في الآونة الأخيرة ، تم استخدام لغة Scala على نطاق واسع بواسطة Data Science. اكتسبت شعبية بسبب ظهور سبارك ، الذي هو مكتوب في سكالا. في الممارسة العملية ، في كثير من الأحيان في مرحلة البحث ، يتم إجراء تحليل وإنشاء النموذج في بيثون ثم يتم تنفيذه في سكالا ، لأن هذه اللغة هي أكثر ملاءمة للإنتاج.
لقد أعددنا نظرة عامة مفصلة للمكتبات الأكثر إثارة للاهتمام المستخدمة لتنفيذ مهام التعلم الآلي وعلوم البيانات في سكالا. يتم استخدام بعضها في برنامجنا التعليمي " تحليل البيانات على سكالا ".
للراحة ، تم تقسيم جميع المكتبات المقدمة في التصنيف إلى 5 مجموعات: تحليل البيانات والرياضيات ، البرمجة اللغوية العصبية ، التصور ، التعلم الآلي ، وأكثر من ذلك.
تحليل البيانات والرياضيات
رقم 1. النسيم (عدد مرات الدخول: 3316 ، المساهمون: 84)
تُعرف مكتبة Breeze باسم مكتبة العلوم الأساسية لـ Scala. لديها أشياء مماثلة من MATLAB (من حيث هياكل البيانات) ، ومن فئات بيثون ، NumPy. يوفر Breeze معالجة سريعة وفعالة لصفائف البيانات ويسمح لك بإجراء العديد من العمليات الأخرى ، بما في ذلك ما يلي:
- عمليات المصفوفة والمتجهات لإنشاء عمليات نقل العناصر ونقلها وتنفيذها وإجراء عمليات حسابية لها ومحدداتها وأشياء أخرى كثيرة.
- الدالات الاحتمالية والإحصائية: من التوزيعات الإحصائية وحساب الإحصاءات الوصفية (مثل الوسط والتباين والانحراف المعياري) إلى نماذج سلسلة ماركوف. الحزم الرئيسية للإحصاءات هي breeze.stats و breeze.stats.distributions.
- التحسين ، الذي يتضمن فحص وظيفة بحد أدنى محلي أو عالمي. يتم تخزين طرق التحسين في النسيم. تحسين الحزمة.
- Linear Algebra: تستند جميع العمليات الأساسية إلى مكتبة netlib-java ، مما يجعل Breeze سريعًا للغاية بالنسبة للحوسبة الجبرية.
- عمليات معالجة الإشارات. أمثلة على هذه العمليات في Breeze هي الإلتفاف وتحويل Fourier ، الذي يقسم هذه الوظيفة إلى مجموع مكونات جيب التمام وجيب التمام.
تجدر الإشارة إلى أن Breeze يسمح لك أيضًا بإنشاء رسوم بيانية ، لكننا سنتحدث عن ذلك لاحقًا.
رقم 2. سرج (يرتكب: 184 ، المساهمون: 10)
أداة بيانات أخرى لـ Scala هي Saddle. هذا هو التماثلية لباندا في بيثون ، ولكن فقط لسكالا. مثل إطارات البيانات في Pandas أو R ، يعتمد Saddle على بنية الإطار (مصفوفة مفهرسة ثنائية الأبعاد).
هناك خمسة هياكل البيانات الأساسية في المجموع ، وهي:
الإطار (المصفوفة المفهرسة ثنائية الأبعاد)
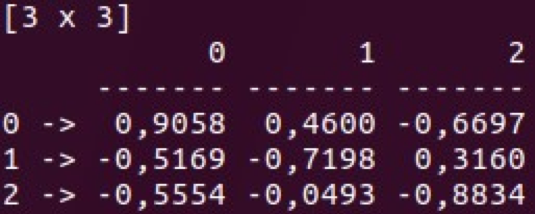
- الفهرس (كما hashmap)
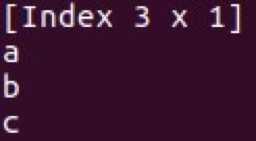
توجد فصول Vec و Mat في السلاسل والإطار. يمكنك إجراء عمليات معالجة متعددة باستخدام بنيات البيانات هذه واستخدامها لتحليل البيانات الأساسي. ميزة أخرى كبيرة من السرج هي مقاومتها لفجوات البيانات.
رقم 3. ScalaLab (عدد مرات الدخول: 23 ، المساهمون: 1)
ScalaLab هو نوع من MATLAB في Scala. علاوة على ذلك ، يمكن لـ ScalaLab الاتصال مباشرة والوصول إلى نتائج MATLAB النصي.
الفرق الرئيسي عن مكتبات الحوسبة السابقة هو أن ScalaLab تستخدم لغتها الخاصة بالمجال والتي تسمى ScalaSci. يعتبر Scalalab مناسبًا لأنه يصل إلى العديد من المكتبات العلمية في Java و Scala ، بحيث يمكنك بسهولة استيراد بياناتك ومن ثم استخدام طرق متنوعة لإجراء عمليات المعالجة والحسابات. معظم الأشياء تشبه النسيم والسرج. علاوة على ذلك ، كما في Breeze ، هناك مخططات تسمح لك بمزيد من تفسير البيانات.
NLP
رقم 4. Epic (Commits: 1790، Contributors: 15) and Puck (Commits: 536، Contributors: 1)
لدى Scala بعض مكتبات معالجة اللغات الطبيعية الجيدة كجزء من ScalaNLP ، بما في ذلك Epic and Puck. تستخدم هذه المكتبات بشكل أساسي كأدوات لتحليل النص. في الوقت نفسه ، يعد Puck أكثر ملاءمة إذا كنت بحاجة إلى تحليل الآلاف من العروض بسبب سرعته العالية واستخدام وحدة معالجة الرسومات. يُعرف Epic أيضًا بإطار عمل تنبؤي يستخدم التنبؤ المنظم لبناء أنظمة معقدة.
تصور
رقم 5. بريز - فيز (عدد المشاركات: 29 ، المساهمون: 3)
كما يوحي الاسم ، Breeze-viz هي مكتبة تصورية تم تطويرها بواسطة Breeze for Scala. وهو يستند إلى مكتبة جافا المعروفة JFreeChart والتخطيط يشبه إلى حد ما MATLAB. على الرغم من أن Breeze-viz له ميزات أقل بكثير من MATLAB ، أو matplotlib في Python أو R ، إلا أنه مفيد في إنشاء النماذج وتحليل البيانات.
رقم 6. فيجاس (عدد مرات الدخول: 210 ، عدد المساهمين: 14)
مكتبة Scala الأخرى لتصور البيانات هي Vegas. إنه أكثر وظيفية من Breeze-viz ، ويسمح لك بإجراء بعض التحويلات المفيدة للرسوم البيانية: التصفية والتحويلات والتجميعات. بشكل عام ، تشبه المكتبة Bokeh و Plotly في Python.
تسمح لك Vegas بكتابة التعليمات البرمجية بأسلوب تعريفي ، مما يجعل من الممكن التركيز بشكل أساسي على تحديد ما يجب القيام به مع البيانات وإجراء مزيد من التحليل للمرئيات دون القلق بشأن تنفيذ التعليمات البرمجية.

تعلم الآلة
رقم 7. Smile (Commits: 1019 ، المساهمون: 21)
The Statistical Machine Intelligence and Learning Engine ، أو ببساطة Smile ، هي مكتبة واعدة لتعلم الآلات الحديثة ، تشبه إلى حد ما scikit-learning في Python. تم تطويره في Java ، ولكنه يحتوي أيضًا على واجهة برمجة التطبيقات لـ Scala. المكتبة سريعة ومثمرة: الاستخدام الفعال للذاكرة ، مجموعة كبيرة من خوارزميات التعلم الآلي للتصنيف ، الانحدار ، NNS ، اختيار الوظيفة ، إلخ.

رقم 8. شرارة ML
مكتبة تعلم الآلة التي تعمل خارج الصندوق في Apache Spark. Spark نفسها مكتوبة في Scala ولديها واجهة برمجة تطبيقات مناسبة لجميع مكتباتها.
Spark ML - على عكس Spark MLlib (مكتبة قديمة) ، فهو يعمل مع إطارات البيانات. كما أنه يجعل من الممكن بناء خطوط أنابيب للتحولات المختلفة على البيانات الخاصة بك. يمكن اعتبار ذلك بمثابة سلسلة من المراحل ، حيث تكون كل مرحلة إما محولًا يحول إطار بيانات واحد إلى آخر ، أو مقدّرًا ، على سبيل المثال ، خوارزمية تعلم آلي يتم تدريبها على إطار بيانات.
رقم 9. DeepLearning.scala (عدد مرات التحميل: 1647 ، المساهمون: 14)
DeepLearning.scala هي أداة تعليمية بديلة للآلة تتيح لك بناء نماذج تعليمية عميقة. تستخدم المكتبة الصيغ الرياضية لإنشاء شبكات عصبية ديناميكية معقدة من خلال مجموعة من البرمجة الوظيفية والموجهة للكائنات. ويستخدم مجموعة واسعة من الأنواع ، وكذلك فئات من الأنواع التطبيقية. يسمح لك هذا الأخير ببدء حسابات متعددة في نفس الوقت ، مما يحسن الإنتاجية.
رقم 10. Summing Bird (Commits: 1772، Contributors: 31)
Summingbird هو إطار عمل لمعالجة البيانات يسمح باستخدام العمليات الحسابية وحساب MapReduce في الوقت الفعلي. كان مطورو Twitter ، المحفز الرئيسي لتطوير اللغة ، الذين كتبوا في كثير من الأحيان نفس الكود مرتين: أولاً لمعالجة batche ، ثم مرة أخرى للتدفق.
يستخدم Summingbird ويولد نوعين من البيانات: التدفقات (تسلسل لانهائي من tuples) واللقطات ، والتي في وقت معين تعتبر الحالة الكاملة لمجموعة البيانات. أخيرًا ، يوفر Summingbird نظامًا أساسيًا للعاصفة والسحق ومحرك الذاكرة لأغراض الاختبار.
رقم 11. التنبؤ (عدد مرات الدخول: 4343 ، المساهمون: 125)
تجدر الإشارة أيضًا إلى خدمة التعلم الآلي لإنشاء ونشر آليات تنبؤية تسمى PredictionIO. إنه مبني على Apache Spark MLlib و HBase ، وقد تم تصنيفه حتى على Github كأفضل منتج للتعلم الآلي على أساس Apache Spark. يتيح لك إنشاء خدمات ونشرها بسهولة وكفاءة وتطبيق نماذج التعلم الآلي الخاصة بك ودمجها في خدمتك.
آخر
رقم 12. عكا (مرتكب: 21430 ، مساهم: 467)
تم تطوير Akka بواسطة Scala ، وهي بيئة موازية لبناء تطبيقات JVM الموزعة. يستخدم نموذجًا قائمًا على الفاعل ، حيث يكون الفاعل كائنًا يتلقى الرسائل ويقوم بتنفيذ الإجراءات المناسبة.
يتمثل الاختلاف الرئيسي في الطبقة الإضافية بين العناصر الفاعلة والإطار ، الأمر الذي لا يتطلب من الجهات الفاعلة سوى معالجة الرسائل ، في حين يتعامل الإطار مع كل شيء آخر. جميع الجهات الفاعلة منظمة بشكل هرمي ، وهذا يساعد الجهات الفاعلة على التفاعل بشكل أكثر فعالية مع بعضها البعض وحل المشكلات المعقدة ، وتقسيمها إلى مهام أصغر.
رقم 13. سليك (يرتكب: 1940 ، المساهمون: 92)
أحدث مكتبة هي Slick ، مما يعني مجموعة أدوات اتصال متكاملة باللغة Scala. هذه مكتبة لإنشاء وتنفيذ استعلامات قاعدة البيانات: H2 ، MySQL ، PostgreSQL ، إلخ. تتوفر بعض قواعد البيانات من خلال إضافات slick.
لإنشاء استعلامات ، يوفر Slick DSL قويًا يجعل الشفرة كما لو كنت تستخدم مجموعات Scala. يدعم Slick كلاً من استعلامات SQL البسيطة ووصلات مكتوبة بقوة في عدة جداول. بالإضافة إلى ذلك ، يمكن استخدام الاستعلامات الفرعية البسيطة لإنشاء استفسارات أكثر تعقيدًا.
استنتاج
في هذه المقالة ، حددنا ووصفنا باختصار بعض مكتبات Scala التي يمكن أن تكون مفيدة للغاية في أداء مهام معالجة البيانات الأساسية.
إذا كانت لديك خبرة في العمل مع أي من مكتبات Scala أو منصات أخرى مفيدة تستحق الإضافة إلى هذه القائمة ، فلا تتردد في مشاركتها في التعليقات.