قاعدة بيانات جديدة. لكننا نحتاج إلى واجهة برمجة تطبيقات Gateway ، التي تقوم بمزامنة هذه البيانات وتبين للعميل أين وماذا يأخذ.
كلا النهجين تعمل ، اختر وفقا للحالة.
بعد أن نتأكد من أن كل شيء يعمل ، يمكن تعطيل جزء متراصة الذي يعمل مع هياكل قاعدة البيانات القديمة.
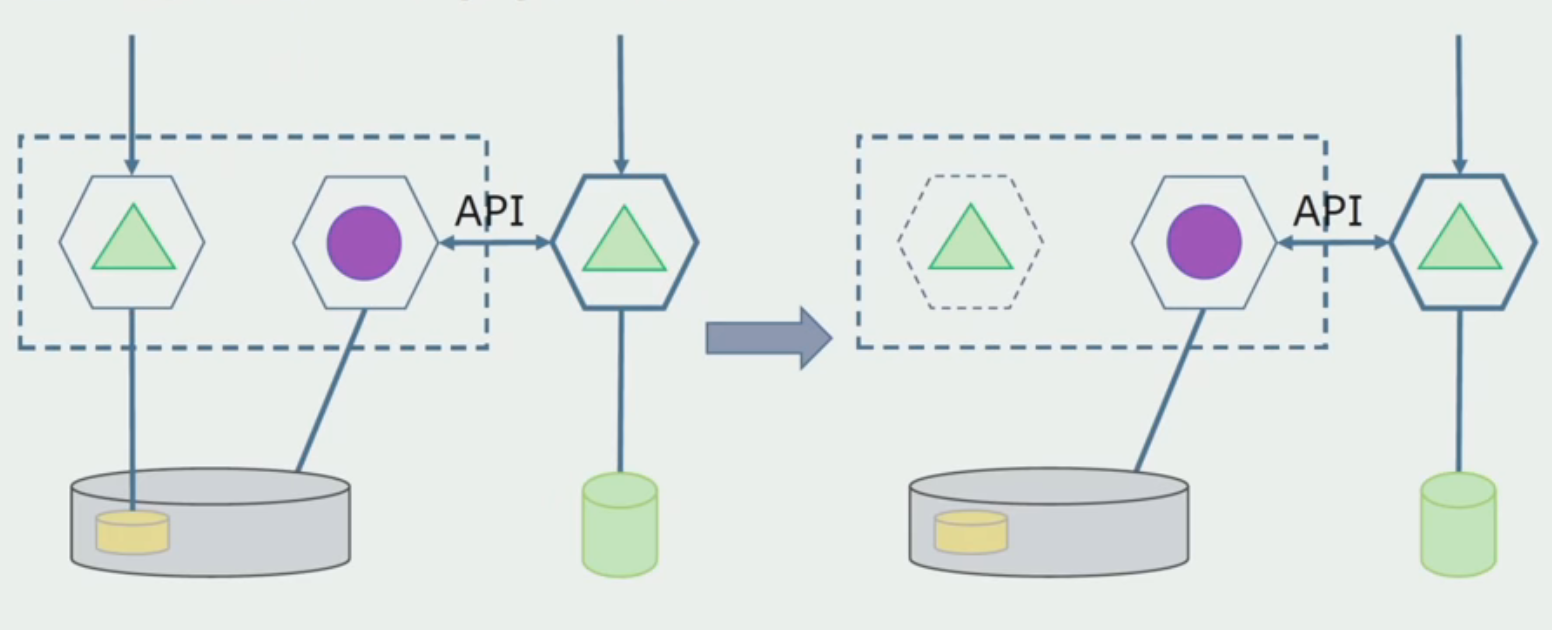
الخطوة الأخيرة هي إزالة بنيات البيانات القديمة.

بإيجاز ، يمكننا القول أن لدينا مشاكل في قاعدة البيانات: من الصعب التعامل معها مقارنة بالكود المصدري ، من الصعب الفصل ، لكن هذا يمكن ويجب القيام به. لقد وجدنا بعض الطرق التي تتيح القيام بذلك بأمان تام ، ومع ذلك فمن السهل ارتكاب خطأ في البيانات مقارنةً بالكود المصدر.
العمل مع شفرة المصدر
هذا ما بدا عليه مخطط شفرة المصدر عندما بدأنا تحليل مشروع مترابط.

