يمثل جمع البيانات وتخزينها وتحويلها وعرضها التحديات الرئيسية التي تواجه مهندسي البيانات. يتلقى قسم Business Intelligence Badoo ويقوم بمعالجة أكثر من 20 مليار حدث يتم إرسالها من أجهزة المستخدم يوميًا ، أو 2 تيرابايت من البيانات الواردة.
دراسة وتفسير جميع هذه البيانات ليست دائما مهمة تافهة ، وهناك حاجة في بعض الأحيان إلى تجاوز قدرات قواعد البيانات الجاهزة. وإذا كانت لديك الشجاعة وقررت أن تفعل شيئًا جديدًا ، فعليك أولاً أن تتعرف على مبادئ العمل للحلول الحالية.
في كلمة واحدة ، مطوري الفضوليين والأقوياء ، يتم تناول هذه المقالة. ستجد فيه وصفًا للنموذج التقليدي لتنفيذ الاستعلام في قواعد البيانات الترابطية باستخدام PigletQL للغة التجريبية كمثال.
محتوى
قبل التاريخ
تعمل مجموعة المهندسين لدينا في الواجهات الخلفية والواجهات ، مما يوفر فرصًا للتحليل والبحث في البيانات داخل الشركة (بالمناسبة ، نحن بصدد التوسع ). أدواتنا القياسية هي قاعدة بيانات موزعة لعشرات الخوادم (Exasol) ومجموعة Hadoop لمئات الأجهزة (Hive و Presto).
معظم الاستعلامات إلى قواعد البيانات هذه تحليلية ، أي تؤثر من مئات الآلاف إلى مليارات السجلات. يستغرق تنفيذها دقائق أو عشرات دقائق أو حتى ساعات ، اعتمادًا على الحل المستخدم وتعقيد الطلب. مع العمل اليدوي للمحلل المستخدم ، يعتبر هذا الوقت مقبولاً ، لكنه غير مناسب للبحث التفاعلي من خلال واجهة المستخدم.
مع مرور الوقت ، قمنا بتسليط الضوء على الاستفسارات والاستفسارات التحليلية الشائعة ، والتي يصعب تحديدها من حيث SQL ، وقامت بتطوير قواعد بيانات متخصصة صغيرة لهم. يقومون بتخزين مجموعة فرعية من البيانات بتنسيق مناسب لخوارزميات الضغط الخفيف (على سبيل المثال ، streamvbyte) ، والذي يسمح لك بتخزين البيانات في جهاز واحد لعدة أيام وتنفيذ الاستعلامات في ثوان.
تم تطبيق لغات الاستعلام الأولى لهذه البيانات ومترجميها الشفويين على حدس ، وكان علينا أن نحسنها باستمرار ، وفي كل مرة استغرق الأمر وقتًا طويلاً بشكل غير مقبول.
لم تكن لغات الاستعلامات مرنة بدرجة كافية ، على الرغم من عدم وجود أسباب واضحة للحد من قدراتها. نتيجة لذلك ، لجأنا إلى تجربة مطوري برامج SQL ، بفضل تمكنا من حل المشكلات التي نشأت جزئيًا.
أدناه سأتحدث عن نموذج تنفيذ الاستعلام الأكثر شيوعًا في قواعد البيانات الترابطية - بركان. الكود المصدري لمترجم لهجة SQL البدائية ، PigletQL ، مرفق بالمقال ، بحيث يمكن لأي شخص مهتم أن يتعرف بسهولة على التفاصيل في المستودع.
بنية SQL مترجم
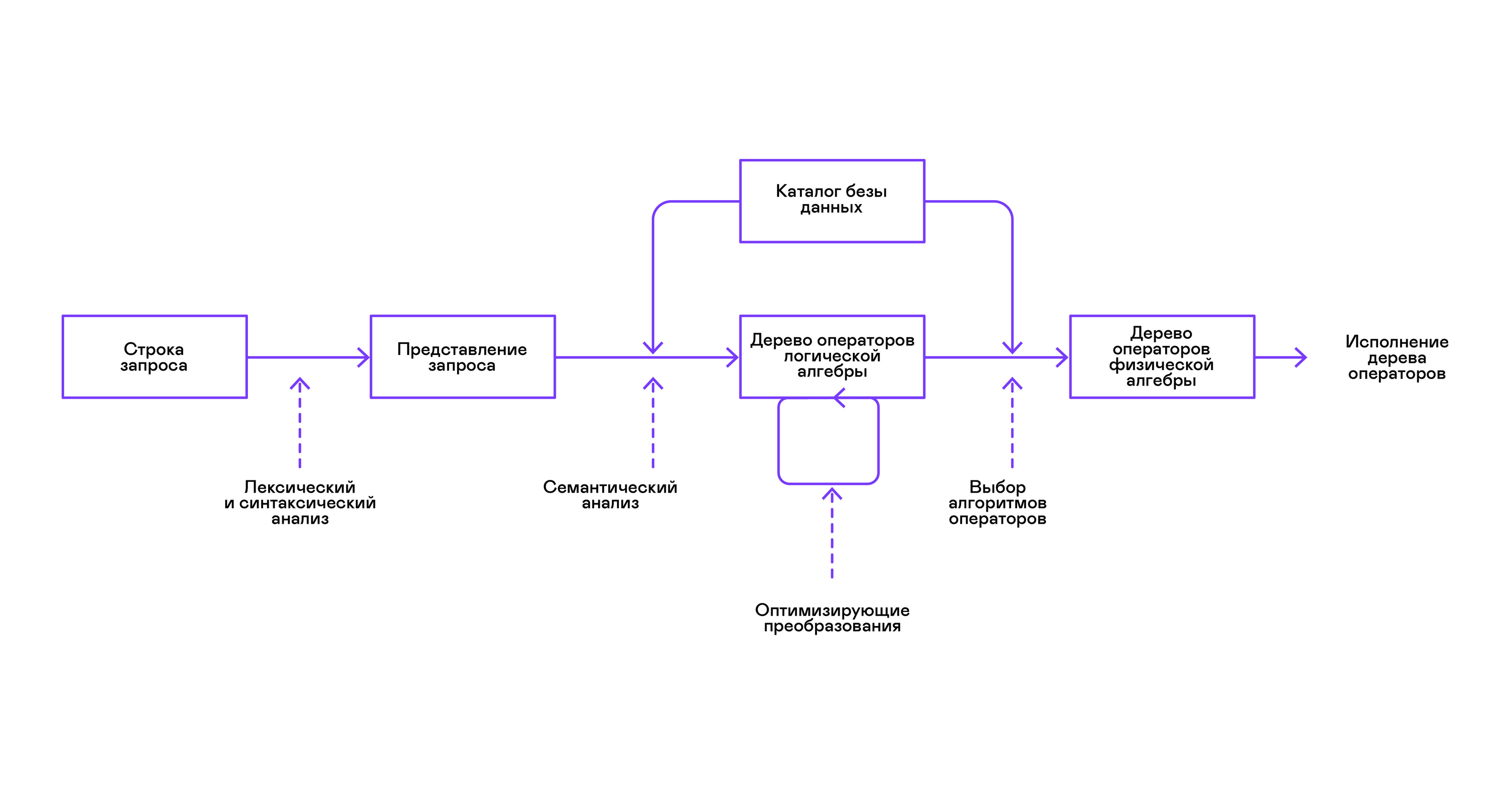
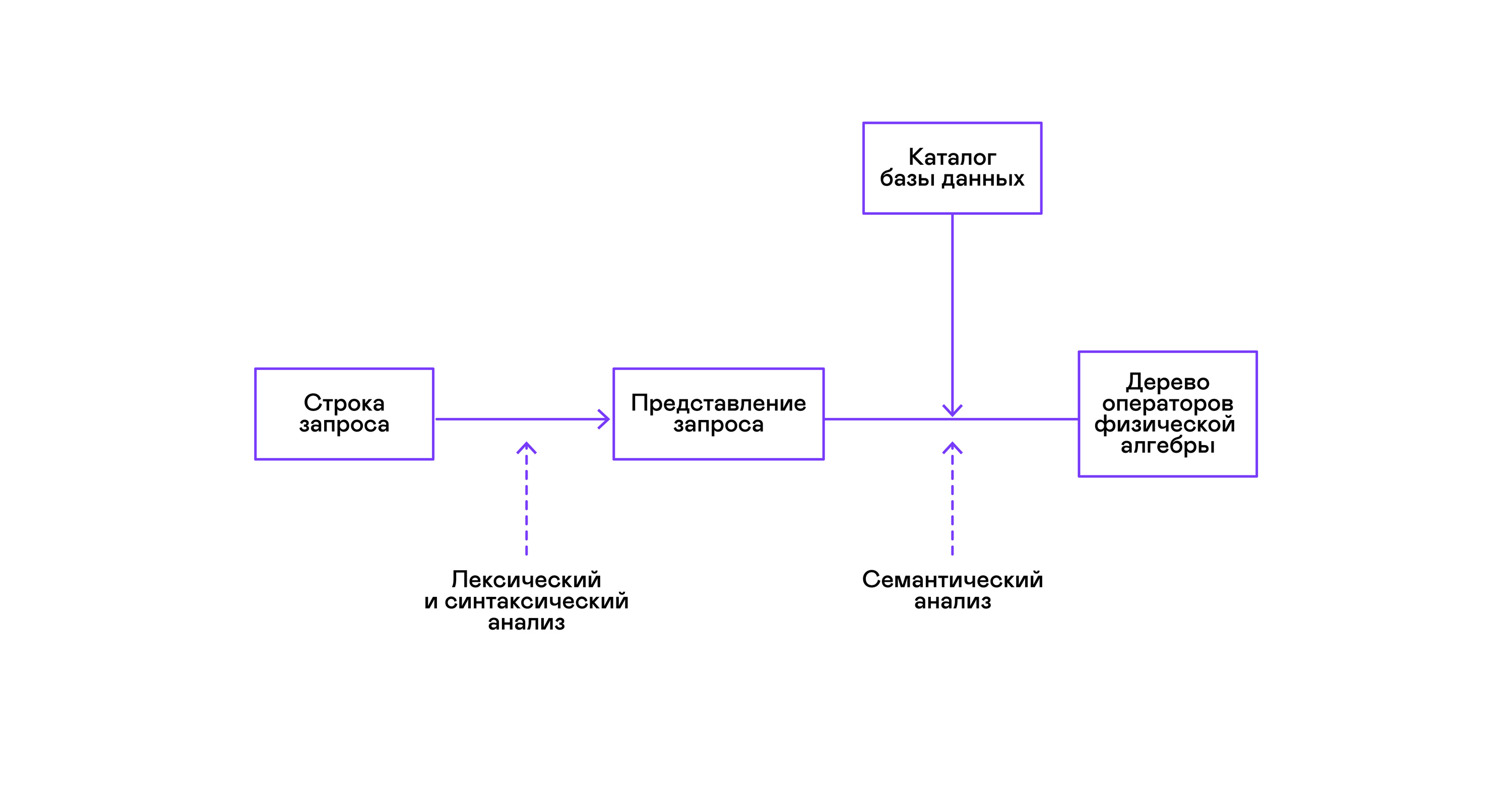
توفر معظم قواعد البيانات الشائعة واجهة للبيانات في شكل لغة استعلام SQL معلن عنها. يتم تحويل استعلام في شكل سلسلة بواسطة المحلل اللغوي إلى وصف الاستعلام ، على غرار شجرة بناء الجملة المجردة. من الممكن تنفيذ استعلامات بسيطة بالفعل في هذه المرحلة ، ومع ذلك ، لتحسين التحويلات والتنفيذ اللاحق ، فإن هذا التمثيل غير مريح. في قواعد البيانات المعروفة لي ، يتم تقديم تمثيلات متوسطة لهذه الأغراض.
أصبحت الجبر العلائقي نموذجًا للتمثيلات الوسيطة. هذه هي اللغة التي يتم فيها وصف التحولات ( المشغلين ) التي أجريت على البيانات بشكل صريح: تحديد مجموعة فرعية من البيانات وفقًا لمصادر ، والجمع بين البيانات من مصادر مختلفة ، وما إلى ذلك. التحولات. لذلك ، من المريح إجراء تحسينات مثالية للتحويلات عبر استعلام في شكل شجرة من مشغلي الجبر العلائقي.
هناك اختلافات مهمة بين التمثيلات الداخلية في قواعد البيانات والجبر العلائقي الأصلي ، لذلك فمن الأصح أن نسميها الجبر المنطقي .
عادة ما يتم إجراء التحقق من صحة الاستعلام عند تجميع التمثيل الأولي للاستعلام في مشغلي الجبر المنطقي ويتوافق مع مرحلة التحليل الدلالي في المجمعين التقليديين. يتم لعب دور جدول الرموز في قواعد البيانات بواسطة دليل قاعدة البيانات ، الذي يخزن معلومات حول مخطط قاعدة البيانات وبيانات التعريف: الجداول ، أعمدة الجدول ، الفهارس ، حقوق المستخدم ، إلخ.
بالمقارنة مع المترجمين الفوريين للأغراض العامة ، فإن لمترجمي قواعد البيانات خصوصية واحدة: الاختلافات في حجم البيانات والمعلومات الوصفية حول البيانات التي من المفترض أن يتم تقديم الاستعلامات إليها. في الجداول ، أو العلاقات من حيث الجبر العلائقي ، يمكن أن يكون هناك كمية مختلفة من البيانات ، ويمكن بناء فهارس في بعض الأعمدة ( سمات العلاقة) ، وما إلى ذلك ، وهذا يتوقف على مخطط قاعدة البيانات وكمية البيانات في الجداول ، ويجب إجراء الاستعلام بواسطة خوارزميات مختلفة ، واستخدامها في ترتيب مختلف.
لحل هذه المشكلة ، يتم تقديم تمثيل وسيط آخر - الجبر المادي . اعتمادًا على توفر فهارس على الأعمدة ، وكمية البيانات في الجداول ، وهيكل شجرة الجبر المنطقي ، يتم تقديم أشكال مختلفة من شجرة الجبر المادي ، يتم اختيار الخيار الأفضل منها. هذه الشجرة هي التي تظهر إلى قاعدة البيانات كخطة استعلام. في المجمعين التقليديين ، تتوافق هذه المرحلة بشكل مشروط مع مراحل تخصيص السجل والتخطيط واختيار التعليمات.
الخطوة الأخيرة في عمل المترجم الفوري هي تنفيذ شجرة مشغلي الجبر المادي مباشرة.
نموذج البركان وتنفيذ الاستعلام
دائمًا ما يتم استخدام المترجمين الفوريين لشجرة الجبر في قواعد البيانات التجارية المغلقة ، لكن الأدب الأكاديمي يشير عادةً إلى محسن البركان التجريبي ، الذي تم تطويره في أوائل التسعينيات.
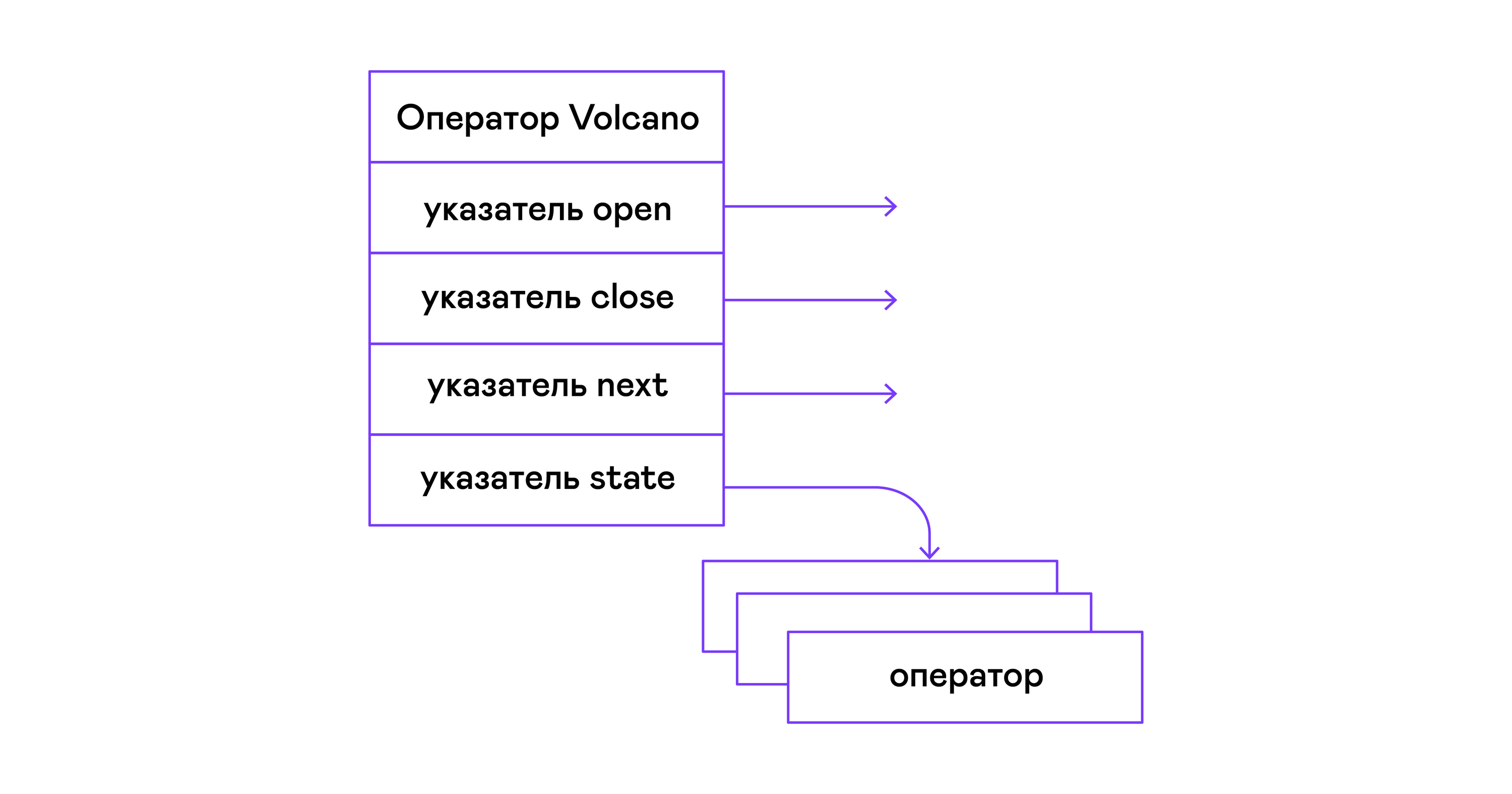
في نموذج البركان ، يتحول كل مشغل لشجرة الجبر المادي إلى هيكل به ثلاث وظائف: مفتوحة ، تالية ، قريبة. بالإضافة إلى الوظائف ، يحتوي المشغل على حالة تشغيل. تقوم الدالة المفتوحة ببدء حالة العبارة ، وتقوم الدالة التالية بإرجاع إما الطبقة التالية (اللغة الإنجليزية) أو NULL ، إذا لم يتبق أي عدد ، فإن وظيفة الإغلاق تنهي العبارة:
يمكن تداخل المشغلين لتشكيل شجرة مشغلي الجبر المادي. وبالتالي ، يتكرر كل عامل على الصفوف الخاصة بأي علاقة موجودة على وسيط حقيقي أو علاقة افتراضية تتكون من تعداد tuples للعوامل المتداخلة:
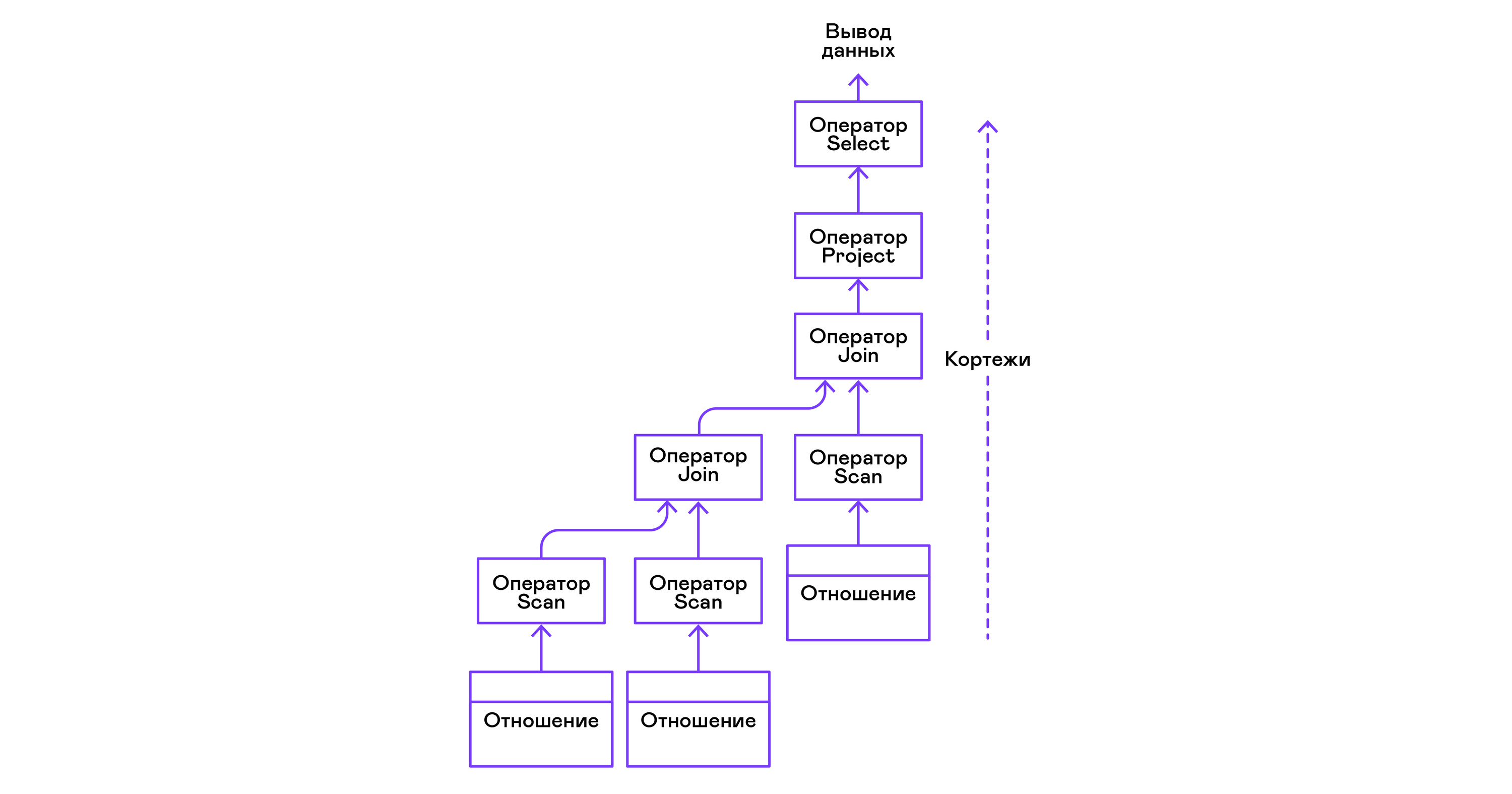
فيما يتعلق باللغات الحديثة عالية المستوى ، فإن شجرة هؤلاء المشغلين هي سلسلة من المتكررين.
حتى مترجمو الاستعلام الصناعي في نظام إدارة قواعد البيانات العلائقية يتم صدهم من نموذج البركان ، ولهذا السبب أخذته كأساس لمترجم PigletQL.
PigletQL
لإظهار النموذج ، قمت بتطوير مترجم لغة PigletQL المحدودة للاستعلام. هو مكتوب في C ، ويدعم إنشاء الجداول في نمط SQL ، ولكن يقتصر على نوع واحد - أعداد صحيحة موجبة 32 بت. جميع الجداول في الذاكرة. يعمل النظام في مؤشر ترابط واحد وليس لديه آلية معاملة.
لا يوجد أي مُحسِّن في PigletQL ، ويتم تجميع استعلامات SELECT مباشرةً في شجرة المشغل من الجبر المادي. تعمل الاستعلامات المتبقية (CREATE TABLE و INSERT) مباشرة من طرق العرض الداخلية الأساسية.
مثال لجلسة المستخدم في PigletQL:
> ./pigletql > CREATE TABLE tab1 (col1,col2,col3); > INSERT INTO tab1 VALUES (1,2,3); > INSERT INTO tab1 VALUES (4,5,6); > SELECT col1,col2,col3 FROM tab1; col1 col2 col3 1 2 3 4 5 6 rows: 2 > SELECT col1 FROM tab1 ORDER BY col1 DESC; col1 4 1 rows: 2
معجمية ومحلل
PigletQL هي لغة بسيطة جدًا ، ولم يكن تنفيذها مطلوبًا في مراحل التحليل المعجمي والتحليلي.
محلل المعجم مكتوب باليد. يتم إنشاء كائن محلل ( scanner_t ) من سلسلة الاستعلام ، والتي تعطي الرموز المميزة واحدة تلو الأخرى:
scanner_t *scanner_create(const char *string); void scanner_destroy(scanner_t *scanner); token_t scanner_next(scanner_t *scanner);
يتم إجراء التحليل باستخدام طريقة النسب العودية. أولاً ، يتم إنشاء كائن parser_t ، والذي ، بعد تلقي المحلل المعجمي (scanner_t) ، يملأ كائن query_t بمعلومات حول الطلب:
query_t *query_create(void); void query_destroy(query_t *query); parser_t *parser_create(void); void parser_destroy(parser_t *parser); bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
نتيجة تحليل في query_t هي واحدة من ثلاثة أنواع من الاستعلام مدعومة من قبل PigletQL:
typedef enum query_tag { QUERY_SELECT, QUERY_CREATE_TABLE, QUERY_INSERT, } query_tag; typedef struct query_t { query_tag tag; union { query_select_t select; query_create_table_t create_table; query_insert_t insert; } as; } query_t;
أكثر أنواع الاستعلامات تعقيدًا في PigletQL هي SELECT. يتوافق مع بنية بيانات query_select_t :
typedef struct query_select_t { attr_name_t attr_names[MAX_ATTR_NUM]; uint16_t attr_num; rel_name_t rel_names[MAX_REL_NUM]; uint16_t rel_num; query_predicate_t predicates[MAX_PRED_NUM]; uint16_t pred_num; bool has_order; attr_name_t order_by_attr; sort_order_t order_type; } query_select_t;
تحتوي البنية على وصف للاستعلام (صفيف من السمات التي طلبها المستخدم) ، وقائمة بمصادر البيانات - العلاقات ، ومجموعة من التنبؤات بتصفية المجموعات ، ومعلومات حول السمة المستخدمة لفرز النتائج.
محلل الدلالي
تتضمن مرحلة التحليل الدلالي في SQL العادي التحقق من وجود الجداول المدرجة ، والأعمدة في الجداول ، والنوع في تعبيرات الاستعلام. لعمليات الفحص المتعلقة بالجداول والأعمدة ، يتم استخدام دليل قاعدة البيانات ، حيث يتم تخزين كافة المعلومات حول بنية البيانات.
لا توجد تعبيرات معقدة في PigletQL ، لذلك يتم تقليل التحقق من الاستعلام للتحقق من بيانات تعريف كتالوج الجداول والأعمدة. يتم التحقق من صحة استعلامات SELECT ، على سبيل المثال ، بواسطة validate_select function. سأحضرها في شكل مختصر:
static bool validate_select(catalogue_t *cat, const query_select_t *query) { for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) { if (catalogue_get_relation(cat, query->rel_names[rel_i])) continue; fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]); return false; } if (!rel_names_unique(query->rel_names, query->rel_num)) return false; if (!attr_names_unique(query->attr_names, query->attr_num)) return false; return true; }
إذا كان الطلب صالحًا ، فستكون الخطوة التالية هي ترجمة شجرة التحليل إلى شجرة مشغل.
ترجمة الاستعلامات إلى طريقة عرض وسيطة
في المترجمين الفوريين SQL الكامل ، عادة ما يكون هناك تمثيلان وسيط: الجبر المنطقي والمادي.
يقوم مترجم PigletQL البسيط بإجراء استعلامات CREATE TABLE و INSERT مباشرةً من الأشجار التي يتم تحليلها ، أي ، query_create_table_t و query_insert_t . يتم تجميع استعلامات SELECT الأكثر تعقيدًا في تمثيل وسيط واحد ، والتي سيتم تنفيذها بواسطة المترجم الفوري.
شجرة المشغل مبنية من الأوراق إلى الجذر بالتسلسل التالي:
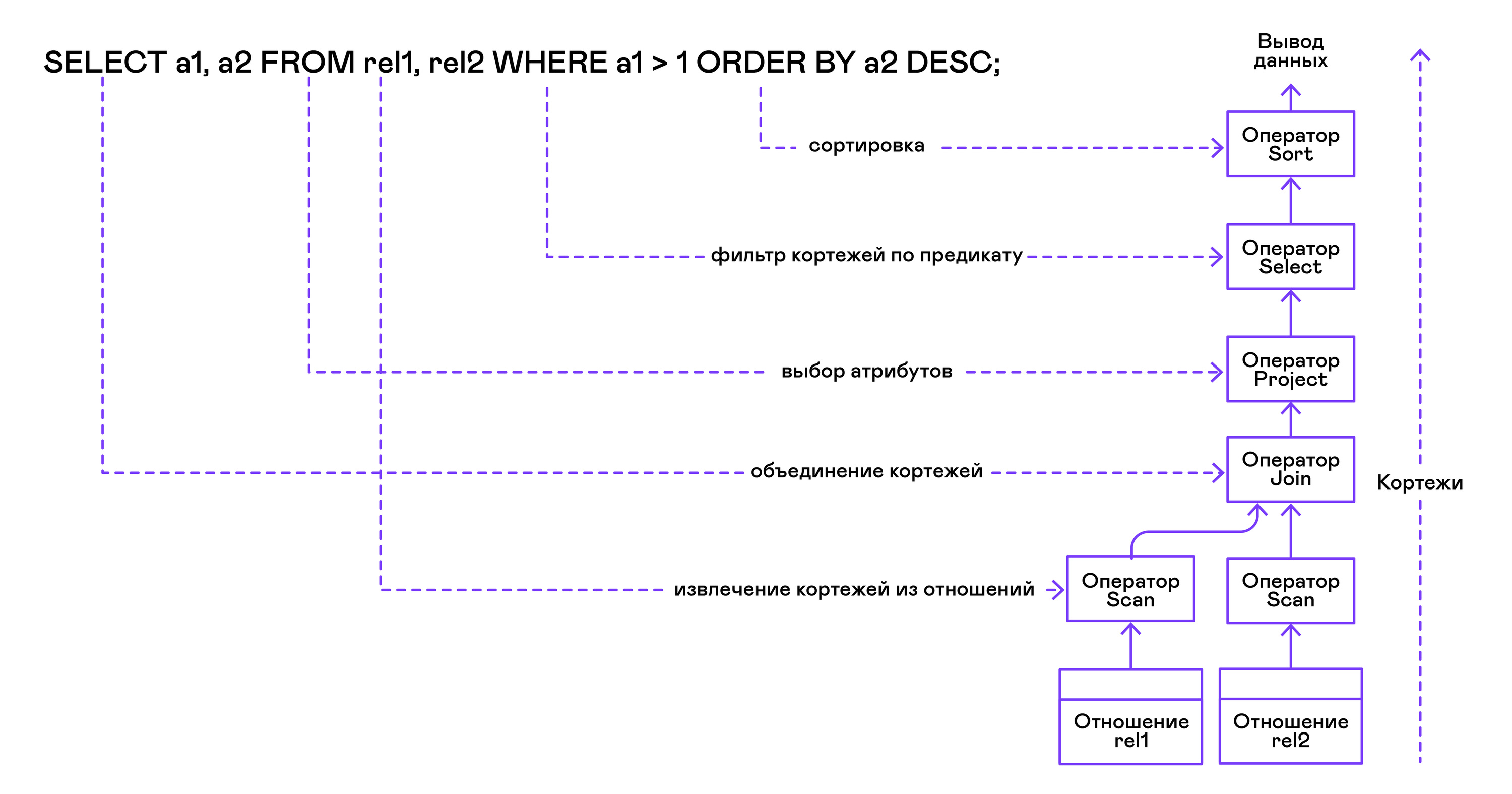
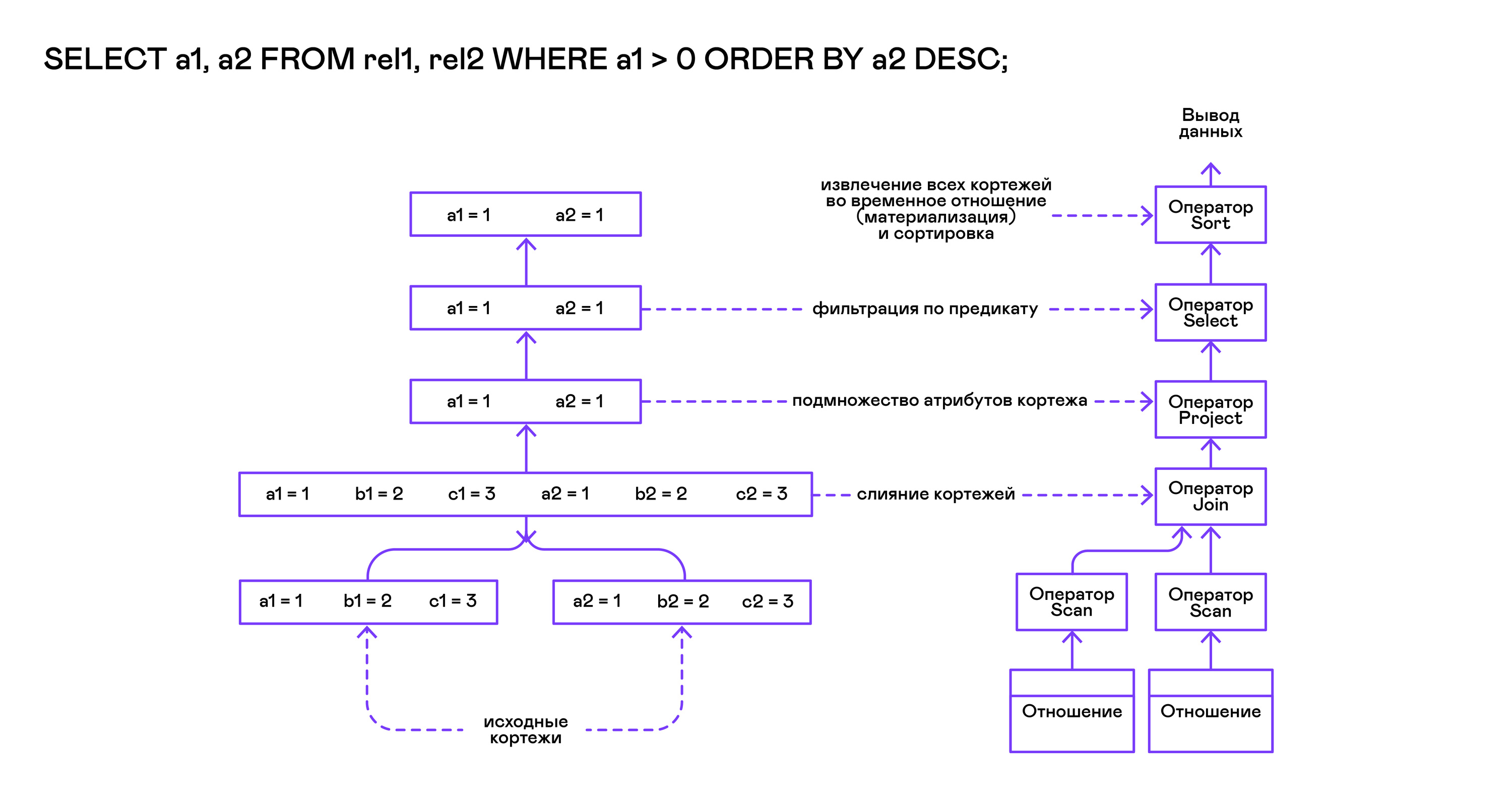
من الجزء الأيمن من الاستعلام ("... FROM relation1، relation2، ...") ، يتم الحصول على أسماء العلاقات المطلوبة ، ويتم إنشاء بيان مسح لكل منها.
استخراج tuples من العلاقات ، يتم دمج مشغلي المسح الضوئي في شجرة ثنائية الجانب الأيسر من خلال مشغل صلة.
يتم تحديد السمات التي يطلبها المستخدم ("SELECT attr1 ، attr2 ، ...") بواسطة بيان المشروع.
إذا تم تحديد أي تقديرات ("... WHERE a = 1 AND b> 10 ...") ، فسيتم إضافة عبارة التحديد إلى الشجرة أعلاه.
إذا تم تحديد طريقة فرز النتيجة ("... ORDER BY attr1 DESC") ، فسيتم إضافة عامل الفرز إلى أعلى الشجرة.
تجميع في رمز PigletQL:
operator_t *compile_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = NULL; { size_t rel_i = 0; relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]); root_op = scan_op_create(rel); rel_i += 1; for (; rel_i < query->rel_num; rel_i++) { rel = catalogue_get_relation(cat, query->rel_names[rel_i]); operator_t *scan_op = scan_op_create(rel); root_op = join_op_create(root_op, scan_op); } } root_op = proj_op_create(root_op, query->attr_names, query->attr_num); if (query->pred_num > 0) { operator_t *select_op = select_op_create(root_op); for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) { query_predicate_t predicate = query->predicates[pred_i]; } root_op = select_op; } if (query->has_order) root_op = sort_op_create(root_op, query->order_by_attr, query->order_type); return root_op; }
بعد تكوين الشجرة ، عادة ما يتم إجراء التحويلات المحسنة ، ولكن PigletQL تنتقل مباشرة إلى مرحلة تنفيذ التمثيل الوسيط.
تنفيذ عرض تقديمي مؤقت
يتضمن نموذج Volcano واجهة للعمل مع المشغلين من خلال ثلاث عمليات مشتركة مفتوحة / تالية / قريبة. في جوهرها ، كل عبارة فولكانو عبارة عن مكرر يتم من خلاله سحب "التلاميذ" واحدًا تلو الآخر ، لذلك يسمى هذا النهج للتنفيذ أيضًا نموذج السحب.
يمكن لكل من هذه التكرارات نفسها أن تسمي نفس الوظائف من التكرارات المتداخلة ، وأن تنشئ جداول مؤقتة بنتائج وسيطة ، وتحول الأنماط الواردة.
تنفيذ استعلامات SELECT في PigletQL:
bool eval_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = compile_select(cat, query); { root_op->open(root_op->state); size_t tuples_received = 0; tuple_t *tuple = NULL; while((tuple = root_op->next(root_op->state))) { if (tuples_received == 0) dump_tuple_header(tuple); dump_tuple(tuple); tuples_received++; } printf("rows: %zu\n", tuples_received); root_op->close(root_op->state); } root_op->destroy(root_op); return true; }
يتم تجميع الطلب أولاً بواسطة الدالة compile_select ، والتي تُرجع جذر شجرة المشغل ، وبعدها يتم استدعاء نفس وظائف الفتح / التالي / الإغلاق على مشغل الجذر. إرجاع كل استدعاء إلى التالي إما tuple التالي أو NULL. في الحالة الأخيرة ، هذا يعني أنه تم استخراج جميع الصفوف ، ويجب استدعاء وظيفة التكرار القريب.
يتم إعادة حساب المجموعات الناتجة وإخراجها بواسطة الجدول إلى دفق الإخراج القياسي.
مشغلي
الشيء الأكثر إثارة للاهتمام حول PigletQL هو شجرة المشغل. سأعرض جهاز بعض منهم.
لدى المشغلين واجهة مشتركة وتتكون من مؤشرات إلى الوظيفة open / next / close ووظيفة إتلاف إضافية ، والتي تُصدر موارد شجرة المشغل بالكامل مرة واحدة:
typedef void (*op_open)(void *state); typedef tuple_t *(*op_next)(void *state); typedef void (*op_close)(void *state); typedef void (*op_destroy)(operator_t *op); struct operator_t { op_open open; op_next next; op_close close; op_destroy destroy; void *state; } ;
بالإضافة إلى الوظائف ، قد يحتوي المشغل على حالة داخلية تعسفية (مؤشر حالة).
أدناه سوف أقوم بتحليل جهاز اثنين من المشغلين للاهتمام: أبسط المسح وإنشاء نوع العلاقة وسيطة.
مسح البيان
البيان الذي يبدأ أي استعلام هو المسح. انه يذهب فقط من خلال جميع tuples العلاقة. الحالة الداخلية للفحص هي مؤشر على العلاقة من حيث سيتم استرداد المجموعات ، ومؤشر المجموعة التالية في العلاقة ، وهيكل ارتباط إلى المجموعة الحالية ينتقل إلى المستخدم:
typedef struct scan_op_state_t { const relation_t *relation; uint32_t next_tuple_i; tuple_t current_tuple; } scan_op_state_t;
لإنشاء حالة بيان المسح ، تحتاج إلى علاقة مصدر ؛ كل شيء آخر (يشير إلى الوظائف المقابلة) معروف بالفعل:
operator_t *scan_op_create(const relation_t *relation) { operator_t *op = calloc(1, sizeof(*op)); assert(op); *op = (operator_t) { .open = scan_op_open, .next = scan_op_next, .close = scan_op_close, .destroy = scan_op_destroy, }; scan_op_state_t *state = calloc(1, sizeof(*state)); assert(state); *state = (scan_op_state_t) { .relation = relation, .next_tuple_i = 0, .current_tuple.tag = TUPLE_SOURCE, .current_tuple.as.source.tuple_i = 0, .current_tuple.as.source.relation = relation, }; op->state = state; return op; }
افتح / أغلق العمليات في حالة إعادة مسح المسح الضوئي مرة أخرى إلى العنصر الأول من العلاقة:
void scan_op_open(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; } void scan_op_close(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; }
المكالمة التالية إما إرجاع tuple التالي ، أو NULL إذا لم يكن هناك tuples أكثر في العلاقة:
tuple_t *scan_op_next(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; if (op_state->next_tuple_i >= op_state->relation->tuple_num) return NULL; tuple_source_t *source_tuple = &op_state->current_tuple.as.source; source_tuple->tuple_i = op_state->next_tuple_i; op_state->next_tuple_i++; return &op_state->current_tuple; }
بيان الترتيب
ينتج بيان الفرز tuples بالترتيب المحدد من قبل المستخدم. للقيام بذلك ، قم بإنشاء علاقة مؤقتة مع tuples التي تم الحصول عليها من العوامل المتداخلة وفرزها.
الحالة الداخلية للمشغل:
typedef struct sort_op_state_t { operator_t *source; attr_name_t sort_attr_name; sort_order_t sort_order; relation_t *tmp_relation; operator_t *tmp_relation_scan_op; } sort_op_state_t;
يتم إجراء الفرز وفقًا للسمات المحددة في الطلب (sort_attr_name و sort_order) عبر نسبة الوقت (tmp_relation). كل هذا يحدث عندما تسمى الوظيفة المفتوحة:
void sort_op_open(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; operator_t *source = op_state->source; source->open(source->state); tuple_t *tuple = NULL; while((tuple = source->next(source->state))) { if (!op_state->tmp_relation) { op_state->tmp_relation = relation_create_for_tuple(tuple); assert(op_state->tmp_relation); op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation); } relation_append_tuple(op_state->tmp_relation, tuple); } source->close(source->state); relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order); op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state); }
يتم تنفيذ تعداد عناصر العلاقة المؤقتة بواسطة العامل المؤقت tmp_relation_scan_op:
tuple_t *sort_op_next(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);; }
يتم إلغاء تخصيص العلاقة المؤقتة في الوظيفة الوثيقة:
void sort_op_close(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; if (op_state->tmp_relation) { op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state); scan_op_destroy(op_state->tmp_relation_scan_op); relation_destroy(op_state->tmp_relation); op_state->tmp_relation = NULL; } }
هنا يمكنك أن ترى بوضوح لماذا يمكن أن يستغرق فرز العمليات على الأعمدة بدون فهارس الكثير من الوقت.
أمثلة العمل
سأقدم بعض الأمثلة على استفسارات PigletQL والأشجار المقابلة للجبر المادي.
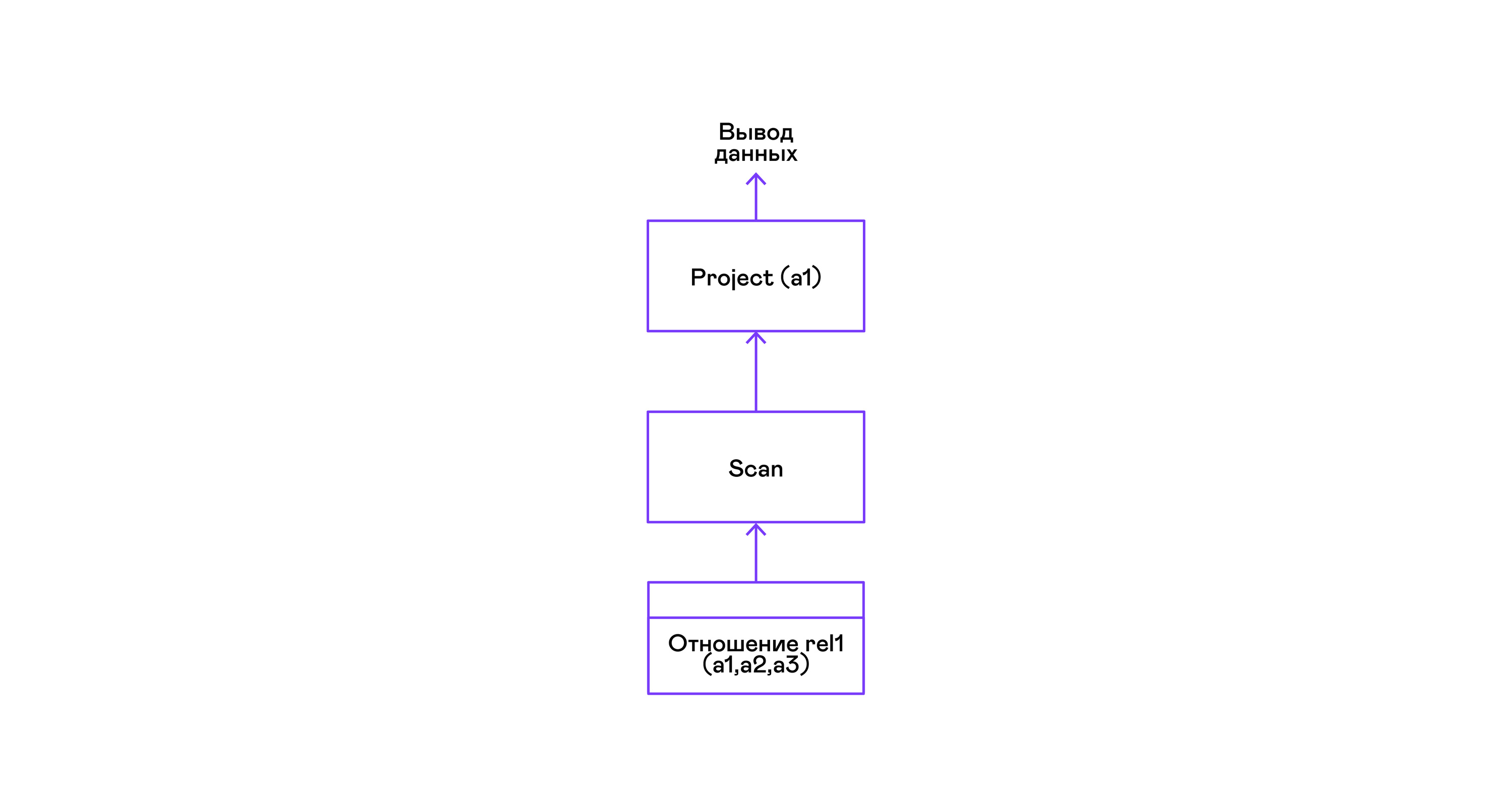
أبسط مثال يتم فيه اختيار جميع التلاميذ من علاقة:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1; a1 1 4 rows: 2 >
لأبسط الاستعلامات ، يتم استخدام استرجاع tuples فقط من علاقة المسح ، وتحديد السمة الوحيدة للمشروع من tuples:
اختيار tuples مع المسند:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 where a1 > 3; a1 4 rows: 1 >
يتم التعبير عن المسندات بواسطة عبارة التحديد:
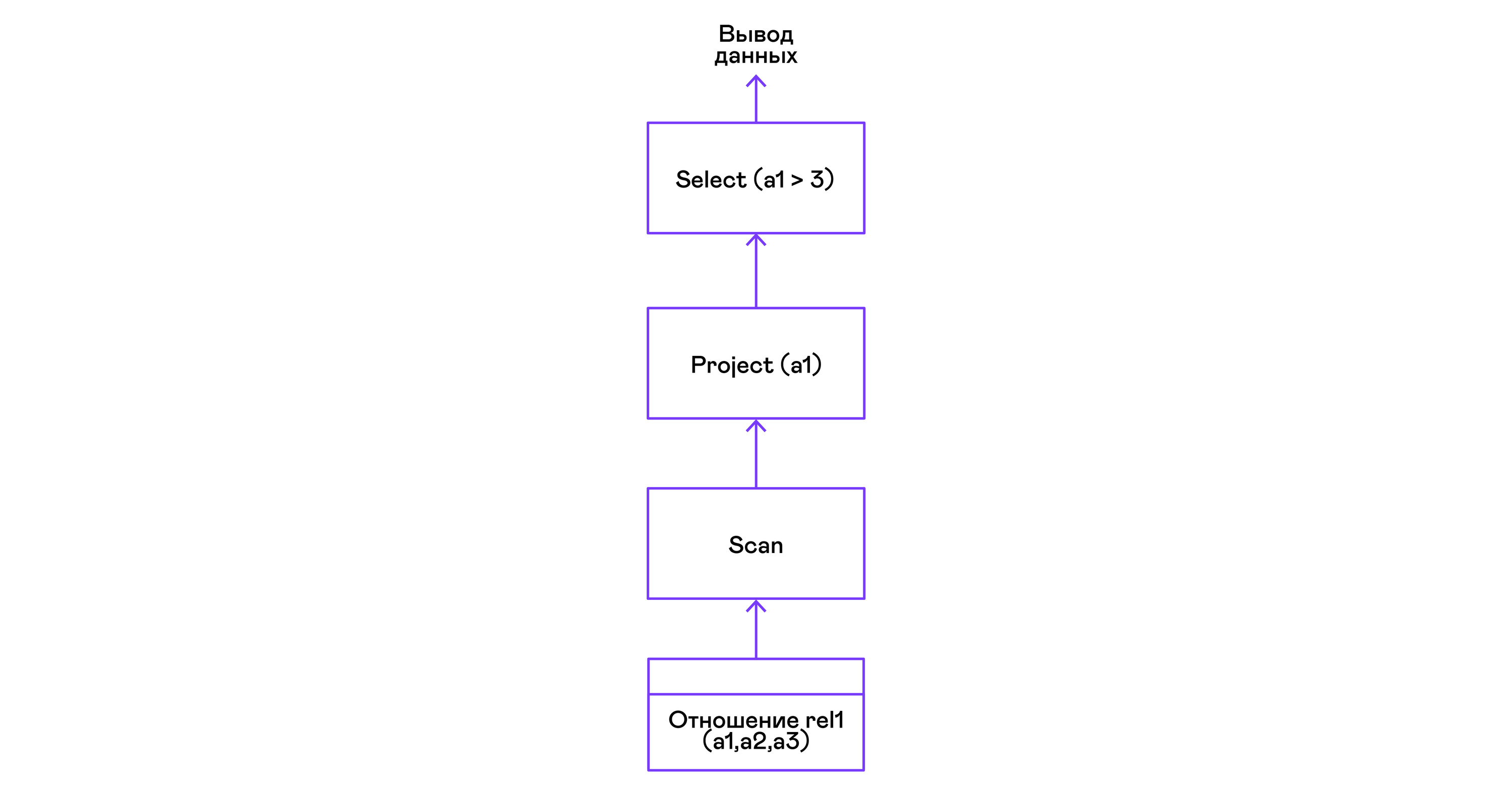
اختيار tuples مع الفرز:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 order by a1 desc; a1 4 1 rows: 2
ينشئ مشغل فرز المسح الضوئي في المكالمة المفتوحة ( يتحقق ) علاقة مؤقتة ، ويضع جميع tuples الواردة هناك ، ويرتب الكل. بعد ذلك ، في المكالمات التالية ، يستنتج tuples من العلاقة المؤقتة بالترتيب المحدد من قبل المستخدم:

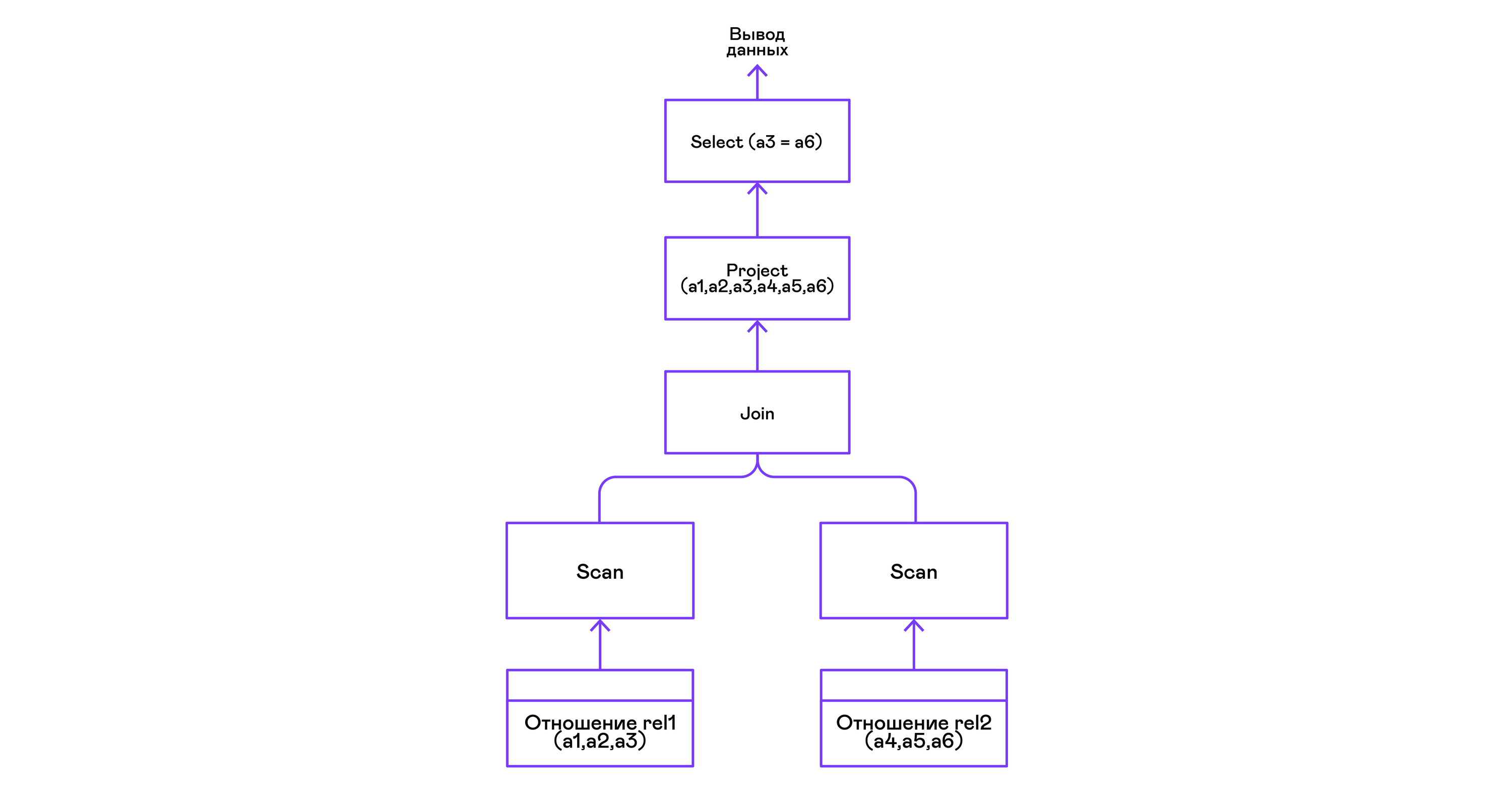
الجمع بين tuples من اثنين من العلاقات مع المسند:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > create table rel2 (a4,a5,a6); > insert into rel2 values (7,8,6); > insert into rel2 values (9,10,6); > select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6; a1 a2 a3 a4 a5 a6 4 5 6 7 8 6 4 5 6 9 10 6 rows: 2
لا يستخدم مشغل الربط في PigletQL أي خوارزميات معقدة ، ولكنه ببساطة يشكل منتجًا ديكارتًا من مجموعات tuples من الشجرة الفرعية اليمنى واليسرى. هذا غير فعال للغاية ، لكن بالنسبة للمترجم التجريبي ، فسوف يقوم بما يلي:
النتائج
في الختام ، لاحظت أنه إذا كنت تقوم بإجراء مترجم للغة مماثلة للغة SQL ، فمن المحتمل أنك يجب أن تأخذ فقط أيًا من قواعد البيانات العلائقية الكثيرة المتاحة. لقد تم استثمار آلاف السنين في المُحسِّنين الحديثين ومترجمي الاستعلام عن قواعد البيانات الشائعة ، ويستغرق الأمر سنوات حتى تطوير أبسط قواعد البيانات للأغراض العامة.
اللغة التجريبية PigletQL تحاكي عمل مترجم SQL ، لكن في الواقع نستخدم العناصر الفردية فقط في بنية بركان وفقط لتلك الاستعلامات (النادرة!) أنواع الاستعلامات التي يصعب التعبير عنها في إطار النموذج الترابطي.
ومع ذلك ، أكرر: حتى التعارف السطحي مع بنية هؤلاء المترجمين الفوريين يكون مفيدًا في الحالات التي يكون فيها من الضروري العمل بمرونة مع تدفقات البيانات.
أدب
إذا كنت مهتمًا بالمسائل الأساسية لتطوير قواعد البيانات ، فستكون الكتب أفضل من "تنفيذ نظام قاعدة البيانات" (Garcia-Molina H.، Ullman JD، Widom J.، 2000) ، فلن تجد.
العيب الوحيد هو التوجه النظري. أنا شخصياً أحب ذلك عندما يتم إرفاق أمثلة ملموسة من الكود أو حتى مشروع تجريبي بالمادة. لهذا ، يمكنك الرجوع إلى كتاب "تصميم وتنفيذ قاعدة البيانات" (Sciore E. ، 2008) ، والذي يوفر الكود الكامل لقاعدة بيانات علائقية في Java.
لا تزال قواعد البيانات العلائقية الأكثر شعبية تستخدم أشكالًا مختلفة حول موضوع البركان. تمت كتابة المنشور الأصلي بلغة يسهل الوصول إليها ويمكن العثور عليها بسهولة على الباحث العلمي من Google: "Volcano - نظام لتقييم الاستعلام موسع ومتوازي" (Graefe G. ، 1994).
على الرغم من أن المترجمين الفوريين SQL قد تغيروا قليلاً في التفاصيل على مدار العقود الماضية ، إلا أن الهيكل العام لهذه الأنظمة لم يتغير لفترة طويلة جدًا. يمكنك الحصول على فكرة عنها من ورقة مراجعة للمؤلف نفسه ، "تقنيات تقييم الاستعلام لقواعد البيانات الكبيرة" (Graefe G. 1993).