كما تعلمون ، تلعب الفهارس دورًا مهمًا في نظام إدارة قواعد البيانات (DBMS) ، حيث توفر بحثًا سريعًا عن السجلات اللازمة. لذلك ، من المهم جدًا خدمتهم في الوقت المناسب. لقد كتب الكثير من المواد عن التحليل والتحسين ، بما في ذلك على الإنترنت. على سبيل المثال ، تم إجراء مراجعة حديثة لهذا الموضوع في
هذا المنشور .
هناك العديد من الحلول المدفوعة والمجانية لهذا الغرض. على سبيل المثال ، يوجد
حل جاهز يعتمد على طريقة تحسين الفهرس التكيفي.
بعد ذلك ، خذ بعين الاعتبار الأداة المساعدة
SQLIndexManager المجانية ، التي
ألفها AlanDenton .
يتكون الفرق الفني الرئيسي بين SQLIndexManager وعدد من نظائرها الأخرى من قبل المؤلف نفسه
هنا وهنا .
في نفس المقالة ، نلقي نظرة على المشروع وإمكانيات استخدام حل البرنامج هذا.
ناقش هذه الأداة
هنا .
بمرور الوقت ، تم إصلاح معظم التعليقات والأخطاء.
لذا ، دعنا الآن ننتقل إلى الأداة المساعدة SQLIndexManager نفسها.
تتم كتابة التطبيق في C # .NET Framework 4.5 في Visual Studio 2017 ويستخدم DevExpress للنماذج:
ويبدو مثل هذا:
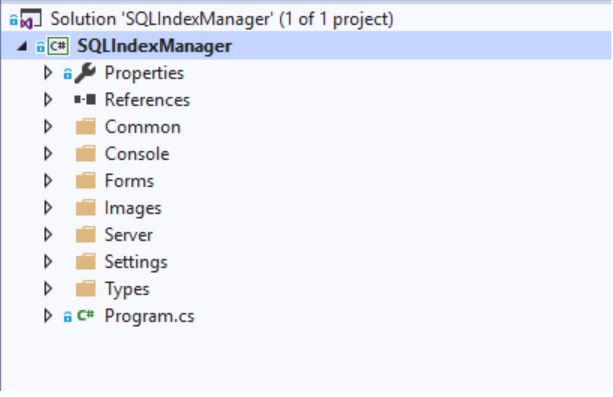
يتم إنشاء جميع الطلبات في الملفات التالية:
- مؤشر
- سؤال
- QueryEngine
- ServerInfo
عند الاتصال بقاعدة البيانات وإرسال الطلبات إلى DBMS ، يتم توقيع التطبيق على النحو التالي:
ApplicationName=”SQLIndexManager”
عند بدء تشغيل التطبيق ، يتم فتح نافذة مشروطة لإضافة اتصال:
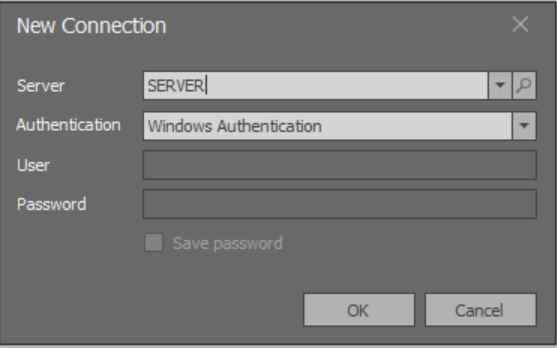
هنا التحميل من القائمة الكاملة لجميع مثيلات MS SQL Server المتاحة عبر الشبكات المحلية لا يعمل حتى الآن.
يمكنك أيضًا إضافة اتصال باستخدام الزر الموجود في أقصى اليسار في القائمة الرئيسية:
بعد ذلك ، سيتم إطلاق استعلامات قواعد البيانات التالية:
الحصول على معلومات DBMS SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT)
الحصول على قائمة قواعد البيانات المتاحة مع خصائصها وجيزة SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
بعد تنفيذ البرامج النصية أعلاه ، تظهر نافذة تحتوي على معلومات مختصرة حول قواعد البيانات الخاصة بمثيل MS SQL Server المحدد:
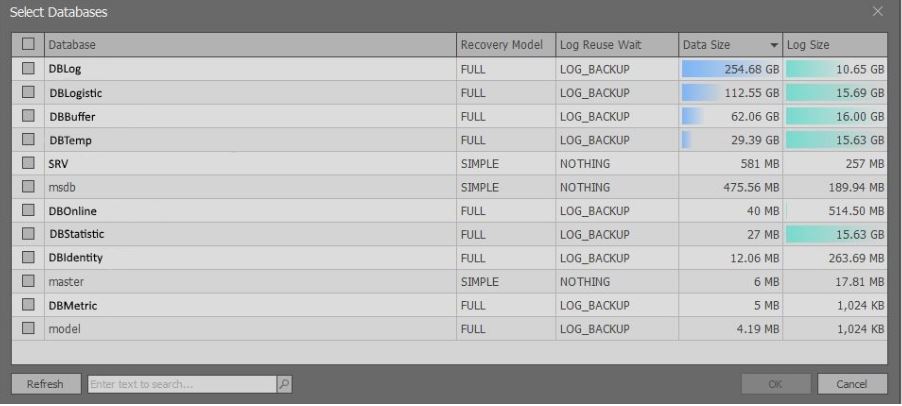
تجدر الإشارة إلى أن المعلومات الموسعة يتم عرضها بناءً على الحقوق. إذا كان هناك
مسؤول النظام ، فيمكنك تحديد البيانات من
طريقة العرض sys.master_files . إذا لم يكن هناك مثل هذه الحقوق ، فسيتم إرجاع بيانات أقل حتى لا يتم إبطاء الطلب.
هنا تحتاج إلى اختيار قاعدة البيانات المثيرة للاهتمام والنقر على زر "موافق".
بعد ذلك ، سيتم تنفيذ البرنامج النصي التالي لكل قاعدة بيانات محددة لتحليل حالة الفهارس:
تحليل حالة الفهرس declare @Fragmentation float=15; declare @MinIndexSize bigint=768; declare @MaxIndexSize bigint=1048576; declare @PreDescribeSize bigint=32768; SET NOCOUNT ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL DROP TABLE
كما ترون من الاستعلامات نفسها ، غالبًا ما يتم استخدام الجداول المؤقتة. يتم ذلك بحيث لا يكون هناك إعادة تجميع ، وفي حالة وجود مخطط كبير ، يمكن إنشاء الخطة بشكل متوازٍ عند إدراج البيانات ، لأن الإدراج مع متغيرات الجدول ممكن في دفق واحد فقط.
بعد تنفيذ البرنامج النصي أعلاه ، ستظهر نافذة بها جدول الفهرس:

هنا يمكنك أيضًا عرض معلومات مفصلة أخرى ، مثل:
- قاعدة بيانات
- عدد الأقسام
- تاريخ ووقت آخر مكالمة
- ضغط
- مجموعة ملفات
ور. د.
يمكن تخصيص الأعمدة نفسها:
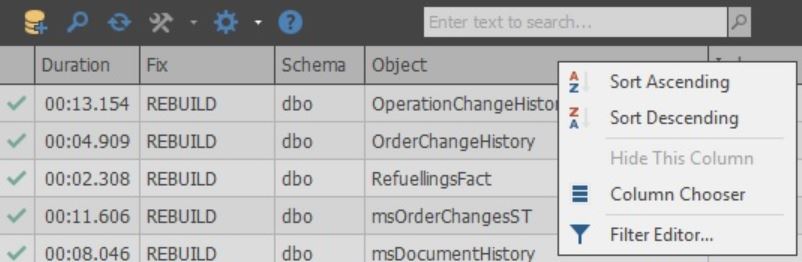
في خلايا عمود Fix ، يمكنك اختيار الإجراء الذي سيتم تنفيذه أثناء التحسين. أيضًا ، عند اكتمال المسح ، يتم تحديد الإجراء الافتراضي بناءً على الإعدادات المحددة:
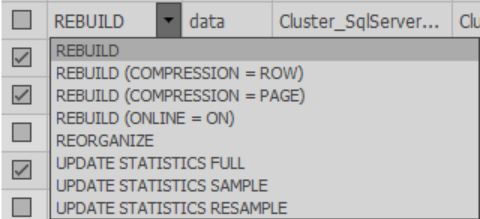
يجب عليك تحديد الفهارس المطلوبة للمعالجة.
باستخدام القائمة الرئيسية ، يمكنك حفظ البرنامج النصي (الزر نفسه يبدأ عملية تحسين الفهرس نفسه):
احفظ الجدول بتنسيقات مختلفة (يسمح لك الزر نفسه بفتح إعدادات مفصلة لتحليل المؤشرات وتحسينها):

أيضا ، يمكن تحديث المعلومات من خلال النقر على الزر الثالث على اليسار في القائمة الرئيسية بجانب العدسة المكبرة.
يسمح لك الزر ذو العدسة المكبرة بتحديد قاعدة البيانات المطلوبة للنظر فيها.
لا يوجد حاليا نظام مساعدة كامل. لذلك ، الضغط على "؟" سيؤدي ذلك ببساطة إلى ظهور نافذة مشروطة تحتوي على معلومات أساسية حول منتج البرنامج:
بالإضافة إلى كل ما سبق ، تحتوي القائمة الرئيسية على شريط بحث:

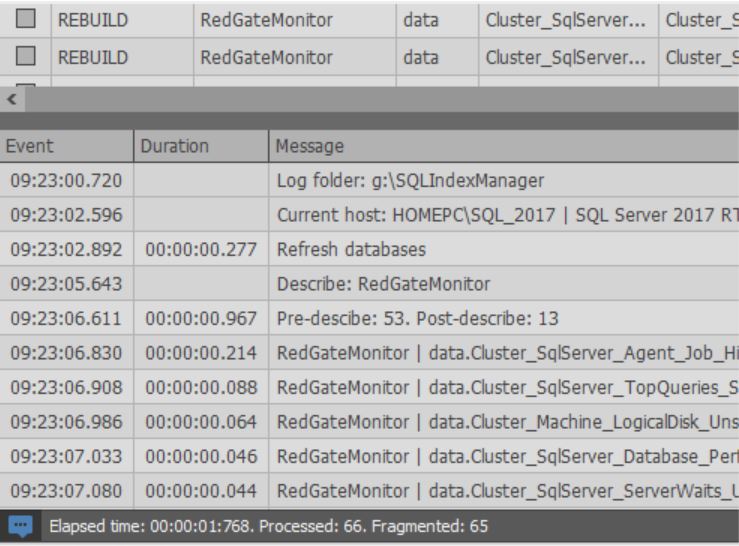
عند بدء عملية تحسين الفهرس:

في الجزء السفلي من النافذة أيضًا ، يمكنك رؤية سجل الإجراءات المنفذة:
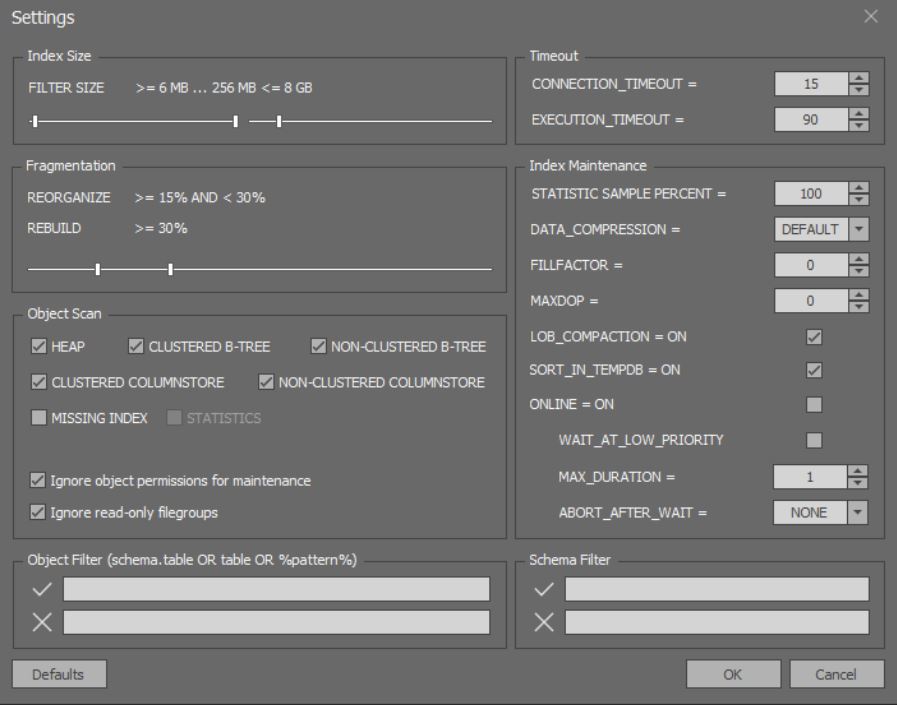
في نافذة التحليل المفصل وتحسين الفهارس ، يمكنك تكوين خيارات أكثر دقة:
 اقتراحات للتطبيق:
اقتراحات للتطبيق:- إتاحة إمكانية تحديث الإحصائيات بشكل انتقائي ليس فقط للفهارس ولكن أيضًا بطرق مختلفة (التحديث الكامل أو جزئيًا)
- لا تجعل تحديد قاعدة البيانات ممكنًا فحسب ، بل أيضًا خوادم مختلفة (يكون ذلك مناسبًا جدًا عند وجود العديد من مثيلات MS SQL Server)
- لمزيد من المرونة في الاستخدام ، يُقترح التفاف الأوامر في المكتبات ، وإخراجها إلى أوامر PowerShell ، كما هو الحال ، على سبيل المثال ، هنا: dbatools.io/commands
- إتاحة حفظ وتغيير الإعدادات الشخصية لكل من التطبيق بالكامل ، وإذا لزم الأمر ، لكل مثيل لـ MS SQL Server وكل قاعدة بيانات
- من الفقرتين 2 و 4 يتبع الرغبة في إنشاء مجموعات على قواعد البيانات ومجموعات على مثيلات MS SQL Server ، والتي الإعدادات هي نفسها
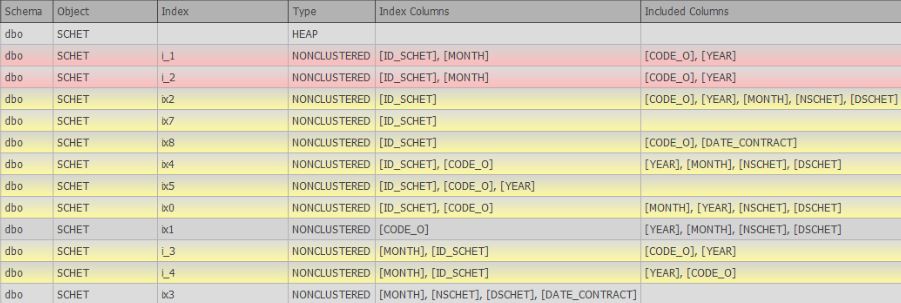
- البحث عن مؤشرات مكررة (كاملة وغير كاملة ، والتي إما تختلف قليلاً أو تختلف فقط في الأعمدة المضمنة)
- منذ يستخدم SQLIndexManager فقط لـ MS SQL Server DBMS ، تحتاج إلى عكس ذلك في الاسم ، على سبيل المثال ، كما يلي: SQLIndexManager for MS SQL Server
- قم بإزالة جميع أجزاء التطبيق من واجهة المستخدم الرسومية إلى وحدات منفصلة وأعد كتابتها إلى .NET Core 2.1
في وقت كتابة هذا التقرير ، تم تطوير المادة 6 من الرغبات بنشاط وهناك دعم بالفعل في شكل بحث عن التكرارات الكاملة والمماثلة:
مصادر