تقريبا. العابرة. : يسعدنا أن نشارك ترجمة المواد الرائعة من المبشر التكنولوجي الأقدم من AWS - Adrian Hornsby. وبكلمات بسيطة ، يوضح أهمية التجارب المصممة للتخفيف من عواقب الفشل في أنظمة تكنولوجيا المعلومات. ربما سمعت بالفعل عن Chaos Monkey (أو حتى استخدام حلول مماثلة)؟ اليوم ، يتم تنفيذ أساليب إنشاء مثل هذه الأدوات وتنفيذها في سياق أوسع كجزء من نشاط يسمى هندسة الفوضى. اقرأ المزيد عنها في هذا المقال.
"لكن وراء كل هذا الجمال تكمن الفوضى والجنون." - دباغة الجدار
رجال الاطفاء . هؤلاء المتخصصين المؤهلين تأهيلا عاليا يخاطرون بحياتهم كل يوم ، محاربة الحريق. هل تعلم أنه قبل أن تصبح رجل إطفاء ، تحتاج إلى قضاء 600 ساعة على الأقل في التدريب؟ وهذه هي البداية فقط. وفقا للتقارير ، رجال الاطفاء تدريب ما يصل إلى 80 ٪ من وقت عملهم.
لماذا؟
عندما يكافح رجل إطفاء بالنيران الحقيقية ، فإنه يحتاج إلى
الحدس المناسب. من أجل تطويره ، يجب عليك التدريب ساعة بعد ساعة ، يوما بعد يوم. كما يقولون ، الممارسة تعمل العجائب.
"يبدو كما لو أنهم يخترقون جوهر النار ؛ هذه نظائرها من الدكتور فيل للشعلة ". - مكافحة حرائق الغابات باستخدام أجهزة الكمبيوتر والحدس
تقريبا. العابرة. : Philip Calvin "Phil" McGraw هو عالم نفسي أمريكي ، كاتب ومقدم لبرنامج تلفزيوني شهير "Doctor Phil" ، يقدم فيه مقدم البرنامج حلولاً لمشاركيه.ذات مرة في سياتل
في أوائل العقد الأول من القرن العشرين ، أنشأ
جيسي روبنز ، الذي شغل منصبًا رسميًا في أمازون يحمل الاسم الرسمي "
سيد الكوارث" ، برنامج GameDay وقاده. واستندت إلى تجربته كرجل إطفاء. تم تصميم GameDay لاختبار وتثقيف وإعداد أنظمة Amazon المختلفة والبرامج والأشخاص لمواجهة الأزمات المحتملة.
تمامًا كما يطور رجال الإطفاء الحدس لمحاربة الحرائق ، كان جيسي على وشك مساعدة فريقه على تطوير الحدس لمواجهة الأحداث الكارثية واسعة النطاق.
"GameDay: خلق المرونة من خلال الدمار" - جيسي روبنزتم تصميم
GameDay لزيادة مرونة موقع البيع بالتجزئة في Amazon من خلال إدخال الأخطاء بشكل متعمد في أنظمة مهمة حرجة.
بدأت GameDay بسلسلة من الإعلانات للشركة بأكملها والتي تم التخطيط لإنذار تدريبي فيها - في بعض الأحيان على نطاق واسع جدًا ، على سبيل المثال ، تعطيل مركز بيانات بأكمله. تم تقديم تفاصيل حول الإغلاق المخطط له ، وتم إعطاء الفريق عدة أشهر للتحضير. كان الهدف الرئيسي من التمرين هو التحقق مما إذا كان الموظفون قادرون على مواجهة الأزمة المحلية والتخلص من آثارها بسرعة.
خلال هذه التمارين ، تم استخدام الأدوات والعمليات الخاصة ، مثل المراقبة والتنبيهات والمكالمات العاجلة ، لتحليل وتحديد الأخطاء في إجراءات الاستجابة للحوادث. كما اتضح فيما بعد ، تكشف GameDay تمامًا عن المشكلات المعمارية الكلاسيكية. في بعض الأحيان كان من الممكن أيضًا اكتشاف ما يسمى "العيوب الخفية" - المشكلات التي تظهر بسبب تفاصيل الحادث. على سبيل المثال ، فشلت أنظمة إدارة الحوادث الهامة لعملية الاسترداد بسبب الآثار الجانبية غير المتوقعة الناجمة عن مشكلة من صنع الإنسان.
