هل تعتقد أنه من الصعب أن تكتب chatbot الخاص بك في بيثون يمكن أن تدعم المحادثة؟ لقد أصبح الأمر سهلاً للغاية إذا وجدت مجموعة بيانات جيدة. علاوة على ذلك ، يمكن القيام بذلك حتى بدون الشبكات العصبية ، على الرغم من الحاجة إلى بعض السحر الرياضي.
سنذهب بخطوات صغيرة: أولاً ، تذكر كيفية تحميل البيانات في Python ، ثم تعلم حساب الكلمات ، وربط الجبر الخطي والمنظّر تدريجياً ، وفي النهاية ، نقوم بإنشاء روبوت لـ Telegram من خوارزمية الدردشة الناتجة.
هذا البرنامج التعليمي مناسب لأولئك الذين لمست بيثون بالفعل قليلاً ، لكنهم ليسوا على دراية خاصة بالتعلم الآلي. عمدا لم أستخدم أي مكتبات nlp-sh لإظهار أنه يمكن تجميع شيء يعمل على sklearn العارية.
ابحث عن إجابة في مجموعة بيانات الحوار
قبل عام ، طُلب مني أن أعرض على الرجال الذين لم يشاركوا في تحليل البيانات من قبل بعض تطبيقات التعلم الآلي الملهمة التي يمكنك الاعتماد عليها. حاولت أن أحضر معهم متكلم بوت ، وقد فعلنا ذلك بالفعل في إحدى الأمسيات. لقد أحببنا العملية والنتيجة ، وكتبنا عنها في
مدونتي . والآن اعتقدت أن Habru سيكون مثيرا للاهتمام.
لذلك نحن هنا نذهب. مهمتنا هي إنشاء خوارزمية تعطي إجابة مناسبة لأي عبارة. على سبيل المثال ، على "كيف حالك؟" أجب "ممتاز ، وأنت؟" أسهل طريقة لتحقيق ذلك هي العثور على قاعدة بيانات جاهزة من الأسئلة والأجوبة. على سبيل المثال ، خذ ترجمات من عدد كبير من الأفلام.
ومع ذلك ،
فسأعمل بشكل أكثر إحكاما ، وأخذ البيانات من
مسابقة Yandex.Algorithm 2018 - هذه هي نفس الحوارات من الأفلام التي حددها موظفو Toloka بتسلسلات جيدة وليست سيئة. جمعت ياندكس هذه البيانات لتدريب أليس (مقالات عن شجاعتها
1 و
2 و
3 ). في الواقع ، كنت مستوحاة من أليس عندما توصلت إلى هذا الروبوت. يعرض
الجدول من Yandex آخر ثلاث عبارات والإجابة عليها (الرد) ، لكننا لن نستخدم إلا الأحدث (سياق_0).
امتلاك قاعدة بيانات من مربعات الحوار هذه ، يمكنك ببساطة البحث فيها عن كل نسخة طبق الأصل من المستخدم ، وإعطاء إجابة جاهزة عليها (إذا كان هناك العديد من هذه النسخ المتماثلة ، فاختر عشوائيًا). مع "كيف حالك؟" اتضح كبيرة ، كما يتضح من الصورة المرفقة. هذا ، إذا كان هناك أي شيء ، عبارة عن
دفتر ملاحظات jupyter في Python 3. إذا كنت ترغب في تكرار ذلك بنفسك ، فإن أسهل طريقة هي تثبيت
Anaconda - ويشمل Python ومجموعة من الحزم المفيدة له. أو لا يمكنك تثبيت أي شيء ، ولكن تشغيل دفتر ملاحظات
في سحابة جوجل .

