في 27 أبريل ، في مؤتمر
Strike-2019 ، في إطار قسم DevOps ، تم إعداد تقرير بعنوان "القياس التلقائي وإدارة الموارد في Kubernetes". يتحدث عن كيفية استخدام K8s لضمان توفر التطبيقات بشكل كبير وضمان أقصى درجات أدائها.

وفقًا للتقاليد ، يسعدنا تقديم
مقطع فيديو مع تقرير (44 دقيقة ، أكثر إفادة من المقال) والضغط الرئيسي في شكل نص. دعنا نذهب!
سنحلل موضوع التقرير وفقًا للكلمات ونبدأ من النهاية.
Kubernetes
دعونا لدينا حاويات الإرساء على المضيف. لماذا؟ لضمان التكرار والعزلة ، والذي بدوره يسمح بنشر بسيط وجيد ، CI / CD. لدينا الكثير من هذه الآلات مع الحاويات.
ما في هذه الحالة يعطي Kubernetes؟
- نتوقف عن التفكير في هذه الآلات ونبدأ العمل مع "السحابة" ، وهي مجموعة من الحاويات أو القرون (مجموعات من الحاويات).
- علاوة على ذلك ، نحن لا نفكر في قرون فردية ، ولكننا ندير مجموعات أكبر. تسمح لنا هذه الأولويات عالية المستوى بقول أن هناك نموذجًا لإطلاق عبء عمل معين ، ولكن العدد المطلوب من المثيلات لإطلاقه. إذا قمنا بتغيير القالب لاحقًا ، فستتغير جميع الحالات أيضًا.
- باستخدام واجهة برمجة التطبيقات التعريفية ، بدلاً من تنفيذ سلسلة من الأوامر المحددة ، نصف "الجهاز العالمي" (في YAML) الذي تنشئه Kubernetes. ومرة أخرى: عندما يتغير الوصف ، سيتغير عرضه الحقيقي أيضًا.
إدارة الموارد
وحدة المعالجة المركزية
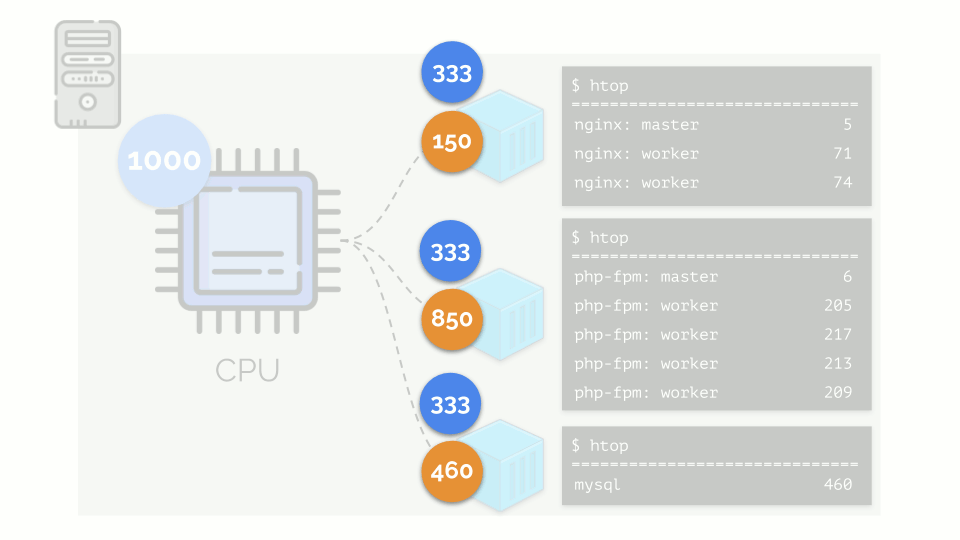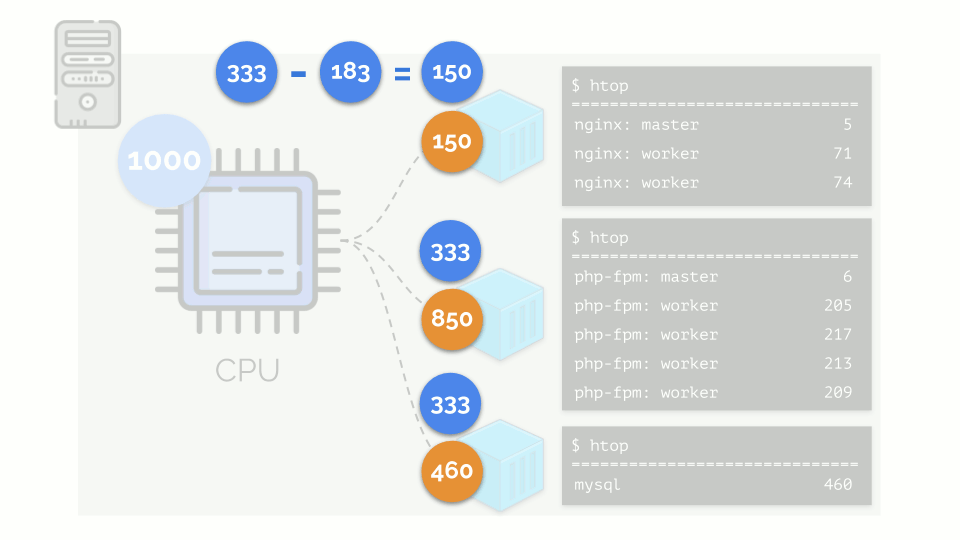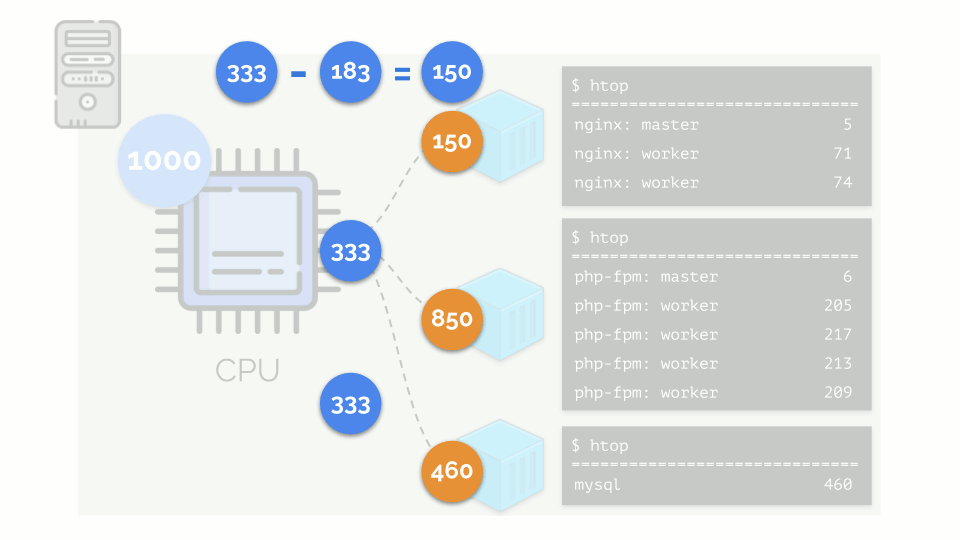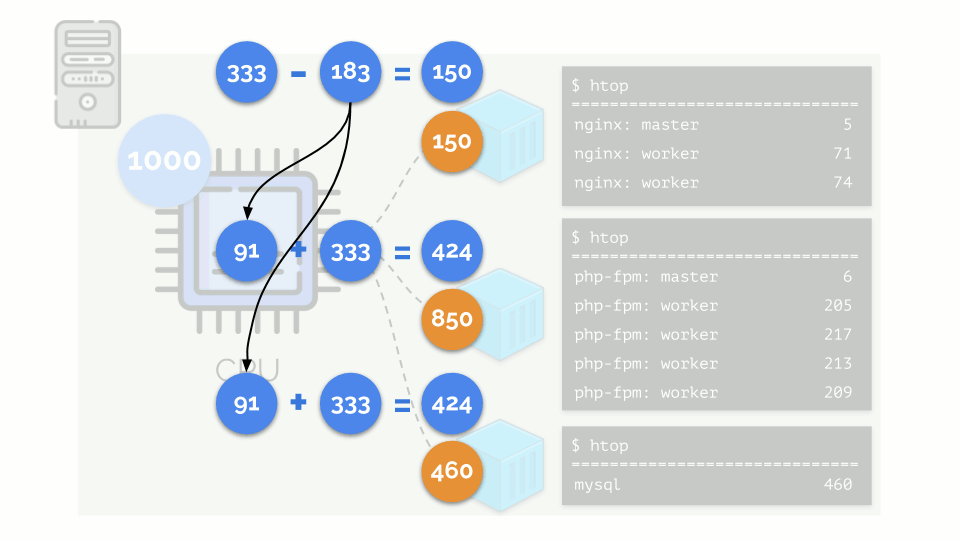
فلنشغل nginx و php-fpm و mysql على الخادم. سيكون لهذه الخدمات في الواقع عمليات أكثر قيد التشغيل ، تتطلب كل منها موارد حسابية:
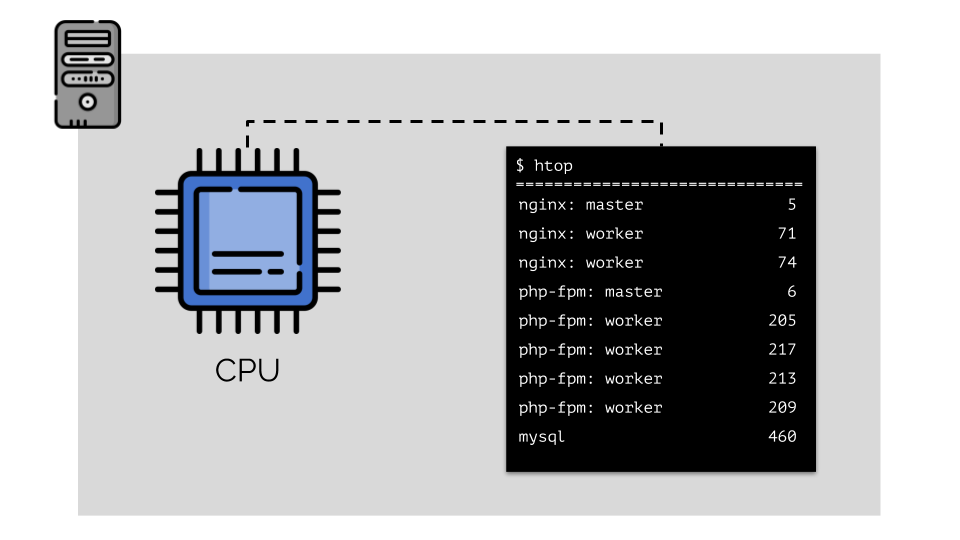 (الأرقام على الشريحة هي "الببغاوات" ، والحاجة المجردة لكل عملية من أجل حساب القوة)
(الأرقام على الشريحة هي "الببغاوات" ، والحاجة المجردة لكل عملية من أجل حساب القوة)لتسهيل التعامل مع هذا ، من المنطقي الجمع بين العمليات في مجموعات (على سبيل المثال ، جميع عمليات nginx في مجموعة "nginx" واحدة). هناك طريقة بسيطة وواضحة للقيام بذلك وهي وضع كل مجموعة في حاوية:
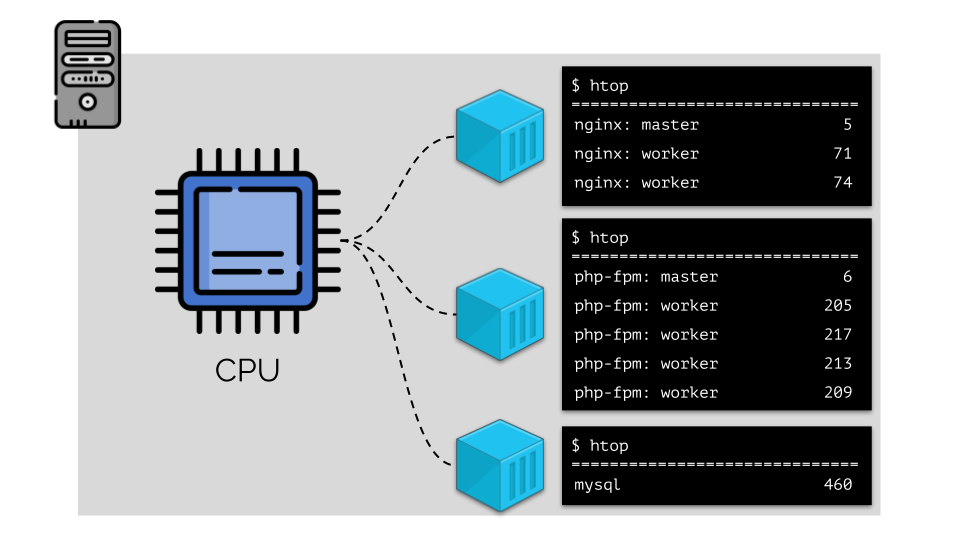
للمتابعة ، يجب أن تتذكر ما هي الحاوية (على Linux). أصبح مظهرها ممكنًا بفضل ثلاث ميزات أساسية في kernel ، تم تنفيذها لفترة طويلة:
القدرات ومساحات الأسماء والمجموعات
cgroups . وساهمت التقنيات الأخرى (بما في ذلك "الأصداف" المريحة مثل Docker) في زيادة التطوير:
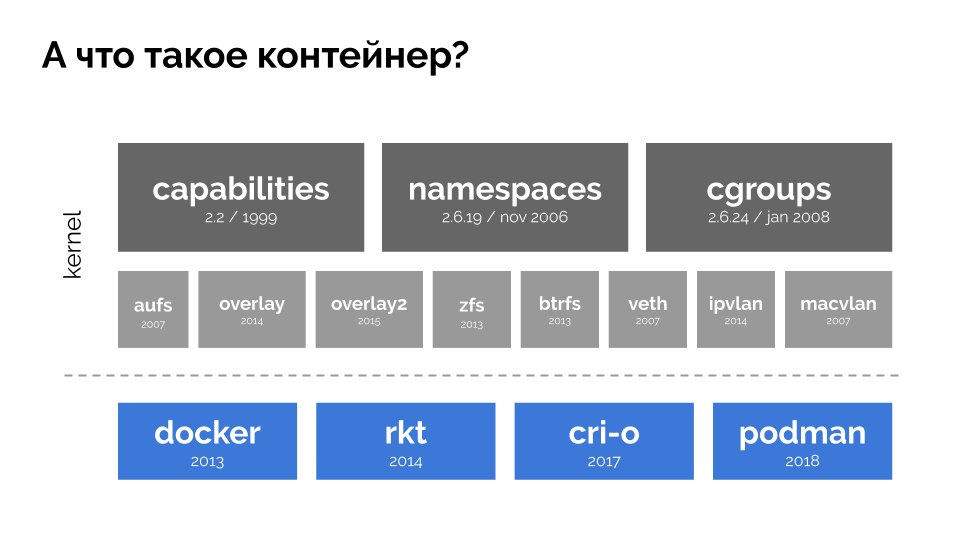
في سياق التقرير ، نحن مهتمون فقط بـ
cgroups ، لأن مجموعات التحكم هي جزء من وظائف الحاويات (Docker ، إلخ) التي تنفذ إدارة الموارد. العمليات ، الموحدة في مجموعات ، كما أردنا ، هي مجموعات المراقبة.
