يواجه كل نظام مراقبة ثلاثة أنواع من مشاكل الأداء.
أولاً ، ينبغي لنظام مراقبة جيد استلام البيانات الواردة من الخارج ومعالجتها وتسجيلها بسرعة كبيرة. يذهب الحساب إلى ميكروثانية. قد يبدو هذا غير مفعم بالحيوية ، لكن عندما يصبح النظام كبيرًا بما فيه الكفاية ، يتم تلخيص كل هذه الكسور من الثواني ، وتتحول إلى تأخيرات ملحوظة بوضوح.

المهمة الثانية هي توفير وصول سهل إلى مجموعة كبيرة من المقاييس التي تم جمعها مسبقًا (بمعنى آخر ، إلى البيانات التاريخية). يتم استخدام البيانات التاريخية في مجموعة واسعة من السياقات. على سبيل المثال ، يتم إنشاء تقارير ورسومات بيانية منها ، ويتم بناء عمليات تدقيق مجمعة عليها ، وتعتمد المشغلات عليها. إذا كان هناك أي تأخير في الوصول إلى السجل ، فإن هذا يؤثر على الفور على سرعة النظام بأكمله ككل.
ثالثًا ، البيانات التاريخية تشغل مساحة كبيرة. حتى تكوينات المراقبة المتواضعة نسبيًا تكتسب تاريخًا قويًا. ولكن لا يكاد أي شخص يريد الاحتفاظ بسجل تحميل المعالج لمدة خمس سنوات في متناول اليد ، لذلك يجب ألا يكون نظام المراقبة قادرًا على تسجيله جيدًا فحسب ، ولكن أيضًا حذف السجل جيدًا (في Zabbix تسمى هذه العملية "التدبير المنزلي"). ليس من الضروري أن يكون حذف البيانات القديمة بنفس كفاءة جمع البيانات الجديدة وتحليلها ، ولكن عمليات الحذف الثقيلة تعتمد على موارد إدارة قواعد البيانات الثمينة ويمكن أن تؤدي إلى إبطاء العمليات الأكثر أهمية.
يتم حل المشاكل الأولين عن طريق التخزين المؤقت. يدعم Zabbix العديد من ذاكرات التخزين المؤقت المتخصصة لتسريع عمليات قراءة وكتابة البيانات. آليات DBMS أنفسهم ليست مناسبة هنا ، لأن لن تعرف خوارزمية التخزين المؤقت للأغراض العامة الأكثر تقدماً أي هياكل بيانات تتطلب الوصول الفوري في وقت معين.
الرصد وبيانات السلاسل الزمنية
كل شيء على ما يرام طالما كانت البيانات في ذاكرة خادم Zabbix. لكن الذاكرة ليست لانهائية وفي بعض الأحيان تحتاج البيانات إلى كتابتها (أو قراءتها) إلى قاعدة البيانات. وإذا كان أداء قاعدة البيانات متأخرا بجدية عن سرعة جمع المقاييس ، فلن تساعد خوارزميات التخزين المؤقت الخاصة الأكثر تقدمًا لفترة طويلة.
تكمن المشكلة الثالثة أيضًا في أداء قاعدة البيانات. لحلها ، تحتاج إلى اختيار استراتيجية حذف موثوقة لا تتداخل مع عمليات قاعدة البيانات الأخرى. بشكل افتراضي ، يحذف Zabbix البيانات التاريخية على دفعات من عدة آلاف من السجلات في الساعة. يمكنك تكوين فترات تدبير منزلي أطول أو أحجام حزم أكبر إذا كانت سرعة جمع البيانات والمكان في قاعدة البيانات تسمح بذلك. ولكن مع وجود عدد كبير للغاية من المقاييس و / أو ارتفاع وتيرة جمعها ، يمكن أن يكون إعداد التدبير المنزلي المناسب مهمة شاقة ، لأن جدول حذف البيانات قد لا يواكب وتيرة تسجيل بيانات جديدة.
باختصار ، يحل نظام المراقبة مشاكل الأداء في ثلاثة اتجاهات - جمع البيانات الجديدة وكتابتها إلى قاعدة البيانات باستخدام استعلامات SQL INSERT ، والوصول إلى البيانات باستخدام استعلامات SELECT ، وحذف البيانات باستخدام DELETE. لنرى كيف يتم تنفيذ استعلام SQL النموذجي:
- يقوم DBMS بتحليل الاستعلام والتحقق من وجود أخطاء في بناء الجملة. إذا كان الطلب صحيحًا بناءً على ذلك ، فإن المحرك يبني شجرة بناء جملة لمزيد من المعالجة.
- يقوم مخطط الاستعلام بتحليل شجرة بناء الجملة ويحسب الطرق المختلفة (المسارات) لتنفيذ الطلب.