المشكلة في عمليات البحث الحرفية هي أن لديها تغطية منخفضة. إلى عبارة "كيف حالك؟" في قاعدة البيانات من 40 ألف الإجابات لم يكن هناك تطابق تام ، على الرغم من أن لها نفس المعنى. لذلك ، في القسم التالي ، سنكمل الشفرة الخاصة بنا باستخدام رياضيات مختلفة لتنفيذ بحث تقريبي. وقبل ذلك ، يمكنك قراءة مكتبة
الباندا ومعرفة ما يفعله كل سطر من الأسطر الستة الموجودة في الكود أعلاه.
تحويل النص
الآن نحن نتحدث عن كيفية تحويل النصوص إلى متجهات عددية من أجل إجراء بحث تقريبي عليها.
لقد التقينا بالفعل بمكتبة الباندا في بيثون - فهي تتيح لك تحميل الجداول ، والبحث فيها ، إلخ. الآن ، دعونا نتناول مكتبة
scikit-learn (sklearn) ، والتي تتيح معالجة البيانات بشكل أكثر صعوبة - ما يسمى بالتعلم الآلي. هذا يعني أن أي خوارزمية يجب أن تُظهر أولاً البيانات (مناسبة) حتى تتعلم شيئًا مهمًا عنها. نتيجة لذلك ، "تتعلم" الخوارزمية أن تفعل شيئًا مفيدًا مع هذه البيانات - تحويلها (تحويل) ، أو حتى التنبؤ بقيم مجهولة (تنبؤ).
في هذه الحالة ، نريد تحويل النصوص ("الأسئلة") إلى متجهات رقمية. هذا ضروري حتى يمكن العثور على نصوص "قريبة" من بعضها البعض باستخدام المفهوم الرياضي للمسافة. يمكن حساب المسافة بين نقطتين بواسطة نظرية فيثاغورس - كجذر لمجموع مربعات الاختلافات في إحداثياتها. في الرياضيات ، وهذا ما يسمى الإقليدية متري. إذا استطعنا تحويل النصوص إلى كائنات لها إحداثيات ، فيمكننا حساب مقياس الإقليدية ، وعلى سبيل المثال ، نجد في قاعدة البيانات سؤالًا يشبه إلى حد بعيد "ما الذي تفكر فيه؟".
تتمثل أسهل طريقة لتحديد إحداثيات النص في ترقيم جميع الكلمات في اللغة ، ونقول أن الإحداثي الأول للنص يساوي عدد مرات تواجد الكلمة الأولى فيه. على سبيل المثال ، بالنسبة للنص "لا أستطيع المساعدة في البكاء" ، فإن إحداثي كلمة "لا" هو 2 ، وإحداثيات الكلمات "أنا" ، و "يمكن" ، و "البكاء" هي 1 ، وإحداثيات جميع الكلمات الأخرى (عشرات الآلاف منها) هي 0. يفقد معلومات حول ترتيب الكلمات ، لكنه لا يزال يعمل بشكل جيد.
المشكلة هي أنه بالنسبة للكلمات التي غالباً ما يتم العثور عليها (على سبيل المثال ، الجزيئات "و" و "a") ، فإن الإحداثيات ستكون كبيرة بشكل غير متناسب ، على الرغم من أنها تحمل القليل من المعلومات. لتخفيف هذه المشكلة ، يمكن تقسيم إحداثيات كل كلمة من خلال لوغاريتم عدد النصوص التي تحدث فيها هذه الكلمة - وهذا ما يسمى tf-idf ويعمل أيضًا بشكل جيد.

هناك مشكلة واحدة فقط: في قاعدة البيانات لدينا من 60 ألف "أسئلة" نصية ، والتي تحتوي على 14 ألف كلمة مختلفة. إذا حولت جميع الأسئلة إلى متجهات ، فستحصل على مصفوفة من 60k * 14k. ليس من الرائع التعامل مع هذا ، لذلك سنتحدث عن تقليل البعد لاحقًا.
تخفيض الأبعاد
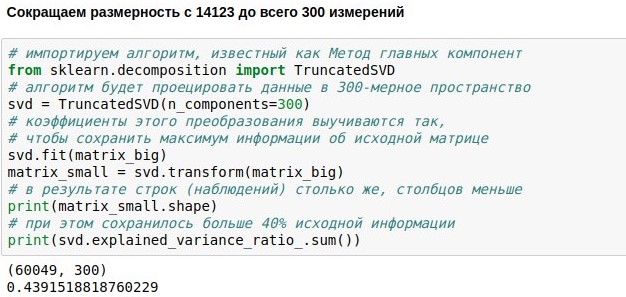
لقد حددنا بالفعل مهمة إنشاء دردشة chatbot ، وتنزيل البيانات وتوجيهها لتدريبها. الآن لدينا مصفوفة عددية تمثل النسخ المتماثلة للمستخدم. يتكون من 60 ألف صف (كان هناك الكثير من النسخ المتماثلة في قاعدة بيانات مربعات الحوار) و 14 ألف عمود (كانت هناك كلمات كثيرة مختلفة فيها). مهمتنا الآن هي جعلها أصغر. على سبيل المثال ، لتقديم كل نص ليس 14123 الأبعاد ، ولكن فقط متجه 300 الأبعاد.
يمكن تحقيق ذلك عن طريق ضرب مصفوفة حجمنا 60049x14123 بمصفوفة مختارة خصيصًا من حجم 14123x300 ، ونتيجة لذلك حصلنا على النتيجة 60049x300. تقوم خوارزمية PCA (
طريقة المكون الرئيسي ) بتحديد مصفوفة الإسقاط بحيث يمكن بعد ذلك إعادة بناء المصفوفة الأصلية باستخدام أصغر خطأ قياسي. في حالتنا ، كان من الممكن الحفاظ على حوالي 44 ٪ من المصفوفة الأصلية ، على الرغم من أن البعد تم تخفيضه بحوالي 50 مرة.
ما الذي يجعل مثل هذا الضغط الفعال ممكنًا؟ تذكر أن المصفوفة الأصلية تحتوي على عدادات لتذكر الكلمات الفردية في النصوص. لكن الكلمات ، كقاعدة عامة ، لا تستخدم بشكل مستقل عن بعضها البعض ، ولكن في السياق. على سبيل المثال ، كلما زاد عدد مرات حدوث كلمة "حظر" في نص الخبر ، زاد عدد مرات ظهور كلمة "البرق" أيضًا في هذا النص. لكن العلاقة بين كلمة "حظر" ، على سبيل المثال ، بكلمة "قفطان" هي علاقة سلبية - فهي موجودة في سياقات مختلفة.
لذلك ، اتضح أن طريقة المكونات الرئيسية لا تتذكر 14 ألف كلمة ، ولكن 300 سياق نموذجي يمكن من خلالها محاولة استعادة هذه الكلمات. عادة ما تكون أعمدة مصفوفة الإسقاط المطابقة للكلمات المترادفة متشابهة مع بعضها البعض لأن هذه الكلمات غالبًا ما توجد في نفس السياق. هذا يعني أنه من الممكن تقليل القياسات الزائدة دون فقد المعلوماتية.
في العديد من التطبيقات الحديثة ، يتم حساب كلمة مصفوفة الإسقاط بواسطة الشبكات العصبية (مثل
word2vec ). ولكن في الواقع ، فإن الجبر الخطي البسيط يكفي بالفعل للحصول على نتيجة مفيدة من الناحية العملية. يتم تقليل طريقة المكونات الرئيسية حسابيًا إلى SVD ، وهي لحساب المتجهات الذاتية والقيم الذاتية للمصفوفة. ومع ذلك ، يمكن برمجتها دون معرفة التفاصيل.
البحث عن الجيران القريبين
في الأقسام السابقة ، قمنا بتحميل مربع الحوار إلى python ، وقمنا بتوجيهه ، وقمنا بتقليل البعد ، والآن نريد أن نتعلم أخيرًا كيفية البحث عن أقرب جيراننا في الفضاء ذي الأبعاد 300 والإجابة على الأسئلة بشكلٍ نهائي في النهاية.
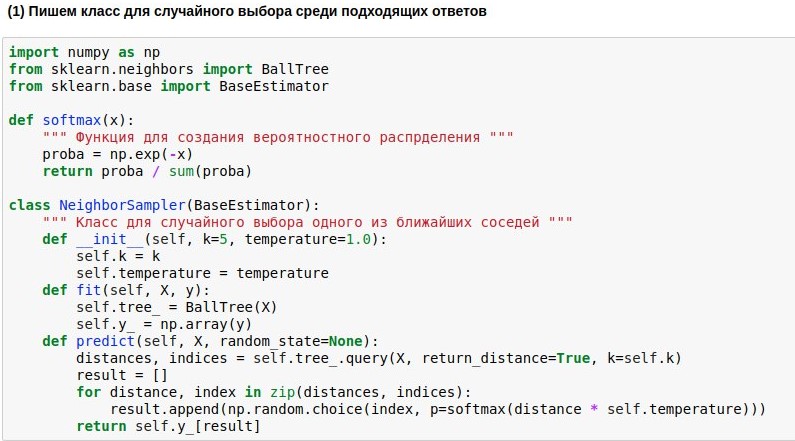
نظرًا لأننا تعلمنا كيفية تعيين أسئلة على المساحة الإقليدية ذات البعد غير المرتفع جدًا ، يمكن إجراء البحث عن الجيران فيه بسرعة كبيرة. سوف نستخدم خوارزمية بحث الجوار
BallTree الجاهزة . لكننا سنكتب نموذج التغليف الخاص بنا ، والذي سيختار أحد الجيران الأقرب k ، وكلما كان الجيران أقرب ، كلما زاد احتمال اختياره. إن اتخاذ واحد من أقرب الجيران دائمًا أمر ممل ، لكن عدم الارتباط بأوجه التشابه على الإطلاق أمر خطير.
لذلك ، نريد تحويل المسافات التي تم العثور عليها من الاستعلام إلى النصوص المرجعية إلى احتمال اختيار هذه النصوص. للقيام بذلك ، يمكنك استخدام وظيفة softmax ، والتي لا تزال تقف عند مخرج الشبكات العصبية. إنها تحول حججها إلى مجموعة من الأرقام غير السالبة ، مجموعها هو 1 - فقط ما نحتاج إليه. علاوة على ذلك ، يمكننا استخدام "الاحتمالات" التي تم الحصول عليها لاختيار عشوائي للإجابة.
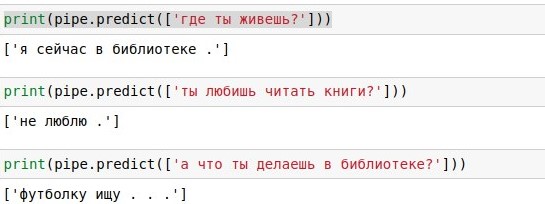
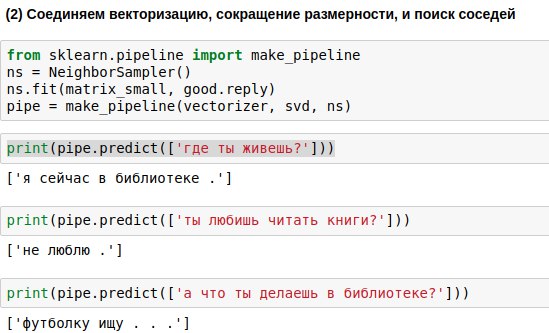
يجب تمرير العبارات التي سيدخلها المستخدم من خلال الخوارزميات الثلاثة - المتجه وطريقة المكون الرئيسي وخوارزمية اختيار الاستجابة. لكتابة رمز أقل ، يمكنك ربطهم في سلسلة واحدة (خط أنابيب) ، وتطبيق الخوارزميات بالتتابع.
نتيجةً لذلك ، حصلنا على خوارزمية يمكنها ، على سؤال المستخدم ، إيجاد سؤال مشابه له وإعطاء إجابة عليه. وأحيانًا تبدو هذه الإجابات ذات معنى تقريبًا.
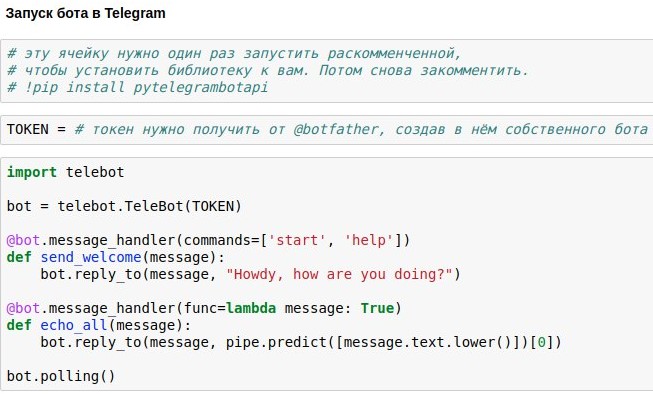
نشر روبوت على برقية
لقد اكتشفنا بالفعل كيفية إنشاء غرفة دردشة chatbot من شأنها أن تعطي إجابات ذات الصلة تقريبا لطلبات المستخدم. الآن أعرض عليكم كيفية إطلاق مثل هذا chatbot على Telegram.
أسهل طريقة لاستخدام ذلك هي المجمّع الجاهزة Telegram API لـ python - على سبيل المثال ،
pytelegrambotapi . لذلك ، تعليمات خطوة بخطوة:
- سجّل بوتك في المستقبل باستخدام botfather واحصل على رمز وصول ، والذي ستحتاج إلى إدراجه في الكود.
- قم بتشغيل أمر التثبيت مرة واحدة - تثبيت نقطة pytelegrambotapi في سطر الأوامر (أو عبر! مباشرة في المفكرة).
- قم بتشغيل الكود كما في لقطة الشاشة. سوف تنتقل الخلية إلى وضع التنفيذ (*) ، وأثناء وجودها في هذا الوضع ، يمكنك التواصل مع الروبوت الخاص بك بقدر ما تريد. لإيقاف الروبوت ، اضغط على Ctrl + C. الحقيقة المحزنة ، ولكنها مهمة: إذا كنت في روسيا ، فعلى الأرجح ، قبل بدء هذه الخلية ، ستحتاج إلى تشغيل VPN حتى لا تحصل على خطأ عند الاتصال ببرقية. بديل أبسط لـ VPN هو كتابة كل الكود ليس على حاسوبك المحلي ، ولكن في google colab ( شيء من هذا القبيل ).
- إذا كنت تريد أن يعمل الروبوت بشكل دائم ، فأنت بحاجة إلى وضع الكود الخاص به على بعض الخدمات السحابية - على سبيل المثال ، AWS أو Heroku أو now.sh أو Yandex.Cloud. يمكنك معرفة كيفية تشغيلها في أصغر التفاصيل على مواقع هذه الخدمات أو في المقالات الموجودة على Habré. على سبيل المثال ، اللفت مع مثال صغير من روبوت يعمل على heroku ووضع سجلات في mongodb.
أنا عمداً لا أحمل الكود الكامل للمقالة - ستحصل على المزيد من المتعة والتجربة المفيدة عند طباعتها بنفسك وستحصل على روبوت عملي نتيجة لجهودك الخاصة. حسنًا ، أو إذا كنت كسولًا جدًا من القيام بذلك ، يمكنك الدردشة مع
الإصدار الخاص بي من برنامج الروبوت.