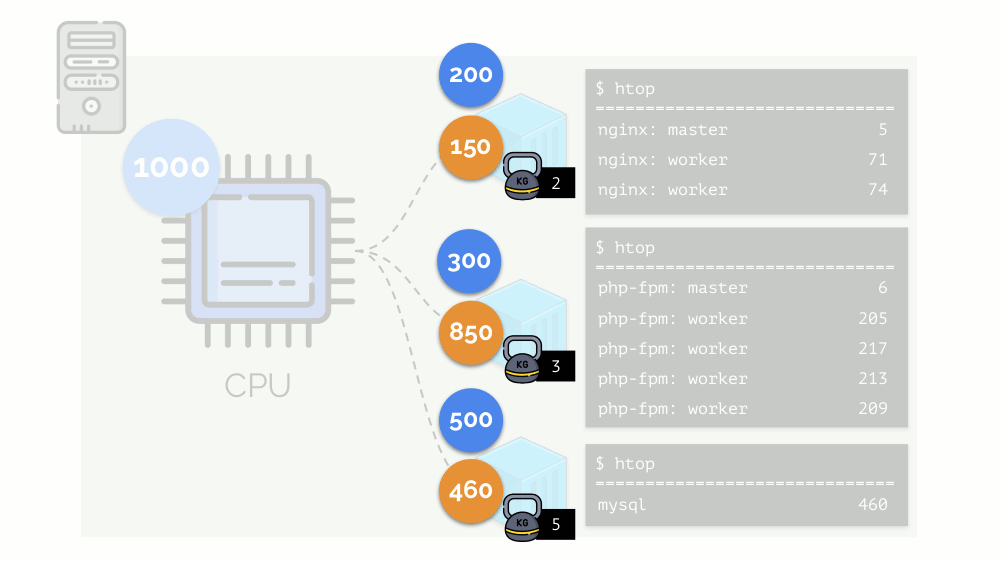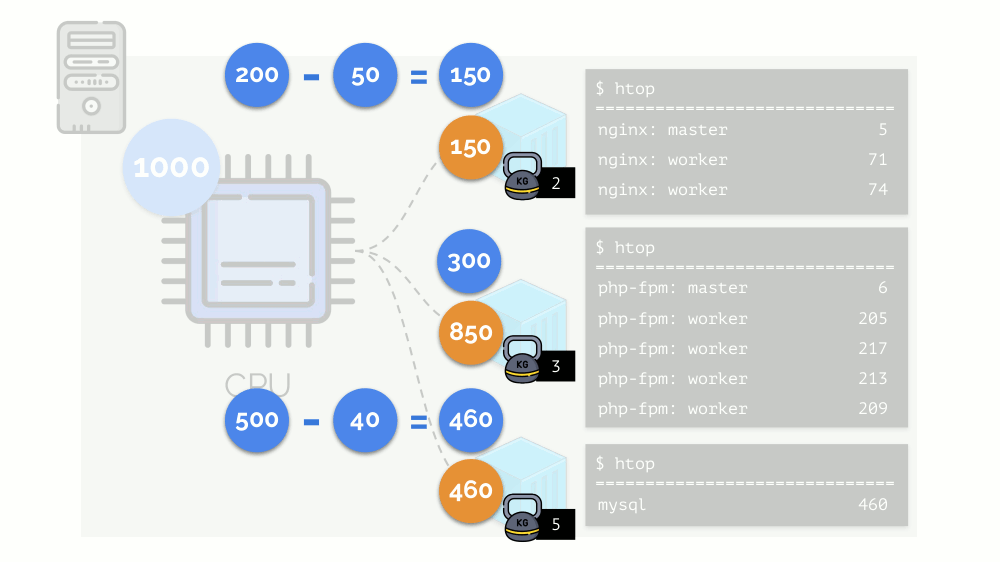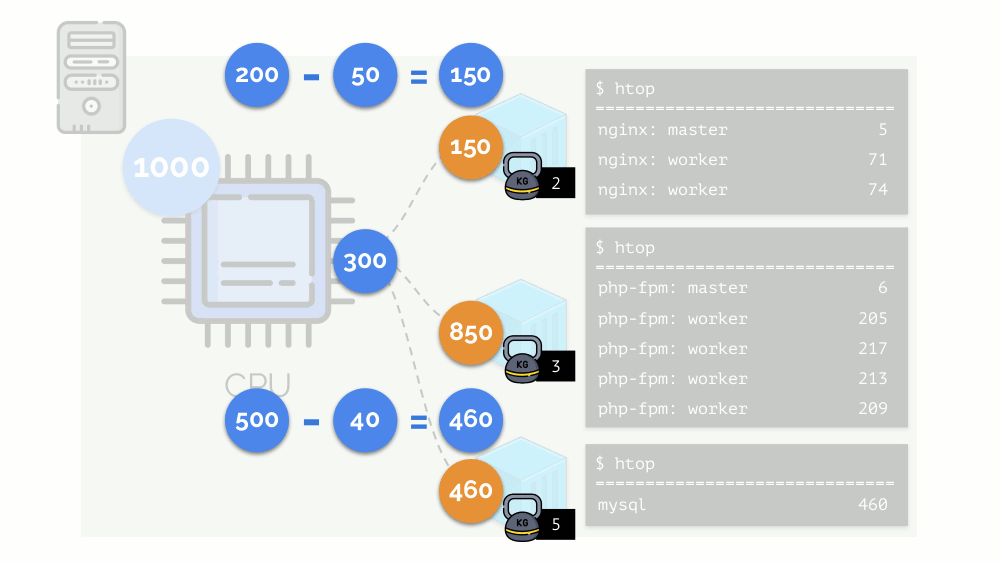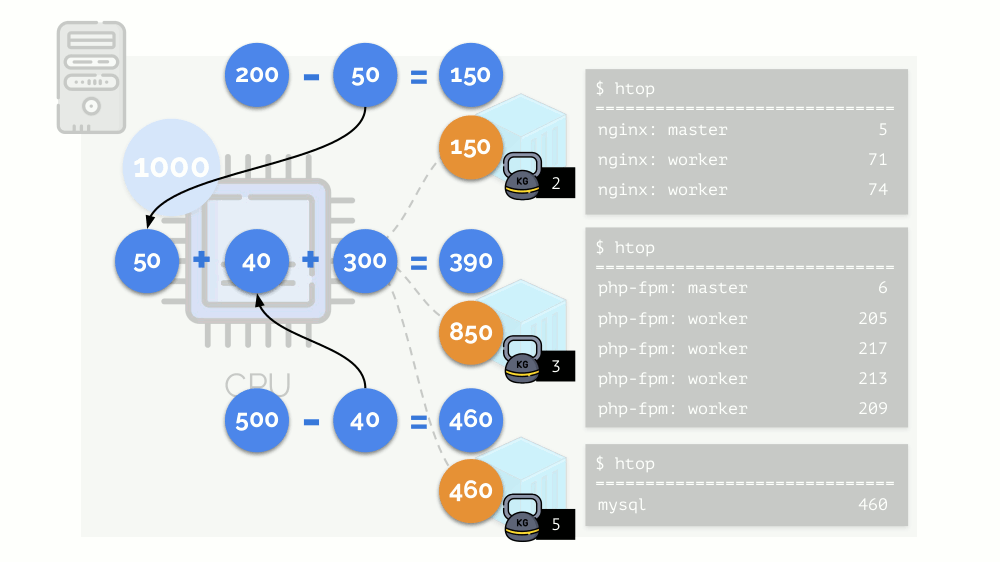
دعنا نعود إلى متطلبات وحدة المعالجة المركزية لهذه العمليات ، والآن لمجموعات العملية:
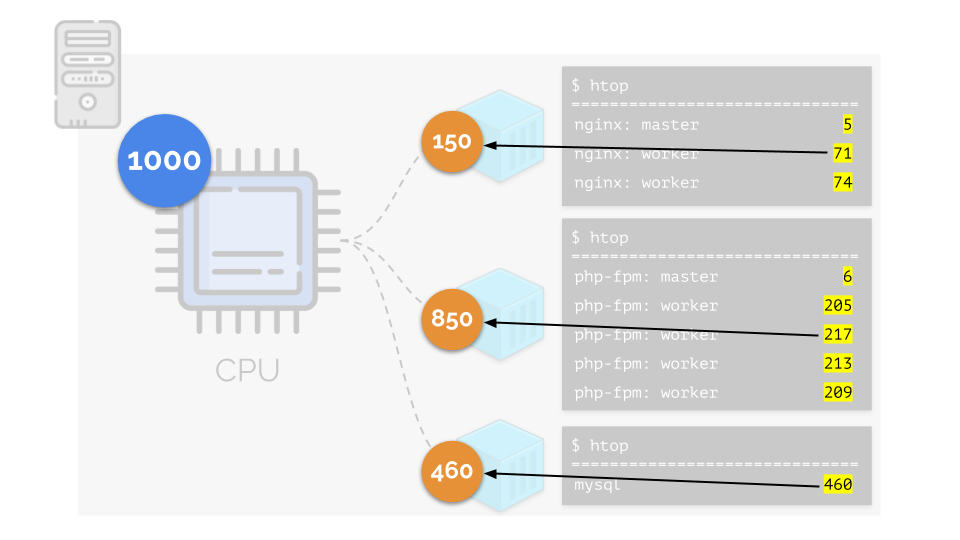 (أكرر أن جميع الأرقام هي تعبير مجردة عن متطلبات الموارد)
(أكرر أن جميع الأرقام هي تعبير مجردة عن متطلبات الموارد)في الوقت نفسه ، تحتوي وحدة المعالجة المركزية نفسها على مورد محدد
(في المثال ، 1000) ، وهو ما قد لا يكون كافياً للجميع (مجموع احتياجات جميع المجموعات هو 150 + 850 + 460 = 1460). ماذا سيحدث في هذه الحالة؟
تبدأ النواة في توزيع الموارد وتنفذها "بأمانة" ، مع إعطاء نفس القدر من الموارد لكل مجموعة. ولكن في الحالة الأولى ، يوجد الكثير منهم أكثر من اللازم (333> 150) ، وبالتالي فإن الفائض (333-150 = 183) لا يزال في الاحتياطي ، والذي يتم توزيعه أيضًا بالتساوي بين حاويتين أخريين:
نتيجة لذلك: كانت الحاوية الأولى لديها موارد كافية ، والحاوية الثانية - لم تكن كافية ، والثالثة - لم تكن كافية. هذه هي نتيجة برنامج
