
تم إعداد ترجمة المقال لطلاب مقرر "الرياضيات لعلوم البيانات"
ملخص
تتناول هذه المقالة مهمة البحث عن ملامح الوجه لصورة واحدة. نوضح كيف يمكن استخدام مجموعة أشجار الانحدار للتنبؤ بموقف ملامح الوجه مباشرةً من مجموعة فرعية متناثرة من شدة البكسل ، مما يحقق أداء فائقًا في الوقت الفعلي مع تنبؤات عالية الجودة. نقدم بنية عامة تستند إلى زيادة التدرج لدراسة مجموعة من أشجار الانحدار التي تعمل على تحسين مجموع الخسائر التربيعية والعمليات الطبيعية للبيانات المفقودة أو الموسومة جزئيًا. سنبين كيف يساعد استخدام التوزيعات المناسبة التي تأخذ في الاعتبار بنية بيانات الصورة في التحديد الفعال للكفافيات. كما يتم التحقيق في استراتيجيات تنظيم مختلفة وأهميتها في مكافحة إعادة التدريب. بالإضافة إلى ذلك ، نقوم بتحليل تأثير كمية بيانات التدريب على دقة التنبؤات ودراسة تأثير زيادة البيانات باستخدام البيانات المركبة.
1. مقدمة
في هذه المقالة ، نقدم خوارزمية جديدة تبحث عن ملامح الوجه بالمللي ثانية وتحقق دقة تفوق الطرق الحديثة على مجموعات البيانات القياسية أو قابلة للمقارنة معها. الزيادة في السرعة مقارنة بالطرق السابقة هي نتيجة لتحديد المكونات الرئيسية للخوارزميات السابقة للبحث عن ملامح الوجه وإدراجه لاحقًا في شكل مُحسّن في سلسلة نماذج الانحدار مع عرض نطاق ترددي عالٍ ، تم ضبطه باستخدام زيادة التدرج اللوني.
لقد أثبتنا ، كما فعلنا من قبل [8 ، 2] ، أنه يمكن إجراء البحث عن ملامح الوجه باستخدام سلسلة من نماذج الانحدار. في حالتنا ، يتنبأ كل نموذج انحدار في التسلسل بفعالية شكل الوجه استنادًا إلى التنبؤ الأولي وشدة المجموعة المتفرقة من البكسلات المفهرسة بالنسبة إلى هذه التوقعات الأولية. يستند عملنا على عدد كبير من الدراسات التي أجريت خلال العقد الماضي ، والتي أدت إلى تقدم كبير في مهمة العثور على ملامح الوجه [9 ، 4 ، 13 ، 7 ، 15 ، 1 ، 16 ، 18 ، 3 ، 6 ، 19]. على وجه الخصوص ، لقد أدرجنا في نماذج الانحدار المضبوطة عنصرين رئيسيين موجودين في العديد من الخوارزميات الناجحة أدناه ، والآن نقوم بتفصيل هذه العناصر.

الشكل 1. نتائج مختارة على مجموعة بيانات HELEN. للكشف عن 194 نقطة رئيسية (معالم) على الوجه في صورة واحدة بالميللي ثانية ، يتم استخدام مجموعة من أشجار الانحدار العشوائي.
يدور الأول حول فهرسة شدة البكسل بالنسبة لتوقعات شكل الوجه الحالي. يمكن أن تختلف الميزات المميزة في تمثيل المتجه لصورة الوجه بشكل كبير بسبب تشوه الشكل ، وبسبب عوامل التداخل مثل التغييرات في ظروف الإضاءة. هذا يجعل من الصعب التنبؤ بدقة الشكل باستخدام هذه الوظائف. المعضلة هي أننا نحتاج إلى علامات موثوقة للتنبؤ بدقة بالشكل ، ومن ناحية أخرى ، نحن بحاجة إلى توقع دقيق للشكل لاستخراج علامات موثوقة. في العمل السابق [4 ، 9 ، 5 ، 8] ، وكذلك في هذا العمل ، يتم استخدام نهج تكراري (تتالي) لحل هذه المشكلة. بدلاً من التراجع عن معلمات الشكل بناءً على الميزات المستخرجة في نظام إحداثيات الصورة العالمية ، يتم تحويل الصورة إلى نظام إحداثيات طبيعي استنادًا إلى توقع الشكل الحالي ، ثم يتم استخراج العلامات للتنبؤ بموجه التحديث لمعلمات الشكل. وعادة ما تتكرر هذه العملية عدة مرات حتى التقارب.
يفحص الثاني كيفية التعامل مع تعقيد مشكلة التفسير / التوقع. أثناء الاختبار ، يجب أن تتنبأ خوارزمية البحث المحيطية بشكل الوجه - وهو ناقل عالي الأبعاد يكون في أفضل اتفاق مع بيانات الصورة ونموذج الأشكال لدينا. المشكلة هي nonconvex مع العديد من optima المحلية. تعمل الخوارزميات الناجحة [4 ، 9] على حل هذه المشكلة ، بافتراض أن النموذج المتوقع يجب أن يكمن في فضاء فرعي خطي يمكن اكتشافه ، على سبيل المثال ، من خلال إيجاد المكونات الرئيسية لنماذج التدريب. هذا الافتراض يقلل بشكل كبير من عدد الأشكال المحتملة التي تم النظر فيها أثناء التفسير ، ويمكن أن يساعد في تجنب أوبتيما المحلية.
يستغل عمل حديث [8 ، 11 ، 2] حقيقة أن فئة معينة من المعتكفات مضمونة لإنشاء تنبؤات تكمن في الفضاء الفرعي الخطي المحدد في نماذج التعلم ، وليس هناك حاجة لقيود إضافية. من المهم أن تحتوي نماذج الانحدار لدينا على هذين العنصرين.
يرتبط هذان العاملان بتدريبنا الفعال في نموذج الانحدار. نحن نحسن وظيفة الخسارة المقابلة ونجري اختيار الميزة على أساس البيانات. على وجه الخصوص ، نقوم بتدريب كل ضاغط باستخدام التدرج المعزز [10] باستخدام وظيفة الفقد التربيعي ، وهي نفس وظيفة الفقد التي نريد تقليلها أثناء الاختبار. يتم تحديد مجموعة البكسل المتناثر المستخدمة كمدخلات إلى regressor باستخدام مزيج من خوارزمية زيادة التدرج واحتمال مسبق للمسافات بين أزواج وحدات البكسل المدخلة. يسمح التوزيع المسبق لخوارزمية التعزيز بالتحقيق الفعال لعدد كبير من الميزات ذات الصلة. والنتيجة هي سلسلة من التراجع التي يمكن توطين معالم الوجه عند التهيئة من الأمام.
المساهمات الرئيسية في هذه المقالة هي:
- طريقة جديدة للعثور على ملامح الوجه ، استنادًا إلى مجموعة من أشجار الانحدار (أشجار القرار) ، والتي تقوم باختيار الميزات الثابتة للنموذج ، مع تقليل وظيفة الخسارة نفسها أثناء التدريب الذي نريد تقليله أثناء الاختبار.
- نقدم امتدادًا طبيعيًا لأسلوبنا الذي يعالج العلامات المفقودة أو غير المحددة.
- يتم تقديم النتائج الكمية والنوعية ، والتي تؤكد أن طريقتنا تعطي تنبؤات عالية الجودة ، كونها أكثر فاعلية من أفضل طريقة سابقة (الشكل 1).
- يتم تحليل تأثير كمية بيانات التدريب ، واستخدام البيانات ذات العلامات الجزئية والبيانات المعممة على جودة التنبؤات.
2. الطريقة
تقدم هذه المقالة خوارزمية لإجراء تقييم دقيق لموقف معالم الوجه (النقاط الرئيسية) من حيث الكفاءة الحسابية. كما في الأعمال السابقة [8 ، 2] ، يتم استخدام سلسلة من regressors في طريقتنا. في الجزء المتبقي من هذا القسم ، نصف تفاصيل شكل المكونات الفردية للتتالي وكيف نجري التدريب.
2.1. الانحدار تتالي
أولا نقدم بعض التدوين. سمح  إحداثيات y للواحد من معالم الوجه في الصورة I. ثم الموجه
إحداثيات y للواحد من معالم الوجه في الصورة I. ثم الموجه  يشير إلى إحداثيات جميع الوجوه p في I. غالبًا في هذه المقالة نسمي المتجه S شكلًا. نحن نستخدم
يشير إلى إحداثيات جميع الوجوه p في I. غالبًا في هذه المقالة نسمي المتجه S شكلًا. نحن نستخدم  للإشارة إلى تصنيفنا الحالي س
للإشارة إلى تصنيفنا الحالي س  (· ، ·) في التسلسل ، يتوقع متجه التحديث من الصورة و الذي يضاف إلى تقييم النموذج الحالي لتحسين التصنيف:
(· ، ·) في التسلسل ، يتوقع متجه التحديث من الصورة و الذي يضاف إلى تقييم النموذج الحالي لتحسين التصنيف:
 ) (1)
) (1)
النقطة الرئيسية في الشلال هي أن المراجع يجعل تنبؤاته بناءً على سمات مثل شدة البكسل المحسوبة بواسطة I والمفهرسة بالنسبة لتقدير الشكل الحالي . يقدم هذا نوعًا من الثبات الهندسي في العملية ، وكلما تقدمت خلال السلسلة ، يمكنك أن تكون واثقًا من أن الموقع الدلالي الدقيق على الوجه مفهرس. سنقوم لاحقًا بوصف كيفية إجراء هذا الفهرسة.
يرجى ملاحظة أن نطاق المخرجات الذي تم تمديده من قبل المجموعة مضمون في المساحة الفرعية الخطية لبيانات التدريب إذا كان التقدير الأولي  ينتمي إلى هذا الفضاء. لذلك ، لا نحتاج إلى فرض قيود إضافية على التنبؤات ، الأمر الذي يبسط طريقة عملنا إلى حد كبير. يمكن ببساطة اختيار النموذج الأولي كنموذج متوسط لبيانات التدريب ، يتم توسيطه وتحجيمه وفقًا لإخراج الصندوق المحيط لجهاز كشف الوجه العام.
ينتمي إلى هذا الفضاء. لذلك ، لا نحتاج إلى فرض قيود إضافية على التنبؤات ، الأمر الذي يبسط طريقة عملنا إلى حد كبير. يمكن ببساطة اختيار النموذج الأولي كنموذج متوسط لبيانات التدريب ، يتم توسيطه وتحجيمه وفقًا لإخراج الصندوق المحيط لجهاز كشف الوجه العام.
لتثقيف الجميع نستخدم خوارزمية التدرج المعزز للأشجار مع مجموع الخسائر التربيعية ، كما هو موضح في [10]. الآن سنقدم تفاصيل مفصلة لهذه العملية.
2.2. تدريب كل التراجع في سلسلة
لنفترض أن لدينا بيانات التدريب  حيث الجميع
حيث الجميع  هي صورة الوجه ، و
هي صورة الوجه ، و  ناقلات الشكل. لمعرفة أول وظيفة الانحدار
ناقلات الشكل. لمعرفة أول وظيفة الانحدار  في التتالي ، نقوم بإنشاء ثلاثة توائم من بيانات التدريب الخاصة بنا لصورة الوجه وتوقعات الشكل الأولي وخطوة التحديث الهدف ، أي
في التتالي ، نقوم بإنشاء ثلاثة توائم من بيانات التدريب الخاصة بنا لصورة الوجه وتوقعات الشكل الأولي وخطوة التحديث الهدف ، أي  أين
أين
 (2)
(2)
 (3) و
(3) و
 (4)
(4)
لأني = 1 ، ... ، N.
قمنا بتعيين العدد الإجمالي لهذه التوائم على N = nR ، حيث R هو عدد التهيئة المستخدمة في الصورة Ii. يتم تحديد كل توقعات الشكل الأولي للصورة بالتساوي من  بدون بديل.
بدون بديل.
على هذه البيانات نقوم بتدريب وظيفة الانحدار  (انظر الخوارزمية 1) باستخدام التدرج التدريجي للأشجار مع مجموع الخسائر التربيعية. ثم يتم تحديث مجموعة التدريب الثلاثي لتوفير بيانات التدريب.
(انظر الخوارزمية 1) باستخدام التدرج التدريجي للأشجار مع مجموع الخسائر التربيعية. ثم يتم تحديث مجموعة التدريب الثلاثي لتوفير بيانات التدريب.  ٪ 20) للراجل التالي
٪ 20) للراجل التالي  في تتالي عن طريق الإعداد (مع ر = 0).
في تتالي عن طريق الإعداد (مع ر = 0).
 ٪ 20) (5)
٪ 20) (5)
 (6)
(6)
تتكرر هذه العملية حتى يتم تدريب سلسلة من T regressors.  والتي مجتمعة توفر مستوى كاف من الدقة.
والتي مجتمعة توفر مستوى كاف من الدقة.
كما هو مبين ، كل التراجع يتعلم باستخدام شجرة التدرج تعزيز خوارزمية. يجب أن نتذكر أنه يتم استخدام وظيفة الخسارة التربيعية ، وأن المخلفات المحسوبة في الحلقة الداخلية تتوافق مع التدرج في دالة الخسارة هذه المقدرة في كل عينة تدريب. تتضمن صياغة الخوارزمية معلمة معدل التعلم 0 <ν ≤ 1 ، والمعروفة أيضًا باسم معامل التنظيم. يساعد الإعداد ν <1 على مكافحة إعادة التكوين وعادة ما يؤدي إلى انتكاسات تعمم بشكل أفضل بكثير من المدربين باستخدام ν = 1 [10].
خوارزمية التعلم 1 في الشلال
لدينا بيانات التدريب  ومعدل التعلم (معامل التنظيم) 0 <ν <1
ومعدل التعلم (معامل التنظيم) 0 <ν <1
- تهيئة

- لـ k = 1 ، ... ، K:
أ) وضعناها في i = 1 ، ... ،

ب) نقوم بضبط شجرة الانحدار على الهدف  مع وظيفة الانحدار ضعيفة
مع وظيفة الانحدار ضعيفة  .
.
ج) التحديث 
- استنتاج

2.3. شجرة التراجع
في صميم كل وظيفة انحدار rt توجد انتكاسات تشبه الأشجار مناسبة للأهداف المتبقية أثناء خوارزمية تعزيز التدرج. سننظر الآن في تفاصيل التنفيذ الأكثر أهمية لتدريب كل شجرة انحدار.
في كل عقدة فصل في شجرة الانحدار ، نتخذ قرارًا بناءً على القيمة الدنيا للفرق بين شدة البكسلين. تكون البيكسلات المستخدمة في الاختبار في الموضعين u و v عندما يتم تعريفهما في نظام إحداثيات الشكل الأوسط. بالنسبة لصورة وجه ذي شكل اعتباطي ، نود فهرسة النقاط التي لها نفس الموضع بالنسبة لشكلها مثل u و v للشكل المتوسط. للقيام بذلك ، قبل استخراج العناصر ، يمكن تشويه الصورة إلى الشكل الأوسط بناءً على تقدير الشكل الحالي. نظرًا لأننا لا نستخدم سوى تمثيل متناثر للغاية للصورة ، فإن تشوه ترتيب النقاط أكثر فعالية بكثير من الصورة بأكملها. بالإضافة إلى ذلك ، يمكن إجراء تقريب تقريبي للتشوه باستخدام تحويل التشابه العالمي فقط بالإضافة إلى التشريد المحلي ، كما هو مقترح في [2].
التفاصيل الدقيقة هي كما يلي. سمح  هو مؤشر المعالم على الوجه في النموذج الأوسط الأقرب إليك ، وتحديد إزاحته من u كـ
هو مؤشر المعالم على الوجه في النموذج الأوسط الأقرب إليك ، وتحديد إزاحته من u كـ  .
.
ثم للنموذج سي المحدد في الصورة موقف في ، وهو يشبه نوعيا لك في صورة متوسطة الشكل ، كما هو معروف
 (7)
(7)
حيث و  - مصفوفة المقياس والتناوب للتحويل المتشابه في
- مصفوفة المقياس والتناوب للتحويل المتشابه في  ، الشكل الأوسط.
، الشكل الأوسط.
النطاق والتناوب تقليل
 (8)
(8)
مجموع المربعات بين النقاط البارزة للشكل الأوسط ،  ويشوه نقطة.
ويشوه نقطة.  يعرف بالمثل.
يعرف بالمثل.
بشكل رسمي ، كل قسم هو حل يتضمن 3 معلمات θ = (τ ، u ، v) ، ويتم تطبيقه على كل مثال تدريب واختبار على النحو
 (9)
(9)
حيث  و يتم تحديد باستخدام مصفوفة الحجم والدوران التي تشوه أفضل
و يتم تحديد باستخدام مصفوفة الحجم والدوران التي تشوه أفضل  في وفقا للمعادلة (7). في الممارسة العملية ، يتم تحديد المهام وعمليات النزوح المحلية في مرحلة التدريب. يتم إجراء حساب تحويل التشابه ، أثناء اختبار الجزء الأكثر تكلفة من هذه العملية ، مرة واحدة فقط في كل مستوى من مستويات التسلسل.
في وفقا للمعادلة (7). في الممارسة العملية ، يتم تحديد المهام وعمليات النزوح المحلية في مرحلة التدريب. يتم إجراء حساب تحويل التشابه ، أثناء اختبار الجزء الأكثر تكلفة من هذه العملية ، مرة واحدة فقط في كل مستوى من مستويات التسلسل.
2.3.2 اختيار الأقسام العقدية
بالنسبة لكل شجرة انحدار ، نقدر الوظيفة الأساسية تقريبًا بوظيفة خطية متقطعة ، حيث يكون الموجه الثابت مناسبًا لكل عقدة محددة. لتدريب شجرة الانحدار ، نقوم بشكل عشوائي بإنشاء مجموعة من الأقسام المناسبة ، أي θ ، في كل عقدة. ثم نختار بفارغ الصبر from * من هؤلاء المرشحين ، مما يقلل من مجموع الخطأ التربيعي. إذا كانت Q عبارة عن مجموعة من مؤشرات أمثلة التدريب في العقدة ، فهذا يتوافق مع التقليل
 (10)
(10)
حيث  - مؤشرات الأمثلة التي يتم إرسالها إلى العقدة اليسرى بسبب القرار θ ،
- مؤشرات الأمثلة التي يتم إرسالها إلى العقدة اليسرى بسبب القرار θ ،  هو متجه لجميع البقايا المحسوبة للصورة i في التدرج اللوغاريتم المعزز ، و
هو متجه لجميع البقايا المحسوبة للصورة i في التدرج اللوغاريتم المعزز ، و
 إلى
إلى  (11)
(11)
يمكن العثور على القسم الأمثل بكفاءة عالية ، لأنه إذا حولنا المعادلة (10) وحذفنا عوامل مستقلة عن θ ، يمكننا أن نرى ذلك

هنا نحن بحاجة فقط لحساب  عند تقييم مختلف ، منذ
عند تقييم مختلف ، منذ  يمكن حسابها من متوسط الأهداف في العقدة الأصل µ و على النحو التالي:
يمكن حسابها من متوسط الأهداف في العقدة الأصل µ و على النحو التالي:

2.3.3 اختيار الخصائص
يعتمد الحل في كل عقدة على قيمة الحد للاختلاف في قيم الكثافة في زوج من البكسل. يعد هذا اختبارًا بسيطًا إلى حد ما ، لكنه أكثر فاعلية من قيمة العتبة بكثافة واحدة ، بسبب عدم حساسيته النسبية للتغيرات في الإضاءة العالمية. لسوء الحظ ، يتمثل عيب استخدام اختلافات البكسل في أن عدد المرشحين المحتملين للفصل (الميزة) تربيعي بالنسبة لعدد البكسل في الصورة المتوسطة. هذا يجعل من الصعب العثور على سلع جيدة دون البحث عن عدد كبير جدًا منها. ومع ذلك ، يمكن إضعاف عامل التحديد هذا إلى حد ما ، مع مراعاة بنية بيانات الصورة.
نقدم التوزيع الأسي
 (12)
(12)
بواسطة المسافة بين وحدات البكسل المستخدمة في الانقسام لتشجيع اختيار أزواج أقرب من وحدات البكسل.
لقد وجدنا أن استخدام هذا التوزيع البسيط يقلل من خطأ التنبؤ لعدد من مجموعات بيانات الوجه. يقارن الشكل 4 الميزات المحددة مع وبدونها ، حيث يتم تعيين حجم مجموعة الكائنات في كلتا الحالتين إلى 20.
2.4. التعامل مع المفقودين العلامات
يمكن توسيع مشكلة المعادلة (10) بسهولة للتعامل مع الحالة عندما لا يتم وضع علامة على بعض المعالم في بعض صور التدريب (أو لدينا قدر من عدم اليقين لكل معلم). أدخل المتغير  [0 ، 1] لكل صورة تدريب i وكل معلم j . تركيب
[0 ، 1] لكل صورة تدريب i وكل معلم j . تركيب  تشير القيمة 0 إلى أن المعلم j غير محدد في الصورة الأولى ، والإعداد 1 يشير إلى أنه تم وضع علامة عليه. ثم يمكن تمثيل المعادلة (10) على النحو التالي
تشير القيمة 0 إلى أن المعلم j غير محدد في الصورة الأولى ، والإعداد 1 يشير إلى أنه تم وضع علامة عليه. ثم يمكن تمثيل المعادلة (10) على النحو التالي

حيث  - مصفوفة قطرية مع ناقل
- مصفوفة قطرية مع ناقل  لها قطري و
لها قطري و
 إلى (13)
إلى (13)
يجب أيضًا تعديل خوارزمية التدرج اللوني لأخذ هذه الأوزان في الاعتبار. يمكن القيام بذلك عن طريق تهيئة نموذج المجموعة ببساطة مع القيمة المتوسطة المرجحة للأهداف وتثبيت أشجار الانحدار على البقايا الموزونة في الخوارزمية 1 على النحو التالي
 (14)
(14)
3. التجارب
القواعد: من أجل إجراء تقييم دقيق لأداء طريقتنا المقترحة ، مجموعة أشجار الانحدار (ERT) ، قمنا بإنشاء قاعدتين أخريين. الأول يعتمد على سرخس عشوائي (سرخس عشوائي) مع اختيار عشوائي للسمات (EF) ، والآخر هو نسخة أكثر تقدماً من هذا النهج مع اختيار السمات القائمة على الارتباط (EF + CB) ، وهو تطبيقنا الجديد [2]. يتم إصلاح جميع المعلمات لجميع النهج الثلاثة.
تستخدم EF التنفيذ المباشر للسراخن العشوائية كمثبطات ضعيفة في المجموعة وهي الأسرع في التدريب. نستخدم نفس طريقة التنظيم كما هو مقترح في [2] لتنظيم السرخس.
يستخدم EF + CB طريقة اختيار الكائنات القائمة على الارتباط والتي تتوقع قيم المخرجات ، ، إلى اتجاه عشوائي w وتحديد أزواج من العلامات (u ، v) التي  لديه أعلى عينة ارتباط لبيانات التدريب مع الأهداف المتوقعة
لديه أعلى عينة ارتباط لبيانات التدريب مع الأهداف المتوقعة  .
.
المعلمات
ما لم ينص على خلاف ذلك ، يتم إجراء جميع التجارب باستخدام إعدادات المعلمة الثابتة التالية. عدد التراجع القوي rt في تتالي هو T = 10 ، ولكل منها يتكون من K = 500 التراجع ضعيفة  . عمق الأشجار (أو السرخس) تستخدم لتمثيل ، تعيين يساوي F = 5. في كل مستوى من مستويات السلسلة ، يتم تحديد P = 400 بكسل من الصورة. من أجل تدريب رجعات ضعيفة ، نختار عشوائياً زوجًا من وحدات البكسل هذه وفقًا لتوزيعنا ونختار عتبة عشوائية لإنشاء فصل محتمل ، كما هو موضح في المعادلة (9). يتم تحقيق أفضل فصل عن طريق تكرار هذه العملية S = 20 مرة واختيار العملية التي تحسن هدفنا. لإنشاء بيانات تدريب لدراسة نموذجنا ، نستخدم R = 20 تهيئة مختلفة لكل مثال تدريب.
. عمق الأشجار (أو السرخس) تستخدم لتمثيل ، تعيين يساوي F = 5. في كل مستوى من مستويات السلسلة ، يتم تحديد P = 400 بكسل من الصورة. من أجل تدريب رجعات ضعيفة ، نختار عشوائياً زوجًا من وحدات البكسل هذه وفقًا لتوزيعنا ونختار عتبة عشوائية لإنشاء فصل محتمل ، كما هو موضح في المعادلة (9). يتم تحقيق أفضل فصل عن طريق تكرار هذه العملية S = 20 مرة واختيار العملية التي تحسن هدفنا. لإنشاء بيانات تدريب لدراسة نموذجنا ، نستخدم R = 20 تهيئة مختلفة لكل مثال تدريب.
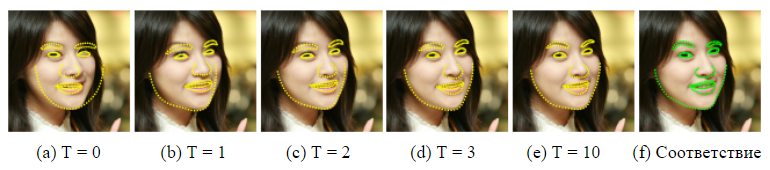
الشكل 2. تنبؤات المعالم على مستويات مختلفة من الشلال ، مع تهيئة الشكل الأوسط في الوسط على إخراج كاشف الوجه الأساسي فيولا آند جونز [17]. بعد المستوى الأول من التسلسل ، يتم بالفعل تقليل الخطأ بالفعل.
O (TKF). O (NDTKF S), N — , D — . HELEN [12], .
, , HELEN [12], , , . 2330 , 194 . 2000 , .
LFPW [1], 1432 . , 778 216 , , .
مقارنة
1 . (Active Shape Models) — STASM [14] CompASM [12].

1. HELEN. — . . , . , . .
, , . 3 , , ERT , . , EF + CB . , EF + CB , .
LFPW [1] ( 2). EF + CB , [2]. ( , .) , , .

2. LFPW. 1.
4 (12) , , . λ 0,1 . . 4 .

3. . , , . (12).
, . , . — . ν 1 ( ν = 0.1). . , , , ν = 1. (10 ) . ( .)
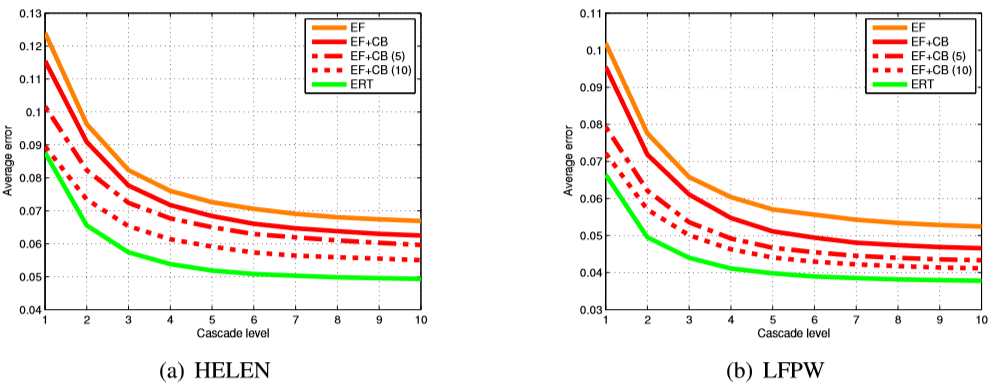
3. HELEN (a) LFPW (b). EF — , EF + CB — , . (5 10), [2]. , (ERT), , , .

4. , . , .
, . , .

4. HELEN . .
, . , , , , .
. . 5 . , , [8, 2] ( 10 × 400 .)

5. .
بيانات التدريب من
أجل اختبار فعالية طريقتنا من حيث عدد صور التدريب ، قمنا بتدريب نماذج مختلفة من مجموعات فرعية مختلفة من بيانات التدريب. يلخص الجدول 6 النتائج النهائية ، ويبين الشكل 5 رسمًا بيانيًا للأخطاء في كل مستوى من السلسلة. يعد استخدام العديد من مستويات التراجع مفيدًا للغاية عندما يكون لدينا عدد كبير من أمثلة التدريب.
كررنا نفس التجارب مع عدد إجمالي ثابت من الأمثلة الموسعة ، لكننا قمنا بتغيير مجموعة النماذج الأولية المستخدمة لإنشاء مثال تدريبي من مثال واضح للوجه وعدد من الصور المشروحة المستخدمة لدراسة التسلسل (الجدول 7).

جدول 6. معدل الخطأ النهائي لعدد أمثلة التدريب. عند إنشاء بيانات تدريب لدراسة مسجلات التتالي ، ولدت كل صورة وجه معلمة 20 مثال تدريبي ، باستخدام 20 وجهًا مختلفًا ذا علامات تمييز كإفتراض أولي حول شكل الوجه.
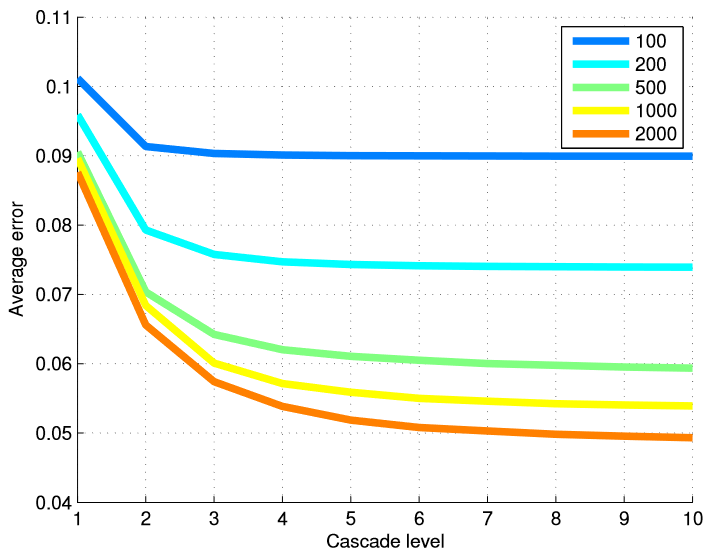
الشكل 5. يتم تقديم متوسط الخطأ في كل مستوى من سلسلة تتالي اعتمادا على عدد من الأمثلة التدريب المستخدمة. يكون استخدام العديد من مستويات التراجع مفيدًا للغاية عندما يكون عدد أمثلة التدريب كبيرًا.
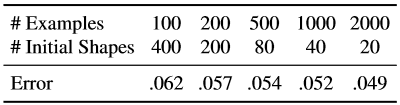
جدول 7. هنا يتم إصلاح عدد فعال من أمثلة التدريب ، لكننا نستخدم مجموعات مختلفة من عدد الصور التدريب وعدد النماذج الأولية المستخدمة لكل صورة وجه ملحوظ.
تؤدي زيادة بيانات التدريب باستخدام مجموعة متنوعة من النماذج الأولية إلى توسيع مجموعة البيانات من حيث الشكل. تظهر نتائجنا أن هذا النوع من الملحقات لا يعوض بشكل كامل عن عدم وجود صور تدريب مشروحة. على الرغم من أن معدل التحسن الذي تم الحصول عليه عن طريق زيادة عدد الصور التدريبية يتناقص بسرعة بعد بضع مئات من الصور.
شروح جزئية
يوضح الجدول 8 نتائج استخدام البيانات المشروحة جزئيًا. 200 دراسة حالة مشروحة بالكامل ، والباقي جزئيًا فقط.

جدول 8. النتائج باستخدام البيانات المميزة جزئيا. 200 أمثلة موضحة تمامًا دائمًا. تشير القيم الموجودة بين قوسين إلى النسبة المئوية للمعالم المرصودة.
تظهر النتائج أنه يمكننا تحقيق تحسن كبير باستخدام بيانات تحمل علامات جزئية. ومع ذلك ، قد لا يتم تشبع التحسين المعروض ، لأننا نعرف أن الحجم الأساسي لمعلمات الشكل أقل بكثير من حجم المعالم (194 × 2). وبالتالي ، هناك احتمال لمزيد من التحسن مع وجود علامات جزئية ، إذا استخدمت بوضوح العلاقة بين موضع المعالم. يرجى ملاحظة أن إجراء التدرج اللوني الموصوف في هذه المقالة لا يستخدم الارتباط بين المعالم. يمكن حل هذه المشكلة في العمل في المستقبل.
4. الخلاصة
وصفنا كيف يمكن استخدام مجموعة من أشجار الانحدار لتراجع موقع معالم الوجه من مجموعة فرعية متفرقة من قيم الكثافة المستخرجة من صورة الإدخال. الهيكل المعروض يقلل الخطأ بشكل أسرع من العمل السابق ، ويمكنه أيضًا معالجة العلامات الجزئية أو غير المحددة. في حين أن المكونات الرئيسية لخوارزمية لدينا تعتبر القياسات المستهدفة المختلفة كمتغيرات مستقلة ، فإن الاستمرار الطبيعي لهذا العمل هو استخدام ارتباط معلمات النموذج لتدريب أكثر فعالية واستخدام أفضل للعلامات الجزئية.

الشكل 6. النتائج النهائية في قاعدة بيانات HELEN.
شكر
تم تمويل هذا العمل من قبل مؤسسة الأبحاث الاستراتيجية السويدية كجزء من مشروع VINST.
الأدب المستخدم
[1] PN Belhumeur و DW Jacobs و DJ Kriegman و N. Kumar. توطين أجزاء من الوجوه باستخدام إجماع من النماذج. في CVPR ، الصفحات 545-552 ، 2011. 1 ، 5
[2] X. Cao و Y. Wei و F. Wen و J. Sun. محاذاة الوجه عن طريق الانحدار الصريح. في CVPR ، الصفحات 2887-2894 ، 2012. 1 ، 2 ، 3 ، 4 ، 5 ، 6
[3] TF Cootes ، M. Ionita ، C. Lindner ، و P. Sauer. نموذج قوي ودقيق الشكل المناسب باستخدام التصويت الانحدار الغابات عشوائي. في ECCV ، 2012.1
[4] TF Cootes و CJ Taylor و DH Cooper و J. Graham. نماذج الشكل النشط-تدريبهم وتطبيقهم. رؤية الكمبيوتر وفهم الصورة ، 61 (1): 38-59 ، 1995.1 ، 2
[5] D. Cristinacce و TF Cootes. تعزيز الانحدار نماذج الشكل النشط. في BMVC ، الصفحات 79.1-79.10 ، 2007.1
[6] M. Dantone و J. Gall و G. Fanelli و LV Gool. في الوقت الحقيقي الكشف عن ميزة الوجه باستخدام غابات الانحدار الشرطي. في CVPR ، 2012.1
[7] L. Ding و AM Mart´ınez. الكشف الدقيق عن الوجوه وميزات الوجه. في CVPR ، 2008.1
[8] P. Dollar و P. Welinder و P. Perona. تتالي تتشكل regres- ion sion. في CVPR ، الصفحات 1078-1085 ، 2010. 1 ، 2 ، 6
[9] جي جي إدواردز ، TF Cootes ، و CJ Taylor. التقدم في نماذج المظهر النشط. في ICCV ، الصفحات 137-142 ، 1999. 1 ، 2
[10] T. Hastie ، R. Tibshirani ، و JH Friedman. عناصر التعلم الإحصائي: التنقيب عن البيانات والاستدلال والتنبؤ. نيويورك: سبرينغر فيرلاغ ، 2001.2 ، 3
[11] ف. كاظمي وج. سوليفان. محاذاة الوجه مع النمذجة المستندة إلى جزء. في BMVC ، الصفحات 27.1-27.10 ، 2011.2
[12] V. Le، J. Brandt، Z. Lin، LD Bourdev، and TS Huang. تعريب ميزة الوجه التفاعلية. في [13] L. Liang و R. Xiao و F. Wen و J. Sun. محاذاة الوجه عبر البحث التمييزي القائم على المكون. في ECCV ، الصفحات 72-85 ، 2008. 1ECCV ، الصفحات 679- 692 ، 2012.5
[14] S. Milborrow and F. Nicolls. تحديد ملامح الوجه مع نموذج الشكل النشط الموسعة. في ECCV ، الصفحات 504-513 ، 2008.5
[15] ج. ساراجيه ، س. لوسي ، و جيه كوهن. تركيب نموذج قابل للتشوه بواسطة تحويلات متوسطة منتظمة. المجلة الدولية لرؤية الكمبيوتر ، 91: 200-215 ، 2010.1
[16] BM Smith و L. Zhang. محاذاة الوجه المشترك مع نماذج الشكل غير البارامترية. في ECCV ، الصفحات 43-56 ، 2012.1
[17] PA Viola و MJ Jones. قوي في الوقت الحقيقي كشف الوجه. في ICCV ، الصفحة 747 ، 2001.5
[18] X. Zhao و X. Chai و S. Shan. محاذاة وجه المفصل: انقاذ محاذاة سيئة مع تلك الجيدة عن طريق إعادة تركيب منتظمة. في ECCV ، 2012.1
[19] X. Zhu and D. Ramanan. كشف الوجه ، وتقدير تشكل ، وتوطين المعالم في البرية. في CVPR ، الصفحات 2879-2886 ، 2012.1