لقد تعرفنا بالفعل على جهاز
ذاكرة التخزين المؤقت المخزن المؤقت ، وهو أحد الكائنات الرئيسية في الذاكرة المشتركة ، وأدركنا أنه حتى يتسنى لك التعافي من الفشل عند فقد محتويات ذاكرة الوصول العشوائي ، يجب عليك الاحتفاظ
بسجل سجل مسبق .
المشكلة التي لم يتم حلها والتي توقفنا عنها في المرة الأخيرة هي أنه من غير المعروف عند أي نقطة يمكنك البدء في تشغيل السجلات أثناء الاسترداد. البدء من البداية ، كما نصحت King
of Alice ، لن ينجح: من المستحيل تخزين جميع إدخالات دفتر اليومية من بداية الخادم - قد يكون هذا مبلغًا كبيرًا ونفس وقت الاسترداد الضخم. نحتاج إلى نقطة تقدم تدريجية يمكن أن نبدأ منها في التعافي (وبالتالي ، يمكننا حذف جميع إدخالات دفتر اليومية السابقة بأمان). هذه هي
نقطة التحكم التي سيتم مناقشتها اليوم.
نقطة التحكم
ما الخاصية يجب أن يكون نقطة مراقبة؟ يجب أن نتأكد من أن جميع إدخالات دفتر اليومية ، بدءًا من نقطة التفتيش ، سيتم تطبيقها على الصفحات المكتوبة على القرص. إذا لم يكن الأمر كذلك ، أثناء عملية الاستعادة ، يمكننا أن نقرأ من القرص إصدارًا قديمًا للغاية من الصفحة وتطبيق إدخال دفتر يومية عليها ، وبالتالي إتلاف البيانات بشكل دائم.
كيف تحصل على نقطة توقف؟ الخيار الأسهل هو تعليق النظام بشكل دوري ومسح كافة الصفحات المتسخة من المخزن المؤقت وغيرها من ذاكرات التخزين المؤقت على القرص. (لاحظ أن الصفحات مكتوبة فقط ، ولكن لا يتم إخراجها من ذاكرة التخزين المؤقت.) سوف تلبي هذه النقاط الشرط ، ولكن بالطبع لن يرغب أحد في العمل مع نظام يتجمد باستمرار لفترة زمنية غير محددة ، ولكنه مهم للغاية.
لذلك ، في الممارسة العملية ، كل شيء أكثر تعقيدًا إلى حد ما: نقطة التحكم من نقطة تتحول إلى مقطع. أولاً
نبدأ نقطة الإيقاف. بعد ذلك ، دون مقاطعة العمل ، وإذا أمكن ، وبدون إنشاء أحمال الذروة ، فإننا نتخلص ببطء من المخازن المؤقتة القذرة على القرص.

عند كتابة جميع المخازن المؤقتة التي كانت متسخة
في بداية نقطة التفتيش ، تعتبر نقطة التفتيش
كاملة . الآن (ولكن ليس سابقًا) يمكننا استخدام نقطة
البداية كنقطة يمكنك من خلالها البدء في الاسترداد. وإدخالات دفتر اليومية حتى هذه المرحلة لم نعد بحاجة إليها.

تتم معالجة نقطة التفتيش بواسطة عملية فحص خلفية خاصة.
يتم تحديد مدة المخازن المؤقتة القذرة بواسطة قيمة المعلمة
checkpoint_completion_target . يوضح مقدار الوقت بين نقطتي التحكم المتجاورتين اللذين سيتم فيهما التسجيل. القيمة الافتراضية هي 0.5 (كما في الأشكال أعلاه) ، أي أن التسجيل يستغرق نصف الوقت بين نقاط التحكم. عادةً ما يتم زيادة القيمة إلى 1.0 للحصول على مزيد من التوحيد.
دعونا نفكر بمزيد من التفصيل في ما يحدث عند تنفيذ نقطة التحكم.
عملية نقطة الاختبار أولاً مسح المخازن المؤقتة لحالة المعاملة (XACT) إلى القرص. نظرًا لوجود عدد قليل منها (128 في المجموع) ، يتم تسجيلها على الفور.
ثم يبدأ العمل الرئيسي - كتابة صفحات متسخة من ذاكرة التخزين المؤقت المخزن المؤقت. كما قلنا من قبل ، من المستحيل إعادة تعيين كل الصفحات مرة واحدة ، حيث يمكن أن يكون حجم ذاكرة التخزين المؤقت المخزن المؤقت كبيرًا. لذلك ، أولاً ، يتم وضع علامة على كل الصفحات المتسخة حاليًا في ذاكرة التخزين المؤقت المؤقتة في الرؤوس ذات علامة خاصة.
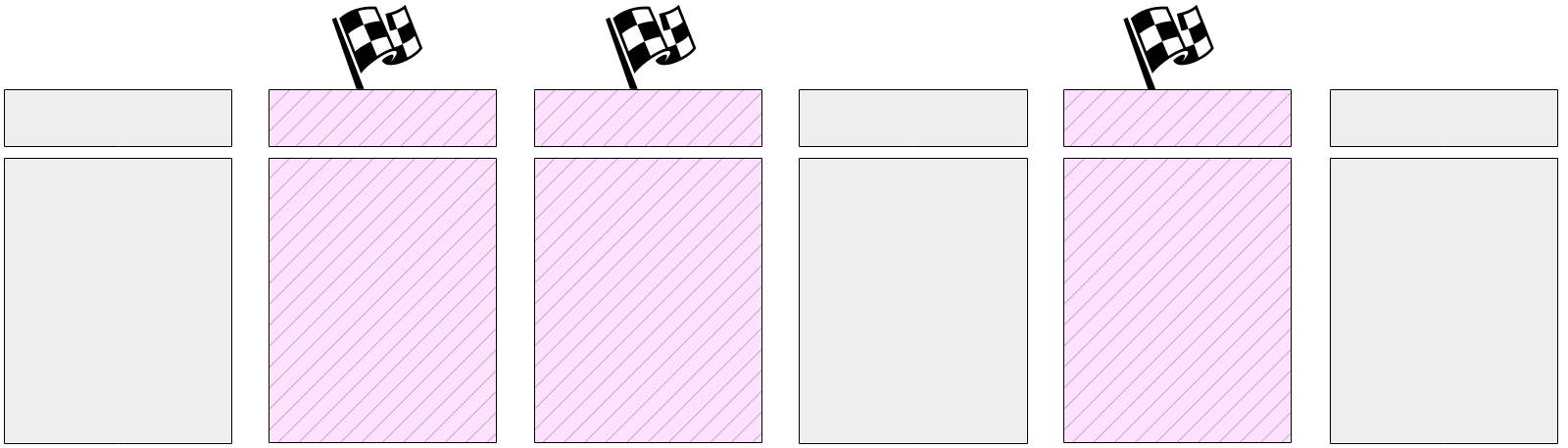
وبعد ذلك ، تمر عملية نقاط التفتيش تدريجياً عبر جميع المخازن المؤقتة وتدفق تلك المحددة على القرص. تذكر أنه لا يتم إخراج الصفحات من ذاكرة التخزين المؤقت ، ولكن تتم كتابتها فقط على القرص ، لذلك لا تحتاج إلى الانتباه إلى عدد المكالمات إلى المخزن المؤقت أو إصلاحه.
يمكن أيضًا كتابة المخازن المؤقتة التي تمت تسميتها بواسطة عمليات الخادم - اعتمادًا على من يصل إلى المخزن المؤقت أولاً. في أي حال ، تتم إزالة العلامة المحددة مسبقًا عند التسجيل ، لذا (لغرض نقطة التفتيش) سيتم كتابة المخزن المؤقت مرة واحدة فقط.
وبطبيعة الحال ، أثناء تنفيذ نقطة التفتيش ، تستمر الصفحات في التغيير في ذاكرة التخزين المؤقت المخزن المؤقت. ولكن لا يتم وضع علامة على المخازن المؤقتة الجديدة القذرة ويجب ألا تكتبها عملية التحقق.
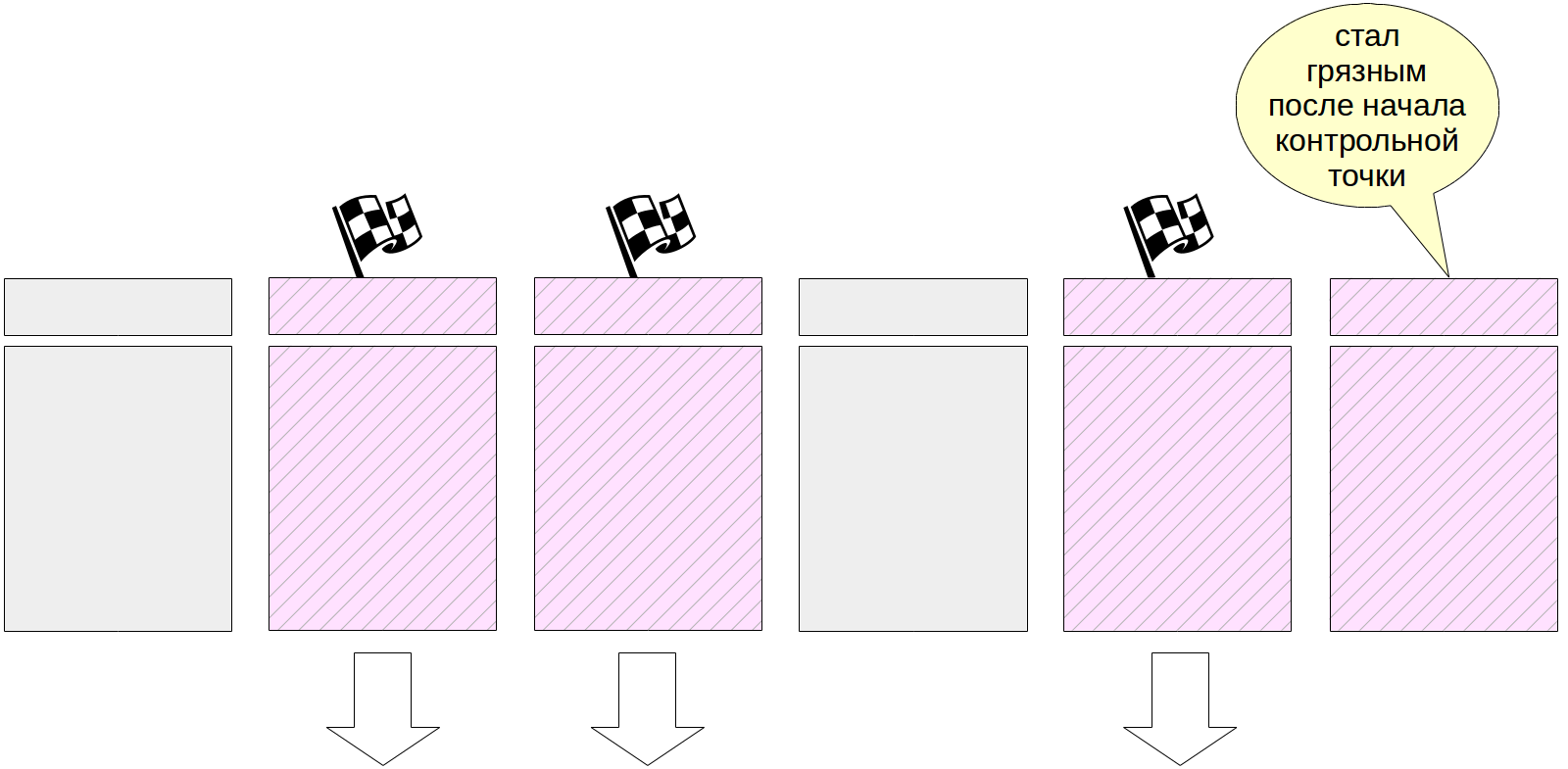
في نهاية عملها ، تنشئ العملية إدخال دفتر يومية لنهاية نقطة التفتيش. يحتوي هذا السجل على LSN لبداية عمل نقطة التحكم. نظرًا لأن نقطة التحكم لا تكتب أي شيء إلى السجل في بداية عملها ، يمكن أن يحتوي LSN على أي سجل سجل.
بالإضافة إلى ذلك ، يقوم ملف PGDATA / global / pg_control $ بتحديث الإشارة إلى آخر نقطة تفتيش
مرت . قبل اكتمال نقطة التفتيش ، يشير pg_control إلى نقطة التفتيش السابقة.

لإلقاء نظرة على عمل نقطة التفتيش ، قم بإنشاء بعض الجداول - ستنتقل صفحاتها إلى ذاكرة التخزين المؤقت المؤقتة وستكون متسخة:
=> CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n); => CREATE EXTENSION pg_buffercache; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 78 (1 row)
تذكر الموضع الحالي في السجل:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A048 (1 row)
سنقوم الآن بتنفيذ نقطة التفتيش يدويًا والتأكد من عدم وجود صفحات متسخة في ذاكرة التخزين المؤقت (كما قلنا ، يمكن ظهور صفحات قذرة جديدة ، ولكن في حالتنا ، لم تحدث تغييرات في عملية تنفيذ نقطة التفتيش):
=> CHECKPOINT; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 0 (1 row)
لنرى كيف انعكست نقطة التفتيش في السجل:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A0E4 (1 row)
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A048 -e 0/3514A0E4
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/3514A048, prev 0/35149CEC, desc: RUNNING_XACTS nextXid 101105 latestCompletedXid 101104 oldestRunningXid 101105
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A07C, prev 0/3514A048, desc: CHECKPOINT_ONLINE redo 0/3514A048; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 101105; online
هنا نرى اثنين من المدخلات. آخر واحد هو سجل لتمرير نقطة التحكم (CHECKPOINT_ONLINE). يشار إلى LSN لبداية نقطة التفتيش بعد كلمة الإعادة ، وهذا الموقف يتوافق مع إدخال دفتر اليومية ، والذي كان الأخير في بداية نقطة التفتيش.
سوف نجد نفس المعلومات في ملف التحكم:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | egrep 'Latest.*location'
Latest checkpoint location: 0/3514A07C Latest checkpoint's REDO location: 0/3514A048
انتعاش
نحن الآن على استعداد لتوضيح خوارزمية الاسترداد الموضحة في المقالة السابقة.
إذا تعطل الخادم ، في المرة التالية التي يبدأ فيها التشغيل ، تكتشف عملية بدء التشغيل هذا من خلال النظر في ملف pg_control ورؤية حالة غير "إيقاف التشغيل". في هذه الحالة ، يتم تنفيذ الاسترداد التلقائي.
أولاً ، سوف تقرأ عملية الاسترداد من نفس موقع pg_control موضع بداية نقطة التحكم. (للتأكد من اكتمالها ، نلاحظ أنه في حالة وجود ملف backup_label ، فسيتم قراءة سجل نقطة التحكم منه - وهذا ضروري للاستعادة من النسخ الاحتياطية ، ولكن هذا موضوع لدورة منفصلة.)
بعد ذلك ، سوف يقرأ المجلة ، بدءًا من الموضع الموجود ، مع تطبيق إدخالات المجلات بشكل متتابع على الصفحات (عند الضرورة ، كما ناقشنا
آخر مرة ).
في الختام ، يتم الكتابة فوق جميع الجداول غير اليومية باستخدام الصور الموجودة في ملفات init.
عند هذه النقطة ، تنتهي عملية بدء التشغيل ، وتنفذ عملية checkpointer على الفور نقطة تفتيش لإصلاح الحالة المستعادة على القرص.
يمكنك محاكاة الفشل عن طريق إيقاف الخادم بالقوة في الوضع الفوري.
student$ sudo pg_ctlcluster 11 main stop -m immediate --skip-systemctl-redirect
(
--skip-systemctl-redirect مطلوب هنا لأن PostgreSQL مثبت في Ubuntu من الحزمة. يتم التحكم فيه بواسطة الأمر pg_ctlcluster ، الذي يستدعي systemctl بالفعل ، ويستدعي بالفعل pg_ctl. مع كل هذه الملفات ، اسم الوضع تضيع على طول الطريق ، ويتيح لك
--skip-systemctl-redirect الاستغناء عن systemctl وحفظ المعلومات المهمة.)
تحقق من حالة الكتلة:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
عند بدء التشغيل ، تدرك PostgreSQL أن هناك فشلًا وأن هناك حاجة إلى استرداد.
student$ sudo pg_ctlcluster 11 main start
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:49.441 MSK [8865] LOG: database system was interrupted; last known up at 2019-07-17 15:27:48 MSK 2019-07-17 15:27:49.801 MSK [8865] LOG: database system was not properly shut down; automatic recovery in progress 2019-07-17 15:27:49.804 MSK [8865] LOG: redo starts at 0/3514A048 2019-07-17 15:27:49.804 MSK [8865] LOG: invalid record length at 0/3514A0E4: wanted 24, got 0 2019-07-17 15:27:49.804 MSK [8865] LOG: redo done at 0/3514A07C 2019-07-17 15:27:49.824 MSK [8864] LOG: database system is ready to accept connections 2019-07-17 15:27:50.409 MSK [8872] [unknown]@[unknown] LOG: incomplete startup packet
تم الإشارة إلى الحاجة إلى الاسترداد في سجل الرسائل:
لم يتم إيقاف تشغيل نظام قاعدة البيانات بشكل صحيح ؛ الانتعاش التلقائي في التقدم . بعد ذلك ، تبدأ إدخالات دفتر اليومية باللعب من الموضع المحدد في "إعادة البدء في" والاستمرار حتى يمكن استرداد إدخالات دفتر اليومية التالية. يكمل هذا الاسترداد في موضع "الإعادة في" ويبدأ نظام إدارة قواعد البيانات (DBMS) العمل مع العملاء (
نظام قاعدة البيانات جاهز لقبول الاتصالات ).
وما يحدث أثناء إيقاف تشغيل الخادم العادي؟ لمسح الصفحات المتسخة على القرص ، يقوم PostgreSQL بفصل جميع العملاء ثم يقوم بتشغيل نقطة التفتيش النهائية.
تذكر الموضع الحالي في السجل:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A14C (1 row)
الآن أوقف الخادم بلطف:
student$ sudo pg_ctlcluster 11 main stop
تحقق من حالة الكتلة:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: shut down
وفي السجل ، نجد السجل الوحيد حول نقطة التحكم النهائية (CHECKPOINT_SHUTDOWN):
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A14C
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A14C, prev 0/3514A0E4, desc: CHECKPOINT_SHUTDOWN redo 0/3514A14C; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown
pg_waldump: FATAL: error in WAL record at 0/3514A14C: invalid record length at 0/3514A1B4: wanted 24, got 0
(في رسالة قاتلة رهيبة ، يريد pg_waldump فقط أن يقول إنه قرأ في نهاية المجلة.)
قم بتشغيل المثيل مرة أخرى.
student$ sudo pg_ctlcluster 11 main start
تسجيل الخلفية
كما اكتشفنا ، فإن نقطة التفتيش هي واحدة من العمليات التي تكتب صفحات متسخة من ذاكرة التخزين المؤقت المخزن المؤقت إلى القرص. لكن ليس الوحيد.
إذا احتاج الواجهة الخلفية إلى إخراج الصفحة من المخزن المؤقت وكانت الصفحة متسخة ، فسيتعين عليها كتابتها على القرص من تلقاء نفسها. هذا وضع سيء ، يؤدي إلى التوقعات - إنه أفضل بكثير عندما يحدث التسجيل بشكل غير متزامن في الخلفية.
لذلك ، بالإضافة إلى
عملية نقاط التفتيش
، هناك أيضًا
عملية تسجيل خلفية (كاتب الخلفية ، bgwriter ، أو كاتب فقط). تستخدم هذه العملية نفس خوارزمية البحث في المخزن المؤقت مثل آلية الاستباق. هناك أساسا اثنين من الاختلافات.
- لا يستخدم المؤشر إلى "الضحية التالية" ، ولكن يستخدمه. يمكن أن يكون في مقدمة المؤشر إلى "الضحية" ، لكنه لم يتخلف عن الركب.
- عند اجتياز المخازن المؤقتة ، لا ينقص عداد الدخول.
مكتوبة المخازن المؤقتة التي هي في وقت واحد:
- تحتوي على بيانات تم تغييرها (متسخة) ،
- غير ثابت (عدد الدبوس = 0) ،
- لديك صفر مرات (عدد الاستخدام = 0).
وبالتالي ، فإن عملية تسجيل الخلفية ، كما هي ، تمضي قدماً قبل الزحام وتجد تلك المخازن المؤقتة التي من المحتمل أن تكون مزدحمة قريبًا. من الناحية المثالية ، نتيجة لهذا ، يجب أن تجد عمليات الخدمة أن المخازن المؤقتة التي تختارها يمكن استخدامها دون التوقف عن الكتابة.
تعديل
عادة ما
يتم تكوين
عملية نقطة التفتيش للأسباب التالية.
تحتاج أولاً إلى تحديد مقدار ملفات السجل التي يمكننا حفظها (وما هو وقت الاسترداد الذي يناسبنا). كلما كانت القيمة أكبر ، كان ذلك أفضل ، ولكن لأسباب واضحة ، ستكون هذه القيمة محدودة.
بعد ذلك ، يمكننا حساب مدة إنشاء هذا الحجم تحت الحمل العادي. لقد درسنا بالفعل كيفية القيام بذلك (نحتاج إلى تذكر المواقف في المجلة وطرح واحدة من الأخرى).
هذه المرة سيكون لدينا الفاصل الزمني المعتاد بين نقاط التحكم. نكتبها في المعلمة
checkpoint_timeout . من الواضح أن القيمة الافتراضية البالغة 5 دقائق صغيرة جدًا ، وعادةً ما يتم زيادة الوقت إلى نصف ساعة. أكرر: كلما كان بمقدورك تحمل نفقات أقل ، كان ذلك أفضل - وهذا يقلل من النفقات العامة.
ومع ذلك ، فمن المحتمل (وحتى المحتمل) أن يكون الحمل في بعض الأحيان أعلى من المعتاد ، وسيتم إنشاء الكثير من إدخالات دفتر اليومية في الوقت المحدد في المعلمة. في هذه الحالة ، أود إجراء نقطة التحكم في كثير من الأحيان. للقيام بذلك ، في المعلمة
max_wal_size ، نحدد المبلغ الصحيح في نفس نقطة التحكم. إذا تم الحصول على وحدة التخزين الفعلية أكثر ، يبدأ الخادم في نقطة تفتيش غير مجدولة.
وبالتالي ، تحدث معظم نقاط التحكم في جدول: مرة واحدة لكل وحدات وقت
checkpoint_timeout . ولكن مع زيادة الحمل ، يتم استدعاء نقطة التحكم في كثير من الأحيان عندما يتم
الوصول إلى وحدة التخزين
max_wal_size .
من المهم أن نفهم أن المعلمة
max_wal_size لا تحدد على الإطلاق الحد الأقصى للمبلغ الذي يمكن أن تشغله ملفات السجل على القرص.
- لاستعادة عطل ما ، تحتاج إلى تخزين الملفات من اللحظة التي مرت فيها نقطة التفتيش الأخيرة ، بالإضافة إلى الملفات التي تراكمت أثناء تشغيل نقطة التفتيش الحالية. لذلك ، يمكن تقدير الحجم الكلي تقريبًا كـ
(1 + checkpoint_completion_target ) × max_wal_size . - قبل الإصدار 11 ، قام PostgreSQL أيضًا بتخزين الملفات لنقطة التفتيش التي تبلغ من العمر عامين ، لذا حتى الإصدار 10 في الصيغة أعلاه ، يجب عليك تعيين 2 بدلاً من 1.
- المعلمة max_wal_size ليست سوى رغبة ، ولكنها ليست حدًا ثابتًا . قد تتحول أكثر.
- ليس للخادم الحق في مسح ملفات السجل التي لم يتم نقلها بعد من خلال فتحات النسخ المتماثل والتي لم يتم أرشفتها بعد أثناء الأرشفة المستمرة. إذا تم استخدام هذه الوظيفة ، فإن المراقبة المستمرة ضرورية ، لأنه من السهل تجاوز سعة ذاكرة الخادم.
لإكمال الصورة ، لا يمكنك فقط تعيين الحد الأقصى لمستوى الصوت ، ولكن أيضًا الحد الأدنى: المعلمة
min_wal_size . معنى هذا الإعداد هو أن الخادم لا يحذف الملفات أثناء
احتوائه على وحدة التخزين في
min_wal_size ، ولكن ببساطة يعيد تسميتها ويستخدمها مرة أخرى. هذا يوفر عليك قليلاً عن طريق إنشاء وحذف الملفات باستمرار.
من المنطقي تكوين
عملية تسجيل الخلفية بعد تكوين نقطة التفتيش. يجب أن يكون لدى هذه العمليات معًا وقت لكتابة مخازن مؤقتة متسخة قبل أن تحتاج إليها عمليات الصيانة.
يتم تشغيل عملية تسجيل الخلفية في دورات من صفحات
bgwriter_lru_maxpages على الأكثر ، وتغفو بين الدورات في
bgwriter_delay .
يتم تحديد عدد الصفحات التي سيتم تسجيلها في دورة عمل واحدة من خلال متوسط عدد المخازن المؤقتة التي تم طلبها من خلال عمليات الصيانة من المدى الأخير (باستخدام متوسط متحرك لتخفيف التباين بين الأشواط ، ولكن لا يعتمد على تاريخ طويل). يتم ضرب عدد المخازن المؤقتة المحسوبة بواسطة معامل
bgwriter_lru_multiplier (ولكن في أي حال لن يتجاوز
bgwriter_lru_maxpages ).
القيم الافتراضية:
bgwriter_delay = 200ms (على الأرجح أكثر من اللازم ،
تسرب الكثير من الماء في 1/5 ثانية) ،
bgwriter_lru_maxpages = 100 ،
bgwriter_lru_multiplier = 2.0 (نحاول الاستجابة للطلب قبل الموعد المحدد).
إذا لم تكشف العملية عن المخازن المؤقتة القذرة على الإطلاق (أي ، لا يحدث أي شيء في النظام) ، فستكون "سبات" ، حيث يُستنتج أن عملية الخادم تصل إلى المخزن المؤقت. بعد ذلك ، تستيقظ العملية وتعمل مرة أخرى بالطريقة المعتادة.
مراقبة
يمكن ، بل ويجب ، ضبط نقطة التحكم وإعدادات تسجيل الخلفية ، وتلقي الملاحظات من المراقبة.
تعرض المعلمة
checkpoint_warning تحذيرًا إذا كانت نقاط التفتيش الناتجة عن تجاوزات حجم ملف السجل تعمل كثيرًا. القيمة الافتراضية هي 30 ثانية ، ويجب أن تتماشى مع قيمة
checkpoint_timeout .
تسمح معلمة
log_checkpoints (تم تعطيلها افتراضيًا) بتلقي معلومات حول نقاط التحقق المنفذة في سجل رسائل الخادم. قم بتشغيله.
=> ALTER SYSTEM SET log_checkpoints = on; => SELECT pg_reload_conf();
الآن قم بتغيير شيء ما في البيانات وقم بتنفيذ نقطة التفتيش.
=> UPDATE chkpt SET n = n + 1; => CHECKPOINT;
في سجل الرسائل ، سنرى شيئًا مثل هذا:
postgres$ tail -n 2 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:55.248 MSK [8962] LOG: checkpoint starting: immediate force wait 2019-07-17 15:27:55.274 MSK [8962] LOG: checkpoint complete: wrote 79 buffers (0.5%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.001 s, sync=0.013 s, total=0.025 s; sync files=2, longest=0.011 s, average=0.006 s; distance=1645 kB, estimate=1645 kB
يمكنك هنا معرفة عدد المخازن المؤقتة التي تمت كتابتها ، وكيف تغير تكوين ملفات السجل بعد نقطة التحكم ، والوقت الذي استغرقته نقطة التحكم والمسافة (بالبايت) بين نقاط التحكم المجاورة.
ولكن ، على الأرجح ، فإن المعلومات الأكثر فائدة هي إحصائيات عمل نقاط التفتيش وتسجيل الخلفية في طريقة العرض pg_stat_bgwriter. طريقة العرض واحدة لشخصين ، لأنه بمجرد أن يتم تنفيذ كل المهام بواسطة عملية واحدة ؛ ثم تم تقسيم وظائفهم ، وبقي الرأي.
=> SELECT * FROM pg_stat_bgwriter \gx
-[ RECORD 1 ]---------+------------------------------ checkpoints_timed | 0 checkpoints_req | 1 checkpoint_write_time | 1 checkpoint_sync_time | 13 buffers_checkpoint | 79 buffers_clean | 0 maxwritten_clean | 0 buffers_backend | 42 buffers_backend_fsync | 0 buffers_alloc | 363 stats_reset | 2019-07-17 15:27:49.826414+03
هنا ، من بين أشياء أخرى ، نرى عدد نقاط التحكم المكتملة:
- checkpoints_timed - وفقًا للجدول (عند الوصول إلى checkpoint_timeout) ،
- checkpoints_req - عند الطلب (بما في ذلك عند الوصول إلى max_wal_size).
تشير القيمة الكبيرة لـ checkpoint_req (مقارنة بـ checkpoints_timed) إلى أن نقاط التحكم تحدث بشكل متكرر أكثر من المتوقع.
معلومات مهمة حول عدد الصفحات المسجلة:
- buffers_checkpoint - عملية نقاط التفتيش ،
- buffers_backend - عن طريق خدمة العمليات ،
- buffers_clean - عملية تسجيل الخلفية.
على نظام مضبوط جيدًا ، يجب أن تكون قيمة buffers_backend أقل بكثير من مجموع buffers_checkpoint و buffers_clean.
كما أن maxwritten_clean مفيد لإعداد تسجيل الخلفية - يوضح هذا الرقم عدد المرات التي توقفت فيها عملية تسجيل الخلفية عن العمل بسبب تجاوز
bgwriter_lru_maxpages .
يمكنك إعادة تعيين الإحصائيات المتراكمة باستخدام المكالمة التالية:
=> SELECT pg_stat_reset_shared('bgwriter');
أن تستمر .