منذ بعض الوقت ، في مناقشة حول أحد إصدارات SObjectizer ، سُئلنا: "هل من الممكن إنشاء DSL لوصف خط أنابيب معالجة البيانات؟" بمعنى آخر ، هل يمكن كتابة شيء كالتالي:
A | B | C | D
واحصل على خط أنابيب يعمل حيث تنتقل الرسائل من A إلى B ، ثم إلى C ، ثم إلى D. مع التحكم ، يتلقى B بالضبط هذا النوع الذي تُرجعه A. ويتلقى C بالضبط هذا النوع الذي يعود B. و هكذا.
لقد كانت مهمة مثيرة للاهتمام مع حل بسيط بشكل مدهش. على سبيل المثال ، هكذا يبدو إنشاء خط أنابيب:
auto pipeline = make_pipeline(env, stage(A) | stage(B) | stage(C) | stage(D));
أو في حالة أكثر تعقيدًا (سيتم مناقشتها أدناه):
auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) );
في هذه المقالة ، سنتحدث عن تنفيذ خط الأنابيب DSL هذا. سنناقش في الغالب الأجزاء المتعلقة stage() ، broadcast() operator|() ووظائف operator|() مع العديد من الأمثلة على استخدام قوالب C ++. لذا آمل أن يكون الأمر ممتعًا حتى بالنسبة للقراء الذين لا يعرفون عن SObjectizer (إذا لم تسمع عن SObjectizer هنا فهي نظرة عامة على هذه الأداة).
بضع كلمات حول التجريبي المستخدمة
تأثر المثال المستخدم في المقالة بتجربتي القديمة (والمنسية) في منطقة SCADA.
فكرة العرض التوضيحي هي معالجة البيانات المقروءة من بعض أجهزة الاستشعار. يتم الحصول على البيانات من جهاز استشعار مع بعض الفترة ، ثم يجب التحقق من صحة البيانات (يجب تجاهل البيانات غير الصحيحة) وتحويلها إلى بعض القيم الفعلية. على سبيل المثال ، يمكن أن تكون البيانات الأولية المقروءة من مستشعر قيمتين صحيحتين 8 بت ويجب تحويل تلك القيم إلى رقم الفاصلة العائمة.
ثم ينبغي أرشفة القيم الصالحة والمحوّلة ، وتوزيعها في مكان ما (على عقد مختلفة للتخيل ، على سبيل المثال) ، والتحقق من وجود "إنذارات" (إذا كانت القيم خارجة عن نطاقات آمنة ، فيجب معالجة ذلك بشكل خاص). هذه العمليات مستقلة ويمكن تنفيذها على التوازي.
يمكن إجراء العمليات المتعلقة بالإنذار المكتشف بشكل متوازٍ أيضًا: يجب بدء "المنبه" (حتى يمكن لجزء SCADA على العقدة الحالية أن يتفاعل معه) ويجب توزيع المعلومات حول "المنبه" في مكان آخر (على سبيل المثال : تخزينها في قاعدة بيانات تاريخية و / أو تصور على شاشة مشغل SCADA).
يمكن التعبير عن هذا المنطق بشكل نصي بهذه الطريقة:
optional(valid_raw_data) = validate(raw_data); if valid_raw_data is not empty then { converted_value = convert(valid_raw_data); do_async archive(converted_value); do_async distribute(converted_value); do_async { optional(suspicious_value) = check_range(converted_value); if suspicious_value is not empty then { optional(alarm) = detect_alarm(suspicious_value); if alarm is not empty then { do_async initiate_alarm(alarm); do_async distribute_alarm(alam); } } } }
أو ، في شكل رسوم بيانية:

إنه مثال مصطنع إلى حد ما ، ولكنه يحتوي على بعض الأشياء المثيرة للاهتمام التي أريد عرضها. الأول هو وجود مراحل متوازية في خط أنابيب (عملية broadcast() موجودة فقط بسبب ذلك). والثاني هو وجود دولة في بعض المراحل. على سبيل المثال ، alarm_detector هو مرحلة الدولة.
قدرات خطوط الأنابيب
تم بناء خط أنابيب من مراحل منفصلة. كل مرحلة هي وظيفة أو فاعل بالتنسيق التالي:
opt<Out> func(const In &);
أو
void func(const In &);
لا يمكن استخدام المراحل التي تُرجع void إلا في المرحلة الأخيرة من خط الأنابيب.
