قد يبدو عنوان هذا المقال غريبًا بعض الشيء. في الواقع: إذا كنت تعمل في مجال علوم البيانات في عام 2019 ، فأنت بالفعل في الطلب. يتزايد الطلب على المتخصصين في هذا المجال بشكل مطرد: في وقت كتابة هذا التقرير ، تم نشر 144.527 وظيفة شاغرة باستخدام الكلمة الرئيسية "علوم البيانات" على LinkedIn.
ومع ذلك ، فإنه يستحق بالتأكيد متابعة آخر الأخبار والاتجاهات في هذه الصناعة. لمساعدتك في هذا ، حللنا مع فريق
CV Compiler عدة مئات من وظائف "علوم البيانات" في يونيو 2019 وحددنا المهارات التي يتوقعها أصحاب العمل أكثر من المرشحين.
الأكثر طلبًا بعد مهارات علوم البيانات في عام 2019
يوضح هذا الرسم البياني المهارات التي ذكرها أصحاب العمل في وظائف علوم البيانات في عام 2019:
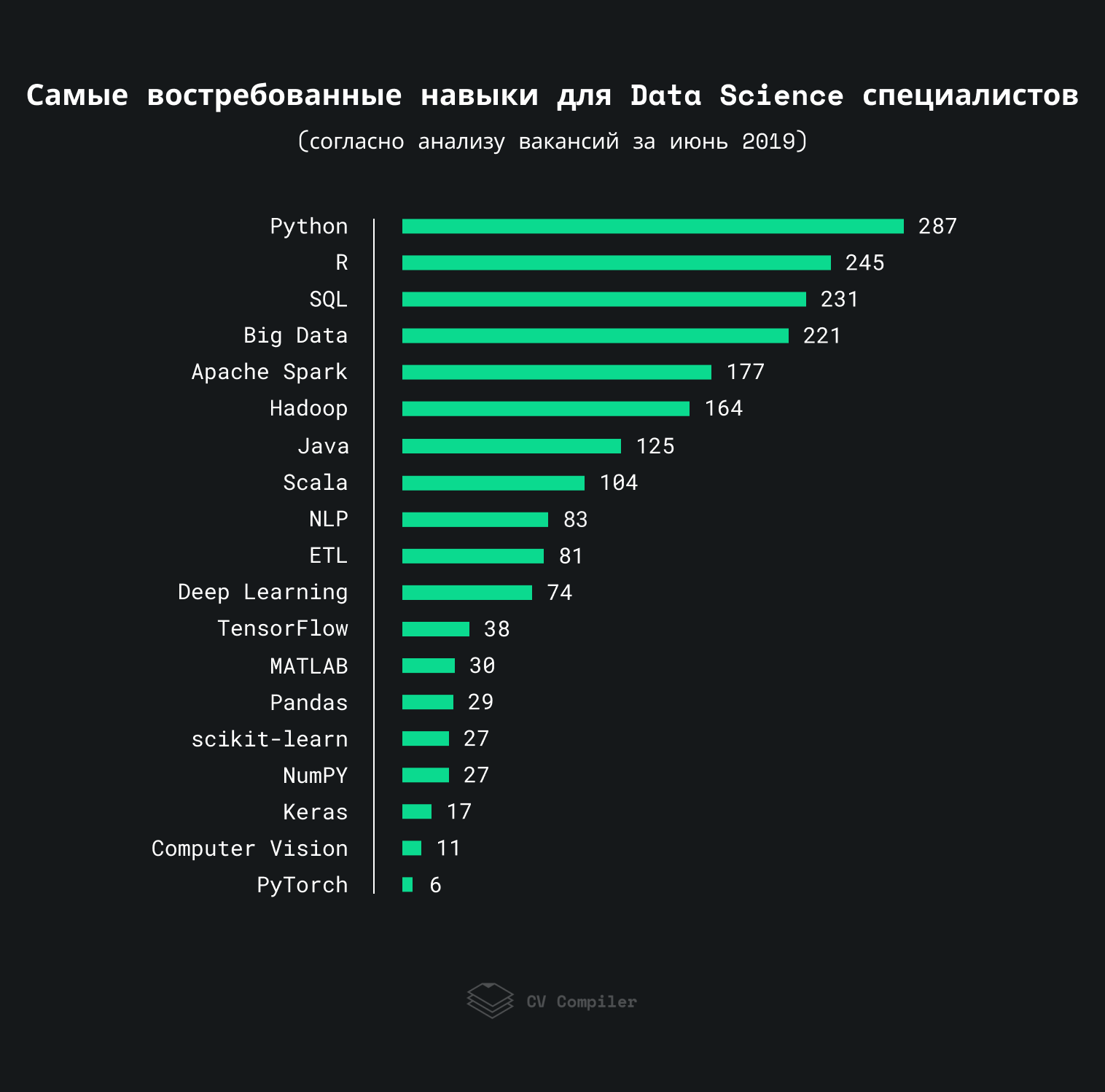
قمنا بتحليل حوالي 300 وظيفة باستخدام StackOverflow و AngelList وموارد مماثلة. يمكن تكرار بعض المصطلحات أكثر من مرة في نفس الوظيفة الشاغرة.
هام: يوضح هذا التصنيف تفضيلات أصحاب العمل بدلاً من المتخصصين في مجال علوم البيانات.
الاتجاهات الرئيسية في علم البيانات
من الواضح أن علوم البيانات ليست في الأساس أطر عمل ومكتبات ، بل هي معرفة أساسية. ومع ذلك ، لا تزال بعض الاتجاهات والتقنيات تستحق الذكر.
البيانات الكبيرة
وفقًا
لبحوث السوق للبيانات الكبيرة في عام 2018 ، زاد استخدام البيانات الكبيرة في المؤسسات من 17٪ في عام 2015 إلى 59٪ في عام 2018. وفقًا لذلك ، زادت شعبية أدوات العمل مع البيانات الضخمة. إذا تجاهلت Apache Spark و Hadoop (سنتحدث عن الأخير بمزيد من التفاصيل) ، فإن الأدوات الأكثر شعبية هي
MapReduce (36) و
Redshift (29).
Hadoop
على الرغم من شعبية Spark والتخزين السحابي ، فإن
عصر Hadoop لم ينته بعد. لذلك ، تتوقع بعض الشركات أن يعرف المرشحون
Apache Pig (30) و
HBase (32) وتقنيات مشابهة.
تم العثور على HDFS (20) أيضًا في بعض الوظائف.
في الوقت الحقيقي معالجة البيانات
نظرًا للاستخدام الشامل لكل أجهزة الاستشعار والأجهزة المحمولة ، فضلاً عن شعبية
إنترنت الأشياء (18) ، تحاول الشركات تعلم كيفية معالجة البيانات في الوقت الفعلي. لذلك ، فإن منصات الترابط مثل
Apache Flink (21) شائعة لدى أصحاب العمل.
ميزة الهندسة وضبط Hyperparameter
يعد إعداد البيانات واختيار معلمات النموذج جزءًا مهمًا من عمل أي متخصص في مجال علوم البيانات. لذلك ، فإن مصطلح
تعدين البيانات (128) يحظى بشعبية كبيرة بين أصحاب العمل. تهتم بعض الشركات أيضًا
بضبط Hyperparameter Tuning (21) (
لا ينبغي نسيان مصطلح مثل
Feature Engineering أيضًا ). من المهم اختيار المعلمات المثلى للنموذج ، لأن الأداء الكلي للنموذج يعتمد على نجاح هذه العملية.
التصور البيانات
من المهم القدرة على معالجة البيانات وعرض الأنماط اللازمة بشكل صحيح. ومع ذلك ،
تصور البيانات (55) هو مهارة بنفس القدر من الأهمية. يجب أن تكون قادرًا على تقديم نتائج عملك بتنسيق يمكن فهمه لأي عضو أو عميل في الفريق. من حيث أدوات تصور البيانات ، يفضل أصحاب العمل
Tableau (54).
الاتجاهات العامة
في الوظائف الشاغرة ، صادفنا أيضًا مصطلحات مثل
AWS (86) ،
Docker (36) ، وكذلك
Kubernetes (24). يمكن أن نستنتج أن الاتجاهات العامة من مجال تطوير البرمجيات انتقلت ببطء إلى مجال علوم البيانات.
رأي الخبراء
تعكس هذه القائمة من التقنيات حقًا الحالة الحقيقية للأشياء في عالم علوم البيانات. ومع ذلك ، لا توجد أشياء أقل أهمية من كتابة التعليمات البرمجية. هذه هي القدرة على تفسير نتائج أعمالهم بشكل صحيح ، وكذلك تصورها وتقديمها في شكل مفهوم. كل هذا يتوقف على الجمهور - إذا كنت تتحدث عن إنجازاتك لمرشحي العلوم ، وتحدث لغتهم ، ولكن إذا قدمت النتائج إلى العميل ، فلن يهتم بالشفرة - فقط النتيجة التي حققتها.
كارلا جينتري
عالم البيانات ، صاحب
الحل التحليليينكدين |
تغريديوضح هذا الرسم البياني الاتجاهات الحالية في مجال علوم البيانات ، لكن من الصعب التنبؤ بالمستقبل بناءً عليه. أنا أميل إلى الاعتقاد بأن شعبية R ستنخفض (مثل شعبية MATLAB) ، في حين أن شعبية بيثون سوف تنمو فقط. انتهت Hadoop و Big Data أيضًا في القائمة عن طريق القصور الذاتي: ستختفي Hadoop قريبًا (لم يعد أحد يستثمر بجدية في هذه التكنولوجيا بعد الآن) ، ولم تعد Big Data بمثابة اتجاه متزايد. مستقبل Scala ليس واضحًا تمامًا: تدعم Google رسميًا Kotlin ، وهو أسهل بكثير في التعلم. أنا أيضًا متشكك في مستقبل TensorFlow: المجتمع العلمي يفضل PyTorch ، وتأثير المجتمع العلمي في مجال علوم البيانات أعلى بكثير من جميع المجالات الأخرى. (هذا هو رأيي الشخصي ، والذي قد لا يتزامن مع رأي غارتنر).
أندريه بوركوف ،
مدير التعلم الآلي في غارتنر ،
مؤلف كتاب
مائة صفحة آلة التعلم .
ينكدينPyTorch هي القوة الدافعة وراء التعلم المعزز ، وكذلك إطار قوي لتنفيذ الشفرة الموازية على وحدات معالجة الرسومات المتعددة (والتي لا يمكن قولها عن TensorFlow). تساعد PyTorch أيضًا على إنشاء رسوم بيانية ديناميكية تكون فعالة عند العمل مع الشبكات العصبية المتكررة. تعمل TensorFlow برسوم بيانية ثابتة ويصعب دراستها ، ولكن يستخدمه المزيد من المطورين والباحثين. ومع ذلك ، فإن PyTorch أقرب إلى Python من حيث كود التصحيح والمكتبات لتصور البيانات (matplotlib ، seaborn). يمكن استخدام معظم أدوات تصحيح شفرة Python لتصحيح كود PyTorch. يحتوي TensorFlow أيضًا على أداة تصحيح الأخطاء الخاصة به - tfdbg.
جاناباتي بوليباكا ،
كبير علماء البيانات في أكسنتشر ،
أفضل 50 فائز بجائزة قائد التقنية.
ينكدين |
تغريدفي رأيي ، العمل والمهنة في علم البيانات ليسا نفس الشيء. للعمل ، ستحتاج إلى مجموعة المهارات المذكورة أعلاه ، ولكن لبناء مهنة ناجحة في علوم البيانات ، فإن أهم مهارة هي القدرة على التعلم. يعتبر Data Data حقلًا متقلبًا ، وعليك أن تتعلم إتقان التقنيات والأدوات والمناهج الجديدة من أجل مواكبة العصر. تفرض باستمرار تحديات جديدة ولا تحاول أن "تكتفي بالقليل".
لون ريسبيرج
مؤسس / أمينة
بيانات Elixir ،
السابق NASA.
تويتر |
ينكدينعلم البيانات هو مجال سريع التطور ومعقد فيه المعرفة الأساسية مهمة مثل تجربة أدوات معينة. نأمل أن تساعدك هذه المقالة في تحديد المهارات المطلوبة لتصبح متخصصًا أكثر رواجًا في مجال علوم البيانات في عام 2019. حظ سعيد!
كتب هذا المقال فريق CV Compiler ، وهو أداة لتحسين السير الذاتية لعلوم البيانات وغيرهم من متخصصي تكنولوجيا المعلومات.