تقريبا. العابرة. : مؤلف هذه المادة هو Cindy Sridharan ، وهو مهندس من imgix يشارك في تطوير واجهات برمجة التطبيقات ، ولا سيما اختبار الخدمات المصغرة. في هذه المقالة ، تشاركها رؤيتها التفصيلية للمشاكل الفعلية في مجال التتبع الموزع ، حيث ، في رأيها ، هناك نقص في الأدوات الفعالة حقا لحل المشاكل الملحة. [يتم استعارة الرسم التوضيحي من مادة أخرى حول التتبع الموزع.]
[يتم استعارة الرسم التوضيحي من مادة أخرى حول التتبع الموزع.]من المعتقد أنه من الصعب تنفيذ
التتبع الموزع ، والعائد عليه
مشكوك فيه في أحسن الأحوال . يتم تفسير "مشكلة" التتبع بعدة أسباب ، وغالبًا ما تشير إلى تعقيد إعداد كل مكون من مكونات النظام لإرسال الرؤوس المقابلة مع كل طلب. على الرغم من حدوث هذه المشكلة ، إلا أنه لا يمكن تسميتها على الإطلاق. بالمناسبة ، لا يفسر لماذا لا يحب المطورون حقًا التتبع (حتى يعمل بالفعل).
إن الصعوبة الرئيسية في التتبع الموزع هي عدم جمع البيانات ، وليس توحيد التنسيقات الخاصة بتوزيع النتائج وعرضها ، وعدم تحديد موعد ومكان أخذ العينات. لا أحاول إطلاقًا تقديم "مشاكل الهضم" هذه على أنها
تافهة - في الواقع ، هناك تحديات تقنية كبيرة (وإذا كنا ننظر حقًا إلى
المعايير والبروتوكولات مفتوحة المصدر) يجب التغلب عليها حتى يمكن اعتبار هذه المشكلات حلها.
ومع ذلك ، إذا كنت تتخيل أنه تم حل جميع هذه المشكلات ، فمن المحتمل ألا يتغير أي شيء بشكل كبير فيما يتعلق
بتجربة المستخدم النهائي . قد لا يزال التتبع غير عملي في أكثر سيناريوهات تصحيح الأخطاء شيوعًا - حتى بعد نشره.
هذا أثر مختلف
يشمل التتبع الموزع عدة مكونات مختلفة:
- تجهيز التطبيقات والوسيطة مع الضوابط ؛
- انتقال السياق الموزع
- جمع التتبع ؛
- تخزين الآثار ؛
- الاستخراج والتصور.
الكثير من الحديث عن التتبع الموزع يأتي إلى اعتباره نوعًا من العمليات الأحادية الغرض منه هو المساعدة في التشخيص الكامل للنظام. هذا يرجع إلى حد كبير إلى الطريقة التي تشكل مفهوم تتبع الموزعة. في منشور بالمدونة تم إنشاؤه عند فتح مصادر Zipkin ، ذكر
أنه [Zipkin] يجعل Twitter أسرع . كما تم الترويج للعروض التجارية الأولى للبحث عن المفقودين
كأدوات APM .
تقريبا. العابرة. : من أجل فهم النص الإضافي بشكل أفضل ، نحدد مصطلحين أساسيين وفقًا لتوثيق مشروع OpenTracing :- سبان - العنصر الأساسي للتتبع الموزعة. إنه وصف لسير عمل معين (على سبيل المثال ، استعلام قاعدة بيانات) مع الاسم وأوقات البدء والنهاية والعلامات والسجلات والسياق.
- عادةً ما تحتوي المسافات على روابط إلى مسافات أخرى ، مما يسمح لك بدمج العديد من المسافات في تتبع - تصور لحياة الطلب أثناء تحركه عبر نظام موزع.
تتبع يحتوي على بيانات قيمة بشكل لا يصدق التي يمكن أن تساعد في مهام مثل: الاختبار في الإنتاج ، وإجراء اختبارات التعافي من الكوارث ، والاختبار مع إدخال الأخطاء ، الخ في الواقع ، تستخدم بعض الشركات بالفعل التتبع لهذه الأغراض. بادئ ذي بدء ،
نقل السياق العالمي له استخدامات أخرى إلى جانب نقل المسافات إلى نظام التخزين:
- على سبيل المثال ، يستخدم Uber نتائج التتبع للتمييز بين حركة مرور الاختبار وحركة الإنتاج.
- يستخدم Facebook بيانات التتبع لتحليل المسار الحرج ولتبديل حركة المرور خلال اختبارات التعافي من الكوارث العادية.
- تستخدم الشبكة الاجتماعية أيضًا دفاتر Jupyter ، والتي تسمح للمطورين بتنفيذ استعلامات تعسفية على نتائج التتبع.
- يستخدم أتباع الحقن الناشئ عن الفشل ( LDFI) آثارًا موزعة لاختبار الأخطاء.
لا يرتبط أي من الخيارات المذكورة أعلاه تمامًا بسيناريو
تصحيح الأخطاء ، حيث يحاول المهندس خلاله حل المشكلة من خلال النظر إلى التتبع.
عندما يتعلق الأمر بسيناريو التصحيح ، يظل مخطط
التتبع في الواجهة الأساسية (على الرغم من أن البعض يسمونه أيضًا
"مخطط جانت" أو
"الرسم التخطيطي المتتالي" ). بواسطة
traceview ، أعني جميع
المسافات وبيانات التعريف المرتبطة التي تشكل معًا التتبع. يوفر كل نظام تتبع مفتوح المصدر ، بالإضافة إلى كل حل تتبع تجاري ، واجهة مستخدم قائمة على التتبع
لتخيل بيانات التتبع وتفصيلها وتصفيتها.
المشكلة في جميع أنظمة التتبع التي كنت على دراية بها في الوقت الحالي هي أن
التصور النهائي
(traceview) يعكس بشكل كامل ميزات عملية إنشاء التتبع. حتى عندما يتم تقديم تصورات بديلة: خرائط الكثافة (خريطة الحرارة) ، طبولوجيا الخدمة ، رسوم بيانية
زمنية - في النهاية لا تزال تأتي
لتتبع وجهة نظر .
في الماضي ،
اشتكت من أن معظم "الابتكار" في التتبع فيما يتعلق بـ UI / UX يبدو
أنه يقتصر على
تضمين بيانات وصفية إضافية في التتبع ، أو تضمين معلومات ذات
أصل عالي فيها ، أو توفير القدرة على الانتقال إلى نطاقات محددة أو تنفيذ الاستعلامات
بين وداخل التتبع . في هذه الحالة ، تظل
طريقة التتبع هي الوسيلة الرئيسية للتصور. وطالما استمرت هذه الحالة ، سيتبع التتبع الموزع (في أحسن الأحوال) المركز الرابع كأداة تصحيح ، تليها المقاييس والسجلات وآثار مكدس ، وفي أسوأ الأحوال سيصبح مضيعة للمال والوقت.
مشكلة مع traceview
الغرض من
traceview هو تقديم صورة كاملة عن حركة طلب فردي عبر جميع مكونات النظام الموزع الذي يتعلق به. تسمح لك بعض أنظمة التتبع الأكثر تقدمًا بالانتقال إلى مسافات فردية وعرض تفاصيل الوقت
ضمن عملية واحدة (عندما يكون للمسافات حدود وظيفية).
الفرضية الأساسية لهندسة الخدمات المصغرة هي فكرة أن الهيكل التنظيمي ينمو مع احتياجات الشركة. يجادل مؤيدو الخدمات المصغرة بأن توزيع مهام العمل المختلفة عبر خدمات منفصلة يتيح لفرق التطوير الصغيرة المستقلة ذاتياً التحكم في دورة حياة هذه الخدمات بأكملها ، مما يتيح لهم إنشاء هذه الخدمات واختبارها ونشرها بشكل مستقل. ومع ذلك ، فإن عيب هذا التوزيع هو فقدان المعلومات حول كيفية تفاعل كل خدمة مع الآخرين. في مثل هذه الظروف ، تدعي تتبعات التوزيع أنها أداة لا غنى عنها
لتصحيح التفاعلات المعقدة بين الخدمات.
إذا كان لديك
نظام موزّع معقد بشكل مذهل حقًا ، فلن يتمكن أحد من وضع صورته
الكاملة في الاعتبار. في الواقع ، فإن تطوير أداة قائمة على افتراض أنه من الممكن بشكل عام هو نوع من المضاد (نهج غير فعال وغير مثمر). من الناحية المثالية ، يتطلب تصحيح الأخطاء أداة للمساعدة في
تضييق نطاق البحث بحيث يمكن للمهندسين التركيز على مجموعة فرعية من الأبعاد (الخدمات / المستخدمين / المضيفين ، إلخ) ذات الصلة بالسيناريو المعني. عند تحديد سبب الفشل ، لا يُطلب من المهندسين فهم ما حدث في
جميع الخدمات في وقت واحد ، لأن هذا الشرط من شأنه أن يتعارض مع فكرة بنية الخدمة المصغرة.
ومع ذلك ، traceview هو ذلك
تماما . نعم ، تقدم بعض أنظمة التتبع عروض تتبع مضغوطة عندما يكون عدد المسافات في التتبع كبيرًا بحيث لا يمكن عرضها في تصوّر واحد. ومع ذلك ، نظرًا للكمية الكبيرة من المعلومات الموجودة حتى في مثل هذا التصور المقطوع ، لا يزال المهندسون
مجبرين على "غربلة" ذلك ، وتضييق نطاق الاختيار يدويًا على مجموعة من مصادر الخدمة. للأسف ، في هذا المجال تكون الآلات أسرع بكثير من البشر ، وأقل عرضة للأخطاء ، ويمكن تكرار نتائجها.
سبب آخر أعتقد أن طريقة التتبع غير صحيحة لأنه غير مناسب لتصحيح الأخطاء المفترض. في جوهرها ، التصحيح هو عملية
تكرارية تبدأ بفرضية ، تليها التحقق من الملاحظات والحقائق المختلفة الواردة من النظام باستخدام متجهات مختلفة ، والاستنتاجات / التعميمات ، وتقييم إضافي لحقيقة الفرضية.
إن القدرة
على اختبار الفرضيات
بسرعة وبتكلفة منخفضة وتحسين النموذج العقلي وفقًا لذلك هي
حجر الزاوية في تصحيح الأخطاء. يجب أن تكون أي أداة لتصحيح الأخطاء
تفاعلية وتضييق مساحة البحث أو ، في حالة وجود تتبع خاطئ ، تسمح للمستخدم بالعودة والتركيز على منطقة أخرى من النظام. ستقوم الأداة المثالية بذلك بشكل
استباقي ، فتجذب انتباه المستخدم على الفور إلى المناطق التي يحتمل أن تسبب مشاكل.
للأسف ، لا يمكن استدعاء
traceview كأداة واجهة تفاعلية. أفضل ما يمكن أن تتمناه عند استخدامه هو اكتشاف مصدر معين من التأخير المتزايد وعرض جميع أنواع العلامات والسجلات المرتبطة به. هذا لا يساعد المهندس على تحديد
الأنماط في حركة المرور ، مثل تفاصيل توزيع التأخير ، أو اكتشاف الارتباطات بين القياسات المختلفة. يمكن أن يعمل
تحليل التتبع العام على حل بعض هذه المشكلات. في الواقع ،
هناك أمثلة للتحليل الناجح باستخدام التعلم الآلي لتحديد المسافات غير الطبيعية وتحديد مجموعة فرعية من العلامات التي قد تكون مرتبطة بسلوك غير طبيعي. ومع ذلك ، لم أتوصل بعد إلى تصورات مقنعة للاكتشافات التي يتم إجراؤها باستخدام التعلم الآلي أو تحليل البيانات المطبقة على النطاقات التي ستكون مختلفة بشكل كبير عن traceview أو DAG (الرسم البياني الحاد الاتجاهي).
يمتد مستوى منخفض جدا
المشكلة الأساسية في traceview هي أن المسافات هي بدايات منخفضة المستوى للغاية لكل من تحليل الكمون وتحليل السبب الجذري. يشبه تحليل أوامر المعالج الفردية في محاولة للتخلص من استثناء ، مع العلم أن هناك أدوات عالية المستوى مثل backtrace ، والتي هي أكثر ملاءمة للعمل معها.
علاوة على ذلك ، سأحظى بحرية التأكيد على ما يلي: من الناحية المثالية ، لسنا بحاجة إلى
صورة كاملة لما حدث خلال دورة حياة الطلب ، والتي تمثلها الأدوات الحديثة للبحث عن المفقودين. بدلاً من ذلك ، هناك حاجة إلى شكل من أشكال التجريد عالي المستوى ، يحتوي على معلومات حول
الخطأ الذي حدث (على غرار الرجوع إلى الخلف) ، إلى جانب بعض السياق. بدلاً من مراقبة التتبع بأكمله ، أفضل رؤية
جزء منه حيث يحدث شيء مثير أو غير عادي. في الوقت الحالي ، يتم البحث يدويًا: يتلقى المهندس تتبعًا ويقوم بتحليل المسافات بشكل مستقل بحثًا عن شيء مثير للاهتمام. إن النهج الذي يحدق فيه الأشخاص بالامتداد في آثار منفصلة على أمل اكتشاف نشاط مشبوه لا يتم قياسه على الإطلاق (خاصةً عندما يتعين عليهم فهم جميع البيانات التعريفية المشفرة في مسافات مختلفة ، مثل معرف المسافة واسم طريقة RPC ومدة الامتداد 'a ، سجلات ، علامات ، إلخ).
بدائل Traceview
تكون نتائج التتبع مفيدة للغاية عندما يمكن تصورها بطريقة تحصل على فكرة غير تافهة عما يحدث في الأجزاء المترابطة من النظام. إلى أن يتم ذلك ، تظل عملية تصحيح الأخطاء
خاملة إلى حد كبير وتعتمد على قدرة المستخدم على ملاحظة الارتباطات الصحيحة أو التحقق من الأجزاء الصحيحة من النظام أو تجميع أجزاء من الفسيفساء معًا - على عكس
الأداة التي تساعد المستخدم على صياغة هذه الفرضيات.
لست مصممًا مرئيًا أو أخصائي UX ، لكن في القسم التالي أريد أن أشارك بعض الأفكار حول كيفية ظهور هذه المرئيات.
التركيز على خدمات محددة
في بيئة يتم فيها دمج الصناعة حول أفكار
SLO (أهداف مستوى الخدمة) و SLI (مؤشرات مستوى الخدمة) ، يبدو من المنطقي أن تقوم الفرق الفردية أولاً وقبل كل شيء بمراقبة مدى صلة خدماتها بهذه الأهداف. ويترتب على ذلك أن التصور
الموجه نحو الخدمة هو الأنسب لمثل هذه الفرق.
تتبعات ، وخاصة دون أخذ عينات ، هي مخزن للمعلومات حول كل مكون من مكونات النظام الموزع. يمكن تغذية هذه المعلومات إلى معالج صعب يقوم بتوفير النتائج الموجهة
للخدمة للمستخدمين ، والتي يمكن اكتشافها مقدمًا - حتى قبل أن ينظر المستخدم إلى الآثار:
- تأخير مخططات التوزيع فقط للطلبات المميزة بشدة (الطلبات الخارجية) ؛
- تأخير مخططات التوزيع للحالات التي لا تتحقق فيها أهداف خدمة SLO ؛
- العلامات "الأكثر شيوعًا" و "المثيرة للاهتمام" و "الغريبة" في الاستعلامات التي تتكرر غالبًا ؛
- انهيار التأخير في الحالات التي لا تصل فيها تبعيات الخدمة إلى أهداف SLO المحددة ؛
- انهيار التأخير لمختلف الخدمات المصب.
لا تستطيع المقاييس المدمجة الإجابة ببساطة على بعض هذه الأسئلة ، مما يجبر المستخدمين على دراسة المدد بعناية. نتيجة لذلك ، لدينا آلية معادية للغاية للمستخدم.
في هذا الصدد ، فإن السؤال الذي يطرح نفسه: ماذا عن التفاعلات المعقدة بين مختلف الخدمات التي تسيطر عليها فرق مختلفة؟ ألا تعتبر
طريقة التتبع هي الأداة الأنسب لتغطية مثل هذا الموقف؟
قد يهتم مطورو الأجهزة المحمولة وأصحاب خدمات عديمي الجنسية ومالكي خدمات الحالة المدارة (مثل قواعد البيانات) ومالكي المنصة
بعرض آخر للنظام الموزع ؛
traceview هو حل عالمي للغاية لهذه الاحتياجات المختلفة بشكل أساسي. حتى في بنية الخدمة المصغرة المعقدة للغاية ، لا يحتاج أصحاب الخدمة إلى معرفة متعمقة بأكثر من خدمتين أو ثلاث خدمات منبع إلى أعلى وأسفل النهر. في جوهر الأمر ، في معظم السيناريوهات ، يحتاج المستخدمون فقط للإجابة على الأسئلة المتعلقة بمجموعة
محدودة من الخدمات .
هو مثل النظر إلى مجموعة فرعية صغيرة من الخدمات من خلال عدسة مكبرة من أجل دراسة دقيقة. سيسمح ذلك للمستخدم بطرح أسئلة أكثر إلحاحًا فيما يتعلق بالتفاعل المعقد بين هذه الخدمات وتوابعها المباشرة. يشبه هذا التراجع في عالم الخدمات ، حيث يعرف المهندس
ما هو الخطأ ، ولديه أيضًا فكرة عما يحدث في الخدمات المحيطة لفهم
السبب .
الطريقة التي أقوم بتطويرها هي عكس النهج الذي تتبعه من أعلى لأسفل استنادًا إلى traceview ، عندما يبدأ التحليل بالتتبع بأكمله ، ثم ينحدر تدريجياً إلى مسافات فردية. على العكس من ذلك ، فإن النهج التصاعدي يبدأ بتحليل منطقة صغيرة قريبة من السبب المحتمل للحادث ، ثم يتم توسيع مساحة البحث إذا لزم الأمر (مع إمكانية إشراك الفرق الأخرى لتحليل مجموعة واسعة من الخدمات). الطريقة الثانية مناسبة بشكل أفضل لاختبار الفرضيات الأولية بسرعة. بعد الحصول على نتائج محددة ، سيكون من الممكن الانتقال إلى تحليل أكثر تركيزًا وتفصيلا.
بناء الطوبولوجيا
يمكن أن تكون المشاهدات المرتبطة بخدمة معينة مفيدة بشكل لا يصدق إذا كان المستخدم يعرف الخدمة أو مجموعة الخدمات المسؤولة عن زيادة التأخير أو مصدر الأخطاء. ومع ذلك ، في نظام معقد ، قد لا يكون تحديد الدخلاء مهمة تافهة أثناء الفشل ، خاصة إذا لم يتم تلقي رسائل خطأ من الخدمات.
يمكن أن يكون بناء طوبولوجيا الخدمة مفيدًا للغاية في تحديد الخدمة التي تظهر ارتفاعًا في معدل الخطأ أو زيادة في الكمون ، مما يؤدي إلى تدهور ملحوظ في أداء الخدمة. عند الحديث عن بناء طوبولوجيا ، لا أقصد
خريطة خدمة تعرض كل خدمة متوفرة في النظام وتُعرف
بخرائطها المعمارية في شكل نجمة الموت . هذا التمثيل ليس أفضل من وجهة نظر تتبع بناءً على رسم بياني موجه. بدلاً من ذلك ، أرغب في رؤية هيكل
خدمة تم إنشاؤه ديناميكيًا استنادًا إلى سمات معينة ، مثل معدل الخطأ أو وقت الاستجابة أو أي معلمة يحددها المستخدم والتي تساعد في توضيح الموقف مع خدمات مشبوهة محددة.
لنلقِ نظرة على مثال. تخيل موقع أخبار افتراضي. تتواصل خدمة
الصفحة الأولى مع Redis ، من خلال خدمة التوصية ، مع خدمة الإعلان وخدمة الفيديو. تأخذ خدمة الفيديو مقاطع فيديو من S3 ، وبيانات التعريف من DynamoDB. تتلقى خدمة التوصية البيانات الأولية من DynamoDB ، وتنزيل البيانات من Redis و MySQL ، وتكتب الرسائل إلى Kafka. تتلقى خدمة الإعلان بيانات من MySQL وتكتب رسائل إلى Kafka.
فيما يلي تمثيل تخطيطي لهذه الهيكلية (تقوم العديد من برامج التوجيه التجارية ببناء الهيكل). يمكن أن يكون مفيدًا إذا كنت بحاجة إلى فهم تبعيات الخدمات. ومع ذلك ، أثناء
تصحيح الأخطاء ، عندما توضح خدمة معينة (على سبيل المثال ، خدمة فيديو) زيادة وقت الاستجابة ، فإن هذا الهيكل غير مفيد للغاية.
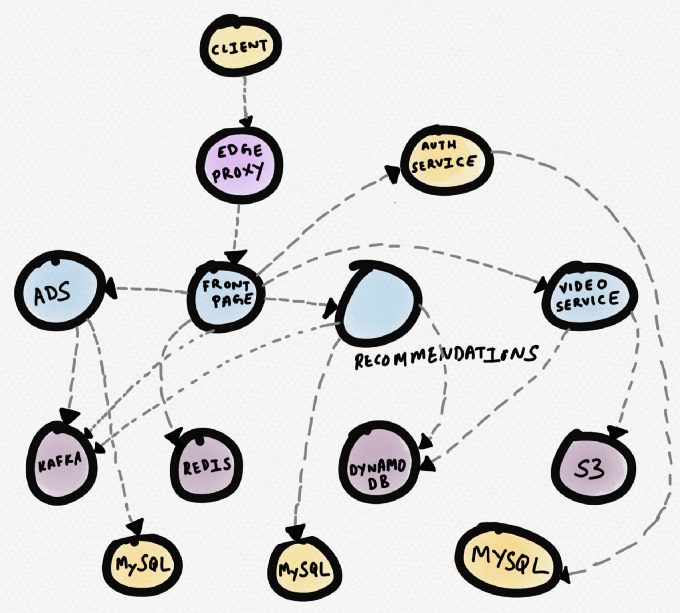 نظام خدمات الموقع الإخباري الافتراضي
نظام خدمات الموقع الإخباري الافتراضيالمخطط أدناه سيكون أفضل. على ذلك يصور خدمة إشكالية
(فيديو) مباشرة في الوسط. المستخدم يلاحظ على الفور له. من هذا التصور ، يصبح من الواضح أن خدمة الفيديو تعمل بشكل غير طبيعي بسبب زيادة وقت الاستجابة لـ S3 ، مما يؤثر على سرعة تنزيل جزء من الصفحة الرئيسية.
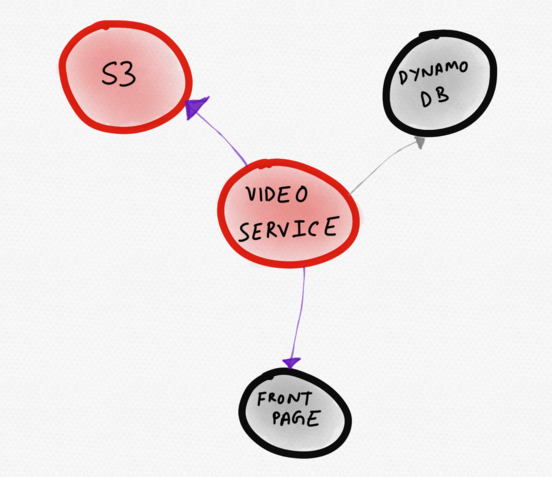 طوبولوجيا ديناميكية تعرض فقط خدمات "مثيرة للاهتمام"
طوبولوجيا ديناميكية تعرض فقط خدمات "مثيرة للاهتمام"يمكن أن تكون مخططات الطوبولوجيا المولدة ديناميكيًا أكثر كفاءة من خرائط الخدمة الثابتة ، خاصة في البنى التحتية المرنة والقابلة للتوسعة تلقائيًا. تتيح إمكانية مقارنة طبولوجيا الخدمة وتباينها للمستخدم طرح أسئلة أكثر صلة. من المرجح أن تؤدي الأسئلة الأكثر دقة حول النظام إلى فهم أفضل لكيفية عمل النظام.
عرض مقارن
سيكون التصور المفيد الآخر هو عرض مقارن. عمليات التتبع غير مناسبة حاليًا لإجراء المقارنات جنبًا إلى جنب ، لذلك عادةً ما تتم مقارنة المسافات. والفكرة الرئيسية لهذه المقالة هي بالتحديد أن المسافات منخفضة للغاية بحيث لا يمكن استخراج المعلومات الأكثر قيمة من نتائج التتبع.
المقارنة بين اثنين من trace'ov لا تتطلب تصورات جديدة في الأساس. في الواقع ، يكفي شيء مثل الرسم البياني الذي يمثل نفس المعلومات التي تتبعها. والمثير للدهشة ، حتى هذه الطريقة البسيطة يمكن أن تحقق ثمارًا أكثر بكثير من الدراسة البسيطة لاثنين من الآثار بشكل منفصل. والأكثر قوة هي القدرة على
تصور المقارنة بين الآثار
في المجموع . سيكون من المفيد للغاية معرفة كيف يؤثر تغيير تكوين قاعدة البيانات المنشورة حديثًا مع تضمين GC (مجموعة البيانات المهملة) على وقت استجابة خدمة المتلقين للمعلومات في غضون ساعات قليلة. إذا بدا ما أصفه هنا بمثابة تحليل A / B لتأثير تغييرات البنية الأساسية
في مجموعة متنوعة من الخدمات باستخدام نتائج التتبع ، فأنت لست بعيدًا عن الحقيقة.
استنتاج
أنا لا أشك في فائدة التتبع نفسه. أعتقد مخلصًا أنه لا توجد طريقة أخرى لجمع البيانات الغنية والعادية والسياقية كتلك الموجودة في التتبع. , . , traceview-, , , trace'. , , .
, , . ,
, . , production , , , , .
, , , , , . , , , trace' span'.
( UI). , , . , . . .
PS من المترجم
اقرأ أيضًا في مدونتنا: