مرحبا يا هبر.
في
الجزء الأول ، تم اعتبار NVIDIA Jetson Nano - لوحة في عامل الشكل Raspberry Pi الذي يركز على حوسبة الأداء باستخدام GPU. لقد حان الوقت لاختبار اللوحة في ما تم إنشاؤه من أجله - لإجراء عمليات حسابية موجهة نحو الذكاء الاصطناعى.

فكر في كيفية تنفيذ المهام المختلفة على اللوحة ، مثل تصنيف الصور أو التعرف على المشاة أو الأختام (حيث بدونها). لجميع الاختبارات ، يمكن تشغيل الكود المصدري على سطح المكتب أو Jetson Nano أو Raspberry Pi. بالنسبة لأولئك الذين يهتمون ، واصلت تحت خفض.
هناك طريقتان لاستخدام هذا المنتدى. الأول هو تشغيل الأطر القياسية مثل Keras و Tensorflow. ستعمل من حيث المبدأ ، لكنها ستعمل ، ولكن كما رأينا بالفعل من الجزء الأول ، فإن Jetson Nano ، بالطبع ، أدنى من بطاقة فيديو سطح المكتب أو الكمبيوتر المحمول الكاملة. سيتعين على المستخدم تولي مهمة تحسين النموذج. الطريقة الثانية هي أخذ دروس جاهزة تأتي مع السبورة. إنه أبسط ويعمل "خارج الصندوق" ، الطرح هو أن جميع تفاصيل التنفيذ مخفية إلى حد كبير ، بالإضافة إلى ذلك ، سيتعين عليك الدراسة واستخدام custom-sdk ، والتي ، إلى جانب هذه اللوحات ، لن تكون مفيدة في أي مكان آخر. ومع ذلك ، سوف ننظر في كلا الاتجاهين ، نبدأ مع الأول.
تصنيف الصورة
النظر في مشكلة التعرف على الصور. للقيام بذلك ، سوف نستخدم طراز ResNet50 المرفق مع Keras (كان هذا النموذج هو الفائز في تحدي ImageNet في عام 2015). لاستخدامها ، بضعة أسطر من التعليمات البرمجية كافية.
import tensorflow as tf import numpy as np import time IMAGE_SIZE = 224 IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) resnet = tf.keras.applications.ResNet50(input_shape=IMG_SHAPE) img = tf.contrib.keras.preprocessing.image.load_img('cat.png', target_size=(IMAGE_SIZE, IMAGE_SIZE)) t_start = time.time() img_data = tf.contrib.keras.preprocessing.image.img_to_array(img) x = tf.contrib.keras.applications.resnet50.preprocess_input(np.expand_dims(img_data, axis=0)) probabilities = resnet.predict(x) print(tf.contrib.keras.applications.resnet50.decode_predictions(probabilities, top=5)) print("dT", time.time() - t_start)
لم أكن حتى تبدأ في إزالة الكود تحت المفسد ، لأنه هو صغير جدا. كما ترون ، تم تغيير حجم الصورة أولاً إلى 224x224 (هذا هو تنسيق شبكة الإدخال) ، في النهاية ، تقوم دالة التنبؤ بكامل مهامها.
نلتقط صورة القط وندير البرنامج.

النتائج:
[[('n02123045', 'tabby', 0.765179), ('n02123159', 'tiger_cat', 0.19059166), ('n02124075', 'Egyptian_cat', 0.013605555), ('n04493381', 'tub', 0.0025916891), ('n04553703', 'washbasin', 0.0021566998)]]
مرة أخرى ، مستاءًا من معرفته باللغة الإنجليزية (أتساءل كم من الأشخاص غير الأصليين يعرفون ماهية "العتاب"؟) ، لقد راجعت المخرجات بالقاموس ، نعم ، كل شيء يعمل.
كان وقت تنفيذ كود الكمبيوتر هو
0.5 ثانية لإجراء العمليات الحسابية على وحدة المعالجة المركزية و 2 ثانية (!) لإجراء العمليات الحسابية على وحدة معالجة الرسومات. إذا حكمنا من خلال السجل ، فإن المشكلة هي إما في النموذج أو في Tensorflow ، ولكن عندما يبدأ تشغيله ، يحاول الرمز تخصيص قدر كبير من الذاكرة ، والحصول على العديد من التحذيرات من النموذج "Allocator (GPU_0_bfc) نفدت الذاكرة في محاولة تخصيص 2.13GiB مع freed_by_count = 0." . هذا تحذير وليس خطأ ، يعمل الرمز ، لكنه أبطأ بكثير مما يجب.
في Jetson Nano ، لا يزال أبطأ:
2.8c على وحدة المعالجة المركزية و
18.8 c على وحدة معالجة الرسومات ، في حين أن الإخراج يبدو كما يلي:
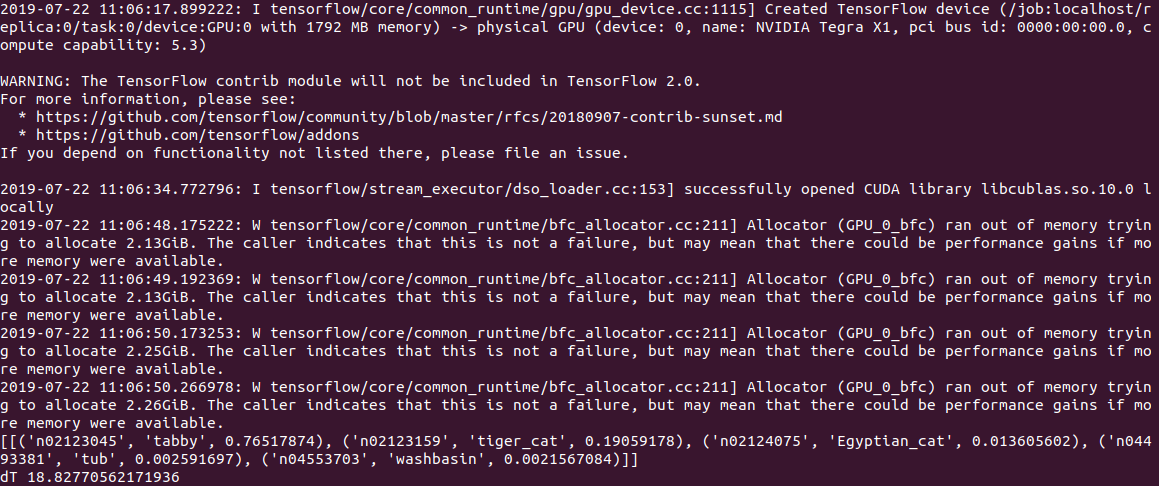
بشكل عام ، حتى 3 ثوانٍ لكل صورة ، هذا ليس وقتًا حقيقيًا بعد. لا يساعد تعيين الخيار gpu_options.allow_growth الموصى به على تجاوز سعة المكدس ، إذا كان أي شخص يعرف طريقة أخرى ، فاكتب في التعليقات.
التعديل : كما هو مطلوب في التعليقات ، فإن البداية الأولى لـ tensorflow تستغرق دائمًا وقتًا طويلًا ، ومن الخطأ قياس الوقت في استخدامها. في الواقع ، عند معالجة الملفات الثانية واللاحقة ، تكون النتائج أفضل بكثير - 0.6 ثانية بدون وحدة معالجة الرسومات و 0.2 ثانية باستخدام وحدة معالجة الرسومات. على سطح المكتب ، تكون السرعة 2.0 و 0.05 ثانية على التوالي.
ميزة ملائمة لـ ResNet50 هي أنه في البداية ، يضخ النموذج بأكمله على القرص (حوالي 100 ميجابايت) ، ثم يعمل الرمز بشكل مستقل تمامًا ، دون تسجيل ورسائل نصية قصيرة. وهو أمر لطيف بشكل خاص ، نظرًا لأن معظم خدمات AI الحديثة تعمل فقط على الخادم ، وبدون الإنترنت ، يتحول الجهاز إلى "قرع".
القطط مقابل الكلاب
النظر في المشكلة التالية. باستخدام Keras ، سننشئ شبكة عصبية يمكنها التمييز بين القطط والكلاب. ستكون شبكة عصبية تلافيفية (CNN - شبكة عصبية تلافيفية) ، سنتخذ تصميم الشبكة من
هذا المنشور. يتم تضمين مجموعة تدريب من صور القطط والكلاب بالفعل في حزمة tensorflow_datasets ، لذلك لن تضطر إلى تصويرها بنفسك.
نقوم بتحميل مجموعة من الصور وتقسيمها إلى ثلاث كتل - التدريب والتحقق والاختبار. نحن "تطبيع" كل صورة ، وبذلك تصل الألوان إلى المدى 0..1.
import tensorflow as tf from tensorflow.keras import layers import tensorflow_datasets as tfds from keras.preprocessing import image import numpy as np import time IMAGE_SIZE = 64 IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) splits = tfds.Split.TRAIN.subsplit(weighted=(80, 10, 10)) (cat_train, cat_valid, cat_test), info = tfds.load('cats_vs_dogs', split=list(splits), with_info=True, as_supervised=True) label_names = info.features['label'].int2str def pre_process_image(image, label): image = tf.cast(image, tf.float32) image = image / 255.0
نكتب وظيفة توليد شبكة عصبية تلافيفية.
def custom_model():
الآن يمكننا تشغيل التدريب على الشبكة على مجموعة "كلب القط". يستغرق التدريب وقتًا طويلاً (20 دقيقة على وحدة معالجة الرسومات و 1-2 ساعات على وحدة المعالجة المركزية) ، لذلك في النهاية نقوم بحفظ النموذج في ملف.
tl_model = custom_model() t_start = time.time() tl_model.fit(train_batch, steps_per_epoch=8000, epochs=2, validation_data=validation_batch, validation_steps=10, callbacks=None) print("Training done, dT:", time.time() - t_start) print(tl_model.summary()) validation_steps = 20 loss0, accuracy0 = tl_model.evaluate(validation_batch, steps=validation_steps) print("Loss: {:.2f}".format(loss0)) print("Accuracy: {:.2f}".format(accuracy0)) tl_model.save("dog_cat_model.h5")
بالمناسبة ، فشلت محاولة بدء التدريب مباشرة على Jetson Nano - بعد 5 دقائق ، ارتفعت درجة الحرارة على اللوحة وتعليقها. لإجراء عمليات حسابية كثيفة الاستخدام للموارد ، يلزم وجود مبرد للوحة ، رغم أنه لا يوجد أي معنى للقيام بهذه المهام مباشرةً على Jetson Nano - يمكنك تدريب النموذج على جهاز كمبيوتر واستخدام الملف المحفوظ النهائي على Nano.
تم العثور على مأزق آخر هنا - تم تثبيت مكتبة tensowflow الإصدار 14 على جهاز الكمبيوتر ، وكان آخر إصدار لـ Jetson Nano حتى الآن هو 13. ولم يتم قراءة النموذج المحفوظ في الإصدار 14 في الثالث عشر ، واضطررت إلى تثبيت نفس الإصدارات باستخدام pip.
أخيرًا ، يمكننا تحميل النموذج من ملف واستخدامه للتعرف على الصور.
def predict_model(model, image_file): img = image.load_img(image_file, target_size=(IMAGE_SIZE, IMAGE_SIZE)) t_start = time.time() img_arr = np.expand_dims(img, axis=0) result = model.predict_classes(img_arr) print("Result: {}, dT: {}".format(label_names(result[0][0]), time.time() - t_start)) model = tf.keras.models.load_model('dog_cat_model.h5') predict_model(model, "cat.png") predict_model(model, "dog1.png") predict_model(model, "dog2.png")
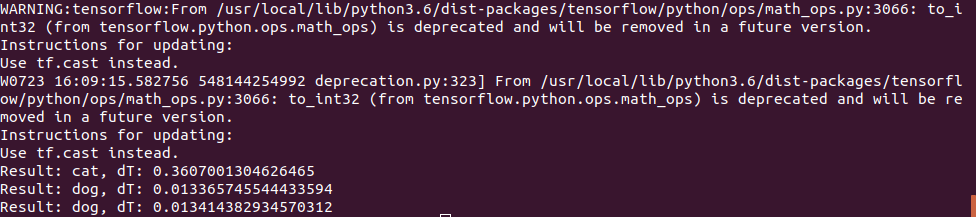
تم استخدام صورة القطة بنفس الطريقة ، لكن في اختبار "الكلب" تم استخدام صورتين:

الأول خمن بشكل صحيح ، والثاني في البداية كان لديه أخطاء والشبكة العصبية اعتقدت أنها كانت قطة ، وكان علي أن أزيد من عدد مرات تكرار التدريب. ومع ذلك ، ربما كنت قد ارتكبت خطأ في المرة الأولى ؛)
تبين أن وقت التنفيذ على Jetson Nano كان صغيراً للغاية - فقد تمت معالجة الصورة الأولى في 0.3 ثانية ، لكن كل الصور اللاحقة كانت أسرع بكثير ، ويبدو أن البيانات مخبأة في الذاكرة.
بشكل عام ، يمكننا أن نفترض أنه على مثل هذه الشبكات العصبية البسيطة ، تكون سرعة اللوحة كافية تمامًا حتى من دون أي تحسينات ، 100fps هي قيمة كافية حتى للفيديو في الوقت الفعلي.
استنتاج
كما ترون ، يمكن استخدام حتى الطرز القياسية من Keras و Tensorflow على Nano ، وإن كان ذلك بدرجات متفاوتة من النجاح - شيء ما يعمل ، شيء ما لا يعمل. ومع ذلك ، يمكن تحسين النتائج ، ويمكن قراءة التعليمات حول تحسين النموذج وتقليل حجم الذاكرة
هنا .
لكن لحسن الحظ بالنسبة لنا ، قام المصنعون بالفعل بهذا من أجلنا. إذا ظل اهتمام القراء ، سيتم تخصيص الجزء الأخير
للمكتبات الجاهزة المُحسّنة للعمل مع Jetson Nano.