
خلال السنوات القليلة الماضية ، تطورت قواعد بيانات السلاسل الزمنية من شيء فضولي (متخصص بدرجة عالية في أنظمة المراقبة المفتوحة (والمرتبطة بحلول محددة) أو مشاريع البيانات الكبيرة) إلى "سلع استهلاكية". في أراضي الاتحاد الروسي ، يجب تقديم شكر خاص إلى Yandex و ClickHouse على ذلك. حتى هذه المرحلة ، إذا كنت بحاجة إلى توفير كمية كبيرة من بيانات السلاسل الزمنية ، فعليك إما قبول الحاجة إلى رفع مكدس Hadoop وحشي ومرافقته ، أو التواصل مع البروتوكولات الخاصة بكل نظام.
قد يبدو أنه في عام 2019 ، ستتألف مقالة حول TSDB من جملة واحدة فقط: "مجرد استخدام ClickHouse". ولكن ... هناك فروق دقيقة.
في الواقع ، تتطور ClickHouse بنشاط ، وقاعدة المستخدمين تنمو ، والدعم نشط للغاية ، لكن هل أصبحنا رهائن لنجاح ClickHouse العام ، الذي طغى على حلول أخرى ، ربما أكثر فعالية / موثوقية؟
في بداية العام الماضي ، بدأنا في معالجة نظام المراقبة الخاص بنا ، والذي نشأ خلاله السؤال عن اختيار القاعدة المناسبة لتخزين البيانات. أريد أن أخبر عن تاريخ هذا الاختيار هنا.
بيان المشكلة
بادئ ذي بدء ، المقدمة اللازمة. لماذا نحتاج إلى نظام المراقبة الخاص بنا وكيف تم ترتيبه؟
بدأنا في تقديم خدمات الدعم في عام 2008 ، وبحلول عام 2010 أصبح من الواضح أنه كان من الصعب تجميع البيانات حول العمليات التي تحدث في البنية التحتية للعميل مع الحلول التي كانت موجودة في ذلك الوقت (نحن نتحدث عن ، سامحني الله ، Cacti ، Zabbix و الوليدة الجرافيت).
متطلباتنا الرئيسية هي:
- دعم (في ذلك الوقت - العشرات ، وفي المستقبل - المئات) من العملاء داخل نفس النظام وفي الوقت نفسه وجود نظام مركزي لإدارة التنبيه ؛
- المرونة في إدارة نظام التنبيه (تصاعد التنبيهات بين الحاضرين ، محاسبة الجدول ، قاعدة المعرفة) ؛
- إمكانية التفاصيل العميقة للرسوم البيانية (كان Zabbix في ذلك الوقت يرسم الرسوم البيانية في صورة صور) ؛
- تخزين طويل الأجل لكمية كبيرة من البيانات (سنة أو أكثر) والقدرة على تحديدها بسرعة.
في هذه المقالة ، نحن مهتمون بالنقطة الأخيرة.
عند الحديث عن التخزين ، كانت المتطلبات كما يلي:
- يجب أن يعمل النظام بسرعة ؛
- من المستحسن أن يحتوي النظام على واجهة SQL ؛
- يجب أن يكون النظام مستقرًا وأن يكون لديه قاعدة مستخدمين نشطة ودعم (بمجرد أن نواجه الحاجة إلى دعم أنظمة مثل MemcacheDB ، على سبيل المثال ، توقفنا عن تطويرها ، أو تخزين الموزع الموزع ، الذي تم إجراء bugtracker منه باللغة الصينية: تكرار هذه القصة لمشروعنا لا تريد) ؛
- المراسلات إلى CAP- theorem: الاتساق (ضروري) - يجب أن تكون البيانات ذات صلة ، لا نريد أن لا يتلقى نظام إدارة الإشعارات بيانات جديدة ويبث تنبيهات بشأن عدم وصول البيانات لجميع المشاريع ؛ Partition Tolerance (ضروري) - لا نريد الحصول على أنظمة Split Brain ؛ التوفر (ليس حرجًا ، في حالة وجود نسخة متماثلة نشطة) - يمكننا التبديل إلى نظام النسخ الاحتياطي في حالة وقوع حادث ، باستخدام رمز.
الغريب في ذلك الوقت ، كان MySQL هو الحل الأمثل لنا. كانت بنية بياناتنا بسيطة للغاية: معرف الخادم ، معرف العداد ، الطابع الزمني والقيمة ؛ تم توفير عينات سريعة من البيانات الساخنة بواسطة تجمع عازلة كبير ، وتم تقديم عينات البيانات التاريخية بواسطة SSD.
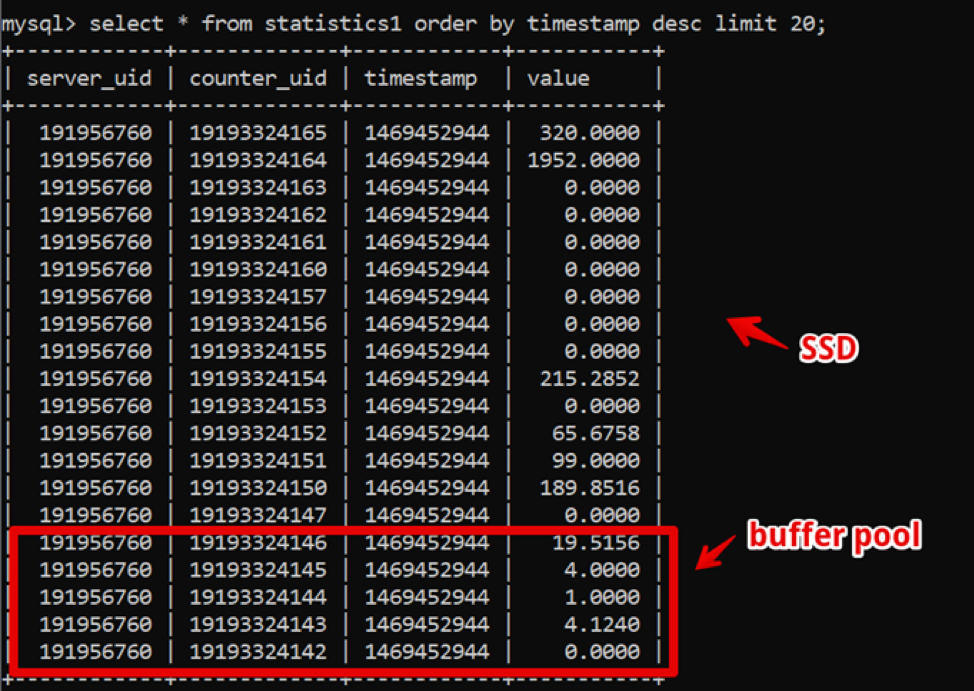
وبالتالي ، حققنا عينة من بيانات جديدة لمدة أسبوعين ، مع تفصيل يصل إلى 200 مللي ثانية قبل تقديم البيانات بالكامل ، وعاشنا في هذا النظام لبعض الوقت.
وفي الوقت نفسه ، مر الوقت ونمت كمية البيانات. بحلول عام 2016 ، وصلت أحجام البيانات إلى عشرات تيرابايت ، والتي من حيث تخزين SSD المستأجر كانت نفقات كبيرة.
في هذه المرحلة ، كانت قواعد البيانات العمودية تنتشر بشكل نشط ، وبدأنا في التفكير بنشاط: في قواعد البيانات العمودية ، يتم تخزين البيانات ، كما يمكنك أن تفهم ، في الأعمدة ، وإذا نظرت إلى بياناتنا ، فمن السهل أن نرى عددًا كبيرًا من الإجراءات التي يمكن أن تكون في حالة استخدام قاعدة بيانات عمود ، ضغط بضغط.
ومع ذلك ، استمر النظام الأساسي لعمل الشركة في العمل بثبات ، ولم أكن أرغب في تجربة الانتقال إلى شيء آخر.