لا بد المراحل في سلسلة. تستقبل كل مرحلة تالية كائنًا تم إرجاعه بواسطة المرحلة السابقة. إذا كانت المرحلة السابقة تُرجع القيمة الفارغة ، opt<Out> القيمة opt<Out> ثم لا يتم استدعاء المرحلة التالية.
هناك مرحلة broadcast الخاصة. هي التي شيدت من عدة خطوط أنابيب. تستقبل مرحلة broadcast كائنًا من المرحلة السابقة وتبثه إلى كل خط أنابيب فرعي.
من وجهة نظر خط الأنابيب ، تبدو مرحلة broadcast كدالة بالتنسيق التالي:
void func(const In &);
نظرًا لعدم وجود قيمة إرجاع من مرحلة broadcast يمكن أن تكون مرحلة broadcast المرحلة الأخيرة فقط في خط أنابيب.
لماذا ترجع مرحلة خط الأنابيب قيمة اختيارية؟
ذلك لأن هناك حاجة لإسقاط بعض القيم الواردة. على سبيل المثال ، لا تقوم مرحلة validate بإرجاع أي شيء إذا كانت القيمة الأولية غير صحيحة ، ولا يوجد أي معنى لمعالجتها.
مثال آخر: لا تقوم مرحلة alarm_detector بإرجاع أي شيء إذا لم تنتج القيمة المشبوهة الحالية عن حالة إنذار جديدة.
تفاصيل التنفيذ
لنبدأ من أنواع البيانات والوظائف المتعلقة بمنطق التطبيق. في المثال الذي تمت مناقشته ، يتم استخدام أنواع البيانات التالية لتمرير المعلومات من مرحلة إلى أخرى:
هناك مثيل لـ raw_value ينتقل إلى المرحلة الأولى من خط أنابيبنا. يحتوي هذا raw_value على معلومات تم الحصول عليها من جهاز استشعار في شكل كائن raw_measure . ثم يتم تحويل valid_raw_value إلى valid_raw_value . ثم valid_raw_value تحولت إلى sensor_value مع قيمة جهاز استشعار الفعلي في شكل calulated_measure . إذا احتوى مثيل من sensor_value على قيمة مريبة ، فسيتم إنتاج مثيل للقيمة suspicious_value . ويمكن تحويل هذا القيمة suspicious_value إلى مثيل alarm_detected لاحقًا.
أو بالصيغة الرسومية:

الآن يمكننا إلقاء نظرة على تنفيذ مراحل خط الأنابيب لدينا:
فقط تخطي أشياء مثل stage_result_t و make_result و make_empty ، سنناقشها في القسم التالي.
آمل أن رمز تلك المراحل تافهة إلى حد ما. الجزء الوحيد الذي يتطلب بعض التفسير الإضافي هو تنفيذ مرحلة alarm_detector .
في هذا المثال ، يتم تشغيل المنبه فقط إذا كان هناك على الأقل اثنين من القيم suspicious_values في نافذة زمنية تبلغ 25 مللي ثانية. لذلك يتعين علينا أن نتذكر وقت المثيل suspicious_value السابق في مرحلة alarm_detector . وذلك لأن تطبيق alarm_detector يتم تطبيقه كمسؤول ذي حالة جيدة مع مشغل استدعاء دالة.
تقوم المراحل بإرجاع نوع SObjectizer بدلاً من std :: اختياري
قلت في وقت سابق أن هذه المرحلة يمكن أن تعود قيمة اختيارية لكن std::optional لا يستخدم في التعليمات البرمجية ، يمكن رؤية النوع stage_result_t في تنفيذ المراحل.
فذلك لأن بعض SObjectizer المحددة تلعب دورها هنا. سيتم توزيع القيم التي يتم إرجاعها كرسائل بين وكلاء SObjectizer (ويعرف أيضًا باسم العناصر الفاعلة). يتم إرسال كل رسالة في SObjectizer ككائن مخصص بشكل حيوي. لذلك لدينا نوع من "التحسين" هنا: بدلاً من إرجاع std::optional ومن ثم تخصيص كائن رسالة جديد ، نحن فقط نخصص كائن رسالة ونعيد مؤشر ذكي إليه.
