
نواصل نشر تحليلات المهام التي تم اقتراحها في البطولة الأخيرة. التالي في السطر هي المهام التي اتخذت من جولة التأهيل لأخصائيي التعلم الآلي. هذا هو المسار الثالث من أربعة (الخلفية ، الواجهة الأمامية ، ML ، التحليلات). يحتاج المشاركون إلى صنع نموذج لتصحيح الأخطاء المطبعية في النصوص ، واقتراح استراتيجية للعب على ماكينات القمار ، ووضع نظام توصيات للمحتوى ، وإنشاء عدة برامج أخرى.
أ. الأخطاء المطبعية
حالة
(الكتابة) (من منتدى واحد)
- من يتكون هذا الهراء؟
- علماء الفيزياء الفلكية. هم الناس أيضا.
- لقد ارتكبت 10 أخطاء في كلمة "الصحفيين".
يرتكب العديد من المستخدمين أخطاء في الكتابة ، بعضها بسبب ضرب المفاتيح ، والبعض الآخر بسبب أميتهم. نريد التحقق مما إذا كان المستخدم يمكن أن يعني في الواقع كلمة أخرى غير الكلمة التي كتبها.
بشكل أكثر رسمية ، افترض أن نموذج الخطأ التالي يحدث: يبدأ المستخدم بكلمة يريد كتابتها ، ثم يقوم بعد ذلك بعدد من الأخطاء فيها. كل خطأ هو استبدال لبعض سلسلة فرعية من الكلمة لسلسلة فرعية أخرى. خطأ واحد يتوافق مع استبدال فقط في موقف واحد (أي إذا كان المستخدم يريد أن يرتكب خطأ واحد من قبل القاعدة "abc" → "cba" ، ثم من سلسلة "abcabc" يمكنه الحصول على "cbaabc" أو "abccba"). بعد كل خطأ ، تتكرر العملية. يمكن استخدام نفس القاعدة عدة مرات في خطوات مختلفة (على سبيل المثال ، في المثال أعلاه ، يمكن الحصول على "cbacba" في خطوتين).
يجب تحديد الحد الأدنى لعدد الأخطاء التي يمكن أن يرتكبها المستخدم إذا كان يفكر في كلمة معينة وكتب كلمة أخرى.
تنسيقات I / O ومثالتنسيق الإدخال
يحتوي السطر الأول على الكلمة التي ، حسب افتراضنا ، كان المستخدم في ذهنه (تتكون من أحرف الأبجدية اللاتينية في الأحرف الصغيرة ، لا يتجاوز الطول 20).
يحتوي السطر الثاني على الكلمة التي كتبها بالفعل (وهي تتألف أيضًا من أحرف الأبجدية اللاتينية في الأحرف الصغيرة ، لا يتجاوز الطول 20).
يحتوي السطر الثالث على رقم واحد N (N <50) - هو عدد البدائل التي تصف الأخطاء المختلفة.
تحتوي الأسطر N التالية على بدائل محتملة في تنسيق & lt "الحروف" التسلسل & gt <space> <تسلسل الحروف "الخاطئة">. التسلسلات لا يزيد طولها عن 6 أحرف.
تنسيق الإخراج
يجب طباعة رقم واحد - وهو الحد الأدنى لعدد الأخطاء التي قد يرتكبها المستخدم. إذا تجاوز هذا الرقم 4 أو كان من المستحيل الحصول على آخر من كلمة واحدة ، فقم بطباعة -1.
مثال
قرار
دعنا نحاول إنشاء كل الكلمات الممكنة من الإملاء الصحيح دون أكثر من 4 أخطاء. في أسوأ الحالات ، قد يكون هناك O ((L﹒N)
4 ). في حدود المشكلة ، هذا عدد كبير إلى حد ما ، لذلك تحتاج إلى معرفة كيفية الحد من التعقيد. بدلاً من ذلك ، يمكنك استخدام خوارزمية الالتقاء في الوسط: إنشاء كلمات لا تزيد عن 2 أخطاء ، وكذلك الكلمات التي يمكنك من خلالها الحصول على كلمة مكتوبة بواسطة المستخدم مع عدم وجود أكثر من خطأين. لاحظ أن حجم كل مجموعة من هذه المجموعات لن يتجاوز 10
6 . إذا لم يتجاوز عدد الأخطاء التي ارتكبها المستخدم 4 ، فسوف تتقاطع هذه المجموعات. وبالمثل ، يمكننا التحقق من أن عدد الأخطاء لا يتجاوز 3 و 2 و 1.
struct FromTo { std::string from; std::string to; }; std::pair<size_t, std::string> applyRule(const std::string& word, const FromTo &fromTo, int pos) { while(true) { int from = word.find(fromTo.from, pos); if (from == std::string::npos) { return {std::string::npos, {}}; } int to = from + fromTo.from.size(); auto cpy = word; for (int i = from; i < to; i++) { cpy[i] = fromTo.to[i - from]; } return {from, std::move(cpy)}; } } void inverseRules(std::vector<FromTo> &rules) { for (auto& rule: rules) { std::swap(rule.from, rule.to); } } int solve(std::string& wordOrig, std::string& wordMissprinted, std::vector<FromTo>& replaces) { std::unordered_map<std::string, int> mapping; std::unordered_map<int, std::string> mappingInverse; mapping.emplace(wordOrig, 0); mappingInverse.emplace(0, wordOrig); mapping.emplace(wordMissprinted, 1); mappingInverse.emplace(1, wordMissprinted); std::unordered_map<int, std::unordered_set<int>> edges; auto buildGraph = [&edges, &mapping, &mappingInverse](int startId, const std::vector<FromTo>& replaces, bool dir) { std::unordered_set<int> mappingLayer0; mappingLayer0 = {startId}; for (int i = 0; i < 2; i++) { std::unordered_set<int> mappingLayer1; for (const auto& v: mappingLayer0) { auto& word = mappingInverse.at(v); for (auto& fromTo: replaces) { size_t from = 0; while (true) { auto [tmp, wordCpy] = applyRule(word, fromTo, from); if (tmp == std::string::npos) { break; } from = tmp + 1; { int w = mapping.size(); mapping.emplace(wordCpy, w); w = mapping.at(wordCpy); mappingInverse.emplace(w, std::move(wordCpy)); if (dir) { edges[v].emplace(w); } else { edges[w].emplace(v); } mappingLayer1.emplace(w); } } } } mappingLayer0 = std::move(mappingLayer1); } }; buildGraph(0, replaces, true); inverseRules(replaces); buildGraph(1, replaces, false); { std::queue<std::pair<int, int>> q; q.emplace(0, 0); std::vector<bool> mask(mapping.size(), false); int level{0}; while (q.size()) { auto [w, level] = q.front(); q.pop(); if (mask[w]) { continue; } mask[w] = true; if (mappingInverse.at(w) == wordMissprinted) { return level; } for (auto& v: edges[w]) { q.emplace(v, level + 1); } } } return -1; }
B. العصابات المسلحة
حالة
هذه مهمة تفاعلية.
أنت نفسك لا تعرف كيف حدث ذلك ، ولكنك وجدت نفسك في قاعة بها آلات القمار مع حقيبة كاملة من الرموز. للأسف ، في شباك التذاكر ، يرفضون قبول الرموز المميزة ، وقررت تجربة حظك. هناك العديد من ماكينات القمار في القاعة التي يمكنك لعبها. لعبة واحدة مع فتحة آلة تستخدم رمز واحد. في حالة الفوز ، يمنحك الجهاز دولارًا واحدًا ، في حالة الخسارة - لا شيء. كل جهاز لديه احتمالية ثابتة للفوز (لا تعرفه) ، لكنه يختلف عن الأجهزة المختلفة. بعد دراسة موقع الشركة المصنعة لهذه الآلات ، اكتشفت أن احتمال الفوز لكل جهاز يتم اختياره عشوائيًا في مرحلة التصنيع من
توزيع بيتا مع بعض المعلمات.
تريد زيادة أرباحك المتوقعة إلى الحد الأقصى.
تنسيقات I / O ومثالتنسيق الإدخال
قد يتكون تنفيذ واحد من عدة اختبارات.
يبدأ كل اختبار بحقيقة أن البرنامج على الخط يحتوي على عددين صحيحين مفصولين بمسافة: الرقم N هو عدد الرموز في حقيبتك ، و M هو عدد الآلات في القاعة (N ≤ 10
4 ، M ≤ min (N ، 100) ). يحتوي السطر التالي على رقمين حقيقيين α و β (1 ≤ α و β ≤ 10) - معلمات التوزيع التجريبي لاحتمال الفوز.
بروتوكول الاتصال مع نظام التحقق هو هذا: يمكنك تقديم طلبات N بالضبط. لكل طلب ، اطبع في سطر منفصل رقم الجهاز الذي ستلعبه (من 1 إلى M ضمناً). كإجابة ، في سطر منفصل سيكون هناك إما "0" أو "1" ، وهذا يعني على التوالي خسارة وفوز في لعبة مع آلة القمار المطلوبة.
بعد الاختبار الأخير ، بدلاً من الأرقام N و M ، سيكون هناك صفرين.
تنسيق الإخراج
سيتم اعتبار المهمة مكتملة إذا لم يكن قرارك أسوأ من قرار لجنة التحكيم. إذا كان قرارك أسوأ بكثير من قرار هيئة المحلفين ، فستتلقى الحكم "إجابة خاطئة".
من المضمون أنه إذا كان قرارك ليس أسوأ من قرار هيئة المحلفين ، فإن احتمال تلقي الحكم "إجابة خاطئة" لا يتجاوز
10-6 .
الملاحظات
مثال التفاعل:
____________________ stdin stdout ____________________ ____________________ 5 2 2 2 2 1 1 0 1 1 2 1 2 1
قرار
هذه المشكلة معروفة جيدًا ، ويمكن حلها بطرق مختلفة. طبق القرار الرئيسي لهيئة المحلفين استراتيجية
أخذ عينات Thompson ، ولكن نظرًا لأن عدد الخطوات كان معروفًا في بداية البرنامج ، فهناك استراتيجيات أكثر مثالية (على سبيل المثال ، UCB1). علاوة على ذلك ، يمكن للمرء حتى الحصول على مع استراتيجية الجشع epsilon: مع وجود احتمال معين ، تلعب آلة عشوائية ومع الاحتمال (1 - ε) تلعب آلة مع أفضل إحصائيات النصر.
class SolverFromStdIn(object): def __init__(self): self.regrets = [0.] self.total_win = [0.] self.moves = [] class ThompsonSampling(SolverFromStdIn): def __init__(self, bandits_total, init_a=1, init_b=1): """ init_a (int): initial value of a in Beta(a, b). init_b (int): initial value of b in Beta(a, b). """ SolverFromStdIn.__init__(self) self.n = bandits_total self.alpha = init_a self.beta = init_b self._as = [init_a] * self.n
C. محاذاة الجمل
حالة
واحدة من أهم المهام لتدريب نموذج الترجمة الآلية الجيدة هي حالة جيدة من الجمل المتوازية. عادةً ما يكون مصدر العروض المتوازية مستندات موازية. اتضح أنه في كثير من الأحيان لبناء مجموعة معينة من الجمل المتوازية ، لا تحتاج إلى معرفة أي شيء سوى أطوالها. على وجه الخصوص ، قد تلاحظ أنه كلما طالت مدة الجملة في لغة المصدر ، كلما تمت ترجمتها على الأرجح. تكمن بعض الصعوبات في حقيقة أنه أثناء الترجمة يمكن أن يتغير عدد الجمل في النص: في بعض الأحيان يمكن دمج جملتين متجاورتين في الترجمة في جملة واحدة ، أو العكس - يمكن تقسيم جملة واحدة إلى جملتين. في بعض الحالات النادرة ، قد يتم حذف الجمل بالكامل في الترجمة ، أو قد تظهر الترجمة في الترجمة التي لم تكن بالأصل.
بشكل أكثر رسمية ، افترض أن النموذج التوليفي التالي للمرفقات الموازية صحيح. في كل خطوة ، نقوم بأحد الإجراءات التالية:
1. توقفمع الاحتمال p
h ، ينتهي توليد الأجسام.
2. [1-0] تخطي العروضمع الاحتمال p
d نسند جملة واحدة إلى النص الأصلي. نحن لا ننسب أي شيء للترجمة. يتم تحديد طول الجملة باللغة الأصلية L ≥ 1 من التوزيع المنفصل:
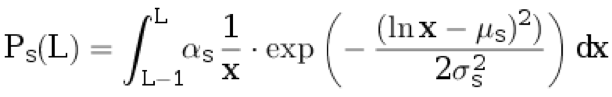
.
فيما يلي معلمات التوزيع ، و
α s هي معامل التطبيع المختار بحيث

.
3. [0-1] أدخل الاقتراحمع الاحتمال p
i نخصص جملة واحدة للترجمة. نحن لا ننسب أي شيء إلى الأصل. يتم تحديد طول الجملة في لغة الترجمة L ≥ 1 من توزيع منفصل:

.
هنا،
t ،
σ t هي معلمات التوزيع ، و
α t هي معامل التطبيع المختار بحيث

.
4. الترجمةمع الاحتمال (1 - p
d - p
i - p
h ) نأخذ طول الجملة باللغة الأصلية L
s ≥ 1 من التوزيع p
s (مع التقريب لأعلى). بعد ذلك ، نقوم بإنشاء طول الجملة في لغة الترجمة L
t ≥ 1 من التوزيع المنفصل الشرطي:
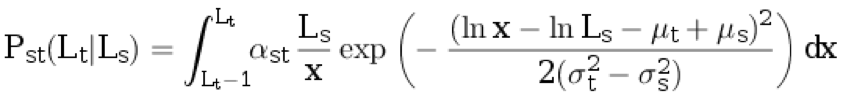
.
هنا
α st هو معامل التطبيع ، ويتم وصف المعلمات المتبقية في الفقرات السابقة.
التالي هو خطوة أخرى:
1. [2-1] مع الاحتمال p
split s ، تنقسم الجملة المولدة في اللغة الأصلية إلى كلمتين غير فارغتين ، بحيث يزيد العدد الإجمالي للكلمات
بواحدة . احتمال أن تنفصل جملة الطول L
s إلى أجزاء من الطول L
1 و L
2 (أي L
1 + L
2 = L
s + 1) تتناسب مع P
s (L
1 ) ⋅ P
s (L
2 ).
2. [1-2] مع وجود الاحتمال p
split t ، تنقسم الجملة التي تم إنشاؤها في اللغة الهدف إلى جملتين غير فارغتين ، بحيث يزيد العدد الإجمالي للكلمات بحرف واحد. احتمال أن تنفصل جملة الطول L
t إلى أجزاء من الطول L1 و L2 (أي L
1 + L
2 = L
t + 1) تتناسب مع P
t (L
1 ) ⋅ P
t (L
2 ).
3. 3. [1-1] مع احتمال (1 - p
split s - p
split t ) ، لن يتحلل أي من الجمل المتولدة.
I / O التنسيقات والأمثلة والملاحظاتتنسيق الإدخال
يحتوي السطر الأول من الملف على معلمات التوزيع: p
h ، p
d ، p
i ، p
split s ، p
split t ،،
s ، σ
s ، μ
t ، σ
t . 0.1 ≤ σ
s <σ
t ≤ 3. 0 ≤ μ
s ، μ
t ≤ 5.
يحتوي السطر التالي على الأرقام N
s و N
t - عدد الجمل في الحالة باللغة الأصلية وباللغة الهدف ، على التوالي (1 ≤ N
s و N
t ≤ 1000).
يحتوي السطر التالي على أعداد صحيحة N - أطوال الجمل في اللغة الأصلية. يحتوي السطر التالي على أعداد صحيحة N
t - أطوال الجمل في اللغة الهدف.
يحتوي السطر التالي على رقمين: j و k (1 ≤ j ≤ N
s ، 1 ≤ k ≤ N
t ).
تنسيق الإخراج
من الضروري اشتقاق احتمال أن تكون الجمل ذات الفهارس j و k في النصوص ، على التوالي ، متوازية (أي ، يتم إنشاؤها في خطوة واحدة من الخوارزمية وليس أي منها ناتج عن الانحلال).
سيتم قبول إجابتك إذا كان الخطأ المطلق لا يتجاوز
10-4 .
مثال 1
مثال 2
مثال 3
الملاحظات
في المثال الأول ، يمكن الحصول على التسلسل الأولي للأرقام بثلاث طرق:
• أولاً ، مع الاحتمال p
d أضف جملة واحدة إلى النص الأصلي ، ثم مع الاحتمال p
i أضف جملة واحدة إلى الترجمة ، ثم مع الاحتمال p
h أنهي التوليد.
احتمال هذا الحدث هو P
1 = p
d * P
s (4) * p
i * P
t (20) * p
h .
• أولاً ، مع الاحتمال p
d أضف جملة واحدة إلى النص الأصلي ، ثم مع الاحتمال p
i أضف جملة واحدة إلى الترجمة ، ثم مع الاحتمال p
h أنهي التوليد.
احتمال هذا الحدث يساوي P
2 = p
i * P
t (20) * p
d * P
s (4) * p
h .
• مع الاحتمال (1 - p
h - p
d - p
i ) قم بإنشاء جملتين ، ثم مع الاحتمال (1 - p
split s - p
split t ) اترك كل شيء كما هو (أي ، لا تقسم الأصل أو الترجمة إلى جملتين ) وبعد ذلك مع الاحتمال p
h ينهي الجيل.
احتمال هذا الحدث هو

.
نتيجة لذلك ، يتم حساب الإجابة كـ

.
قرار
المهمة هي حالة خاصة من المحاذاة باستخدام نماذج Markov المخفية (محاذاة HMM). الفكرة الرئيسية هي أنه يمكنك حساب احتمال إنشاء زوج معين من المستندات باستخدام هذا النموذج
وخوارزمية إعادة التوجيه : في هذه الحالة ، تكون الحالة عبارة عن بادئات من المستندات. وفقًا لذلك ، يمكن حساب الاحتمال المطلوب لمحاذاة زوج معين من الجمل المتوازية بواسطة خوارزمية
الأمام والخلف .
قانون #include <iostream> #include <iomanip> #include <cmath> #include <vector> double p_h, p_d, p_i, p_tr, p_ss, p_st, mu_s, sigma_s, mu_t, sigma_t; double lognorm_cdf(double x, double mu, double sigma) { if (x < 1e-9) return 0.0; double res = std::log(x) - mu; res /= std::sqrt(2.0) * sigma; res = 0.5 * (1 + std::erf(res)); return res; } double length_probability(int l, double mu, double sigma) { return lognorm_cdf(l, mu, sigma) - lognorm_cdf(l - 1, mu, sigma); } double translation_probability(int ls, int lt) { double res = length_probability(ls, mu_s, sigma_s); double mu = mu_t - mu_s + std::log(ls); double sigma = std::sqrt(sigma_t * sigma_t - sigma_s * sigma_s); res *= length_probability(lt, mu, sigma); return res; } double split_probability(int l1, int l2, double mu, double sigma) { int l_sum = l1 + l2; double total_prob = 0.0; for (int i = 1; i < l_sum; ++i) { total_prob += length_probability(i, mu, sigma) * length_probability(l_sum - i, mu, sigma); } return length_probability(l1, mu, sigma) * length_probability(l2, mu, sigma) / total_prob; } double log_prob10(int ls) { return std::log(p_d * length_probability(ls, mu_s, sigma_s)); } double log_prob01(int lt) { return std::log(p_i * length_probability(lt, mu_t, sigma_t)); } double log_prob11(int ls, int lt) { return std::log(p_tr * (1 - p_ss - p_st) * translation_probability(ls, lt)); } double log_prob21(int ls1, int ls2, int lt) { return std::log(p_tr * p_ss * split_probability(ls1, ls2, mu_s, sigma_s) * translation_probability(ls1 + ls2 - 1, lt)); } double log_prob12(int ls, int lt1, int lt2) { return std::log(p_tr * p_st * split_probability(lt1, lt2, mu_t, sigma_t) * translation_probability(ls, lt1 + lt2 - 1)); } double logsum(double v1, double v2) { double res = std::max(v1, v2); v1 -= res; v2 -= res; v1 = std::min(v1, v2); if (v1 < -30) { return res; } return res + std::log(std::exp(v1) + 1.0); } double loginc(double* to, double from) { *to = logsum(*to, from); } constexpr double INF = 1e25; int main(void) { using std::cin; using std::cout; cin >> p_h >> p_d >> p_i >> p_ss >> p_st >> mu_s >> sigma_s >> mu_t >> sigma_t; p_tr = 1.0 - p_h - p_d - p_i; int Ns, Nt; cin >> Ns >> Nt; using std::vector; vector<int> ls(Ns), lt(Nt); for (int i = 0; i < Ns; ++i) cin >> ls[i]; for (int i = 0; i < Nt; ++i) cin >> lt[i]; vector< vector< double> > fwd(Ns + 1, vector<double>(Nt + 1, -INF)), bwd = fwd; fwd[0][0] = 0; bwd[Ns][Nt] = 0; for (int i = 0; i <= Ns; ++i) { for (int j = 0; j <= Nt; ++j) { if (i >= 1) { loginc(&fwd[i][j], fwd[i - 1][j] + log_prob10(ls[i - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j] + log_prob10(ls[Ns - i])); } if (j >= 1) { loginc(&fwd[i][j], fwd[i][j - 1] + log_prob01(lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i][Nt - j + 1] + log_prob01(lt[Nt - j])); } if (i >= 1 && j >= 1) { loginc(&fwd[i][j], fwd[i - 1][j - 1] + log_prob11(ls[i - 1], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 1] + log_prob11(ls[Ns - i], lt[Nt - j])); } if (i >= 2 && j >= 1) { loginc(&fwd[i][j], fwd[i - 2][j - 1] + log_prob21(ls[i - 1], ls[i - 2], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 2][Nt - j + 1] + log_prob21(ls[Ns - i], ls[Ns - i + 1], lt[Nt - j])); } if (i >= 1 && j >= 2) { loginc(&fwd[i][j], fwd[i - 1][j - 2] + log_prob12(ls[i - 1], lt[j - 1], lt[j - 2])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 2] + log_prob12(ls[Ns - i], lt[Nt - j], lt[Nt - j + 1])); } } } int j, k; cin >> j >> k; double rlog = fwd[j - 1][k - 1] + bwd[j][k] + log_prob11(ls[j - 1], lt[k - 1]) - bwd[0][0]; cout << std::fixed << std::setprecision(12) << std::exp(rlog) << std::endl; }
الشريط من التوصيات
حالة
النظر في موجز للتوصيات لمحتوى غير متجانسة. يمزج الكائنات من أنواع مختلفة (الصور ومقاطع الفيديو والأخبار وما إلى ذلك). عادةً ما يتم ترتيب هذه الكائنات حسب صلتها بالمستخدم: كلما كان الكائن (المستخدم) الأكثر صلة بالموضوع ، كلما اقتربنا من أعلى قائمة التوصيات. ومع ذلك ، مع مثل هذا الترتيب ، تنشأ مواقف غالبًا تظهر فيها عدة كائنات من نفس النوع في قائمة التوصيات. يؤدي هذا إلى تفاقم التنوع الخارجي لتوصياتنا إلى حد كبير وبالتالي لا يحب المستخدمون ذلك. من الضروري تنفيذ خوارزمية ، وفقًا لقائمة التوصيات ، ستشكل قائمة جديدة ستكون خالية من هذه المشكلة وستكون ذات صلة.
اسمح بقائمة أولية من التوصيات: = [a
0 ، a
1 ، ...،
n - 1 ] من الطول n> 0. كائن برقم
i كتبته بالرقم b
i 0 {0، ...، m - 1}. بالإضافة إلى ذلك ، يوجد كائن تحت الرقم i ذو صلة r (a
i ) = 2
−i . النظر في القائمة التي تم الحصول عليها من القائمة الأولية عن طريق اختيار مجموعة فرعية من الكائنات والتقليب: x = [a
i 0 ،
i i 1 ، ...،
i k - 1 ] من الطول k (0 ≤ k ≤ n). تُدعى قائمة مقبولة إذا لم يتزامن وجود كائنين متتاليين في النوع ، أي ، b
i j ≠ b
i j + 1 للجميع j = 0 ، ... ، k - 2. يتم احتساب أهمية القائمة من خلال الصيغة
. تحتاج إلى العثور على قائمة الصلة القصوى بين جميع صالحة.
I / O التنسيقات والأمثلةتنسيق الإدخال
في السطر الأول ، تتم كتابة الأرقام n و m بمسافة (1 ≤ n ≤ 100000 ، 1 ≤ m ≤ n). تحتوي الأسطر n التالية على الأرقام b
i لـ i = 0 ، ... ، n - 1 (0 ≤ b
i ≤ m - 1).
تنسيق الإخراج
اكتب ، بمسافة ، عدد الكائنات في القائمة النهائية: i
0 ، i
1 ، ... ، i
k - 1 .
مثال 1
مثال 2
مثال 3
قرار
باستخدام حسابات رياضية بسيطة ، يمكن إثبات أن المشكلة يمكن حلها من خلال نهج "جشع" ، أي في القائمة المثلى للتوصيات ، كل عنصر لديه الكائن الأكثر صلة بكل ما هو صالح في بداية نفس القائمة. تنفيذ هذا النهج بسيط: نأخذ الأشياء على التوالي ونضيفها إلى الإجابة ، إن أمكن. عندما تتم مصادفة كائن غير صالح (يتزامن نوعه مع نوع العنصر السابق) ، فإننا نضعه جانباً في قائمة انتظار منفصلة ، نقوم بإدخاله في الاستجابة في أقرب وقت ممكن. لاحظ أنه في كل لحظة من الزمن ، سيكون لكل الكائنات في قائمة الانتظار نوع مطابق. في النهاية ، قد تبقى عدة كائنات في قائمة الانتظار ، ولن يتم تضمينها في الاستجابة.
std::vector<int> blend(int n, int m, const std::vector<int>& types) { std::vector<int> result; std::queue<int> repeated; for (int i = 0; i < n; ++i) { if (result.empty() || types[result.back()] != types[i]) { result.push_back(i); if (!repeated.empty() && types[repeated.front()] != types[result.back()]) { result.push_back(repeated.front()); repeated.pop(); } } else { repeated.push(i); } } return result; }
D. تجميع تسلسل الأحرف
هناك أبجدية محددة A = {a
1 ، a
2 ، ...،
K - 1 ، a
K = S}، a ∈ {a، b، ...، z}، S هي نهاية السطر.
النظر في الطريقة التالية لإنشاء سلاسل عشوائية على الأبجدية A:
1. الحرف الأول x
1 هو متغير عشوائي مع التوزيع P (x
1 = a
i ) = q
i (من المعروف أن q
K = 0).
2. يتم إنشاء كل حرف تالي بناءً على الحرف السابق وفقًا للتوزيع الشرطي P (x
i = a
j || x
i - 1 = a
l ) = p
jl .
3. إذا كانت x
i = S ، يتوقف الجيل وتكون النتيجة x
1 ×
2 ... x
i - 1 .
يتم توفير مجموعة من الخطوط الناتجة من مزيج من نموذجين الموصوفة مع معلمات مختلفة. من الضروري أن يعطي كل صف فهرس السلسلة التي تم إنشاؤه منها.
تنسيقات I / O ، مثال ، وملاحظاتتنسيق الإدخال
يحتوي السطر الأول على رقمين 1000 ≤ N ≤ 2000 و 3 ≤ K ≤ 27 - عدد الخطوط وحجم الأبجدية ، على التوالي.
يحتوي السطر الثاني على سطر يتكون من K - 1 بأحرف صغيرة مختلفة من الأبجدية اللاتينية ، يشير إلى العناصر K - 1 الأولى من الأبجدية.
يتم إنشاء كل سطر من الأسطر N التالية وفقًا للخوارزمية الموضحة في الشرط.
تنسيق الإخراج
أسطر N ، يحتوي السطر i على رقم الكتلة (0/1) للتسلسل على السطر i + 1-th لملف الإدخال. يجب أن تكون مصادفة الإجابة الحقيقية 80٪ على الأقل.
مثال
الملاحظات
ملاحظة للاختبار من الشرط: فيه يتم إنشاء الخطوط 50 الأولى من التوزيع
P (x
i = a | x
i - 1 = a) = 0.5، P (x
i = S | x
i - 1 = a) = 0.5، P (x
1 = a) = 1؛ 50 الثانية - من التوزيع
P (x
i = b | x
i - 1 = b) = 0.5، P (x
i = S | x
i - 1 = b) = 0.5، P (x
1 = b) = 1.
قرار
تم حل المشكلة باستخدام
خوارزمية EM : من المفترض أن يتم إنشاء العينة المقدمة من خليط من اثنين من سلاسل Markov التي يتم استعادة المعلمات أثناء التكرار. تم وضع قيود بنسبة 80٪ من الإجابات الصحيحة بحيث لا تتأثر صحة الحل بأمثلة ذات احتمال كبير في كلتا السلسلتين. لذلك ، عند استعادة هذه الأمثلة بشكل صحيح ، يمكن تعيينها إلى سلسلة غير صحيحة من حيث الاستجابة التي تم إنشاؤها.
import random import math EPS = 1e-9 def empty_row(size): return [0] * size def empty_matrix(rows, cols): return [empty_row(cols) for _ in range(rows)] def normalized_row(row): row_sum = sum(row) + EPS return [x / row_sum for x in row] def normalized_matrix(mtx): return [normalized_row(r) for r in mtx] def restore_params(alphabet, string_samples): n_tokens = len(alphabet) n_samples = len(string_samples) samples = [tuple([alphabet.index(token) for token in s] + [n_tokens - 1, n_tokens - 1]) for s in string_samples] probs = [random.random() for _ in range(n_samples)] for _ in range(200): old_probs = [x for x in probs]
.