تقريبا. العابرة. : نقدم انتباهكم إلى التفاصيل الفنية حول أسباب الانقطاع الأخير في الخدمة السحابية ، والتي يقدمها المبدعون في Grafana. هذا مثال كلاسيكي على كيف أن فرصة جديدة ومفيدة للغاية على ما يبدو مصممة لتحسين جودة البنية التحتية ... يمكن أن تسبب الكثير من الضرر إذا لم يتوقع المرء الفروق الدقيقة العديدة لتطبيقه في واقع الإنتاج. إنه لأمر رائع أن تظهر مثل هذه المواد التي تتيح لك التعلم ليس فقط من أخطائك. التفاصيل موجودة في ترجمة هذا النص من نائب رئيس المنتج من Grafana Labs.
في يوم الجمعة 19 يوليو ، توقفت خدمة Prometheus المستضافة في Grafana Cloud عن العمل لمدة 30 دقيقة تقريبًا. أعتذر لجميع العملاء الذين عانوا من الفشل. مهمتنا هي توفير الأدوات اللازمة للمراقبة ، ونفهم أن عدم إمكانية الوصول إليها يعقد حياتك. نحن نأخذ هذا الحادث على محمل الجد. تشرح هذه المذكرة ما حدث ، وكيف كان رد فعلنا عليه ، وما الذي نفعله حتى لا يحدث هذا مرة أخرى.
قبل التاريخ
تعتمد خدمة Grafana Cloud Hosted Prometheus على
Cortex ، وهو مشروع CNCF لإنشاء خدمة بروميثيوس قابلة للتطوير أفقياً ويمكن الوصول إليها ومتعددة المستأجرين. تتكون بنية Cortex من مجموعة من الخدمات المصغرة المنفصلة ، يؤدي كل منها وظيفته: النسخ المتماثل ، التخزين ، الطلبات ، إلخ. يجري تطوير اللحاء بنشاط ، وهي تتمتع باستمرار بفرص جديدة وتعمل على تحسين الإنتاجية. نقوم بانتظام بنشر إصدارات Cortex الجديدة للمجموعات بحيث يمكن للعملاء الاستفادة من هذه الفرص - لحسن الحظ ، يمكن تحديث Cortex دون توقف.
للحصول على تحديثات سلسة ، تتطلب خدمة Ingester Cortex نسخة متماثلة إضافية من Ingester أثناء عملية التحديث.
( ملاحظة : إنجستر هي العنصر الأساسي في Cortex. وتتمثل مهمتها في جمع دفق مستمر من العينات ، وتجميعها في أجزاء من Prometheus وتخزينها في قاعدة بيانات مثل DynamoDB أو BigTable أو Cassandra.) وهذا يتيح لـ Ingesters الأقدم. إعادة توجيه البيانات الحالية إلى Ingesters الجديدة. تجدر الإشارة إلى أن Ingesters يطالبون بالموارد. من أجل عملهم ، من الضروري وجود 4 نوى و 15 جيجابايت من الذاكرة لكل جراب ، أي 25٪ من طاقة المعالج وذاكرة الجهاز الأساسي في حالة مجموعات Kubernetes الخاصة بنا. بشكل عام ، عادة ما يكون لدينا موارد غير مستخدمة أكثر من ذلك بكثير في كتلة من 4 مراكز و 15 جيجابايت من الذاكرة ، لذلك يمكننا بسهولة تشغيل هذه Ingersers إضافية أثناء التحديثات.
ومع ذلك ، يحدث غالبًا أنه خلال التشغيل العادي ، لا تمتلك أي من هذه الأجهزة هذه 25٪ من الموارد غير المطالب بها. نعم ، نحن لا نسعى جاهدين: وحدة المعالجة المركزية والذاكرة هي دائما مفيدة لعمليات أخرى. لحل هذه المشكلة ، قررنا استخدام
أولويات قرنة Kubernetes . تكمن الفكرة في إعطاء المتدربين أولوية أعلى من الخدمات المجهرية الأخرى (عديمة الجنسية). عندما نحتاج إلى تشغيل إنغستر إضافي (N + 1) ، فإننا نفرض مؤقتًا قرونًا أخرى أصغر. يتم نقل هذه القرون إلى موارد مجانية على الأجهزة الأخرى ، وترك "ثقب" كبير بما يكفي لإطلاق Ingester إضافية.
في يوم الخميس الموافق 18 يوليو ، أطلقنا أربعة مستويات أولوية جديدة في مجموعاتنا:
حرجة وعالية ومتوسطة ومنخفضة . تم اختبارها على كتلة داخلية بدون مرور العميل لمدة أسبوع تقريبًا. افتراضيًا ، حصلت القرون التي ليس لها أولوية معينة على أولوية
متوسطة ؛ تم تعيين فئة ذات أولوية
عالية لـ Ingesters. تم تخصيص
Critical للمراقبة (Prometheus ، Alertmanager ، مصدر العقدة ، مقاييس حالة kube ، إلخ). لدينا التكوين مفتوح ، ونرى العلاقات العامة
هنا .
حادث
في يوم الجمعة 19 يوليو ، أطلق أحد المهندسين مجموعة Cortex جديدة مخصصة لعميل كبير. لم يتضمن التكوين الخاص بهذه المجموعة أولويات pod الجديدة ، لذا تم تعيين جميع الأيقونات الجديدة على الأفضلية الافتراضية -
المتوسطة .
لم يكن لدى مجموعة Kubernetes موارد كافية لمجموعة نظام Cortex الجديدة ، ولم يتم تحديث مجموعة إنتاج Cortex الحالية (تركت Ingesters دون أولوية
عالية ). نظرًا لأن المتعثرين في المجموعة الجديدة تعثروا في الأولوية
المتوسطة ، وعملت القرون الموجودة في الإنتاج دون أولوية على الإطلاق ، فقد أخرجت Ingesters من المجموعة الجديدة Ingesters من مجموعة إنتاج Cortex الحالية.
قامت ReplicaSet الخاصة بـ Ingester المحظورة في كتلة الإنتاج باكتشاف poded preceded وإنشاء واحدة جديدة للحفاظ على العدد المحدد من النسخ. تم تعيين جراب جديد إلى أولوية
متوسطة بشكل افتراضي ، وفقد "Ingester" التالي في الإنتاج الموارد. وكانت النتيجة
عملية تشبه الانهيار الجليدي أدت إلى انتزاع جميع القرون من شركة Ingester لمجموعات إنتاج Cortex.
يحتفظ الصغار بالحالة ويخزنون البيانات لمدة 12 ساعة سابقة. يسمح لنا ذلك بضغطها بشكل أكثر كفاءة قبل الكتابة على التخزين طويل الأجل. للقيام بذلك ، تقوم Cortex بتسلسل البيانات باستخدام جدول التجزئة الموزع (DHT) ، وتكرار كل سلسلة إلى ثلاثة Ingesters باستخدام تناسق النصاب القانوني على نمط Dynamo. لا يقوم Cortex بكتابة البيانات إلى Ingesters ، والتي يتم تعطيلها. وبالتالي ، عندما يغادر عدد كبير من Ingesters DHT ، لا يمكن لـ Cortex توفير النسخ المتماثل الكافي للسجلات ، وأنها "تسقط".
الكشف والقضاء
بدأت إخطارات Prometheus الجديدة المستندة إلى "المستند إلى
الخطأ " (ستظهر التفاصيل
المستندة إلى الخطأ في مقال لاحق) في إصدار صوت تنبيه بعد 4 دقائق من بدء الإغلاق. خلال الدقائق الخمس التالية أو نحو ذلك ، أجرينا التشخيصات وقمنا بتوسيع مجموعة Kubernetes الأساسية لاستيعاب مجموعات الإنتاج الجديدة والحالية.
بعد خمس دقائق ، نجح Ingesters القديمون في تسجيل بياناتهم بنجاح ، وبدأت البيانات الجديدة الجديدة ، وأصبحت مجموعات Cortex متاحة مرة أخرى.
استغرق الأمر 10 دقائق أخرى لتشخيص وإصلاح أخطاء خارج الذاكرة (OOM) من وكلاء المصادقة العكسية الموجود أمام Cortex. كانت أخطاء OOM ناتجة عن زيادة بمقدار عشرة أضعاف في QPS (كما نعتقد ، نظرًا للطلبات العدوانية المفرطة من خوادم عملاء Prometheus).
العواقب
وكان التوقف الكلي 26 دقيقة. لا توجد بيانات مفقودة. قام المُنشئون بنجاح بتحميل جميع بيانات الذاكرة إلى وحدة تخزين طويلة الأجل. أثناء إيقاف التشغيل ، حفظت خوادم عميل Prometheus الإدخالات
البعيدة إلى المخزن المؤقت باستخدام
واجهة برمجة تطبيقات remote_write المستندة إلى WAL
الجديدة (تأليف
Callum Styan من Grafana Labs) والإدخالات الفاشلة المتكررة بعد الفشل.
