توفر هذه المقالة تعليمات برمجية لإنشاء تقارير منتظمة عن حالة محركات أقراص التخزين EMC VNX مع طرق بديلة وتاريخ الإنشاء.
حاولت كتابة التعليمات البرمجية مع التعليقات الأكثر تفصيلا وملف واحد. استبدل كلمات المرور الخاصة بك فقط. يشار أيضًا إلى تنسيق البيانات المصدر ، لذلك سأكون سعيدًا إذا حاول شخص ما تطبيقه في المنزل.
قبل التاريخ
يمكنك تخطي إذا لم تكن مثيرة للاهتمام من أين تنمو "الأرجل".
لدينا مركز بيانات. لا توجد أنظمة تخزين جديدة جدًا. هناك العديد من أنظمة التخزين ، فشل القرص أيضا. عدة مرات في الأسبوع يذهب الناس إلى مركز البيانات ويغيرون محركات الأقراص في نظام التخزين. يتم اتخاذ قرار باستبدال الأقراص بعد إنذار من نظام " استبدال القرص الموصى به ".
لا شيء خارج عن المألوف.

ولكن في الآونة الأخيرة ، بدأت LUNs الفردية التي تم جمعها على أنظمة التخزين هذه وعرضها على البيئة الافتراضية في التدهور بشكل خطير. بعد التحدث مع الدعم الفني للبائع ، أصبح من الواضح أن الأقراص يجب تغييرها بالفعل ليس فقط عند ظهور رسالة الإنذار أعلاه ، ولكن أيضًا عندما يظهر عدد كبير من الرسائل الأخرى أن النظام لا يأخذ في الاعتبار الأخطاء الخطيرة.
مراقبة SNMP بواسطة أنظمة التخزين هذه غير مدعومة. أنت بحاجة إلى استخدام إما برنامج ملكية باهظ الثمن (ليس لدينا) ، أو أداة مساعدة NaviSECCli ، والتي يجب أن تكون متصلاً بكل وحدة تحكم (يوجد اثنان منهم) لكل نظام تخزين ، ولكن هذا لم يكن مرغوبًا فيه.
تقرر أتمتة مجموعة السجلات والبحث عن الأخطاء فيها. ويجب ترك قرار استبدال الأقراص للمهندسين المسؤولين بناءً على نتائج تحليل التقرير.
الخطوات الأولى
في البداية ، كتب أحد زملائي رمز PowerShell قام بما يلي:
- أخذ جدول إدخال يحتوي على عناوين IP لوحدات التحكم في التخزين ؛
- ذهبت الدورة إلى عناوين IP لوحدات التحكم A ، ثم إلى عناوين IP لوحدات التحكم B ؛
- في هذه العملية ، قابلتهم بالإضافة إلى الأرقام التسلسلية للأقراص ؛
- معالجة جميع أسطر السجلات وتصفيتها لمحتوى الرسائل المطلوبة ؛
- إنشاء كائن PowerShell وفي خصائصه قام بتحليل البيانات الضرورية من الخطوط التي تم الحصول عليها أعلاه ؛
- دمج جميع الكائنات الناتجة في جدول تم إصداره في شكل ملف CSV.
الرمز أدناه. تحفظ فوراً على أنه يعمل ، لكننا قدمنا حلاً بديلاً.
مصدر PowerShellcd 'd:\Navisphere CLI\' $csv = "D:\VNX-IP.csv" $Filter1 = "name1" $Filter2 = "name2" $Filter3 = "name3" $Data = import-csv $csv -Delimiter ';' | Where {$_.cl -EQ $Filter1 -Or $_.cl -EQ $Filter2 -Or $_.cl -EQ $Filter3} | Sort-Object -Property @{Expression={$_.cl}; Ascending=$true}, @{Expression={$_.Name} ;Ascending=$true} #$Filter1 = "nameOfcl" #$Data = import-csv $csv -Delimiter ';' | Where {$_.Name -EQ $Filter1} $Data | select Name,IP,cl $yStart = (Get-Date).AddDays(-30).ToString('yyyy') $yEnd = (Get-Date).ToString('yyyy') $mStart = (Get-Date).AddDays(-30).ToString('MM') $mEnd = (Get-Date).ToString('MM') $dStart = (Get-Date).AddDays(-30).ToString('dd') $dEnd = (Get-Date).ToString('dd') #$start = (Get-Date).AddDays(-3).ToString('MM\/dd\/yy') #$end = (Get-Date).ToString('MM\/dd\/yy') $i = 1 $table = ForEach ($row in $Data) { Write-Host $row.Name -ForegroundColor "Yellow" Write-Host "SP A" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "A" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host "SP B" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newB -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "B" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host " " } $table | select i,cl,Storage,SP,Date,Time,Disk,Error,eCode,SN | Export-Csv -Path 'd:\VNX-Errors.csv' -NoTypeInformation -UseCulture -Encoding UTF8
كان كل شيء على ما يرام ، وكان كل ما تبقى هو إضافة "لمعان" في شكل إرسال تلقائي لخطاب إلى الزملاء المهتمين وتنسيق الحد الأدنى من CSV الناتجة. لكن (!) كل هذه المشاكل عملت لفترة طويلة جدًا. على سبيل المثال ، تم جمع البيانات لمدة شهر حوالي 45 دقيقة ، وهو ما لم يكن مناسبًا جدًا ، لأنه بالإضافة إلى التقارير المنتظمة ، أردت إجراء تحليل للعام الحالي ، وسيكون هذا وقتًا طويلاً للغاية. ولكن "رفض - العرض". بدأوا في التفكير.

من الواضح أنك تحتاج إلى تحسين الكود وتمكين الحوسبة المتوازية. في PowerShell ، لم ننجح في أكثر من 5 سلاسل متزامنة باستخدام سير العمل ، ولم نقم بعد بطرق بديلة. لذلك تقرر محاولة تحويل منطق البرنامج النصي إلى R. الأداة المساعدة NaviSECCli ، والتي يمكن تشغيلها من تحت R ، تجعل مسح التخزين في التعليمات البرمجية المصدر ، وبالتالي فإن الحل مناسب تمامًا.
يقال - بضعة أيام - انتهيت!
قررنا في الإخراج أن أتلقى رسالة إخبارية يومية تحتوي على إجمالي عدد الأخطاء في نص الرسالة ، وبعض الجدول الزمني لعدد الحوادث (بحيث كان هناك شيء لإظهار الإدارة) ، وكذلك مرفق في شكل جدول xlsx. لقد قررنا أنه في الجدول أريد أن أحصل على 3 علامات تبويب:
- بيانات الحوادث لمدة 3 أيام حسب نوع القرص والحادث
- علامة تبويب مماثلة ، ولكن لمدة 30 يومًا
- بيانات أولية (إذا أراد شخص ما تشغيلها في Excel بأنفسهم)
خوارزمية البرنامج النصي
1. قم بتنزيل البيانات المتوفرة على csv من وحدات التحكم ؛
2. تشغيل من خلال الحوسبة المتوازية دورة لجميع وحدات التحكم مع البحث عن سجلات رسائل الإنذار المطلوبة ؛
3. الجمع بين النتائج في إطار البيانات ؛
4. القيام بمعالجة البيانات والتحويل ؛
5. توليد وثيقة XLSX.
6. نحن تشكيل الجدول الذي نحفظه في بابوا نيو غينيا.
7. تشكيل خطاب يحتوي على البيانات التي تم جمعها.
8. إرسال خطاب.
دعنا نذهب من خلال نقاط الخوارزمية
1. قم بتنزيل البيانات المتاحة على وحدات التحكم من CSV
تنسيق الجدول المصدر مع معلمات VNX لجمع معلومات الطوارئ ، تحتاج إلى الاتصال في سلسلة على حد سواء وحدات التحكم ( أعمدة newA و newB ) باستخدام برنامج EMC المتخصصة - NaviCLI مع مفاتيح معينة.
للراحة ، نعيد تهيئة الجدول الناتج بعد التحميل بحيث تكون عناوين IP لكلتا الوحدتين في نفس العمود ، بحيث يمكنك إنشاء دورة واحدة خلال القائمة ، وليس دورتين متتاليتين. نحن نفعل هذا باستخدام وظيفة جمع . يتم وصف قضايا العمل باستخدام تنسيقات البيانات "الرأسية" أو "الأفقية" جيدًا في الوثائق الرسمية للمكتبة العكسية . يمكنك قراءتها هنا .
نقرأ البيانات باستخدام دالة read_csv2 ، ونحدد أيضًا أنواع الأعمدة يدويًا من خلال المعلمة col_types الإضافية. هذه ممارسة جيدة يسرع كثيرا التحميل. في حالتنا ، هذا ليس مهما ، لأن يحتوي ملف CSV الأصلي على أقل من 100 سطر ، لكننا معتادون على الكتابة بشكل صحيح.
في الإخراج ، نحصل على إطار البيانات هذا (الأعمدة الجديدة هي cntName و cntIP ):
2-3. نحن ننفذ من خلال حسابات متوازية دورة لجميع وحدات التحكم مع البحث عن سجلات رسائل الإنذار المطلوبة. الجمع بين النتائج في إطار البيانات
التالي هو الأكثر إثارة للاهتمام. الحوسبة المتوازية .
يوجد في R عدة خيارات (بدلاً من ذلك ، حتى) للحوسبة المتوازية. أعجبني الرابط من مكتبات foreach و doParallel أكثر . يمكنك أن تقرأ عنها وعن خيارات الحوسبة المتوازية الأخرى في R هنا .
باختصار ، نأخذ 3 خطوات فقط:
الخطوة 1 سجل حبات الزمرد النقي وحدة المعالجة المركزية للعمل في الحوسبة المتوازية عبر registerDoParallel (في حالتنا ، نكتشف أولاً عدد النوى في حالة)
تسجيل النوى وحدة المعالجة المركزية numCores <- detectCores() registerDoParallel(numCores)
الخطوة 2 نبدأ الدورة من خلال foreach (لا تنس تحديد عامل التشغيل ٪ dopar٪ بحيث يتم تشغيل الدورة بشكل متوازٍ وتشير ، من خلال المعلمة .combine ، إلى الطريقة التي نجمع بها النتيجة). في حالتنا .combine = rbind ، لأنه عند إخراج كل حلقة سيكون لدينا إطار بيانات .
خطأ في استعادة رمز الجدول الخطوة 3 نقوم بمسح نظام التوازي الذي تم إنشاؤه من خلال stopImplicitCluster ()
مزيد من التفاصيل حول الحصول على جدول قابل للقراءة من نص الخطأ الخام
في النموذج النصي ، الأخطاء هي كما يلي:
head(errors_raw) [1] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841d1080 10006 " [2] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841e1a00 10006 " [3] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 8420b600 10006 " [4] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 84206900 10006 " [5] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc900 10006 " [6] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc000 10006
هنا لدينا قيم مفصولة بمسافة ، والتي ، للوهلة الأولى ، حتى في CSV سيتم إدراجها بشكل طبيعي. لكنها ليست بهذه البساطة. تعقيد التحليل هنا هو:
- يتم فصل التاريخ والوقت أيضًا بمسافة (أصغر الشرور) ؛
- يتكون نص الخطأ من "الكلمات" ، أي مفصولة أيضًا بمسافة ؛
- لسبب ما ، لا توجد مساحة بين رقم القرص ورمز الخطأ (والذي يوجد بين قوسين).
بشكل عام ، الجنة لمحبي التعبيرات العادية :)

لن أتناول بالتفصيل ، لأنه مسألة ذوق ، لكنني سأوضح أنه يجب تمزيق نص الخطأ ، حيث إن القيم الموجودة بين قوس الإغلاق لرقم الخطأ وقوس الفتح لبعض القيم الأخرى. في حلقة ، وهذا هو متغير الأخطاء .
إنها أيضًا نقطة مثيرة للاهتمام ، من أجل تسهيل إنشاء إطار البيانات النهائي ، فإننا نرغب في التعرّف على عناوين IP لوحدات التحكم ، حيث نقوم بتعيين التسلسل ليس من خلال العمود الذي يحتوي على عناوين IP لوحدات التحكم (على سبيل المثال ، I = VNX_ip $ cntIP ) ، ولكن من خلال رقم السطر (أي: ه = 1: nrow (VNX_ip) ). يتيح لنا ذلك ، عند تشكيل إطار بيانات به أخطاء موزعة بالفعل ، إضافة رقم الكتلة واسم التخزين من خلال المكالمات VNX_ip $ cl [i] و VNX_ip $ Name [i] على التوالي. بدون هذا ، يجب إجراء الوصلات ، والتي ستكون أبطأ وأسوأ قراءة في التعليمات البرمجية.
في النهاية ، نحصل على إطار بيانات (لنكون صادقين ، ثم نقلب ، لكن الفرق يتجاوز نطاق المقالة) ، والذي يحتوي على جميع البيانات التي نحتاجها. أي على أي نظام تخزين ، على أي قرص ، عندما حدث خطأ ما.
الإطار النهائي لعرض البيانات أذكى شيء هو أن دورة الاقتراع المتوازي لجميع أنظمة التخزين لا تستغرق 30 دقيقة ، ولكن 30 ثانية .
الحمد لله أن هذا ليس هو الحال عندما تكون 30 ثانية سريعة جدًا.

تجدر الإشارة إلى أن شفرة PowerShell جمعت أيضًا الأرقام التسلسلية للأقراص من جميع أنظمة التخزين في دورة ، وفي وقت إعادة كتابة الكود على R ، كانت هذه البيانات زائدة عن الحاجة. لذا فإن مقارنة وقت التشغيل ليست صادقة تمامًا ، لكنها ما زالت مثيرة للإعجاب.
تم تقليل تحويل بيانات مستندات xlsx إلى تصفية الجدول المصدر في آخر 3 أيام ، وكذلك في الشهر الماضي وتحويل الأعمدة بأسماء الخطأ إلى التنسيق "الأفقي" ، بحيث يكون كل نوع من الأخطاء في عمود منفصل. تمت كتابة وظيفة منفصلة لهذا (حتى لا يتم تكرار نفس الخطوات مرتين)
وظيفة تصفية المصدر myErrorStats <- function(data, period, orderColname = quo(Soft_Media_Error)) { data %>% filter(Date > period) %>% group_by(cl, Storage, Disk, Error) %>% summarise(count = n()) %>% spread(Error, count, fill = 0) %>% arrange(desc(!!orderColname)) }
لعرض أنواع الأخطاء في عمود منفصل ، تم تطبيق وظيفة الحشو مع ملء المفتاح الإضافي = 0 ، مع ملء القيم المفقودة بـ 0 . بدون هذا المفتاح ، إذا لم يكن هناك نوع من الأخطاء في يوم ما ، فسيحتوي العمود المقابل على قيم NA .
أيضًا ، في الوظيفة ، أردت الاحتفاظ بالقدرة على تمرير اسم العمود للفرز كمتغير ، ولكن في الوقت نفسه ، تحتوي على قيم افتراضية لهذا المتغير. لهذا الغرض ، يتم استخدام بناء الجملة الغريب ، والذي يمكنك قراءة المزيد عنه هنا .
في حالتنا ، عند تحديد معلمات دالة ، نضع واحدة منها على القيمة الافتراضية ونقتبسها ( orderColname = quo (Soft_Media_Error) ) ، ثم ، عند استدعاء ، نضع الأحرف أمامها !! للحصول على ترتيب (تنازلي (!! orderColname)) .
مظهر الجدول مع وجود أخطاء لهذا الشهر لقد قمت بتحليل تكوين مستند xlsx في المقالة حول تقارير حالة VM ، لذلك لن أتناول بالتفصيل. يتم إعطاء كل رمز في نهاية المقال.

فيما يلي بعض الميزات المهمة التي تزيد من سهولة قراءة التقرير:
- علامات التبويب الموقعة (بشكل افتراضي ، الأكثر إثارة للاهتمام مفتوح) ؛
- أسماء الأعمدة المميزة
- التنسيق التلقائي لجميع الأعمدة بحيث يكون كل النص قابلاً للقراءة دون الحاجة إلى توسيع الأعمدة.
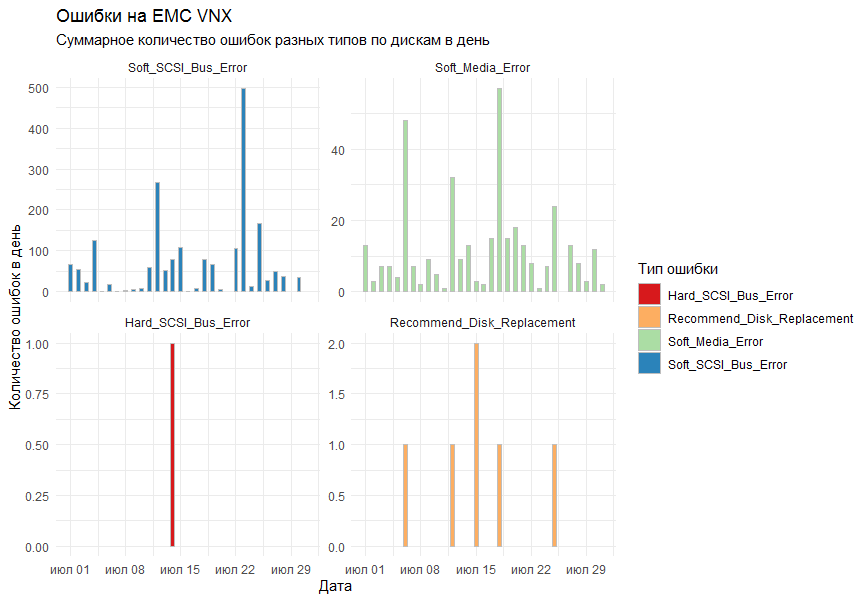
على الرسم البياني ، أردت الحصول على إجمالي عدد الأخطاء يوميًا لجميع أنظمة التخزين حسب النوع. كأداة رسم ، تقرر استخدام مكتبة ggplot2 القياسية.
أظهر الإصدار الأول من الرسم البياني جميع الأخطاء في رسم بياني واحد وبدا كما يلي:

قال الزملاء أنه اتضح أنه غير قابل للقراءة.
ماذا سيفهمون؟
تم أخذ الملاحظات في الاعتبار وتمت إضافة وظيفة facet_grid إلى الأعمدة القياسية ( geom_bar ) لتقسيم النتيجة إلى رسوم بيانية منفصلة حسب نوع الخطأ.
النتيجة النهائية تناسب الجميع.

إعداد البيانات ، الرسوم البيانية ، حفظ إلى ملف من المثير للاهتمام في تشكيل الجدول الزمني.
أردت أن تكون المخططات بترتيب معين. للقيام بذلك ، كان لا بد من نقل معامل تكوين الصفوف في facet_grid كعامل ، أو حتى كعامل منظم . العامل هو مثل هذا التنسيق للبيانات الماكرة في R ، وهو عبارة عن مجموعة من القيم (في حالتنا ، السلاسل ، أي الأحرف ) ، ويتم تعريف مجموعة هذه القيم بدقة (تسمى مستويات عامل) ، وحتى يتم فرز هذه المستويات. يبدو الأمر معقدًا ، لكن كل شيء يقع في مكانه الصحيح إذا قلت إن أسماء الأشهر هي مثال رائع على عامل مرتب. أي نحن نعرف أسماء أشهر يمكن أن يكون لها ، ونعرف أيضًا (جيدًا ، آمل) أن يأتي أولاً يناير ثم فبراير ثم مارس وما إلى ذلك. على نفس المبدأ الذي نخلقه عاملا.
كما تم النظر في تشكيل وإرسال الرسائل ، وكذلك تشكيل المهام في ويندوز جدولة في مقال عن تقارير عن حالة VM . نحن ببساطة نضع بعض المتغيرات في النص وننسقها بشكل أو بآخر. لا تنسى المرفق.
النتائج
أثبتت R مرة أخرى أنها أداة عالمية لأداء المهام اليومية وتصور نتائجها. ومع تمكين الحوسبة المتوازية ، تصبح هذه الأداة أيضًا سريعة.
أظهرت الممارسة أيضًا أن PowerShell بطيء جدًا في تحليل السجلات وترجمتها إلى تنسيق قابل للقراءة.
شكرا جزيلا للجميع الذين قرأوا الكثير من الرسائل حتى النهاية.
رمز التطبيق الكامل
- : EMC VNX 5300
- : NaviCLI-Win-32-x86-en_US-7.31.25.1.29-1
- , : 4*2 CPU, 8 Gb RAM
R > sessionInfo() R version 3.5.3 (2019-03-11) Platform: x86_64-w64-mingw32/x64 (64-bit) Running under: Windows Server 2012 R2 x64 (build 9600) Matrix products: default locale: [1] LC_COLLATE=Russian_Russia.1251 LC_CTYPE=Russian_Russia.1251 LC_MONETARY=Russian_Russia.1251 [4] LC_NUMERIC=C LC_TIME=Russian_Russia.1251 attached base packages: [1] parallel stats graphics grDevices utils datasets methods base other attached packages: [1] taskscheduleR_1.4 pander_0.6.3 doParallel_1.0.14 iterators_1.0.10 foreach_1.4.4 mailR_0.4.1 [7] xlsx_0.6.1 stringi_1.4.3 zoo_1.8-6 lubridate_1.7.4 wesanderson_0.3.6 forcats_0.4.0 [13] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3 tibble_2.1.3 [19] ggplot2_3.2.0 tidyverse_1.2.1 loaded via a namespace (and not attached): [1] tidyselect_0.2.5 reshape2_1.4.3 rJava_0.9-11 haven_2.1.1 lattice_0.20-38 colorspace_1.4-1 [7] vctrs_0.2.0 generics_0.0.2 utf8_1.1.4 rlang_0.4.0 R.oo_1.22.0 pillar_1.4.2 [13] glue_1.3.1 withr_2.1.2 R.utils_2.9.0 RColorBrewer_1.1-2 modelr_0.1.4 readxl_1.3.1 [19] plyr_1.8.4 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0 rvest_0.3.4 R.methodsS3_1.7.1 [25] codetools_0.2-16 labeling_0.3 fansi_0.4.0 xlsxjars_0.6.1 broom_0.5.2 Rcpp_1.0.1 [31] scales_1.0.0 backports_1.1.4 jsonlite_1.6 digest_0.6.20 hms_0.5.0 grid_3.5.3 [37] cli_1.1.0 tools_3.5.3 magrittr_1.5 lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2 [43] zeallot_0.1.0 data.table_1.12.2 xml2_1.2.0 assertthat_0.2.1 httr_1.4.0 rstudioapi_0.10 [49] R6_2.4.0 nlme_3.1-137 compiler_3.5.3