الجدولة "الصادق" في Linux -
CFS . يمكن تنظيم عملها من خلال تحديد
الوزن لكل حاوية. على سبيل المثال ، مثل هذا:
دعونا نلقي نظرة على حالة نقص الموارد في الحاوية الثانية (php-fpm). يتم توزيع جميع موارد الحاويات بين العمليات على قدم المساواة. نتيجة لذلك ، تعمل العملية الرئيسية بشكل جيد ، ويبطئ جميع العمال ، ويتلقون أقل من نصف ما هو مطلوب:
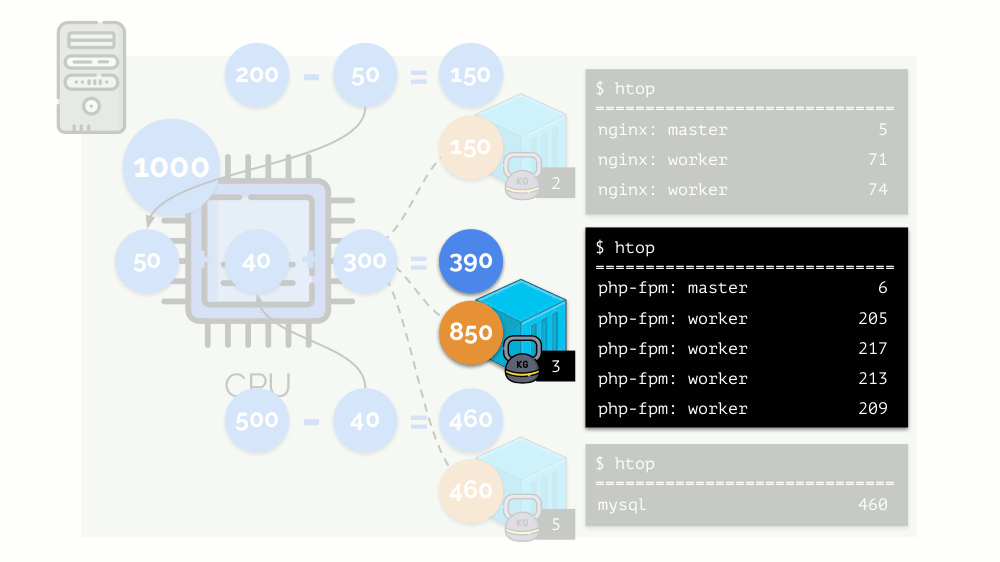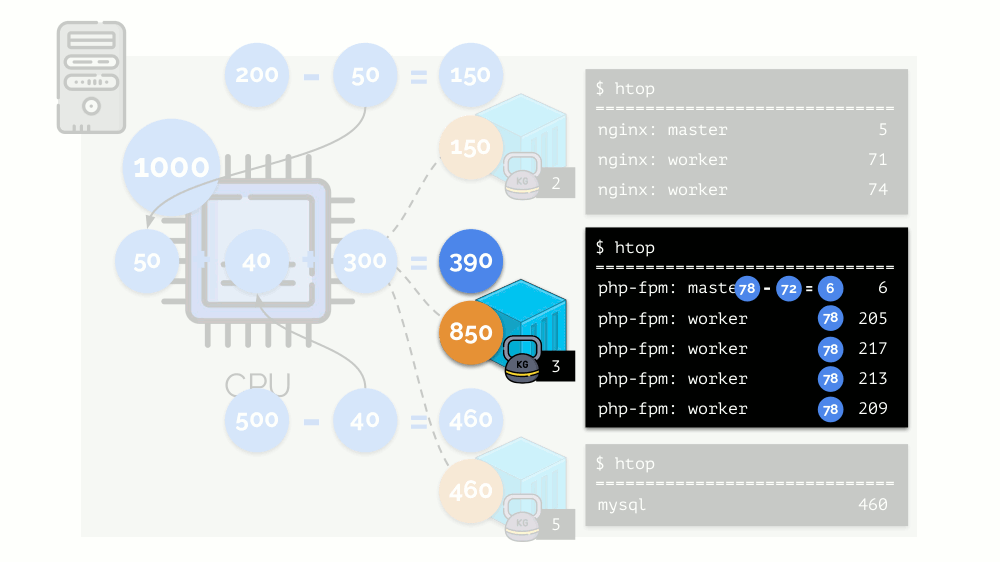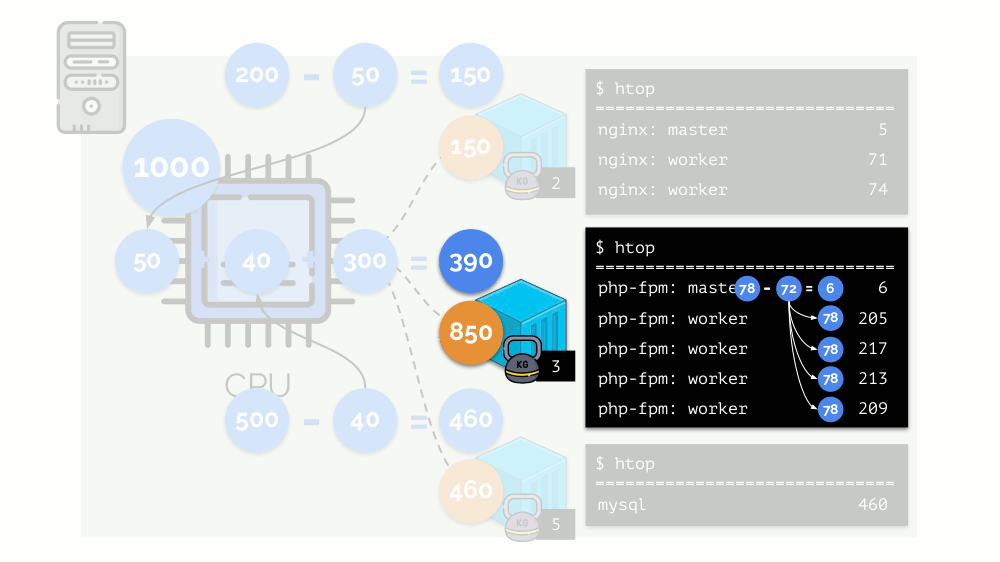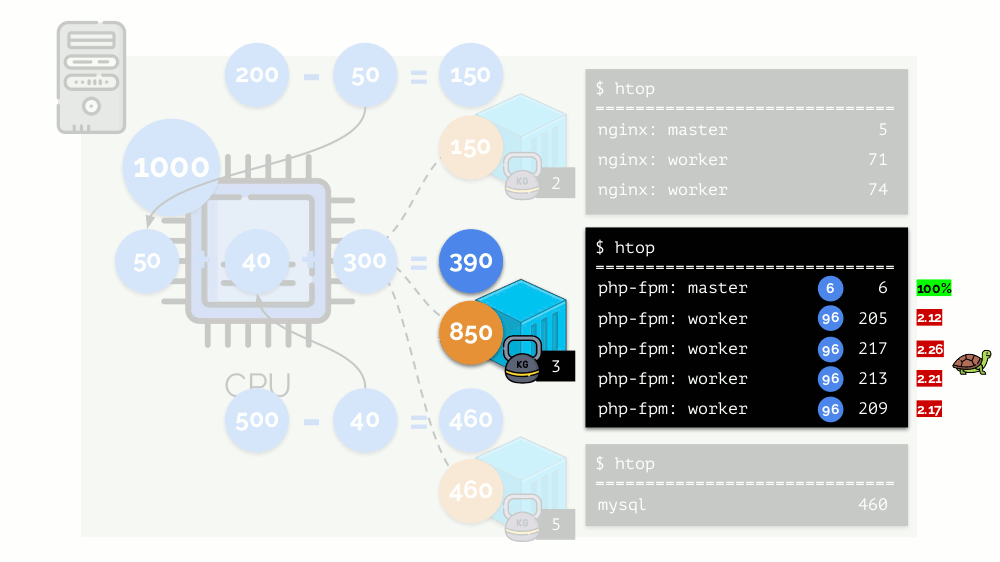
هذه هي الطريقة التي يعمل بها جدولة CFS. الأوزان التي نخصصها للحاويات سوف تسمى
طلبات في المستقبل. لماذا هكذا - انظر أدناه.
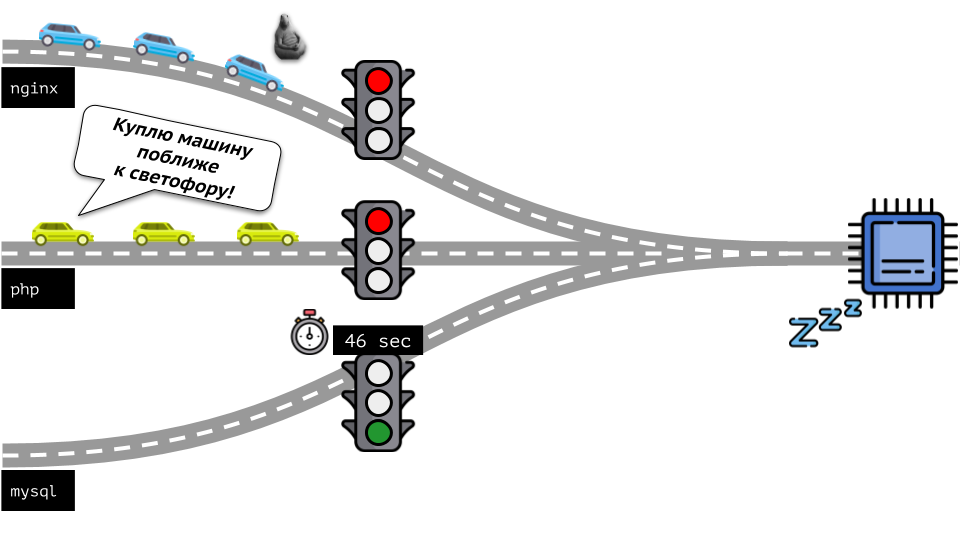
دعنا نلقي نظرة على الوضع برمته من الجانب الآخر. كما تعلم ، كل الطرق تؤدي إلى روما ، وفي حالة الكمبيوتر إلى وحدة المعالجة المركزية. وحدة المعالجة المركزية واحدة ، والكثير من المهام - تحتاج إلى إشارة المرور. أسهل طريقة لإدارة الموارد هي "إشارة المرور": فهي تمنح عملية واحدة وقت وصول ثابت إلى وحدة المعالجة المركزية ، ثم العملية التالية ، إلخ.
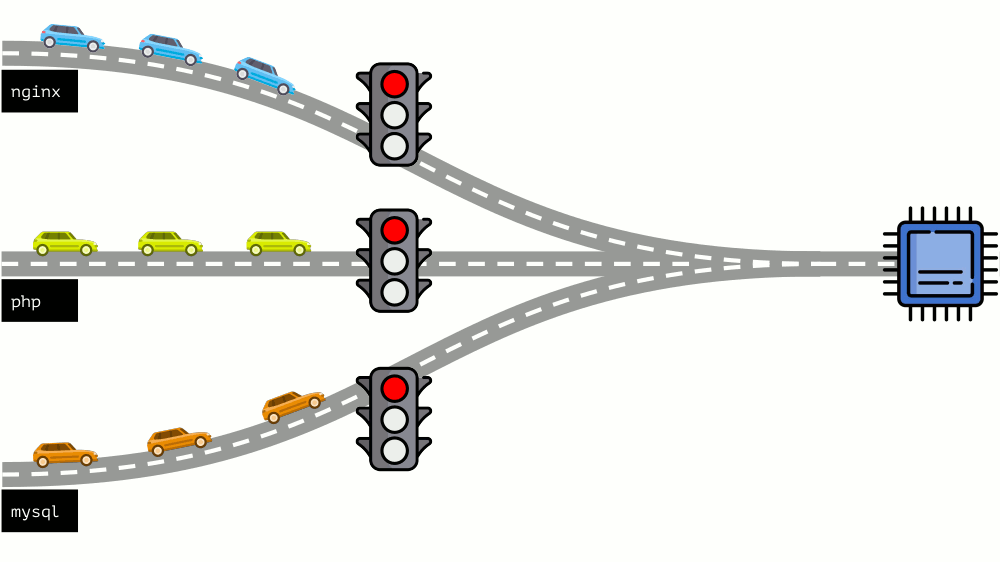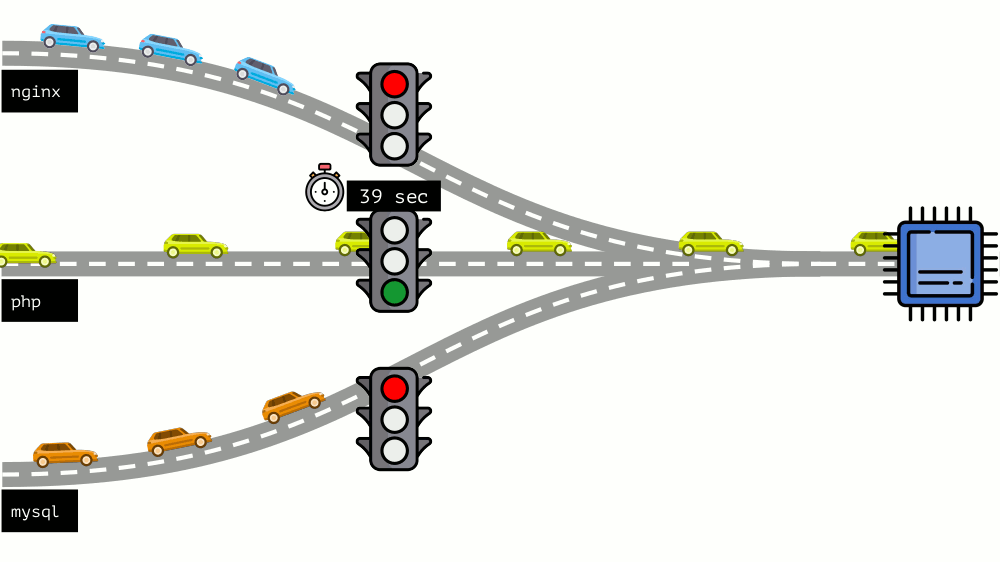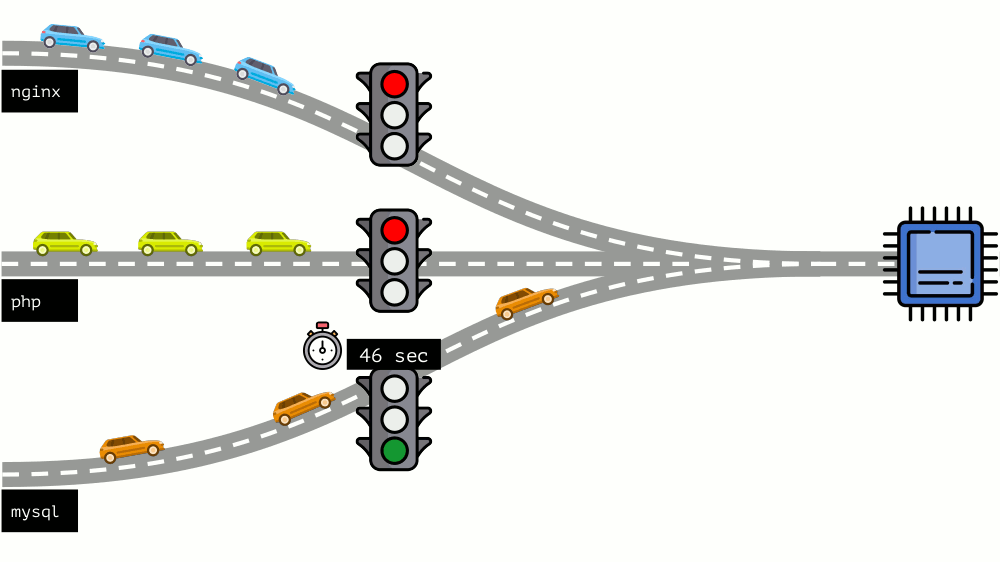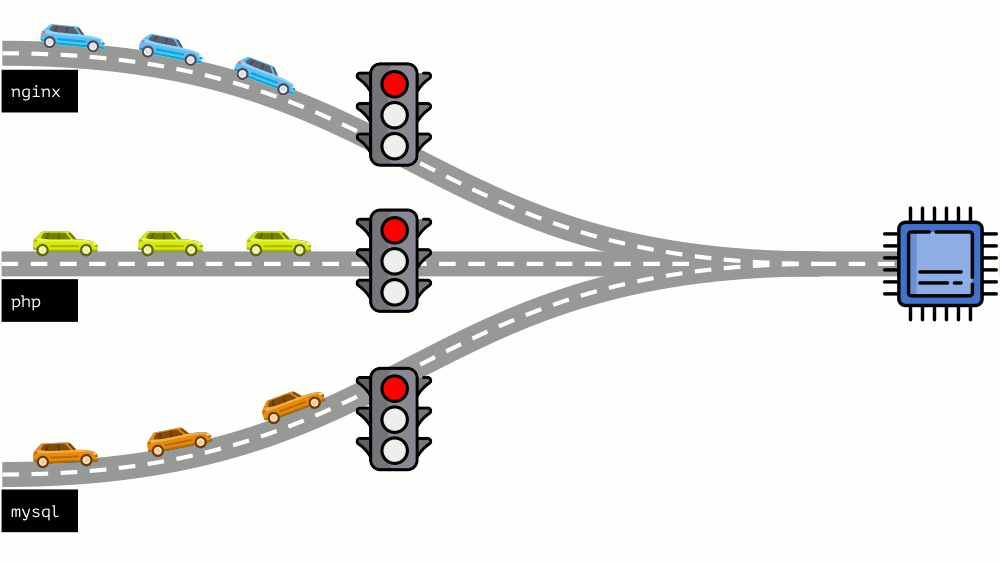
ويسمى هذا النهج
الحد الثابت . تذكرها
كحدود . ومع ذلك ، إذا قمت بتوزيع حدود على جميع الحاويات ، فستظهر مشكلة: كان mysql يقود سيارته على الطريق ، وفي وقت من الأوقات ، كانت حاجته إلى وحدة المعالجة المركزية قد انتهت ، ولكن اضطرت جميع العمليات الأخرى إلى الانتظار أثناء توقف وحدة المعالجة المركزية عن
العمل .
دعنا نعود إلى نواة لينكس وتفاعلها مع وحدة المعالجة المركزية - الصورة العامة هي كما يلي:
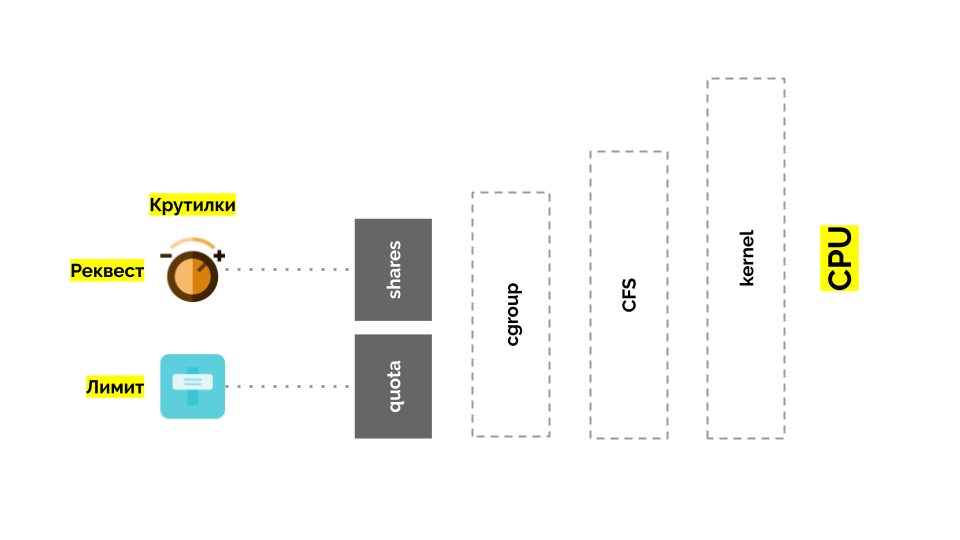
يحتوي Cgroup على إعدادين - في الواقع ، هذان هما "تطوران" بسيطان يسمحان لك بتحديد:
- وزن الحاوية (طلب) هو سهم ؛
- النسبة المئوية من إجمالي وقت وحدة المعالجة المركزية للعمل على مهام الحاوية (الحدود) هي الحصة النسبية .
كيفية قياس وحدة المعالجة المركزية؟
هناك طرق مختلفة:
- ما هي الببغاوات ، لا أحد يعرف - في كل مرة تحتاج إلى الاتفاق.
- الاهتمام أكثر وضوحًا ، لكن نسبيًا: 50٪ من الخوادم التي تحتوي على 4 مراكز و 20 مركزًا مختلفة تمامًا.
- يمكنك استخدام الأوزان التي سبق ذكرها والتي يعرفها Linux ، لكنها أيضًا نسبية.
- الخيار الأكثر ملاءمة هو قياس موارد الحوسبة في ثوان . أي في ثوانٍ من وقت المعالج بالنسبة لثواني الوقت الفعلي: لقد أعطوا ثانية واحدة من وقت المعالج في ثانية واحدة حقيقية - هذا هو وحدة المعالجة المركزية واحدة كاملة.
لجعل الأمر أسهل في القول ، بدأوا في القياس مباشرة في
النوى ، مما يعني وقت وحدة المعالجة المركزية بالنسبة إلى الوقت الحقيقي. نظرًا لأن Linux يفهم الأوزان بدلاً من الوقت / النوى للمعالج ، فقد كانت هناك حاجة إلى آلية ترجمة من واحدة إلى أخرى.
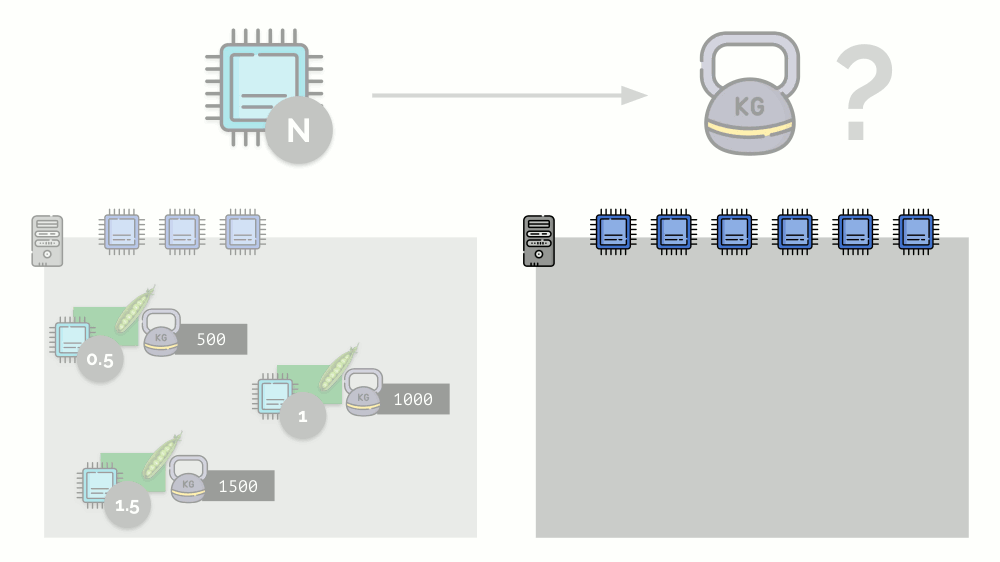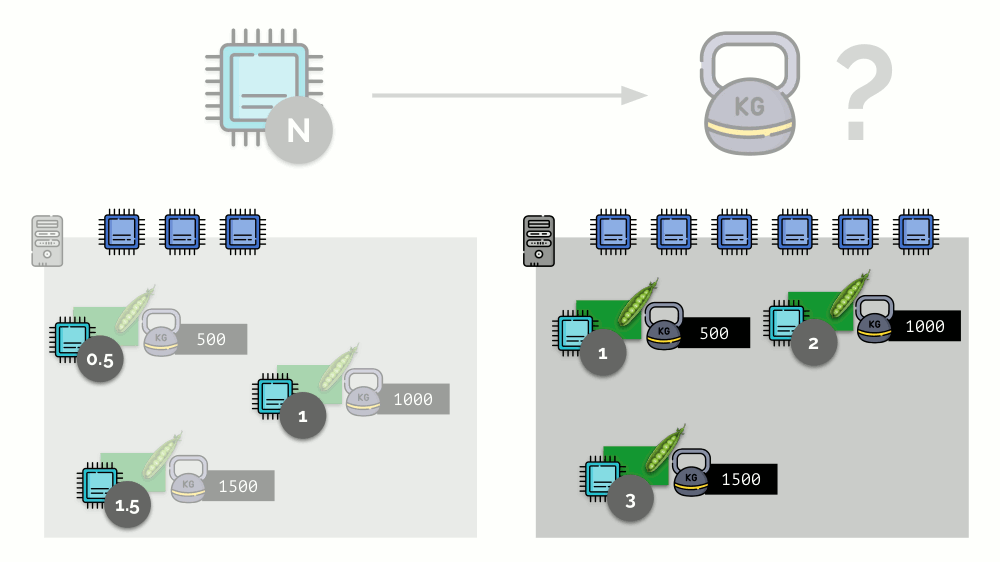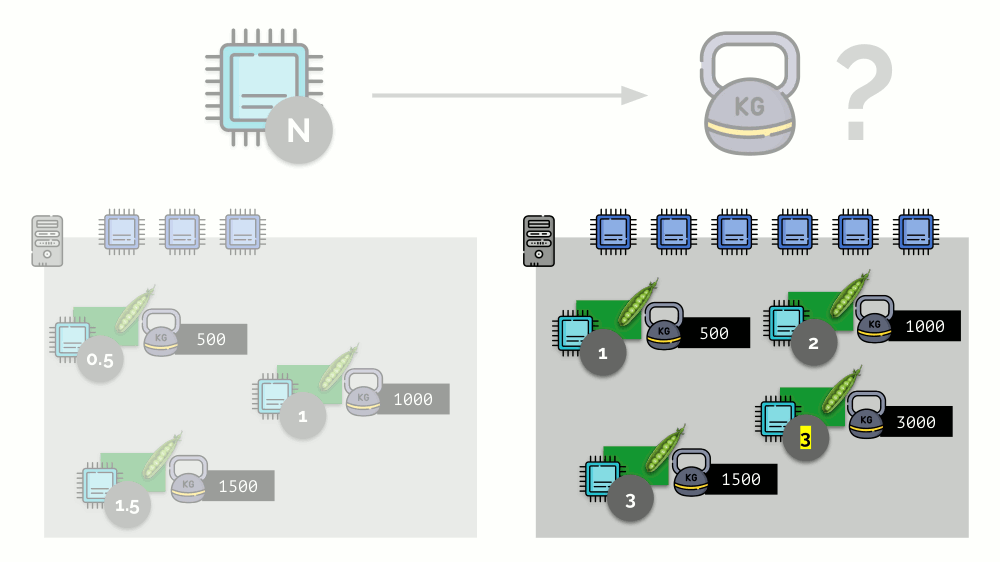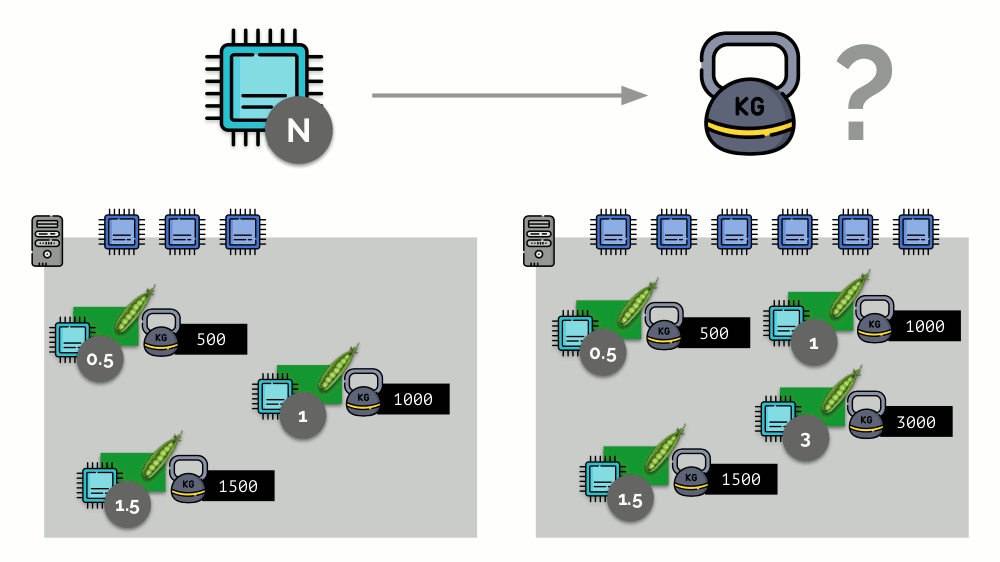
خذ مثالاً بسيطًا على خادم مزود بثلاثة مراكز للوحدة المعالجة المركزية (CPU) ، حيث ستختار ثلاثة قرون أوزان (500 و 1000 و 1500) يمكن تحويلها بسهولة إلى الأجزاء المقابلة من المراكز المخصصة لها (0.5 و 1 و 1.5).
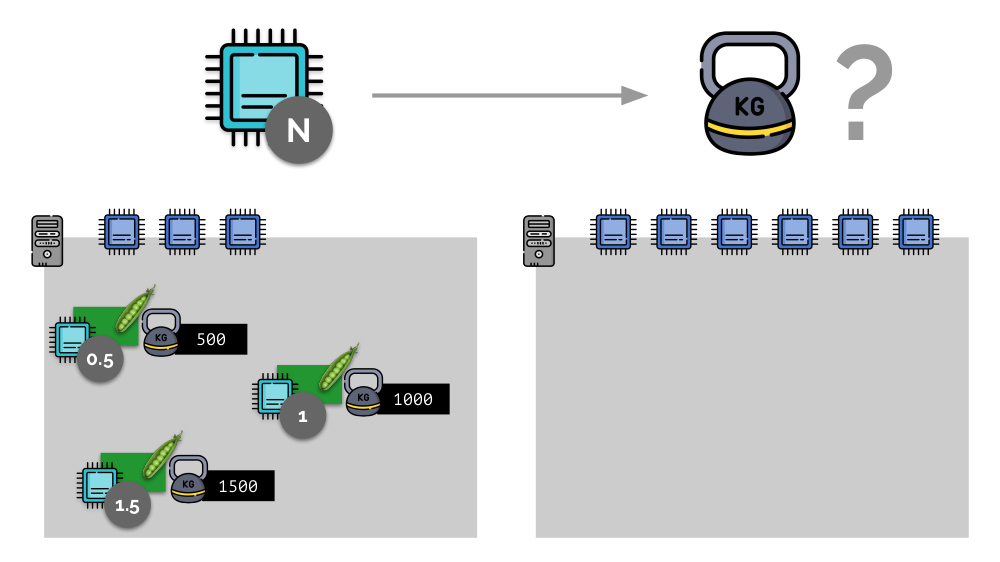
إذا كنت تأخذ خادمًا ثانيًا ، حيث سيكون هناك ضعف عدد النوى (6) وتضع نفس السنفات هناك ، فيمكن حساب توزيع النوى بسهولة بضرب 2 (1 و 2 و 3 على التوالي). لكن النقطة المهمة تحدث عندما يظهر الجراب الرابع على هذا الخادم ، الذي يبلغ وزنه 3000 للراحة. فهو يأخذ بعض موارد وحدة المعالجة المركزية (نصف النوى) ، بينما يقوم باقي الجراب بإعادة فرزها (النصف):
Kubernetes وموارد وحدة المعالجة المركزية
في Kubernetes ، عادةً ما يتم قياس موارد وحدة المعالجة المركزية بالميلي ، أي يتم أخذ 0.001 حبات كوزن أساسي.
(نفس الشيء في مصطلحات Linux / cgroups يُسمى مشاركة وحدة المعالجة المركزية (CPU) ، على الرغم من أن أكثر دقة ، 1000 وحدة مشاركة = 1024 وحدة مشاركة وحدة المعالجة المركزية.) K8s تتأكد من عدم وضع المزيد من القرون على الخادم من موارد وحدة المعالجة المركزية لمجموع الأوزان جميع القرون.
كيف الحال؟ عندما تتم إضافة خادم إلى كتلة Kubernetes ، فإنه يبلغ عن عدد نوى وحدة المعالجة المركزية المتاحة له. وعند إنشاء جراب جديد ، يعرف مجدول Kubernetes عدد النوى التي يحتاج إليها هذا الجراب. وبالتالي ، سيتم تعريف جراب على الخادم ، حيث يوجد عدد كاف من النوى.
ماذا سيحدث إذا
لم يتم تحديد الطلب (على سبيل المثال ، لا يحدد pod عدد النواة التي يحتاجها)؟ دعونا نرى كيف تحسب Kubernetes الموارد بشكل عام.
يمكن أن يحدد جراب كلا الطلبات (جدولة CFS) والحدود (تذكر إشارة المرور؟):
- إذا كانت متساوية ، فسيتم تعيين فئة جودة الخدمة المضمونة إلى الحافظة. ويضمن مثل هذه الكمية من حبات المتاحة دائما له.
- إذا كان الطلب أقل من الحد ، تكون فئة جودة الخدمة قابلة للانفجار . أي نتوقع أن pod ، على سبيل المثال ، يستخدم دائمًا كورًا واحدًا ، ولكن هذه القيمة ليست قيدًا على ذلك: في بعض الأحيان يمكن أن يستخدم pod أكثر (عندما تكون هناك موارد مجانية على الخادم لهذا).
- هناك أيضًا أفضل نوعية لجودة الخدمة - تلك القرون التي لم يتم تحديد طلب تخصها. يتم إعطاء الموارد لهم الماضي.
