نظم المعلومات الحديثة معقدة للغاية. أخيرًا وليس آخرًا ، يرجع تعقيدها إلى تعقيد البيانات التي تمت معالجتها فيها. غالبًا ما يكمن تعقيد البيانات في مجموعة متنوعة من نماذج البيانات المستخدمة. لذلك ، على سبيل المثال ، عندما تصبح البيانات "كبيرة" ، لا تُعتبر إحدى الخصائص غير الملائمة حجمها فقط ("حجم") ، ولكن أيضًا تنوعها ("التنوع").
إذا كنت لا تزال لا تجد عيبًا في المنطق ، فاقرأ.

متقن لعدة لغات
ما سبق يؤدي إلى حقيقة أنه في بعض الأحيان ، حتى في إطار نظام واحد ، من الضروري استخدام عدة قواعد بيانات مختلفة لتخزين البيانات وحل مختلف المهام لمعالجتها ، كل منها يدعم نموذج البيانات الخاص به. بيد خفيفة من M. Fowler ، مؤلف العديد من الكتب المعروفة وأحد المؤلفين المشاركين في Agile Manifesto ، أطلق على هذا الوضع اسم " التخزين متعدد المتغيرات " ("polyglot persistence").
يمتلك فاولر أيضًا المثال التالي لتنظيم تخزين البيانات في تطبيق يعمل بكامل طاقته وتحميله بشكل كبير في مجال التجارة الإلكترونية.

هذا المثال ، بالطبع ، مبالغ فيه إلى حد ما ، ولكن يمكن العثور على بعض الاعتبارات المؤيدة لاختيار واحد أو أكثر من نظم إدارة قواعد البيانات للغرض المقابل ، على سبيل المثال ، هنا .
من الواضح أن كونك وزيراً في حديقة الحيوان هذه ليس بالأمر السهل.
- ينمو مقدار الكود الذي يقوم بتخزين البيانات بما يتناسب مع عدد قواعد البيانات المستخدمة ؛ مقدار الكود الذي يقوم بمزامنة البيانات جيد إن لم يكن متناسباً مع مربع هذا الرقم.
- يزيد عدد مضاعفات نظم إدارة قواعد البيانات المستخدمة من تكلفة توفير خصائص المؤسسة (قابلية التوسع والتسامح مع الأعطال والتوافر العالي) لكلٍ من نظم إدارة قواعد البيانات المستخدمة.
- لا يمكن توفير خصائص المؤسسة للنظام الفرعي للتخزين ككل - خاصةً المعاملات.
من وجهة نظر مدير حديقة الحيوان ، يبدو كل شيء كما يلي:
- زيادة متعددة في تكلفة التراخيص والدعم الفني من الشركة المصنعة DBMS.
- الموظفين سخام وأطول مهلة.
- خسائر مالية مباشرة أو غرامات بسبب بيانات غير متناسقة.
هناك زيادة كبيرة في التكلفة الإجمالية لملكية النظام (TCO). هل هناك أي طريقة للخروج من الوضع "التخزين متعدد المتغيرات"؟
متعددة النماذج
بدأ استخدام مصطلح "التخزين متعدد المتغيرات" في عام 2011. استغرق الوعي بمشاكل النهج والبحث عن حل عدة سنوات ، وبحلول عام 2015 ، تمت صياغة الإجابة من خلال محللي Gartner:
يبدو أن محللي Gartner هذه المرة لم يخطئوا في التنبؤ. إذا ذهبت إلى الصفحة التي لها تصنيف DBMS الرئيسي على محركات DB ، يمكنك أن ترى أن معظم قادتها يضعون أنفسهم في صورة قواعد بيانات متعددة النماذج. يمكن رؤية الشيء نفسه على الصفحة مع أي تصنيف خاص.
يوضح الجدول أدناه قواعد إدارة قواعد البيانات (DBMS) - القادة في كل تصنيف من التصنيفات الخاصة ، معلنين نماذجهم المتعددة. لكل DBMS ، يشار إلى النموذج المدعوم الأولي (مرة واحدة فقط) ، جنبا إلى جنب ، مع النماذج المعتمدة الآن. هناك أيضًا قواعد بيانات إدارة قواعد البيانات (DBMS) التي تضع نفسها "نموذجًا متعدد النماذج في البداية" ، والتي لا تحتوي على أي نموذج موروث أولي ، وفقًا للمبدعين.
ملاحظات الجدولعلامات العلامة النجمية في جدول العلامات التي تتطلب حجوزات:
- لا يدعم PostgreSQL نموذج بيانات رسومية ، لكنه مدعوم من قبل منتج قائم عليه ، على سبيل المثال ، AgensGraph.
- فيما يتعلق بـ MongoDB ، من الأصح التحدث أكثر عن وجود مشغلي
$graphLookup البيانية في لغة الاستعلام ( $lookup ، $graphLookup ) أكثر من دعم نموذج الرسم البياني ، على الرغم من أن تقديمهم يتطلب بالطبع بعض التحسينات على مستوى التخزين الفعلي في اتجاه دعم نموذج الرسم البياني. - بالنسبة لـ Redis ، يشير هذا إلى ملحق RedisGraph .
علاوة على ذلك ، سوف نوضح لكل فئة من الفئات كيفية تنفيذ دعم العديد من النماذج في DBMS من هذه الفئة. سنأخذ في الاعتبار أهم النماذج العلائقية والمستندات والرسم البياني ونعرض مع أمثلة عن نظم إدارة قواعد البيانات المعينة كيفية تنفيذ "المفقود".
Multimodel DBMS استنادا إلى نموذج العلائقية
تعتبر أنظمة قواعد البيانات الرئيسية الرائدة حاليًا علائقية ؛ فلا يمكن اعتبار توقعات Gartner صحيحة إذا لم تظهر أنظمة إدارة قواعد البيانات (RDBMS) في اتجاه متعدد النماذج. ويظهرون. الآن ، يمكن إرسال فكرة أن DBMS متعددة النماذج مثل السكين السويسري ، والتي لا يمكن القيام بها بشكل جيد ، على الفور إلى لاري إليسون.
على الرغم من ذلك ، يحب المؤلف تطبيق multimodeling في Microsoft SQL Server ، على سبيل المثال سيتم وصف دعم RDBMS لنماذج المستندات والرسومات.
نموذج المستند في MS SQL Server
حول كيفية دعم MS SQL Server لطراز المستند ، كان هناك بالفعل مقالتان ممتازتان عن Habré ، سأقتصر على سرد موجز وتعليق:
تعد طريقة دعم نموذج المستند في MS SQL Server نموذجية تمامًا بالنسبة لقواعد بيانات قواعد البيانات الترابطية (DBMS): يُقترح تخزين مستندات JSON في حقول النص العادي. دعم نموذج المستند هو توفير عوامل تشغيل خاصة لتحليل JSON:
الوسيطة الثانية لكلا المشغلين هي تعبير في بناء جملة JSONPath-like.
يمكن القول بصورة مجردة أن المستندات المخزنة بهذه الطريقة ليست "كيانات من الدرجة الأولى" في قواعد بيانات إدارة قواعد البيانات العلائقية ، على عكس tuples. على وجه التحديد ، لا يحتوي MS SQL Server حاليًا على فهارس في حقول مستندات JSON ، مما يجعل من الصعب ربط الجداول بقيم هذه الحقول وحتى تحديد المستندات بهذه القيم. ومع ذلك ، من الممكن إنشاء عمود محسوب وفهرس عليه في هذا الحقل.
بالإضافة إلى ذلك ، يوفر MS SQL Server القدرة على إنشاء مستند JSON بسهولة من محتويات الجداول باستخدام عبارة FOR JSON PATH ، وهي ميزة ، على نحو ما ، هي عكس التخزين العادي السابق. من الواضح أنه بغض النظر عن سرعة RDBMS ، فإن هذا النهج يتناقض مع أيديولوجية قواعد بيانات DBMS ، التي تخزن في الواقع إجابات جاهزة على الاستعلامات الشائعة ، ويمكنها فقط حل مشكلات سهولة التطوير ، ولكن ليس السرعة.
أخيرًا ، يسمح لك MS SQL Server بحل المشكلة ، وهو معكوس تصميم المستند: يمكنك تحليل JSON إلى جداول باستخدام OPENJSON . إذا لم يكن المستند مسطحًا بالكامل ، فستحتاج إلى استخدام CROSS APPLY .
نموذج الرسم البياني في MS SQL Server
دعم نماذج الرسم البياني ( LPG ) المطبقة في Microsoft SQL Server يمكن التنبؤ به تمامًا: يُقترح استخدام جداول خاصة لتخزين العقد وتخزين حواف الرسم البياني. يتم إنشاء هذه الجداول باستخدام التعبيرات CREATE TABLE AS NODE و CREATE TABLE AS EDGE على التوالي.
تشبه الجداول من النوع الأول الجداول العادية لتخزين السجلات مع الفارق الخارجي الوحيد الذي يحتوي عليه الجدول في حقل النظام $node_id - معرف عقدة الرسم البياني الفريد داخل قاعدة البيانات.
وبالمثل ، تحتوي جداول النوع الثاني على حقول النظام $from_id و $to_id ، والسجلات في هذه الجداول تحدد بوضوح العلاقات بين العقد. يتم استخدام جدول منفصل لتخزين العلاقات من كل نوع.
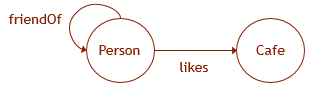 نوضح ما قيل بالقدوة. دع بيانات الرسم البياني لها مخطط كما هو موضح في الشكل. بعد ذلك ، لإنشاء البنية المقابلة في قاعدة البيانات ، تحتاج إلى تنفيذ استعلامات DDL التالية:
نوضح ما قيل بالقدوة. دع بيانات الرسم البياني لها مخطط كما هو موضح في الشكل. بعد ذلك ، لإنشاء البنية المقابلة في قاعدة البيانات ، تحتاج إلى تنفيذ استعلامات DDL التالية:
CREATE TABLE Person ( ID INTEGER NOT NULL, name VARCHAR(100) ) AS NODE; CREATE TABLE Cafe ( ID INTEGER NOT NULL, name VARCHAR(100), ) AS NODE; CREATE TABLE likes ( rating INTEGER ) AS EDGE; CREATE TABLE friendOf AS EDGE;
خصوصية مثل هذه الجداول هي أنه من الممكن استخدام أنماط الرسم البياني مع بناء جملة Cypher-like في الاستعلامات الخاصة بهم (ومع ذلك ، " * " ، وما إلى ذلك ، غير مدعومة). أيضًا ، استنادًا إلى قياسات الأداء ، يمكن افتراض أن طريقة تخزين البيانات في هذه الجداول مختلفة عن آلية تخزين البيانات في الجداول العادية وتم تحسينها لتنفيذ استعلامات الرسم البياني هذه.
SELECT Cafe.name FROM Person, likes, Cafe WHERE MATCH (Person-(friendOf)-(likes)->Cafe) AND Person.name = 'John';
علاوة على ذلك ، من الصعب جدًا عدم استخدام أنماط الرسوم البيانية هذه عند العمل مع هذه الجداول ، لأنه في استعلامات SQL العادية لحل المشكلات المماثلة ، ستكون هناك حاجة إلى بذل جهود إضافية للحصول على معرّفات عقدة "الرسم البياني" للنظام ( $node_id ، $from_id ، $to_id ؛ لهذا للسبب نفسه ، لا يتم تقديم طلبات إدراج البيانات هنا مرهقة للغاية).
بإيجاز وصف تطبيقات المستند ونماذج الرسوم البيانية في MS SQL Server ، أود أن أشير إلى أن مثل هذه التطبيقات لنموذج واحد فوق الآخر لا تبدو ناجحة في المقام الأول من وجهة نظر تصميم اللغة. مطلوب توسيع لغة مع أخرى ، واللغات ليست "متعامدة" تمامًا ، ويمكن أن تكون قواعد التوافق غريبة تمامًا.
Multimodel DBMS بناءً على نموذج المستند
في هذا القسم ، أود أن أوضح تنفيذ multimodel في قواعد بيانات DBMS باستخدام مثال $graphLookup (كما هو مذكور ، فإنه يحتوي فقط على عوامل تشغيل $graphLookup البيانية المشروطة $lookup و $graphLookup التي لا تعمل على مجموعات shard) ، ولكن على سبيل المثال ، يكون أكثر نضجًا و " المشاريع »DBMS MarkLogic .