- يحسب المجدول أرخص طريقة. في هذه العملية ، يأخذ في الاعتبار الكثير من الأشياء - كم هي كبيرة الجداول ، هل من الضروري فرز النتائج ، هل هناك فهارس قابلة للتطبيق على الاستعلام ، إلخ.
- عند العثور على المسار الأمثل ، يقوم المحرك بتنفيذ الاستعلام عن طريق الوصول إلى كتل البيانات المطلوبة (باستخدام الفهارس أو المسح التسلسلي) ، ويطبق معايير الفرز والتصفية ، ويجمع النتيجة ويعيدها إلى العميل.
- لإدراج الاستعلامات وتعديلها وحذفها ، يجب على المحرك أيضًا تحديث الفهارس للجداول المقابلة. بالنسبة للجداول الكبيرة ، قد تستغرق هذه العملية وقتًا أطول من العمل مع البيانات نفسها.
- على الأرجح ، سيقوم نظام إدارة قواعد البيانات بتحديث الإحصاءات الداخلية لاستخدام البيانات للمكالمات اللاحقة لجدولة الاستعلام.
بشكل عام ، هناك الكثير من العمل. توفر معظم نظم إدارة قواعد البيانات طنًا من الإعدادات لتحسين الاستعلام ، لكنها عادةً ما تركز على بعض تدفقات العمل المتوسطة التي يتم فيها إدراج وحذف السجلات بنفس التردد الذي يحدث فيه التغيير.
ومع ذلك ، كما ذكر أعلاه ، بالنسبة لأنظمة المراقبة ، فإن العمليات الأكثر شيوعًا تقوم بإضافة وحذف دوري في وضع الدُفعات. لا يتم تغيير البيانات المضافة سابقًا تقريبًا ، ويتضمن الوصول إلى البيانات استخدام وظائف مجمعة. بالإضافة إلى ذلك ، عادةً ما يتم ترتيب قيم المقاييس المضافة حسب الوقت. يشار عادةً إلى هذه البيانات بالسلاسل
الزمنية :
السلسلة الزمنية هي سلسلة من نقاط البيانات المفهرسة (أو المدرجة أو الكتابة على الجدران) بترتيب مؤقت.
من وجهة نظر قاعدة البيانات ، تحتوي السلاسل الزمنية على الخصائص التالية:
- يمكن تحديد موقع السلاسل الزمنية على القرص كسلسلة من الكتل الزمنية المطلوبة.
- يمكن فهرسة جداول السلاسل الزمنية باستخدام عمود زمني.
- تستخدم معظم استعلامات SQL SELECT جمل WHERE أو GROUP BY أو ORDER BY في عمود يشير إلى الوقت.
- عادةً ما يكون لبيانات السلاسل الزمنية "تاريخ انتهاء الصلاحية" وبعد ذلك يمكن حذفها.
من الواضح أن قواعد بيانات SQL التقليدية ليست مناسبة لتخزين هذه البيانات ، لأن تحسينات الأغراض العامة لا تأخذ هذه الصفات في الاعتبار. لذلك ، في السنوات الأخيرة ، ظهر عدد قليل جدًا من قواعد بيانات إدارة قواعد البيانات الجديدة الموجهة للوقت ، مثل InfluxDB ، على سبيل المثال. لكن جميع نظم إدارة قواعد البيانات (DBMS) الشائعة للسلسلة الزمنية لها عيب واحد كبير - عدم وجود دعم SQL كامل. علاوة على ذلك ، معظمهم ليسوا حتى CRUD (إنشاء ، قراءة ، تحديث ، حذف).
هل تستطيع Zabbix استخدام قواعد البيانات هذه بأي طريقة؟ أحد الأساليب الممكنة هو نقل البيانات التاريخية للتخزين إلى قاعدة بيانات خارجية متخصصة في السلسلة الزمنية. بالنظر إلى أن بنية Zabbix تدعم الخلفية الخارجية لتخزين البيانات التاريخية (على سبيل المثال ، يتم تطبيق دعم Elasticsearch في Zabbix) ، يبدو هذا الخيار للوهلة الأولى معقولاً للغاية. ولكن إذا دعمنا واحدًا أو أكثر من قواعد بيانات قواعد البيانات (DBMS) للسلسلة الزمنية كخوادم خارجية ، فسيتعين على المستخدمين حساب النقاط التالية:
- نظام آخر يحتاج إلى استكشاف وتكوينه وصيانته. مكان آخر لتتبع الإعدادات ومساحة القرص وسياسات التخزين والأداء ، إلخ.
- الحد من التسامح مع الخطأ لنظام الرصد ، كما يظهر رابط جديد في سلسلة المكونات ذات الصلة.
