
دخول
على مر السنين من تطوير مشاريع ML و DL ، اكتسب الاستوديو الخاص بنا قاعدة رمز كبيرة ، والكثير من الخبرة ، والرؤى والاستنتاجات المثيرة للاهتمام. عند بدء مشروع جديد ، تساعدك هذه المعرفة المفيدة على بدء البحث بثقة أكبر وإعادة استخدام الطرق المفيدة والحصول على النتائج الأولى بشكل أسرع.
من المهم جدًا أن تكون كل هذه المواد ليست فقط في أذهان المطورين ، ولكن أيضًا في شكل قابل للقراءة على القرص. سيسمح ذلك بتدريب أكثر فعالية للموظفين الجدد ، وتحديثهم وتغمرهم في المشروع.
بالطبع ، لم يكن هذا هو الحال دائما. واجهنا الكثير من المشاكل في المراحل المبكرة
- تم تنظيم كل مشروع بشكل مختلف ، خاصةً إذا كان قد بدأه أشخاص مختلفون.
- إنهم لم يتتبعوا ما الذي كان يقوم به الكود ، وكيفية تشغيله ، ومن كان المؤلف.
- لم يستخدموا المحاكاة الافتراضية إلى الدرجة المناسبة ، وغالبًا ما يمنعون زملائهم من تثبيت مكتبات موجودة في إصدار مختلف.
- تم نسيان الاستنتاجات المستخلصة من الرسوم البيانية التي استقرت وماتت في جبل دفاتر المشتري.
- فقدت تقارير عن النتائج والتقدم المحرز في المشروع.
من أجل حل هذه المشكلات مرة واحدة وإلى الأبد ، قررنا أننا نحتاج إلى العمل على تنظيم موحد ومناسب للمشروع ، وعلى الافتراضية ، وتجريد المكونات الفردية وإعادة استخدام التعليمات البرمجية المفيدة. تدريجيا ، نما كل تقدمنا في هذا المجال إلى إطار مستقل - المحيط.
الكرز على الكعكة - سجلات المشروع ، والتي يتم تجميعها وتحويلها إلى موقع جميل ، يتم جمعها تلقائيا باستخدام أمر واحد.
في هذه المقالة ، سوف نخبرك بمثال مصطنع صغير عن الأجزاء التي يتكون منها المحيط وكيفية استخدامها.
لماذا المحيط
في عالم ML ، هناك خيارات أخرى نظرنا فيها. بادئ ذي بدء ، نحتاج إلى الإشارة إلى علم ملفات تعريف الارتباط (المشار إليها فيما يلي باسم CDS) كمصدر إيديولوجي. دعنا نبدأ بالأمر الجيد: لا توفر CDS هيكلًا مناسبًا للمشروع فحسب ، بل أيضًا تخبرنا كيف تدير المشروع بحيث يكون كل شيء على ما يرام - لذلك ، نوصيك بالبحث والنظر إلى الأفكار الرئيسية لهذا النهج في مقالة CDS الأصلية .
بعد تسليحها بواسطة CDS في مسودة العمل ، أدخلنا على الفور العديد من التحسينات عليها: لقد أضفنا مسجلاً مريحًا للملفات ، وفئة منسق مسؤولة عن التنقل في المشروع ومولدًا تلقائيًا لوثائق Sphinx. بالإضافة إلى ذلك ، تم تقديم العديد من الأوامر إلى Makefile ، بحيث كان حتى غير مستهل في تفاصيل مدير المشروع مناسبًا لتنفيذها.
ومع ذلك ، في هذه العملية ، بدأت السلبيات لنهج CDS في الظهور:
- يمكن أن ينمو مجلد البيانات ، ولكن أي من النصوص أو دفاتر الملاحظات التي تنشئ الملف التالي غير واضحة تمامًا. يسهل الخلط بين عدد كبير من الملفات. ليس من الواضح ما إذا كان من الضروري ، في إطار تنفيذ الوظيفة الجديدة ، استخدام بعض الملفات من الملفات الموجودة ، لأن الوصف أو الوثائق المتعلقة بالغرض منها لا يتم تخزينها في أي مكان.
