
اسمي إدوارد تيانتوف ، أقود فريق رؤية الكمبيوتر في مجموعة Mail.ru. على مدار سنوات عديدة من الوجود ، حل فريقنا العشرات من مشاكل رؤية الكمبيوتر ، وسأخبرك اليوم عن الطرق التي نستخدمها لإنشاء نماذج تعلم آلي ناجحة تعمل على مجموعة واسعة من المهام. سوف أشارك الحيل التي يمكن أن تسرع النموذج في جميع المراحل: تحديد مهمة ، إعداد البيانات ، التدريب والنشر في الإنتاج.
رؤية الكمبيوتر في Mail.ru
بادئ ذي بدء ، ما هي رؤية الكمبيوتر في Mail.ru ، وما هي المشاريع التي نقوم بها. نحن نقدم حلولًا في منتجاتنا ، مثل Mail و Mail.ru Cloud (تطبيق لتخزين الصور ومقاطع الفيديو) و Vision (حلول B2B القائمة على رؤية الكمبيوتر) وغيرها. سأقدم بعض الأمثلة.
السحابة (هذا هو عميلنا الأول والرئيسي) يحمل 60 مليار صورة. نقوم بتطوير العديد من الميزات استنادًا إلى التعلم الآلي للمعالجة الذكية الخاصة بهم ، على سبيل المثال ، التعرف على الوجوه ومشاهدة المعالم السياحية (
هناك منشور منفصل حول هذا ). يتم تشغيل جميع صور المستخدم من خلال نماذج التعرف ، والتي تتيح لك تنظيم عملية بحث وتجميع بواسطة الأشخاص والعلامات والمدن والبلدان التي تمت زيارتها ، وما إلى ذلك.
بالنسبة إلى Mail ، فعلنا التعرف الضوئي على الحروف (OCR) - التعرف على النص من الصورة. اليوم سوف أخبركم عنه قليلاً.
بالنسبة لمنتجات B2B ، نحن نعترف ونحسب الأشخاص في قوائم الانتظار. على سبيل المثال ، هناك قائمة انتظار لمصعد التزلج ، وتحتاج إلى حساب عدد الأشخاص الموجودين فيها. بادئ ذي بدء ، من أجل اختبار التكنولوجيا واللعب ، قمنا بنشر نموذج أولي في غرفة الطعام في المكتب. هناك العديد من مكاتب النقد ، وبالتالي ، هناك العديد من قوائم الانتظار ، ونحن ، باستخدام عدة كاميرات (واحدة لكل قوائم الانتظار) ، باستخدام النموذج ، نحسب عدد الأشخاص الموجودين في قوائم الانتظار وعدد الدقائق المتبقية في كل منها. بهذه الطريقة يمكننا تحقيق توازن أفضل بين الخطوط في غرفة الطعام.

بيان المشكلة
لنبدأ بالجزء الحرج من أي مهمة - صياغتها. يستغرق تطوير ML - تقريبًا شهرًا على الأقل (يكون ذلك في أفضل الأحوال عندما تعرف ما يجب القيام به) ، وفي معظم الحالات عدة أشهر. إذا كانت المهمة غير صحيحة أو غير دقيقة ، فهناك فرصة كبيرة في نهاية العمل لسماع شيء من مدير المنتج بروح: "كل شيء خطأ. هذا ليس جيد أردت شيئا آخر. " لمنع حدوث ذلك ، تحتاج إلى اتخاذ بعض الخطوات. ما هو خاص حول المنتجات القائمة على ML؟ على عكس مهمة تطوير موقع ، لا يمكن إضفاء الطابع الرسمي على مهمة التعلم الآلي بالنص وحده. علاوة على ذلك ، كقاعدة عامة ، يبدو لشخص غير مستعد أن كل شيء واضح بالفعل ، وأنه مطلوب ببساطة القيام بكل شيء "بشكل جميل". ولكن ما هي التفاصيل الصغيرة الموجودة ، التي قد لا يعرفها مدير المهام ، ولم يفكر فيها أبدًا ولن يفكر حتى يطلعوا على المنتج النهائي ويقولون: "ماذا فعلت؟"
المشاكل
دعونا نفهم على سبيل المثال ما هي المشاكل التي يمكن أن تكون. افترض أن لديك مهمة التعرف على الوجوه. يمكنك الحصول عليها ، ونفرح وتدعو والدتك: "الصيحة ، مهمة مثيرة للاهتمام!" ولكن هل من الممكن الانهيار مباشرة والبدء في القيام به؟ إذا قمت بذلك ، فقد تتوقع مفاجآت في النهاية:
- هناك جنسيات مختلفة. على سبيل المثال ، لم يكن هناك آسيويون أو أي شخص آخر في مجموعة البيانات. وفقًا لذلك ، لا يعرف طرازك كيفية التعرف عليها على الإطلاق ، ويحتاج المنتج إليها. أو بالعكس ، لقد قضيت ثلاثة أشهر إضافية على المراجعة ، وسيكون للمنتج قوقازيين فقط ، وهذا لم يكن ضروريًا.
- هناك اطفال. بالنسبة للآباء الذين ليس لديهم أطفال ، مثلي ، جميع الأطفال على وجه واحد. أنا أتفق تمامًا مع هذا النموذج ، عندما ترسل جميع الأطفال إلى مجموعة واحدة - من غير الواضح حقًا كيف يختلف غالبية الأطفال! ؛) لكن الأشخاص الذين لديهم أطفال لديهم رأي مختلف تمامًا. عادة ما يكونون أيضًا قادتك. أو لا تزال هناك أخطاء مضحكة في التعرف عند مقارنة رأس الطفل بنجاح بالكوع أو رأس رجل أصلع (قصة حقيقية).
- ما يجب فعله مع الشخصيات المطلية غير واضح بشكل عام. هل أحتاج إلى التعرف عليهم أم لا؟
هذه الجوانب من المهمة مهمة جدًا لتحديدها في البداية. لذلك ، تحتاج إلى العمل والتواصل مع المدير منذ البداية "على البيانات". لا يمكن قبول التفسيرات الشفوية. من الضروري أن ننظر إلى البيانات. من المرغوب فيه من نفس التوزيع الذي سيعمل عليه النموذج.
من الناحية المثالية ، في عملية هذه المناقشة ، سيتم الحصول على مجموعة بيانات الاختبار والتي يمكنك من خلالها تشغيل النموذج أخيرًا والتحقق مما إذا كان يعمل كما يريد المدير. من المستحسن إعطاء جزء من مجموعة بيانات الاختبار للمدير نفسه ، بحيث لا يكون لديك أي وصول إليها. نظرًا لأنه يمكنك التراجع بسهولة عن مجموعة الاختبار هذه ، فأنت مطور ML!
تحديد مهمة في ML هو عمل مستمر بين مدير المنتج ومتخصص في ML. حتى إذا قمت في البداية بتعيين المهمة جيدًا ، فمع تطور النموذج ، ستظهر المزيد والمزيد من المشكلات الجديدة ، وهي ميزات جديدة ستتعلمها عن بياناتك. كل هذا يحتاج إلى مناقشة مستمرة مع المدير. يبث المديرون الجيدين دائمًا إلى فرق عملهم التي يحتاجون إليها لتحمل المسؤولية ومساعدة المدير في تعيين المهام.
