الشبكات العصبية - هذا موضوع يسبب اهتمامًا كبيرًا ورغبة في فهمه. لكن لسوء الحظ ، لا يناسب الجميع. عندما ترى مجلدات من الأدب الغامض ، فإنك تفقد الرغبة في الدراسة ، لكنك لا تزال ترغب في مواكبة ما يحدث.
في النهاية ، بدا لي أنه لا توجد طريقة أفضل لإثبات ذلك من مجرد اتخاذ وإنشاء مشروع صغير خاص بك.
يمكنك قراءة الخلفية الغنائية عن طريق توسيع النص ، أو يمكنك تخطي هذا والانتقال مباشرة إلى
وصف الشبكة العصبية.ما هي الفائدة من القيام مشروعك.الايجابيات:
- أنت تفهم بشكل أفضل كيف يتم ترتيب الخلايا العصبية
- تفهم بشكل أفضل كيفية العمل مع المكتبات الموجودة
- تعلم شيء جديد بالتوازي
- دغدغة الأنا الخاصة بك ، وخلق شيء خاص بك
سلبيات:
- أنت تقوم بإنشاء دراجة ، على الأرجح أسوأ من الدراجات الحالية
- لا أحد يهتم بمشروعك.
اختيار اللغة.في وقت اختيار اللغة ، كنت أعرف إلى حد ما لغة C ++ ، وكنت على دراية بأساسيات بايثون. من الأسهل التعامل مع الخلايا العصبية في بيثون ، لكن C ++ كانت تعرف بشكل أفضل وليس هناك موازنة أبسط للحسابات من OpenMP. لذلك ، اخترت C ++ ، وستقوم واجهة برمجة التطبيقات لـ Python ، حتى لا تهتم ، بإنشاء مجموعة
كبيرة تعمل على Windows و Linux. (
مثال على كيفية إنشاء مكتبة Python من رمز C ++)
OpenMP و GPU تسارع.في الوقت الحالي ، OpenMP الإصدار 2.0. مثبت في Visual Studio ، حيث لا يوجد سوى تسريع وحدة المعالجة المركزية. ومع ذلك ، بدءًا من الإصدار 3.0 ، يدعم OpenMP أيضًا تسريع GPU ، في حين أن صيغة التوجيهات ليست معقدة. يبقى فقط الانتظار حتى يتم دعم OpenMP 3.0 من قبل جميع المترجمين. في غضون ذلك ، للبساطة ، فقط وحدة المعالجة المركزية.
بلدي أشعل النار الأولى.عند حساب قيمة الخلية العصبية ، هناك النقطة التالية: قبل أن نحسب وظيفة التنشيط ، نحتاج إلى إضافة مضاعفة الأوزان إلى بيانات الإدخال. كيف تتعلم القيام بذلك في الجامعة: قبل جمع متجه كبير من الأرقام الصغيرة ، يجب فرزها بترتيب تصاعدي. لذلك هنا. في الشبكات العصبية ، بصرف النظر عن إبطاء البرنامج N times ، فإن هذا لا يعطي أي شيء. لكنني أدركت هذا فقط عندما اختبرت شبكتي بالفعل على MNIST.
وضع مشروع على جيثب.أنا لست أول من نشر إبداعي على جيثب. ولكن في معظم الحالات ، بعد الارتباط ، تشاهد فقط مجموعة من التعليمات البرمجية مع النقش في README.md
"هذه هي شبكتي
العصبية ، انظر ودرس .
" ليكون أفضل من الآخرين ، على الأقل في هذا ، وصف
README.md أكثر أو أقل
واملأ Wiki . الرسالة بسيطة -
املأ الويكي. ملاحظة مهمة: إذا كان العنوان الموجود في ويكي على جيثب مكتوبًا بالروسية ، فلن يعمل
مرساة هذا العنوان.
الترخيص.عندما تنشئ مشروعك الصغير ، يكون الترخيص مرة أخرى وسيلة لدغدغة الأنا. هنا
مقال مثير للاهتمام حول ماهية الترخيص. اخترت
APACHE 2.0 .
وصف الشبكة.
الميزات:
الميزة الرئيسية لمكتبتي هي إنشاء شبكة بها سطر واحد من التعليمات البرمجية.
من السهل أن نرى أن عدد الخلايا العصبية في الطبقة الواحدة يساوي عدد معلمات الإدخال في الطبقة التالية في الطبقات الخطية. بيان آخر واضح - عدد الخلايا العصبية في الطبقة الأخيرة يساوي عدد قيم مخرجات الشبكة.
لنقم بإنشاء شبكة تستقبل ثلاث معلمات عند الإدخال ، والتي تحتوي على ثلاث طبقات تحتوي على 5 و 4 و 2 من الخلايا العصبية.
import foxnn nn = foxnn.neural_network([3, 5, 4, 2])
إذا نظرت إلى الصورة ، يمكنك فقط رؤية: أول 3 معلمات إدخال ، ثم طبقة بها 5 خلايا عصبية ، ثم طبقة بها 4 خلايا عصبية ، وأخيراً ، الطبقة الأخيرة مع 2 عصبونات.
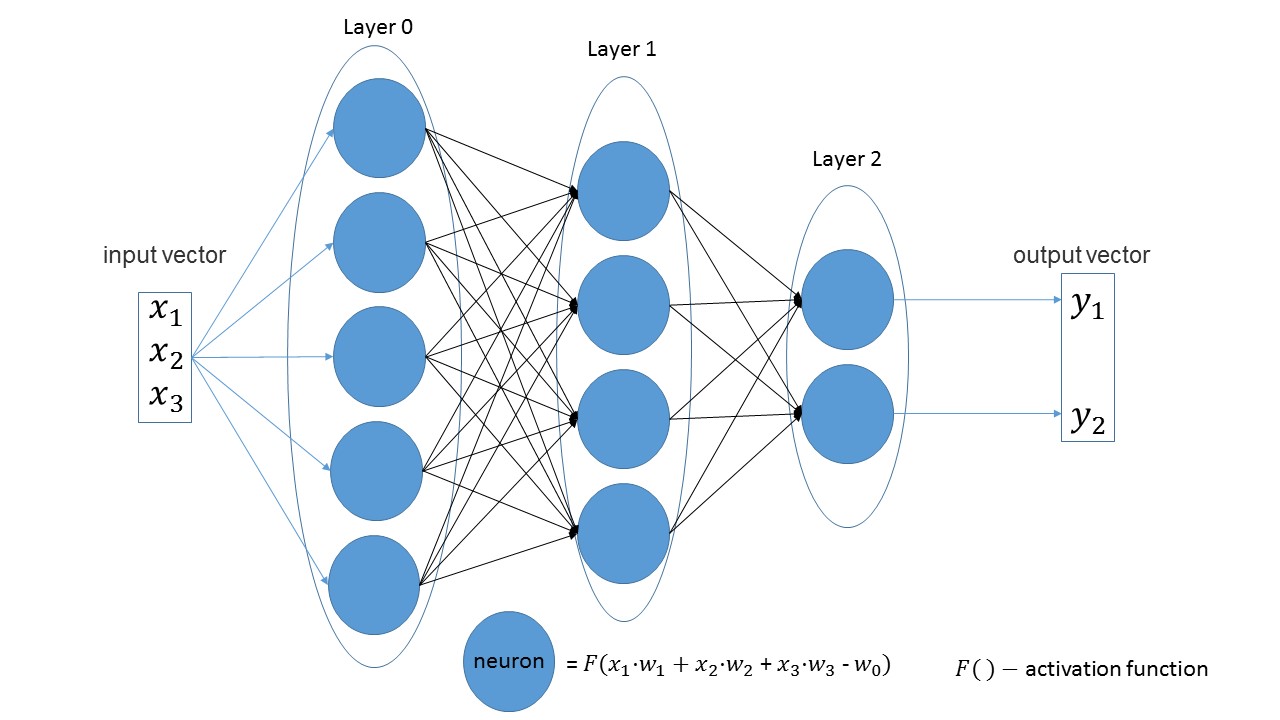
بشكل افتراضي ، تكون جميع وظائف التنشيط هي السيني (أحبها أكثر).
إذا رغبت في ذلك ، في أي طبقة يمكن تغييرها إلى وظيفة أخرى.
تتوفر ميزات التنشيط الأكثر شعبية. nn.get_layer(0).set_activation_function("gaussian")
من السهل إنشاء مجموعة التدريب. المتجه الأول هو بيانات الإدخال ، والمتجه الثاني هو البيانات المستهدفة.
data = foxnn.train_data() data.add_data([1, 2, 3], [1, 0])
تدريب الشبكة:
nn.train(data_for_train=data, speed=0.01, max_iteration=100, size_train_batch=98)
تمكين التحسين:
nn.settings.set_mode("Adam")
وطريقة للحصول على قيمة الشبكة فقط:
nn.get_out([0, 1, 0.1])
قليلا عن اسم الأسلوب.بشكل منفصل ، الحصول على يترجم كيفية الحصول ، والخروج يعني الإخراج . كنت أرغب في الحصول على اسم " إعطاء قيمة الإخراج " ، وحصلت عليه. فقط في وقت لاحق لاحظت أنه تبين أن الخروج . لكنها أكثر متعة ، وقررت الرحيل.
تجريب
لقد أصبح بالفعل تقليدًا غير مكتوب لاختبار أي شبكة تعتمد على
MNIST . ولم أكن استثناء. يمكن العثور على جميع التعليمات البرمجية مع التعليقات
هنا .
يخلق عينة التدريب: from mnist import MNIST import foxnn mndata = MNIST('C:download/') mndata.gz = True imagesTrain, labelsTrain = mndata.load_training() def get_data(images, labels): train_data = foxnn.train_data() for im, lb in zip(images, labels): data_y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
إنشاء شبكة: ثلاث طبقات ، 784 معلمة للإدخال ، و 10 للإخراج: nn = foxnn.neural_network([784, 512, 512, 10]) nn.settings.n_threads = 7
نحن ندرب: nn.train(data_for_train=train_data, speed=0.001, max_iteration=10000, size_train_batch=98)
ماذا حدث:
في حوالي 10 دقائق (تسريع وحدة المعالجة المركزية فقط) ، يمكن الحصول على دقة 75 ٪. مع تحسين آدم ، يمكن الحصول على دقة بنسبة 88 ٪ في 5 دقائق. في النهاية ، تمكنت من تحقيق دقة 97 ٪.
العيوب الرئيسية (هناك بالفعل خطط للمراجعة):- في بيثون ، لم يتم ارتكاب الأخطاء بعد ، أي في بيثون ، لن يتم اعتراض الخطأ وسيتم إنهاء البرنامج ببساطة مع وجود خطأ.
- بينما يشار إلى التدريب في التكرار ، وليس في العصور ، كما هو معتاد في الشبكات الأخرى.
- لا تسريع GPU
- لا توجد أنواع أخرى من الطبقات حتى الآن.
- نحتاج إلى تحميل المشروع إلى PyPi.
لقليل من إكمال المشروع ، كانت هذه المقالة غير موجودة. إذا كان ما لا يقل عن عشرة أشخاص مهتمين باللعب ، فسيكون هناك بالفعل نصر. مرحبا بكم في
جيثب بلدي.
ملاحظة: إذا كنت بحاجة إلى إنشاء شيء خاص بك من أجل معرفة ذلك ، لا تخف وخلق.