مقال موجز عن تعدين العمليات التجارية في سياق الاهتمام المتزايد بمفهوم "التوأم الرقمي". نظرًا للظهور الدوري لهذا الموضوع ، فأنا أعتبر أنه من المناسب مشاركة النهج في الحل.
بيان المشكلة
الوضع بسيط للغاية.
- هناك شركة X (Y ، Z ، ...).
- وتمتلك الشركة العمليات التجارية الآلي من قبل أنظمة تكنولوجيا المعلومات المختلفة.
- هناك محللو الأعمال الذين رسموا مخططات bpmn لهذه العمليات. بشكل أكثر تحديدًا ، "فكرة bpmn" الخاصة بهم حول كيفية النظر في هذه العمليات.
- يريد مستخدمو الأعمال الحصول على نوع من التمثيل (KPI) لهذه العمليات.
كيف تصل إلى الحقيقة وعد هذه المقاييس؟
إنه استمرار للمنشورات السابقة .
المسلمات الأساسية:
- يوجد سجل أحداث مؤقت (سجلات مختلفة لأنظمة تقنية المعلومات ، cdr \ xdr ، سجلات الأحداث فقط في قاعدة البيانات) بدرجات متفاوتة من النقاء والاكتمال والاتساق.
- تعمل أنظمة تكنولوجيا المعلومات كآلة حكومية و "تمشي" بين الولايات المختلفة وفقًا لإجراءات المستخدمين ومنطق الأعمال الذي وضعه المبرمجون فيه.
- يتم تفاعل المستخدم في شكل معاملات.
تصحيحات العالم المادي:
- إن عدد التغييرات التي تم إجراؤها على نظام تكنولوجيا المعلومات هو أن الرسوم البيانية bpmn لمحللي الأعمال لا علاقة لها بالواقع تقريبًا.
- يمكن أن تكون البيانات غير منظمة للغاية (على سبيل المثال ، سجلات التطبيق).
- "المعاملات" هو مفهوم منطقي. تحتوي سجلات الأحداث نفسها على سمات متأصلة في هذه الحالة ولا يوجد مُعرّف معاملة من طرف إلى طرف.
- عدد السجلات في اليوم هو عشرات ، مئات ، آلاف الملايين من القطع .
مجموعة العد الحل
لحل هذه المشاكل ، من الضروري:
- إعادة بناء المعاملات
- إعادة بناء العمليات التجارية الحقيقية
- عمل حسابات
- توليد نتائج في شكل قابل للقراءة الإنسان.
يمكنك البدء في البحث عن حلول البائعين ودفع الملايين. لكن لدينا R. في أيدينا ، فهو يتيح لنا حل هذه المشكلة تمامًا. اعتبارات موجزة أدناه.
يبدو كل شيء بسيطًا ويحتوي R على مجموعة جيدة ومتناسقة من حزم bupaR . لكن الذبابة في المرهم موجودة وتسمم كل شيء. هذه المجموعة في وقت مقبول لا يمكنها سوى التعامل مع عدد صغير من الأحداث (مئات الآلاف - عدة ملايين).
بالنسبة للكميات الكبيرة ، يجب استخدام طرق أخرى.
إضافة السرعة!
محاكاة مجموعة بيانات الإدخال
لإظهار الأفكار ، من الضروري تكوين نوع من مجموعة بيانات الاختبار. لنأخذ مثالاً على سلسلة متاجر فيدرالية كمصدر مادي لنموذج رياضي ، ولحسن الحظ ، هذا واضح للجميع. على الرغم من النجاح نفسه ، يمكن أن تكون أجهزة الصراف الآلي ومراكز الاتصال ووسائل النقل العام وإمدادات المياه وغيرها.
- هناك محلات من مختلف الأحجام (الصغيرة والمتوسطة والكبيرة).
- في المتاجر هناك مكاتب نقدية (نقاط البيع).
- يمكن أن تكون أرقام المتجر أبجدية رقمية ، ويمكن أن تكون الأرقام الطرفية رقمية.
- يذهب المتسوقون إلى المتاجر ويقومون بشراء شيء أثناء الدفع ببطاقة.
- يتم وصف تفاعل محطة نقاط البيع مع البطاقة والبنك من قبل مجموعة معينة من الدول وقواعد الانتقال بينهما.
- المعاملات ناجحة ، غير ناجحة ، مؤجلة وغير مكتملة (البنك غير متوفر ، على سبيل المثال).
- المعاملات لها مهلات.
خذ المجموعة التالية من أنماط المعاملات التجارية:
"INIT-REQUEST-RESPONSE-SUCCESS" "INIT-REQUEST-RESPONSE-ERROR" "INIT-REQUEST-RESPONSE-DEFFERED" "INIT-REQUEST" "INIT"
لإظهار النهج ، سننشئ عينة صغيرة ، لكن كل شيء يعمل بشكل جيد على مليارات السجلات (بالنسبة لمثل هذا المجلد دون التحسين الفائق ، يتم قياس الوقت المميز بمئات الثواني فقط على خادم واحد ذو أداء متواضع للغاية).
المفسد المباشر للكميات الكبيرة:
- في كثير من الأماكن ، تعني كلمة
tidyverse لا يمكنك الحصول على إجابة ؛ - يعد تحسين الخطوات الدقيقة حتى مفيدًا ويمكن أن يقدم مساهمة كبيرة.
نموذج رمز المحاكاة library(tidyverse) library(datapasta) library(tictoc) library(data.table) library(stringi) library(anytime) library(rTRNG) data.table::setDTthreads(0) # data.table data.table::getDTthreads() # set.seed(46572) RcppParallel::setThreadOptions(numThreads = parallel::detectCores() - 1) # -- -, # 5 -, 2 -- bo_pattern <- tibble::tribble( # , , ~pattern, ~prob, ~mean_duration, "INIT-REQUEST-RESPONSE-SUCCESS", 0.7, 5, "INIT-REQUEST-RESPONSE-ERROR", 0.15, 5, "INIT-REQUEST-RESPONSE-DEFFERED", 0.07, 8, "INIT-REQUEST", 0.05, 2, "INIT", 0.03, 0.5 ) # + checkmate::assertTRUE(sum(bo_pattern$prob) == 1) df <- bo_pattern %>% separate_rows(pattern) %>% # mutate(coeff = sum(prob)) %>% group_by(pattern) %>% # summarise(event_prob = sum(prob/coeff)*100) %>% ungroup() checkmate::assertTRUE(sum(df$event_prob) == 100) # 3 : (4 ), (12 ), (30 ) df1 <- tribble( ~type, ~n_pos, ~n_store, "small", 4, 10, "medium", 12, 5, "large", 30, 2 ) %>% # mutate(store = map2(row_number(), n_store, ~sample(x = .x * 1000 + 1:.y, size = .y, replace = FALSE))) %>% unnest(store) %>% # mutate(pos = map(n_pos, ~sample(x = .x, size = .x, replace = FALSE))) %>% unnest(pos) %>% mutate(pattern = sample(bo_pattern$pattern, n(), replace = TRUE, prob = bo_pattern$prob)) tic("Generate transactions") # , # , df2 <- df1 %>% # select(-matches("duration")) %>% left_join(bo_pattern, by = "pattern") %>% # sample_frac(size = 200, replace = TRUE) %>% mutate(duration = rnorm(n(), mean = mean_duration, sd = mean_duration * .25)) %>% select(-prob, -mean_duration) %>% # , > # 30 filter(duration > 0.5 & duration < 30) %>% # POS mutate(session_id = row_number()) %>% # , separate_rows(pattern) %>% rename(event = pattern) toc() tic("Generate time markers, data.table way") samples_tbl <- data.table::as.data.table(df2) %>% # setkey(session_id, duration, physical = FALSE) %>% # # 1- , , 5 # .[, ticks := base::sort(runif(.N, 5, 5 + duration)), by = .(session_id, duration)] %>% # match.arg base::order!! # # 0 1 # # .[, tshift := runif(.N, 0, 1)] %>% # trng ( ) # , .[, trand := runif_trng(.N, 0, 1, parallelGrain = 100L) * duration] %>% # , # .[, ticks := sort(tshift), by = .(session_id)] %>% # , session_id, , .[, t_idx := session_id + trand / max(trand)/10] %>% # # session_id . .[, tshift := (sort(t_idx) - session_id) * 10 * max(trand)] %>% # , POS (60 ) .[event == "INIT", tshift := tshift + runif_trng(.N, 0, 60, parallelGrain = 100L)] %>% # .[, `:=`(duration = NULL, trand = NULL, t_idx = NULL, n_store = NULL, n_pos = NULL, timestamp = as.numeric(anytime("2019-03-11 08:00:00 MSK")))] %>% # , 01.03.2019 .[, timestamp := timestamp + cumsum(tshift), by = .(store, pos)] %>% # .[timestamp <= as.numeric(anytime("2019-04-11 23:00:00 MSK")), ] %>% # .[, timestamp := anytime(timestamp, tz = "Europe/Moscow")] %>% as_tibble() %>% select(store, pos, event, timestamp, session_id) toc()
من أجل نقاء التجربة ، نترك فقط المعلمات الهامة ونخلط كل شيء. في الحياة الواقعية ، لا يزال من الضروري التخلص بشكل عشوائي من جزء من الأجزاء (ربما في كتل زمنية منفصلة) ، وبالتالي محاكاة الخسائر في تلقي البيانات.
# log_tbl <- samples_tbl %>% select(store, pos, state = event, timestamp_msk = timestamp) %>% sample_n(n()) # log_tbl %>% mutate(timegroup = lubridate::ceiling_date(timestamp_msk, unit = "10 mins")) %>% ggplot(aes(timegroup)) + # geom_bar(width = 0.7*600) + geom_bar(colour = "white", size = 1.3) + theme_bw()
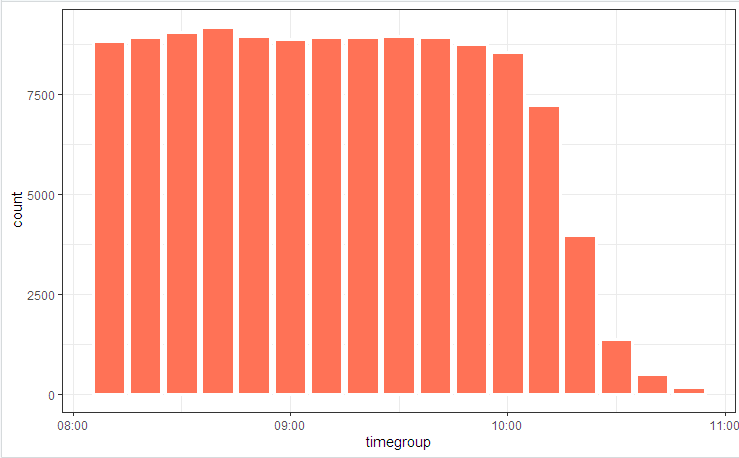
نوضح مخطط العملية مع صورة

وتوزيع الدولة

يرجع التقلبات الطفيفة إلى حقيقة أن الجدول يتم اعتباره في البداية (يتم تضمينه في التعليمات البرمجية) ، وقد عملت bupaR::process_map في النهاية عندما تم قطع بعض البيانات التي تم إنشاؤها عشوائيًا والتي لا تتناسب مع القيود المتكاملة عن طريق تصفية العناصر.
إعادة بناء المعاملات
أول ما يتم تقديمه عادةً عندما يتعين عليك جمع / تفكيك / مقارنة السلاسل الزمنية هو التجمعات ودورات المقارنة. في العروض التوضيحية التي تحتوي على 100 إدخال ، ستعمل هذه الزيادة ، لكن ملايين القوائم لن تنجح. للتعامل مع هذه المهمة ، تحتاج إلى توطين نقاط فقدان الوقت (الحلقات الداخلية وتخصيصات الذاكرة الوسيطة والنسخ) ومحاولة القضاء عليها إلى الحد الأدنى.
نتيجة لذلك ، يمكن تقليل هذه المشكلة إلى عشرة خطوط.
كود اعادة بناء المعاملة clean_dt <- as.data.table(log_tbl) %>% # INIT .[, start := (state == "INIT")] %>% # session_id , # .[, event_date := lubridate::as_date(timestamp_msk)] %>% .[, date_str := format(.BY[[1]], "%y%m%d"), by = event_date] %>% # # timestamp_msk setorder(store, pos, timestamp_msk) %>% # -- .[, session_id := paste(date_str, store, pos, cumsum(start), sep = "_")] %>% # ( 30 ) # .[, time_shift := timestamp_msk - shift(timestamp_msk), by = .(store, pos)] %>% # , INIT .[, time_locf := cummax(as.numeric(timestamp_msk) * as.numeric(start)), by = .(store, pos)] %>% .[, time_shift := as.numeric(timestamp_msk) - time_locf] %>% # , 30 .[, lost_chain := time_shift > 30] %>% # .[, time_shift := as.numeric(!start) * as.numeric(timestamp_msk - shift(timestamp_msk, fill = 0))] %>% # INIT # .[, time_accu := cumsum(time_shift)] %>% .[, date_str := NULL] # # tidyverse , dt <- as.data.table(clean_dt) %>% # !!! .[lost_chain != TRUE] %>% # 1- .[order(timestamp_msk, store, pos)] %>% .[, bp_pattern := stri_join(state, collapse = "-"), by = session_id] # as_tibble(dt) %>% distinct(session_id, bp_pattern) %>% count(session_id, sort = TRUE)
في بضع ثوان ، لدينا صورة أعيد بناؤها من العمليات التجارية.
و (من كان يظن !!!) في الواقع ، اتضح أن العمليات التجارية الآلية في أنظمة تكنولوجيا المعلومات تعمل بشكل مختلف نوعًا ما (أو لا تعمل على الإطلاق) كما أقنع محللو الأعمال الجميع. عجائب وحجج "أصحاب العملية" سترافق دراسة الصورة النهائية.
تطبيق بنشاط الحيل
عندما تصبح سرعة الحوسبة كمية مهمة ، فإن كتابة رمز العمل لا يكفي. من الضروري الانتباه إلى جميع المستويات. هناك أيضًا عدد من الحيل الحسابية التي يمكن أن تقلل بشكل كبير من وقت التنفيذ.
على وجه الخصوص ، في هذه المهمة يمكن أن نذكر ما يلي:
- للمعالجة الرئيسية ، فقط
data.table (السرعة ، العمل على الروابط) ، + محاسبة تحسين الاستعلام الداخلي. - يمكن أن تحتوي
POSIXct على أجزاء من الثانية (على الرغم من أنها لا تظهر بشكل طبيعي ، ولكن يمكن تصحيحها باستخدام options(digits.secs=X) ) ، فإننا options(digits.secs=X) هناك ، وسيكون من السهل المقارنة والفرز. - تجنب الفرز البدني داخل المجموعات! يضمن الفرز المادي الفردي للناقل بأكمله فرز البيانات في مجموعات.
- تجنب الحوسبة داخل المجموعات. نحاول أن نفعل كل ما هو ممكن على البيانات المصدر (نطبق التوجيه ، وخفض فواتير المكالمات الوظيفية).
- نحن نستخدم مهلة معاملة للتعامل مع الفجوات الزمنية.
- أساليب locf (Last Observation Carward Forward) بطيئة. لنقل الخصائص على جدول زمني ، استخدم
cumsum ، cummax . - العمليات المستهلكة للوقت ، مثل POSIX -> تحويل السلسلة ، البحث المنتظم ، إلخ. نحن لا نفعل ذلك عنصر تلو الآخر ، ولكن على تلافيف. النفقات العامة على الفهرسة الداخلية وتجميع الحقل المحول أصغر بشكل لا يضاهى.
- نحن نستخدم بنشاط multithreading (بما في ذلك داخل الحزمة).
- لا تهمل microoptimization. على سبيل المثال ،
stri_c أسرع عدة مرات من paste0 .
# 1 log <- getLog(fileName) bench::mark( paste0 = paste0(log$value, collapse = "\n"), stringi = stri_c(log$value, collapse = "\n") ) # # A tibble: 2 x 13 # expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc total_time # <bch:expr> <bch:> <bch:> <dbl> <bch:byt> <dbl> <int> <dbl> <bch:tm> # 1 paste0 58ms 59.1ms 16.9 496KB 0 9 0 533ms # 2 stringi 16.9ms 17.5ms 57.1 0B 0 29 0 508ms
الوظيفة السابقة - سكين معالجة json السويسري .