في عام 2017 ، في مؤتمر Percona Live في سان خوسيه ، ربما تكون المرة الأولى التي يعلن فيها مطورو Clickhouse عن أنفسهم. للوهلة الأولى ، كان النظام جاهزًا للإنتاج (جيدًا ، Yandex.Metrica هو إنتاج قاسٍ) ، وكان الدعم سريعًا وبسيطًا ، والأهم من ذلك ، كانت العملية بسيطة. منذ عام 2018 ، بدأنا عملية الانتقال. ولكن بحلول ذلك الوقت ، كان هناك الكثير من أنظمة TSDB الخاصة بالبالغين والتي تم اختبارها بالوقت ، وقررنا تخصيص وقت كبير ومقارنة البدائل من أجل التأكد من عدم وجود حلول Clickhouse بديلة ، وفقًا لمتطلباتنا.
بالإضافة إلى متطلبات التخزين المشار إليها بالفعل ، ظهرت متطلبات جديدة:
- يجب أن يوفر النظام الجديد نفس أداء MySQL على الأقل ، بنفس كمية الحديد ؛
- يجب أن يشغل تخزين النظام الجديد مساحة أقل بكثير ؛
- يجب أن تظل إدارة قواعد البيانات (DBMS) سهلة ؛
- أردت تقليل التطبيق عند تغيير نظام إدارة قواعد البيانات.
ما النظم التي بدأنا في النظر فيها
اباتشي خلية / اباتشي امبالاالضرب الكبير Hadoop المكدس. في الواقع ، هذه واجهة SQL مبنية على تخزين البيانات في التنسيقات الأصلية على HDFS.
الايجابيات.
- مع التشغيل المستقر ، من السهل جدًا توسيع نطاق البيانات.
- هناك حلول العمود لتخزين البيانات (مساحة أقل).
- تنفيذ سريع للغاية للمهام الموازية في وجود الموارد.
سلبيات.
- هذا هو Hadoop ، وأنه من الصعب أن تعمل. إذا لم نكن مستعدين لاتخاذ حل جاهز في السحابة (ونحن لسنا مستعدين للتكلفة) ، فسيتعين تجميع المكدس بالكامل ودعمه من قبل المسؤولين ، لكنني لا أريد هذا حقًا.
- يتم تجميع البيانات بسرعة حقا .
ولكن:

تتحقق السرعة من خلال زيادة عدد خوادم الحوسبة. ببساطة ، إذا كنا شركة كبيرة تعمل في مجال التحليلات والأعمال ، من المهم للغاية تجميع المعلومات في أسرع وقت ممكن (حتى على حساب استخدام عدد كبير من موارد الحوسبة) - قد يكون هذا هو خيارنا. لكننا لسنا مستعدين لمضاعفة الحديقة الحديدية لتسريع المهام.
الكاهن / pinotبالفعل أكثر من ذلك بكثير حول TSDB على وجه التحديد ، ولكن مرة أخرى - Hadoop-stack.
هناك
مقال رائع يقارن بين إيجابيات وسلبيات درويد وبينوت مقارنة مع ClickHouse .
في بضع كلمات: تبدو Druid / Pinot أفضل من Clickhouse في الحالات التي:
- لديك طبيعة غير متجانسة للبيانات (في حالتنا ، نحن نسجل فقط جداول زمنية لمقاييس الخادم ، وهذا في الواقع جدول واحد ، لكن قد تكون هناك حالات أخرى: سلاسل زمنية للمعدات ، سلاسل زمنية اقتصادية ، إلخ - كل منها له هيكله الخاص ، والتي يجب تجميعها ومعالجتها).
- علاوة على ذلك ، هناك الكثير من هذه البيانات.
- تظهر الجداول والبيانات ذات السلاسل الزمنية وتختفي (أي أن مجموعة من البيانات جاءت ، تم تحليلها وحذفها).
- لا يوجد معيار واضح يمكن من خلاله تقسيم البيانات.
في الحالات المقابلة ، يظهر ClickHouse نفسه بشكل أفضل ، وهذه هي حالتنا.
ClickHouse- SQL-مثل.
- سهل الإدارة.
- يقول الناس أنه يعمل.
انها تقع في قائمة مختصرة للاختبار.
InfluxDBالبديل الخارجي ل ClickHouse. من السلبيات: High Availability موجود فقط في الإصدار التجاري ، ولكن يجب مقارنته.
انها تقع في قائمة مختصرة للاختبار.
كاساندرامن ناحية ، نعلم أنه يستخدم لتخزين
مواعيد زمنية مترية بواسطة أنظمة المراقبة مثل ،
SignalFX أو OkMeter. ومع ذلك ، هناك تفاصيل.
كاساندرا ليست قاعدة بيانات عمود بالمعنى المعتاد. يبدو الأمر أشبه بالحرف الصغير ، ولكن يمكن أن يحتوي كل صف على عدد مختلف من الأعمدة ، نظرًا لأنه يسهل تنظيم تمثيل العمود. وبهذا المعنى ، من الواضح أنه مع وجود ملياري عمود كحد أقصى ، يمكنك تخزين بعض البيانات في الأعمدة (نعم ، السلسلة الزمنية نفسها). على سبيل المثال ، يوجد في MySQL حد أقصى يبلغ 4096 عمودًا ومن السهل التعثر عند حدوث خطأ بالكود 1117 إذا حاولت القيام بنفس الشيء.
يركز محرك Cassandra على تخزين كميات كبيرة من البيانات في نظام موزع بدون معالج ، وفي نظرية CAP المذكورة أعلاه تتركز Cassandra على AP ، أي حول إمكانية الوصول إلى البيانات ومقاومة التقسيم. وبالتالي ، يمكن أن تكون هذه الأداة رائعة إذا كنت تحتاج فقط إلى الكتابة إلى قاعدة البيانات هذه ونادراً ما تقرأ منها. ومن المنطقي هنا استخدام كاساندرا كمخزن "بارد". هذا هو ، كمكان طويل الأجل موثوق لتخزين كميات كبيرة من البيانات التاريخية التي نادراً ما تكون مطلوبة ، ولكن يمكن الحصول عليها إذا لزم الأمر. ومع ذلك ، من أجل الاكتمال ، ونحن سوف اختباره. ولكن ، كما قلت سابقًا ، ليست هناك رغبة في إعادة كتابة الكود الخاص بحل الديسيبل المحدد بنشاط ، لذلك سنختبره محدودًا إلى حد ما - دون تكييف بنية قاعدة البيانات مع تفاصيل كاساندرا.
بروميثيوسحسنًا ، وبدافع الاهتمام ، قررنا اختبار أداء متجر بروميثيوس - فقط لفهم ما إذا كنا أسرع من الحلول الحالية أو أبطأ وكم.
المنهجية ونتائج الاختبار
لذلك ، قمنا باختبار 5 قواعد بيانات في التكوينات الستة التالية: ClickHouse (عقدة واحدة) ، ClickHouse (جدول موزع من 3 عقد) ، InfluxDB ، Mysql 8 ، Cassandra (3 عقد) و Prometheus. خطة الاختبار هي كما يلي:
- ملء البيانات التاريخية للأسبوع (840 مليون قيمة في اليوم ؛ 208 ألف مقاييس) ؛
- توليد حمولة تسجيل (تم النظر في 6 أوضاع تحميل ، انظر أدناه) ؛
- بالتوازي مع التسجيل ، نقوم بعمل عينات دورية ، لمحاكاة طلبات مستخدم يعمل مع المخططات. من أجل عدم تعقيد الأمور أكثر من اللازم ، اخترنا البيانات بمقدار 10 مقاييس (مثلها في الرسم البياني لوحدة المعالجة المركزية) في الأسبوع.
نقوم بالتحميل عن طريق محاكاة سلوك وكيل المراقبة لدينا ، والذي يرسل القيم إلى كل مقياس كل 15 ثانية. في هذه الحالة ، نحن مهتمون بالتنوع:
- إجمالي عدد المقاييس التي تتم فيها كتابة البيانات ؛
- الفاصل الزمني لإرسال القيم في مقياس واحد ؛
- حجم الدفعة.
حول حجم الدفعة. نظرًا لأن جميع قواعدنا التجريبية تقريبًا غير موصى بها ليتم تحميلها بإدخالات مفردة ، فسنحتاج إلى مرحل ، يجمع المقاييس الواردة ويجمعها قدر الإمكان ويكتبها في القاعدة مع إدراج حزمة.
أيضًا ، لكي نفهم بشكل أفضل كيفية ترجمة البيانات المستلمة لاحقًا ، تخيل أننا لا نرسل فقط مجموعة من المقاييس ، ولكن يتم تنظيم المقاييس في خوادم - 125 مقاييس لكل خادم. هنا ، يعد الخادم مجرد كيان افتراضي - فقط لفهم أنه ، على سبيل المثال ، يتوافق 10000 مقياس مع حوالي 80 خادمًا.
وهكذا ، مع أخذ كل هذا في الاعتبار ، لدينا 6 أوضاع تحميل تسجيل للقاعدة:
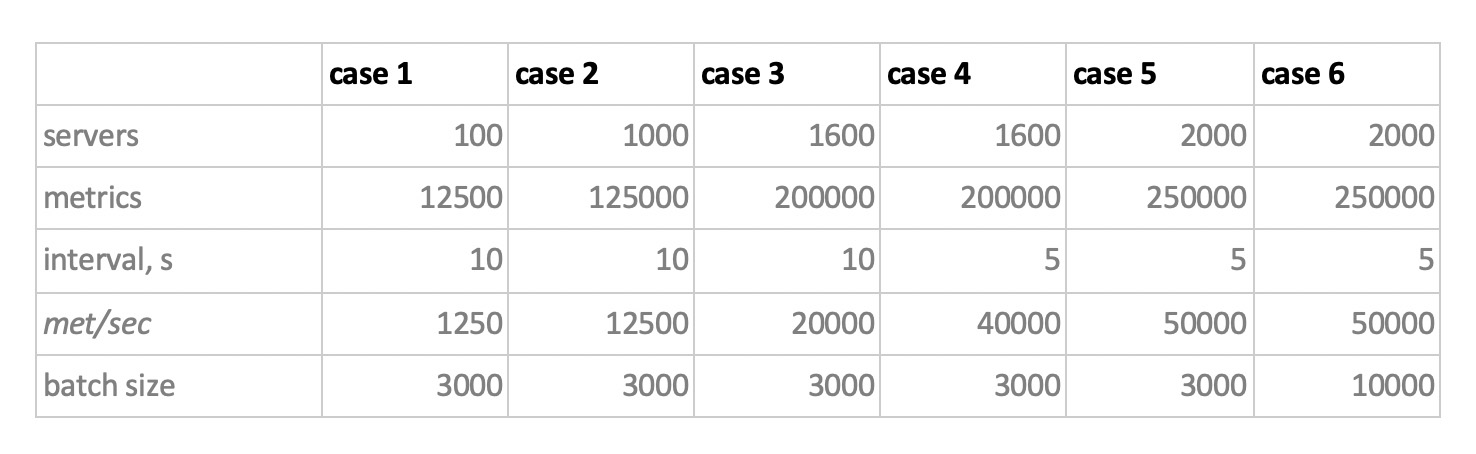
هناك نقطتان. أولاً ، بالنسبة إلى كاسندرا ، تبين أن أحجام هذه الدُفعات كبيرة جدًا ، فقد استخدمنا قيمًا 50 أو 100. وثانيًا ، نظرًا لأن مادة prometeus تعمل بشكل صارم في وضع السحب ، أي يمشي ويجمع البيانات من المصادر المترية (وحتى بوابة الدفع ، على الرغم من الاسم ، لا يغير الموقف بشكل أساسي) ، تم تنفيذ الأحمال المقابلة باستخدام مزيج من التكوينات الثابتة.
نتائج الاختبار هي كما يلي:
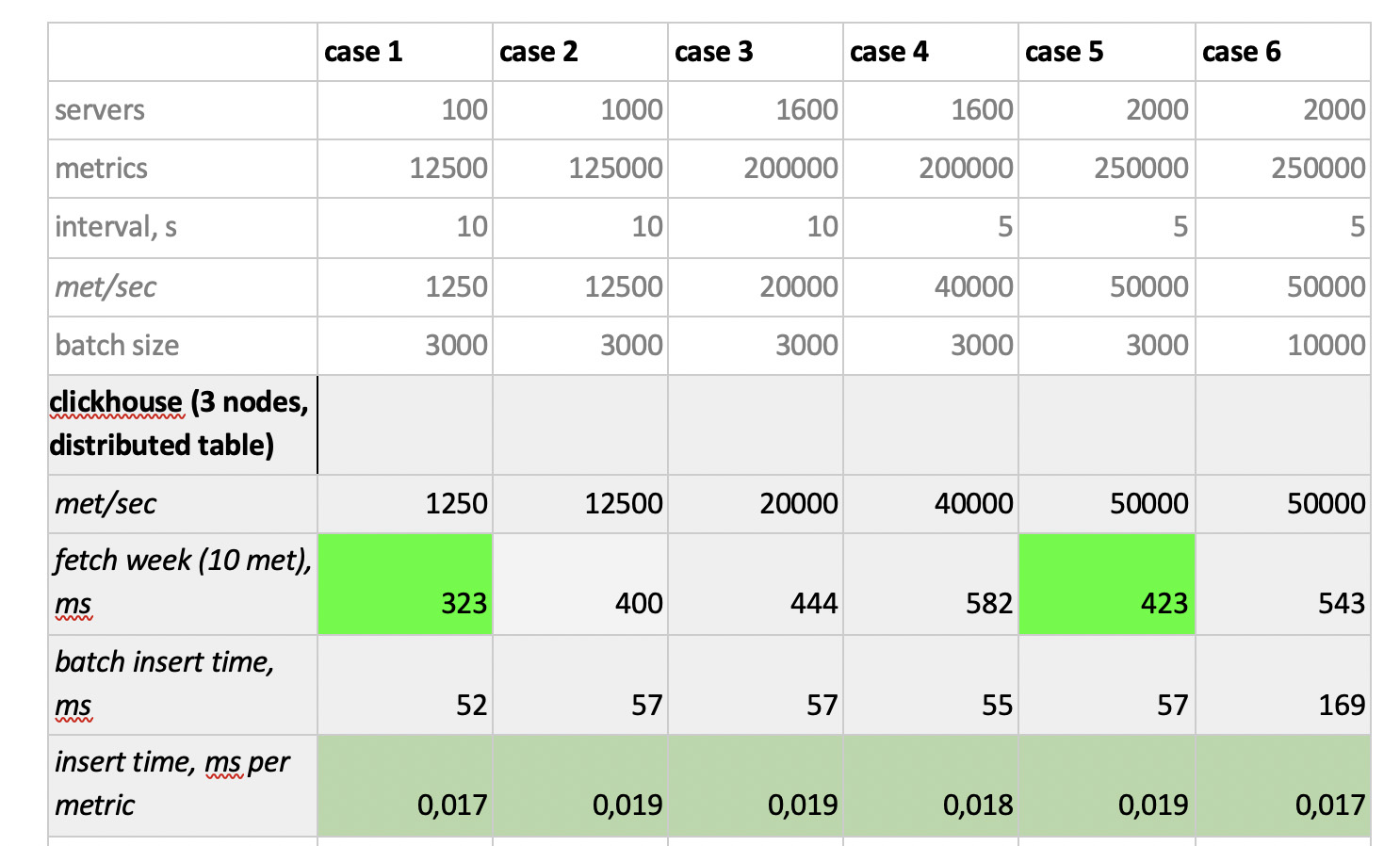
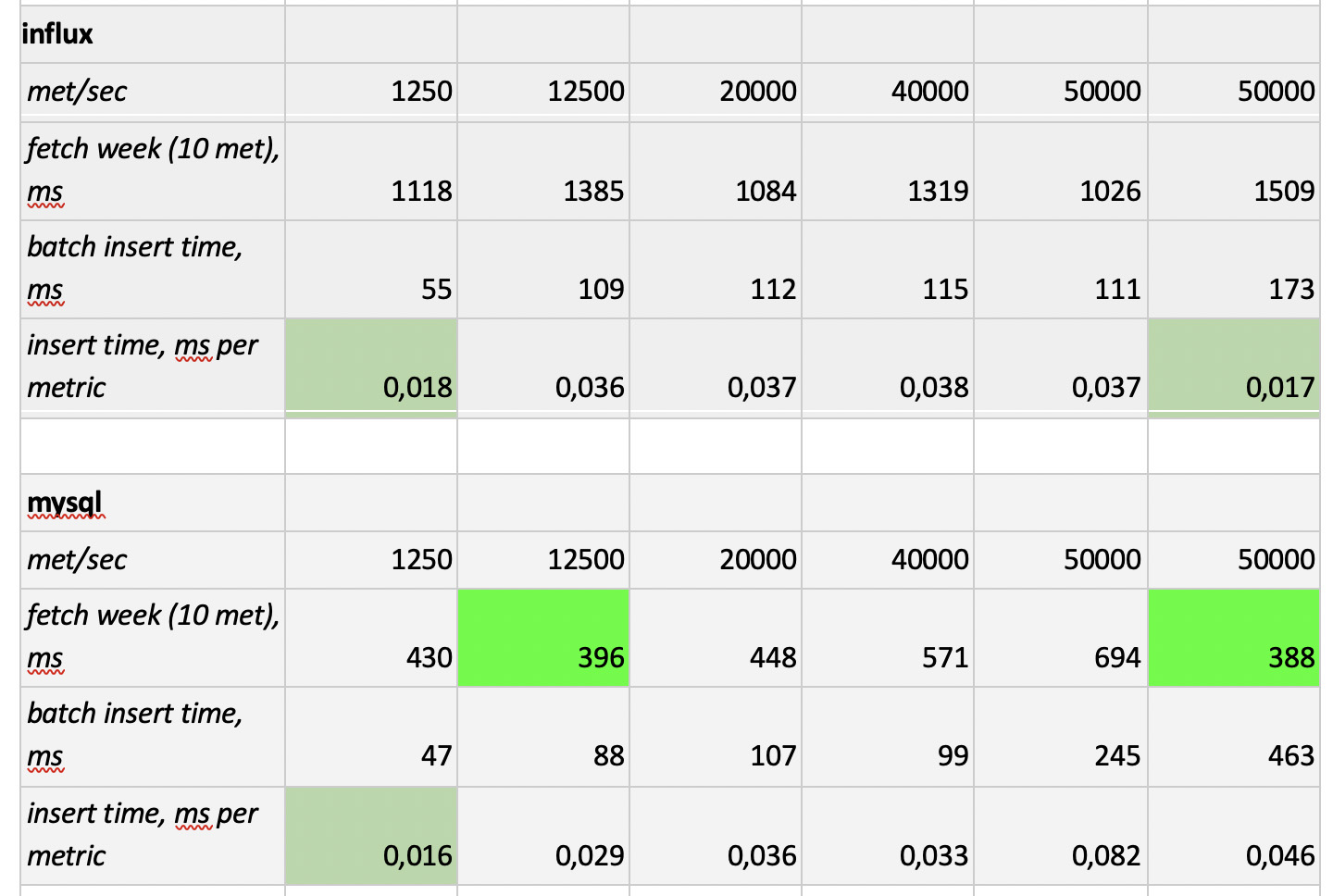
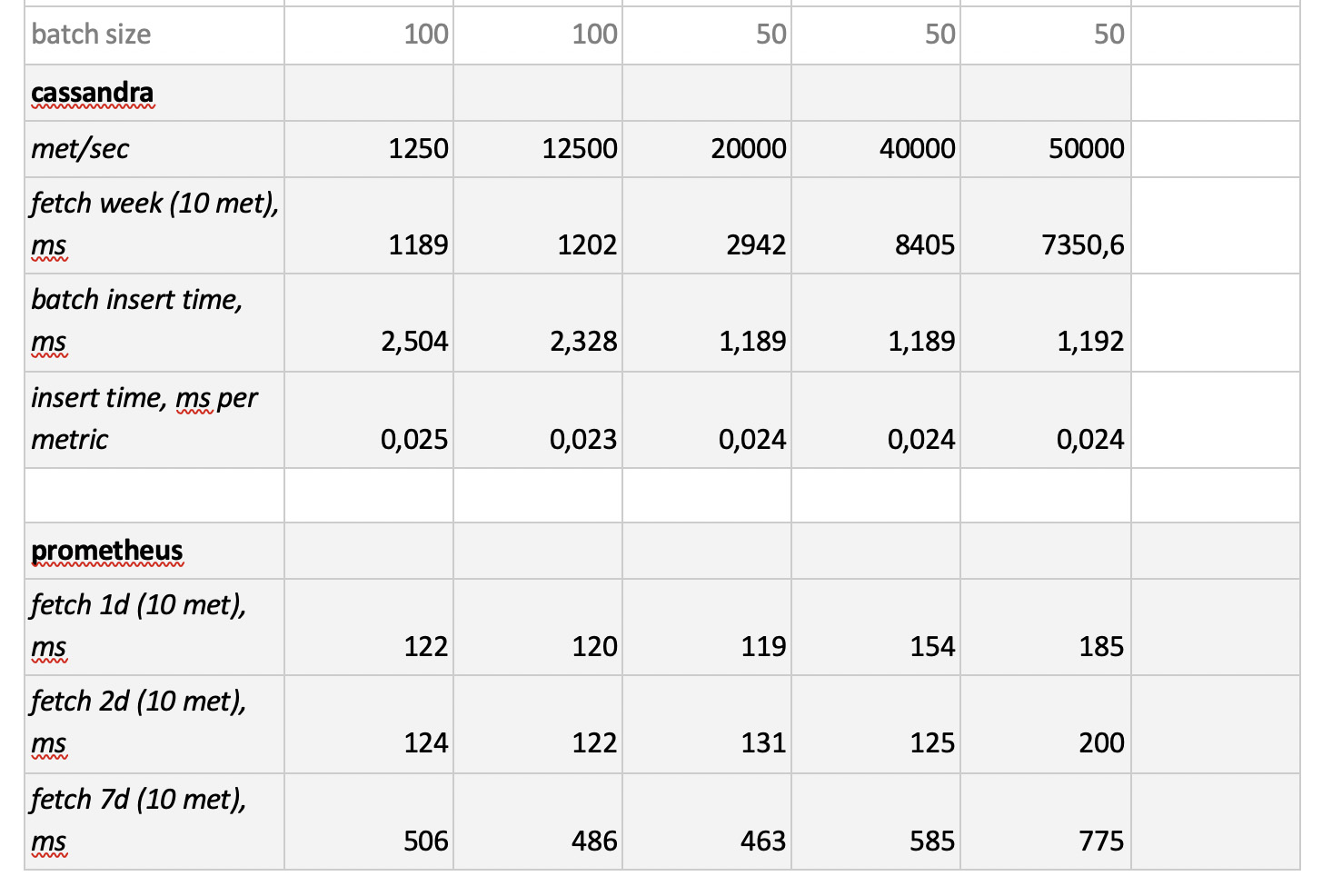 ما تجدر الإشارة إليه
ما تجدر الإشارة إليه : عينات سريعة خيالي من بروميثيوس ، وعينات بطيئة بشكل رهيب من كاساندرا ، وعينات بطيئة بشكل غير مقبول من InfluxDB ؛ فاز ClickHouse من حيث سرعة التسجيل ، ولا تشارك بروميثيوس في المسابقة ، لأنها تدرج داخل نفسها ولا نقيس أي شيء.
كنتيجة لذلك : أظهر كل من ClickHouse و InfluxDB أفضل ما في الأمر ، ولكن لا يمكن إنشاء مجموعة من Influx إلا على أساس إصدار Enterprise ، الذي يكلف مالًا ، ولا تكلف ClickHouse أي شيء ويتم تصنيعها في روسيا. من المنطقي أن يكون الخيار في الولايات المتحدة الأمريكية لصالح inInfluxDB ، وفي حالتنا يكون لصالح ClickHouse.