لذلك ، دع المجموعة تحتوي على مجموعة من مستندات XML من النموذج التالي (يسمح MarkLogic أيضًا بتخزين مستندات JSON):
<Person INN="631803299804"> <name>John</name> <surname>Smith</surname> </Person>
نموذج العلائقية في MarkLogic
يمكن إنشاء تمثيل علائقي لمجموعة من المستندات باستخدام قالب عرض (يمكن أن تكون محتويات عناصر value في المثال أدناه عبارة عن XPath تعسفي):
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <rows> <row> <view-name>Person</view-name> <columns> <column> <name>SSN</name> <value>@SSN</value> <type>string</type> </column> <column> <name>name</name> <value>name</value> </column> <column> <name>surname</name> <value>surname</value> </column> </columns> </row> <rows> </template>
يمكن توجيه استعلام SQL إلى طريقة العرض التي تم إنشاؤها (على سبيل المثال ، عبر ODBC):
SELECT name, surname FROM Person WHERE name="John"
لسوء الحظ ، فإن طريقة العرض العلائقية التي تم إنشاؤها باستخدام قالب العرض للقراءة فقط. عند معالجة طلب إليه ، سيحاول MarkLogic استخدام فهارس المستندات . اعتادت أن تكون هناك وجهات نظر علائقية محدودة في MarkLogic كانت تستند إلى الفهرس وقابلة للكتابة بالكامل ، لكن الآن يتم اعتبارها مهملة.
الرسم البياني نموذج في MarkLogic
مع دعم نموذج الرسم البياني ( RDF ) ، تكون الأشياء متشابهة إلى حد كبير. مرة أخرى ، باستخدام قالب العرض ، يمكنك إنشاء تمثيل RDF لمجموعة المستندات من المثال أعلاه:
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <vars> <var> <name>PREFIX</name> <val>"http://example.org/example#"</val> </var> </vars> <triples> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || surname )</value></predicate> <object><value>xs:string( surname )</value></object> </triple> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || name )</value></predicate> <object><value>xs:string( name )</value></object> </triple> </triples> </template>
يمكن معالجة الرسم البياني RDF الناتج مع استعلام SPARQL:
PREFIX : <http://example.org/example
على عكس العلائقية ، يدعم نموذج الرسم البياني MarkLogic بطريقتين أخريين:
- يمكن أن يكون نظام إدارة قواعد البيانات (DBMS) عبارة عن مستودع منفصل كامل لبيانات RDF (سيتم استدعاء ثلاثة توائم فيه مُدارة ، على عكس المستخلص المستخلص أعلاه).
- يمكن ببساطة إدراج RDF في تسلسل خاص في مستندات XML أو JSON (ثم يطلق على التوائم الثلاثة اسم غير مدار ). ربما يكون هذا بديلاً لآليات
idref ، إلخ.
تقدم واجهة برمجة التطبيقات البصرية فكرة جيدة عن كيفية عمل كل شيء "حقًا" في MarkLogic ، وبهذا المعنى تكون منخفضة المستوى ، على الرغم من أن الغرض منها هو عكس ذلك تمامًا - محاولة الاستخلاص من نموذج البيانات المستخدم ، لضمان العمل المتسق مع البيانات في نماذج مختلفة ، والمعاملات و العلاقات العامة.
Multimodel DBMS "بدون النموذج الرئيسي"
تتوفر نظم إدارة قواعد البيانات (DBMS) أيضًا في السوق ، حيث تضع نفسها كنماذج متعددة في البداية ، وليس لديها أي نموذج أساسي موروث. وتشمل هذه ArangoDB ، OrientDB (منذ عام 2018 ، شركة التطوير تنتمي إلى SAP) و CosmosDB (خدمة مضمنة في النظام الأساسي السحابي Microsoft Azure).
في الواقع ، هناك نماذج "أساسية" في ArangoDB و OrientDB. في كلتا الحالتين ، هذه نماذج بيانات خاصة ، وهي تعميمات المستند. التعميمات هي أساسا لتسهيل القدرة على إنتاج الرسم البياني والاستعلامات العلائقية.
هذه النماذج هي النماذج الوحيدة المتاحة للاستخدام في قواعد بيانات إدارة قواعد البيانات المشار إليها ؛ وقد صممت لغات الاستعلام الخاصة بها لتعمل معها. بالطبع ، تعد هذه النماذج و DBMSs واعدة ، لكن عدم التوافق مع النماذج واللغات القياسية يجعل من المستحيل استخدام هذه DBMSs في الأنظمة القديمة - استبدالها بـ DBMS التي تستخدمها بالفعل.
حول ArangoDB و OrientDB على Habré كان هناك بالفعل مقال رائع: JOIN في قواعد بيانات NoSQL .
ArangoDB
ArangoDB تدعي الدعم لنموذج بيانات الرسم البياني.
العقد الرسم البياني في ArangoDB هي مستندات عادية ، والحواف عبارة عن مستندات من نوع خاص لها ، إلى جانب حقول النظام المعتادة ( _id ، _rev ، _rev ) ، وحقول النظام _from و _to . يتم دمج المستندات الموجودة في المستند DBMSs بشكل تقليدي في مجموعات. تسمى مجموعات المستندات التي تمثل الحواف مجموعات الحواف في ArangoDB. بالمناسبة ، مستندات مجموعات الحافة هي أيضًا مستندات ، لذلك يمكن أن تكون الحواف في ArangoDB بمثابة عقد.
مصدر البياناتلنفترض أن لدينا مجموعة من persons الذين تبدو مستنداتهم كما يلي:
[ { "_id" : "people/alice" , "_key" : "alice" , "name" : "" }, { "_id" : "people/bob" , "_key" : "bob" , "name" : "" } ]
واسمحوا أيضا مجموعة من cafes :
[ { "_id" : "cafes/jd" , "_key" : "jd" , "name" : " " }, { "_id" : "cafes/jj" , "_key" : "jj" , "name" : "-" } ]
ثم قد تبدو مجموعة الإعجابات بهذا الشكل:
[ { "_id" : "likes/1" , "_key" : "1" , "_from" : "persons/alice" , "_to" : "cafes/jd", "since" : 2010 }, { "_id" : "likes/2" , "_key" : "2" , "_from" : "persons/alice" , "_to" : "cafes/jj", "since" : 2011 } , { "_id" : "likes/3" , "_key" : "3" , "_from" : "persons/bob" , "_to" : "cafes/jd", "since" : 2012 } ]
الاستفسارات والنتائجاستعلام على غرار الرسم البياني في AQL المستخدم في ArangoDB والذي يُرجع معلومات النموذج المقروءة من قبل الإنسان حول من يحب المقهى الذي يبدو كالتالي:
FOR p IN persons FOR c IN OUTBOUND p likes RETURN { person : p.name , likes : c.name }
بأسلوب علائقي ، عندما يكون من المحتمل أكثر "حساب" العلاقات ، بدلاً من تخزينها ، يمكن إعادة كتابة هذا الاستعلام على هذا النحو (بالمناسبة ، يمكنك الاستغناء عن مجموعة likes ):
FOR p IN persons FOR l IN likes FILTER p._key == l._from FOR c IN cafes FILTER l._to == c._key RETURN { person : p.name , likes : c.name }
النتيجة في كلتا الحالتين ستكون هي نفسها:
[ { "person" : "" , likes : "-" } , { "person" : "" , likes : " " } , { "person" : "" , likes : " " } ]
المزيد من الاستفسارات والنتائجإذا كان يبدو أن تنسيق النتيجة أعلاه نموذجي بالنسبة لنظام إدارة قواعد البيانات العلائقية مقارنة بمستند واحد ، يمكنك تجربة هذا الاستعلام (أو يمكنك استخدام COLLECT ):
FOR p IN persons RETURN { person : p.name, likes : ( FOR c IN OUTBOUND p likes RETURN c.name ) }
ستكون النتيجة على النحو التالي:
[ { "person" : "" , likes : ["-" , " "] } , { "person" : "" , likes : [" "] } ]
OrientDB
يعتمد تطبيق نموذج الرسم البياني أعلى نموذج المستند في OrientDB على قدرة حقول المستند على أن يكون ، بالإضافة إلى القيم العددية القياسية أكثر أو أقل ، أنواعًا مثل LINK و LINKBAG و LINKBAG و LINKBAG و LINKBAG . قيم هذه الأنواع هي ارتباطات أو مجموعات من الارتباطات إلى معرفات مستند النظام .
معرف المستند المعين من قبل النظام له "معنى مادي" ، يشير إلى موضع السجل في قاعدة البيانات ، ويبدو مثل هذا: @rid : #3:16 . وبالتالي ، فإن قيم الخصائص المرجعية هي في الحقيقة مؤشرات أكثر احتمالًا (كما في نموذج الرسم البياني) ، بدلاً من شروط التحديد (كما في نموذج العلائقية).
كما هو الحال في ArangoDB ، في OrientDB ، يتم تمثيل الحواف كمستندات منفصلة (على الرغم من أنه إذا لم يكن للحافة خصائص خاصة بها ، فيمكن جعلها خفيفة الوزن ولن تكون الوثيقة المنفصلة متوافقة معها).
مصدر البياناتفي تنسيق قريب من تنسيق تفريغ قاعدة بيانات OrientDB ، ستبدو البيانات من المثال السابق لـ ArangoDB كما يلي:
[ { "@type": "document", "@rid": "#11:0", "@class": "Person", "name": "", "out_likes": [ "#30:1", "#30:2" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#12:0", "@class": "Person", "name": "", "out_likes": [ "#30:3" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#21:0", "@class": "Cafe", "name": "-", "in_likes": [ "#30:2", "#30:3" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#22:0", "@class": "Cafe", "name": " ", "in_likes": [ "#30:1" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#30:1", "@class": "likes", "in": "#22:0", "out": "#11:0", "since": 1262286000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:2", "@class": "likes", "in": "#21:0", "out": "#11:0", "since": 1293822000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:3", "@class": "likes", "in": "#21:0", "out": "#12:0", "since": 1325354400000, "@fieldTypes": "in=LINK,out=LINK,since=date" } ]
كما نرى ، تخزن القمم أيضًا معلومات حول الحواف الواردة والصادرة. عند استخدام واجهة برمجة تطبيقات Document ، يجب عليك اتباع التكامل المرجعي بنفسك ، كما أن واجهة برمجة تطبيقات Graph تأخذك في الاعتبار. ولكن دعونا نرى كيف تبدو الدعوة إلى OrientDB "نظيفة" ، غير مدمجة في لغات البرمجة ، ولغات الاستعلام.
الاستفسارات والنتائجيبدو استعلام مماثل في الغرض من الاستعلام من مثال ArangoDB في OrientDB كما يلي:
SELECT name AS person_name, OUT('likes').name AS cafe_name FROM Person UNWIND cafe_name
سيتم الحصول على النتيجة على النحو التالي:
[ { "person_name": "", "cafe_name": " " }, { "person_name": "", "cafe_name": "-" }, { "person_name": "", "cafe_name": "-" } ]
إذا ظهر تنسيق النتيجة مرة أخرى "علائقية" ، فأنت بحاجة إلى إزالة السطر مع UNWIND() :
[ { "person_name": "", "cafe_name": [ " ", "-" ] }, { "person_name": "", "cafe_name": [ "-" ' } ]
يمكن وصف لغة استعلام OrientDB على أنها SQL مع إدراج يشبه Gremlin. قدم الإصدار 2.2 نموذج طلب Cypher-like ، MATCH :
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe} RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name GROUP BY person_name
سيكون تنسيق النتيجة هو نفسه كما في الاستعلام السابق. فكر فيما يجب إزالته لجعله "أكثر ارتباطية" ، كما في الاستعلام الأول.
أزور CosmosDB
إلى حد أقل ، يشير ما قيل أعلاه حول ArangoDB و OrientDB إلى Azure CosmosDB. يوفر CosmosDB واجهات برمجة التطبيقات (API) للوصول إلى البيانات التالية: SQL و MongoDB و Gremlin و Cassandra.
تستخدم واجهة برمجة تطبيقات SQL API و MongoDB للوصول إلى البيانات في نموذج المستند. Gremlin API و Cassandra API - للوصول إلى البيانات في الرسم البياني والعمود ، على التوالي. يتم حفظ البيانات في جميع الطرز بتنسيق النموذج الداخلي لـ CosmosDB: ARS ("تسلسل ذرة - سجل") ، وهو أيضًا قريب من المستند واحد.

ولكن تم إصلاح نموذج البيانات الذي حدده المستخدم وواجهة برمجة التطبيقات المستخدمة في وقت إنشاء الحساب في الخدمة. من المستحيل الوصول إلى البيانات التي تم تحميلها في نموذج واحد بتنسيق نموذج آخر ، والذي سيوضحه شيء مثل هذا:

وبالتالي ، تعد الوسائط المتعددة في Azure CosmosDB اليوم مجرد فرصة لاستخدام العديد من قواعد البيانات التي تدعم نماذج مختلفة من نفس الشركة المصنعة ، والتي لا تحل جميع مشاكل التخزين متعدد المتغيرات.
Multimodel DBMS بناء على نموذج الرسم البياني؟
تجدر الإشارة إلى أنه لا يوجد في السوق قواعد بيانات إدارة قواعد بيانات متعددة النماذج تعتمد على نموذج رسم بياني (باستثناء دعم نماذج متعددة لنماذج جرافيك متزامنة: RDF و LPG ؛ انظر هذا في منشور سابق ). تتمثل أكبر الصعوبات في التنفيذ أعلى نموذج الرسم البياني للوثيقة ، بدلاً من العلائقية.
تم النظر في مسألة كيفية تنفيذ نموذج علائقي على نموذج الرسم البياني حتى في وقت تشكيل الأخير. كما قال ديفيد ماكغفرن ، على سبيل المثال:
لا يوجد شيء متأصل في نهج الرسم البياني الذي يمنع إنشاء طبقة (على سبيل المثال ، عن طريق الفهرسة المناسبة) على قاعدة بيانات الرسم البياني التي تمكن من عرض علائقية مع (1) استرداد المجموعات من أزواج قيمة المفتاح المعتادة و (2) تجميع المجموعات نوع العلاقة.
عند تنفيذ نموذج المستند أعلى الرسم البياني ، يجب أن تأخذ في الاعتبار ، على سبيل المثال ، ما يلي:
- تعتبر عناصر مجموعة JSON مرتبة ، وهي تأتي من أعلى حافة الرسم البياني - لا ؛
- عادة ما تتم إزالة البيانات في نموذج المستند ، ولا تزال لا ترغب في تخزين عدة نسخ من المستند المرفق نفسه ، وعادة ما لا تحتوي المستندات الثانوية على معرفات ؛
- من ناحية أخرى ، فإن أيديولوجية المستندات DBMSs هي أن المستندات هي "وحدات" جاهزة لا تحتاج إلى إعادة بنائها في كل مرة. يجب أن يوفر في نموذج الرسم البياني القدرة على الحصول بسرعة على الرسم البياني المقابل للوثيقة النهائية.
بعض الإعلاناتيرتبط مؤلف المقال بتطوير قاعدة بيانات NitrosBase DBMS ، والتي يكون النموذج الداخلي لها نماذج رسومية ، والنماذج الخارجية - العلائقية والمستندية - هي تمثيلاتها. جميع النماذج متساوية: تتوفر أي بيانات تقريبًا في أي منها باستخدام لغة الاستعلام الطبيعية لها. علاوة على ذلك ، في أي تمثيل البيانات عرضة للتغيير. سوف تنعكس التغييرات في النموذج الداخلي ، وبالتالي في التمثيلات الأخرى.
كيف يبدو نموذج المطابقة في NitrosBase - سأصف ، كما آمل ، في واحدة من المقالات التالية.
استنتاج
آمل أن تصبح المعالم العامة لما يسمى بالنماذج المتعددة أكثر وضوحًا للقارئ. تسمى أنظمة إدارة قواعد البيانات (DBMS) المختلفة تمامًا نماذج متعددة ، وقد يبدو "دعم العديد من النماذج" مختلفًا. لفهم ما يسمى "متعدد النماذج" في كل حالة ، من المفيد الإجابة على الأسئلة التالية:
- هل هو عن دعم النماذج التقليدية ، أو عن نموذج هجين واحد؟
- هل النماذج "متساوية" أم أن أحدها يخضع للآخرين؟
- هل النماذج "غير مبالية" لبعضها البعض؟ يمكن قراءة البيانات المسجلة في نموذج واحد في آخر أو حتى الكتابة؟
أعتقد أنه من الممكن بالفعل تقديم إجابة إيجابية عن مسألة أهمية نظم إدارة قواعد البيانات المتعددة الوسائط ، ولكن مسألة الأنواع المحددة التي ستكون أكثر طلبًا في المستقبل القريب أمر مثير للاهتمام. يبدو أن نظم إدارة قواعد البيانات متعددة النماذج التي تدعم النماذج التقليدية ، وخاصة النماذج العلائقية ، ستكون أكثر طلبًا ؛ , , , — .