يستضيف GitHub أكثر من 300 لغة برمجة - من اللغات الشائعة الاستخدام مثل Python و Java و Javascript إلى اللغات الباطنية مثل
Befunge ، والمعروفة فقط للمجتمعات الصغيرة جدًا.
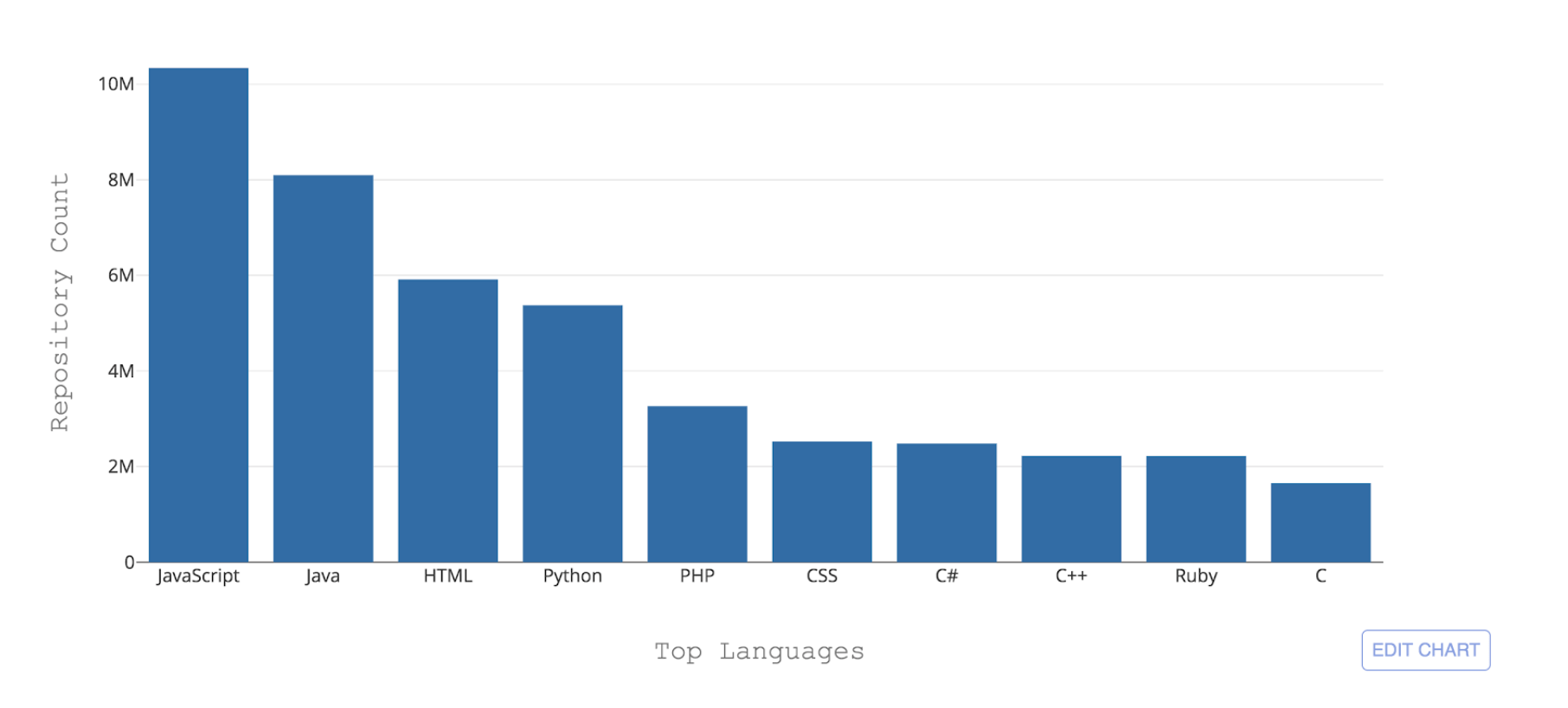 الشكل 1: أفضل 10 لغات برمجة يستضيفها GitHub من خلال عدد المستودعات
الشكل 1: أفضل 10 لغات برمجة يستضيفها GitHub من خلال عدد المستودعاتأحد التحديات الضرورية التي تواجه GitHub هو أن تكون قادرًا على التعرف على هذه اللغات المختلفة. عندما يتم دفع بعض التعليمات البرمجية إلى مستودع ، من المهم التعرف على نوع الكود الذي تمت إضافته لأغراض البحث ، وتنبيه ثغرة أمنية ، وتسليط الضوء على بناء الجملة - ولإظهار توزيع محتوى المستودع على المستخدمين.
Linguist هي الأداة التي نستخدمها حاليًا للكشف عن لغات الترميز في GitHub. Linguist تطبيق يستند إلى Ruby يستخدم استراتيجيات متنوعة لاكتشاف اللغة ، والاستفادة من اصطلاحات التسمية وإضافات الملفات وأيضًا مراعاة نماذج Vim أو Emacs ، وكذلك المحتوى الموجود في الجزء العلوي من الملف (shebang). يقوم Linguist بمعالجة الغموض اللغوي عبر الاستدلال ، وإذا لم يتم ذلك ، عبر مصنّف Naive Bayes المدرّب على عينة صغيرة من البيانات.
على الرغم من أن Linguist يقوم بعمل جيد في صنع تنبؤات للغة على مستوى الملف (دقة 84٪) ، فإن أدائه ينخفض بشكل كبير عندما تستخدم الملفات اصطلاحات تسمية غير متوقعة ، وبشكل حاسم ، عندما لا يتم توفير ملحق ملف. هذا يجعل Linguist غير مناسب لمحتوى مثل GitHub Gists أو مقتطفات الكود ضمن README ، والمشاكل ، وسحب الطلبات.
من أجل جعل اكتشاف اللغة أكثر قوة ويمكن صيانته على المدى الطويل ، قمنا بتطوير مصنف تعليمي آلي يدعى Octo Lingua استنادًا إلى بنية الشبكة العصبية الاصطناعية (ANN) التي يمكنها التعامل مع التنبؤات اللغوية في سيناريوهات صعبة. الإصدار الحالي من النموذج قادر على عمل تنبؤات لأفضل 50 لغة يستضيفها GitHub ويتفوق على Linguist في الدقة والأداء.
الصواميل والمسامير خلف OctoLingua
تم بناء OctoLingua من نقطة الصفر باستخدام Python و Keras مع TensorFlow للخلفية - وتم تصميمه ليكون دقيقًا وقويًا وسهل الصيانة. في هذا القسم ، نصف مصادر البيانات الخاصة بنا ، وهندسة النماذج ، ومعيار الأداء لأوكولينجوا. نصف أيضًا ما يلزم لإضافة دعم للغة جديدة.
مصادر البيانات
تم تدريب الإصدار الحالي من OctoLingua على الملفات التي تم استردادها من
Rosetta Code ومن مجموعة من مستودعات الجودة الداخلية. حصرنا لغتنا في مجموعة من أفضل 50 لغة مستضافة على جيثب.
كان Rosetta Code عبارة عن مجموعة بيانات ممتازة للمبتدئين حيث احتوت على شفرة المصدر لنفس المهمة المعبر عنها بلغات البرمجة المختلفة. على سبيل المثال ، يتم التعبير عن مهمة إنشاء
تسلسل فيبوناتشي في C و C ++ و CoffeeScript و D و Java و Julia والمزيد. ومع ذلك ، فإن التغطية عبر اللغات لم تكن موحدة حيث تحتوي بعض اللغات فقط على عدد قليل من الملفات وكانت بعض الملفات قليلة للغاية. لذلك ، كان من الضروري زيادة مجموعة التدريب لدينا مع بعض المصادر الإضافية وتحسين التغطية اللغوية والأداء بشكل كبير.
أصبحت عملية إضافة لغة جديدة مؤتمتة بالكامل الآن. نقوم بجمع شفرة المصدر برمجياً من المستودعات العامة على جيثب. نختار مستودعات التخزين التي تلبي الحد الأدنى من معايير التأهيل مثل امتلاك الحد الأدنى لعدد الشوكات وتغطية اللغة الهدف وتغطية امتدادات ملفات محددة. بالنسبة لهذه المرحلة من جمع البيانات ، نحدد اللغة الأساسية لمستودع التخزين باستخدام التصنيف من Linguist.
الميزات: الاستفادة من المعرفة السابقة
تقليديًا ، بالنسبة لمشكلات تصنيف النص في الشبكات العصبية ، غالبًا ما يتم استخدام البنى القائمة على الذاكرة مثل الشبكات العصبية المتكررة (RNN) وشبكات الذاكرة طويلة المدى (LSTM). ومع ذلك ، نظرًا لوجود اختلافات في لغات البرمجة في المفردات وأسلوب التعليق وإضافات الملفات والهيكل ونمط استيراد المكتبات وغيرها من الاختلافات الطفيفة ، فقد اخترنا أسلوبًا أبسط يستفيد من جميع هذه المعلومات عن طريق استخراج بعض الميزات ذات الصلة في شكل جدول لتغذيتها المصنف لدينا. الميزات المستخرجة حاليًا كالتالي:
- أعلى خمسة أحرف خاصة لكل ملف
- أفضل 20 رمزًا لكل ملف
- امتداد الملف
- وجود أحرف خاصة معينة شائعة الاستخدام في ملفات التعليمات البرمجية المصدر مثل colons ، والأقواس المتعرجة ، والفاصلة المنقوطة
نموذج الشبكة العصبية الاصطناعية (ANN)
نحن نستخدم الميزات المذكورة أعلاه كمدخلات لشبكة اصطناعية عصبية من طبقتين مبنية باستخدام Keras مع الواجهة الخلفية Tensorflow.
يوضح الرسم البياني أدناه أن خطوة استخراج الميزة تنتج مدخلات جدولية ذات أبعاد n لمصنفنا. عندما تنتقل المعلومات على طول طبقات شبكتنا ، يتم تنظيمها عن طريق التسرب وتنتج في النهاية مخرجات ذات أبعاد 51 والتي تمثل الاحتمال المتوقع أن يتم كتابة الكود المعطى في كل من لغات GitHub الخمسين العليا بالإضافة إلى احتمال عدم نشرها. مكتوب في أي من هؤلاء.
الشكل 2: هيكل ANN من نموذجنا الأولي (50 لغة + 1 ل "الآخر")استخدمنا 90 ٪ من مجموعة البيانات الخاصة بنا للتدريب على ما يقرب من ثمانية حقبة. بالإضافة إلى ذلك ، قمنا بإزالة نسبة من امتدادات الملفات من بيانات التدريب الخاصة بنا في خطوة التدريب ، لتشجيع النموذج على التعلم من مفردات الملفات ، وليس التجاوز في ميزة امتداد الملف ، وهو أمر تنبئي للغاية.
معيار الأداء
أوكتولينجوا vs. لغويفي الشكل 3 ، نعرض
درجة F1 (متوسط التوافقي بين الدقة والاسترجاع) لأوكولينجوا ولغويست محسوبة على نفس مجموعة الاختبار (10٪ من مصدر البيانات الأولي).
هنا نعرض ثلاثة اختبارات. الاختبار الأول هو مع مجموعة اختبار يمس بأي حال من الأحوال. يستخدم الاختبار الثاني نفس مجموعة ملفات الاختبار مع إزالة معلومات امتداد الملف ويستخدم الاختبار الثالث أيضًا نفس مجموعة الملفات ولكن هذه المرة مع امتدادات الملفات المخفوقة وذلك لإرباك المصنفين (على سبيل المثال ، قد يكون ملف Java "". txt "ملحق وملف Python قد يكون له ملحق" .java ").
الهدف من وراء تخليط أو إزالة امتدادات الملفات في مجموعة الاختبار الخاصة بنا هو تقييم متانة OctoLingua في تصنيف الملفات عند إزالة ميزة أساسية أو مضللة. سيكون المصنف الذي لا يعتمد اعتمادًا كبيرًا على الامتداد مفيدًا للغاية لتصنيف عناصر القصاصات والمقتطفات ، لأنه في هذه الحالات يكون من الشائع للأشخاص عدم تقديم معلومات دقيقة عن الامتداد (على سبيل المثال ، العديد من برامج معالجة الرموز ذات الامتداد لها امتداد .txt).
يوضح الجدول أدناه كيف يحتفظ OctoLingua بأداء جيد في ظل ظروف مختلفة ، مما يشير إلى أن النموذج يتعلم في المقام الأول من مفردات التعليمات البرمجية ، بدلاً من معلومات التعريف (مثل امتداد الملف) ، في حين يفشل Linguist بمجرد أن المعلومات الموجودة في امتدادات الملفات هي تغييرها.
الشكل 3: أداء OctoLingua مقابل لغوي على نفس مجموعة الاختبارتأثير إزالة امتداد الملف أثناء وقت التدريبكما ذكرنا سابقًا ، قمنا خلال فترة التدريب بإزالة نسبة من امتدادات الملفات من بيانات التدريب لدينا لتشجيع النموذج على التعلم من مفردات الملفات. يوضح الجدول أدناه أداء نموذجنا مع إزالة كسور مختلفة من امتدادات الملفات أثناء وقت التدريب.
 الشكل 4: أداء OctoLingua مع نسبة مختلفة من امتدادات الملفات التي تمت إزالتها في صيغ الاختبار الثلاثة
الشكل 4: أداء OctoLingua مع نسبة مختلفة من امتدادات الملفات التي تمت إزالتها في صيغ الاختبار الثلاثةلاحظ أنه مع عدم إزالة امتداد الملف أثناء وقت التدريب ، فإن أداء OctoLingua في ملفات الاختبار التي لا تحتوي على امتدادات وملحقات عشوائية يقل بشكل ملحوظ عن أداء بيانات الاختبار العادية. من ناحية أخرى ، عندما يتم تدريب النموذج على مجموعة بيانات حيث تتم إزالة بعض امتدادات الملفات ، فإن أداء النموذج لا ينخفض كثيرًا في مجموعة الاختبار المعدلة. هذا يؤكد أن إزالة امتداد الملف من جزء صغير من الملفات في وقت التدريب يدفع المصنف الخاص بنا إلى معرفة المزيد من المفردات. كما يوضح أن ميزة امتداد الملف ، على الرغم من أنها تنبؤية للغاية ، كانت تميل إلى السيطرة ومنع المزيد من الأوزان المخصصة لميزات المحتوى.
دعم لغة جديدة
إضافة لغة جديدة في OctoLingua واضحة إلى حد ما. يبدأ بالحصول على مجموعة كبيرة من الملفات باللغة الجديدة (يمكننا القيام بذلك برمجيًا كما هو موضح في مصادر البيانات). يتم تقسيم هذه الملفات إلى تدريب ومجموعة اختبار ، ثم يتم تشغيلها عبر معالجنا المسبق ومستخرج الميزات. تتم إضافة مجموعة التدريب والاختبار الجديدة هذه إلى مجموعة بيانات التدريب والاختبار الموجودة لدينا. تسمح لنا مجموعة الاختبارات الجديدة بالتحقق من أن دقة نموذجنا تظل مقبولة.
الشكل 5: إضافة لغة جديدة مع OctoLinguaخططنا
اعتبارا من الآن ، OctoLingua في "مرحلة النماذج المتقدمة". محرك تصنيف اللغات لدينا قوي وموثوق به بالفعل ، لكنه لا يدعم جميع لغات الترميز على نظامنا الأساسي. بصرف النظر عن توسيع نطاق دعم اللغة - والذي سيكون بسيطًا إلى حد ما - نهدف إلى تمكين اكتشاف اللغة على مستويات مختلفة من التفاصيل. إن تطبيقنا الحالي يسمح لنا بالفعل ، مع إدخال تعديل بسيط على محرك التعلم الآلي لدينا ، بتصنيف مقتطفات الكود. لن يكون الانتقال بعيدًا إلى حد كبير لنقل النموذج إلى المسرح حيث يمكنه اكتشاف وتصنيف اللغات المضمنة بشكل موثوق.
نحن نفكر أيضًا في إمكانية الاستعانة بمصادر خارجية لنموذجنا ونود أن نسمع من المجتمع إذا كنت مهتمًا.
ملخص
مع OctoLingua ، يتمثل هدفنا في توفير خدمة تمكن من اكتشاف لغة شفرة مصدر قوية وموثوقة على مستويات متعددة من التفاصيل ، من مستوى الملف أو مستوى المقتطف إلى اكتشاف اللغة وتصنيفها المحتمل على مستوى الخط. في النهاية ، يمكن لهذه الخدمة أن تدعم ، من بين أمور أخرى ، إمكانية البحث عن الكود ومشاركة الكود وإبراز اللغة وتقديم الفرق - كل هذا يهدف إلى دعم المطورين في أعمال التطوير اليومية بالإضافة إلى مساعدتهم في كتابة كود الجودة. إذا كنت مهتمًا بالاستفادة من عملنا أو المساهمة فيه ، فلا تتردد في الاتصال على
Twittergithub !