بالنسبة لبعض المستخدمين ، قد تفوق فوائد التخزين المخصص المخصص للبيانات التاريخية إزعاج القلق بشأن نظام آخر. لكن بالنسبة للكثيرين ، هذا تعقيد غير ضروري. تجدر الإشارة إلى أنه نظرًا لأن معظم هذه الحلول المتخصصة لها واجهات برمجة التطبيقات الخاصة بها ، فإن درجة تعقيد الطبقة العالمية للعمل مع قواعد بيانات Zabbix ستزداد بشكل ملحوظ. ونحن ، من الناحية المثالية ، نفضل إنشاء وظائف جديدة ، بدلاً من محاربة واجهات برمجة التطبيقات الأخرى.
السؤال الذي يطرح نفسه - هل هناك طريقة للاستفادة من نظم إدارة قواعد البيانات للسلسلة الزمنية ، ولكن دون أن تفقد مرونة ومزايا SQL؟ بطبيعة الحال ، لا توجد إجابة شاملة ، ولكن حل واحد محدد اقترب جدًا من الإجابة -
TimescaleDB .
ما هو TimescaleDB؟
TimescaleDB (TSDB) هو امتداد PostgreSQL يعمل على تحسين العمل مع السلاسل الزمنية في قاعدة بيانات PostgreSQL (PG) منتظمة. على الرغم من أنه ، كما ذكر أعلاه ، لا يوجد نقص في حلول السلاسل الزمنية القابلة للتطوير في السوق ، إلا أن الميزة الفريدة لـ TimescaleDB هي قدرتها على العمل بشكل جيد مع السلاسل الزمنية دون التضحية بتوافق وفوائد قواعد البيانات الترابطية التقليدية لـ CRUD. في الممارسة العملية ، هذا يعني أننا نحصل على أفضل ما في العالمين. تعرف قاعدة البيانات الجداول التي ينبغي اعتبارها سلاسل زمنية (وتطبيق جميع التحسينات اللازمة) ، ولكن يمكنك العمل معها بنفس طريقة استخدام الجداول العادية. علاوة على ذلك ، لا يُطلب من التطبيقات معرفة أن البيانات يتم التحكم فيها بواسطة TSDB!
لتمييز جدول كجدول سلسلة زمنية (في TSDB يسمى هذا hypertable) ، فقط استدعاء إجراء TSDB create_ hypertable (). تحت الغطاء ، يقوم TSDB بتقسيم هذا الجدول إلى ما يسمى بالشظايا (المصطلح الإنكليزي مقطع) وفقًا للشروط المحددة. يمكن تمثيل الشظايا كأقسام يتم التحكم فيها تلقائيًا من الجدول. كل جزء له نطاق زمني المقابلة. لكل جزء ، يقوم TSDB أيضًا بتعيين فهارس خاصة بحيث لا يؤثر العمل مع نطاق بيانات واحد على الوصول إلى الآخرين.
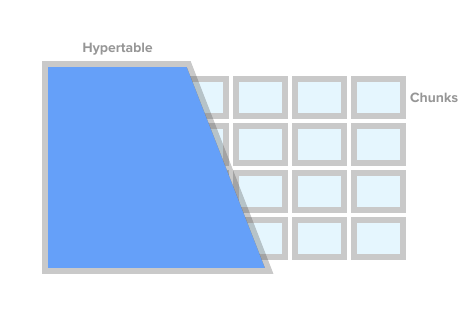 Hypertable Image from timescaledb.com
Hypertable Image from timescaledb.comعندما يضيف التطبيق قيمة جديدة للسلسلة الزمنية ، يوجه الامتداد هذه القيمة إلى الجزء المطلوب. إذا لم يتم تحديد نطاق وقت القيمة الجديدة ، فسيقوم TSDB بإنشاء جزء جديد وتعيين النطاق المطلوب وإدخال القيمة هناك. إذا طلب أحد التطبيقات بيانات من hypertable ، فقبل تنفيذ الطلب ، يتحقق الملحق من الأجزاء التي ترتبط بهذا الطلب.
لكن هذا ليس كل شيء. يستكمل TSDB نظام PostgreSQL الإيكولوجي القوي الذي تم اختباره بمرور الوقت مع مجموعة من تغييرات الأداء وقابلية التوسع. وتشمل هذه الإضافة السريعة للسجلات الجديدة واستعلامات الوقت السريعة وحذف الدُفعات المجانية تقريبًا.
