أثناء الجلسة التدريبية (مايو-يونيو وديسمبر-يناير) ، يطلب المستخدمون منا التحقق من القروض التي تصل إلى 500 وثيقة في كل دقيقة. تأتي المستندات في ملفات بتنسيقات مختلفة ، ويختلف تعقيد العمل مع كل منها. للتحقق من مستند للاقتراض ، نحتاج أولاً إلى استخراج نصه من الملف ، وفي الوقت نفسه التعامل مع التنسيق. وتتمثل المهمة في تنفيذ استخراج عالي الجودة لنصف ألف نص مع التنسيق في الدقيقة ، مع انخفاضه بشكل نادر (أو من الأفضل عدم السقوط على الإطلاق) ، واستهلاك موارد قليلة وعدم دفع نصف ميزانية المجرة لتطوير وتشغيل منشئ الأفكار النهائي.
نعم ، نعم ، بالطبع ، نحن نعلم أنه من بين ثلاثة أشياء - بسرعة ، بثمن بخس وكفاءة - تحتاج إلى اختيار أي شيئين. ولكن الشيء الأكثر سوءًا هو أنه في حالتنا لا يمكننا حذف أي شيء. والسؤال هو كيف فعلنا ذلك ...

مصدر الصورة: ويكيبيديا
كثيرا ما يقال لنا إن مصير الناس يعتمد على نوعية عملنا. لذلك ، عليك أن تثقيف في نفسك الكمال. بالطبع ، نحن نعمل باستمرار على تحسين جودة النظام (في جميع الجوانب) ، حيث يتوصل المؤلفون عديمي الضمير إلى طرق جديدة لحلها. وآمل أن يقترب اليوم الذي يؤدي فيه تعقيد الخداع ، من ناحية ، والشعور بالرضا من العمل الجيد الذي قام به ، من ناحية أخرى ، إلى دفع الغالبية العظمى من الطلاب إلى التخلي عن رغبتهم الحبيبة في الاحتيال. في الوقت نفسه ، نحن نفهم أن ثمن الخطأ يمكن أن يكون المعاناة المحتملة للأبرياء إذا مزيفنا فجأة.
لماذا انا؟ إذا كنا نشعر بالكمال ، فسنقترب بعناية من كتابة سلسلة من المقالات حول عمل نظام مكافحة الانتحال . سنضع بصعوبة خطة للنشر لتحديد كل شيء بالطريقة الأكثر منطقية والمتوقعة للقارئ:
- أولاً ، سنتحدث عن كيفية هيكلة نظامنا ( المنشور الخامس عن Habré) ، وسوف نصف المراحل الرئيسية الثلاثة لمعالجة المستند عند فحصه للاقتراض:
- استخراج نص المستند (أنت هنا!) ؛
- البحث عن القروض (قطع بالفعل في العديد من مقالاتنا ) ؛
- بناء تقرير عن الوثيقة (في الخطط).
- علاوة على ذلك ، سنبدأ في تكريس القارئ لجهاز آليات مساعدة مثيرة للاهتمام ، مثل البحث عن قروض قابلة للتحويل ( المادة الأولى ) ، وتعريف إعادة الصياغة ( الرابعة ) والتصنيف المواضيعي ( الثاني ).
- وأخيرا ، وصلنا إلى محرك البحث - فهرس القوباء المنطقية ( المادة السابعة ).
يجب أن يكون القارئ المهتم قد لاحظ أننا ما زلنا لا نعاني من الكمالية المفرطة ، لذلك حان الوقت للانتقال إلى المرحلة الأولى - استخراج النصوص وتنسيق المستندات. هذا هو ما سنفعله اليوم ، في الطريقة التي نفكر فيها بموت الوجود والنور في نهاية النفق ، وعن عدم وجود أي شيء مثالي وعن السعي لتحقيق التفوق ، وعن وجود خطة واتباعها وعن التسويات التي تميلنا إليها الحياة دائمًا.
في البداية كانت الكلمة
في البداية ، استخرجنا من المستندات أكثر المستندات اللازمة للتحقق منها عند الاقتراض - نص المستندات نفسها. تم دعم التنسيقات الرئيسية - docx ، doc ، txt ، pdf ، rtf ، html. ثم تمت إضافة ppt ، pptx ، odt ، epub ، fb2 ، djvu الأقل شيوعًا ، ومع ذلك ، كان من الضروري رفض العمل مع معظمهم في المستقبل . تمت معالجة كل منها بطريقتها الخاصة - في مكان ما في مكتبة منفصلة ، في مكان ما في محللها الخاص. في المتوسط ، استمر استخراج النص حول مئات الميلي ثانية. يبدو أن الصعوبة الرئيسية والوحيدة تقريبًا في استخراج النص هي "تحليل" التنسيق نفسه ، وهذا ينطبق بشكل خاص على تنسيقات pdf و doc الثنائية ( والطبيعة المملوكة للأخيرة تجعل العمل معها أكثر إشكالية). ومع ذلك ، في هذه المرحلة بالفعل ، عندما كانت رغباتنا تقتصر فقط على استخراج النص ، أصبح من الواضح أن أي طريقة لقراءة الأشكال التي نحتاجها تجلب معها عددًا من الميزات غير السارة. وأهمها:
- توجد استثناءات حتى عند معالجة بعض المستندات الصالحة ، ناهيك عن معالجة المستندات "المعطلة" المشكلة بشكل غير صحيح. ما يخلق المزيد من المشاكل هو أن الكود الأصلي يمكن أن يسقط ، ومعالجة مثل هذه المواقف في .net code صعبة ؛
- الاستهلاك غير المرتفع للذاكرة ، والذي يمكن أن يضر كل من العمليات المجاورة والوقت الحالي بمعالجة وثيقة "المشكلة" (نفاد الذاكرة في الشفرة المدارة أو غير المُدارة) ؛
- معالجة طويلة جدًا لوثيقة ما ، تفاقمت بسبب الافتقار إلى آليات الإلغاء لمعظم المكتبات ، وأحيانًا بسبب تعقيد (قراءة: يكاد يكون من المستحيل) إلغاء مكالمة رمز غير مدار من مكالمة مُدارة ؛
- "استخراج النص من المستندات." إنشاء نص مستند pdf (وهذا التنسيق هو المفتاح بالنسبة لنا) ، والذي تم بالفعل تحليله ، على عكس التوقعات ، هو مهمة غير تافهة. والحقيقة هي أن تنسيق pdf تم تطويره في الأصل بشكل أساسي للعرض الإلكتروني لمواد الطباعة. النص في ملفات pdf هو مجموعة من كتل النصوص الموجودة على صفحات الوثيقة. علاوة على ذلك ، يمكن أن تكون الكتلة فقرة من النص أو حرف واحد. تكمن مهمة استعادة النص في شكله الأصلي من مجموعة الكتل هذه في المكتبة (الكود / البرنامج) الذي يقرأ المستند. نعم ، يوفر التنسيق ، بدءًا من إصدار معين منه ، القدرة على تحديد ترتيب القطع ، ولكن لسوء الحظ ، فإن المستندات التي تحتوي على تسلسل ملحوظ من كتل النص نادر. لذلك ، تحتوي مكتبات قراءة نصوص pdf على عدد من
الأساليب البحثية (حسنًا ، من المعتاد هنا: التعلم الآلي ، البيانات الكبيرة ، blockchain ، ...) التي تسمح لك باستعادة النص في النموذج الصحيح بدرجة أو بأخرى ، وكما هو متوقع ، تختلف النتيجة التي يتم الحصول عليها من مكتبة إلى أخرى .

أسفل الصورة المصدر: المادة
أعلى مصدر الصورة: هم ...
بحاجة الى مزيد من البيانات!
إذا كانت الخلفية النصية للمستند كافية لتحليل مستند للاقتراض ، فإن تنفيذ عدد من الميزات الجديدة أمر مستحيل أو صعب للغاية دون استخراج بيانات إضافية من المستند. اليوم ، بالإضافة إلى خلفية النص ، نقوم أيضًا باستخراج تنسيق المستند وتقديم صور الصفحة. نستخدم هذا الأخير للتعرف على النص البصري ( OCR ) ، وكذلك لتحديد بعض أنواع التجاوزات.
تنسيق المستند يتضمن الترتيب الهندسي لجميع الكلمات والحروف على الصفحات ، وكذلك حجم الخط لجميع الأحرف. تتيح لنا هذه المعلومات:
- عرض تقرير التحقق من المستند بشكل جميل ، ورسم الاقتراض المكتشفة مباشرةً على المستند الأصلي ؛

- لتحديد كتل المستندات (صفحة العنوان ، المراجع ) بدقة أكبر واسترداد بيانات التعريف الخاصة بها (المؤلفون ، المسمى الوظيفي ، السنة ومكان العمل ، إلخ) ؛
- الكشف عن محاولات تجاوز النظام.
لتوحيد معالجة المستندات ومجموعة من البيانات المستخرجة ، نقوم بتحويل المستندات بجميع التنسيقات التي ندعمها إلى pdf. وبالتالي ، يتم إجراء استخراج بيانات المستند على مرحلتين:
- تحويل وثيقة لقوات الدفاع الشعبي.
- استخراج البيانات من قوات الدفاع الشعبي.
تحويل إلى قوات الدفاع الشعبي. اختيار المكتبة
نظرًا لأنه ليس من السهل أخذ المستند وتحويله إلى pdf ، فقد قررنا عدم إعادة اختراع العجلة واستكشاف حلول جاهزة ، واختيار الأنسب لنا. كان مرة أخرى في عام 2017.
معايير اختيار المرشحين:
- مكتبة على. صافي ، مثالي. صافي الأساسية وعبر منصة
المفسد!نتيجة لذلك ، في تلك اللحظة ، كان الهدف المثالي بعيد المنال
- دعم التنسيقات المطلوبة - doc ، docx ، rtf ، odf ، ppt ، pptx
- استقرار
- إنتاجية
- جودة الدعم الفني
- سعر الإصدار
قمنا بتحليل الحلول المتاحة ، من بينها ستة الحلول الأنسب لمهامنا:
يتطلب كل من MS Word Interop و Neevia Document Converter Pro و DynamicPdf تثبيت MS Office على الإنتاج ، مما قد يؤدي في النهاية إلى ربطنا بنظام Windows. لذلك ، لم نعد نعتبر هذه الخيارات.
وبالتالي ، لدينا ثلاثة من المرشحين الرئيسيين اليسار ، واحد منهم فقط يدعم بالكامل جميع الأشكال التي نحتاجها. حسنا ، لقد حان الوقت لنرى ما يمكنهم.
لاختبار المكتبات ، شكلنا عينة من 120 ألف مستند مستخدم حقيقي ، وهي نسبة التنسيقات التي تتوافق تقريبًا مع ما نراه كل يوم على الإنتاج.
لذلك الجولة الأولى. دعونا نرى ما هي نسبة الوثائق التي يمكن تحويلها بنجاح إلى مكتبات pdf قيد الدراسة. بنجاح ، في حالتنا ، هو عدم وضع استثناء ، وتلبية مهلة 3 دقائق وإرجاع نص غير فارغ.
تميز Syncfusion على الفور ، والذي لم يكن فقط قادرًا على معالجة أصغر عدد من المستندات بنجاح ، ولكن أيضًا تم إلقاء العملية برمتها على بعض المستندات (إنشاء استثناءات مثل OutOfMemoryException أو استثناءات من الكود الأصلي الذي لم يتم اكتشافه دون الرقص باستخدام الدف).
فشلت GroupDocs في معالجة حوالي 5.5 مرة أكثر من مستندات DevExpress (يمكن رؤية كل شيء على اللوحة أعلاه). هذا على الرغم من حقيقة أن ترخيص مطور واحد من GroupDocs هو حوالي 9 أضعاف تكلفة ترخيص مطور واحد من DevExpress. هذا هو الحال ، بالمناسبة.
الاختبار الجاد الثاني هو وقت التحويل ، وهو نفس 120 ألف مستند:
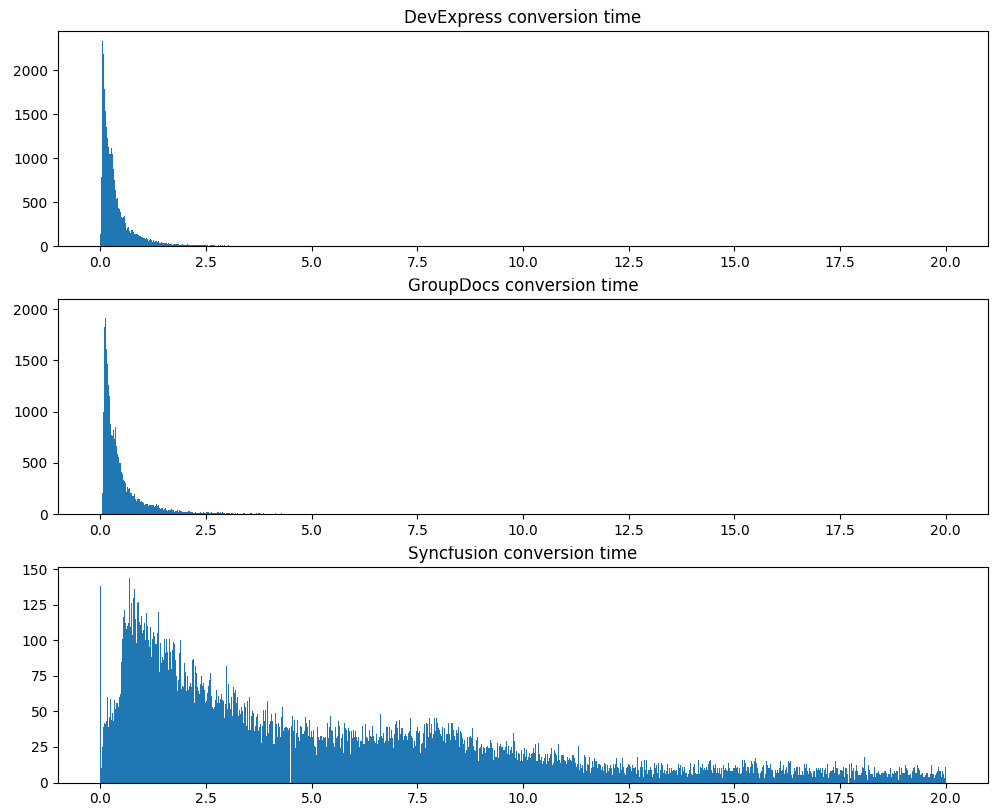
لاحظ أن DevExpress لا يقوم بمعالجة المستندات بشكل أسرع في المتوسط فحسب ، بل يوضح أيضًا وقت معالجة أكثر استقرارًا.
لكن الاستقرار وسرعة المعالجة لا تعني شيئًا إذا كان الإخراج سيئًا. ربما يتخطى DevExpress نصف النص؟ نحن نتحقق. لذلك ، نفس 120 ألف مستند ، سنحسب هذه المرة الحجم الكلي للنص المستخرج ومتوسط نصيب كلمات القاموس (كلما كانت الكلمات المستخرجة أكثر هي القاموس ، كلما كان حجم البيانات المهملة / النص المستخرج بشكل غير صحيح):
في جزء منه ، كان الافتراض الصحيح. كما اتضح ، يمكن لـ GroupDocs ، على عكس DevExpress ، العمل مع الحواشي السفلية. DevExpress ببساطة يتخطى لهم عند تحويل وثيقة إلى قوات الدفاع الشعبي. بالمناسبة ، نعم ، يتم استخراج النص من pdf'ok المستلم في جميع الحالات باستخدام DevExpress'a.
لذلك ، درسنا سرعة واستقرار المكتبات المعنية ، والآن نقوم بتقييم جودة تحويل وثيقة pdf بعناية. للقيام بذلك ، سنقوم بتحليل ليس فقط حجم النص المراد استخلاصه ونسبة كلمات القاموس فيه ، ولكننا سنقارن النصوص المستخرجة من ملفات pdf المستلمة بنصوص pdf التي تم الحصول عليها باستخدام MS Word. نحن نقبل نتيجة تحويل مستند باستخدام MS Word كمرجع pdf . تم إعداد حوالي 4500 زوج من " المستند ، المرجع pdf'ka " لهذا الاختبار.
لكل زوج " مرجع pdf ، نتيجة التحويل " ، حسبنا التشابه في طول النص المستخرج وفي ترددات الكلمات المستخرجة. بطبيعة الحال ، تم الحصول على هذه المقاييس فقط في تلك الحالات عندما كان التحويل ناجحًا. لذلك ، لا يتم اعتبار نتائج Syncfusion هنا. أظهر DevExpress و GroupDocs نفس الأداء تقريبًا. على الجانب DevExpress ، هناك نسبة أعلى بكثير من التحويلات الناجحة ، على الجانب GD ، العمل الصحيح مع الحواشي السفلية.
بالنظر إلى النتائج ، كان الاختيار واضحًا. حتى يومنا هذا ، نستخدم الحل من DevExpress وسنخطط قريبًا للترقية إلى الإصدار التاسع عشر.
هناك قوات الدفاع الشعبي ، واستخراج النص مع التنسيق
لذلك ، يمكننا تحويل الوثائق إلى قوات الدفاع الشعبي. الآن لدينا مهمة أخرى: استخدام DevExpress لاستخراج النص ، ومعرفة كل كلمة بكل المعلومات التي نحتاجها. وهي:
- على أي صفحة هي الكلمة ؛
- موقع الكلمة على الصفحة (تأطير مستطيل) ؛
- حجم الخط للكلمة (حروف كلمة).
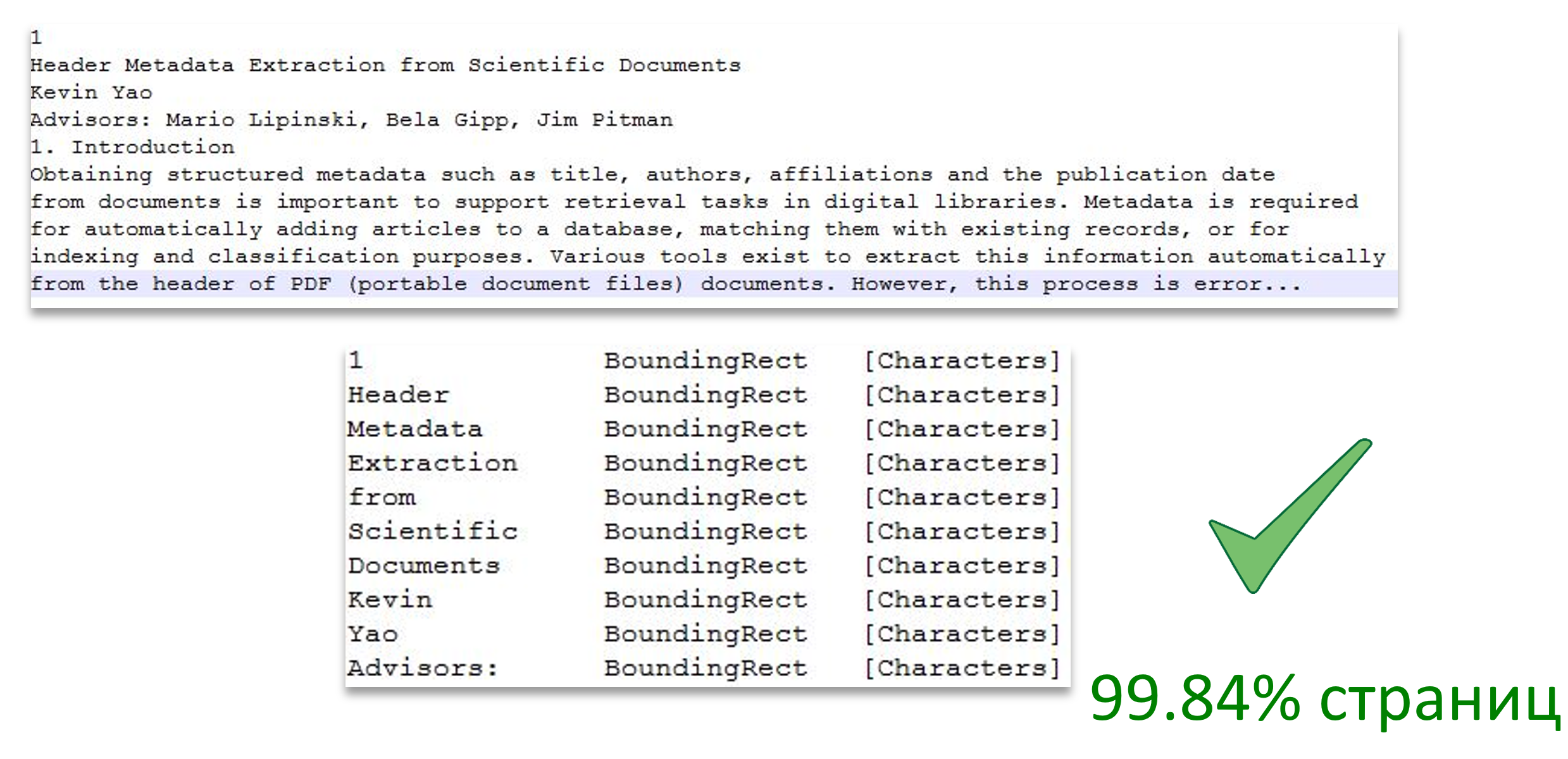
تُظهر الصورة تقسيم النص إلى صفحات ، كما تُظهر مراسلات كلمة النص إلى منطقة الصفحة.

مصدر الصورة: استخراج البيانات الوصفية للرأس من الوثائق العلمية
يبدو أن كل شيء يجب أن يكون بسيطا. نحن ننظر إلى ما يوفره لنا API DevExpress:
- لدينا طريقة تقوم بإرجاع نص المستند بأكمله. سلسلة عادي
- لدينا القدرة على التكرار وفقا للوثيقة. لكل كلمة يمكننا الحصول عليها:
- نص الكلمة
- الصفحة التي توجد بها الكلمة ؛
- مستطيل تأطير الكلمة ؛
- معلومات عن الأحرف الفردية للكلمة (معنى الحرف الذي يؤطر المستطيل ، حجم الخط ، ...).
حسنا ، يبدو أن كل شيء هناك. هنا فقط هو كيفية الحصول على البيانات اللازمة لكل كلمة في نص المستند الذي يعيد DevExpress؟ لا نريد حقًا جمع نص المستند من الكلمات بأنفسنا ، لأنه ، على سبيل المثال ، ليس لدينا معلومات حيث يوجد فقط مسافة بين الكلمات وأين يوجد موجز السطر. سيتعين علينا أن نتوصل إلى استدلال بناء على موقع الكلمات ... النص - هنا ، قبله ، قد تم تجميعه بالفعل.

مصدر الصورة: يوريكا!
الحل الواضح هو مطابقة الكلمات بنص المستند. نحن ننظر - في الواقع ، في نص المستند ، يتم ترتيب الكلمات بالترتيب نفسه الذي يتم به إرجاع التكرار وفقًا لكلمات المستند.
ننفذ بسرعة خوارزمية بسيطة لمطابقة الكلمات مع نص المستند ، ونضيف الشيكات التي تتم مطابقة كل شيء بشكل صحيح ، ونبدأ ...
في الواقع ، كل شيء يعمل بشكل صحيح على الغالبية العظمى من الصفحات ، ولكن لسوء الحظ ، لا يعمل على جميع الصفحات.

مصدر الصورة الأعلى: هل أنت متأكد؟
في جزء من المستندات ، نرى أن الكلمات الموجودة في النص ليست بالترتيب الذي تذهب به عند تكرار الكلمات الموجودة في المستند. علاوة على ذلك ، يمكن ملاحظة أن قوس مربع الفتح في النص في قائمة الكلمات يتم تمثيله كقوس إغلاق وفي "كلمة" أخرى. يمكن رؤية العرض الصحيح لجزء النص هذا عن طريق فتح المستند في MS Word. والأهم من ذلك ، إذا لم تقم بتحويل المستند إلى pdf ، لكنك استخرجت النص مباشرة من المستند ، فسنحصل على الإصدار الثالث من جزء النص الذي لا يتطابق مع الترتيب الصحيح أو الطلبين الآخرين اللذين تم استلامهما من المكتبة. في هذه الشريحة ، كما هو الحال في معظم البقية ، التي تنشأ عنها مشكلة مماثلة ، تكون النقطة هي أحرف "RTL" غير المرئية ، والتي تغير ترتيب الأحرف / الكلمات المجاورة.
تجدر الإشارة هنا إلى أننا أطلقنا على جودة الدعم الفني أهمية عند اختيار مكتبة. كما أظهرت الممارسة ، في هذا الجانب ، التفاعل مع DevExpress فعال للغاية. تم إصلاح مشكلة المستند المقدم بسرعة بعد أن أنشأنا التذكرة المقابلة. تم إصلاح عدد من المشكلات الأخرى المتعلقة بالاستثناءات / استهلاك الذاكرة العالي / معالجة المستندات الطويلة.
ومع ذلك ، على الرغم من أن DevExpress لا توفر طريقة مباشرة للحصول على النص بالمعلومات اللازمة لكل كلمة ، إلا أننا نواصل المقارنة في بعض الأحيان لا تضاهى. إذا لم نتمكن من بناء تطابق تام بين الكلمات والنصوص ، فإننا نستخدم عددًا من الأساليب البحثية التي تسمح بالتغييرات الصغيرة للكلمات. إذا لم يساعد أي شيء ، يبقى المستند بدون تنسيق. نادرا ، ولكن هذا يحدث.
وداعا :)