مرحبا بالجميع! عُقد مؤتمر حول تطوير التطبيقات المحملة بدرجة عالية HighLoad ++ Siberia 2019 في نوفوسيبيرسك في يونيو / حزيران. في وقت سابق من المقالات حول Habré ، ذكرنا أننا في Plesk نجري بأثر رجعي من المؤتمرات والتقارير التي نحضرها حتى لا نفقد المعرفة المكتسبة ومن ثم تطبيقها. سنخبرك بالتقارير التي لاحظناها لأنفسنا ، كما سنطلعك على وصفة استعادية. يقوم المنظمون بنشر الفيديو تدريجياً هنا:
قناة يوتيوب . جزء مما نصفه يمكن رؤيته بالفعل.
نظرة عامة على التقارير
فيكتور إريمتشينكو (ميرو)هذا هو تقرير مراجعة حول الترحيل الناجح لـ Redis -> PostgreSQL -> Pgbouncer + PostgreSQL -> Patroni Consul + Pgbouncer + PostgreSQL. يقدم المؤلف مخططات ، ومخاطر نموذجية من الحلول الواضحة ، ويتحدث عن حلول بديلة ولماذا لم تكن ملائمة. من المثير للاهتمام:
- قام مهندسو Miro بتجميع حلهم حتى لا يدفعوا مقابل Amazon RDS ، وهذا الحل يناسبهم حتى الآن.
- Likbez على مديري الاتصال ل PostgreSQL.
- وصف عملية تحديث عقد نظام المجموعة دون إيقاف التطبيق.
- يعرض خدعة لتحديث PostgreSQL بسرعة.
من المفيد أن نرى أولئك الذين يستخدمون أو سيستخدمون PostgreSQL ، والذين لديهم كمية متزايدة من البيانات.
فاسيلي بوجوناتوف (ياندكس)كمتحدث تمهيدي ، أجرى مقارنة موجزة لبعض ميزات Kafka و RabbitMQ. باختصار: كافكا - قائمة انتظار بسيطة ، متلقي معقد ؛ RabbitMQ هي قائمة انتظار معقدة ، وجهاز استقبال بسيط. تحدث المؤلف أيضًا عن أنواع الضمانات لتوصيل رسالة من قائمة الانتظار. ملاحظة مهمة: لا توجد طابور يمكن أن يضمن تسليم الرسالة بالضبط مرة واحدة دون دعم من المرسل والمستلم.
التقرير مخصص لـ YandexMQ. YandexMQ (YMQ) عبارة عن واجهة برمجة تطبيقات متوافقة مع قائمة انتظار Amazon SQS. أساس YandexMQ هو قاعدة بيانات Yandex (YDB). أظهر فاسيلي ميزة YandexMQ ، وكيفية تحقيق الاتساق والموثوقية الصارمة ، وقدم لمحة عامة عن بنية YMQ. YMQ تنفذ نمط المستهلكين المتنافسين - رسالة واحدة لمستهلك واحد. رقاقة YMQ: عندما يسأل المستهلك عن رسالة ، يتم إخفاؤها في قائمة الانتظار حتى لا يأخذها أي شخص آخر إلى المعالجة. إذا كانت هناك مشاكل أثناء المعالجة ، فبعد VisibilityTimeout تصبح الرسالة مرئية في قائمة الانتظار مرة أخرى. يدعي المتحدث أن Apache Kafka لديه مشكلة في فقدان البيانات عندما يتم قتل العملية فجأة ، Yandex MessageQueue مقاومة لذلك.

يوصى بالتقرير لكل من يريد فهم السمات الأساسية لقوائم الانتظار.
إيفان مرادوف (شركة المراقبة الأولى)قم بالإبلاغ عن كيفية تخزين ومعالجة البيانات في سلسلة زمنية PostgreSQL.
يتيح لك TimescaleDB تخزين وحدات تخزين كبيرة بسبب التقسيم الماكرة ، ويوفر PipelineDB العمل مع تدفقات مباشرة في PostgreSQL (وكذلك التكامل مع قوائم الانتظار).
TimescaleDB:
- لها سرعة تسجيل مستقرة للغاية مع زيادة في حجم قاعدة البيانات تحت الأحمال الثقيلة مع زيادة في عدد الأقسام ، ويقاس بالآلاف.
- يتيح لك استخدام ميزات PostgreSQL القياسية مثل SQL والنسخ المتماثل والنسخ الاحتياطي والاستعادة ، إلخ.
- يتم الإعلان عن مجموعة جيدة من عمليات الدمج ، على سبيل المثال ، مع Prometheus و Telegraf و Grafana و Zabbix و Kubernetes.
- هناك نسخة مجانية مفتوحة المصدر.
الفكرة الرئيسية: هناك حاجة إلى TimescaleDB بشكل أساسي لتخزين البيانات.
PipelineDB:
- يتيح لك معالجة البيانات الواردة باستمرار باستخدام SQL وإضافة النتيجة إلى جدول.
- لديه واجهة SQL.
- هناك أداء الإجراءات المخزنة في ظل هذه الظروف.
- التكامل مع اباتشي كافكا و Amazon Kinesis ممكن.
- هناك نسخة مجانية مفتوحة المصدر.
- يتم تجميد تطوير PipelineDB في الإصدار 1.0 ، والآن يتم إصدار إصلاحات الأخطاء فقط.
الفكرة الرئيسية: PipelineDB ضرورية في المقام الأول لمعالجة البيانات.
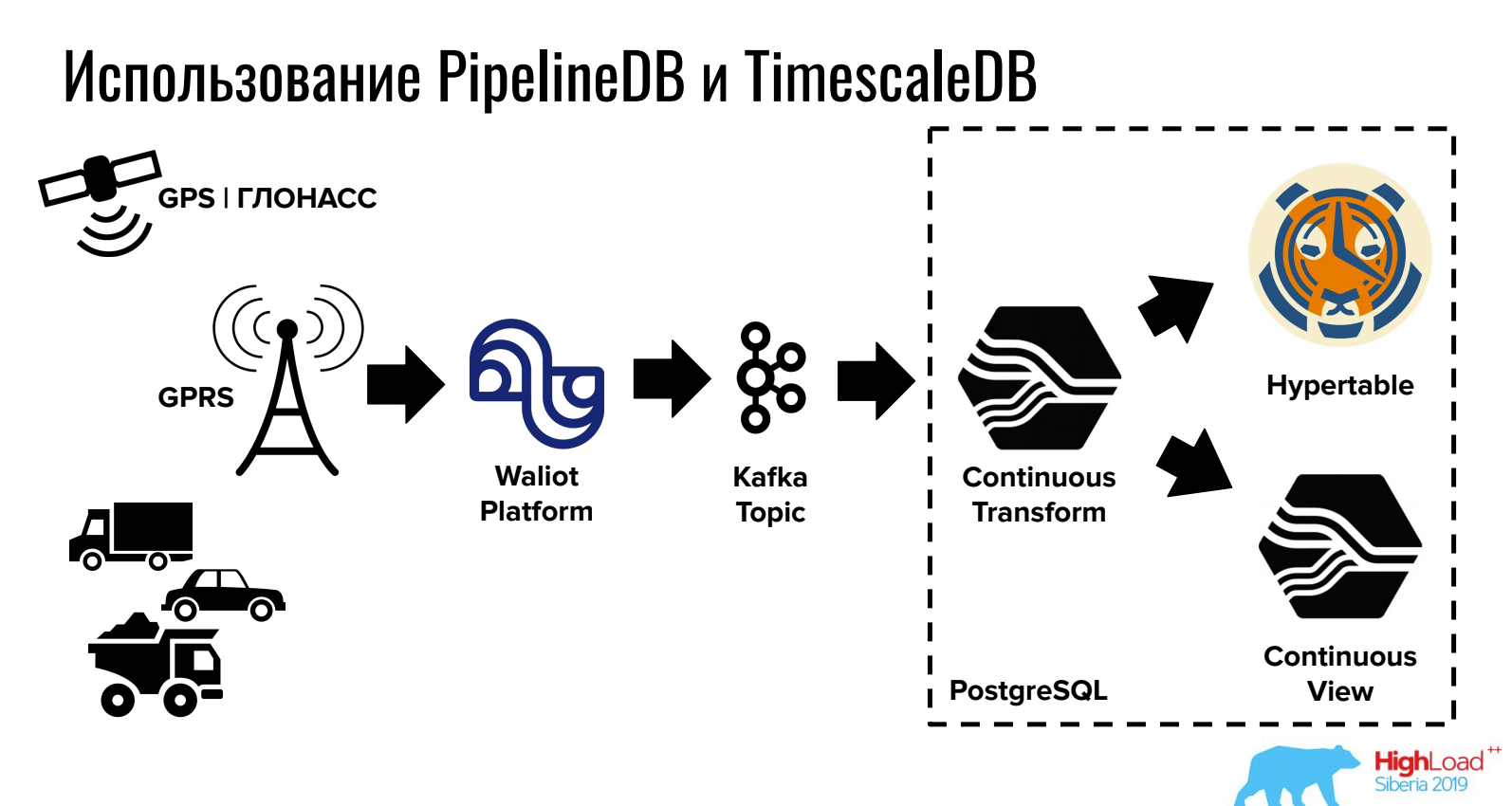
بالنسبة للمهام التي تتطلب وجود قواعد بيانات علائقية و NoSQL وسلسلة زمنية في نفس الوقت ، يمكن أن يكون هذا الخيار مناسبًا تمامًا.
بافل لوزانوف (Postgres Professional)تقرير عام جيد عن PostgreSQL ووراثة المائدة وأداء النصائح والخدع لـ PostgreSQL 10 و 11 و 12+. التقسيم من خلال الميراث ، التقسيم. من المفيد رؤية كل من يستخدم PostgreSQL ويريد أن يجعلها أسرع قليلاً.
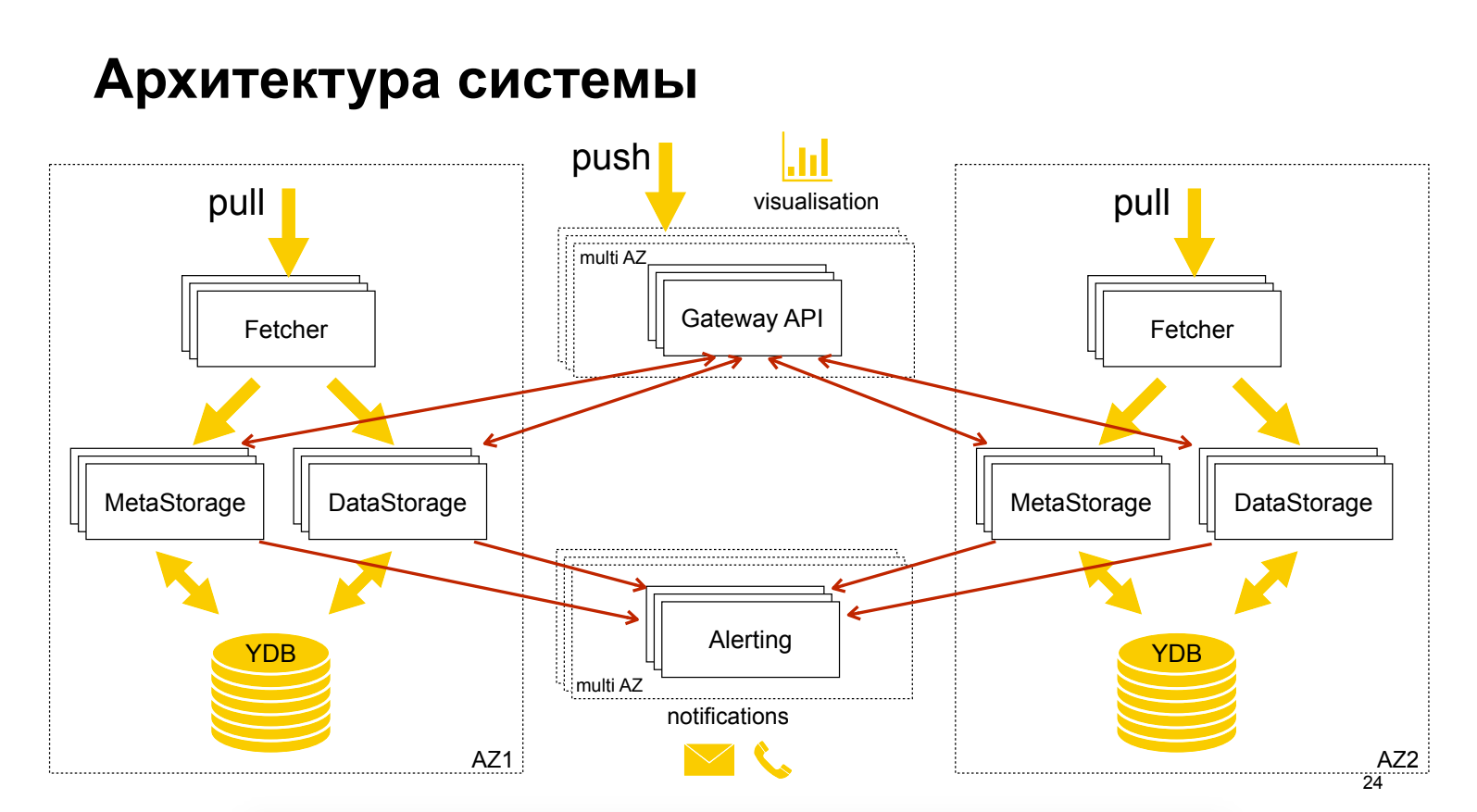
سيرجي بولوفكو (ياندكس)حول المنتج السحابي Yandex Monitoring ، والذي لا يزال في مرحلة "المعاينة" ، مجاني. قليلا جدا عن الهندسة المعمارية. يتم عرض تقنية مثيرة للاهتمام - فصل البيانات الوصفية عن البيانات ، والتي تتيح التحجيم والتحسين المستقلين. يستخدم Grafana باعتباره واجهة المستخدم الرسومية ، في حين أن تنبيهاتها ليست في Grafana.
 أندريه سالنيكوف (بيانات البلشون)
أندريه سالنيكوف (بيانات البلشون)خبرة في إدارة النظام التجاري للعديد من خوادم PostgreSQL. إنها تخبر عن معلمات الخادم التي تتم مراقبتها تلقائيًا ، وكيفية تحديد أولويات المهام.
يستخدم Data Egret تجربة معممة في الويكي مع الوصفات وقوائم المراجعة - وهذا هو الأساس للمقالات والتقارير المستقبلية. يستخدمون قاعدة بيانات الحوادث مع وصف للمشاكل والحلول - وهذا يوفر بشكل كبير الموارد. أصدر عددًا من الأدوات المساعدة للعمل مع PostgreSQL ، وفر روابط لهم.
 يفغيني سوكولوف (Yandex.Market)
يفغيني سوكولوف (Yandex.Market)قم بالإبلاغ عن بنية تطبيق Yandex.Market المعقد والموزع للغاية والموزع وعن العمليات والأدوات اللازمة لتطويره واختباره وتحديثه ومراقبته. من المثير للاهتمام:
- "Stop-crane" هو الحل للتطبيق السريع واستعادة التكوين ، فهو يساعد على اختبار وظائف جديدة.
- تتم إعادة توجيه حركة المرور من مركز البيانات الحالي بواسطة الموازن إلى مركز بيانات آخر في حالة حدوث مشاكل.
- وتستخدم الجرافيت وغرافانا للمراقبة.
- هناك مكررة مراقبة أساسية على كومة تقنية أخرى.
- يتم استخدام مجموعة الظل للمطورين ، والتي تكرر جزءًا من حركة مرور المستخدم. لا يرى المستخدمون استجابات نظام الظل.
- يتم إجراء حساب الجودة التلقائي أثناء اختبار A / B.
 انطون الكسيف (2GIS)
انطون الكسيف (2GIS)قم بالإبلاغ عن ما هو مفيد في ClickHouse وكيفية طبخه بالاشتراك مع Grafana. للاهتمام الرئيسي:
- إذا لم تكن هناك سرعة كافية ، فيجب عليك استخدام أخذ العينات (يُقال إن دقة البيانات بعد أخذ العينات كافية). أخذ العينات في ClickHouse - أخذ عينات جزئية من البيانات مع التجميع مع الحفاظ على نسبة القيم المختلفة في مفتاح الجدول ، يسمح لك بتسريع التجميع في بعض الأحيان وفي نفس الوقت تكون النتيجة قريبة جدًا من القيمة الحقيقية.
- يمكن استخدام ClickHouse للتحقيق بسرعة في الحوادث (مثال مثير للاهتمام في التقرير).
- لديها ClickHouse أيضا على MaterializedView لتسريع جلب.
- يوصف ClickHouse HTTP interface للاستعلام وتحميل البيانات.
في ختام مراجعة التقارير ، أود أن أشير إلى أننا بالفعل أحببنا التقرير
"مكالمات الفيديو: من الملايين يوميًا إلى 100 مشارك في مؤتمر واحد" (
ألكساندر توبول / أودنوكلنيكي) ، الذي تم تضمينه في قائمة أفضل تقارير المؤتمر وفقًا لنتائج التصويت. هذه نظرة عامة رائعة على كيفية عمل مؤتمرات الفيديو لمجموعة من المشاركين. يتميز التقرير بعرض تقديمي مفهوم. إذا كان عليك إجراء مكالمات فيديو فجأة ، فيمكنك مشاهدة التقرير من أجل الحصول على نظرة ثاقبة حول موضوع الموضوع.
هيكل Plesk Conference Flashback
والآن ، للحلوى ، حول كيف نكتب بأثر رجعي داخل الشركة. بادئ ذي بدء ، نحن نحاول كتابة الرجعية في الأسبوع الأول بعد حضور المؤتمر ، في حين أن ذكرياتنا لا تزال حية. بالمناسبة ، يمكن بعد ذلك استخدام المادة الاسترجاعية كأساس لهذه المقالة ، كما قد تتخيل ؛)
ليس الغرض من كتابة أثر رجعي هو تعزيز المعرفة فحسب ، بل أيضًا مشاركتها مع أولئك الذين لم يحضروا المؤتمر ، ولكنهم يريدون مواكبة أحدث الاتجاهات والحلول المثيرة للاهتمام. تساعد القائمة الجاهزة في تقليل وقت البحث عن تقارير مثيرة للاهتمام لعرضها. نكتب الدروس التي تعلمناها من أجل أنفسنا ، ونذكر أشخاص محددين بمذكرة ، لماذا تحتاج إلى رؤية التقرير والتفكير في أفكار وقرارات الآخرين. تساعد الدروس المكتوبة على التركيز وعدم فقدان ما أردنا القيام به. بالنظر إلى التسجيلات في 3-6 أشهر ، سوف نفهم ما إذا كنا قد نسينا شيئًا مهمًا.
نقوم بتخزين الوثائق في الشركة في Confluence ، وللمؤتمرات لدينا شجرة صفحة منفصلة ، قطعة من الخشب:
كما يتضح من لقطة الشاشة ، فنحن نضع المواد كل عام لسهولة التصفح.
داخل الصفحة المخصصة لمؤتمر معين ، نقوم بتخزين الأقسام التالية: نظرة عامة مع روابط إلى موقع الحدث ، والجدول الزمني ، ومقاطع الفيديو والعروض التقديمية ، وقائمة المشاركين (شخصيا وعلى البث) ، والانطباع العام (الانطباع العام) ونظرة عامة مفصلة (نظرة عامة مفصلة) ). بالمناسبة ، نقوم بإنشاء صفحة للرجعية من قالب يوجد به الهيكل بأكمله بالفعل. نصنع أيضًا محتويات العناوين بحيث يمكنك عرض قائمة التقارير بسرعة كبيرة والانتقال إلى القائمة المطلوبة.
يقدم قسم الانطباع العام تقييمًا موجزًا للمؤتمر ويعطي انطباعات المشاركين. إذا كان المشاركون في المؤتمر في السنوات الماضية ، فيمكنهم مقارنة مستوياتهم وفهم فائدة حضور هذا الحدث بشكل عام.
يحتوي قسم النظرة العامة التفصيلية على جدول:

مثال على ملء الجدول:

سنكون مهتمين بمعرفة التقارير التي أعجبتني في Highload Siberia 2019 ، بالإضافة إلى خبرتك في إدارة الأحداث الماضية.