مرحبا يا هبر! اسمي نيكولاي ، وأنا منخرط في بناء وتنفيذ نماذج التعلم الآلي في سبيربنك. سأتحدث اليوم عن تطوير نظام توصيات للمدفوعات والتحويلات في التطبيق على هواتفك الذكية.
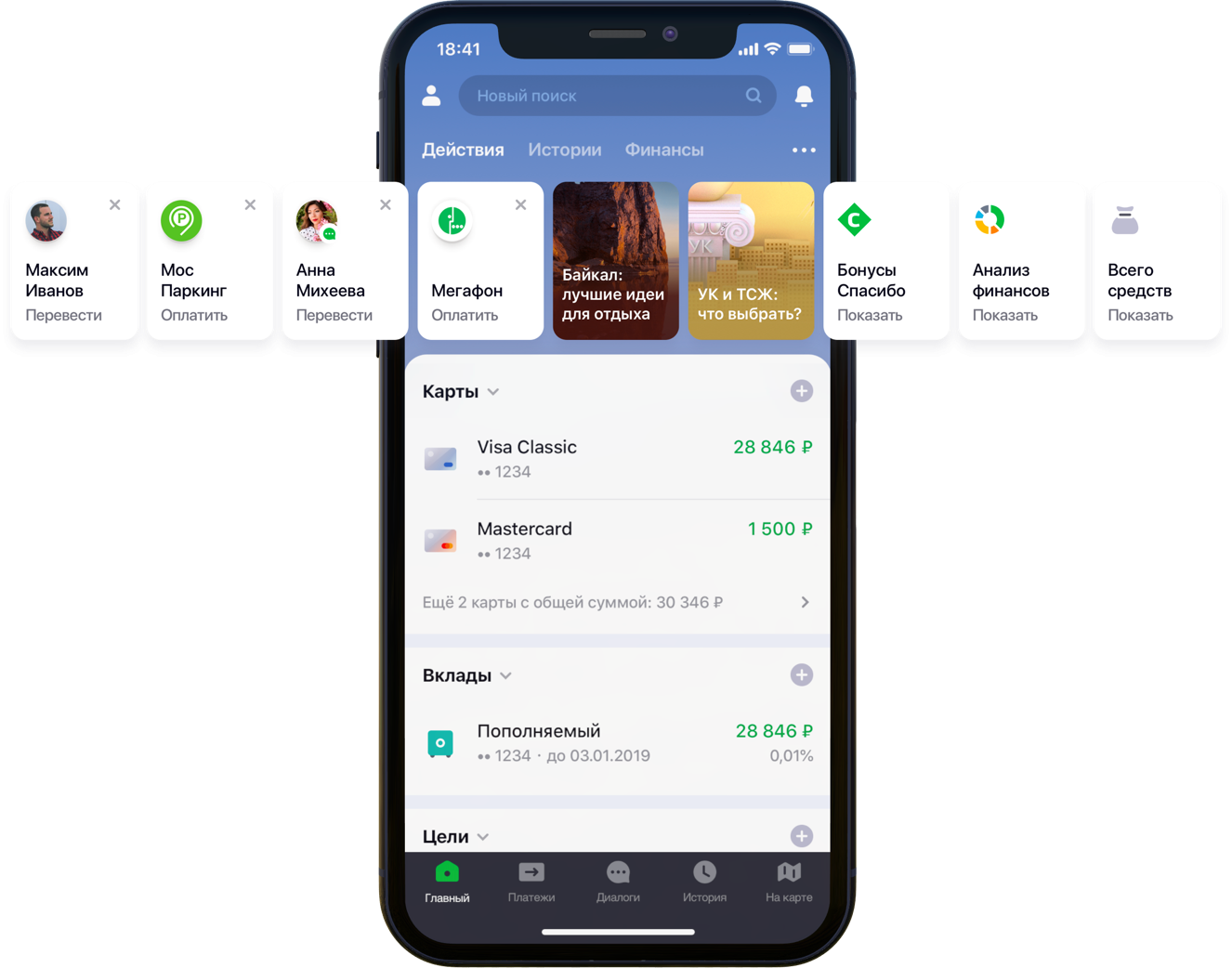 تصميم الشاشة الرئيسية للتطبيق المحمول مع التوصيات
تصميم الشاشة الرئيسية للتطبيق المحمول مع التوصياتكان لدينا مئات الآلاف من خيارات الدفع الممكنة ، 55 مليون عميل ، 5 مصادر مصرفية مختلفة ، نصف عمود مطور وجبل من النشاط المصرفي ، خوارزميات وكل ذلك ، كل الألوان ، بالإضافة إلى لتر من البذور العشوائية ، مربع من المعلمات الفائقة ، نصف لتر من عوامل التصحيح واثنين العشرات من المكتبات. ليس هذا كل ما هو ضروري في العمل ، ولكن منذ أن بدأ في تحسين حياة العملاء ، ثم انتقل إلى هوايتك. تحت القص ، هي قصة معركة UX ، والصياغة الصحيحة للمشكلة ، ومكافحة البعد من البيانات ، والمساهمة في المصادر المفتوحة ونتائجنا.
بيان المشكلة
مع التطوير والتوسع ، يكتسب تطبيق Sberbank Online ميزات مفيدة ووظائف إضافية. على وجه الخصوص ، في التطبيق يمكنك تحويل الأموال أو الدفع مقابل خدمات المنظمات المختلفة.
"لقد بحثنا بعناية في جميع مسارات المستخدم داخل التطبيق وأدركنا أنه يمكن تخفيض الكثير منها بشكل كبير. للقيام بذلك ، قررنا تخصيص الشاشة الرئيسية على عدة مراحل. أولاً ، حاولنا حذف ما لا يستخدمه العميل من الشاشة ، بدءًا من البطاقات المصرفية. ثم قاموا بإظهار تلك الإجراءات التي قام بها العميل بالفعل في وقت مبكر والتي يمكنه الدخول في التطبيق الآن. قال زميلي سيرجي كوماروف ، الذي يعمل على تطوير الوظيفة من وجهة نظر العميل في فريق Sberbank Online ، إن قائمة الإجراءات تتضمن مدفوعات للمنظمات وتحويلات إلى جهات اتصال ، ثم سيتم توسيع قائمة هذه الإجراءات. من الضروري إنشاء نموذج من شأنه أن يملأ الشرائح المخصصة في عناصر واجهة تعامل الإجراءات (الشكل أعلاه) بتوصيات شخصية للمدفوعات والتحويلات بدلاً من القواعد البسيطة.
قرار
نحن في الفريق حللنا المهمة إلى قسمين:
- توصية بتكرار العمليات لدفع تكاليف الخدمات أو تحويل الأموال (حظر "العمليات الموصى بها")
- توصية بأمثلة لطلبات البحث الخاصة بالدفع مقابل الخدمات التي لم يستخدمها هذا العميل من قبل (حظر "أمثلة البحث")
قررنا اختبار الوظيفة أولاً في علامة تبويب البحث:
أوصى تصميم شاشة البحثالعمليات الموصى بها
سجل التحسين
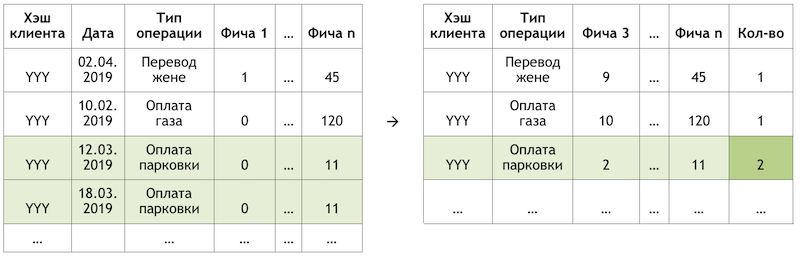
إذا قمنا بتعيين المهمة الفرعية كتكرار للعمليات ، فإن هذا يسمح لنا بالتخلص من حساب وتقييم تريليونات المجموعات المختلطة لجميع العمليات الممكنة لجميع العملاء والتركيز على عدد محدود للغاية منهم. إذا ، من بين مجموعة العمليات الكاملة المتاحة لعملائنا ، فإن العميل الافتراضي مع YYY has has يستخدم فقط الدفع مقابل الغاز ووقوف السيارات ، ثم سنقوم بتقييم احتمال تكرار هذه العمليات فقط لهذا العميل:
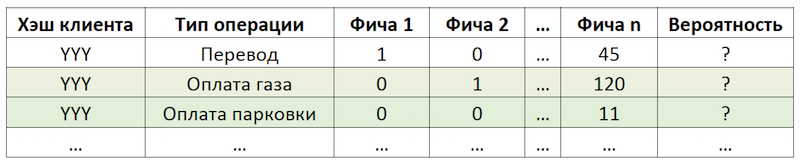 مثال على تقليل البعد البيانات للتسجيل
مثال على تقليل البعد البيانات للتسجيلإعداد مجموعة البيانات
العينة عبارة عن ملاحظة للمعاملات ، غنية بعوامل التركيبة السكانية للعميل ، والمجاميع المالية وخصائص التردد المختلفة لعملية معينة.
المتغير المستهدف في هذه الحالة ثنائي ويعكس حقيقة الحدث في اليوم التالي لليوم الذي يتم فيه حساب العوامل. وبالتالي ، مع تحريك يوم حساب العوامل وتحديد علامة المتغير الهدف بشكل متكرر ، فإننا نضرب ونحدد نفس العمليات ونضع علامة عليها بشكل مختلف اعتمادًا على الموضع بالنسبة لهذا اليوم.
مخطط المراقبةحساب الخفض في 03/17/2019 للعميل "YYY" ، نحصل على ملاحظتين:
مثال على الملاحظات لمجموعة البياناتيمكن أن تعني "الميزة 1" ، على سبيل المثال ، رصيد جميع بطاقات العميل ، "الميزة 2" - وجود هذا النوع من العمليات في الأسبوع الماضي.
نأخذ نفس المعاملات ، لكننا نشكل ملاحظات للتدريب في تاريخ مختلف:
مخطط المراقبةسوف نحصل على ملاحظات لمجموعة البيانات مع القيم الأخرى لكل من الميزات والمتغير الهدف:
 مثال على الملاحظات لمجموعة البيانات
مثال على الملاحظات لمجموعة البياناتفي الأمثلة أعلاه ، من أجل الوضوح ، يتم إعطاء القيم الفعلية للعوامل ، ولكن في الواقع ، تتم معالجة القيم بواسطة خوارزمية تلقائية: يتم تغذية نتائج
تحويل WOE إلى إدخال النموذج. يسمح لك بإحضار المتغيرات إلى علاقة رتابة مع المتغير الهدف وفي الوقت نفسه التخلص من آثار القيم المتطرفة. على سبيل المثال ، لدينا عامل "عدد البطاقات" وبعض التوزيع للمتغير الهدف:
 مثال التحويل WOE
مثال التحويل WOEيسمح لنا تحويل WOE بتحويل الاعتماد غير الخطي إلى واحد على الأقل رتيب. ترتبط كل قيمة للعامل الذي تم تحليله بقيمة WOE الخاصة به ، وبالتالي يتم تشكيل عامل جديد ، وتتم إزالة القيمة الأصلية من مجموعة البيانات:
 تحول تأثير WOE على العلاقة مع المتغير الهدف
تحول تأثير WOE على العلاقة مع المتغير الهدفيتم حفظ قاموس تحويل القيم المتغيرة إلى WOE واستخدامه لاحقًا للتسجيل. أي إذا احتجنا إلى حساب الاحتمالات ليوم غد ، فنحن ننشئ مجموعة بيانات كما في الجداول مع أمثلة على الملاحظات أعلاه ، ونحول المتغيرات الضرورية إلى WOE مع الكود المحفوظ ، ونطبق النموذج على هذه البيانات.
تدريب
كان اختيار الطريقة محدودًا تمامًا - التفسير. لذلك ، من أجل الامتثال للمواعيد النهائية ، تقرر تأجيل التفسيرات باستخدام نفس
SHAP في النصف الثاني من المشكلة واختبار طرق بسيطة نسبيا: الانحدار والخلايا العصبية الضحلة. كانت الأداة هي SAS Miner ، وهو برنامج للمعالجة المسبقة ، وتحليل ، وبناء نماذج على مختلف البيانات في شكل تفاعلي ، مما يوفر الكثير من الوقت في كتابة التعليمات البرمجية.
 ساس مينر واجهة
ساس مينر واجهةتقييم الجودة
أظهرت مقارنة مقياس GINI على عينة خارج الزمن أن الشبكة العصبية تتواءم مع المهمة على أفضل وجه:
جدول مقارن لنماذج الجودة وقواعد التردديحتوي النموذج على نقطتي خروج. تشمل التوصيات في شكل بطاقات واجهة المستخدم على الشاشة الرئيسية العمليات التي تكون توقعاتها أعلى من حد معين (انظر الصورة الأولى في المنشور). يتم تحديد الحدود بناءً على توازن الجودة والتغطية ، والذي يمثل نصف جميع العمليات المنفذة في مثل هذه البنية. يتم إرسال عمليات Top-4 إلى كتلة "العمليات الموصى بها" من شاشة البحث (انظر الصورة الثانية).
أمثلة البحث
بالانتقال إلى الجزء الثاني من المهمة ، نعود إلى مشكلة وجود عدد كبير من خيارات الدفع الممكنة لخدمات الموفرين الذين يحتاجون إلى التقييم والفرز داخل كل عميل - تريليونات من الأزواج. بالإضافة إلى ذلك ، لدينا بيانات ضمنية ، أي أنه لا توجد معلومات حول تقييم المدفوعات التي تم إجراؤها أو سبب عدم قيام العميل بأي مدفوعات. لذلك ، بالنسبة للمبتدئين ، فقد تقرر اختبار أساليب مختلفة لتوسيع مصفوفة المدفوعات من العملاء إلى مقدمي الخدمات: ALS و FM.
ALS
ALS (المربعات الصغرى المتناوبة) أو المربعات الصغرى المتناوبة - في التصفية التعاونية ، إحدى الطرق لحل مشكلة عوامل المصفوفة التفاعلية. سنقدم بيانات المعاملات الخاصة بنا حول دفع الخدمات في شكل مصفوفة تكون فيها الأعمدة معرفات فريدة لخدمات جميع مقدمي الخدمات ، والصفوف عملاء فريدون. في الخلايا ، نضع عدد عمليات عملاء محددين مع موفرين محددين لفترة زمنية محددة:
 مبدأ تحلل المصفوفة
مبدأ تحلل المصفوفةمعنى الطريقة هو أننا نقوم بإنشاء اثنين من هذه المصفوفات ذات البعد السفلي ، والتي يعطي ضربها أقرب نتيجة للمصفوفة الكبيرة الأصلية في الخلايا المملوءة. يتعلم النموذج إنشاء وصف عاملي مخفي للعملاء ومقدمي الخدمات. تم استخدام تطبيق الطريقة في المكتبة
الضمنية . يتم التدريب وفقًا للخوارزمية التالية:
- تتم تهيئة مصفوفات العملاء وموفري العوامل الخفية. عددهم هو hyperparameter للنموذج.
- مصفوفة العوامل الخفية لمقدمي الخدمات ثابتة ومشتق من وظيفة الخسارة لتصحيح مصفوفة العميل. استخدم المؤلف طريقة مثيرة للاهتمام في التدرجات المترافقة ، والتي تتيح لك تسريع هذه الخطوة بشكل كبير.
- يتم تكرار الخطوة السابقة بالمثل لمصفوفة العوامل الخفية للعملاء.
- الخطوات 2-3 البديل حتى تتقارب الخوارزمية.
تدريب
تم تحويل بيانات المعاملات إلى مصفوفة من التفاعلات مع درجة من تباين ~ 99 ٪ مع تفاوت كبير بين مقدمي الخدمات. لفصل البيانات في عينات تدريب والتحقق من صحتها ، قمنا بإخفاء عدد الخلايا المعبأة بشكل عشوائي:
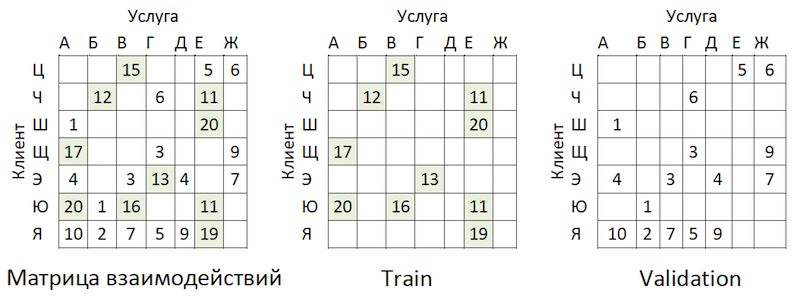 مثال مشاركة البيانات
مثال مشاركة البياناتتم أخذ المعاملات كاختبار للفترة الزمنية التي تلي التدريب ، وتم وضعها في مصفوفة من نفس التنسيق - لقد انتهى الوقت.
تدريب
يحتوي النموذج على العديد من المعلمات الفائقة التي يمكن ضبطها لتحسين الجودة:
- ألفا - معامل يتم من خلاله وزن المصفوفة ، وضبط درجة الثقة ( C_iu ) بأن الخدمة المقدمة من المزود "تعجب" العميل حقًا.
- عدد العوامل في المصفوفات المخفية للعملاء والموفرين هو عدد الأعمدة والصفوف ، على التوالي.
- معامل التنظيم L2 λ.
- عدد مرات تكرار الطريقة.
استخدمنا مكتبة
hyperopt ، والتي تتيح لنا تقييم تأثير المعلمات الفائقة على مقياس الجودة باستخدام طريقة
TPE وتحديد القيمة المثلى لها. تبدأ الخوارزمية ببداية باردة وتقوم بإجراء عدة تقييمات لمقياس الجودة اعتمادًا على قيم المعلمات الفوقية التي تم تحليلها. ثم ، في جوهره ، يحاول تحديد مجموعة من قيم المعلمات الفائقة التي من المرجح أن تعطي قيمة جيدة لقياس الجودة. يتم حفظ النتائج في قاموس يمكنك من خلاله إنشاء رسم بياني وتقييم مرئي لنتائج المحسن (اللون الأزرق أفضل):
رسم بياني لمقاييس الجودة مقابل مجموعة المقاييس الفوقيةيوضح الرسم البياني أن قيم المعلمات الفائقة تؤثر بشدة على جودة النموذج. نظرًا لأنه من الضروري تطبيق نطاقات لكل منها على إدخال الطريقة ، يمكن للرسم البياني تحديد ما إذا كان من المنطقي توسيع مساحة القيمة أم لا. على سبيل المثال ، من الواضح في مهمتنا أنه من المنطقي اختبار قيم كبيرة لعدد العوامل. في المستقبل ، هذا حقا تحسين النموذج.
تقييم الجودة متري والتعقيد
كيفية تقييم جودة النموذج؟ أحد المقاييس الأكثر شيوعًا لأنظمة التوصية حيث يكون الترتيب مهمًا هو
MAP @ k أو Mean Average Precision في K. ويقيس هذا المقياس دقة النموذج على توصيات K ، مع مراعاة ترتيب العناصر في قائمة هذه التوصيات في المتوسط لجميع العملاء.
لسوء الحظ ، استغرقت عملية تقييم الجودة حتى على عينة عدة ساعات. بعد أن طوَّرت عن سواعدنا ، بدأنا في تحديد وظيفة mean_a aver_pecision_at_k () مع مكتبة line_profiler. ومما زاد من تعقيد المهمة حقيقة أن الوظيفة تستخدم كود cython وكان لا بد من
أخذها في الاعتبار بشكل صحيح ، وإلا لم يتم جمع الإحصاءات اللازمة. نتيجة لذلك ، واجهنا مرة أخرى مشكلة بُعدية بياناتنا. لحساب هذا المقياس ، تحتاج إلى الحصول على بعض التقديرات لكل خدمة من كل ما هو ممكن لكل عميل وتحديد التوصيات الشخصية من أعلى K عن طريق التصنيف من الصفيف الناتج. حتى لو نظرنا إلى استخدام الفرز الجزئي لـ numpy.argpartition () مع تعقيد O (n) ، فقد أصبح فرز الدرجات هو الخطوة الأطول ، حيث امتدت عملية تصنيف الجودة على مدار الساعة. نظرًا لأن numpy.argpartition () لم يستخدم كل نواة خادمنا ، فقد تقرر تحسين الخوارزمية عن طريق إعادة كتابة هذا الجزء في C ++ و OpenMP عبر cython. خوارزمية جديدة لفترة وجيزة هي كما يلي:
- يتم قطع البيانات إلى دفعات من قبل العملاء.
- تهيئة مصفوفة فارغة ومؤشرات للذاكرة.
- يتم فرز سلاسل الدُفعات حسب المؤشرات بطريقتين: حسب دالة الجزئية ثم الفرز حسب مكتبة خوارزمية C ++.
- تتم كتابة النتائج على خلايا المصفوفة الفارغة على التوازي.
- يتم إرجاع البيانات في بيثون.
هذا سمح لنا بتسريع حساب التوصيات عدة مرات. تمت
إضافة المراجعة إلى المستودع الرسمي.
تحليل نتائج OOT
والآن حان الوقت لتقييم جودة النموذج. لماذا نحتاج إلى أخذ عينات خارج الوقت المحدد؟ إذا نظرنا إلى توزيع العمليات من قبل مقدمي الخدمات ، فسنرى الصورة التالية:
توزيع شعبية مقدمي الخدماتهناك خلل. هذا يؤدي إلى حقيقة أن النموذج يحاول التوصية بخدمات شعبية. العودة إلى الصورة أعلاه:
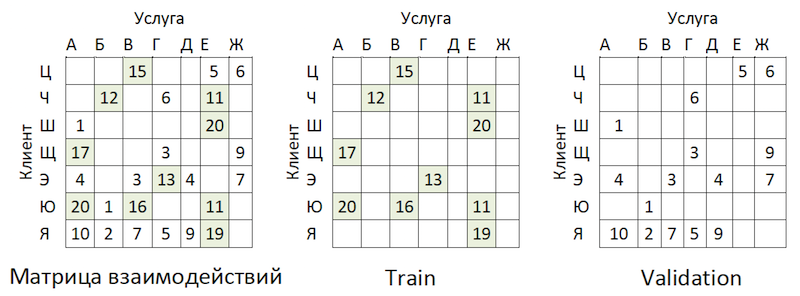
المشكلة هي أنه إذا قمت بفحص دقة النموذج عن طريق إخفاء المصفوفة نفسها ، كما هو موصى به في كل مكان تقريبًا ، فبالنسبة لمعظم العملاء (أمثلة هامشية: "W" و "E" و "I") جودة تنبؤات التحقق من الصحة (سوف ندعي أن وقالت إنها لم تشارك في اختيار hyperparameters) ستكون عالية إذا كانت هذه هي مقدمي الأكثر شعبية. نتيجة لذلك ، نحصل على ثقة زائفة في قوة النموذج. لذلك ، تصرفنا على النحو التالي:
- التقديرات المشكلة لمقدمي الخدمات حسب النموذج.
- تم استبعاد أزواج خدمة العملاء الحالية من التصنيفات (انظر الشكل أدناه) ومصفوفات OOT.
- تم تشكيلها من التصنيفات المتبقية لتوصيات أعلى الصفحة وتقييم الـ MAP @ k على OOT المتبقية.
 منطق إعداد المصفوفة لتوليد التوقعات
منطق إعداد المصفوفة لتوليد التوقعاتكخط أساسي ، قمنا بتجميع قائمة من مقدمي الخدمات ، مرتبة حسب الشعبية ، وضربناها من قبل جميع العملاء ، مرة أخرى باستثناء أزواج خدمة العملاء الحالية. اتضح أن هذا أمر محزن وليس على الإطلاق ما توقعناه ورأينا في عينات التحقق من القطار:
المعيار ونموذج مقارنة جودة الرسم البيانيتوقف عن ذلك! لدينا عوامل العميل والمعلمات من مقدمي الخدمات. نحصل على آلات التخصيم.
FM
آلات التخصيم (آلة التهيئة) - خوارزمية تعليمية مع المعلم ، مصممة لإيجاد علاقات بين العوامل التي تصف الكيانات المتفاعلة ، والتي يتم تقديمها في شكل مصفوفات متفرقة. استخدمنا تطبيق FM من مكتبة
LightFM .
تنسيق البيانات
بالإضافة إلى مصفوفة التفاعل المعيارية ، تستخدم
الطريقة مجموعتي بيانات إضافيتين تشتملان على عوامل للعملاء وللخدمات المقدمة من مقدمي الخدمات في شكل مصفوفات ذات ترميز واحد ساخن متصلة بأخرى مفردة:
 منطق إعداد المصفوفة لتوليد التوقعات
منطق إعداد المصفوفة لتوليد التوقعاتتقييم الجودة
تبين أن جودة نموذج FM على بياناتنا أقل من ALS:
جدول مقارن لنماذج الجودة وخط الأساستغيير نموذج العمارة - تعزيز
تقرر أن تأتي من الجانب الآخر. وإذ نذكّر بتوزيع شعبية الخدمات ، فقد حددنا 300 منها ، المعاملات التي تغطي 80 ٪ من جميع العمليات ، وقمنا بتدريب المصنف عليها. هنا ، تمثل البيانات مجاميع معاملات العملاء المخصّصة بميزات العميل:
 مخطط تجميع المعاملات
مخطط تجميع المعاملاتلماذا فقط العميل ، تسأل؟ لأنه في هذه الحالة ، لإعداد التوصيات ، سيكون كافياً بالنسبة لنا أن يكون لدينا سطر واحد لكل عميل. بتطبيق النموذج عليه ، نحصل على متجه مخرجات الاحتمالات لجميع الفئات ، والتي من السهل اختيار توصيات أفضل من K. إذا أضفنا ميزات خدمات الموفر إلى مجموعة التدريب ، فسوف نضطر في مرحلة تطبيق النموذج إلى إعداد 300 سطر لكل عميل - واحد لكل خدمة مزود بميزات تصفها ، أو بناء نموذج آخر لمرشحي تسجيل النتائج المسبق .
لا تؤدي إضافة ميزات إلى العملاء من ALS إلى زيادة بياناتنا ، نظرًا لأننا أخذنا بالفعل في الاعتبار نشاط المعاملات - على سبيل المثال ، في أقسام MCC أو فئات بأسلوب "gamer" أو "theatre". في هذا التنسيق ، تمكنا من الحصول على نتائج جيدة:
جدول مقارن لنماذج الجودة وخط الأساسمرشح الإقليمية
على الرغم من الجودة العالية للنموذج ، تظل هناك مشكلة أخرى في هذا النهج. نظرًا لأن بنية البيانات والنموذج لا تعني استخدام ميزات خدمات مقدمي الخدمات ، فإن النموذج لا يأخذ في الاعتبار الجغرافيا تمامًا وقد يوصي الأشخاص بدفع مقابل خدمة مزود محلي من منطقة أخرى. لتقليل هذا الخطر ، قمنا بتطوير مرشح صغير لخفض الخيارات قبل الدخول في توصيات. يتم طرح سهل العودية على الخوارزمية:
- نقوم بجمع معلومات حول منطقة العميل من الملفات الشخصية للبنك والمصادر الداخلية الأخرى.
- نحن واحدة من المناطق الرئيسية للحضور لكل مزود.
- نحن نوضح / نملأ المعلومات المتعلقة بمنطقة العميل حسب مناطق مقدمي الخدمة الذين يستخدمهم.
بعد هذه التلاعب ، باستخدام
مؤشر Herfindahl ، نفصل مقدمي الخدمات الإقليميين ، الذين يمثلون في مجموعة محدودة من المناطق ، عن تلك الفيدرالية:
فصل مقدمي الخدمات عن طريق التواجد في المناطقنحن نشكل قناعًا مع موفري خدمات مقبولين من قبل العملاء ونستبعد العناصر غير الضرورية من تنبؤات النماذج قبل إنشاء قائمة بالتوصيات.
استنتاج
لقد طورنا نموذجين يشكلان مجموعة كاملة من التوصيات حول المدفوعات والتحويلات. كان من الممكن تقليل مسار العميل لنصف العمليات المتكررة بنقرة واحدة. في الخطط المستقبلية لتحسين نموذج "العمليات الموصى بها" باستخدام بيانات الملاحظات (يمكن إخفاء البطاقات ، وما إلى ذلك) ، مما يقلل من عتبة اختيار التوصيات وزيادة التغطية. من المخطط أيضًا توسيع تغطية الدفعات الموصى بها في نموذج "أمثلة البحث" وتطوير خوارزمية لتسجيل النتائج.
لقد مررنا بالطريق الشائك لبناء نظام للمدفوعات والتحويلات. في الطريق ، حصلنا على مطبات واكتسبنا خبرة في تحليل هذه المهام وتبسيطها ، وتقييم هذه الأنظمة بشكل صحيح ، وإمكانية تطبيق الأساليب ، والعمل الأمثل مع كميات كبيرة من البيانات ، وتوسيع فهمنا لخصائص هذه المهام بشكل كبير. على طول الطريق ، تمكنت من المساهمة في المصدر المفتوح ، الذي نستخدمه نحن أنفسنا. أتمنى لك مهام مثيرة للاهتمام وخطوط أساس واقعية وواحدة F1. شكرا لاهتمامكم!