مع نمو الشركة ، توسعت دائرة نصف قطرها النظري للهزيمة من GameDay. في النهاية ، توقفت هذه التمارين: أصبح الضرر المحتمل للشركة كبيرًا جدًا إذا حدث خطأ ما. منذ ذلك الحين ، تحول البرنامج إلى سلسلة من التجارب التجارية المتباينة وغير المؤثرة لتدريب الموظفين في حالات الأزمات. لن أخوض في تفاصيل التجارب في هذه المقالة ، لكنني سأفعل ذلك في المستقبل. أريد هذه المرة مناقشة الفكرة المهمة الكامنة في GameDay:
هندسة المرونة ، والمعروفة أيضًا باسم
هندسة الفوضى .
ارتفاع القرد
ربما تكون قد سمعت عن Netflix ، مزود محتوى الفيديو عبر الإنترنت. بدأت Netflix في الانتقال من مركز البيانات الخاص بها إلى AWS Cloud في أغسطس 2008. سبب هذه الخطوة إلى أضرار جسيمة لقاعدة البيانات ، بسبب تأخر تسليم أقراص DVD لمدة ثلاثة أيام (نعم ، بدأ Netflix بإرسال الأفلام عبر البريد العادي). ارتبطت عملية الترحيل إلى السحابة بالحاجة إلى تحمل أحمال التدفق الأعلى ، بالإضافة إلى الرغبة في التخلي عن البنية المتجانسة والانتقال إلى الخدمات الصغيرة التي يسهل قياسها اعتمادًا على عدد المستخدمين وحجم الفريق الهندسي. انتقل جزء المستخدم من خدمة البث إلى AWS أولاً ، بين عامي 2010 و 2011 ، تليها تكنولوجيا المعلومات للشركات وجميع الهياكل الأخرى. تم إغلاق مركز بيانات Netflix الخاص في عام 2016. تقيس الشركة إمكانية الوصول كنسبة من عدد المحاولات الناجحة لإطلاق فيلم إلى العدد الإجمالي ، وليس كمقارنة بسيطة لوقت التشغيل والتوقف ، وتحاول تحقيق رقم 0.9999 في كل منطقة على أساس ربع سنوي (غالبًا ما تنجح). تمتد بنية Netflix العالمية على ثلاث مناطق AWS. وبالتالي ، في حالة وجود مشاكل في إحدى المناطق ، فإن الشركة لديها القدرة على إعادة توجيه المستخدمين إلى الآخرين.
أكرر أحد عروضي المفضلة:
"الفشل أمر لا مفر منه. في النهاية ، فإن أي نظام سيتعطل بمرور الوقت. " - فيرنر فوجل
في الواقع ، لا يمكن تجنب الفشل في الأنظمة الموزعة ، خاصة الأنظمة واسعة النطاق ، حتى في السحابة. ومع ذلك ، فإن سحابة AWS وبدائل التكرار - على وجه الخصوص ،
مبدأ مناطق الوصول المتعددة التي بنيت عليها - تسمح لأي شخص بتصميم خدمات موثوقة للغاية.
باستخدام مبادئ التكرار
والتدهور اللطيف ،
تمكنت Netflix من
التغلب على حالات الفشل دون التأثير على المستخدمين النهائيين.
منذ البداية ، التزمت Netflix بالمبادئ المعمارية الأكثر صرامة. أحد أوائل التطبيقات التي تم نشرها على AWS كان
Chaos Monkey - لدعم الخدمات الميكروية عديمي الجنسية. بمعنى آخر ، يمكن إيقاف أي مثيل واستبداله تلقائيًا دون أي فقدان للحالة. يضمن Chaos Monkey عدم انتهاك أي شخص لهذا المبدأ.
تقريبا. العابرة. : بالمناسبة ، بالنسبة إلى Kubernetes يوجد تناظرية تسمى kube-monkey ، يبدو أن تطورها قد توقف في مارس من هذا العام.لدى Netflix قاعدة أخرى ، والتي تنص على توزيع كل خدمة في ثلاث مناطق توفر. يجب أن تستمر في العمل في حالة توفر اثنين منهم فقط. لضمان تلبية هذه القاعدة ، تقوم
Chaos Gorilla بتعطيل مناطق التوافر. أكثر على المستوى العالمي ، فإن
Chaos Kong قادرة على تعطيل منطقة AWS بأكملها للتأكد من أنه يمكن تقديم خدمات إلى جميع مستخدمي Netflix من أي من المناطق الثلاث. ويقومون بهذه الاختبارات واسعة النطاق كل بضعة أسابيع في الإنتاج للتأكد من أن لا شيء يفلت من الانتباه.
أخيرًا ، طور Netflix أيضًا
أدوات اختبار Chaos الأكثر تركيزًا للمساعدة في اكتشاف المشكلات المتعلقة بالخدمات المصغرة وهندسة التخزين. يمكنك معرفة المزيد حول هذه التقنيات من كتاب Chaos Engineering ، الذي أوصي به أي شخص مهتم بهذا الموضوع.
"من خلال إجراء تجارب على أساس منتظم تحاكي الانقطاعات الإقليمية ، تمكنا من تحديد العديد من العيوب الجهازية والقضاء عليها في مرحلة مبكرة." - مدونة Netflix
اليوم ، تتم
صياغة مبادئ هندسة الفوضى. يتم إعطاء التعريف التالي:
"هندسة الفوضى هي نهج ينطوي على إجراء تجارب على نظام الإنتاج لضمان قدرته على تحمل التداخلات المختلفة التي تحدث أثناء التشغيل." - principleofchaos.org
ومع ذلك ، في
خطاب ألقاه في AWS re: Invent 2018 حول هندسة الفوضى ، قدم
أدريان كوكروفت ، وهو مصمم سابق لهندسة سحابة Netflix ، الذي ساعد الشركة على التحول بالكامل إلى البنية التحتية السحابية ، تعريفًا بديلاً لهندسة الفوضى. في رأيي ، هو أكثر دقة وراسخة:
"هندسة الفوضى هي تجربة مصممة للتخفيف من عواقب الفشل".
في الواقع ، نحن نعلم أن حوادث التعطل تحدث في كل وقت. مع الاستجابة الصحيحة ، لا ينبغي أن تؤثر على المستخدمين النهائيين. الهدف الرئيسي من هندسة الفوضى هو اكتشاف المشكلات التي لم يتم حلها بشكل صحيح.
المتطلبات الأساسية لخلق الفوضى
قبل الشروع في هندسة الفوضى ، تأكد من القيام بكل الأعمال اللازمة لضمان الاستدامة على جميع مستويات المؤسسة. إنشاء أنظمة تتسامح مع الأخطاء لا يتعلق فقط بالبرنامج. يبدأ على مستوى
البنية الأساسية ، ويمتد إلى
الشبكة والبيانات ، ويؤثر على بنية
التطبيقات ، ويشمل في النهاية
الناس والثقافة . في الماضي ، كتبت الكثير عن نماذج الاستقرار والفشل (
هنا ،
هنا ،
هنا وهنا ) ولن أركز على هذا الآن ، لكن لا يمكنني الاستغناء عن القليل من التذكير.
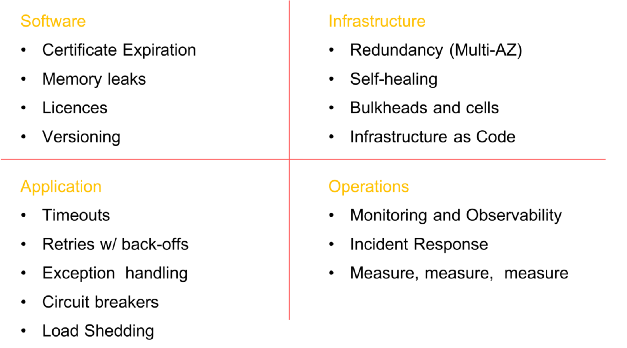 بعض العناصر الإلزامية قبل إدخال الفوضى في النظام (القائمة ليست شاملة)
بعض العناصر الإلزامية قبل إدخال الفوضى في النظام (القائمة ليست شاملة)مراحل هندسة الفوضى
من المهم أن نفهم أن جوهر هندسة الفوضى هو
عدم السماح للقردة بالتخلي عنهم والسماح لهم بتدمير كل شيء على التوالي ، دون أي غرض. الهدف من هذا التخصص هو تدمير بعض عناصر النظام في بيئة يتم التحكم فيها من خلال تجارب جيدة التخطيط للتحقق مما إذا كان التطبيق الخاص بك يمكنه تحمل الظروف المضطربة.
للقيام بذلك ، يجب اتباع العملية الرسمية المحددة بوضوح والموضحة في الشكل أدناه. مع ذلك ، يمكنك الانتقال من فهم الحالة المستقرة لنظامك إلى صياغة فرضية ، واختبارها ، وأخيراً ، تحليل الخبرة المكتسبة أثناء التجربة وزيادة ثبات النظام نفسه.
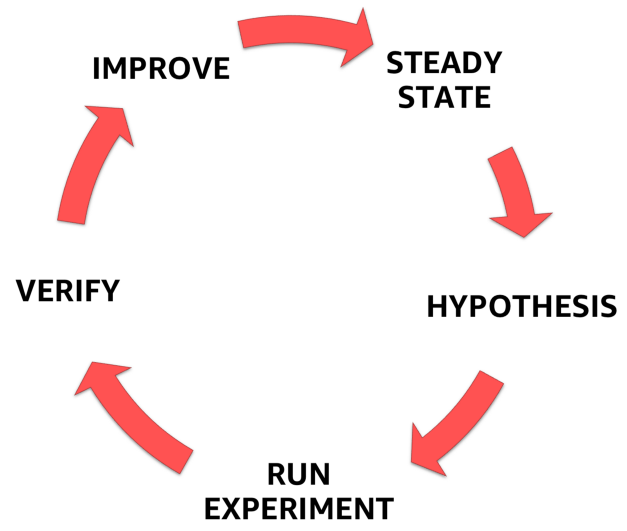 مراحل هندسة الفوضى
مراحل هندسة الفوضى1. حالة مستقرة
أحد أهم عناصر هندسة الفوضى هو فهم سلوك النظام في ظل الظروف العادية.
لماذا؟ إنه أمر بسيط: بعد إدخال الفشل الاصطناعي ، يجب عليك التأكد من أن النظام قد عاد إلى حالة مستقرة مدروسة جيدًا وأن التجربة لم تعد تتداخل مع سلوكه الطبيعي.
النقطة الأساسية هنا هي أنك تحتاج إلى التركيز ليس على السمات الداخلية للنظام (المعالج ، الذاكرة ، إلخ) ، ولكن لمراقبة إشارات الخرج القابلة للقياس التي تربط الأداء بتجربة المستخدم. لكي تكون إشارات الخرج في حالة مستقرة ، يجب أن يكون لسلوك النظام الملحوظ نمط يمكن التنبؤ به ، ولكن يتغير بشكل كبير عند حدوث عطل في النظام.
مع الأخذ في الاعتبار
تعريف هندسة الفوضى المقترح أعلاه من قبل أدريان كوكروفت ، تتغير هذه الحالة المستقرة عندما يتسبب فشل خارج عن السيطرة في حدوث مشكلة غير متوقعة وإشارات إلى أنه يجب مقاطعة تجربة الفوضى.
كمثال على الظروف المستقرة ، دعونا نستشهد بتجربة Amazon. تستخدم الشركة عدد الطلبات كأحد مقاييس الحالة المستقرة ولسبب وجيه. في عام 2007 ، تحدث جريج ليندن ، الذي كان يعمل سابقًا في Amazon ، عن كيف حاول ، كجزء من تجربة باستخدام طريقة
اختبار A / B ، إبطاء وقت تحميل الصفحات على الموقع بزيادات قدرها 100 مللي ثانية ووجد أنه حتى التأخير الطفيف ينتج عنه إلى انخفاض خطير في الإيرادات. مع زيادة وقت التحميل بمقدار 100 مللي ثانية ، انخفض عدد الطلبات (وبالتالي المبيعات) بنسبة 1٪. هذا هو السبب في أن عدد الطلبات هو مرشح ممتاز للمقاييس مستقرة.
يستخدم Netflix مقياس جانب الخادم المرتبط ببدء التشغيل - عدد النقرات على زر التشغيل. لقد لاحظوا انتظامًا في سلوك مؤشر SPS (البدء في الثانية) وتقلباته الكبيرة في حالة فشل النظام. يسمى المقياس "نبض Netflix" (
نبض Netflix ).
يعد عدد الطلبات في حالة Amazon و Netflix Pulse مقاييس استقرار ممتازة ، لأنها تجمع بين تجربة المستخدم والمقاييس التشغيلية في مؤشر واحد قابل للقياس ويمكن التنبؤ به بدرجة كبيرة.
قياس وقياس وقياس مرة أخرى
من نافلة القول أنه إذا لم تتمكن من تسجيل أداء النظام بشكل صحيح ، فلن تكون قادرًا على مراقبة التغييرات في حالة مستقرة (أو حتى اكتشافها). انتبه بشكل خاص لإزالة جميع المعلمات / المؤشرات ، من الشبكة والأجهزة وانتهاء بالتطبيق والأشخاص. ارسم رسوم بيانية لهذه القياسات ، حتى لو لم تتغير مع مرور الوقت. ستندهش من اكتشاف العلاقات التي لم تكن على علم بها.
"اجعل الأمر سهلاً قدر الإمكان للمهندسين للوصول إلى البيانات التي يمكنهم حسابها أو ترجمتها إلى شكل رسوم بيانية." - إيان مالباس
2. الفرضية
بعد التعامل مع حالة مستقرة ، يمكننا المضي قدمًا في صياغة فرضية.

- ماذا لو توقفت آلية التوصية؟
- ماذا لو كان موازن الحمل يسقط؟
- ماذا لو تسقط التخزين المؤقت؟
- ماذا لو زاد التأخير بمقدار 300 مللي ثانية؟
- ماذا لو تحطمت القاعدة الرئيسية؟
بالطبع ، يجب اختيار فرضية واحدة فقط وليس من الضروري تعقيدها بشكل غير ضروري. تبدأ صغيرة. أحب أن أبدأ بفرضية الموظفين. هل سمعت عن
عامل الحافلة ؟ عامل الحافلة هو مقياس للمخاطر يرتبط بحقيقة أن المعرفة لا يتم توزيعها بالتساوي بين أعضاء الفريق. يسمح لك بحساب الحد الأدنى لعدد المشاركين ، وبعد خسارة مفاجئة سيتوقف المشروع بسبب نقص المعرفة أو الخبرة.
يوجد لدى العديد من الشركات خبراء تقنيون سيكون للاختفاء المفاجئ ("اصطدام الحافلة") تأثير مدمر على كل من المشروع والفريق. حدد هؤلاء الأشخاص وإجراء تجارب الفوضى بمشاركتهم: على سبيل المثال ، أخذ أجهزة الكمبيوتر منها وإرسالها إلى المنزل لمدة يوم واحد ، ومن ثم مراقبة النتائج (الفوضى في كثير من الأحيان).
اجعل المشكلة مشتركة للجميع!
إشراك
الفريق بأكمله في تطوير فرضية. دع الجميع يشارك في العصف الذهني: مالك المنتج والمدير الفني ومطوري الواجهة الخلفية والمصممين والمهندسين المعماريين ، إلخ. كل شخص متصل بطريقة أو بأخرى بالمنتج.
بادئ ذي بدء ، اطلب من الجميع كتابة إجاباتهم الخاصة على السؤال "ماذا لو ...؟" على قطعة من الورق. سترى أنه في معظم الحالات سيكون لكل فرد إجابته الخاصة ، وسوف تفهم أن بعض أعضاء الفريق ما زالوا لم يفكروا في مثل هذه المشكلة على الإطلاق.
توقف عند هذه النقطة وناقش لماذا يكون لدى أعضاء الفريق رؤية مختلفة لسلوك المنتج في حالة "ماذا لو ...؟". ارجع إلى مواصفاتها وتأكد من أن الجميع يفهم بشكل صحيح التطور المحتمل للأحداث.