الذاكرة
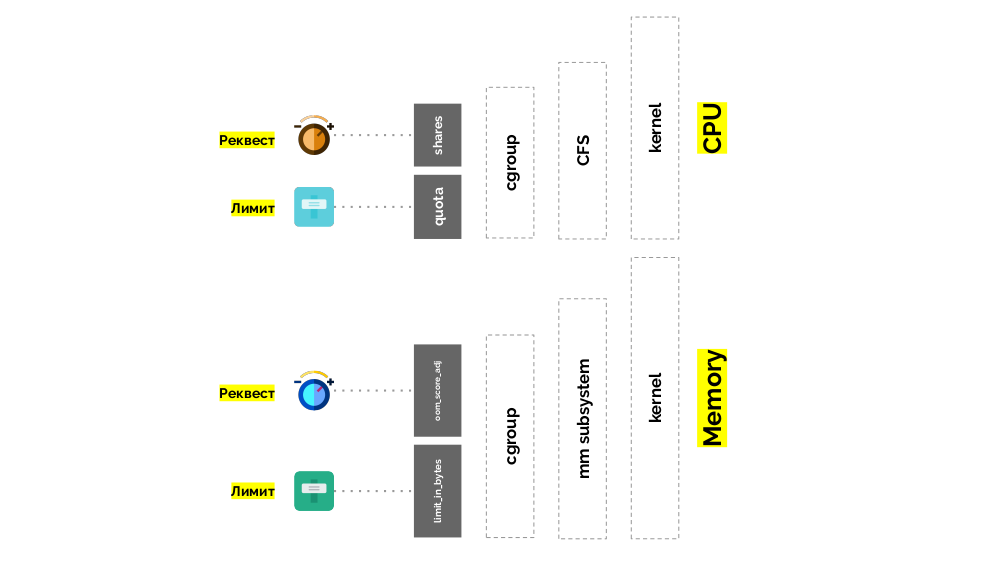
الموقف مشابه للذاكرة ، ولكنه يختلف قليلاً - بعد كل شيء ، تختلف طبيعة هذه الموارد. بشكل عام ، فإن القياس هو كما يلي:
دعونا نرى كيف يتم تنفيذ الطلبات في الذاكرة. اسمح للقرون بالعيش على الخادم ، وتغيير الذاكرة المستهلكة ، حتى يصبح أحدها كبيرًا بحيث نفدت الذاكرة. في هذه الحالة ، يظهر قاتل OOM ويقتل أكبر عملية:
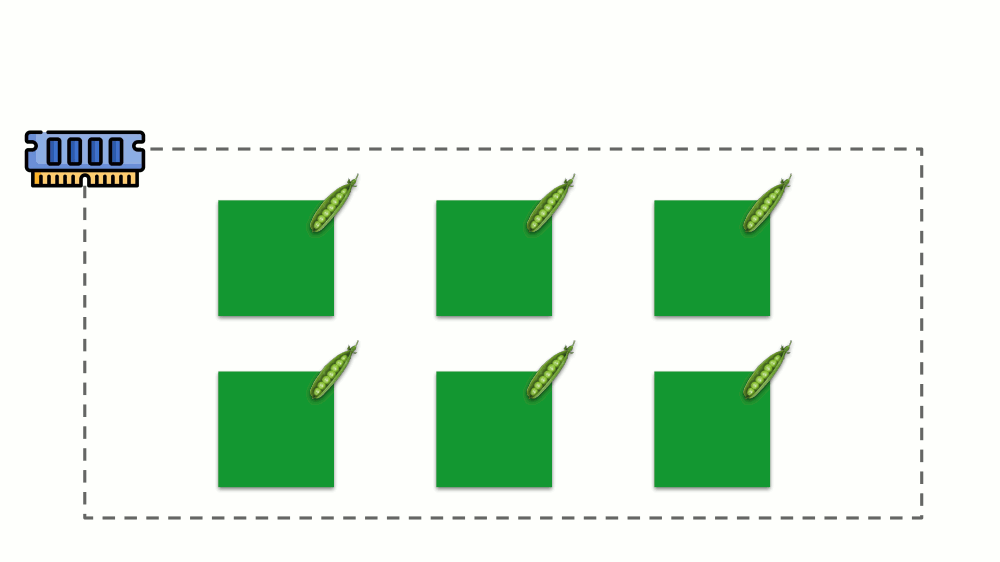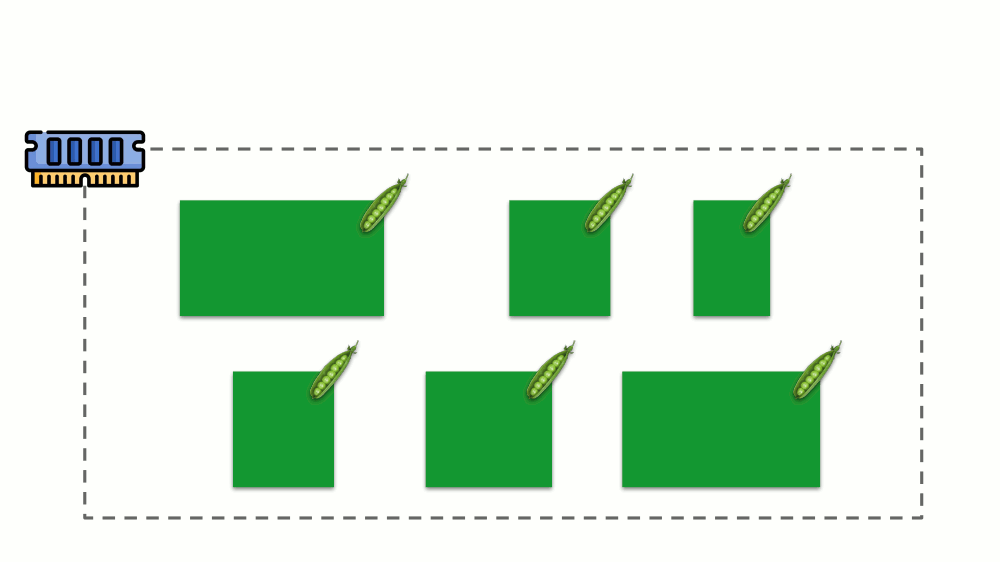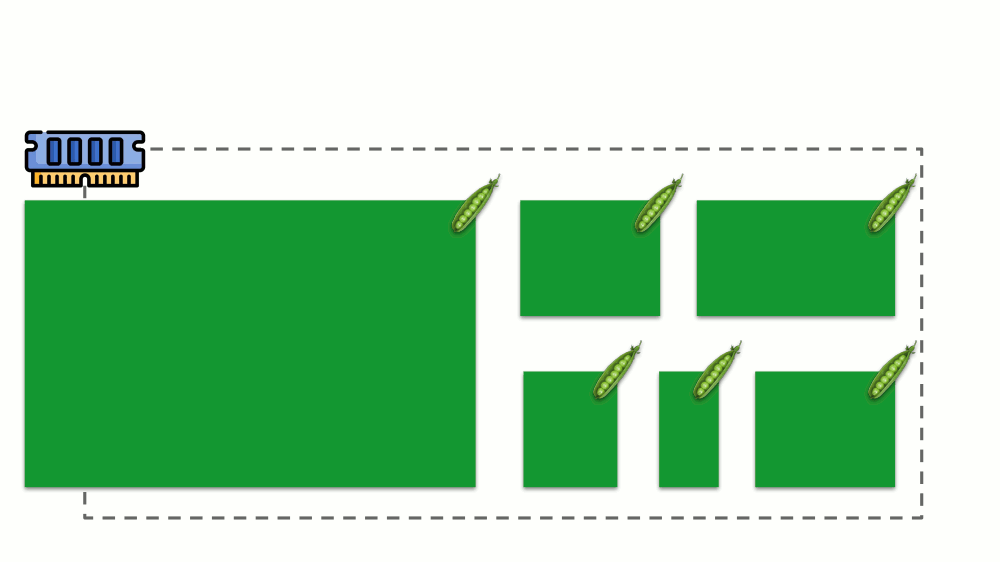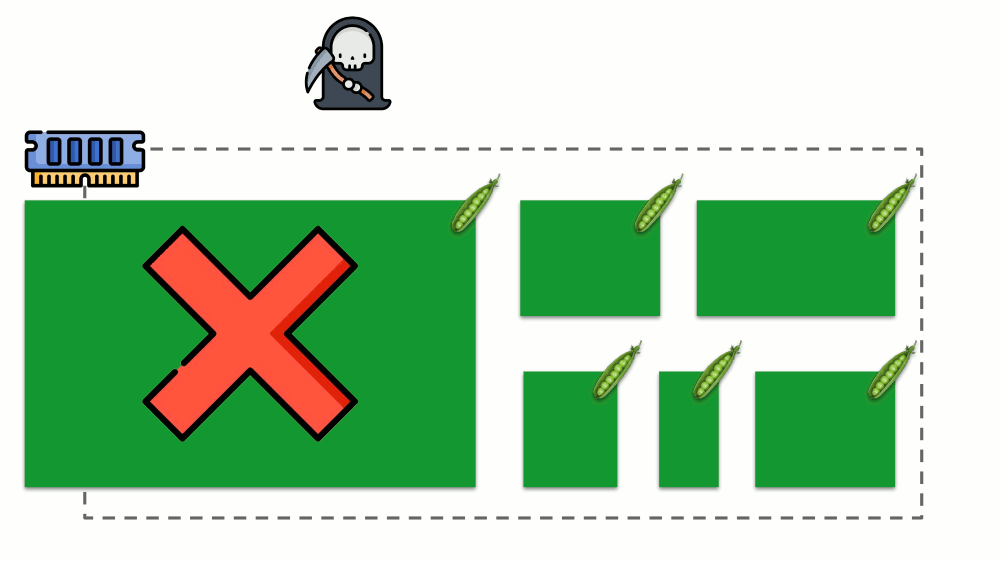
هذا لا يناسبنا دائمًا ، لذلك ، من الممكن تنظيم العمليات المهمة بالنسبة لنا ويجب ألا يتم قتلها. للقيام بذلك ، استخدم المعلمة
oom_score_adj .
دعنا نعود إلى فئات جودة الخدمة في وحدة المعالجة المركزية ونرسم تشابهاً مع القيم oom_score_adj ، التي تحدد أولويات قرون على استهلاك الذاكرة:
- أدنى قيمة oom_score_adj من pod هي -998 ، مما يعني أنه يجب قتل هذا pod في المكان الأخير ، وهذا مضمون .
- أعلى - 1000 - هو أفضل جهد ، يتم قتل هذه القرون قبل أي شخص آخر.
- لحساب بقية القيم ( القابلة للانفجار ) ، هناك صيغة يتلخص جوهرها في حقيقة أنه كلما زاد عدد الموارد المطلوبة المطلوبة ، قل احتمال قتله.

الثاني "تطور" -
limit_in_bytes - للحدود. كل شيء أبسط من ذلك: نحن ببساطة نخصص الحد الأقصى لمقدار الذاكرة التي سيتم إصدارها ، وهنا (على عكس وحدة المعالجة المركزية) لا يوجد أي شك في ما تقاس به (الذاكرة).
في المجموع
يتم تعيين الطلبات
limits لكل جراب في Kubernetes - كلا معلمات وحدة المعالجة المركزية والذاكرة:
- بناءً على الطلبات ، يعمل برنامج جدولة Kubernetes ، الذي يوزع القرون عبر الخوادم ؛
- بناءً على جميع المعلمات ، يتم تحديد فئة QodS الخاصة بالجراب ؛
- يتم حساب الأوزان النسبية بناءً على طلبات وحدة المعالجة المركزية ؛
- بناءً على طلبات وحدة المعالجة المركزية ، يتم تكوين برنامج جدولة CFS ؛
- بناءً على طلبات الذاكرة ، يتم تكوين قاتل OOM ؛
- استنادا إلى حدود وحدة المعالجة المركزية ، يتم تعيين إشارة المرور.
- بناءً على حدود الذاكرة ، يتم تعيين حد على cgroup.
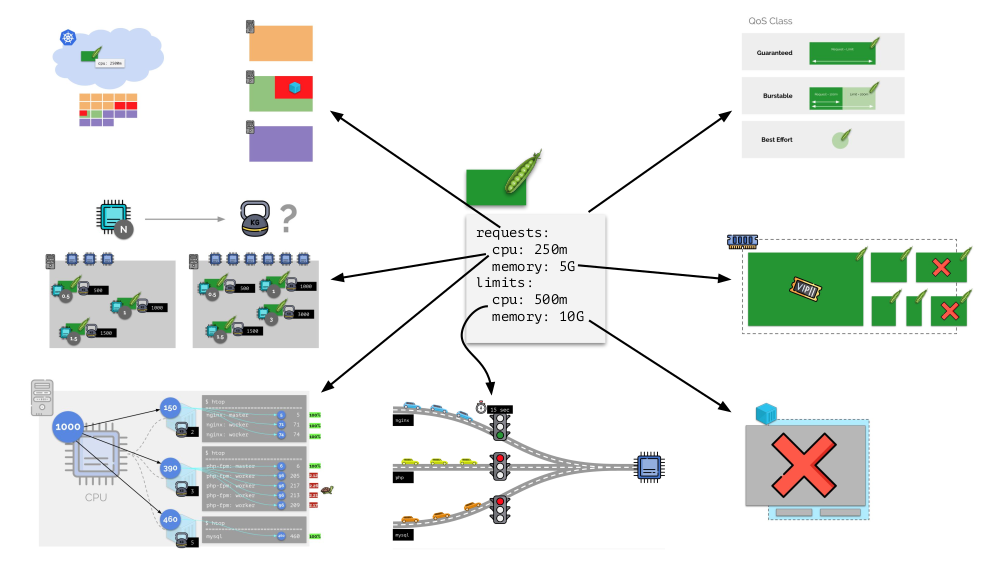
بشكل عام ، تجيب هذه الصورة على جميع الأسئلة حول كيفية حدوث الجزء الرئيسي من إدارة الموارد في Kubernetes.