يمكن تقسيمها بشروط إلى ثلاث طبقات. هذه طبقة من الوحدات النمطية والإضافات والخدمات والأنشطة الفردية التي تم إطلاقها. في الواقع ، كانت هذه هي نقاط الدخول في حل متآلف. كلهم كانوا مرتبطين بإحكام بطبقة مشتركة. كان لديه منطق عمل تم مشاركته بين الخدمات والعديد من الاتصالات. تستخدم كل خدمة ومكوّن إضافي ما يصل إلى 10 مجموعات شائعة أو أكثر ، اعتمادًا على حجمها وضمير المطورين.
كنا محظوظين ، كان لدينا مكتبات للبنية التحتية يمكن استخدامها بشكل منفصل.
في بعض الأحيان ، تنشأ حالة عندما لا تنتمي بعض الكائنات العامة إلى هذه الطبقة بالفعل ، ولكن كانت مكتبات البنية التحتية. وقد تقرر ذلك عن طريق إعادة تسمية.
الأكثر قلقا بشأن السياقات المحدودة. اعتادت أن تكون 3-4 سياقات مختلطة معًا في مجموعة واحدة مشتركة وتستخدم بعضها البعض في نفس وظائف الأعمال. كان من الضروري أن نفهم أين يمكن تقسيم ذلك وبأي حدود ، وما الذي يجب فعله بعد ذلك مع تعيين هذا الفصل في تجميعات الكود المصدري.
لقد قمنا بصياغة عدة قواعد لعملية فصل الشفرة.
أولاً : لم نعد نرغب في مشاركة منطق العمل بين الخدمات والأنشطة والإضافات. لقد أرادوا جعل منطق الأعمال مستقلًا في إطار الخدمات المصغرة. من ناحية أخرى ، يُنظر إلى الخدمات الميكروية ، في الحالة المثالية ، على أنها خدمات موجودة بشكل مستقل تمامًا. أعتقد أن هذا النهج يضيع إلى حد ما ، ومن الصعب تحقيقه ، لأنه ، على سبيل المثال ، سيتم توصيل الخدمات في C # في أي حال بواسطة مكتبة قياسية. نظامنا مكتوب بلغة C # ، ولم يتم استخدام تقنيات أخرى بعد. لذلك ، قررنا أن نتمكن من استخدام المجالس الفنية المشتركة. الشيء الرئيسي هو أنه ليس لديهم أي شظايا من منطق الأعمال. إذا كان لديك غلاف مناسب فوق ORM الذي تستخدمه ، فإن نسخه من خدمة إلى أخرى باهظ الثمن.
فريقنا من المعجبين بالتصميم الموجه نحو الموضوع ، وبالتالي فإن "هندسة البصل" مثالية لنا. الأساس في خدماتنا لم يكن طبقة الوصول إلى البيانات ، ولكن التجميع مع منطق المجال ، والذي يحتوي على منطق العمل فقط ويخلو من اتصالات البنية التحتية. في الوقت نفسه ، يمكننا تعديل مجموعة المجال بشكل مستقل لحل المشكلات المرتبطة بالأطر.
في هذه المرحلة ، التقينا أول مشكلة خطيرة. كان من المفترض أن تشير الخدمة إلى تجميع مجال واحد ، أردنا أن نجعل المنطق مستقلاً ، وهنا يتدخل مبدأ DRY بشدة معنا. لتجنب الازدواجية ، أراد المطورون إعادة استخدام الفئات من التجميعات المجاورة ، ونتيجة لذلك ، بدأت المجالات في التواصل مع بعضها البعض مرة أخرى. قمنا بتحليل النتائج وقررنا أن المشكلة ربما تكمن أيضًا في منطقة جهاز تخزين شفرة المصدر. كان لدينا مستودع كبير تكمن فيه جميع أكواد المصدر. كان حل المشروع بأكمله صعبًا للغاية لتجميعه على جهاز محلي. لذلك ، تم إنشاء حلول صغيرة منفصلة لأجزاء المشروع ، ولم يحظر أحد إضافة أي تجميع أو مجال مشترك إليهم وإعادة استخدامها. الأداة الوحيدة التي لم تسمح لنا بذلك هي كود المراجعة. لكن في بعض الأحيان انه تحطمت أيضا.
ثم بدأنا في التحول إلى نموذج مع مستودعات منفصلة. توقف منطق الأعمال عن التدفق من الخدمة إلى الخدمة ، وأصبحت المجالات مستقلة حقًا. يتم دعم السياقات المحدودة بشكل أكثر وضوحًا. كيف نعيد استخدام مكتبات البنية التحتية؟ قمنا بتخصيصها لمستودع منفصل ، ثم وضعناها في حزم Nuget التي وضعناها في Artifactory. مع أي تغيير ، يحدث التجميع والنشر تلقائيًا.
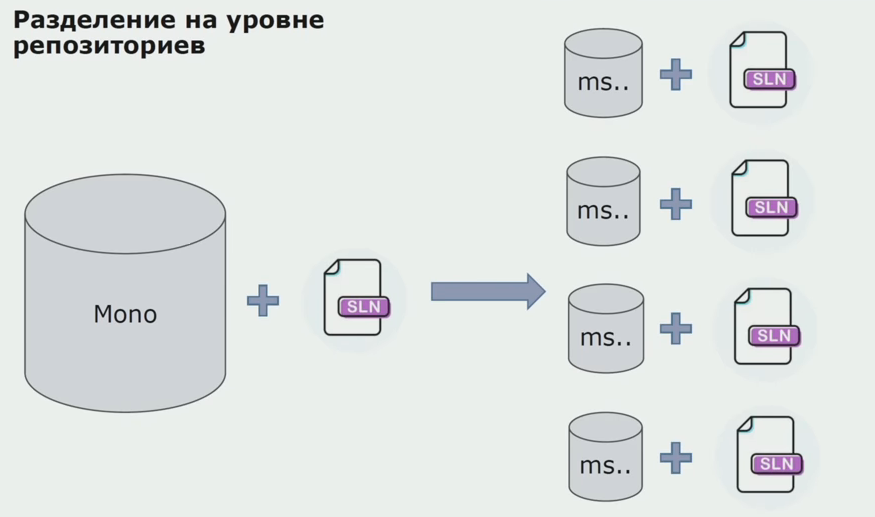
بدأت خدماتنا تشير إلى حزم البنية التحتية الداخلية بنفس طريقة حزم الخدمات الخارجية. نقوم بتنزيل المكتبات الخارجية من Nuget. للعمل مع Artifactory ، حيث وضعنا هذه الحزم ، استخدمنا مديري الحزم. في المستودعات الصغيرة ، استخدمنا أيضًا Nuget. في المستودعات التي تحتوي على العديد من الخدمات ، استخدمنا Paket ، والذي يوفر مزيدًا من تناسق الإصدار بين الوحدات النمطية.
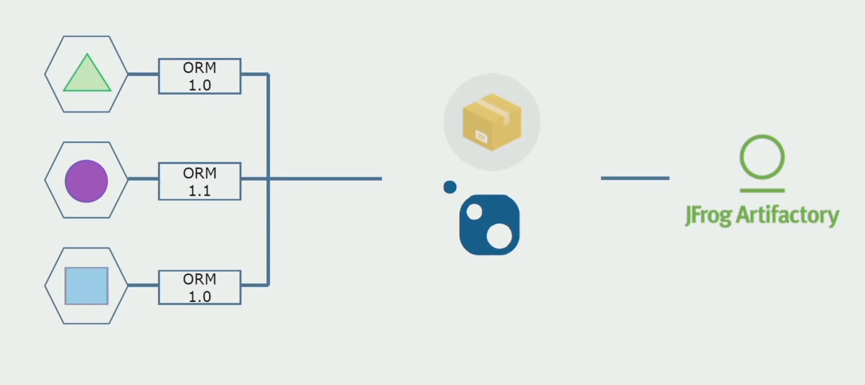
وبالتالي ، من خلال العمل على شفرة المصدر ، وتغيير البنية ومشاركة مستودعات التخزين قليلاً ، نجعل خدماتنا أكثر استقلالية.
قضايا البنية التحتية
ترتبط معظم الجوانب السلبية للتحول إلى الخدمات المصغرة بالبنية التحتية. ستحتاج إلى النشر التلقائي ، وستحتاج إلى مكتبات جديدة للبنية التحتية.
التثبيت اليدوي في البيئاتفي البداية ، قمنا بتثبيت الحل على البيئة يدويًا. لأتمتة هذه العملية ، أنشأنا خط أنابيب CI / CD. لقد اخترنا عملية التسليم المستمر ، لأن النشر المستمر بالنسبة لنا ليس مقبولًا من وجهة نظر العمليات التجارية. لذلك ، يتم الإرسال إلى التشغيل عن طريق الزر وللاختبار - تلقائيًا.
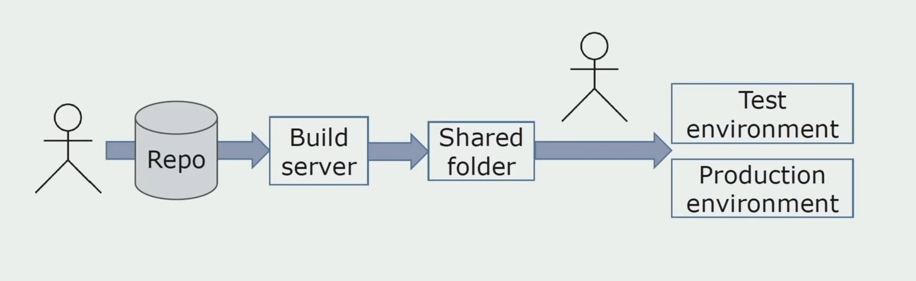
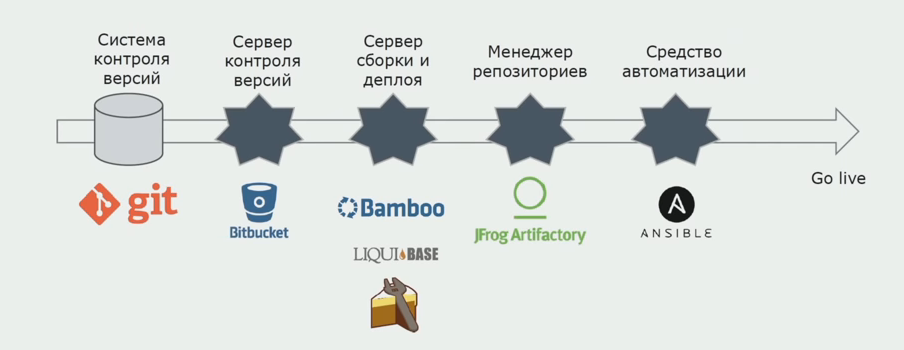
نستخدم Atlassian و Bitbucket لتخزين الكود المصدري و Bamboo للتجميع. نود كتابة البرامج النصية للتجميع في Cake لأنها نفس C #. تأتي الحزم الجاهزة إلى Artifactory ، ويصل Ansible تلقائيًا إلى خوادم الاختبار ، وبعد ذلك يمكن اختبارها على الفور.
تسجيل منفصلة
في وقت واحد ، كانت إحدى أفكار المتراصة هي توفير التسجيل المشترك. نحن بحاجة أيضًا إلى فهم ما يجب فعله بالسجلات الفردية الموجودة على الأقراص. سجلات مكتوبة لنا في الملفات النصية. قررنا استخدام مكدس ELK القياسي. لم نكتب مباشرةً إلى ELK من خلال موفري الخدمة ، لكننا قررنا وضع اللمسات الأخيرة على السجلات النصية وكتابة معرف التتبع فيها كمعرف ، مع إضافة اسم الخدمة بحيث يمكن تحليل هذه السجلات بعد ذلك.

باستخدام Filebeat ، نحصل على فرصة لجمع سجلاتنا من الخوادم ، ثم تحويلها ، باستخدام Kibana لإنشاء الطلبات في واجهة المستخدم ومشاهدة كيفية انتقال المكالمة بين الخدمات. معرف التتبع يساعد كثيرا في هذا.
اختبار وتصحيح الخدمات ذات الصلة
في البداية ، لم نفهم تمامًا كيفية تصحيح الخدمات المتقدمة. كان كل شيء بسيطًا مع المتراصة ، وقمنا بتشغيله على الجهاز المحلي. في البداية ، حاولوا أن يفعلوا الشيء نفسه مع خدمات microservices ، ولكن في بعض الأحيان لإطلاق خدمة microservice كاملة واحدة ، يجب أن تبدأ العديد من الخدمات الأخرى ، وهذا غير مريح. , , , . , prod. , , . , , .
, production- . , .
Specflow. NUnit Ansible. , . - . , , Jira.
, . JMeter, — InfluxDB, — Grafana.
?
-, «». , production-, -. 1,5 , , .
. , , . .
. , .
, . , . Scrum-. , .
- . , , , . .
- . , , . , , , Scrum.
- — . . . legacy, , .
: . . , , , , , , , — , . . , , .
PS ( ) – .
.