خذ ، على سبيل المثال ، موقع أمازون للبيع بالتجزئة المذكور. ماذا لو توقفت خدمة التسوق حسب الفئة عن التحميل على الصفحة الرئيسية؟

هل يجب علي إرجاع خطأ 404؟ هل يستحق الأمر تحميل الصفحة ، مع ترك مساحة فارغة كما في الصورة أدناه؟

هل يستحق التضحية بجزء من الوظيفة ، على سبيل المثال ، السماح للصفحة بتوسيع وإخفاء الخطأ؟
وهذا هو فقط على جانب واجهة المستخدم. ماذا يجب أن يحدث في الخلفية؟ هل يجب إرسال التنبيهات؟ هل يجب أن تستمر الخدمة الفاشلة في تلقي الطلبات في كل مرة يقوم فيها المستخدم بتحميل الصفحة الرئيسية ، أم يجب أن تقوم الواجهة الخلفية بقطعها تمامًا؟
وآخر واحد. من فضلك لا تصوغ فرضية ، وهي معروفة مسبقًا بأنها ستكسر الحطب! قم بتجربة أجزاء من النظام ، برأيك ، مستقرة - هذه هي النقطة الأساسية للتجربة في النهاية.3. تصميم وتشغيل تجربة
- اختيار فرضية واحدة ؛
- تحديد نطاق التجربة ؛
- تحديد المؤشرات ذات الصلة المراد قياسها ؛
- أخبر المنظمة.
اليوم ، يروج الكثير من الناس ، بالإضافة إلى موقع ويب
المبادئ ، فكرة هندسة الفوضى في الإنتاج. على الرغم من أن هذا يجب أن يكون الهدف النهائي ، إلا أن معظم المنظمات خائفة من هذا النهج ، لذلك يجب ألا تبدأ به.
بالنسبة لي ، هندسة الفوضى ليست فقط تدمير عناصر مختلفة من أنظمة الإنتاج. هذه رحلة. رحلة إلى عالم المعرفة ، ترتبط ارتباطًا وثيقًا بأنشطة مثل تدمير الأنظمة في بيئة خاضعة للرقابة - أي بيئة ، سواء كانت بيئة تطوير محلية ، أو تجريبية ، أو مرحلية. التدمير من خلال تجارب جيدة التصميم لبناء الثقة في قدرة التطبيق الخاص بك على تحمل الظروف المضطربة. تعد "
بناء الثقة " نقطة أساسية في هذه الحالة ، فهي مقدمة للتغييرات الثقافية اللازمة للتنفيذ الناجح لهندسة الفوضى وممارسة تحسين الموثوقية في شركتك.
بصراحة ، ستتعلم معظم الفرق الكثير عن طريق كسر الأشياء حتى في بيئة غير إنتاجية. فقط حاول أن تجعل
docker stop database في البيئة المحلية الخاصة بك ومعرفة ما إذا كان يمكنك التعامل مع هذه المشكلة دون عواقب. احتمال كبير أن لا.
توقف قاعدة البيانات - مثالابدأ صغيرة وابني الثقة تدريجياً داخل فريقك ومؤسستك. سيتم إخبارك أن "حركة الإنتاج الحقيقية هي الطريقة الوحيدة لالتقاط سلوك النظام بشكل موثوق." اسمع ، ابتسم واستمر في فعل ما تقوم به ببطء. أسوأ شيء يمكنك القيام به هو تطبيق هندسة الفوضى على الإنتاج وفشل فشلاً ذريعًا. بعد ذلك ، لن يثق بك أحد ، وسوف تضطر إلى نسيان "قرود الفوضى" إلى الأبد.
اكتسب المصداقية أولاً. أظهر للمنظمات والزملاء أنك تعرف ما تفعله. تصبح رجل اطفاء وتعرف على اللهب قدر الإمكان قبل الانتقال إلى التدريب بالنار الحي. كسب المصداقية. تذكر
قصة السلحفاة والأرنب ؟ يفوز السباق دائمًا بطيء وصبور.
واحدة من أهم النقاط خلال التجربة هي فهم
نصف القطر المحتمل
للضرر من العطل الذي تعرضه وتقليله. اسأل نفسك الأسئلة التالية:
- كم عدد العملاء الذين سيتأثرون بالتجربة؟
- ما وظيفة سوف تعاني؟
- ما هي الأماكن سوف تتأثر؟
فكر في "زر إيقاف الطوارئ" أو وسيلة لإنهاء التجربة على الفور والعودة إلى حالة مستقرة في أسرع وقت ممكن. أحب إجراء تجارب باستخدام ما يسمى. النشرات "الكناري". تقلل هذه التقنية من خطر الفشل عند بدء تشغيل إصدارات جديدة من أحد التطبيقات في الإنتاج من خلال طرح التغييرات تدريجياً على مجموعة فرعية صغيرة من المستخدمين ثم نشرها ببطء عبر البنية التحتية بأكملها وجميع المستخدمين. أحب نشرات الكناري لمجرد أنها تفي بمبدأ
البنية التحتية الثابتة ، والتجربة نفسها سهلة للغاية للتوقف.
 مثال على إصدار الكناري المستندة إلى DNS للتجارب الفوضى
مثال على إصدار الكناري المستندة إلى DNS للتجارب الفوضىكن حذرا مع التجارب التي تغير حالة التطبيق (ذاكرة التخزين المؤقت أو قاعدة البيانات) أو تلك التي لا يمكن التراجع (بسهولة أو من حيث المبدأ).
من الغريب أن أخبرني Adrian Cockcroft أن أحد أسباب بدء Netflix في استخدام قواعد بيانات NoSQL هو عدم وجود مخططات للتغييرات أو الاستعادة فيها ، لذلك فمن الأسهل بكثير تحديث السجلات الفردية أو تصحيحها تدريجياً مع البيانات (أي أنها أكثر ودية للهندسة الفوضى).
4. مراقبة والتعلم
لتعلم شيء جديد ومراقبة تقدم التجربة ، يجب أن تكون قادرًا على تتبع أداء النظام. كما ذكر آنفا ، إيلاء أقصى قدر من الاهتمام لجميع أنواع المقاييس والمعلمات! ثم تحديد النتائج ودائما - دائما! - لاحظ الوقت حتى تظهر العلامات الأولى للمشكلة. في تاريخي ، حدث مرارًا وتكرارًا أن أنظمة التحذير رفضت وأول من أبلغ العملاء عن المشكلة على Twitter ... صدقوني ، لن ترغب في أن تكون في هذا الموقف ، لذا استخدم تجارب الفوضى للتحقق من أنظمة المراقبة والتحذير.
- الوقت لاكتشاف؟
- حان الوقت لتنبيه وبدء العمل النشط؟
- الوقت لإشعار الجمهور؟
- الوقت لفقدان جزئي للوظيفة؟
- طول فترة الشفاء الذاتي؟
- وقت الانتعاش الكامل أو الجزئي؟
- هل حان الوقت لإنهاء الأزمة والعودة إلى حالة مستقرة؟
تذكر أنه لا يوجد سبب منفرد للفشل. الحوادث الكبرى هي دائمًا نتيجة لعدة إخفاقات صغيرة تتراكم وتؤدي إلى أزمة واسعة النطاق.
إجراء تحليل مفصل بعد الوفاة لكل تجربة!في AWS ، نولي اهتمامًا كبيرًا لتحليل حالات الفشل المكتشفة وفهم الأسباب التي تسببت في منعهم من حدوث مشكلات مماثلة في المستقبل. يتم تلخيص جميع استنتاجات ونتائج التجربة في وثيقة تسمى تصحيح الأخطاء (COE). COE يسمح لنا أن نتعلم من أخطائنا ، سواء كانت معيبة في التكنولوجيا أو العملية أو حتى المنظمة. نحن نستخدم هذه الآلية للقضاء على الأسباب الجذرية للانهيارات والتطوير المستمر.
مفتاح النجاح في هذه العملية هو الانفتاح والشفافية فيما يتعلق بالخطأ. واحدة من أهم المبادئ عند كتابة COE جيد هو أن تكون محايدة وتجنب ذكر أشخاص محددين. وغالبًا ما يكون هذا صعبًا في بيئة لا تشجع على مثل هذا السلوك ولا تسمح بالفشل. تستخدم أمازون مجموعة من
مبادئ القيادة لتعزيز هذا السلوك - على سبيل المثال ،
النقد الذاتي ، والنهج التحليلي ، والالتزام بأعلى المعايير ، والمسؤولية هي المكونات الرئيسية لعملية مركز التميز والتميز التشغيلي بشكل عام.
يحتوي تقرير مركز التميز على خمسة أقسام رئيسية:
- ماذا حدث (الترتيب الزمني)؟
- ما هو التأثير على العملاء؟
- لماذا حدث الخطأ؟ ( خمسة "لماذا؟" )
- ماذا تعلمنا؟
- كيف تمنع هذا في المستقبل؟
من الصعب الإجابة على هذه الأسئلة أكثر مما يبدو للوهلة الأولى ، حيث يتعين عليك التأكد من أن كل لحظة غير مفهومة / غير معروفة تتم دراستها بعناية.
من أجل تحويل آلية المعدات المملوكة للوحدات إلى عملية كاملة ، فإننا نجري باستمرار عمليات فحص في شكل اجتماعات أسبوعية مع تحليل إلزامي للمقاييس التشغيلية. بالإضافة إلى ذلك ، يقوم الخبراء الفنيون البارزون بإجراء مراجعات أسبوعية مترية مع جميع موظفي AWS.
5. تصحيح وتحسين!
الدرس الرئيسي هنا هو
، أولاً وقبل كل شيء ، القضاء على المشكلات التي تم تحديدها أثناء تجارب الفوضى ، وإعطاءها أولوية أعلى من تطوير وظائف جديدة . إشراك الإدارة العليا في هذه العملية وتعريفه بفكرة أن إصلاح المشكلات الحالية أهم بكثير من تطوير وظائف جديدة.
مرة واحدة ، بمساعدة تجربة فوضى ، ساعدت عميلًا على تحديد مشكلات الاستقرار الحرجة ، ولكن بسبب ضغوط قسم المبيعات ، تم تخفيض أولوية الإصلاح ، وتم توجيه كل الجهود نحو تقديم شيء جديد "مهم للغاية" للعملاء. بعد أسبوعين ، أجبر التوقف لمدة 16 ساعة الشركة على معالجة نفس المشكلات التي حددناها أثناء تجربة الفوضى. فقط الخسائر كانت أعلى من ذلك بكثير.
فوائد هندسة الفوضى
هناك العديد من المزايا. سأسلط الضوء على اثنين ، في رأيي ، الأهم:
أولاً ، تساعد هندسة الفوضى على حل المشكلات غير المعروفة في النظام وإصلاحها قبل أن تؤدي إلى فشل الإنتاج ، على سبيل المثال ، الساعة 3 صباحًا يوم الأحد. وهذا يعني ، أنه
يزيد من مقاومة التصادم ، وفي الواقع ، نوعية النوم .
ثانياً ، تتسبب تجارب الفوضى التي تجري بكفاءة دائمًا في حدوث تغييرات أكثر شمولًا (ثقافيًا في الأساس) مما كان متوقعًا. ربما كان أهمها التطور الطبيعي
لثقافة "لا تلوم" عندما يكون السؤال "لماذا فعلت هذا؟" يتحول إلى "كيف يمكننا تجنب هذا في المستقبل؟". نتيجة لذلك ، يصبح الفريق أكثر سعادة وكفاءة وأكثر اهتمامًا ونجاحًا.
وهذا رائع!على هذا ، الجزء الأول يأتي إلى نهايته. آمل أن تستمتع به. يرجى كتابة تعليقات أو مشاركة الآراء أو تصفيق يديك على "
متوسطة" . في الجزء التالي ، سألقي نظرة على الأدوات والتقنيات لإدخال فشل النظام. حتى - وداعا!
بالنسبة لأولئك الذين يتوقون إلى التعرف على الجزء الثاني ، أقدم عرضي التقديمي حول موضوع هندسة الفوضى في NDC في أوسلو. في ذلك ، أتحدث عن العديد من أدواتي المفضلة:
PS من المترجم
لقد ظهر بالفعل الجزء الثاني من المقالة باللغة الإنجليزية وسنترجمها أيضًا إذا رأينا اهتمامًا كافياً من قراء Habré بهذه المادة - التعليقات ذات الصلة على المقال مرحب بها! محدث (3 سبتمبر): تم أيضًا
نشر ترجمة للجزء الثاني.
محدث (19 ديسمبر): أصبحت
ترجمة الجزء الثالث متاحة.
اقرأ أيضًا في مدونتنا: