تتعلق المشكلات الرئيسية للعمل مع قاعدة البيانات بميزات جهاز نظام التشغيل الذي تعمل عليه قاعدة البيانات. Linux هو الآن نظام التشغيل الرئيسي لقواعد البيانات. لا تزال تستخدم Solaris و Microsoft وحتى HPUX في المؤسسة ، لكنها لن تحتل المرتبة الأولى مطلقًا. يكتسب Linux بثقة لأن هناك المزيد والمزيد من قواعد البيانات مفتوحة المصدر. لذلك ، فإن مسألة تفاعل قاعدة البيانات مع نظام التشغيل تتعلق بوضوح بقواعد بيانات Linux. يتم فرضه على مشكلة DB الأبدية - أداء IO. من الجيد أنه في السنوات الأخيرة ، خضع نظام Linux لإصلاح كبير لمكدس الإدخال / الإخراج (IO) وهناك أمل في التنوير.
يعمل Ilya Kosmodemyansky (
hydrobiont ) لدى Data Egret ، وهي شركة
تتشاور وتدعم PostgreSQL ، وتعرف الكثير عن التفاعل بين نظام التشغيل وقواعد البيانات. في تقرير عن HighLoad ++ ، تحدث Ilya عن تفاعل IO وقواعد البيانات باستخدام مثال PostgreSQL ، ولكنه أظهر أيضًا كيف تعمل قواعد البيانات الأخرى مع IO. نظرت إلى مكدس Linux IO ، وما الأشياء الجديدة والجيدة التي ظهرت فيه ولماذا لم يكن كل شيء كما كان قبل عامين. كتذكير مفيد - قائمة فحص لإعدادات PostgreSQL و Linux للحصول على أقصى أداء للنظام الفرعي IO في النواة الجديدة.
يحتوي تقرير الفيديو على الكثير من اللغة الإنجليزية ، وقد ترجمنا معظمها في المقال.لماذا نتحدث عن IO؟
I / O السريع هو الشيء الأكثر أهمية لمسؤولي قاعدة البيانات . يعلم الجميع ما الذي يمكن تغييره في العمل مع وحدة المعالجة المركزية ، ويمكن توسيع تلك الذاكرة ، لكن I / O يمكن أن تدمر كل شيء. إذا كانت سيئة مع الأقراص ، والكثير I / O ، ثم سوف تشتك قاعدة البيانات. سوف IO تصبح عنق الزجاجة.
لجعل كل شيء يعمل بشكل جيد ، تحتاج إلى تكوين كل شيء.
ليس فقط قاعدة البيانات أو الأجهزة فقط - هذا كل شيء. حتى أوراكل رفيع المستوى ، والذي هو في حد ذاته نظام تشغيل في بعض الأماكن ، يتطلب التكوين. نقرأ التعليمات الموجودة في "دليل التثبيت" من Oracle: قم بتغيير معلمات kernel هذه ، وقم بتغيير الآخرين - هناك العديد من الإعدادات. بالإضافة إلى حقيقة أنه في Unernableable Kernel ، فإن الكثير بالفعل افتراضيًا سلكي إلى Oracle Linux.
بالنسبة لـ PostgreSQL و MySQL ، يلزم إجراء المزيد من التغييرات. وذلك لأن هذه التقنيات تعتمد على آليات التشغيل. يجب أن يكون DBA الذي يعمل مع PostgreSQL ، أو MySQL ، أو NoSQL الحديث مهندس تشغيل Linux وأن يعمل على تحسين أنظمة التشغيل المختلفة.
كل من يريد التعامل مع إعدادات kernel ، يتحول إلى
LWN . المورد عبقري ، أضيق الحدود ، يحتوي على الكثير من المعلومات المفيدة ، ولكن تمت
كتابته بواسطة مطوري kernel لمطوري kernel . ماذا يكتب مطورو النواة بشكل جيد؟ جوهر ، وليس المادة ، وكيفية استخدامها. لذلك ، سأحاول شرح كل شيء لك للمطورين ، والسماح لهم بكتابة النواة.
كل شيء معقد عدة مرات بسبب حقيقة أن تطوير نواة Linux ومعالجة مكدسها في البداية كانا متخلفين ، وفي السنوات الأخيرة ذهبوا بسرعة كبيرة. لا الحديد ولا المطورين مع مقالات وراءه مواكبة.
قاعدة البيانات النموذجية
لنبدأ بأمثلة لـ PostgreSQL - هنا يتم تخزينه مؤقتًا I / O. يحتوي على ذاكرة مشتركة ، يتم تخصيصها في
مساحة المستخدم من وجهة نظر نظام التشغيل ، ولديه نفس ذاكرة التخزين المؤقت في ذاكرة التخزين المؤقت kernel في
مساحة Kernel .
 المهمة الرئيسية لقاعدة بيانات حديثة
المهمة الرئيسية لقاعدة بيانات حديثة :
- التقاط صفحات من القرص في الذاكرة ؛
- عند حدوث تغيير ، قم بتمييز الصفحات على أنها متسخة ؛
- الكتابة إلى سجل الكتابة إلى الأمام ؛
- ثم قم بمزامنة الذاكرة بحيث تتوافق مع القرص.
في موقف PostgreSQL ، تعد هذه رحلة ذهابًا وإيابًا ثابتة: من الذاكرة المشتركة التي يتحكم فيها PostgreSQL في نواة ذاكرة التخزين المؤقت للصفحة ، ثم إلى القرص من خلال حزمة Linux بأكملها. إذا كنت تستخدم قاعدة بيانات على نظام ملفات ، فستعمل على هذه الخوارزمية مع أي نظام يشبه UNIX وأي قاعدة بيانات. الاختلافات هي ، ولكن ضئيلة.
سيكون استخدام Oracle ASM مختلفًا - يتفاعل Oracle نفسه مع القرص. لكن المبدأ هو نفسه: مع Direct IO أو مع Page Cache ، ولكن المهمة هي
رسم الصفحات عبر مكدس I / O بأكمله بأسرع وقت ممكن ، مهما كان. ويمكن أن تنشأ مشاكل في كل مرحلة.
مشكلتين من IO
في حين أن كل شيء
للقراءة فقط ، لا توجد مشاكل. يقرؤون ، وإذا كانت هناك ذاكرة كافية ، يتم وضع جميع البيانات التي يجب قراءتها في ذاكرة الوصول العشوائي. حقيقة أنه في حالة PostgreSQL في
Buffer Cache هي نفسها ، لسنا قلقين للغاية.
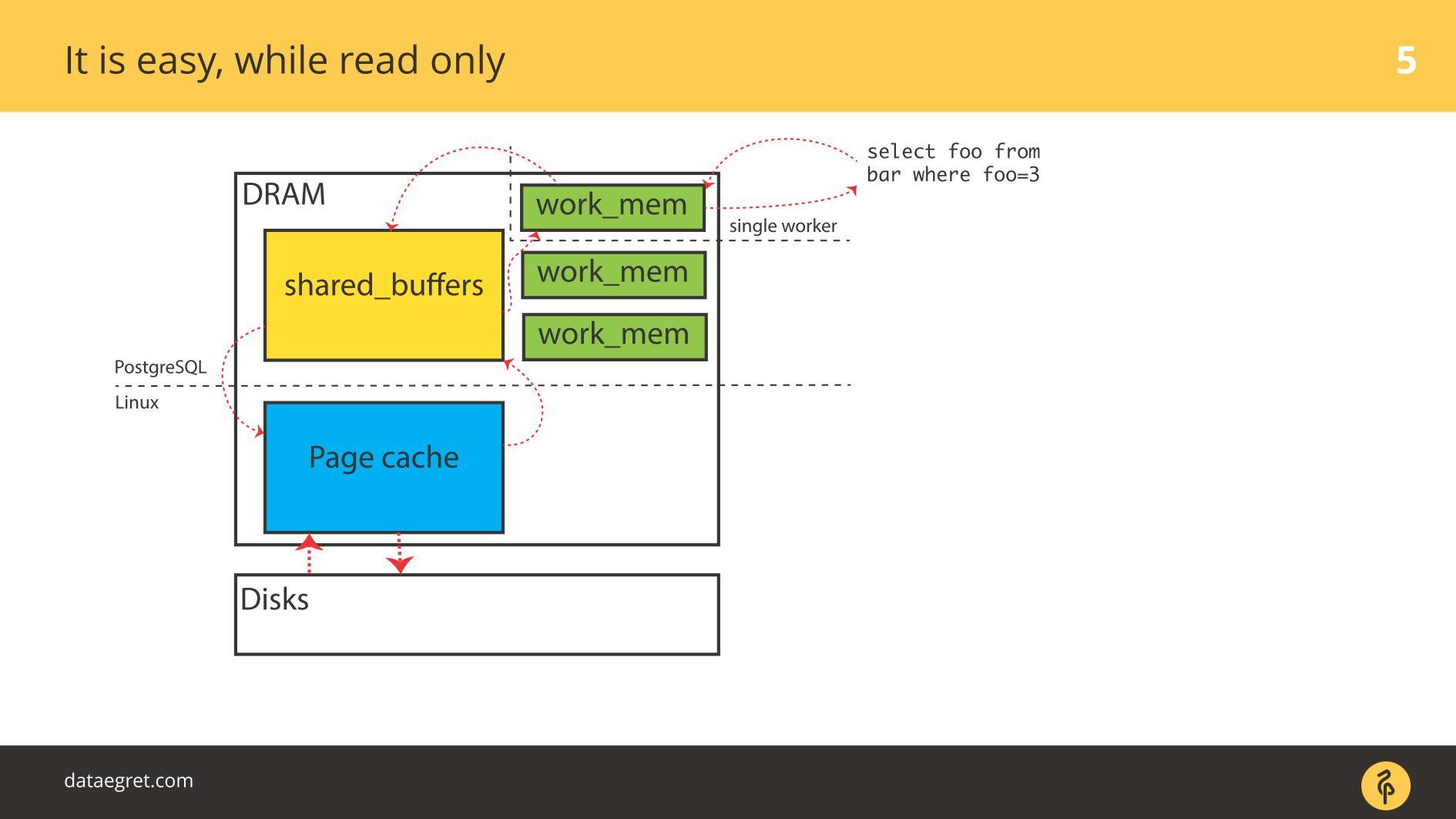 المشكلة الأولى في IO هي تزامن ذاكرة التخزين المؤقت.
المشكلة الأولى في IO هي تزامن ذاكرة التخزين المؤقت. يحدث عند التسجيل مطلوب. في هذه الحالة ، سوف تضطر إلى دفع المزيد والمزيد من الذاكرة.
وفقًا لذلك ، تحتاج إلى تكوين PostgreSQL أو MySQL بحيث يحصل كل شيء على القرص من الذاكرة المشتركة. في حالة PostgreSQL - لا تزال بحاجة إلى ضبط الغش في الخلفية للصفحات القذرة في Linux لإرسال كل شيء إلى القرص.
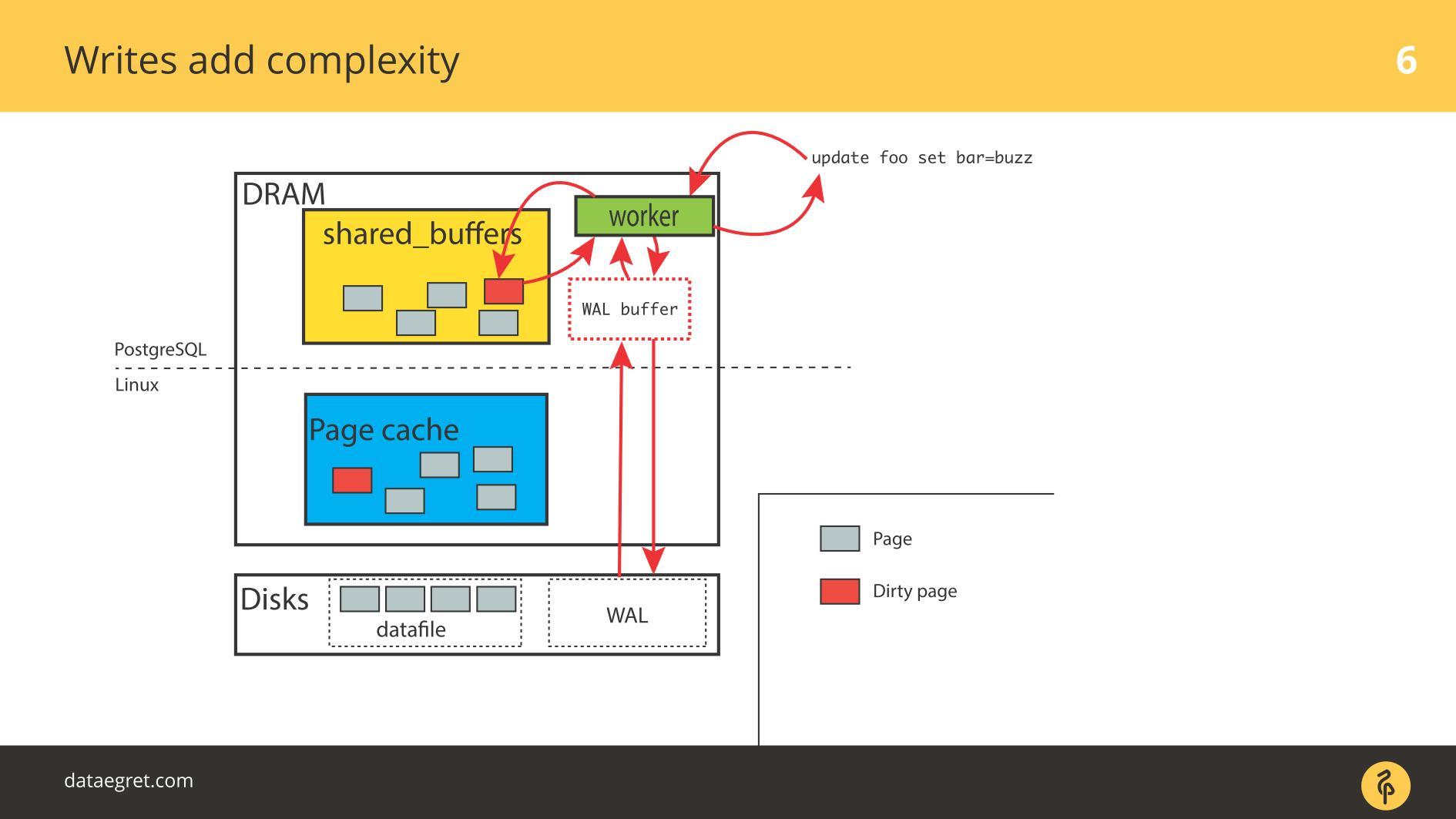
المشكلة الشائعة الثانية هي فشل الكتابة إلى الأمام سجل . يظهر عندما يكون التحميل قويًا للغاية حتى أن السجل المسجل بالتتابع يقع على القرص. في هذه الحالة ، يجب أيضًا تسجيلها بسرعة.
الموقف لا يختلف كثيرا عن
تزامن ذاكرة التخزين المؤقت . في PostgreSQL ، نعمل مع عدد كبير من المخازن المؤقتة المشتركة ، وقاعدة البيانات لديها آليات للتسجيل الفعال لتسجيل الدخول إلى السجل ، وتم تحسينها إلى الحد الأقصى. الشيء الوحيد الذي يمكن القيام به لجعل السجل نفسه أكثر فاعلية هو تغيير إعدادات Linux.
المشاكل الرئيسية للعمل مع قاعدة البيانات
يمكن أن تكون شريحة الذاكرة المشتركة كبيرة جدًا . بدأت أتحدث عن هذا في المؤتمرات في عام 2012. ثم قلت أن الذاكرة انخفضت في السعر ، حتى أن هناك خوادم بسعة 32 جيجابايت من ذاكرة الوصول العشوائي. في عام 2019 ، قد يكون هناك بالفعل المزيد في أجهزة الكمبيوتر المحمولة ، وفي كثير من الأحيان على الخوادم 128 ، 256 ، إلخ.
حقا الكثير من الذاكرة . يستغرق تسجيل المألوف وقتًا والموارد ،
والتقنيات التي نستخدمها في هذا الأمر متحفظة . قواعد البيانات قديمة ، وقد تم تطويرها لفترة طويلة ، فهي تتطور ببطء. الآليات الموجودة في قواعد البيانات ليست صحيحة تمامًا مع أحدث التقنيات.
تزامن الصفحات في الذاكرة مع القرص يؤدي إلى عمليات إدخال / إخراج ضخمة . عندما نقوم بمزامنة ذاكرات التخزين المؤقت ، ينشأ دفق كبير من IO ، وتنشأ مشكلة أخرى -
لا يمكننا تحريف شيء وإلقاء نظرة على التأثير. في تجربة علمية ، قام الباحثون بتغيير معلمة واحدة - الحصول على التأثير ، والثاني - الحصول على التأثير ، والمعلم الثالث. لن ننجح. نقوم بتحريف بعض المعلمات في PostgreSQL ، ونقوم بتكوين نقاط التفتيش - لم نر التأثير. ثم قم مرة أخرى بتكوين المكدس بالكامل للحصول على بعض النتائج على الأقل. تطور معلمة واحدة لا يعمل - نحن مضطرون لتكوين كل شيء في وقت واحد.
تقوم معظم أدوات إدخال PostgreSQL بإنشاء مزامنة الصفحة: نقاط التفتيش وآليات التزامن الأخرى. إذا كنت تعمل مع PostgreSQL ، فربما تكون قد شهدت زيادة سريعة في نقاط التفتيش عند ظهور "المنشار" بشكل دوري على المخططات. في السابق ، واجه الكثيرون هذه المشكلة ، ولكن هناك الآن أدلة حول كيفية حلها ، فقد أصبح الأمر أسهل.
سواقات الأقراص الصلبة اليوم إنقاذ الوضع إلى حد كبير. في PostgreSQL ، نادراً ما يقع شيء ما مباشرة على سجل القيمة. كل شيء يعتمد على المزامنة: عند حدوث نقطة تفتيش ، يتم استدعاء fsync وهناك نوع من "ضرب" نقطة تفتيش واحدة على أخرى. الكثير من IO. نقطة تفتيش واحدة لم تنته بعد ، ولم تكمل جميع عملياتها المزيفة ، ولكنها اكتسبت بالفعل نقطة تفتيش أخرى ، وبدأت!
PostgreSQL لديه ميزة فريدة من نوعها -
autov Vacuum . هذا هو تاريخ طويل من العكازات لهندسة قواعد البيانات. في حالة فشل التعبئة التلقائية ، فإنها عادة ما تقوم بإعدادها بحيث تعمل بقوة ولا تتداخل مع الباقي: هناك الكثير من عمال التعبئة التلقائية ، يتدفقون بشكل متكرر قليلاً ، طاولات المعالجة بسرعة. خلاف ذلك ، سيكون هناك مشاكل مع DDL ومع الأقفال.
ولكن عندما يكون Autov Vacuum عدوانيًا ، فإنه يبدأ في مضغ IO.
إذا تم تثبيت الفراغ التلقائي على نقاط التفتيش ، فغالبًا ما يتم إعادة تدوير الأقراص بنسبة 100٪ تقريبًا ، وهذا هو مصدر المشاكل.
الغريب ، هناك مشكلة
إعادة ملء ذاكرة التخزين المؤقت . انها عادة ما تكون أقل شهرة ديسيبل. مثال نموذجي: بدأت قاعدة البيانات ، وتباطأ كل شيء للأسف لبعض الوقت. لذلك ، حتى إذا كان لديك الكثير من ذاكرة الوصول العشوائي (RAM) ، قم بشراء الأقراص الجيدة حتى يسخن المكدس ذاكرة التخزين المؤقت.
كل هذا يؤثر بشكل خطير على الأداء. تبدأ المشاكل ليس مباشرة بعد إعادة تشغيل قاعدة البيانات ، ولكن في وقت لاحق. على سبيل المثال ، مرت نقطة تفتيش ، والعديد من الصفحات متسخة في قاعدة البيانات. يتم نسخها إلى القرص لأنك بحاجة إلى مزامنتها. ثم تطلب الطلبات إصدارًا جديدًا من صفحات القرص ومن علامات قاعدة البيانات. ستوضح الرسوم البيانية كيفية إعادة ملء ذاكرة التخزين المؤقت بعد كل نقطة تفتيش تساهم بنسبة مئوية معينة في التحميل.
أكثر الأشياء غير السارة في الإدخال / الإخراج من قاعدة البيانات هي
Worker IO. عندما يبدأ كل عامل تطلبه ، في إنشاء IO الخاص به. في Oracle ، الأمر أسهل ، ولكن في PostgreSQL ، إنها مشكلة.
هناك العديد من أسباب مشاكل
Worker IO : لا توجد ذاكرة تخزين مؤقت كافية "لنشر" صفحات جديدة من القرص. على سبيل المثال ، يحدث أن يتم مشاركة جميع المخازن المؤقتة ، فهي كلها قذرة ، لم يتم بعد نقاط التفتيش. لكي يقوم العامل بأداء التحديد الأبسط ، تحتاج إلى أخذ ذاكرة التخزين المؤقت من مكان ما. للقيام بذلك ، تحتاج أولاً إلى حفظ كل شيء على القرص. ليس لديك عملية فحص متخصصة ، ويبدأ العامل برنامج fsync لتحريره وتعبئته بشيء جديد.
هذا يثير مشكلة أكبر: العامل هو شيء غير متخصص ، والعملية كلها ليست الأمثل على الإطلاق. من الممكن تحسين مكان ما على مستوى Linux ، لكن في PostgreSQL يعد هذا إجراءً طارئًا.
مشكلة IO الرئيسية ل DB
ما المشكلة التي نحلها عندما ننشئ شيئًا ما؟ نريد تعظيم انتقال الصفحات القذرة بين القرص والذاكرة.
لكن غالبًا ما يحدث أن هذه الأشياء لا تلمس القرص مباشرة. حالة نموذجية - ترى متوسط حمل كبير جدًا. لماذا هذا لأن هناك من ينتظر القرص ، وجميع العمليات الأخرى تنتظر أيضًا. يبدو أنه لا يوجد استخدام واضح للقرص للأقراص ، ولكن هناك شيء ما يحظر القرص هناك ، والمشكلة هي في الإدخال / الإخراج على أي حال.
مشاكل I / O قاعدة البيانات دوماً لا يهم الأقراص فقط.
كل شيء متورط في هذه المشكلة: الأقراص والذاكرة ووحدة المعالجة المركزية (CPU) وجداول IO وأنظمة الملفات وإعدادات قاعدة البيانات. الآن ، دعنا ننتقل من المكدس ونرى ماذا نفعل به وما الأشياء الجيدة التي تم اختراعها في نظام Linux بحيث يعمل كل شيء بشكل أفضل.
أقراص
لسنوات عديدة ، كانت الأقراص بطيئة بشكل رهيب ولم يشارك أحد في زمن الانتقال أو تحسين المراحل الانتقالية. تحسين fsyncs لم يكن له معنى. كان القرص يدور ، وكانت الرؤوس تتحرك على طولها مثل سجل الفونوغراف ، وكان طول هذه الفترة أطول من أن المشاكل لم تظهر.
الذاكرة
من غير المجدي النظر إلى أهم الاستعلامات دون ضبط قاعدة البيانات. ستقوم بتكوين كمية كافية من الذاكرة المشتركة ، وما إلى ذلك ، وسيكون لديك استعلام أعلى جديد - سيكون عليك تكوينه مرة أخرى. هذه هي نفس القصة. تم إنشاء مكدس Linux بالكامل من هذا الحساب.
عرض النطاق الترددي والكمون
إن تعظيم أداء IO عن طريق زيادة الإنتاجية أمر سهل إلى حد ما. اخترعت عملية PageWriter المساعدة في PostgreSQL التي تم تفريغها من نقطة التفتيش. أصبح العمل موازيا ، ولكن لا يزال هناك أساس لإضافة التوازي. ولتقليل زمن الانتقال ، تكون مهمة الميل الأخير ، والتي تحتاج إلى تقنيات فائقة.
هذه التقنيات الفائقة عبارة عن محركات أقراص صلبة. عندما ظهرت ، انخفض الكمون بحدة. ولكن في جميع المراحل الأخرى للمكدس ، ظهرت مشاكل: من جانب الشركات المصنعة لقاعدة البيانات ومن شركات تصنيع Linux. مشاكل تحتاج إلى معالجة.
تركز تطوير قاعدة البيانات حول زيادة الإنتاجية إلى الحد الأقصى ، كما فعلت تطوير نواة Linux. العديد من الطرق لتحسين عصر الإدخال / الإخراج للأقراص الدورانية ليست جيدة جدًا لمحركات الأقراص الثابتة.
فيما بينهما ، اضطررنا لإجراء نسخ احتياطي للبنية الأساسية لنظام Linux الحالي ، ولكن باستخدام أقراص جديدة. شاهدنا اختبارات الأداء من الشركة المصنعة مع عدد كبير من IOPS مختلفة ، وقاعدة البيانات لم تتحسن ، لأن قاعدة البيانات ليست فقط وليس الكثير عن IOPS. يحدث غالبًا أنه يمكننا تخطي 50000 IOPS في الثانية ، وهذا أمر جيد. ولكن إذا كنا لا نعرف الكمون ، لا نعرف توزيعها ، ثم لا يمكننا أن نقول أي شيء عن الأداء. في مرحلة ما ، ستبدأ قاعدة البيانات في نقطة تفتيش ، وسيزداد الكمون بشكل كبير.
لفترة طويلة ، كما هو الحال الآن ، كانت هذه مشكلة كبيرة في الأداء على قواعد البيانات الافتراضية. يتميز IO الظاهري باختفاء غير متكافئ ، وهو ما يستتبع ، بالطبع ، مشاكل.
كومة IO. كما كان من قبل
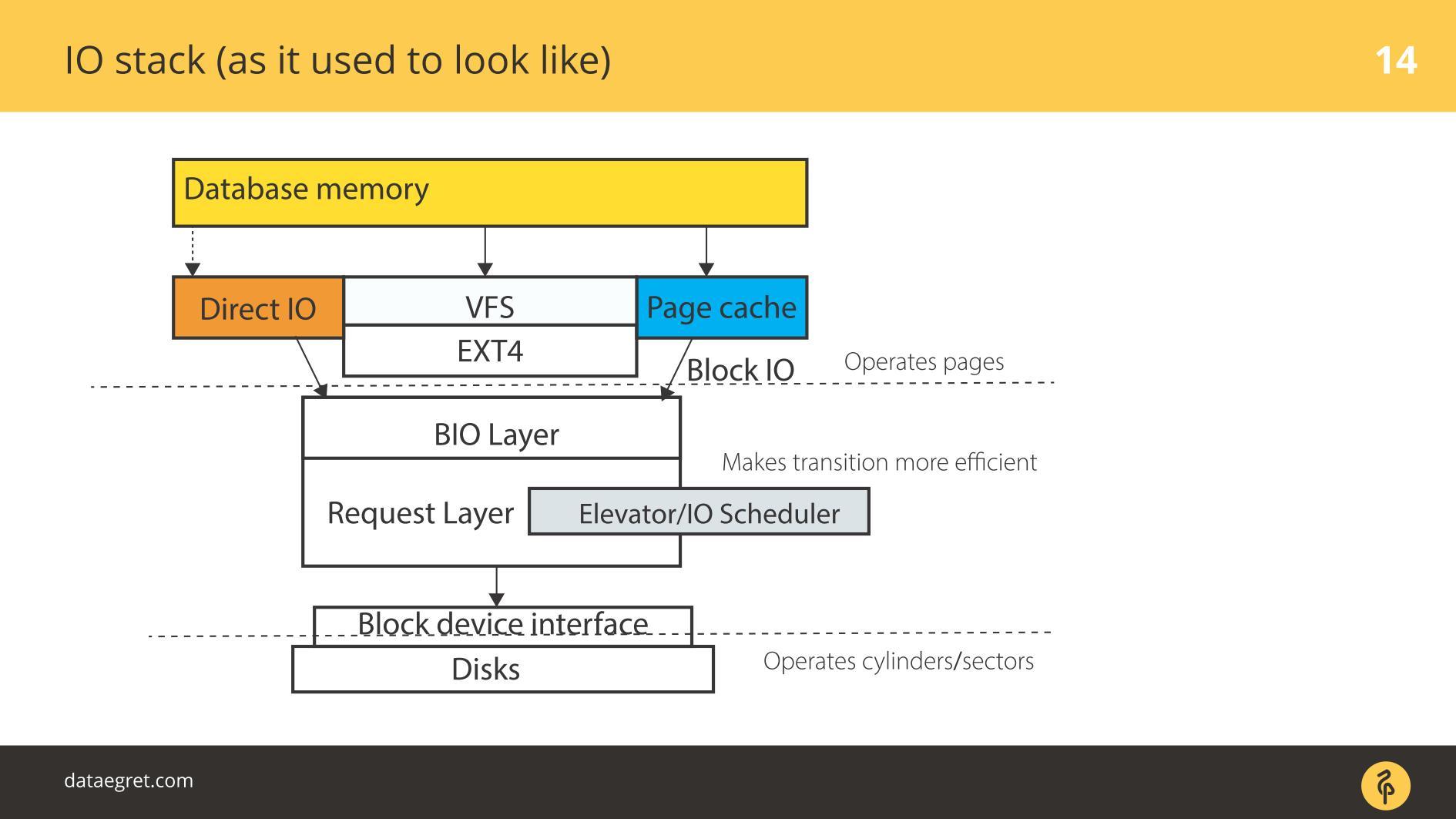
هناك مساحة المستخدم - تلك الذاكرة ، التي تديرها قاعدة البيانات نفسها. في DB تكوين بحيث عملت كل شيء كما يجب. يمكن القيام بذلك في تقرير منفصل ، ولا حتى في تقرير واحد. ثم كل شيء يمر حتماً عبر ذاكرة التخزين المؤقت للصفحة أو من خلال واجهة Direct IO التي تدخل
طبقة حظر الإدخال / الإخراج .
تخيل واجهة نظام الملفات. الصفحات التي كانت في ذاكرة التخزين المؤقت المخزن المؤقت ، كما كانت في الأصل في قاعدة البيانات ، أي كتل ، تأتي من خلالها. تتعامل طبقة IO مع ما يلي. هناك بنية C تصف كتلة في النواة. يأخذ الهيكل هذه الكتل ويجمع منها متجهات (صفائف) طلبات الإدخال أو الإخراج. أسفل طبقة BIO هي طبقة الطالب. يتم جمع المتجهات على هذه الطبقة وسوف تذهب أبعد من ذلك.
لفترة طويلة ، تم شحذ هاتين الطبقتين في Linux للتسجيل الفعال على الأقراص المغناطيسية. كان من المستحيل الاستغناء عن عملية الانتقال. هناك كتل ملائمة لإدارة من قاعدة البيانات. من الضروري تجميع هذه الكتل في متجهات تتم كتابتها بشكل مريح على القرص بحيث تقع في مكان قريب. من أجل أن يعمل هذا بشكل فعال ، توصلوا إلى المصاعد ، أو المجدول IO.
المصاعد
شاركت المصاعد في المقام الأول في الجمع بين المتجهات وفرزها. كل ذلك من أجل برنامج التشغيل SD block - برنامج التشغيل quasidisk - وصول كتل التسجيل بالترتيب المناسب له. ترجم السائق من كتل إلى قطاعاته وكتب إلى القرص.
كانت المشكلة أنه كان من الضروري القيام بعدة انتقالات ، وفي كل منها تنفيذ منطقها الخاص بالعملية المثلى.
المصاعد: حتى 2.6 نواة
قبل kernel 2.6 ، كان هناك Linus Elevator - الأكثر جدولة IO جدولة ، والذي كتبه تخمين من. لفترة طويلة كان يعتبر غير متزعزع وجيد للغاية ، حتى طوروا شيئًا جديدًا.
واجهت Linus Elevator الكثير من المشكلات.
انه الجمع وفرزها وفقا لكيفية تسجيل أكثر كفاءة . في حالة الأقراص الميكانيكية الدوارة ، أدى ذلك إلى ظهور "
المجاعة" : وهو الموقف الذي تعتمد فيه كفاءة التسجيل على دوران القرص. إذا كنت بحاجة فجأة إلى القراءة بفعالية في نفس الوقت ، ولكن تم إيقافها بالفعل بشكل صحيح ، فستتم قراءتها بشكل سيئ من هذا القرص.
تدريجيا ، أصبح من الواضح أن هذه طريقة غير فعالة. لذلك ، بدءًا من kernel 2.6 ، بدأت تظهر مجموعة كاملة من أدوات الجدولة ، والتي كانت مخصصة للمهام المختلفة.
المصاعد: بين 2.6 و 3
يخلط العديد من الأشخاص بين هذه المجدولات وجداول نظام التشغيل لأن لديهم أسماء مشابهة.
CFQ - قائمة الانتظار العادلة تمامًا ليست هي نفسها برامج جدولة نظام التشغيل. فقط أسماء متشابهة. تم صياغتها كجدول زمني عالمي.
ما هو المجدول العالمي؟ هل تعتقد أن لديك متوسط الحمل أو ، على العكس من ذلك ، واحدة فريدة من نوعها؟ قواعد البيانات لديها براعة سيئة للغاية. الحمل العالمي يمكن تصوره كجهاز كمبيوتر محمول عادي. كل شيء يحدث هناك: نستمع إلى الموسيقى واللعب ونوع النص. لهذا ، كانت مكتوبة فقط المجدول العالمي.
المهمة الرئيسية للجدول العالمي: في حالة نظام Linux ، لكل محطة افتراضية وعملية ، قم بإنشاء قائمة انتظار للطلب. عندما نريد الاستماع إلى الموسيقى في مشغل صوت ، يأخذ IO الخاص بالمشغل قائمة انتظار. إذا كنا نريد نسخ احتياطي لشيء باستخدام الأمر cp ، فهناك شيء آخر معني.
في حالة قواعد البيانات ، تحدث مشكلة. كقاعدة عامة ، قاعدة البيانات هي عملية بدأت ، وخلال العملية نشأت عمليات موازية تنتهي دائمًا في نفس قائمة انتظار الإدخال / الإخراج. والسبب هو أن هذا هو نفس التطبيق ، نفس العملية الأصل. بالنسبة للأحمال الصغيرة جدًا ، كان هذا الجدولة مناسبًا ، أما الباقي فلم يكن له معنى. كان من الأسهل إيقافه وعدم استخدامه إذا أمكن ذلك.
تدريجيا ، ظهرت
جدولة الموعد النهائي - أنها تعمل بشكل أكثر دهاء ، ولكن في الأساس هو دمج والفرز للأقراص الغزل. نظرًا لتصميم نظام فرعي معين للقرص ، نقوم بتجميع متجهات الكتلة لكتابتها بالطريقة المثلى. كان لديه مشاكل أقل مع
الجوع ، لكنهم كانوا هناك.
لذلك ، بدا أقرب إلى نواة لينكس الثالثة
noop أو
لا شيء ، والتي عملت بشكل أفضل بكثير مع انتشار SSDs. بما في ذلك جدولة noop ، نحن في الواقع تعطيل الجدولة: لا توجد عمليات فرز ، ودمج ، وأشياء مماثلة فعلت CFQ والموعد النهائي.
يعمل هذا بشكل أفضل مع محركات أقراص الحالة الصلبة ، لأن محركات أقراص الحالة الصلبة متوازية بطبيعتها: تحتوي على خلايا ذاكرة. كلما زاد عدد هذه العناصر في لوحة PCIe ، زادت فاعليتها.
المجدول من بعض العالم الآخر ، من وجهة نظر SSD ، الاعتبارات ، يجمع بعض المتجهات ويرسلها إلى مكان ما. كل هذا ينتهي مع القمع. لذلك نحن نقتل التزامن من محركات الأقراص الصلبة ، لا نستخدمها على أكمل وجه. لذلك ، فإن الإغلاق البسيط ، عندما تتحرك الموجهات عشوائياً دون أي فرز ، يعمل بشكل أفضل من حيث الأداء. ولهذا السبب ، يعتقد أن القراءة العشوائية ، والكتابة العشوائية أفضل على محركات الأقراص الصلبة.
المصاعد: 3.13 وما فوق
بدءًا من kernel 3.13 ،
ظهر blk-mq . قبل ذلك بقليل كان هناك نموذج أولي ، ولكن في الإصدار 3.13 ظهرت نسخة العمل لأول مرة.
بدأت Blk-mq كجدول زمني ، لكن من الصعب أن نسميها مجدولاً - إنها قائمة بذاتها من الناحية المعمارية. هذا بديل لطبقة الطلب في النواة. ببطء ، أدى تطوير blk-mq إلى إصلاح كبير لمكدس الإدخال / الإخراج Linux بأكمله.
الفكرة هي: دعنا نستخدم القدرة الأصلية لمحركات أقراص الحالة الصلبة (SSD) للقيام بتزامن فعال للإدخال / الإخراج. اعتمادًا على عدد تدفقات الإدخال / الإخراج المتوازية التي يمكنك استخدامها ، هناك قوائم انتظار نكتب من خلالها ببساطة كما هي على SSD. CPU .
blk-mq . . , 4 ,
blk-mq — 5-10%, .
blk-mq — , SSD.
blk-mq NVMe driver Linux. Linux, Microsoft.
blk-mq NVMe driver — Linux, .
, . - PCIe SSD. , .
blk-mq NVMe , . .
, , . NVMe , , .
elevators

: CPU, , - .
Elevators -. CPU . - , , , , IO .
elevators
blk-mq — . CPU, NUMA- / . , , , . SD , , .
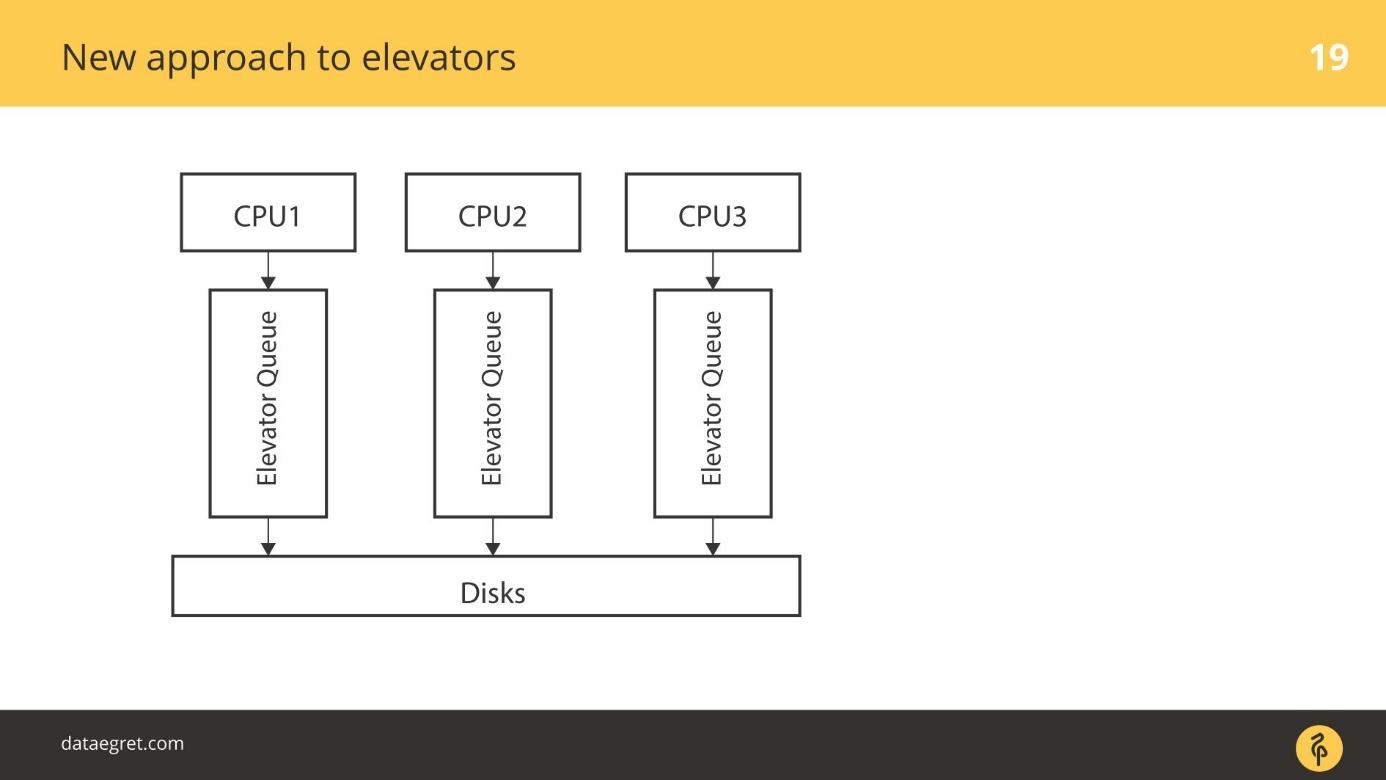
. - RAID- , RAID. SSD — . SD- , blq-mq.
blk-mq
.

. , . / , , Block IO-.
blk-mq , , scheduler.
3.13 , . schedulers
blk-mq , . Linux schedulers IO — Kyber BFQ.
blk-mq .
BFQ — Budget Fair Queueing — FQ . , . BFQ — scheduler . IO. IO, / . , . — . BFQ, , .
Kyber — . BFQ, . Kyber scheduler . — CPU . Kyber .
—
blk-mq SD- . , , , IO-. blk-mq NVMe driver . .
— latency, . SSD, — . -, , NVMe-, blk-mq , . .
Linux IO
/ Linux.
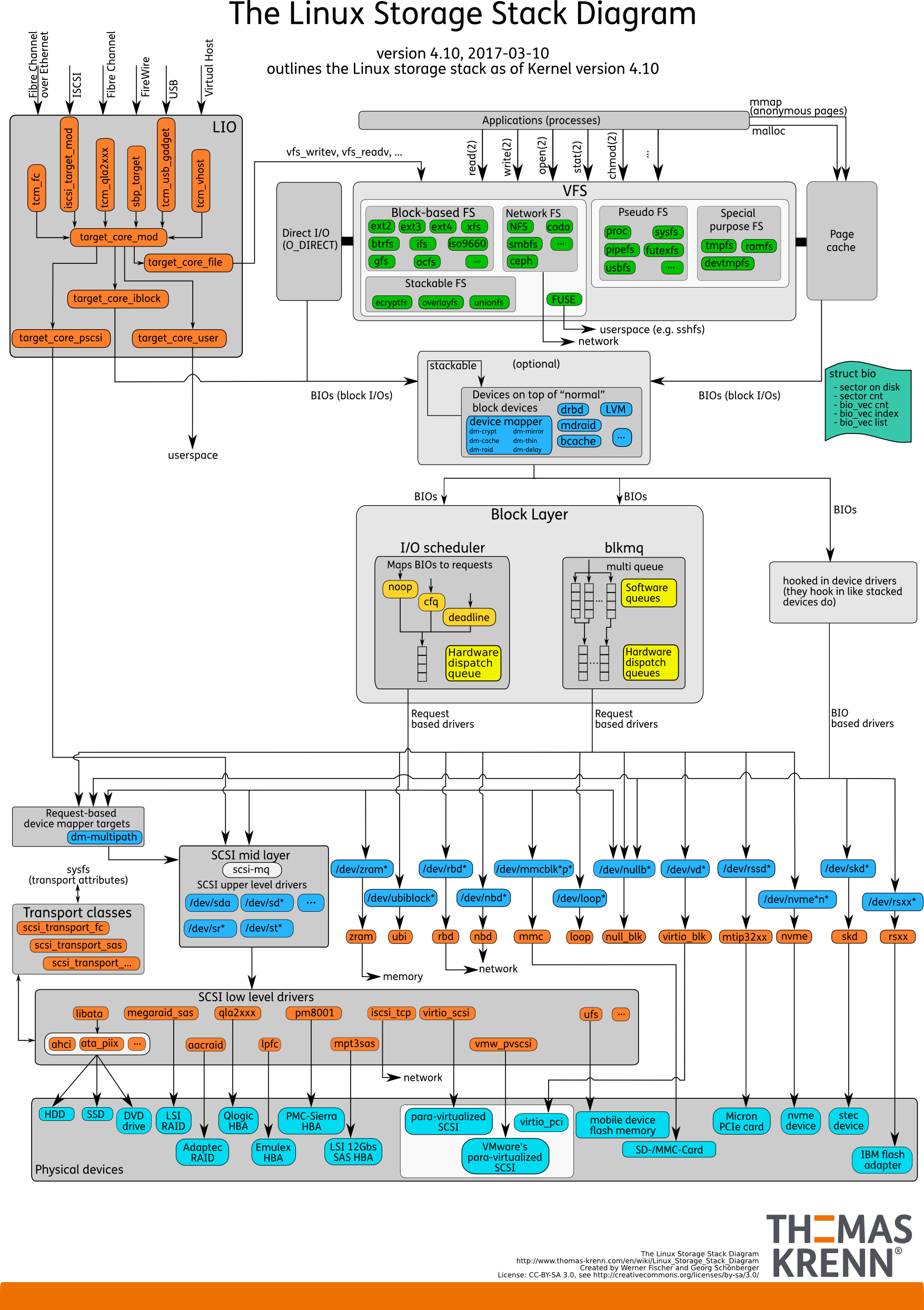
, , , Elevators, .
, , .
NVM Express
إن NVM Express أو NVMe هي مجموعة مواصفات ، وهي مجموعة من المعايير التي تساعدك على الاستفادة بشكل أفضل من محركات أقراص الحالة الصلبة. يتم تنفيذ المواصفات بشكل جيد على نظام Linux. يعتبر Linux أحد القوى المحركة للمعيار.الآن في الإنتاج هو الإصدار الثالث. وفقًا للمواصفات ، يمكن أن يتجاوز برنامج تشغيل هذا الإصدار حوالي 20 جيجابايت / ثانية لكل كتلة SSD واحدة ، والإصدار الخامس من NVMe ، والذي لم يتوفر بعد ، حتى 32 جيجابايت / ثانية . لا يحتوي برنامج تشغيل SD على واجهات أو آليات بداخله لتوفير هذا النطاق الترددي.هذه المواصفات هي أسرع بكثير من أي شيء كان من قبل.
بمجرد كتابة قواعد البيانات للأقراص الدوارة وموجهة إليها - لديهم فهارس على شكل شجرة B ، على سبيل المثال. السؤال الذي يطرح نفسه:
هل قواعد البيانات جاهزة لـ NVMe ؟ هل قواعد البيانات قادرة على مضغ مثل هذا الحمل؟
ليس بعد ، لكنها تتكيف. تحتوي قائمة PostgreSQL البريدية مؤخرًا على بضعة
pwrite() وأشياء مماثلة. يتفاعل مطورو PostgreSQL و MySQL مع مطوري kernel. بالطبع ، أود المزيد من التفاعل.
التطورات الأخيرة
خلال العام الماضي ونصف العام ، أضاف NVMe
استقصاء IO .
في البداية كان هناك أقراص الغزل مع الكمون عالية. ثم جاءت محركات أقراص الحالة الصلبة ، وهي أسرع بكثير. ولكن كان هناك دعامة: fsync يستمر ، يبدأ التسجيل ، وعلى مستوى منخفض جدًا - عميقًا في برنامج التشغيل ، يتم إرسال طلب مباشرة إلى قطعة الأجهزة - قم بتدوينها.
كانت الآلية بسيطة - لقد أرسلوها وننتظر حتى تتم معالجة المقاطعة. لا يمثل انتظار معالجة المقاطعة مشكلة مقارنة بالكتابة على قرص دوار. استغرق الأمر وقتًا طويلاً لانتظار أنه بمجرد انتهاء التسجيل ، نجحت المقاطعة.
نظرًا لأن SSD تكتب بسرعة شديدة ، فقد ظهرت آلية لاستقصاء قطعة الأجهزة المتعلقة بالتسجيل. في الإصدارات الأولى ، وصلت الزيادة في سرعة الإدخال / الإخراج إلى 50 ٪ بسبب حقيقة أننا لا ننتظر حدوث انقطاع ، لكننا نسأل بنشاط قطعة الحديد عن السجل.
وتسمى هذه الآلية الاقتراع IO .
تم تقديمه في الإصدارات الحديثة. في الإصدار 4.12 ، ظهرت
جدولة IO ، شحذ خصيصًا للعمل مع
blk-mq و NVMe ، والتي قلت عنها
Kyber و BFQ . هم بالفعل رسميا في النواة ، ويمكن استخدامها.
الآن في شكل صالح للاستخدام هناك ما يسمى
IO العلامات . معظم الشركات المصنعة للغيوم والأجهزة الافتراضية ستساهم في هذا التطور. تحدث تقريبًا ، يمكن تناول الإدخال من تطبيق معين وإعطائه الأولوية. قواعد البيانات ليست جاهزة لهذا بعد ، ولكن لا تنزعج. أعتقد أنه سيكون السائدة قريبا.
ملاحظات IO المباشرة
لا يدعم PostgreSQL Direct IO ، وهناك عدد من المشكلات التي تجعل من الصعب تمكين الدعم . الآن يتم دعم هذا فقط للقيمة ، وفقط إذا لم يتم تمكين النسخ المتماثل.
يجب كتابة الكثير من التعليمات البرمجية الخاصة بنظام التشغيل ، وفي الوقت الحالي ، يمتنع الجميع عن ذلك.
على الرغم من حقيقة أن نظام Linux يقسم بشدة على فكرة Direct IO وكيفية تنفيذها ، فإن جميع قواعد البيانات تذهب إلى هناك. في Oracle و MySQL ، يستخدم Direct IO بكثرة. PostgreSQL هي قاعدة البيانات الوحيدة التي لا يتحملها Direct IO.
تحقق من القائمة
كيف تحمي نفسك من مفاجآت fsync في PostgreSQL:
- إعداد نقاط التفتيش لتكون أقل تواترا وأكبر.
- إعداد كاتب الخلفية للمساعدة في نقطة تفتيش.
- سحب Autov Vacuum بحيث لا يوجد I / O زائفة لا لزوم لها
وفقًا للتقاليد ، في نوفمبر ننتظر المطورين المحترفين للخدمات المحملة للغاية في Skolkovo على HighLoad ++ . لا يزال هناك شهر لتقديم طلب للحصول على تقرير ، لكننا قبلنا بالفعل التقارير الأولى للبرنامج . الاشتراك في النشرة الإخبارية لدينا ومعرفة موضوعات جديدة مباشرة.