- في البيانات ، لا يوجد ما يكفي من الميزات مجلد فرعي يمكنك من خلاله تخزين العلامات: إحصائيات محسوبة وناقلات وخصائص أخرى يتم من خلالها تجميع البيانات النهائية المختلفة للبيانات. هذا وقد كتب بالفعل بشكل ملحوظ في بلوق وظيفة.
- src هو مجلد مشكلة أخرى. يحتوي على وظائف ذات صلة بالمشروع بأكمله ، على سبيل المثال ، إعداد وتنظيف بيانات وحدة src.data . ولكن هناك أيضًا وحدة src.models ، والتي تحتوي على جميع النماذج من جميع التجارب ، ويمكن أن يكون هناك العشرات منها. نتيجة لذلك ، يتم تحديث src في كثير من الأحيان ، مع التوسع في التغييرات الطفيفة للغاية ، ووفقًا لفلسفة CDS ، بعد كل تحديث ، من الضروري إعادة بناء المشروع ، وهذا هو الوقت ... كذلك ، فهمت جيدًا.
- يتم تقديم المراجع ، ولكن لا يزال هناك سؤال مفتوح: من ومتى وبأي شكل يجب أن يجلب المواد إلى هناك. ويمكنك معرفة الكثير في سياق المشروع: ما هو العمل الذي تم إنجازه ، وما هي نتائجه ، وما هي الخطط المستقبلية.
لحل المشاكل المذكورة أعلاه ، يتم تقديم الجوهر التالي في المحيط: التجربة . التجربة عبارة عن مستودع لجميع البيانات المتعلقة باختبار بعض الفرضيات. قد يشمل ذلك: ما هي البيانات التي تم استخدامها ، وما هي البيانات (التحف) الناتجة ، وإصدار الكود ، ووقت البدء ونهاية التجربة ، والملف القابل للتنفيذ ، والمعلمات ، والمقاييس والسجلات. يمكن تتبع بعض هذه المعلومات باستخدام أدوات مساعدة خاصة ، على سبيل المثال ، MLFlow. ومع ذلك ، فإن هيكل التجارب المقدمة في المحيط أكثر ثراءً ومرونة.
وحدة التجربة الواحدة هي كما يلي:
<project_root> └── experiments ├── exp-001-Tree-models │ ├── config <- yaml- │ ├── models <- │ ├── notebooks <- │ ├── scripts <- , , train.py predict.py │ ├── Makefile <- │ ├── requirements.txt <- │ └── log.md <- │ ├── exp-002-Gradient-boosting ...
إننا نشارك قاعدة الكود: تظل الكود الجيد القابل لإعادة الاستخدام والذي يكون مهمًا طوال المشروع في وحدة src لمستوى المشروع. نادراً ما يتم تحديثه ، لذا في كثير من الأحيان يكون عليك بناء مشروع. ويجب أن تحتوي وحدة البرامج النصية للتجربة الواحدة على رمز مناسب فقط للتجربة الحالية. وبالتالي ، يمكن تغييرها بشكل متكرر: لا يؤثر على عمل الزملاء في تجارب أخرى.
دعونا ننظر في إمكانيات إطارنا باستخدام مثال لمشروع ML / DL الملخص.
سير عمل المشروع
التهيئة
لذا ، قام العميل - شرطة شيكاغو - بتحميل البيانات والمهمة إلينا: لتحليل الجرائم المرتكبة في المدينة خلال 2011-2017 واستخلاص النتائج.
لنبدأ! نذهب إلى المحطة وننفذ الأمر:
ocean project new -n Crimes
قام الإطار بإنشاء مجلد مشروع الجرائم المقابل. نحن ننظر إلى هيكلها:
crimes ├── crimes <- src- , ├── config <- , ├── data <- ├── demos <- ├── docs <- Sphinx- ├── experiments <- ├── notebooks <- EDA ├── Makefile <- ├── log.md <- ├── README.md └── setup.py
يساعد المنسق من الوحدة التي تحمل الاسم نفسه ، والتي تمت كتابتها وجاهزة بالفعل ، على التنقل في جميع هذه المجلدات. لاستخدامه ، يحتاج المشروع إلى تجميع:
make package
هذا خطأ : إذا كنت لا ترغب في تنفيذ الأوامر ، فقم بإضافة علامة -B إليها ، على سبيل المثال ، "make -B package". وهذا ينطبق على جميع الأمثلة الأخرى.
سجلات والتجارب
نبدأ بحقيقة أن بيانات العميل ، في حالتنا ، ملف crime.csv ، يتم وضعها في مجلد البيانات / الخام .
توجد على موقع شيكاغو على شبكة الإنترنت خرائط مع تقسيمات المدينة إلى وظائف ("يدق" - أصغر موقع بحجم سيارة دورية واحدة) ، والقطاعات ("القطاعات" ، تتكون من 3-5 منشورات) ، والأقسام ("المناطق" ، تتكون من 3 قطاعات) ، المناطق الإدارية ("أجنحة") ، وأخيراً ، المناطق العامة ("منطقة المجتمع"). هذه البيانات يمكن استخدامها للتصور. في الوقت نفسه ، ملفات json مع إحداثيات أقسام المضلع من كل نوع ليست بيانات مرسلة من قبل العميل ، لذلك نضعها في بيانات / خارجية .
بعد ذلك ، تحتاج إلى تقديم مفهوم التجربة. كل شيء بسيط: نحن نعتبر مهمة منفصلة بمثابة تجربة منفصلة. هل تحتاج إلى تحليل / ضخ البيانات وإعدادها للاستخدام في المستقبل؟ الأمر يستحق وضع تجربة. إعداد الكثير من التصور والتقارير؟ تجربة منفصلة. اختبار الفرضية من خلال إعداد نموذج؟ حسنا ، أنت تحصل على هذه النقطة.
لإنشاء تجربتنا الأولى من مجلد المشروع ، نقوم بتنفيذ:
ocean exp new -n Parsing -a ivanov
الآن ظهر مجلد جديد يحمل الاسم exp-001-Parsing في مجلد الجرائم / التجارب ، ويرد هيكله أعلاه.
بعد ذلك ، تحتاج إلى إلقاء نظرة على البيانات. للقيام بذلك ، قم بإنشاء كمبيوتر محمول في مجلد أجهزة الكمبيوتر المحمولة المقابلة. في Surf ، نتبع التسمية "رقم الكمبيوتر المحمول - الاسم" ، وسيتم تسمية الكمبيوتر المحمول الذي تم إنشاؤه باسم 001-Parse-data.ipynb . في الداخل سوف نقوم بإعداد البيانات لمزيد من العمل.
كود إعداد البيانات import numpy as np import pandas as pd pd.options.display.max_columns = 100
لكي يكون زملاؤك على دراية بما قمت به وما إذا كان يمكن استخدام النتائج الخاصة بك من قبلهم ، تحتاج إلى التعليق على هذا في السجل: ملف السجل. هيكل السجل (والذي هو في الأساس ملف تخفيض سعر مألوف) كما يلي:

الأجزاء المملوءة باليد مظللة بالألوان. التعريف الرئيسي للتجربة (لون البرقوق الفاتح) هو مؤلف وشرح مهمته ، والنتيجة التي تسير عليها التجربة. تساعد الارتباطات إلى البيانات ، التي تم التقاطها وتوليدها في العملية (اللون الأخضر) ، في مراقبة ملفات البيانات وفهم من ، ومن داخلها ولماذا تستخدمها. السجل نفسه (اللون الأصفر) يروي نتيجة العمل والاستنتاجات والمنطق. كل هذه البيانات ستصبح فيما بعد محتوى موقع سجل المشروع.
التالي هو مرحلة EDA ( تحليل البيانات الاستكشافية - "تحليل بيانات الاستخبارات" ). ربما سيتم إجراؤه بواسطة أشخاص مختلفين ، وسنحتاج بالطبع إلى نتائج في شكل تقارير ورسوم بيانية لاحقًا. هذه الحجج مناسبة لإنشاء تجربة جديدة. نقوم بها:
ocean exp new -n Eda -a ivanov
في مجلد دفاتر الملاحظات في التجربة ، أنشئ دفتر ملاحظات 001-EDA.ipynb . الكود الكامل غير منطقي ، ولكن ليس هناك حاجة إليه ، على سبيل المثال ، من قِبل زملائك. لكنك بحاجة إلى الرسوم البيانية والاستنتاجات. يظهر الكثير من التعليمات البرمجية في دفتر الملاحظات ، وهو في حد ذاته ليس ما يريد المرء إظهاره للعميل. لذلك ، سنقوم بتسجيل النتائج والرؤى الخاصة بنا في ملف log.md ، وحفظ صور الرسوم البيانية في المراجع .
هنا ، على سبيل المثال ، خريطة للمناطق الآمنة في شيكاغو ، إذا كان المصير ينقلك إلى هناك:
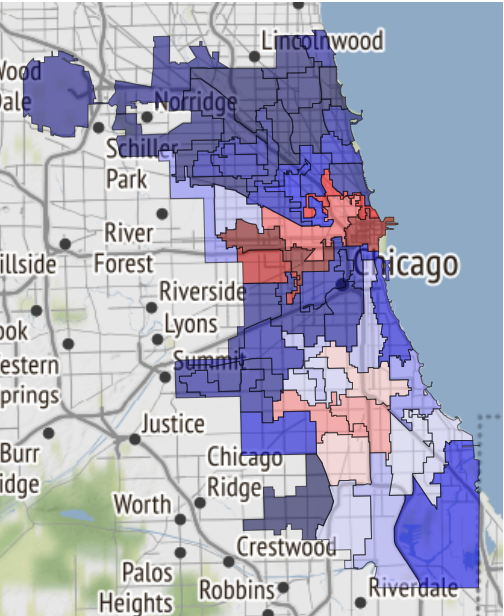
تم استلامه للتو في دفتر ملاحظات ونقله إلى المراجع .
تمت إضافة الإدخال التالي إلى السجل:
19.02.2019, 18:15 EDA conclusion: * The most common and widely spread crimes are theft (including burglary), battery and criminal damage done with firearms. * In 1 case out of 4 the suspect will be set free after detention. [!Criminal activity in different beats of the city](references/beats_activity.jpg) Actual exploration you can check in [the notebook](notebooks/001-Eda.ipynb)
يرجى ملاحظة: تم تصميم المخطط تماما مثل إدراج صورة في ملف md. وإذا تركت رابطًا إلى دفتر الملاحظات ، فسيتم تحويله إلى تنسيق html وحفظه كصفحة منفصلة على الموقع.
لجمعها من سجلات التجارب ، ننفذ الأمر التالي على مستوى المشروع:
ocean log new
بعد ذلك ، يتم إنشاء جريمة / project_log المجلد ، و index.html فيه هو سجل المشروع.
هذا خطأ : عندما يتم عرضه في Jupyter ، يتم تطبيق الموقع كإطار iframe لمزيد من الأمان ، وبالتالي لا يتم عرض الخطوط بشكل صحيح. لذلك ، باستخدام Ocean ، يمكنك على الفور إنشاء أرشيف مع نسخة من الموقع بحيث يكون من المناسب تنزيله وفتحه على جهاز كمبيوتر محلي أو إرساله عبر البريد. مثل هذا:
ocean log archive [-n NAME] [-p PASSWORD]
الوثائق
دعونا نلقي نظرة على بناء الوثائق باستخدام Sphinx. إنشاء وظيفة في ملف الجرائم / my_cool_module.py وتوثيقها. لاحظ أن Sphinx يستخدم تنسيق النص المُعاد هيكلته (RST):
my_cool_module.py def my_super_cool_random(max_value): ''' Returns a random number from [0; max_value) interval. Considers the number to be taken from uniform distribution. :param max_value: Maximum value that defines range. :returns: Random number. ''' return 4
ثم كل شيء بسيط للغاية: على مستوى المشروع ، نقوم بتنفيذ فريق توليد الوثائق ، وتكون جاهزًا:
ocean docs new
سؤال من الجمهور : لماذا ، إذا قمنا بجمع المشروع من خلال make ، فهل يتعين عليك جمع الوثائق من خلال ocean ؟
الإجابة : إن عملية إنشاء الوثائق ليست فقط تنفيذ أمر Sphinx ، والذي يمكن وضعه في وضع. يتولى Ocean مسح فهرس الرموز المصدر ، ويقوم بإنشاء فهرس لـ Sphinx منها ، وعندها فقط يبدأ Sphinx نفسه في العمل.
تنتظرك وثائق HTML الجاهزة الصنع على طول مسار الجرائم / docs / _build / html / index.html . ووحدة لدينا مع التعليقات قد ظهرت بالفعل هناك:

نموذج
والخطوة التالية هي بناء النموذج. نقوم بها:
ocean exp new -n Model -a ivanov
وهذه المرة ، إلقاء نظرة على ما يكمن في مجلد البرامج النصية داخل التجربة. ملف train.py فارغ لعملية التدريب المستقبلية. يحتوي الملف بالفعل على رمز النمذجة التي تقوم بعدة أشياء دفعة واحدة.
- تأخذ وظيفة التعلم العديد من مسارات الملفات:
- إلى ملف التكوين ، حيث يكون من المعقول نقل معلمات النموذج ، ومعلمات التدريب ، والخيارات الأخرى المناسبة للتحكم من الخارج ، دون الخوض في الشفرة.
- إلى ملف البيانات.
- المسار إلى الدليل حيث تريد حفظ تفريغ النموذج النهائي.
- يتتبع المقاييس التي تم الحصول عليها في عملية التعلم في mlflow . يمكن عرض كل ما تمت المطالبة به من خلال تدفق واجهة المستخدم عن طريق تشغيل أمر
make dashboard في مجلد التجربة. - يرسل تنبيهًا إلى Telegram بأن عملية التعلم قد اكتملت. لتنفيذ هذه الآلية ، تم استخدام بوت Alarmerbot . لإنجاز هذا العمل ، عليك القيام ببعض الشيء: إرسال الأمر / start إلى برنامج الروبوت ، ثم نقل الرمز المميز الصادر عن الروبوت إلى ملف crime / config / alarm_config.yml . قد تبدو السلسلة كما يلي:
ivanov: a5081d-1b6de6-5f2762 - يتم التحكم فيه من وحدة التحكم.
لماذا إدارة البرنامج النصي لدينا من وحدة التحكم؟ يتم تنظيم كل شيء بحيث يتم بسهولة تنظيم عملية التعلم أو الحصول على تنبؤات لأي نموذج بواسطة مطور تابع لجهة خارجية لا يعرف تفاصيل تنفيذ تجربتك. لكي تتوافق جميع أجزاء اللغز معًا ، بعد تصميم القطار. تحتاج إلى ترتيب Makefile . إنه يحتوي على أمر train فارغًا ، وعليك فقط تعيين المسارات إلى ملفات التكوين المطلوبة المذكورة أعلاه بشكل صحيح ، وإدراج كل شخص يريد تلقي إعلامات Telegram في قيمة معلمة اسم المستخدم. على وجه الخصوص ، الاسم المستعار all الأعمال ، والتي سوف ترسل تنبيهًا لجميع أعضاء الفريق.
بمجرد أن يصبح كل شيء جاهزًا ، تبدأ تجربتنا مع make train ، ببساطة وأنيق.
في حال كنت ترغب في استخدام الشبكات العصبية لأشخاص آخرين ، فإن البيئات الافتراضية ( venv ) ستساعد. من السهل جدًا إنشاءها وحذفها كجزء من تجربة:
ocean env new سيخلق بيئة جديدة. إنه ليس نشطًا بشكل افتراضي فحسب ، ولكنه أيضًا ينشئ نواة إضافية (kernel) لأجهزة الكمبيوتر المحمولة وللبحث الإضافي. سيتم استدعاؤها بنفس طريقة تسمية التجربة.- يعرض
ocean env list قائمة من النوى. ocean env delete سيؤدي إلى ocean env delete البيئة التي تم إنشاؤها في التجربة.
ما هو مفقود؟
- المحيط ليس صداقات مع كوندا (
لأننا لا نستخدمها ). - قالب المشروع باللغة الإنجليزية فقط.
- لا تزال تنطبق مشكلة الترجمة على الموقع: يفترض إنشاء سجل المشروع أن جميع السجلات باللغة الإنجليزية.
استنتاج
شفرة المصدر للمشروع تكمن هنا .
إذا كنت مهتما - عظيم! يمكنك العثور على مزيد من المعلومات في مستودع README في مستودع المحيط .
وكما يقولون عادة في مثل هذه الحالات ، نرحب بالمساهمات ، وسنكون سعداء فقط إذا شاركت في تحسين المشروع.