في الواقع ، stage_result_t هو مجرد typedef ل anal_ptr Shared_ptr التناظرية:
template< typename M > using stage_result_t = message_holder_t< M >;
و make_result و make_empty هما دالات مساعدة فقط لإنشاء stage_result_t مع أو بدون قيمة فعلية بداخل:
template< typename M, typename... Args > stage_result_t< M > make_result( Args &&... args ) { return stage_result_t< M >::make(forward< Args >(args)...); } template< typename M > stage_result_t< M > make_empty() { return stage_result_t< M >(); }
للبساطة ، يمكن القول أن مرحلة validation من validation يمكن التعبير عنها بهذه الطريقة:
std::shared_ptr< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return std::make_shared< valid_raw_value >( v.m_data ); else return std::shared_ptr< valid_raw_value >{}; }
ولكن نظرًا لخصوصية SObjectizer ، لا يمكننا استخدام std::shared_ptr so_5::message_holder_t التعامل مع so_5::message_holder_t type. ونحن نخفي ذلك المحدد وراء stage_result_t و make_result و make_empty المساعدين.
stage_handler_t والفصل stage_builder_t
تتمثل إحدى النقاط المهمة في تنفيذ خط الأنابيب في الفصل بين مفاهيم معالج المرحلة ومرحلة البناء . يتم ذلك من أجل البساطة. سمح لي وجود هذه المفاهيم بأن يكون لدي خطوتين في تعريف خط الأنابيب.
في الخطوة الأولى ، يصف المستخدم مراحل خطوط الأنابيب. نتيجة لذلك ، أتلقى مثيل stage_t الذي يحتفظ بجميع مراحل خط الأنابيب في الداخل.
في الخطوة الثانية ، يتم إنشاء مجموعة من وكلاء SObjectizer الأساسي. يتلقى هؤلاء الوكلاء رسائل تحتوي على نتائج المراحل السابقة ويتصلون بمعالجات المرحلة الفعلية ، ثم يرسلون النتائج إلى المراحل التالية.
ولكن لإنشاء هذه المجموعة من العوامل ، يجب أن يكون لكل مرحلة منشئ مرحلة . يمكن رؤية منشئ المرحلة كمصنع يقوم بإنشاء وكيل SObjectizer الأساسي.
لذلك لدينا العلاقة التالية: كل مرحلة من مراحل خط الأنابيب تنتج كائنين: معالج المرحلة الذي يحتفظ بالمنطق المرتبط بالمرحلة ، ومنشئ المرحلة الذي ينشئ وكيل SObjectizer الأساسي لاستدعاء معالج المرحلة في الوقت المناسب:

يتم تمثيل معالج المرحلة بالطريقة التالية:
template< typename In, typename Out > class stage_handler_t { public : using traits = handler_traits_t< In, Out >; using func_type = function< typename traits::output(const typename traits::input &) >; stage_handler_t( func_type handler ) : m_handler( move(handler) ) {} template< typename Callable > stage_handler_t( Callable handler ) : m_handler( handler ) {} typename traits::output operator()( const typename traits::input & a ) const { return m_handler( a ); } private : func_type m_handler; };
حيث يتم تعريف handler_traits_t بالطريقة التالية:
ويمثل باني المرحلة فقط std::function :
using stage_builder_t = function< mbox_t(coop_t &, mbox_t) >;
أنواع المساعدة lambda_traits_t و callable_traits_t
نظرًا لأن المراحل يمكن تمثيلها بواسطة وظائف مجانية أو عوامل توجيه (مثل مثيلات فئة alarm_detector أو الفئات التي تم إنشاؤها بواسطة مترجم مجهول تمثل lambdas) ، فنحن بحاجة إلى بعض المساعدين للكشف عن أنواع وسيطة المرحلة وقيمة الإرجاع. لقد استخدمت الكود التالي لهذا الغرض:
آمل أن يكون هذا الرمز مفهوما تمامًا للقراء الذين لديهم معرفة جيدة بـ C ++. إذا لم يكن الأمر كذلك ، فلا تتردد في lambda_traits_t ، lambda_traits_t أن أشرح المنطق وراء lambda_traits_t و callable_traits_t بالتفصيل.
المرحلة () ، وظائف البث () و | () المشغل
الآن يمكننا أن ننظر داخل وظائف بناء خطوط الأنابيب الرئيسية. ولكن قبل ذلك ، من الضروري إلقاء نظرة على تعريف فئة القالب stage_t :
template< typename In, typename Out > struct stage_t { stage_builder_t m_builder; };
إنها بنية بسيطة للغاية تحتوي على مثيل stage_bulder_t فقط. لا يتم استخدام معلمات القالب داخل stage_t ، فلماذا تكون موجودة هنا؟
وهي ضرورية للتحقق من وقت ترجمة توافق النوع بين مراحل خطوط الأنابيب. سنرى ذلك قريباً.
لنلقِ نظرة على أبسط وظيفة لبناء خطوط الأنابيب ، stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( Callable handler ) { stage_builder_t builder{ [h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent< a_stage_point_t<In, Out> >( std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
يتلقى معالج مرحلة الفعلي كمعلمة واحدة. يمكن أن يكون مؤشرًا لوظيفة أو وظيفة lambda أو functor. يتم استنباط أنواع المدخلات والمخرجات في المرحلة تلقائيًا بسبب "قالب السحر" وراء قالب callable_traits_t .
يتم إنشاء مثيل منشئ المرحلة داخل ويتم إرجاع هذا المثيل في كائن stage_t جديد stage_t stage() . يتم التقاط معالج المرحلة الفعلي بواسطة أداة بناء المرحلة lambda ، ثم سيتم استخدامه لإنشاء وكيل SObjectizer الأساسي (سنتحدث عن ذلك في القسم التالي).
الوظيفة التالية للمراجعة هي operator|() الذي يسلسل مرحلتين معًا ويعيد مرحلة جديدة:
template< typename In, typename Out1, typename Out2 > stage_t< In, Out2 > operator|( stage_t< In, Out1 > && prev, stage_t< Out1, Out2 > && next ) { return { stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } } }; }
إن أبسط طريقة لشرح منطق operator|() هي محاولة رسم صورة. لنفترض أن لدينا التعبير:
stage(A) | stage(B) | stage(C) | stage(B)
سيتم تحويل هذا التعبير بهذه الطريقة:

هناك يمكننا أيضًا أن نرى كيف يعمل فحص نوع الترجمة: يتطلب تعريف operator|() أن يكون نوع إخراج المرحلة الأولى هو مدخلات المرحلة الثانية. إذا لم يكن الأمر كذلك ، فلن يتم تجميع الشفرة.
والآن يمكننا إلقاء نظرة على وظيفة بناء خطوط الأنابيب الأكثر تعقيدًا ، broadcast() . الوظيفة نفسها بسيطة إلى حد ما:
template< typename In, typename Out, typename... Rest > stage_t< In, void > broadcast( stage_t< In, Out > && first, Rest &&... stages ) { stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } }; return { std::move(builder) }; }
الفرق الرئيسي بين المرحلة العادية والمرحلة الإذاعية هو أن المرحلة الإذاعية يجب أن تحمل ناقلات منشئي المرحلة الفرعية. لذلك يتعين علينا إنشاء هذا المتجه وتمريره إلى باني المسرح الرئيسي لمرحلة البث. لهذا السبب ، يمكننا أن نرى دعوة إلى collect_sink_builders في قائمة التقاط lambda داخل وظيفة broadcast() :
stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)]
إذا نظرنا إلى collect_sink_builder الرمز التالي:
يعمل التحقق من وقت التحويل البرمجي للوقت هنا أيضًا: لأنه يتم استدعاء معلمة move_sink_builder_to بشكل واضح حسب النوع "في". يعني ذلك أن إجراء مكالمة في النموذج collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...) سيؤدي إلى حدوث خطأ في الترجمة لأن المحول البرمجي يحظر إجراء المكالمة move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...) .
يمكنني أيضًا ملاحظة أنه نظرًا لأن عدد خطوط الأنابيب الفرعية broadcast() معروف في وقت الترجمة ، يمكننا استخدام std::array بدلاً من std::vector ويمكن تجنب بعض عمليات تخصيص الذاكرة. لكن std::vector يستخدم هنا فقط للبساطة.
العلاقة بين المراحل ووكلاء / mboxes SObjectizer
الفكرة وراء تنفيذ خط الأنابيب هي إنشاء وكيل منفصل لكل مرحلة من مراحل خط الأنابيب. يتلقى الوكيل رسالة واردة ، ويمررها إلى معالج المرحلة المقابل ، ويحلل النتيجة ، وإذا لم تكن النتيجة فارغة ، يرسل النتيجة كرسالة واردة إلى المرحلة التالية. يمكن توضيحه بواسطة مخطط التسلسل التالي:

يجب مناقشة بعض الأشياء المرتبطة بـ SObjectizer ، على الأقل لفترة وجيزة. إذا لم تكن مهتمًا بمثل هذه التفاصيل ، يمكنك تخطي الأقسام أدناه والانتقال إلى الاستنتاج مباشرةً.
Coop هي مجموعة من العملاء للعمل معًا
يتم تقديم الوكلاء في SObjectizer ليس بشكل فردي ولكن في مجموعات باسم حظائر. حظيرة هي مجموعة من العوامل التي يجب أن تعمل معا وليس هناك معنى لمواصلة العمل إذا كان أحد وكلاء المجموعة مفقود.
لذا فإن إدخال العوامل إلى SObjectizer يشبه إنشاء مثيل حظيرة ، وملء هذا المثيل بالوكلاء المناسبين ثم تسجيل حظيرة في SObjectizer.
وبسبب ذلك ، فإن الحجة الأولى لباني المسرح هي إشارة إلى حظيرة جديدة. يتم إنشاء هذا حظيرة في وظيفة make_pipeline() (تمت مناقشتها أدناه) ، ثم يتم ملؤها بواسطة منشئي المسرح ثم يتم تسجيلها (مرة أخرى في وظيفة make_pipeline() ).
صناديق الرسائل
ينفذ SObjectizer العديد من النماذج المتعلقة التزامن. ممثل نموذج واحد منهم فقط. بسبب ذلك ، يمكن أن تختلف SObjectizer بشكل كبير عن أطر الفاعل الأخرى. أحد الاختلافات هو نظام العنونة للرسائل.
لا يتم توجيه الرسائل في SObjectizer إلى الجهات الفاعلة ، ولكن مربعات الرسائل (mboxes). يتعين على الممثلين الاشتراك في رسائل من mbox. إذا اشترك أحد الممثلين في نوع رسالة معين من mbox ، فسيتلقى رسائل من هذا النوع:
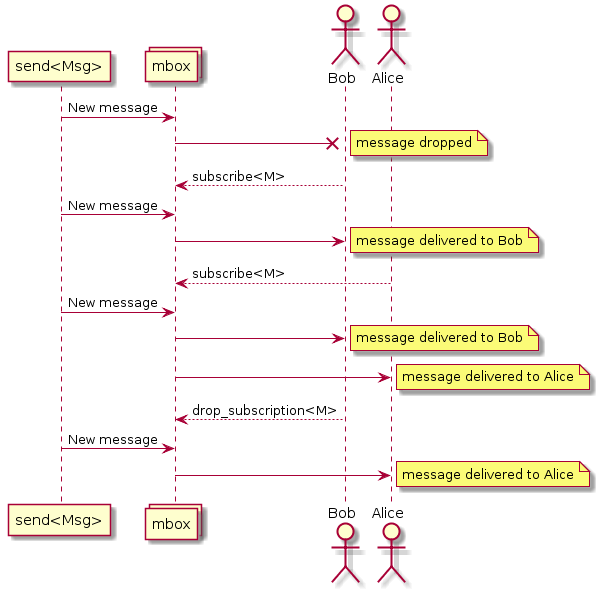
هذه الحقيقة ضرورية لأنه من الضروري إرسال رسائل من مرحلة إلى أخرى. وهذا يعني أن كل مرحلة يجب أن يكون لها mbox وأن mbox يجب أن تكون معروفة للمرحلة السابقة.
كل ممثل (الملقب وكيل) في SObjectizer لديه mbox المباشر . يرتبط mbox هذا بوكيل المالك فقط ولا يمكن استخدامه من قبل أي وكلاء آخرين. سيتم استخدام mboxes المباشر للعوامل التي تم إنشاؤها لمراحل التفاعل التفاعلي.
تحدد ميزة SObjectizer المحددة بعض تفاصيل تنفيذ خط الأنابيب.
الأول هو حقيقة أن باني المسرح لديه النموذج الأولي التالي:
mbox_t builder(coop_t &, mbox_t);
هذا يعني أن منشئ المرحلة يتلقى mbox من المرحلة التالية ويجب أن ينشئ وكيلًا جديدًا يرسل نتائج المرحلة إلى ذلك mbox. يجب إعادة mbox الخاص بالوكيل الجديد بواسطة باني المسرح . سيتم استخدام mbox لإنشاء وكيل للمرحلة السابقة.
والثاني هو حقيقة أن يتم إنشاء وكلاء للمراحل في ترتيب احتياطي. وهذا يعني أنه إذا كان لدينا خط أنابيب:
stage(A) | stage(B) | stage(C)
سيتم إنشاء وكيل للمرحلة C أولاً ، ثم سيتم استخدام mbox الخاص به لإنشاء وكيل للمرحلة B ، ومن ثم سيتم استخدام mbox من وكيل B- المرحلة لإنشاء وكيل للمرحلة A.
تجدر الإشارة إلى أن operator|() لا ينشئ وكلاء:
stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } }
ينشئ operator|() منشئًا يستدعي منشئين آخرين فقط ولكن لا يقدم عوامل إضافية. لذلك بالنسبة للقضية:
stage(A) | stage(B)
سيتم إنشاء وكيلين فقط (للمرحلة A و B- المرحلة) وبعد ذلك سيتم ربطهما معًا في منشئ المرحلة الذي تم إنشاؤه بواسطة operator|() .
لا يوجد وكيل لتطبيق broadcast()
تتمثل إحدى الطرق الواضحة لتطبيق مرحلة البث في إنشاء وكيل خاص يتلقى رسالة واردة ثم يعيد إرسال هذه الرسالة إلى قائمة بمربعات mbox المقصودة. تم استخدام هذه الطريقة في التنفيذ الأول لخط أنابيب DSL الموصوف.
لكن مشروعنا المصاحب ، so5extra ، لديه الآن نوع خاص من mbox: إذاعة واحدة. يعمل mbox بالضبط على ما هو مطلوب هنا: فهو يأخذ رسالة جديدة ويقوم بتسليمها إلى مجموعة من mboxes الوجهة.
نظرًا لعدم وجود حاجة لإنشاء وكيل بث منفصل ، يمكننا فقط استخدام mbox للبث من so5extra:
تنفيذ وكيل المرحلة
الآن يمكننا إلقاء نظرة على تنفيذ وكيل المرحلة:
انها تافهة إلى حد ما إذا كنت تفهم أساسيات SObjectizer. إذا لم يكن الأمر كذلك ، فسيكون من الصعب للغاية شرحه بعدة كلمات (لذلك لا تتردد في طرح الأسئلة في التعليقات).
يقوم التطبيق الرئيسي لوكيل a_stage_point_t بإنشاء اشتراك في رسالة من النوع In. عند وصول رسالة من هذا النوع ، يتم استدعاء معالج المرحلة . في حالة إرجاع معالج المرحلة لنتيجة فعلية ، يتم إرسال النتيجة إلى المرحلة التالية (إذا كانت تلك المرحلة موجودة).
يوجد أيضًا إصدار a_stage_point_t للحالة عندما تكون المرحلة المقابلة هي المرحلة النهائية ولا يمكن أن تكون هناك المرحلة التالية.
قد يبدو تطبيق a_stage_point_t معقدًا بعض الشيء ولكن a_stage_point_t ، إنه أحد أبسط العوامل التي كتبتها.
وظيفة make_pipeline ()
حان الوقت لمناقشة آخر وظيفة لبناء خطوط الأنابيب ، make_pipeline() :
template< typename In, typename Out, typename... Args > mbox_t make_pipeline(
لا يوجد سحر ولا مفاجآت هنا. نحتاج فقط إلى إنشاء حظيرة جديدة للعوامل الأساسية لخط الأنابيب ، وملء تلك القوقعة بالوكلاء عن طريق استدعاء منشئ مرحلة من المستوى الأعلى ، ومن ثم تسجيل ذلك القفاز في SObjectizer. هذا كل شيء.
نتيجة make_pipeline() هي mbox للمرحلة الأكثر يسارًا (الأولى) من خط الأنابيب. يجب استخدام mbox لإرسال الرسائل إلى خط الأنابيب.