autoscaling
K8s الكتلة autoscaler
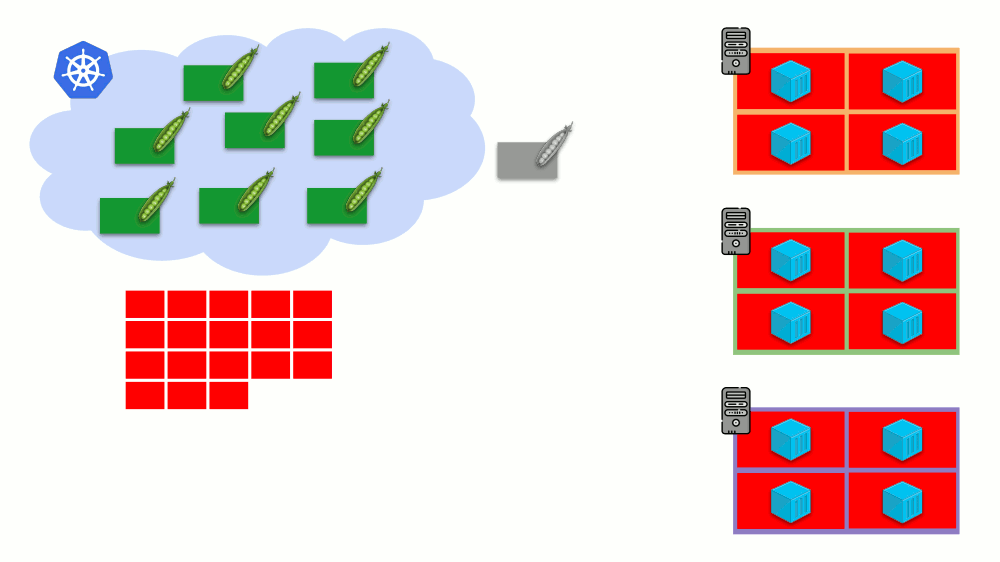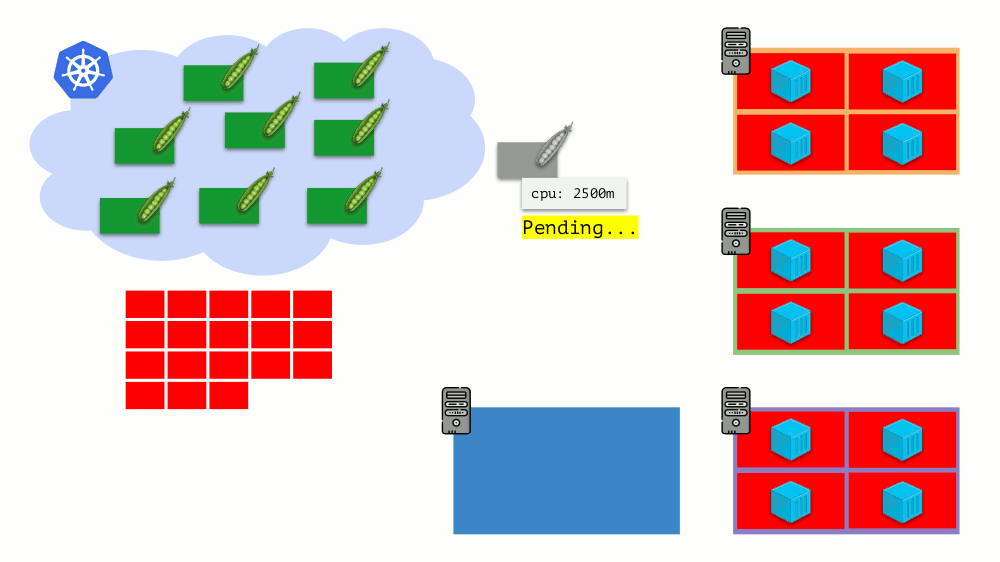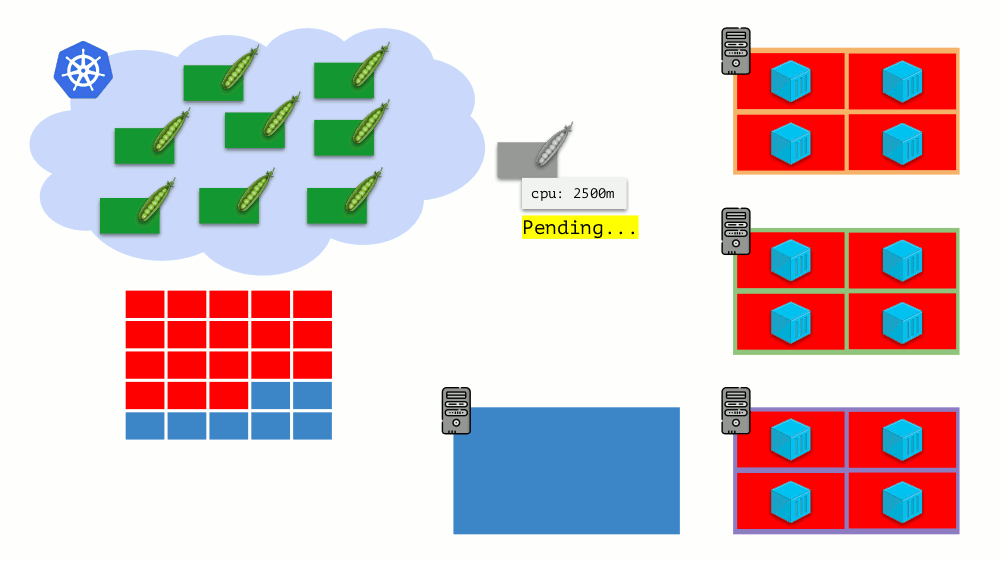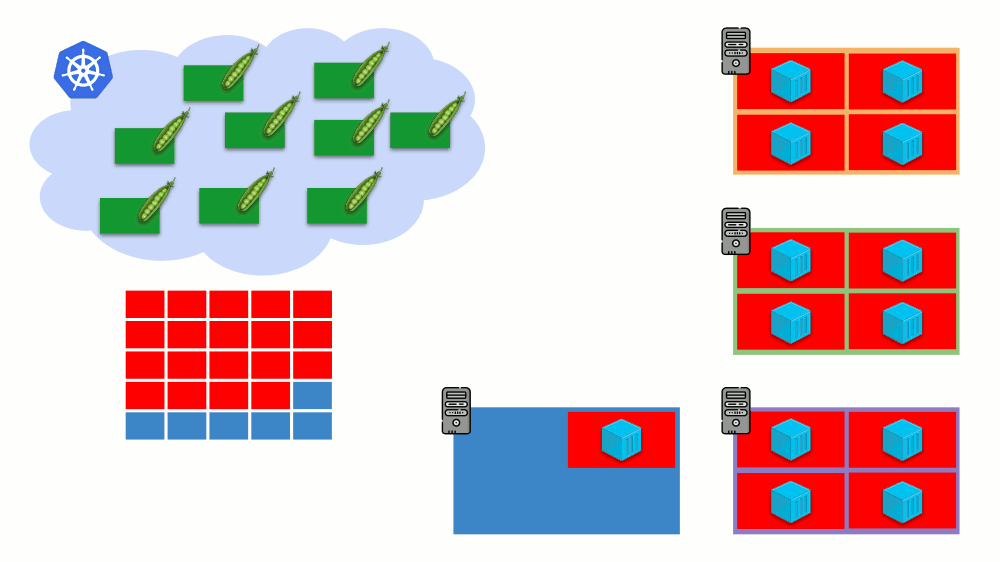
تخيل أن المجموعة بأكملها مشغولة بالفعل ويجب إنشاء جراب جديد. في حين لا يمكن ظهور الجراب ، إلا أنه معلق في حالة
الانتظار . لكي يظهر ، يمكننا توصيل خادم جديد بالكتلة أو ... وضع نظام الكتل الأوتوماتيكي ، الذي سيؤدي ذلك من أجلنا: طلب جهاز ظاهري من الموفر السحابي (حسب طلب API) وتوصيله بالكتلة ، وبعد ذلك ستتم إضافة الحافظة .
هذا هو التحجيم التلقائي لمجموعة Kubernetes ، والتي تعمل بشكل رائع (في تجربتنا). ومع ذلك ، كما هو الحال في أي مكان آخر ، هناك بعض الفروق الدقيقة هنا ...
بينما كنا نعمل على زيادة حجم الكتلة ، كان كل شيء على ما يرام ، ولكن ماذا يحدث عندما
بدأت الكتلة في التحرير؟ تكمن المشكلة في أن نقل القرون (إلى المضيفين المجانين) أمر صعب للغاية ومكلف تقنيًا من حيث الموارد. Kubernetes لديه نهج مختلف تماما.
النظر في مجموعة من 3 خوادم التي يوجد فيها النشر. لديه 6 قرون: الآن هو 2 لكل خادم. لسبب ما ، أردنا إيقاف تشغيل أحد الخوادم. للقيام بذلك ، استخدم الأمر
kubectl drain ، وهو:
- يحظر إرسال قرون جديدة إلى هذا الخادم ؛
- إزالة القرون الموجودة على الخادم.
نظرًا لأن Kubernetes يراقب الحفاظ على عدد القرون (6) ، فبإمكانه ببساطة
إعادة إنشائها على العقد الأخرى ، ولكن ليس على العقد المنفصلة ، حيث تم تمييزها بالفعل على أنها غير قابلة للوصول إلى استضافة قرون جديدة. هذا هو الميكانيكا الأساسية ل Kubernetes.

ومع ذلك ، هناك فارق بسيط هنا. في موقف مشابه لإجراءات StatefulSet (بدلاً من النشر) ستكون مختلفة. الآن لدينا بالفعل تطبيق حالي - على سبيل المثال ، ثلاثة قرون مع MongoDB ، أحدها يعاني من نوع من المشاكل (البيانات سيئة أو خطأ آخر يمنع بدء التشغيل بشكل صحيح). ومرة أخرى نقرر قطع خادم واحد. ماذا سيحدث؟
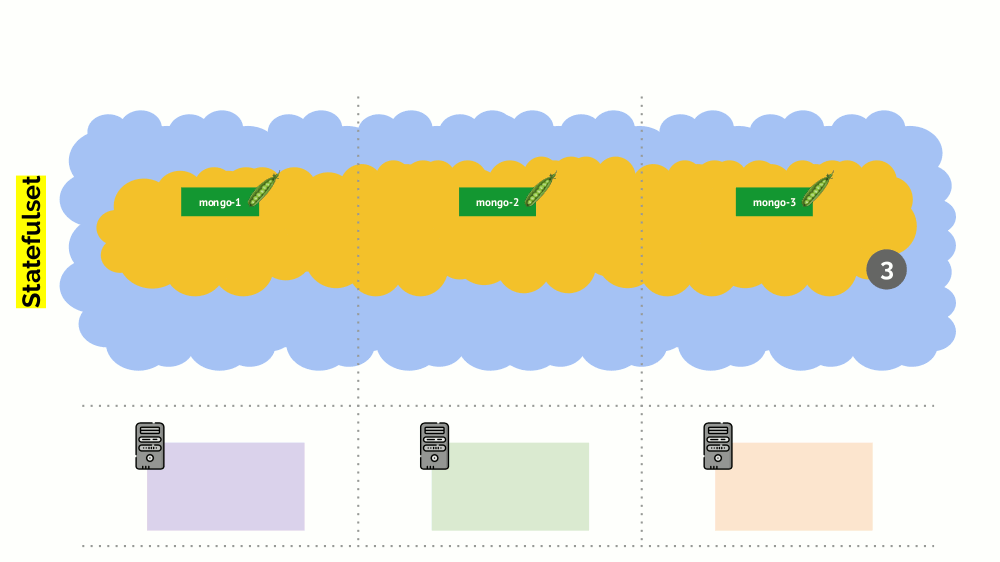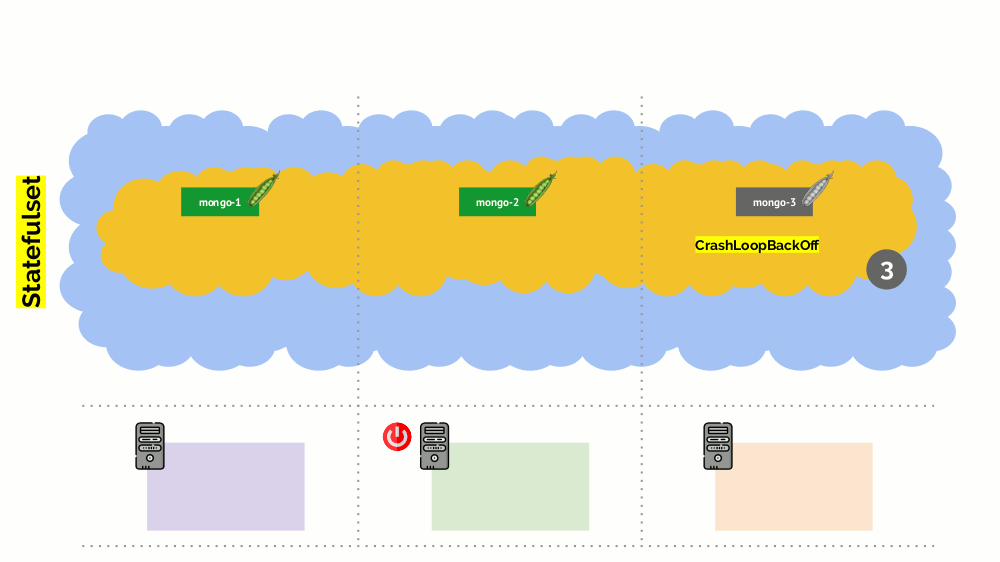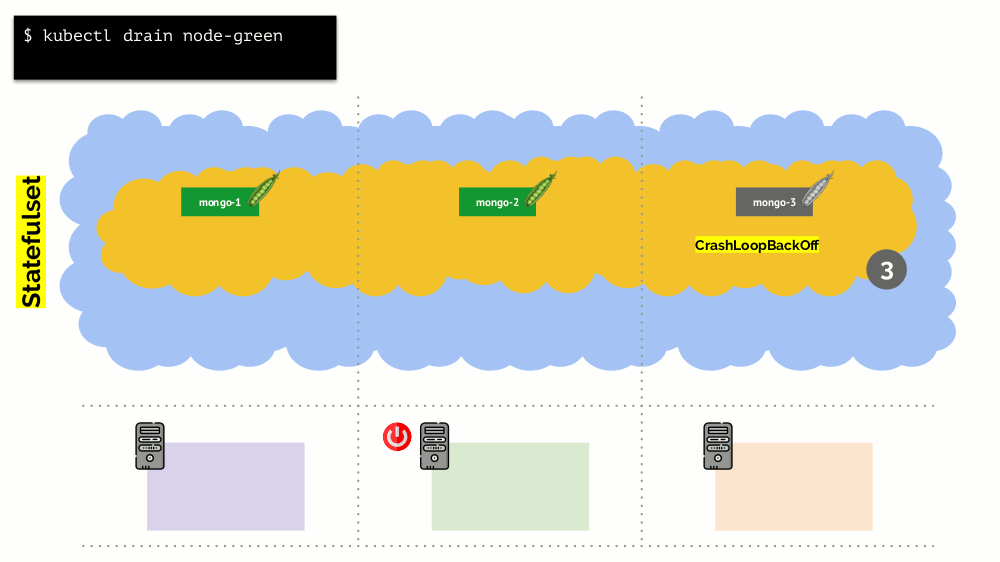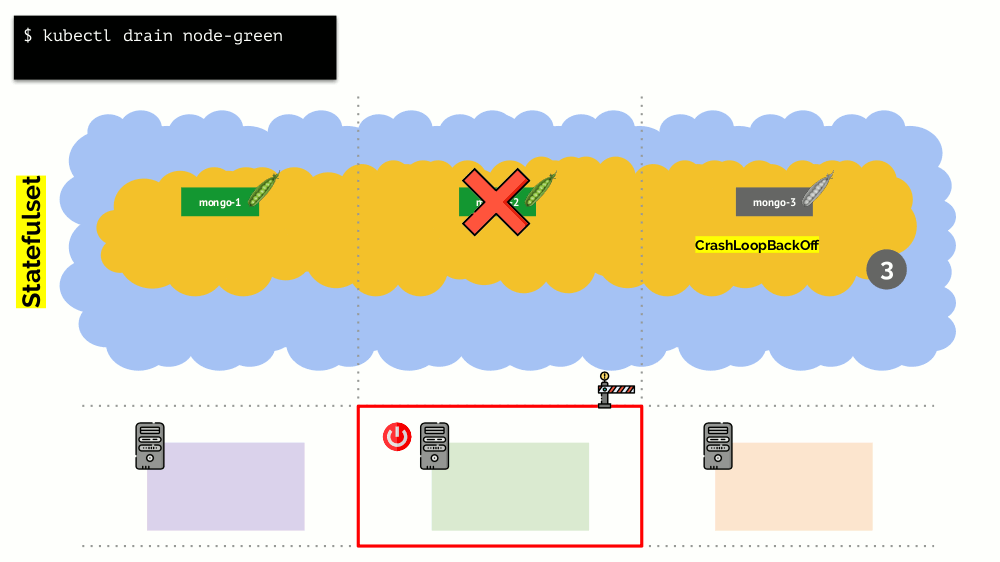 قد
قد يموت MongoDB لأنه يحتاج إلى النصاب القانوني: بالنسبة لمجموعة من ثلاثة منشآت ، يجب أن يعمل اثنان على الأقل. ومع ذلك ، هذا
لا يحدث - بفضل
PodDisruptionB budget . تحدد هذه المعلمة الحد الأدنى المطلوب لعدد القرون العاملة. مع العلم أن أحد الأكواد مع MongoDB لم يعد يعمل ، ورؤية أنه تم توفير minAvailable لـ
minAvailable: 2 في
minAvailable: 2 ، لن تسمح لك Kubernetes بإزالة pod.
خلاصة القول: من أجل نقل قرون (وإعادة إنشائها فعليًا) بشكل صحيح عند إصدار الكتلة ، تحتاج إلى تكوين PodDisruptionB budget.
التحجيم الأفقي
النظر في موقف مختلف. يوجد تطبيق يعمل باسم النشر في Kubernetes. تأتي حركة مرور المستخدمين إلى برامجها (على سبيل المثال ، هناك ثلاثة منها) ، ونقيس مؤشرًا معينًا فيها (مثل ، تحميل وحدة المعالجة المركزية). عندما يزداد الحمل ، نقوم بإصلاحه وفقًا للجدول الزمني ونزيد عدد القرون لتوزيع الطلبات.
اليوم في Kubernetes لا تحتاج إلى القيام بذلك يدويًا: يمكنك تلقائيًا زيادة / تقليل عدد القرون وفقًا لقيم مؤشرات الحمل المقاسة.
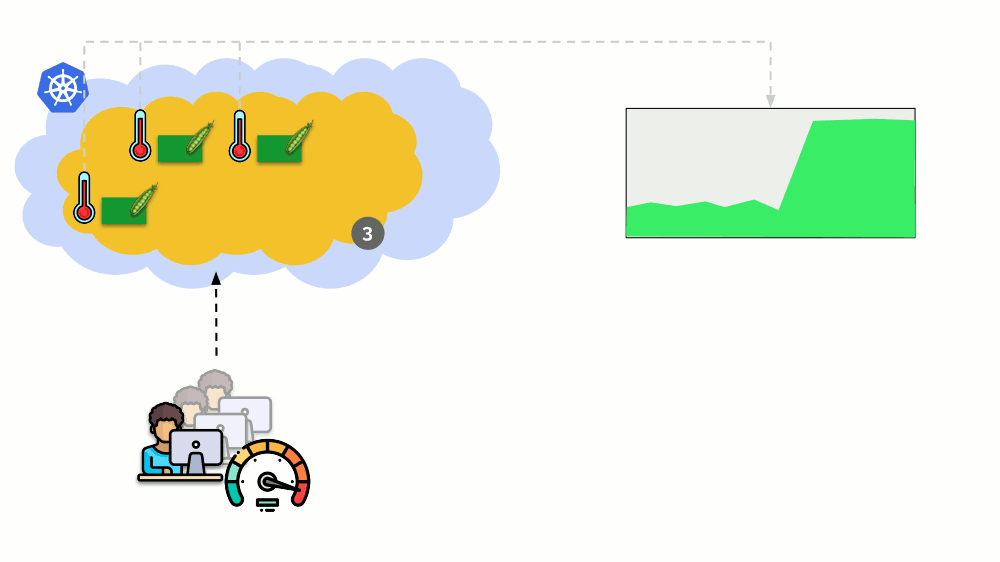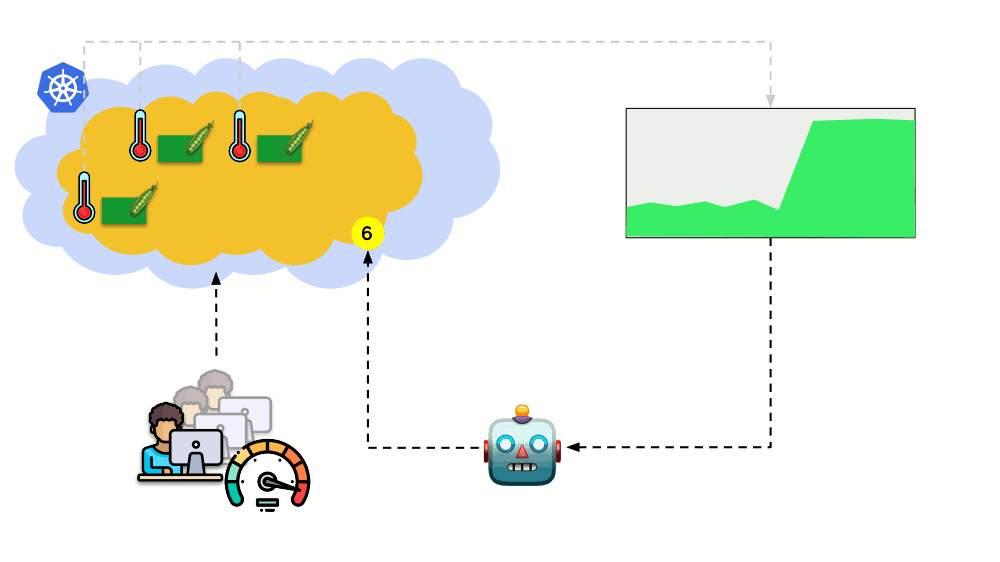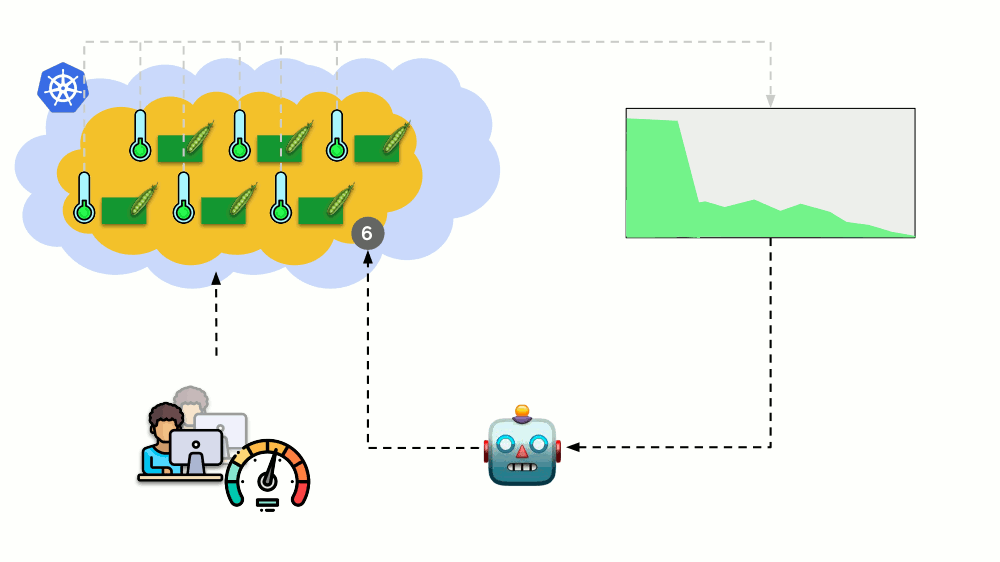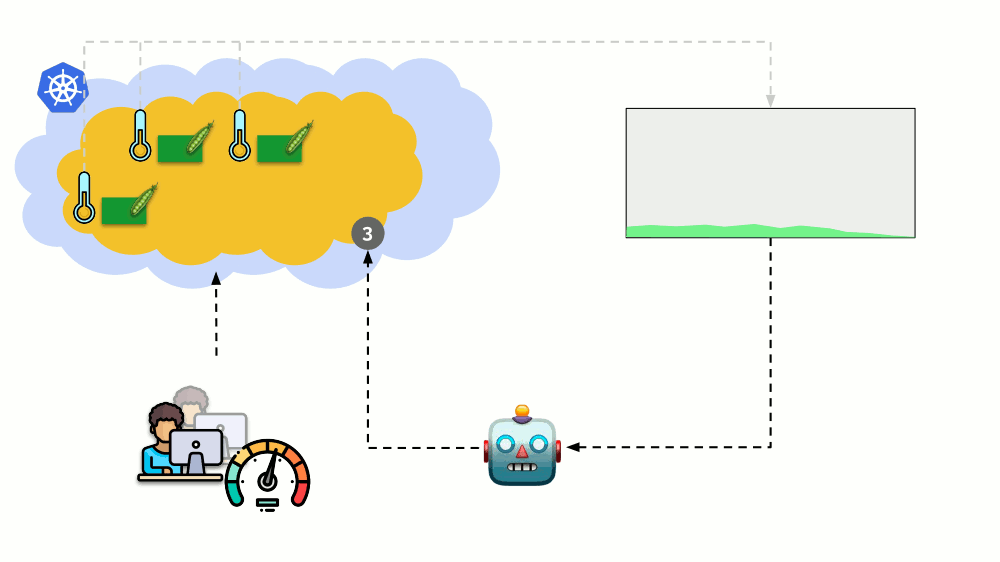
الأسئلة الرئيسية هنا هي
بالضبط ما يجب قياسه وكيفية تفسير القيم التي تم الحصول عليها (لاتخاذ قرار بشأن تغيير عدد القرون). يمكنك قياس الكثير:

كيفية القيام بذلك تقنيًا - جمع المقاييس ، إلخ. - تحدثت بالتفصيل في تقرير
الرصد و Kubernetes . والنصيحة الرئيسية لاختيار المعلمات المثلى هي
تجربة !
هناك
طريقة (استخدام التشبع والأخطاء ) ، والمعنى هو على النحو التالي. على أي أساس يكون من المنطقي التوسع ، على سبيل المثال ، php-fpm؟ استنادا إلى حقيقة أن العمال ينتهي ، هو
الاستفادة . وإذا انتهى العمال ولم يتم قبول اتصالات جديدة - فهذا
تشبع . يجب قياس كل من هذه المعلمات ، واعتمادًا على القيم ، يجب إجراء القياس.
بدلا من الاستنتاج
يحتوي التقرير على استمرارية: حول القياس الرأسي وحول كيفية اختيار الموارد المناسبة. سأتحدث عن ذلك في مقاطع الفيديو المستقبلية على
YouTube - الاشتراك ، حتى لا تفوت!
أشرطة الفيديو والشرائح
فيديو من الأداء (44 دقيقة):
عرض التقرير:
PS
تقارير Kubernetes الأخرى على مدونتنا: