في نهاية شهر يونيو ، قام فريق من جامعة كارنيجي ميلون بعرض XLNet لدينا ، حيث قام على الفور بوضع
المنشور والكود والنموذج النهائي (
XLNet-Large ،
Cased : 24 طبقة ، 1024 مخفية ، 16 رأسًا). هذا نموذج تم تدريبه مسبقًا لحل مختلف مشكلات معالجة اللغة الطبيعية.
في المنشور ، أشاروا على الفور إلى مقارنة
طرازهم مع
بيرت جوجل. يكتبون أن XLNet متفوقة على BERT في عدد كبير من المهام. ويظهر النتائج في 18 مهمة متطورة.
بيرت ، XLNet والمحولات
واحدة من الاتجاهات الحديثة في التعلم العميق هو نقل التعلم. نقوم بتدريب النماذج لحل المشكلات البسيطة على كمية هائلة من البيانات ، ثم نستخدم هذه النماذج المدربة مسبقًا ، ولكن لحل المشكلات الأخرى الأكثر تحديدًا. BERT و XLNet هما مجرد شبكات مدربة مسبقًا يمكن استخدامها لحل مشكلات معالجة اللغة الطبيعية.
تعمل هذه النماذج على تطوير فكرة
المحولات - النهج السائد حاليًا في بناء نماذج للتعامل مع المتواليات. مفصل للغاية ومع أمثلة من التعليمات البرمجية على المحولات وآلية الاهتمام مكتوب في
المحول المشروح .
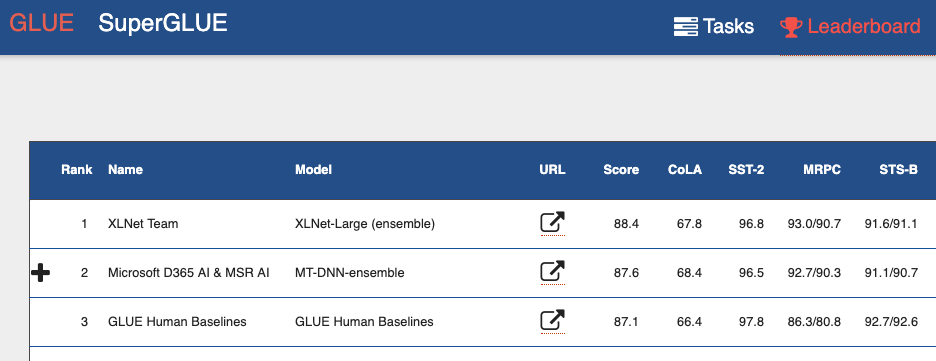
إذا نظرت إلى
لوحة المتصدرين المعيارية لتقييم اللغة العامة (GLUE) ، فيمكنك من خلال ذلك مشاهدة العديد من النماذج المعتمدة على المحولات. بما في ذلك كلا النموذجين التي تظهر نتائج أفضل من البشر. يمكننا القول أنه مع المحولات ، نشهد ثورة صغيرة في معالجة اللغة الطبيعية.
عيوب بيرت
بيرت هو التشفير التلقائي (التشفير التلقائي ، AE). إنه يخفي ويفسد بعض الكلمات في التسلسل ويحاول استعادة التسلسل الأصلي للكلمات من السياق.
هذا يؤدي إلى عيوب النموذج:
- يتم التنبؤ بكل كلمة مخفية بشكل فردي. نفقد المعلومات حول العلاقات المحتملة بين الكلمات المقنعة. تقدم المقالة مثالًا يسمى "نيويورك". إذا حاولنا التنبؤ بهذه الكلمات بشكل مستقل في السياق ، فلن نأخذ في الاعتبار العلاقة بينهما.
- عدم الاتساق بين مراحل تدريب نموذج بيرت واستخدام نموذج بيرت المدرَّب مسبقًا. عندما نقوم بتدريب النموذج - قمنا بإخفاء الكلمات ([MASK]) ، عندما نستخدم النموذج المدربين مسبقًا ، فإننا لا نوفر بالفعل هذه الرموز المميزة للمدخلات.
ومع ذلك ، على الرغم من هذه المشكلات ، أظهر BERT أحدث النتائج في العديد من مهام معالجة اللغة الطبيعية.
ميزات XLNet
XLNet عبارة عن نمذجة لغة الانحدار التلقائي ، AR LM. إنها تحاول التنبؤ بالرمز التالي من تسلسل الرموز السابقة. في نماذج الانحدار التلقائي الكلاسيكية ، يتم أخذ هذا التسلسل السياقي بشكل مستقل عن اتجاهين للسلسلة الأصلية.
يعمم XLNet هذه الطريقة ويشكل السياق من أماكن مختلفة في تسلسل المصدر. كيف يفعل ذلك. يأخذ كل (من الناحية النظرية) التباديل الممكنة من التسلسل الأصلي ويتوقع كل رمزية في التسلسل من سابقاتها.
فيما يلي مثال من المقالة حول كيفية توقع الرمز المميز x3 من التباديل المختلفة للتسلسل الأصلي.
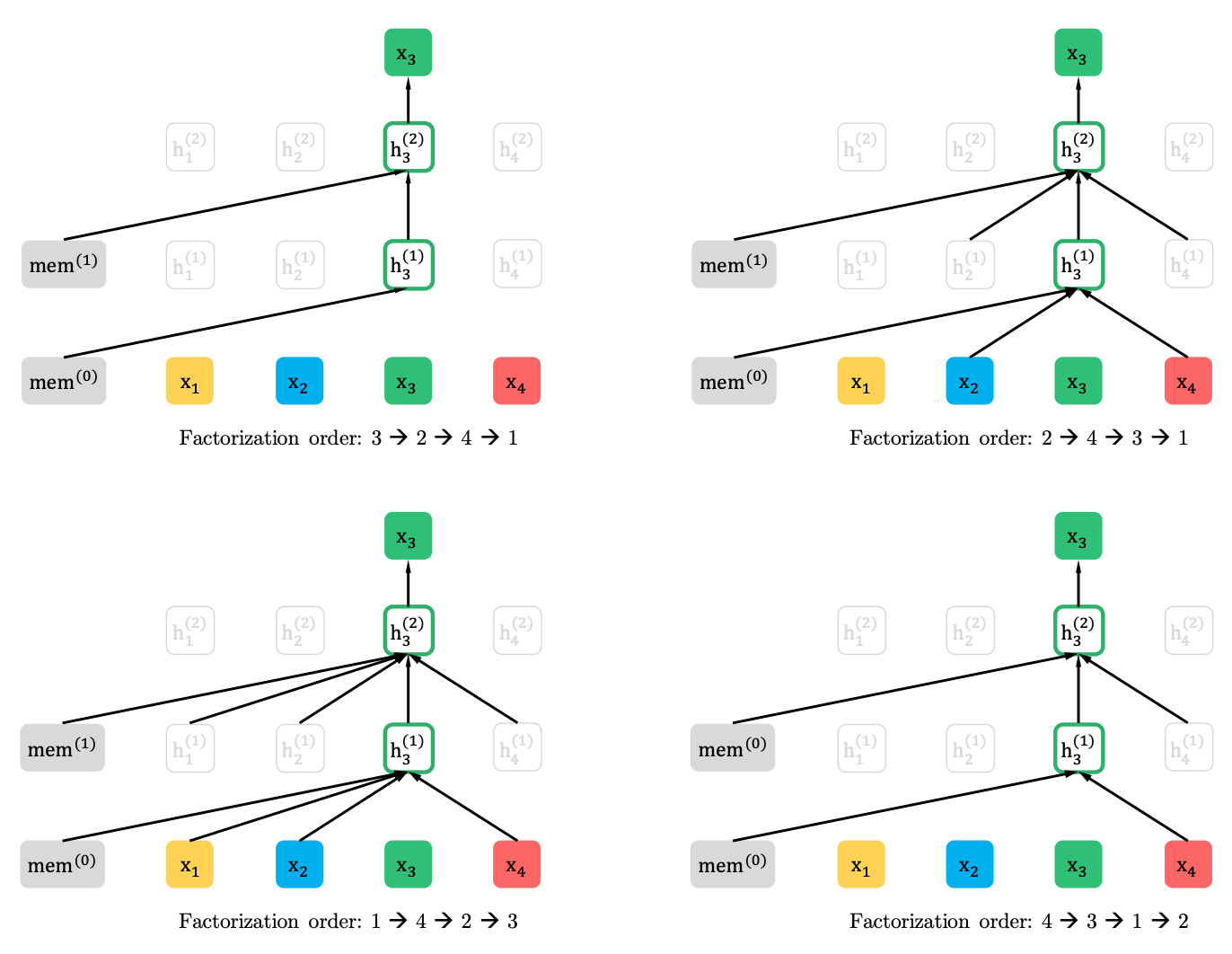
علاوة على ذلك ، السياق ليس كيس كلمات. يتم أيضًا تقديم معلومات حول الترتيب الأولي للرموز إلى النموذج.
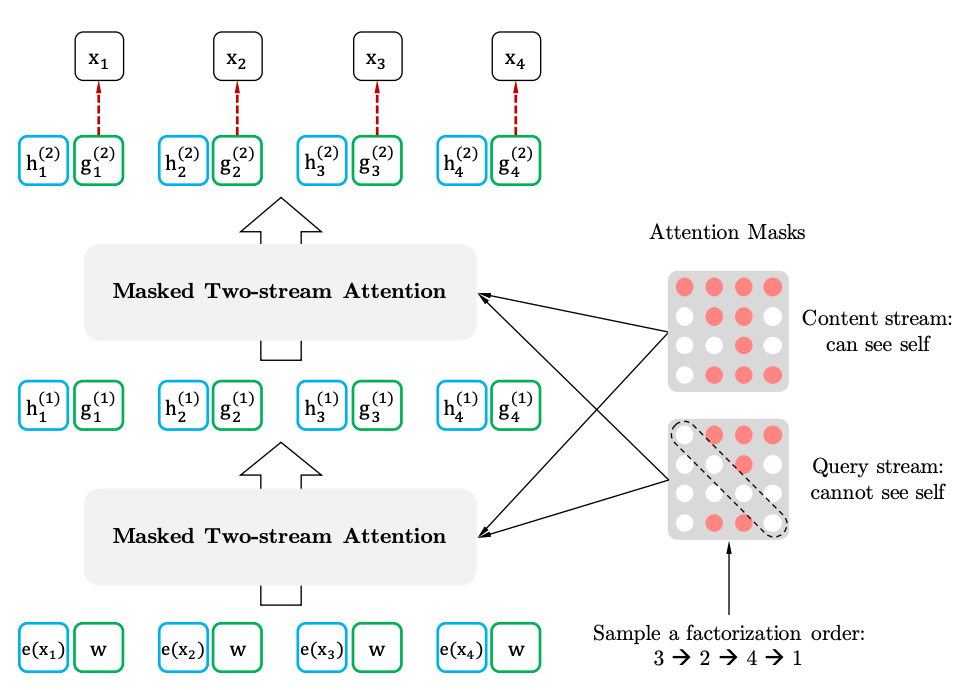
إذا رسمنا أوجه تشابه مع BERT ، اتضح أننا لا نخفي الرموز المميزة مقدمًا ، بل نستخدم مجموعات مختلفة من الرموز المخفية في التباينات المختلفة. في الوقت نفسه ، تختفي المشكلة الثانية لـ BERT - عدم وجود الرموز المخفية عند استخدام النموذج المدربين مسبقًا. في حالة XLNet ، تسلسل كامل ، دون أقنعة ، هو بالفعل إدخال.
من أين يأتي XL في الاسم. XL - لأن XLNet يستخدم آلية Attention والأفكار من طراز Transformer-XL. على الرغم من أن اللغات الشريرة تدعي أن XL يلمح إلى مقدار الموارد اللازمة لتدريب الشبكة.
وحول الموارد. على Twitter ، قاموا بنشر
حساب تكلفة تدريب الشبكة باستخدام المعلمات من المقال. اتضح 245000 دولار. صحيح ، ثم جاء مهندس من Google
وصحح أن المقالة تذكر 512 من رقائق TPU ، أربعة منها على الجهاز. وهذا هو ، التكلفة بالفعل 62440 دولار ، أو حتى 32720 دولار ، بالنظر إلى 512 النوى ، والتي ذكرت أيضا في المقال.
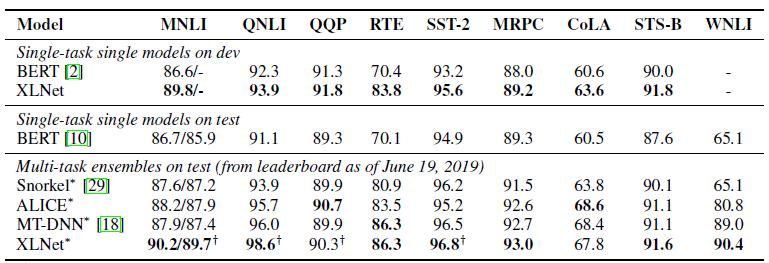
XLNet مقابل بيرت
حتى الآن ، تم وضع نموذج واحد مُدرَّب مسبقًا للغة الإنجليزية للمقالة (XLNet-Large، Cased). لكن المقالة تذكر أيضًا التجارب على نماذج أصغر. وفي العديد من المهام ، تُظهر نماذج XLNet نتائج أفضل مقارنةً بنماذج BERT المشابهة.
اجتذب ظهور BERT وخاصة النماذج المدربة مسبقًا الكثير من اهتمام الباحثين وأدى إلى عدد كبير من الأعمال ذات الصلة. الآن هنا هو XLNet. من المثير للاهتمام معرفة ما إذا كان لبعض الوقت يصبح المعيار الفعلي في البرمجة اللغوية العصبية ، أو العكس ، سيحفز الباحثين في البحث عن بنى وأساليب جديدة لمعالجة اللغة الطبيعية.