المحاكاة والتجارب معها
إذن لدينا الآن أنواع البيانات ووظائفها لمنطق التطبيق لدينا والأدوات اللازمة لتسلسل تلك الوظائف إلى خط أنابيب لمعالجة البيانات. دعونا نفعل ذلك ونرى النتيجة:
int main() {
إذا قمنا بتشغيل هذا المثال ، فسنرى الإخراج التالي:
archiving (0,0) distributing (0,0) archiving (0,5) distributing (0,5) archiving (0,10) distributing (0,10) archiving (0,15) distributing (0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,30) distributing (0,30) ... archiving (0,105) distributing (0,105) archiving (0,110) distributing (0,110) === alarm (0) === alarm_distribution (0) archiving (0,115) distributing (0,115) archiving (0,120) distributing (0,120) === alarm (0) === alarm_distribution (0)
إنه يعمل.
لكن يبدو أن مراحل خط أنابيبنا تعمل بالتتابع ، واحدة تلو الأخرى ، أليس كذلك؟
نعم هو كذلك. وذلك لأن جميع وكلاء خطوط الأنابيب مرتبطون بـ مرسل SObjectizer الافتراضي. ويستخدم هذا المرسل خيط عامل واحد فقط لخدمة معالجة الرسائل لجميع الوكلاء.
ولكن هذا يمكن تغييره بسهولة. ما عليك make_pipeline() تمرير وسيطة إضافية make_pipeline() مكالمة make_pipeline() :
يؤدي هذا إلى إنشاء تجمع مؤشرات ترابط جديد ويربط كافة عوامل خط أنابيب إلى ذلك التجمع. سيتم تقديم الخدمات لكل وكيل بشكل مستقل عن الوكلاء الآخرين.
إذا قمنا بتشغيل المثال المعدل ، يمكننا أن نرى شيئًا كهذا:
archiving (0,0) distributing (0,0) distributing (0,5) archiving (0,5) archiving (0,10) distributing (0,10) distributing (archiving (0,15) 0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,distributing (030) ,30) ... archiving (0,distributing (0,105) 105) archiving (0,alarm_distribution (0) distributing (0,=== alarm (0) === 110) 110) archiving (distributing (0,0,115) 115) archiving (distributing (=== alarm (0) === 0alarm_distribution (0) 0,120) ,120)
لذلك يمكننا أن نرى أن المراحل المختلفة لخط الأنابيب تعمل بشكل متوازٍ.
ولكن هل من الممكن المضي قدمًا ولدينا القدرة على ربط المراحل بالمرسلين المختلفين؟
نعم ، هذا ممكن ، لكن يتعين علينا تنفيذ وظيفة حمل زائد أخرى stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( disp_binder_shptr_t disp_binder, Callable handler ) { stage_builder_t builder{ [binder = std::move(disp_binder), h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent_with_binder< a_stage_point_t<In, Out> >( std::move(binder), std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
لا يقبل هذا الإصدار من stage() معالج المرحلة فحسب ، بل يقبل أيضًا رابط المرسِل. Dispatcher binder is a way to bind an agent to the particular dispatcher. So to assign a stage to a specific working context we can create an appropriate dispatcher and then pass the binder to that dispatcher to stage() function. Let's do that:
In that case stages archiving , distribution , alarm_initiator and alarm_distribution will work on own worker threads. All other stages will work on the same single worker thread.
The conclusion
This was an interesting experiment and I was surprised how easy SObjectizer could be used in something like reactive programming or data-flow programming.
However, I don't think that pipeline DSL can be practically meaningful. It's too simple and, maybe not flexible enough. But, I hope, it can be a base for more interesting experiments for those why need to deal with different workflows and data-processing pipelines. At least as a base for some ideas in that area. C++ language a rather good here and some (not so complicated) template magic can help to catch various errors at compile-time.
In conclusion, I want to say that we see SObjectizer not as a specialized tool for solving a particular problem, but as a basic set of tools to be used in solutions for different problems. And, more importantly, that basic set can be extended for your needs. Just take a look at SObjectizer , try it, and share your feedback. Maybe you missed something in SObjectizer? Perhaps you don't like something? Tell us , and we can try to help you.
If you want to help further development of SObjectizer, please share a reference to it or to this article somewhere you want (Reddit, HackerNews, LinkedIn, Facebook, Twitter, ...). The more attention and the more feedback, the more new features will be incorporated into SObjectizer.
And many thanks for reading this ;)
PS. The source code for that example can be found in that repository .