لماذا هذا التعلم الآلي هو مجال جديد إلى حد ما. لا يملك المديرون (أو لديهم خبرة قليلة) في إدارة هذه المهام. كم مرة يتعلم الناس حل المشاكل الجديدة؟ على الاخطاء. إذا كنت لا تريد أن يصبح مشروعك المفضل خطأً ، فأنت بحاجة إلى المشاركة وتحمل المسؤولية ، وعلِّم مدير المنتج تعيين المهمة بشكل صحيح ، ووضع قوائم تدقيق وسياسات ؛ كل هذا يساعد كثيرا. في كل مرة أسحب نفسي (أو يسحبني أحد من زملائي) عندما تصل مهمة جديدة ومثيرة للاهتمام ، ونركض للقيام بذلك. كل ما قلته للتو ، أنا نفسي أنسى. لذلك ، من المهم أن يكون لديك نوع من قوائم التحقق للتحقق من نفسك.
معطيات
البيانات مهمة للغاية في ML. للتعلم العميق ، كلما كانت البيانات التي تغذيها أكثر ، كلما كان ذلك أفضل. يوضح الرسم البياني الأزرق أن نماذج التعلم العميق عادة ما تتحسن بشكل كبير عند إضافة البيانات.
والخوارزميات "القديمة" (الكلاسيكية) من نقطة ما لم تعد قادرة على تحسين.
عادةً ما تكون مجموعات بيانات ML متسخة. لقد تميزوا بأشخاص يكذبون دائمًا. غالبًا ما يكون المقيِّمون غير مهتمين ويرتكبون الكثير من الأخطاء. نحن نستخدم هذه التقنية: نحن نأخذ البيانات التي لدينا ، ونقوم بتدريب النموذج عليها ، وبعد ذلك بمساعدة هذا النموذج ، نقوم بمسح البيانات ونكرر الدورة مرة أخرى.
دعونا نلقي نظرة فاحصة على مثال التعرف على الوجوه نفسه. دعنا نقول أننا قمنا بتنزيل تجسيدات المستخدم VKontakte. على سبيل المثال ، لدينا ملف تعريف مستخدم به 4 تجسيدات. نكتشف الوجوه الموجودة على جميع الصور الأربعة ونعمل من خلال نموذج التعرف على الوجوه. لذلك ، نحصل على حفلات زفاف للأشخاص ، وبمساعدةهم يمكنهم "غراء" أشخاص مماثلين في مجموعات (عنقودية). بعد ذلك ، نختار المجموعة الأكبر ، بافتراض أن الصور الرمزية للمستخدم تحتوي بشكل أساسي على وجهه. وفقًا لذلك ، يمكننا تنظيف جميع الوجوه الأخرى (التي هي ضوضاء) بهذه الطريقة. بعد ذلك ، يمكننا تكرار الدورة مرة أخرى: على البيانات التي تم تنظيفها ، قم بتدريب النموذج واستخدامه لتنظيف البيانات. يمكنك تكرار عدة مرات.
دائما تقريبا لمثل هذه المجموعات نستخدم خوارزميات CLink. هذه هي خوارزمية تجميع هرمية حيث من المريح جدًا تعيين قيمة عتبة للكائنات المتشابهة "الإلتصاق" (هذا هو بالضبط ما هو مطلوب للتنظيف). Clink يولد مجموعات كروية. هذا مهم ، لأننا نتعلم غالبًا المساحة المترية لهذه التضمينات. الخوارزمية لها تعقيد O (ن
2 ) ، والتي ، من حيث المبدأ ، تقريبا.
في بعض الأحيان يكون الحصول على البيانات أو ترميزها أمرًا صعبًا إلى درجة أنه لا يوجد شيء يُترك للقيام به بمجرد البدء في إنشائها. يتيح لك النهج التوليدي إنتاج كمية هائلة من البيانات. ولكن لهذا تحتاج إلى برمجة شيء ما. أبسط مثال هو التعرف الضوئي على الحروف ، التعرف على النص على الصور. إن ترميز النص لهذه المهمة باهظ الثمن وصاخب: تحتاج إلى تمييز كل سطر وكل كلمة وتوقيع النص وما إلى ذلك. سيستغرق المقيِّمون (الأشخاص المختارون) مائة صفحة من النصوص لفترة طويلة للغاية ، وهناك حاجة إلى المزيد من أجل التدريب. من الواضح ، يمكنك إنشاء النص بطريقة أو بأخرى و "نقله" بطريقة ما بحيث يتعلم النموذج منه.
لقد وجدنا لأنفسنا أن أفضل الأدوات وأكثرها ملاءمة لهذه المهمة هي مزيج من PIL و OpenCV و Numpy. لديهم كل شيء للعمل مع النص. يمكنك تعقيد الصورة بالنص بأي طريقة حتى لا تتم إعادة تدريب الشبكة للحصول على أمثلة بسيطة.

في بعض الأحيان نحتاج بعض الأشياء في العالم الحقيقي. على سبيل المثال ، البضائع على رفوف المتاجر. يتم إنشاء واحدة من هذه الصور تلقائيا. هل تعتقد اليسار أو اليمين؟

في الواقع ، يتم إنشاؤها على حد سواء. إذا لم تنظر إلى التفاصيل الصغيرة ، فلن تلاحظ اختلافات عن الواقع. ونحن نفعل ذلك باستخدام خلاط (التناظرية من 3dmax).
الميزة المهمة الرئيسية هي أنه مفتوح المصدر. يحتوي على واجهة برمجة تطبيقات Python ممتازة ، والتي تتيح لك وضع الكائنات في الشفرة مباشرة ، وتكوين العملية وتخصيصها بطريقة عشوائية والحصول على مجموعة بيانات متنوعة في النهاية.
للتقديم ، يتم استخدام تتبع الأشعة. هذا إجراء مكلف إلى حد ما ، ولكنه ينتج نتيجة بجودة ممتازة. السؤال الأكثر أهمية: من أين يمكن الحصول على نماذج للكائنات؟ كقاعدة عامة ، يجب شراؤها. ولكن إذا كنت طالبًا فقيرًا وترغب في تجربة شيء ما ، فهناك دائمًا السيول. من الواضح أنه بالنسبة للإنتاج ، يتعين عليك شراء أو طلب نماذج مقدمة من شخص ما.
هذا كل شيء عن البيانات. دعنا ننتقل إلى التعلم.
التعلم المتري
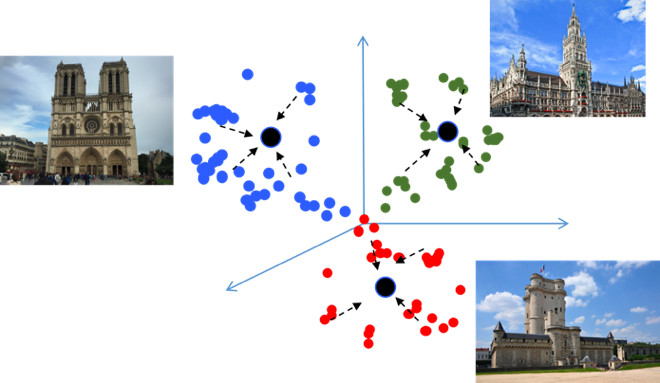
الهدف من تعلم Metric هو تدريب الشبكة بحيث تقوم بترجمة كائنات مماثلة إلى مناطق مماثلة في مساحة القياس المتضمنة. سأقدم مرة أخرى مثالًا على ذلك ، وهو أمر غير معتاد من حيث أنه في جوهره مهمة تصنيف ، ولكن لعشرات الآلاف من الفصول الدراسية. يبدو ، لماذا هنا التعلم المتري ، الذي ، كقاعدة عامة ، هو مناسب في مهام مثل التعرف على الوجوه؟ دعنا نحاول معرفة ذلك.
إذا كنت تستخدم الخسائر القياسية عند التدريب على مشكلة تصنيف ، على سبيل المثال ، Softmax ، فسيتم فصل الفئات الموجودة في المساحة المترية جيدًا ، ولكن في مساحة التضمين ، يمكن أن تكون نقاط الفئات المختلفة قريبة من بعضها البعض ...

هذا يخلق الأخطاء المحتملة خلال التعميم ، كما اختلاف بسيط في البيانات المصدر قد يغير نتيجة التصنيف. نود حقا أن تكون النقاط أكثر إحكاما. لهذا ، يتم استخدام تقنيات التعلم المتري المختلفة. على سبيل المثال ، فقدان المركز ، فكرته بسيطة للغاية: نحن ببساطة نجمع النقاط معًا في مركز التعلم لكل فصل ، والذي يصبح في النهاية أكثر إحكاما.
مبرمجة فقدان المركز حرفيا في 10 خطوط في بيثون ، وهو يعمل بسرعة كبيرة ، والأهم من ذلك ، فإنه يحسن جودة التصنيف ، لأنه الاكتناز يؤدي إلى تعميم أفضل القدرة.
softmax الزاوي
جربنا العديد من طرق التعلم المترية المختلفة وتوصلنا إلى استنتاج مفاده أن Angular Softmax تنتج أفضل النتائج. من بين مجتمع البحث ، يعتبر أيضًا أحدث ما توصلت إليه التكنولوجيا.
لنلقِ نظرة على مثال للتعرف على الوجوه. هنا لدينا شخصان. إذا كنت تستخدم Softmax القياسي ، فسيتم رسم طائرة تقسيم بينهما - استنادًا إلى متجهين للوزن. إذا قمنا بتضمين المعيار 1 ، فستقع النقاط على الدائرة ، أي على الكرة في حالة ن الأبعاد (الصورة على اليمين).
ثم يمكنك أن ترى أن الزاوية بينهما مسؤولة بالفعل عن فصل الطبقات ، ويمكن تحسينها. ولكن هذا ليس كافيا. إذا واصلنا تحسين الزاوية ، فلن تتغير المهمة في الواقع ، لأن نحن ببساطة إعادة صياغتها بعبارات أخرى. هدفنا ، على ما أذكر ، هو جعل المجموعات أكثر إحكاما.
من الضروري بطريقة ما طلب زاوية أكبر بين الطبقات - لتعقيد مهمة الشبكة العصبية. على سبيل المثال ، بطريقة تعتقد أن الزاوية بين نقاط فئة ما أكبر من الواقع ، بحيث تحاول ضغطها أكثر وأكثر. يتم تحقيق ذلك عن طريق إدخال المعلمة m ، التي تتحكم في الفرق في جيب التمام للزوايا.
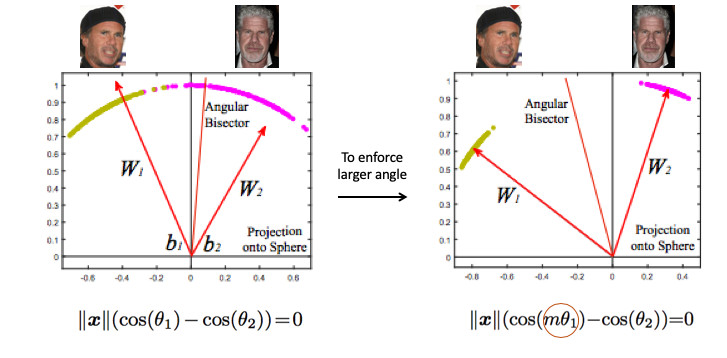
هناك عدة خيارات لـ Softular Softular. انهم جميعا يلعبون مع حقيقة أن تتضاعف م هذه الزاوية أو تضيف ، أو تتضاعف وتضاف. للدولة من بين الفن - ArcFace.
في الواقع ، هذا السهل دمجه في تصنيف خطوط الأنابيب.
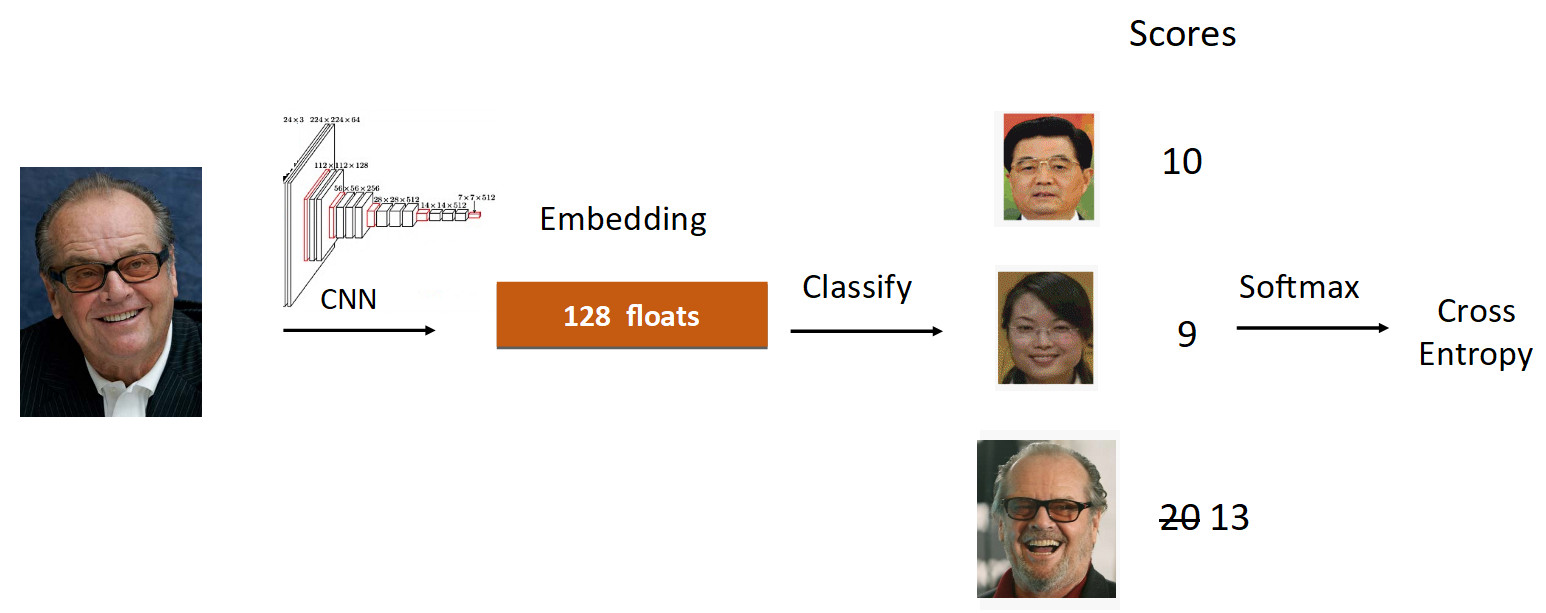
لنلقِ نظرة على مثال جاك نيكولسون. ندير صورته عبر الشبكة في عملية التعلم. لقد حصلنا على التضمين ، ونعمل عبر الطبقة الخطية للتصنيف ونحصل على درجات في المخرجات ، والتي تعكس درجة الانتماء إلى الفصل. في هذه الحالة ، تبلغ سرعة صورة نيكولسون 20 ، وهي الأكبر. علاوة على ذلك ، وفقًا للمعادلة من ArcFace ، نقوم بتقليل السرعة من 20 إلى 13 (يتم ذلك فقط لفئة الأساس الأرضي) ، مما يعقد المهمة على الشبكة العصبية. ثم نفعل كل شيء كالمعتاد: Softmax + Cross Entropy.
في المجموع ، يتم استبدال الطبقة الخطية المعتادة بطبقة ArcFace ، التي لا تتم كتابتها في 10 ، ولكن في 20 سطرًا ، ولكنها تعطي نتائج ممتازة والحد الأدنى من الحمل للتنفيذ. نتيجة لذلك ، يعد ArcFace أفضل من معظم الأساليب الأخرى لمعظم المهام. إنه يتكامل تمامًا مع مهام التصنيف ويحسن الجودة.
نقل التعلم
الشيء الثاني الذي أردت التحدث عنه هو تعلم النقل - باستخدام شبكة مدربة مسبقًا على مهمة مماثلة لإعادة التدريب على مهمة جديدة. وبالتالي ، يتم نقل المعرفة من مهمة إلى أخرى.
لقد بحثنا في الصور. جوهر المهمة هو إنتاج تلك المتشابهة دلالة من قاعدة البيانات في الصورة (الاستعلام).

من المنطقي أخذ شبكة درست بالفعل على عدد كبير من الصور - على مجموعات بيانات ImageNet أو OpenImages ، حيث يوجد ملايين الصور ، وتدريب على بياناتنا.
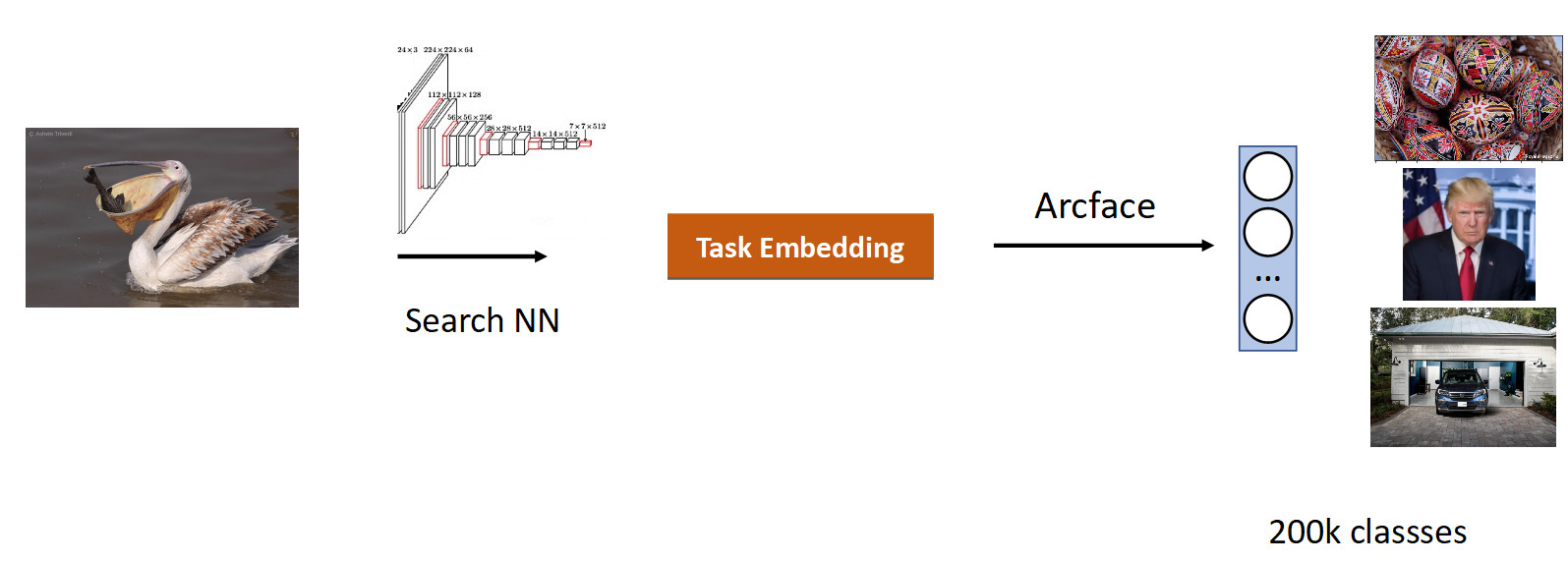
قمنا بجمع البيانات لهذه المهمة بناءً على تشابه الصور ونقرات المستخدم وحصلنا على فصول 200 ألف. بعد التدريب مع ArFace ، حصلنا على النتيجة التالية.

في الصورة أعلاه ، نرى أنه بالنسبة للبجع المطلوب ، دخلت العصافير أيضًا في هذه المشكلة. أي لقد تبين أن التضمين صحيح تمامًا - إنه طائر ، ولكنه غير مخلص من الناحية العرقية. الشيء الأكثر إزعاجًا هو أن النموذج الأصلي الذي أعيد تدريبنا على معرفته بهذه الفئات وميزها تمامًا. نرى هنا التأثير المشترك لجميع الشبكات العصبية ، التي تسمى النسيان الكارثي. أي أثناء إعادة التدريب ، تنسى الشبكة المهمة السابقة ، وأحيانًا بشكل كامل. هذا هو بالضبط ما يمنع في هذه المهمة لتحقيق جودة أفضل.
تقطير المعرفة
يتم التعامل مع ذلك باستخدام تقنية تسمى تقطير المعرفة ، عندما تقوم إحدى الشبكات بتدريس شبكة أخرى و "تنقل معارفها إليها". كيف يبدو (خط أنابيب التدريب الكامل في الصورة أدناه).
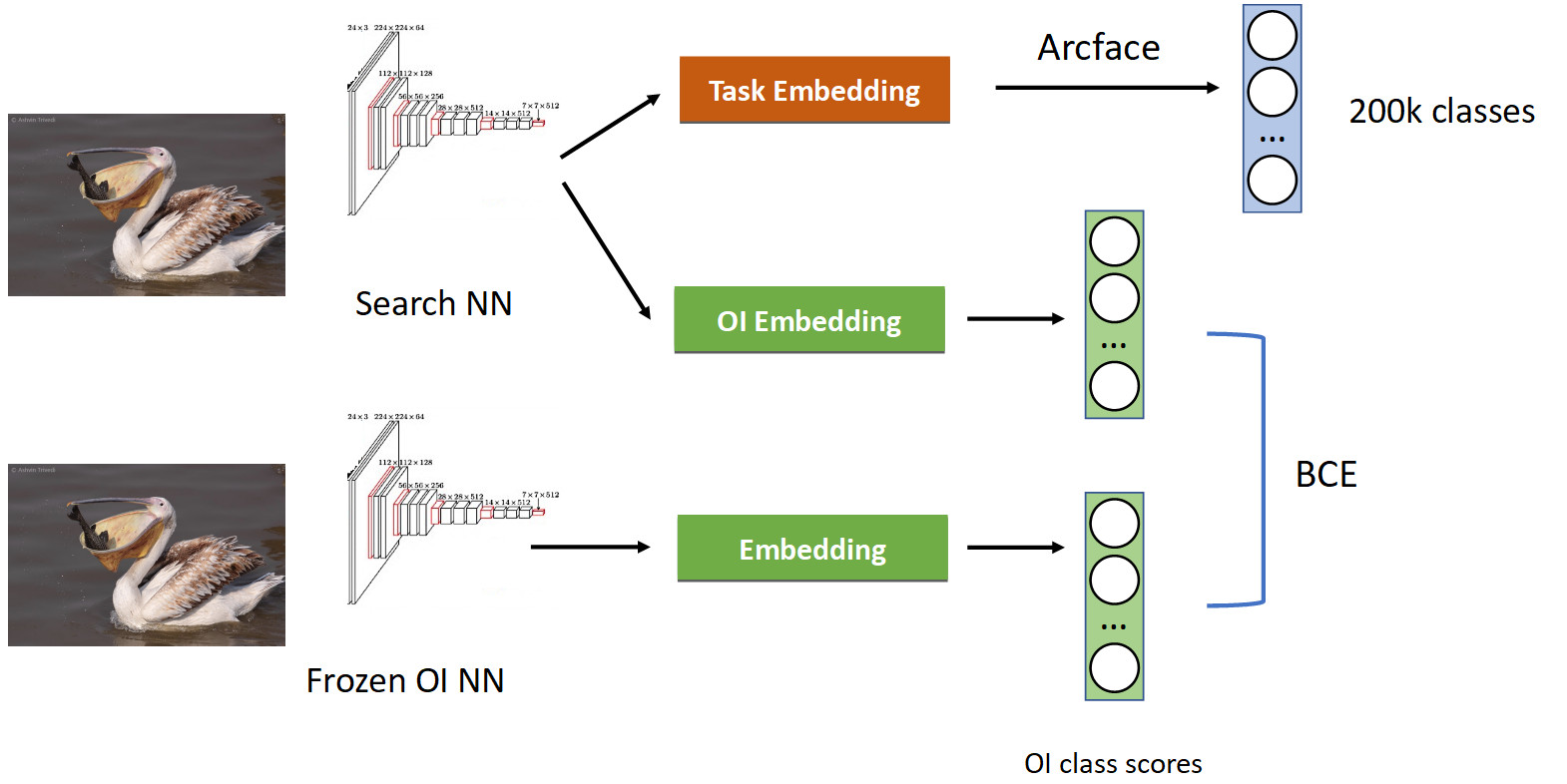
لدينا بالفعل خط أنابيب تصنيف مألوف مع Arcface. أذكر أن لدينا شبكة نتظاهر بها. قمنا بتجميدها وحسابها ببساطة في جميع الصور التي نتعلم بها شبكتنا ، ونحصل على دروس OpenImages بسرعة: البجع والعصافير والسيارات والأشخاص وما إلى ذلك ... نحن نتنقل من الشبكة العصبية المدربة الأصلية ونتعلم التضمين الآخر للفصول OpenImages ، والتي تنتج علامات مماثلة. مع BCE ، نجعل الشبكة تنتج توزيعًا مشابهًا لهذه الدرجات. وهكذا ، من ناحية ، نحن نتعلم مهمة جديدة (في الجزء العلوي من الصورة) ، لكننا أيضًا نجعل الشبكة لا تنسى جذورها (في الأسفل) - تذكر الطبقات التي كانت تعرفها. إذا قمت بموازنة التدرجات بشكل صحيح بنسبة 50/50 الشرطية ، فسيؤدي ذلك إلى ترك جميع البجع في الأعلى وطرد جميع العصافير من هناك.

عندما طبقنا هذا ، حصلنا على نسبة مئوية كاملة في mAP. هذا كثير جدا.
لذلك إذا نسي شبكتك المهمة السابقة ، فقم بالتعامل مع استخدام تقطير المعرفة - وهذا يعمل بشكل جيد.
رؤساء اضافية
الفكرة الأساسية بسيطة للغاية. مرة أخرى على مثال التعرف على الوجه. لدينا مجموعة من الأشخاص في مجموعة البيانات. ولكن أيضًا غالبًا ما توجد في مجموعات البيانات خصائص أخرى للوجه. على سبيل المثال ، كم عمر ولون العين وما إلى ذلك كل هذا يمكن أن تضاف كإضافة واحدة أخرى. إشارة: تعليم رؤساء الفردية للتنبؤ بهذه البيانات. وبالتالي ، تتلقى شبكتنا إشارة أكثر تنوعًا ، ونتيجة لذلك ، قد يكون من الأفضل تعلم المهمة الرئيسية.
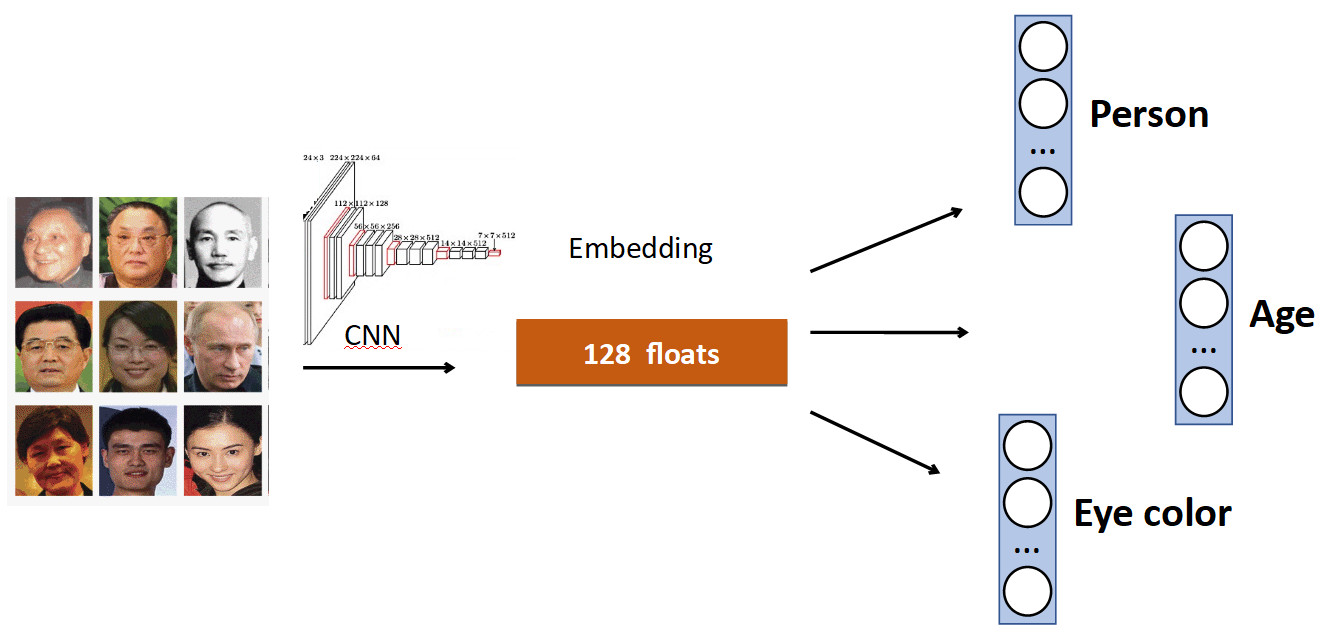
مثال آخر: كشف الصف.

غالبًا في مجموعات البيانات التي تحتوي على أشخاص ، بالإضافة إلى الجسم ، هناك علامة منفصلة لموضع الرأس ، والتي من الواضح أنه يمكن استخدامها. لذلك ، أضفنا إلى الشبكة التنبؤ بصندوق إحاطة الشخص والتنبؤ بصندوق إحاطة الرأس ، وحصلنا على زيادة بنسبة 0.5٪ في الدقة (mAP) ، وهي نسبة مناسبة. والأهم من ذلك - خالية من حيث الأداء ، ل عند الإنتاج ، يتم فصل الرأس الإضافي.

OCR
وهناك حالة أكثر تعقيدا ومثيرة للاهتمام هو التعرف الضوئي على الحروف ، المذكورة أعلاه بالفعل. خط الأنابيب القياسي هو من هذا القبيل.
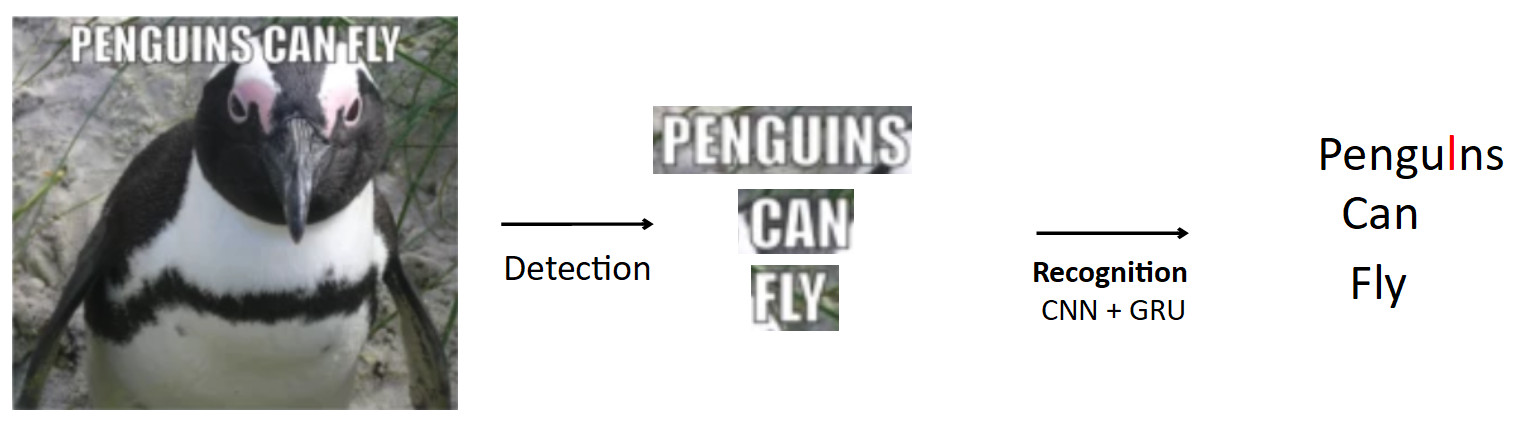
فليكن هناك ملصق به بطريق ، النص مكتوب عليه. باستخدام نموذج الكشف ، نسلط الضوء على هذا النص. علاوة على ذلك ، نقوم بإطعام هذا النص إلى إدخال نموذج التعرف ، والذي ينتج النص المعترف به. دعنا نقول أن شبكتنا خاطئة وبدلاً من كلمة "أنا" في كلمة "طيور البطريق" ، تتوقع "l". هذه في الواقع مشكلة شائعة جدًا في التعرف الضوئي على الحروف (OCR) عندما تربك الشبكة الشخصيات المتشابهة. والسؤال هو كيفية تجنب هذا - ترجمة البطريق إلى طيور البطريق؟ عندما ينظر الشخص إلى هذا المثال ، فمن الواضح له أن هذا خطأ ، لأنه لديه معرفة بنية اللغة. لذلك ، يجب تضمين المعرفة حول توزيع الأحرف والكلمات في اللغة في النموذج.
استخدمنا شيئًا يسمى BPE (تشفير البايت) لهذا الغرض. هذه خوارزمية ضغط تم اختراعها بشكل عام في التسعينيات ليس للتعلم الآلي ، ولكنها الآن شائعة الاستخدام للغاية وتستخدم في التعلم العميق. معنى الخوارزمية هو أن الاستجابات التي تحدث بشكل متكرر في النص يتم استبدالها بأحرف جديدة. لنفترض أن لدينا سلسلة "aaabdaaabac" ، ونحن نريد الحصول على BPE لذلك. نجد أن زوج الحروف "aa" هو الأكثر شيوعًا في كلمتنا. نستبدلها بشخصية جديدة "Z" ، نحصل على السلسلة "ZabdZabac". نكرر التكرار: نرى أن أب هو الأكثر تكرارًا ، استبدلها ب "Y" ، ونحصل على السلسلة "ZYdZYac". الآن "ZY" هي الأكثر تكرارًا ، نستبدلها بـ "X" ، ونحصل على "XdXac". وبالتالي ، نقوم بتشفير بعض التبعيات الإحصائية في توزيع النص. إذا صادفنا كلمة توجد فيها تتابعات "غريبة" للغاية (نادرة بالنسبة لهيئة التدريس) ، فإن هذه الكلمة تكون مشبوهة.
aaabdaaabac
ZabdZabac Z=aa
ZY d ZY ac Y=ab
X d X ac X=ZYكيف يناسب الجميع في الاعتراف.
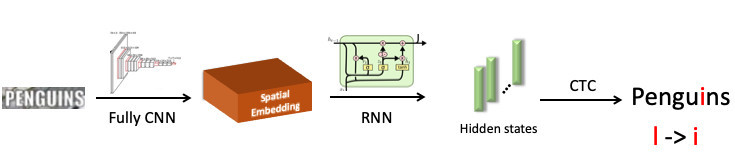
لقد سلطنا الضوء على كلمة "البطريق" ، وأرسلناها إلى الشبكة العصبية التلافيفية ، والتي أنتجت التضمين المكاني (متجه بطول ثابت ، على سبيل المثال 512). يقوم هذا المتجه بترميز معلومات الرمز المكاني. بعد ذلك ، نستخدم شبكة متكررة (UPD: في الواقع ، نستخدم بالفعل نموذج Transformer) ، فهو يقدم بعض الحالات المخفية (الأعمدة الخضراء) ، حيث يتم توزيع توزيع الاحتمالات - حيث يتم تصوير الرمز وفقًا للموقف في موضع معين. بعد ذلك ، باستخدام CTC-Loss ، نقوم بإرخاء هذه الحالات والحصول على تنبؤنا للكلمة بأكملها ، ولكن مع وجود خطأ: L بدلاً من i.
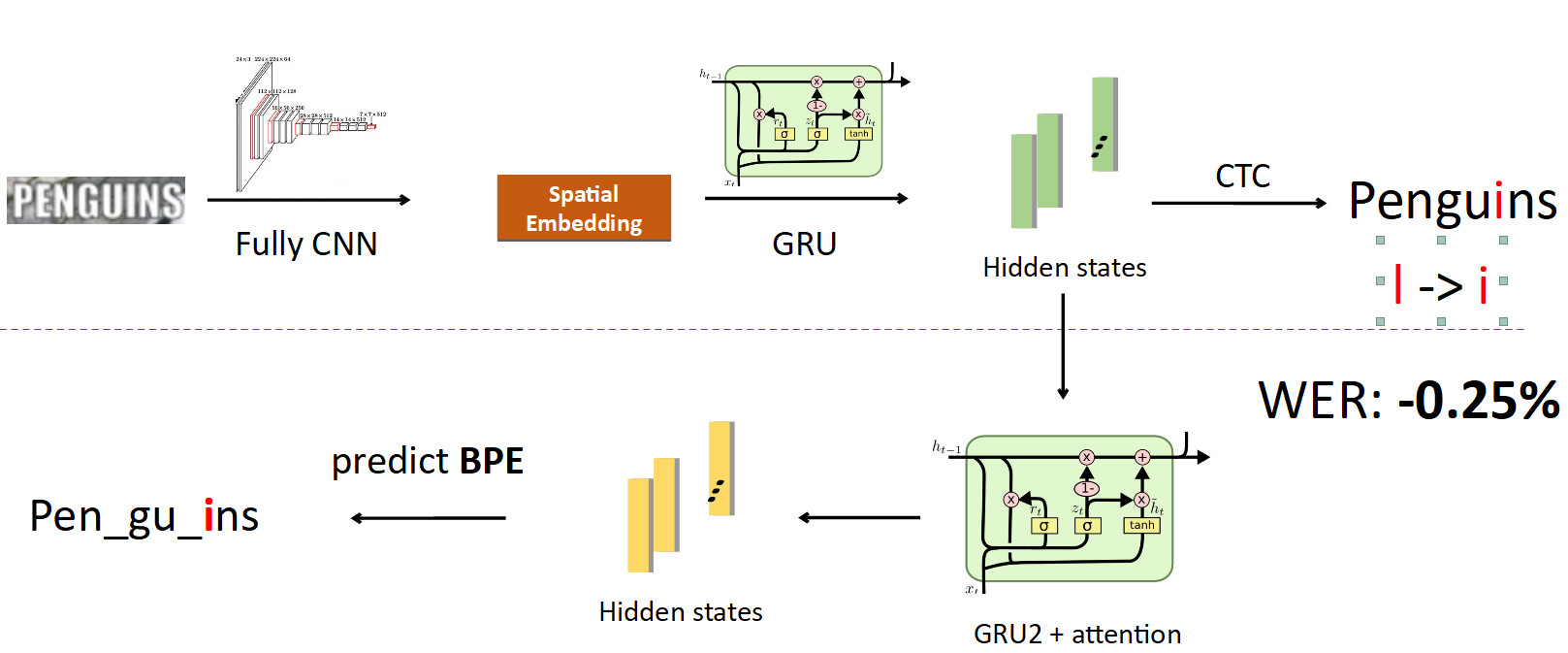
الآن دمج BPE في خط الأنابيب. نريد الابتعاد عن التنبؤ بأحرف فردية للكلمات ، لذلك نتفرع من الحالات التي يتم فيها خيط المعلومات المتعلقة بالأحرف ووضع شبكة عودية أخرى عليها ؛ إنها تتوقع BPE. في حالة الخطأ الموضح أعلاه ، يتم الحصول على 3 BPEs: "peng" ، "ul" ، "ns". هذا يختلف اختلافًا كبيرًا عن التسلسل الصحيح لكلمة البطاريق ، أي pen ، gu ، ins. إذا نظرت إلى هذا من وجهة نظر التدريب النموذجي ، إذن ، في تنبؤ حرفي بكلمة ، ارتكبت الشبكة خطأ في حرف واحد فقط من أصل ثمانية (خطأ بنسبة 12.5٪) ؛ من حيث BPE ، كانت مخطئة بنسبة 100 ٪ في التنبؤ بجميع BPEs 3 بشكل غير صحيح. هذه إشارة أكبر بكثير للشبكة تفيد بوجود خطأ ما وتحتاج إلى إصلاح سلوكك. عندما قمنا بتنفيذ ذلك ، كنا قادرين على إصلاح الأخطاء من هذا النوع وخفض معدل أخطاء الكلمات بنسبة 0.25 ٪ - وهذا كثير. تتم إزالة هذا الرأس الإضافي عند الاستدلال ، وهو يؤدي دوره في التدريب.
FP16
آخر شيء أردت قوله حول التدريب هو FP16. لقد حدث ذلك تاريخيًا أن تم تدريب الشبكات على وحدة معالجة الرسومات في دقة الوحدة ، أي FP32. ولكن هذا لا لزوم له ، وخاصة بالنسبة للاستدلال ، حيث نصف دقة (FP16) يكفي دون فقدان الجودة. ومع ذلك ، هذا ليس هو الحال مع التدريب.
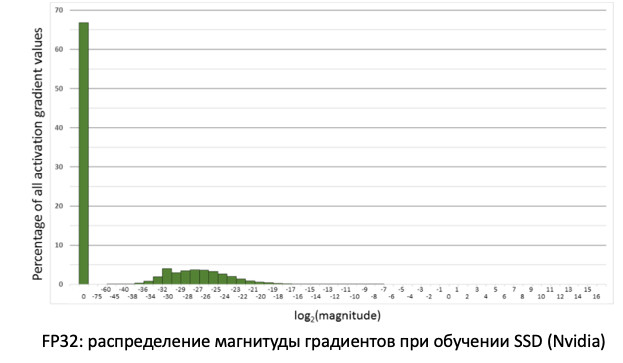
إذا نظرنا إلى توزيع التدرجات ، المعلومات التي تعمل على تحديث أوزاننا عند نشر الأخطاء ، فسوف نرى أن هناك ذروة هائلة عند الصفر. وبشكل عام ، هناك الكثير من القيم بالقرب من الصفر. إذا قمنا فقط بنقل جميع الأوزان إلى FP16 ، اتضح أننا قطعنا الجانب الأيسر في منطقة الصفر (من الخط الأحمر).
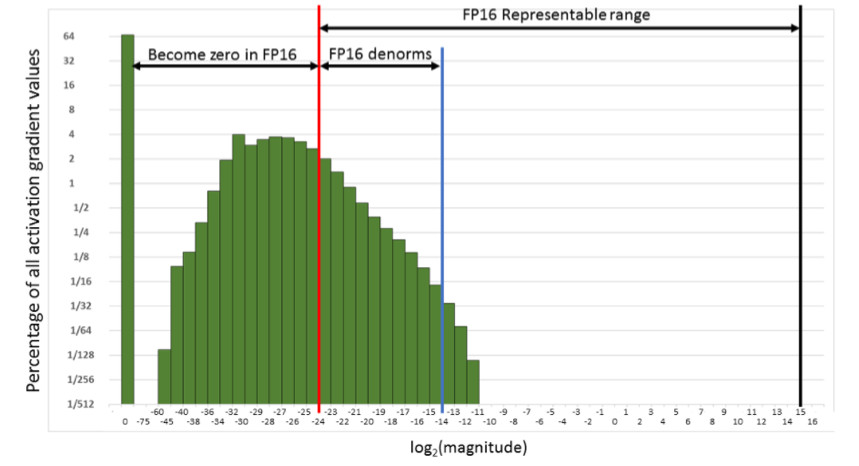
وهذا يعني أننا سنعيد ضبط عدد كبير جدًا من التدرجات. والجزء الأيمن ، في نطاق العمل FP16 ، لا يستخدم على الإطلاق. نتيجة لذلك ، إذا قمت بتدريب الجبهة على FP16 ، فمن المحتمل أن تتفرق العملية (الرسم البياني الرمادي في الصورة أدناه).
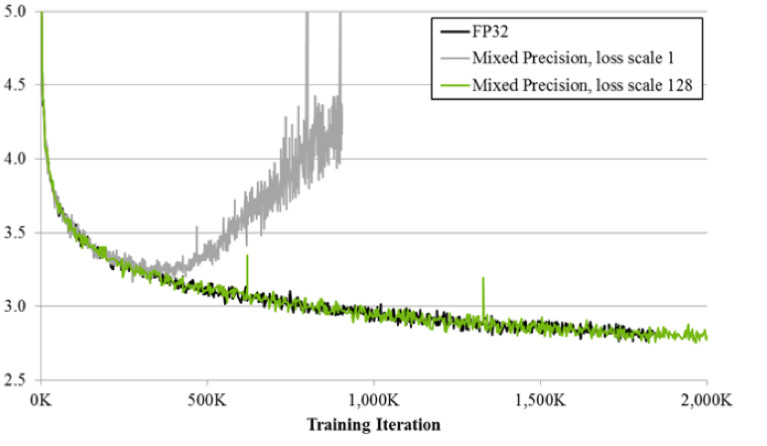
إذا كنت تدرب باستخدام تقنية الدقة المختلطة ، فإن النتيجة تكون متطابقة تقريبًا مع FP32. الدقة المختلطة تنفذ حيلتين.
أولاً: نقوم ببساطة بضرب الخسارة بواسطة ثابت ، على سبيل المثال ، 128. وبالتالي ، فإننا نقيس كل التدرجات ، وننقل قيمها من الصفر إلى نطاق عمل FP16. ثانياً: نقوم بتخزين النسخة الرئيسية لرصيد FP32 ، والذي يستخدم فقط للتحديث ، وفي عمليات حساب شبكات المرور الأمامية والخلفية ، يتم استخدام FP16 فقط.
نحن نستخدم Pytorch لتدريب الشبكات. صنعت NVIDIA مجموعة خاصة لها باستخدام ما يسمى APEX ، والذي ينفذ المنطق الموصوف أعلاه. لديه وضعين. الأول هو الدقة التلقائي المختلط. انظر الكود أدناه لمعرفة مدى سهولة استخدامه.

حرفيًا يتم إضافة سطرين إلى رمز التدريب الذي يلف الخسارة وإجراء التهيئة للنموذج والمحسّن. ماذا تفعل AMP؟ انه القرد patch'it جميع الوظائف. ما الذي يحدث بالضبط؟ على سبيل المثال ، يرى أن هناك وظيفة الالتواء ، وتتلقى ربحًا من FP16. ثم يستبدلها بآخر خاص به ، والذي يتم إرساله أولاً إلى FP16 ، ثم يقوم بعملية الالتواء. لذلك AMP يفعل لجميع الوظائف التي يمكن استخدامها على الشبكة. بالنسبة للبعض ، لا. لن يكون هناك تسارع. بالنسبة لمعظم المهام ، هذه الطريقة مناسبة.
الخيار الثاني: محسن FP16 لمحبي السيطرة الكاملة. مناسب إذا كنت تريد تحديد الطبقات التي ستكون في FP16 وأيها في FP32. ولكن لديها عدد من القيود والصعوبات. إنها لا تبدأ بضربة جزاء (على الأقل كان علينا أن نعرقها لبدء ذلك). أيضا FP_optimizer يعمل فقط مع آدم ، وحتى بعد ذلك فقط مع آدم ، الذي يوجد في APEX (نعم ، لديهم آدم خاص بهم في المستودع ، الذي له واجهة مختلفة تماما عن paytorchev).
لقد أجرينا مقارنة عند التعلم على بطاقات Tesla T4.
في Inference ، لدينا التسارع المتوقع مرتين. في التدريب ، نرى أن إطار Apex يوفر تسارع 20٪ مع FP16 بسيط نسبيًا. نتيجة لذلك ، نحصل على تمرين أسرع مرتين ويستهلك ذاكرة أقل مرتين ، ولا تعاني جودة التدريب بأي شكل من الأشكال. خدمات مجانية.
استدلال
لأن بما أننا نستخدم PyTorch ، فإن السؤال المطروح هو كيفية نشره في الإنتاج بشكل عاجل.
هناك 3 خيارات لكيفية القيام بذلك (وجميعهم استخدمنا (ق).
- ONNX -> Caffe2
- ONNX -> TensorRT
- ومؤخرا Pytorch C ++
دعونا ننظر في كل منهم.
ONNX و Caffe2
ظهر ONNX منذ 1.5 عام. هذا إطار خاص لتحويل النماذج بين الأطر المختلفة. و Caffe2 هو إطار مجاور لـ Pytorch ، وكلاهما يجري تطويرهما على Facebook. تاريخيا ، Pytorch تتطور أسرع بكثير من Caffe2. يتخلف Caffe2 عن Pytorch في الميزات ، لذلك لا يمكن تحويل كل طراز تدربت عليه في Pytorch إلى Caffe2. في كثير من الأحيان عليك أن تتعلم مع طبقات أخرى. على سبيل المثال ، في Caffe2 لا توجد عملية قياسية مثل الاختزال مع أقرب استيفاء جار. ونتيجةً لذلك ، توصلنا إلى استنتاج مفاده أنه بالنسبة لكل نموذج ، قمنا بإحضار صورة مرساة خاصة ، نعلق فيها إصدارات إطار العمل بالأظافر لتجنب التناقضات أثناء تحديثاتها المستقبلية ، بحيث عندما يتم تحديث أحد الإصدارات مرة أخرى ، فإننا لا نضيع الوقت في توافقها . كل هذا ليس مريحًا جدًا ويطيل عملية النشر.
موتر تينور
يوجد أيضًا Tensor RT ، إطار عمل NVIDIA يعمل على تحسين بنية الشبكة لتسريع الاستدلال. أجرينا قياساتنا (على خريطة Tesla T4).
إذا نظرت إلى الرسوم البيانية ، يمكنك أن ترى أن الانتقال من FP32 إلى FP16 يمنح تسارعًا 2x على Pytorch ، بينما يعطي TensorRT في نفس الوقت 4 ×. فرق كبير جدا. لقد قمنا باختباره على Tesla T4 ، الذي يحتوي على حبات tensor التي تستخدم حسابات FP16 بشكل جيد للغاية ، وهو أمر واضح بشكل ممتاز في TensorRT. لذلك ، إذا كان هناك طراز محمّل بدرجة عالية يعمل على عشرات بطاقات الرسومات ، فهناك جميع المحفزات لتجربة Tensor RT.
ومع ذلك ، عند العمل مع TensorRT ، هناك ألم أكثر مما هو عليه في Caffe2: فالطبقات أقل دعمًا فيه. لسوء الحظ ، في كل مرة نستخدم فيها هذا الإطار ، يتعين علينا أن نعاني قليلاً لتحويل النموذج. لكن بالنسبة للطرز المحملة بكثافة ، عليك القيام بذلك. ؛) ألاحظ أنه على الخرائط بدون حبات التينسور ، لم تلاحظ هذه الزيادة الهائلة.
Pytorch C ++
وآخر واحد هو Pytorch C ++. منذ ستة أشهر ، أدرك مطورو Pytorch ألم الأشخاص الذين يستخدمون إطار عملهم
وأصدروا البرنامج التعليمي TorchScript ، والذي يسمح لك بتتبع وتسلسل نموذج بيثون في رسم بياني ثابت دون إيماءات غير ضرورية (JIT). تم إصداره في ديسمبر 2018 ، بدأنا على الفور استخدامه ، واشتعلت على الفور بعض الأخطاء في الأداء وانتظرنا عدة أشهر للتثبيت من
Chintala . لكنها الآن تقنية مستقرة إلى حد ما ، ونحن نستخدمها بنشاط لجميع الموديلات. الشيء الوحيد هو عدم وجود وثائق ، والتي يتم استكمالها بنشاط. بالطبع ، يمكنك دائمًا الاطلاع على ملفات * .h ، ولكن بالنسبة للأشخاص الذين لا يعرفون الإيجابيات ، فإن الأمر صعب. ولكن بعد ذلك هناك عمل متطابق مع بيثون. في C ++ ، يتم تشغيل j-code على مترجم بيثون الحد الأدنى ، والذي يضمن عمليا هوية C ++ مع بيثون.
النتائج
- بيان المشكلة هو السوبر المهم. يجب عليك التواصل مع مديري المنتجات على البيانات. قبل البدء في تنفيذ المهمة ، من المستحسن أن يكون لديك مجموعة اختبار جاهزة نقيس عليها المقاييس النهائية قبل مرحلة التنفيذ.
- نقوم بتنظيف البيانات بأنفسنا بمساعدة التجميع. نحصل على النموذج على البيانات المصدر ، نقوم بتنظيف البيانات باستخدام تجميع CLink ، ونكرر العملية حتى التقارب.
- التعلم المتري: حتى التصنيف يساعد. أحدث التقنيات - ArcFace ، التي يسهل دمجها في عملية التعلم.
- إذا قمت بنقل التعلم من شبكة مُدرَّبة مسبقًا ، حتى لا تنسى المهمة القديمة ، فاستخدم تقطير المعرفة.
- من المفيد أيضًا استخدام العديد من رؤوس الشبكات التي ستستخدم إشارات مختلفة من البيانات لتحسين المهمة الرئيسية.
- بالنسبة إلى FP16 ، تحتاج إلى استخدام مجموعات Apex من NVIDIA ، Pytorch.
- وعند الاستدلال ، من المريح استخدام Pytorch C ++.