كما ذُكر سابقًا ، من أجل التحكم في حجم قاعدة البيانات والامتثال لسياسات الاستبقاء (أي لا تخزن البيانات لفترة أطول من اللازم) ، يجب أن يحل حل المراقبة الجيد كمية كبيرة من البيانات التاريخية بشكل فعال. مع TSDB ، يمكننا حذف القصة المطلوبة ببساطة عن طريق حذف شظايا معينة من hypertable. في هذه الحالة ، لا يحتاج التطبيق إلى تتبع الأجزاء بالاسم أو أي روابط أخرى ، وسوف يحذف TSDB جميع الأجزاء الضرورية وفقًا للشرط الزمني المحدد.
TimescaleDB و PostgreSQL التقسيم
للوهلة الأولى ، قد يبدو أن TSDB عبارة عن غلاف جميل حول التقسيم القياسي لجداول PG (
التقسيم التعريفي ، كما يطلق عليه رسمياً في PG10). في الواقع ، لتخزين البيانات التاريخية ، يمكنك استخدام التقسيم القياسي PG10. ولكن إذا نظرت عن كثب ، فإن شظايا TSDB وقسم PG10 أبعد ما تكون عن المفاهيم المماثلة.
بادئ ذي بدء ، يتطلب إعداد التقسيم في PG فهمًا أعمق للتفاصيل ، التي يجب أن يقوم بها التطبيق نفسه أو DBMS بطريقة جيدة. أولاً ، تحتاج إلى تخطيط التسلسل الهرمي للقسم الخاص بك وتحديد ما إذا كنت تريد استخدام الأقسام المتداخلة. ثانياً ، تحتاج إلى الخروج بمخطط تسمية القسم ونقله بطريقة ما إلى البرامج النصية لإنشاء المخطط. على الأرجح ، سيتضمن نظام التسمية التاريخ و / أو الوقت ، وستحتاج هذه الأسماء إلى أتمتة بطريقة أو بأخرى.
بعد ذلك ، تحتاج إلى التفكير في كيفية حذف البيانات منتهية الصلاحية. في TSDB ، يمكنك ببساطة استدعاء أمر drop_chunks () ، الذي يحدد الأجزاء المراد حذفها لفترة زمنية محددة. في PG10 ، إذا كنت بحاجة إلى إزالة مجموعة معينة من القيم من أقسام PG القياسية ، فسيتعين عليك حساب قائمة أسماء الأقسام لهذا النطاق بنفسك. إذا كان مخطط التقسيم المحدد يتضمن مقاطع متداخلة ، فسيؤدي ذلك إلى زيادة تعقيد الحذف.
هناك مشكلة أخرى يجب معالجتها وهي ما يجب فعله بالبيانات التي تتجاوز النطاقات الزمنية الحالية. على سبيل المثال ، قد تأتي البيانات من مستقبل لم يتم إنشاء أقسام له بعد. أو من الماضي للأقسام المحذوفة بالفعل. بشكل افتراضي في PG10 ، لن يعمل إضافة مثل هذا السجل وسنفقد البيانات ببساطة. في PG11 ، يمكنك تحديد قسم افتراضي لمثل هذه البيانات ، لكن هذا يخفي المشكلة مؤقتًا فقط ولا يحلها.
بالطبع ، يمكن حل جميع المشاكل المذكورة أعلاه بطريقة أو بأخرى. يمكنك تعليق القاعدة باستخدام المشغلات ، وكرات الزيز ورشها بحرية باستخدام البرامج النصية. سيكون قبيحًا ، لكنه وظيفي. ليس هناك شك في أن أقسام PG أفضل من الجداول المتجانسة العملاقة ، ولكن ما لم يتم حلها بالتأكيد من خلال البرامج النصية والمشغلات هو تحسينات في السلاسل الزمنية لا تملك PG.
أي مقارنة بأقسام PG ، تتميز أدوات Hypertable TSDB بشكل إيجابي ليس فقط عن طريق توفير أعصاب مسؤولي DB ، ولكن أيضًا عن طريق تحسين الوصول إلى البيانات وإضافة أخرى جديدة. على سبيل المثال ، الشظايا في TSDB هي دائمًا صفيف أحادي البعد. يعمل ذلك على تبسيط إدارة الأجزاء وتسريع عمليات الإدراج والتحديدات. لإضافة بيانات جديدة ، يستخدم TSDB خوارزمية التوجيه الخاصة به في الجزء المرغوب فيه ، والذي ، على عكس PG القياسي ، لا يفتح جميع الأقسام على الفور. مع وجود عدد كبير من الأقسام ، يمكن أن يختلف الاختلاف في الأداء بشكل كبير. يمكن العثور على التفاصيل الفنية حول الفرق بين التقسيم القياسي في PG و TSDB في
هذه المقالة .
Zabbix و TimescaleDB
من بين جميع الخيارات ، يبدو أن TimescaleDB هو الخيار الأكثر أمانًا لـ Zabbix ومستخدميه:
- تم تصميم TSDB كملحق PostgreSQL ، وليس كنظام مستقل. لذلك ، لا يتطلب أجهزة إضافية أو أجهزة افتراضية أو أي تغييرات أخرى في البنية التحتية. يمكن للمستخدمين الاستمرار في استخدام الأدوات التي اختاروها لبرنامج PostgreSQL.
- TSDB يسمح لك بحفظ تقريبا كل رمز للعمل مع قاعدة البيانات في Zabbix دون تغيير.
- TSDB يحسن بشكل كبير أداء مزامن التاريخ ومدبرة المنزل.
- عتبة الدخول المنخفضة - المفاهيم الأساسية لـ TSDB بسيطة ومباشرة.
- إن التثبيت السهل والتكوين لكل من الامتداد نفسه و Zabbix سيساعد بشكل كبير مستخدمي الأنظمة الصغيرة والمتوسطة.
دعونا نرى ما يجب القيام به لبدء TSDB مع Zabbix المثبتة حديثا. بعد تثبيت Zabbix وتشغيل البرامج النصية لإنشاء قاعدة بيانات PostgreSQL ، تحتاج إلى تنزيل TSDB وتثبيته على النظام الأساسي المطلوب. انظر تعليمات التثبيت
هنا . بعد تثبيت الامتداد ، تحتاج إلى تمكينه لقاعدة Zabbix ، ثم قم بتشغيل البرنامج النصي timecaledb.sql الذي يأتي مع Zabbix. إنه موجود إما في قاعدة البيانات / postgresql / timecaledb.sql إذا كان التثبيت من المصدر أو في /usr/share/zabbix/database/timecaledb.sql.gz إذا كان التثبيت من الحزم. هذا كل شئ! يمكنك الآن بدء تشغيل خادم Zabbix وسيعمل مع TSDB.
البرنامج النصي timescaledb.sql تافه. كل ما يفعله هو تحويل الجداول التاريخية العادية Zabbix إلى TSDB hypertables وتغيير الإعدادات الافتراضية - تعيين المعلمات Override history history period و Override item direction period. الآن (الإصدار 4.2) تعمل جداول Zabbix التالية تحت تحكم TSDB - history ، history_uint ، history_str ، history_log ، history_text ، والاتجاهات و direction_uint. يمكن استخدام البرنامج النصي نفسه لترحيل هذه الجداول (لاحظ أنه تم تعيين المعلمة migrate_data على صواب). يجب ألا يغيب عن البال أن ترحيل البيانات عملية طويلة جدًا وقد تستغرق عدة ساعات.
قد تتطلب المعلمة chunk_time_interval => 86400 أيضًا إجراء تغييرات قبل تشغيل timecaledb.sql ، Chunk_time_interval هو الفاصل الزمني الذي يحد من وقت القيم التي تقع في هذا الجزء. على سبيل المثال ، إذا قمت بتعيين الفاصل الزمني chunk_time_interval إلى 3 ساعات ، فسيتم توزيع بيانات اليوم بأكمله على 8 أجزاء ، مع تغطية الجزء الأول رقم 1 الساعات الثلاث الأولى (0: 00-2: 59) ، والجزء الثاني رقم 2 - الثانية 3 ساعات ( 3: 00-5: 59) ، إلخ سوف تحتوي القطعة الأخيرة رقم 8 على قيم في وقت 21: 00-23: 59. 86400 ثانية (يوم واحد) هي القيمة الافتراضية المتوسطة ، ولكن قد يرغب مستخدمو الأنظمة المحملة في تقليلها.
من أجل تقدير متطلبات الذاكرة تقريبًا ، من المهم فهم مقدار المساحة التي يمكن أن تشغلها قطعة واحدة في المتوسط. المبدأ العام هو أنه يجب أن يكون لدى النظام ذاكرة كافية لترتيب جزء واحد على الأقل من كل hypertable. في الوقت نفسه ، بالطبع ، لا ينبغي أن يتناسب مجموع أحجام الأجزاء مع الذاكرة بهامش فقط ، بل يجب أن يكون أيضًا أقل من قيمة المعلمة Shared_buffers من postgresql.conf. يمكن العثور على مزيد من المعلومات حول هذا الموضوع في وثائق TimescaleDB.
على سبيل المثال ، إذا كان لديك نظام يجمع مقاييس عدد صحيح بشكل رئيسي وقررت تقسيم جدول history_uint إلى أجزاء من ساعتين ، وتقسيم الجداول المتبقية إلى أجزاء من يوم واحد ، فأنت بحاجة إلى تغيير هذا الخط في timecaledb.sql:
SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 7200, migrate_data => true);
بعد تجميع كمية معينة من البيانات القديمة ، يمكنك التحقق من أحجام الأجزاء لجدول history_uint عن طريق استدعاء chunk_relation_size ():
zabbix=> SELECT chunk_table,total_bytes FROM chunk_relation_size('history_uint'); chunk_table | total_bytes -----------------------------------------+------------- _timescaledb_internal._hyper_2_6_chunk | 13287424 _timescaledb_internal._hyper_2_7_chunk | 13172736 _timescaledb_internal._hyper_2_8_chunk | 13344768 _timescaledb_internal._hyper_2_9_chunk | 13434880 _timescaledb_internal._hyper_2_10_chunk | 13230080 _timescaledb_internal._hyper_2_11_chunk | 13189120
يمكن تكرار هذه المكالمة للعثور على أحجام الشظايا لجميع hypertables. على سبيل المثال ، إذا تبين أن حجم الجزء الخاص بـ history_uint هو 13 ميجابايت ، فإن الأجزاء الخاصة بجداول المحفوظات الأخرى ، 20 ميجابايت على سبيل المثال ، وجداول الاتجاه 10 ميجابايت ، فإن متطلبات الذاكرة الإجمالية هي 13 + 4 × 20 + 2 × 10 = 113 ميجابايت. يجب أن نترك أيضًا مساحة من buffers المشتركة لتخزين البيانات الأخرى ، على سبيل المثال 20٪. ثم يجب تعيين قيمة Shared_buffers على 113MB / 0.8 = ~ 140MB.
لضبط أدق TSDB ، ظهرت الأداة المساعدة لضبط الوقت. يقوم بتحليل postgresql.conf ، ويربطه بتكوين النظام (الذاكرة والمعالج) ، ثم يقدم توصيات بشأن تعيين معلمات الذاكرة ، معلمات للمعالجة المتوازية ، WAL. تقوم الأداة المساعدة بتغيير ملف postgresql.conf ، لكن يمكنك تشغيله باستخدام المعلمة -dry-run والتحقق من التغييرات المقترحة.
سنناقش معلمات Zabbix فترة تجاوز عنصر السجل وفترة اتجاه عنصر التخطي (متوفرة في الإدارة -> عام -> التدبير المنزلي). هناك حاجة لحذف البيانات التاريخية كأجزاء كاملة من TSDB hypertables ، وليس السجلات.
الحقيقة هي أن Zabbix يسمح لك بتعيين فترة التدبير المنزلي لكل عنصر البيانات (متري) على حدة. ومع ذلك ، يتم تحقيق هذه المرونة عن طريق مسح قائمة العناصر وحساب فترات فردية في كل تكرار للتدبير المنزلي. إذا كان لدى النظام فترات تدبير منزلي فردية للعناصر الفردية ، فمن الواضح أن النظام لا يمكن أن يكون لديه نقطة فصل واحدة لجميع المقاييس معًا ولن يتمكن Zabbix من إعطاء الأمر الصحيح لحذف الأجزاء الضرورية. وبالتالي ، من خلال إيقاف تشغيل سجل تجاوز المقاييس ، ستفقد Zabbix القدرة على حذف المحفوظات بسرعة عن طريق استدعاء إجراء drop_chunks () لجداول history_ * ، وبالتالي ، فإن إيقاف تشغيل اتجاهات Override سيفقد نفس الوظيفة للجداول trend_ *.
وبعبارة أخرى ، للاستفادة الكاملة من نظام التدبير المنزلي الجديد ، تحتاج إلى جعل كلا الخيارين عالميًا. في هذه الحالة ، لن تقرأ عملية التدبير المنزلي إعدادات عنصر البيانات على الإطلاق.
الأداء مع TimescaleDB
حان الوقت للتحقق مما إذا كان كل ما سبق يعمل فعليًا. إن مقعد الاختبار الخاص بنا هو Zabbix 4.2rc1 مع PostgreSQL 10.7 و TimescaleDB 1.2.1 لـ Debian 9. آلة الاختبار هي Intel Xeon ذات 10 نواة مع 16 جيجابايت من ذاكرة الوصول العشوائي و 60 جيجابايت من مساحة التخزين على SSD. وفقًا لمعايير اليوم ، يعد هذا تكوينًا متواضعًا للغاية ، ولكن هدفنا هو معرفة مدى فعالية TSDB في الحياة الحقيقية. في التكوينات بميزانية غير محدودة ، يمكنك ببساطة إدخال 128-256 جيجابايت من ذاكرة الوصول العشوائي ووضع معظم (إن لم يكن كل) قاعدة البيانات في الذاكرة.
يتكون تكوين الاختبار من 32 وكيلًا نشطًا من Zabbix ينقلون البيانات مباشرةً إلى خادم Zabbix. يخدم كل وكيل 10000 عنصر. يتم تعيين ذاكرة التخزين المؤقت Zabbix التاريخية على 256 ميغابايت ، ويتم تعيين Shared_buffers PG إلى 2GB. يوفر هذا التكوين حمولة كافية على قاعدة البيانات ، ولكن في نفس الوقت لا يُنشئ حمولة كبيرة على عمليات خادم Zabbix. لتقليل عدد الأجزاء المتحركة بين مصادر البيانات وقاعدة البيانات ، لم نستخدم Zabbix Proxy.
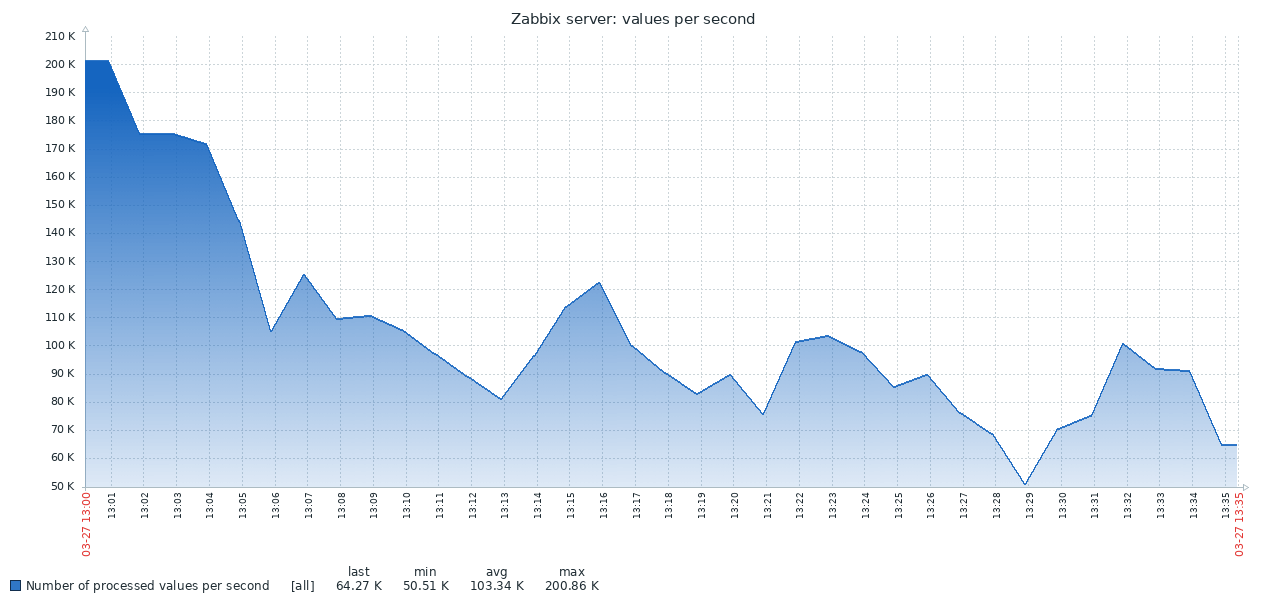
هذه هي النتيجة الأولى التي تم الحصول عليها من نظام PG القياسي:
نتيجة TSDB مختلفة تمامًا:

الرسم البياني أدناه يجمع بين كل من النتائج. يبدأ العمل بقيم NVPS المرتفعة إلى حد ما في 170-200 ألف ، لأن يستغرق بعض الوقت لملء ذاكرة التخزين المؤقت المحفوظات قبل أن تبدأ المزامنة مع قاعدة البيانات.
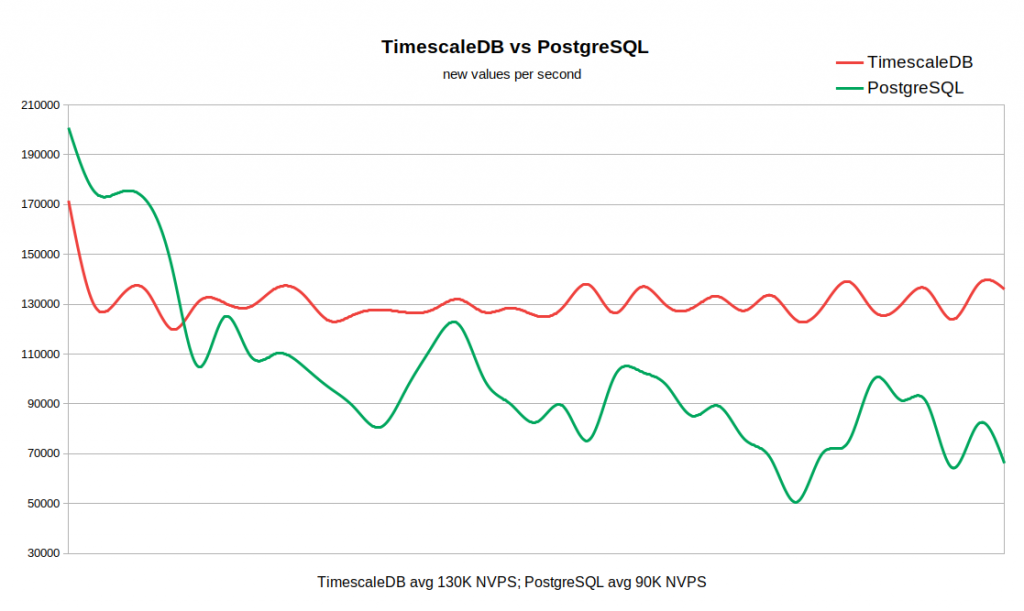
عندما يكون جدول المحفوظات فارغًا ، تكون سرعة الكتابة في TSDB قابلة للمقارنة مع سرعة الكتابة في PG ، وحتى مع وجود هامش صغير من الأخير. بمجرد أن يصل عدد السجلات في التاريخ إلى ما بين 50 إلى 60 مليون ، تنخفض سرعة إنتاج PG إلى 110 كيلوبايت (NVPS) ، ولكن ، ما هو أكثر غير سارة ، يستمر في التغير عكسياً مع عدد السجلات المتراكمة في الجدول التاريخي. في الوقت نفسه ، يحافظ TSDB على سرعة ثابتة تبلغ 130 كيلوبايت (NVPS) طوال الاختبار من 0 إلى 300 مليون سجل.
في المجموع ، في مثالنا ، الفرق في متوسط الأداء كبير جدًا (130 ألفًا مقابل 90 ألفًا دون مراعاة الذروة الأولية). كما لوحظ أن معدل الإدراج في PG قياسي يختلف على نطاق واسع. وبالتالي ، إذا تطلب سير العمل تخزين عشرات أو مئات الملايين من السجلات في التاريخ ، ولكن لا توجد موارد لاستراتيجيات التخزين المؤقت شديدة العدوانية ، فإن TSDB هو مرشح قوي لاستبدال PG القياسي.
إن ميزة TSDB واضحة بالفعل لهذا النظام المتواضع نسبيًا ، ولكن على الأرجح سيصبح الفرق أكثر وضوحًا في صفيفات كبيرة من البيانات التاريخية. من ناحية أخرى ، فإن هذا الاختبار ليس تعميمًا لجميع السيناريوهات المحتملة للعمل مع Zabbix. بطبيعة الحال ، هناك العديد من العوامل التي تؤثر على النتائج ، مثل تكوينات الأجهزة ، وإعدادات نظام التشغيل ، وإعدادات خادم Zabbix والتحميل الإضافي من الخدمات الأخرى التي تعمل في الخلفية. وهذا هو ، قد تختلف الأميال الخاص بك.
استنتاج
TimescaleDB هي تقنية واعدة للغاية. لقد تم بالفعل تشغيلها بنجاح في بيئات إنتاج خطيرة. TSDB يعمل بشكل جيد مع Zabbix ويوفر مزايا كبيرة عبر قاعدة بيانات PostgreSQL القياسية.
هل لدى TSDB أي عيوب أو أسباب لتأجيل استخدامه؟ من الناحية الفنية ، لا نرى أي جدال ضدها. ولكن ينبغي أن يؤخذ في الاعتبار أن التكنولوجيا لا تزال جديدة ، مع دورة إطلاق غير مستقرة واستراتيجية غير واضحة لتطوير الوظيفة. على وجه الخصوص ، يتم إصدار إصدارات جديدة مع تغييرات كبيرة كل شهر أو شهرين. قد تتم إزالة بعض الوظائف ، كما حدث ، على سبيل المثال ، مع قطع الاتصال التكييفية. بشكل منفصل ، كعامل آخر لعدم اليقين ، تجدر الإشارة إلى سياسة الترخيص. إنه أمر محير للغاية لأن هناك ثلاثة مستويات من الترخيص. يتم تصنيع TSDB kernel بموجب ترخيص Apache ، ويتم إصدار بعض الوظائف بموجب ترخيص Timescale الخاص به ، ولكن هناك أيضًا إصدار مغلق من Enterprise.
إذا كنت تستخدم Zabbix مع PostgreSQL ، فلا يوجد سبب على الأقل لعدم تجربة TimescaleDB. ربما يفاجئك هذا الأمر بكل سرور: فقط ضع في اعتبارك أن دعم TimescaleDB في Zabbix لا يزال تجريبيًا - لفترة من الوقت ، بينما نقوم بجمع مراجعات المستخدمين واكتساب الخبرة.