باستخدام nginx لموازنة حركة مرور HTTP على مستوى L7 ، من الممكن إرسال طلب عميل إلى خادم التطبيق التالي إذا كان الهدف لا يُرجع استجابة إيجابية. أظهر اختبار لآلية التحقق السلبي للحالة الصحية لخادم التطبيق غموض الوثائق وخصوصية الخوارزميات لاستبعاد الخادم من مجموعة خوادم الإنتاج.
ملخص موازنة حركة مرور HTTP
هناك طرق مختلفة لموازنة حركة مرور HTTP. حسب مستويات نموذج OSI ،
هناك تقنيات موازنة على مستويات الشبكة والنقل والتطبيق.
يمكن استخدام المجموعات وفقًا لحجم التطبيق.
توفر تقنية موازنة الحركة تأثيرات إيجابية في التطبيق وصيانته. وهنا بعض منهم. التحجيم الأفقي للتطبيق ، حيث
يتم توزيع الحمل بين عدة عقد . المخطط إيقاف تشغيل خادم التطبيق عن طريق إزالة تدفق طلبات العميل منه. تنفيذ استراتيجية اختبار A / B للوظائف المتغيرة للتطبيق. تحسين التسامح مع أخطاء التطبيق عن طريق
إرسال الطلبات إلى خوادم التطبيقات التي تعمل بشكل جيد .
يتم تنفيذ الوظيفة الأخيرة في وضعين. في الوضع الخامل ، يقوم الموازن في حركة مرور العميل بتقييم استجابات خادم التطبيق الهدف ويستبعده من مجموعة خوادم الإنتاج وفقًا لشروط معينة. في الوضع النشط ، يرسل الموازن بشكل دوري طلبات إلى خادم التطبيق على URI المحدد ، وبالنسبة لبعض علامات الاستجابة تقرر استبعاده من مجموعة خوادم الإنتاج. بعد ذلك ، يقوم الموازن ، في ظل ظروف معينة ، بإرجاع خادم التطبيق إلى مجموعة خوادم الإنتاج.
التحقق السلبي لخادم التطبيق واستبعاده من مجموعة خوادم الإنتاج
دعونا نلقي نظرة فاحصة على خادم التطبيق السلبي تحقق في إصدار مجانية من nginx / 1.17.0. يتم تحديد خوادم التطبيقات بدورها بواسطة خوارزمية Round Robin ، والأوزان الخاصة بها هي نفسها.
يُظهر الرسم التخطيطي المكون من ثلاث خطوات قسمًا للوقت يبدأ بإرسال طلب العميل إلى خادم التطبيق رقم 2. يميز المؤشر الساطع الطلبات / الاستجابات بين العميل والموازن. مؤشر غامق - طلبات / استجابات بين nginx وخوادم التطبيقات.
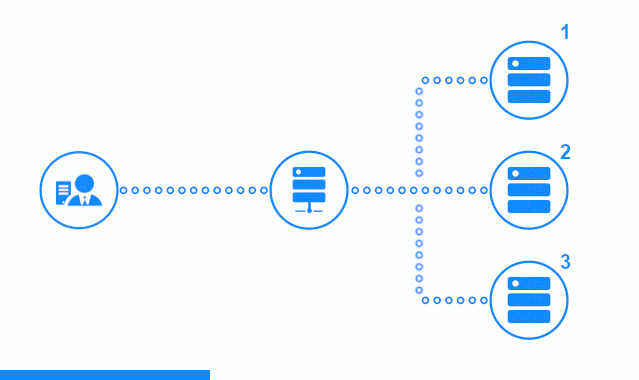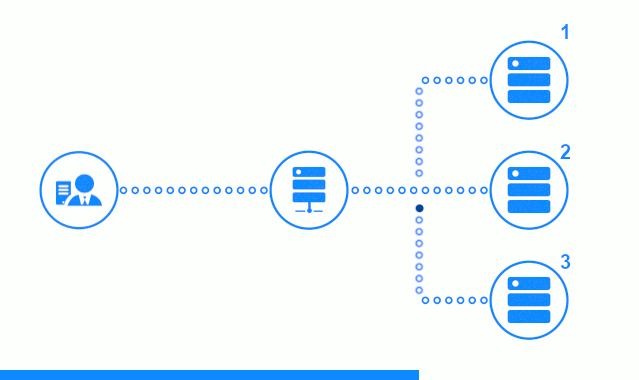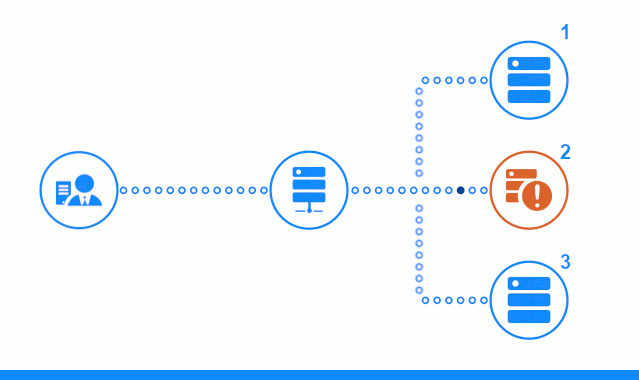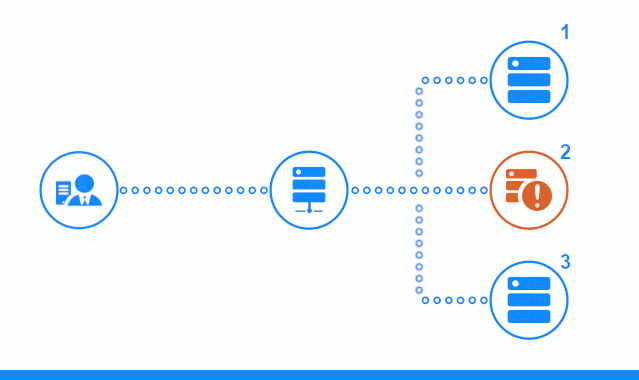
توضح الخطوة الثالثة من المخطط كيفية إعادة موازن توجيه طلب العميل إلى خادم التطبيق التالي في حالة قيام الخادم الهدف بتقديم استجابة خطأ أو لم يرد على الإطلاق.
يتم تحديد قائمة أخطاء HTTP و TCP التي يستخدم فيها الخادم الخادم التالي في توجيه
proxy_next_upstream .
بشكل افتراضي ، يعيد nginx توجيه
الطلبات فقط
باستخدام أساليب HTTP idempotent إلى خادم التطبيق التالي.
ماذا يحصل العميل؟ من ناحية ، تزيد القدرة على إعادة توجيه الطلب إلى خادم التطبيق التالي من فرص تقديم استجابة مرضية للعميل عند فشل الخادم الهدف. من ناحية أخرى ، من الواضح أن المكالمة التسلسلية الأولى للخادم الهدف ، ثم إلى التالي تزيد من زمن الاستجابة الكلي للعميل.
في النهاية ،
يتم إرجاع استجابة خادم التطبيق إلى العميل
، حيث تنتهي العدادات proxy_next_upstream_tries المسموح بها .
عند استخدام وظيفة إعادة التوجيه إلى خادم العمل التالي ، ستحتاج إلى مواءمة المهلات على خوادم الموازن والتطبيقات بشكل إضافي. الحد الأقصى لوقت طلب "السفر" بين خوادم التطبيقات والموازن هو مهلة العميل ، أو وقت الانتظار المحدد من قبل الشركة. عند حساب المهلات ، من الضروري أيضًا مراعاة هامش أحداث الشبكة (التأخيرات / الخسائر أثناء تسليم الحزمة). إذا انتهى العميل في كل مرة من الجلسة بوقت انتهاء مهلة بينما يحصل الموازن على إجابة مضمونة ، فإن النية الطيبة لجعل التطبيق يمكن الاعتماد عليه ستكون عقيمة.

يتم التحكم في التحقق من الصحة السلبية لخوادم التطبيقات من خلال التوجيهات ، على سبيل المثال ، مع الخيارات التالية لقيمها:
upstream backend { server app01:80 weight=1 max_fails=5 fail_timeout=100s; server app02:80 weight=1 max_fails=5 fail_timeout=100s; } server { location / { proxy_pass http://backend; proxy_next_upstream timeout http_500; proxy_next_upstream_tries 1; ... } ... }
اعتبارًا من 2 يوليو
2019 ،
أثبتت الوثائق أن المعلمة
max_fails تعيّن عدد المحاولات غير الناجحة للعمل مع الخادم الذي يجب أن يحدث خلال الوقت المحدد بواسطة المعلمة
fail_timeout .
تعيّن المعلمة
fail_timeout الوقت الذي يجب أن يحدث خلاله العدد المحدد من المحاولات غير الناجحة للعمل مع الخادم من أجل اعتبار الخادم غير متوفر ؛ والوقت الذي سيتم فيه اعتبار الخادم غير متاح.
في المثال المحدد ، وهو جزء من ملف التكوين ، يتم تكوين الموازن لجذب 5 مكالمات فاشلة في غضون 100 ثانية.
إرجاع خادم التطبيق إلى تجمع خادم الإنتاج
كما يلي من الوثائق ، لا يمكن
للموازن بعد
fail_timeout اعتبار الخادم غير
صالح للعمل. ولكن ، لسوء الحظ ، لا تحدد الوثائق بشكل صريح كيفية تقييم أداء الخادم.
بدون تجربة ، يمكن للمرء أن يفترض فقط أن آلية التحقق من الحالة تشبه الآلية الموصوفة مسبقًا.
التوقعات والواقع
في التكوين المقدم ، من المتوقع حدوث السلوك التالي من الموازن:
- حتى يستبعد الموازن خادم التطبيق رقم 2 من مجموعة خوادم الإنتاج ، سيتم إرسال طلبات العميل إليه.
- سيتم إعادة توجيه الطلبات التي يتم إرجاعها مع وجود خطأ 500 من خادم التطبيق رقم 2 إلى خادم التطبيق التالي ، وسوف يتلقى العميل ردودًا إيجابية.
- بمجرد أن يتلقى الموازن 5 ردود بالكود 500 في غضون 100 ثانية ، فسيستبعد خادم التطبيق رقم 2 من مجموعة خوادم الإنتاج. سيتم إرسال جميع الطلبات التالية بعد 100 ثانية على الفور إلى خوادم تطبيقات العمل المتبقية دون وقت إضافي.
- بعد 100 ثانية ، بطريقة ما ، يجب على الموازن تقييم أداء خادم التطبيق وإعادته إلى مجموعة خوادم الإنتاج.
بعد إجراء اختبارات عينية ، وفقًا لمجلات الموازن ، ثبت أن البيان رقم 3 لا يعمل. يستبعد الموازن خادم الخمول بمجرد استيفاء الشرط في المعلمة
max_fails . وبالتالي ، يتم استبعاد خادم فاشل من الخدمة دون انتظار مرور 100 ثانية. تلعب المعلمة
fail_timeout دور الحد الأعلى لوقت تراكم الأخطاء فقط.
كجزء من التأكيد رقم 4 ، اتضح أن nginx يتحقق من وظيفة أحد التطبيقات التي كانت مستبعدة سابقًا من صيانة الخادم بطلب واحد فقط. وإذا كان الخادم لا يزال يستجيب مع وجود خطأ ، فسوف
يفشل الفحص التالي بعد
fail_timeout .
ما هو مفقود؟
- قد لا تكون الخوارزمية المطبقة في nginx / 1.17.0 هي الطريقة الأكثر إنصافًا للتحقق من أداء الخادم قبل إعادته إلى مجموعة خوادم الإنتاج. على الأقل ، وفقًا للوثائق الحالية ، ليس من المتوقع طلب واحد ، ولكن المبلغ المحدد في max_fails .
- لا تأخذ خوارزمية التحقق من الحالة في الاعتبار سرعة الطلبات. كلما زاد حجمها ، كان الطيف الأقوى مع المحاولات غير الناجحة ينتقل إلى اليسار ، وخرج خادم التطبيق من تجمع الخوادم العاملة بسرعة كبيرة. أفترض أن هذا يمكن أن يؤثر سلبًا على التطبيقات التي تسمح لأنفسها بإحداث أخطاء "تجلطات زمنية قصيرة". على سبيل المثال ، عند جمع القمامة.

أردت أن أسألك عما إذا كان هناك أي فائدة عملية من خوارزمية فحص صحة الخادم ، والتي تقيس سرعة المحاولات الفاشلة؟