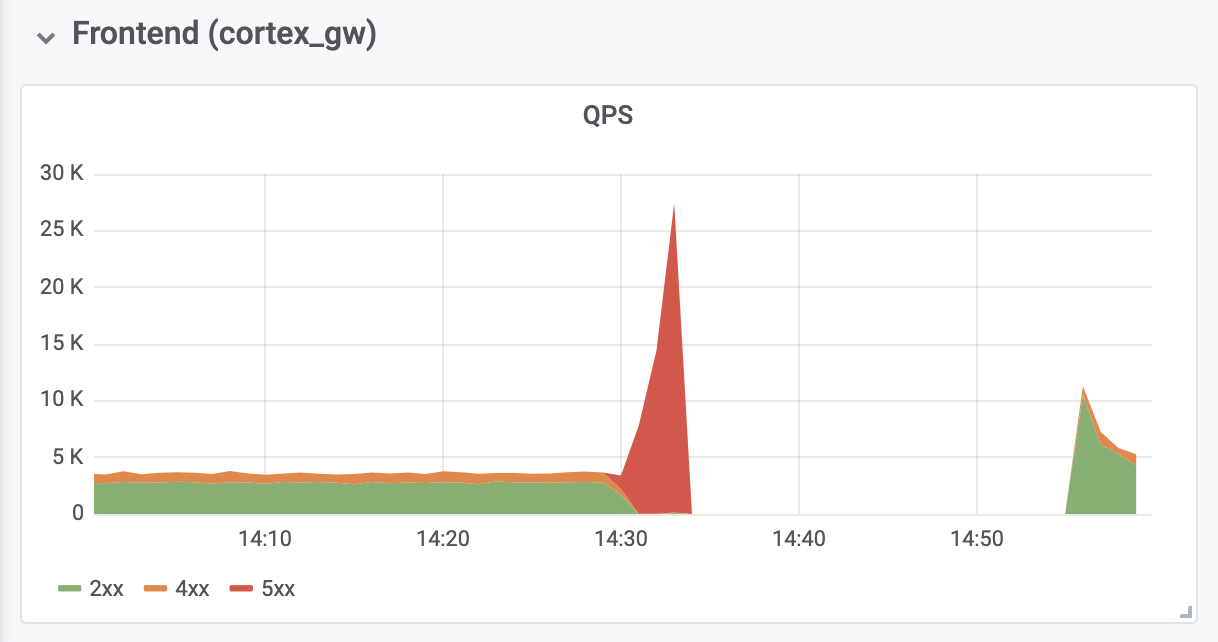 عمليات الكتابة العنقودية للإنتاج
عمليات الكتابة العنقودية للإنتاجالنتائج
من المهم أن نتعلم من هذا الحادث واتخاذ الخطوات اللازمة لتجنب تكرار.
إذا نظرنا إلى الوراء ، يجب أن نعترف أننا يجب ألا نضع أولوية
متوسطة افتراضية ، حتى يحصل جميع الصغار في الإنتاج على أولوية
عالية . بالإضافة إلى ذلك ، كان ينبغي عليهم الاهتمام بأولويتهم
العالية مقدمًا. الآن كل شيء ثابت. نأمل أن تساعد تجربتنا المنظمات الأخرى التي تفكر في استخدام أولويات pod في Kubernetes.
سنضيف مستوى إضافي من التحكم في نشر أي كائنات إضافية تكون تكويناتها عالمية للمجموعة. من الآن فصاعدا ، سيتم تقييم هذه التغييرات من قبل المزيد من الناس. بالإضافة إلى ذلك ، تم اعتبار التعديل الذي أدى إلى الفشل غير مهم للغاية بالنسبة لوثيقة مشروع منفصلة - تمت مناقشته فقط في قضية GitHub. من الآن فصاعدًا ، سيتم إرفاق جميع تغييرات التكوين هذه بوثائق المشروع المناسبة.
أخيرًا ، نقوم تلقائيًا بتغيير حجم وكيل المصادقة العكسي لمنع OOM أثناء الازدحام ، والذي شهدناه ، ونحلل إعدادات Prometheus الافتراضية المتعلقة بالتراجع والتدريج لمنع حدوث مشكلات مماثلة في المستقبل.
كان للفشل المتمرس أيضًا بعض النتائج الإيجابية: بعد تلقي الموارد اللازمة ، تعافى Cortex تلقائيًا دون أي تدخل إضافي. لقد
اكتسبنا أيضًا تجربة قيمة مع
Grafana Loki ، وهو نظام تجميع السجلات الجديد الخاص بنا ، والذي ساعد على ضمان تصرف جميع أنواع Ingesters بشكل صحيح أثناء التعطل وبعده.
PS من المترجم
اقرأ أيضًا في مدونتنا: