استخدام البيانات من نظام إدارة خدمات تكنولوجيا المعلومات (ITSM) كمثال.
في مقال سابق عن
SAP Process Mining أو كيفية فهم عملياتنا التجارية ، تحدثنا عن Process Mining وتطبيقه في بيئة الشركة. اليوم نريد أن نتحدث أكثر عن نموذج البيانات وعملية تحضيره. سننظر في المكونات ، وكيفية ترابطها ، وما هو تنسيق البيانات المطلوب طلبه من مالكي البيانات ، وما هي الطريقة لإنشاء جدول أحداث لـ SAP Process Mining by Celonis.
نموذج البيانات في SAP PROCESS MINING بواسطة CELONIS
بنية البيانات في أداة SAP Process Mining by Celonis بسيطة للغاية:
- "جدول الأحداث." هذا جزء مطلوب من نموذج البيانات. يمكن أن يكون هذا الجدول واحدًا فقط في كل نموذج بيانات فردي. يتم إنشاء رسم بياني للمعالجة تلقائيًا. انظر الشكل 1.
- الدلائل هي أي جداول أخرى تقوم بتوسيع "جدول الأحداث" بمعلومات تحليلية إضافية. خلافا لها في المعلومات المرجعية لا يتغير مع مرور الوقت. بتعبير أدق ، يجب ألا يتغير في الفترة الزمنية التي نحللها. على سبيل المثال ، يمكن أن يكون جدولًا مع وصفًا لخصائص العقود وعناصر المشتريات وطلبات شيء ما والموظفين واللوائح والمقاولين والكائنات الأخرى التي تشارك بطريقة ما في العملية. في هذه الحالة ، سيصف المرجع جميع أنواع الخصائص الثابتة لهذه الكائنات (الكميات والأنواع والأسماء والأسماء والأحجام والإدارات والعناوين والسمات المختلفة الأخرى). الدلائل اختيارية. يمكنك تشغيل نموذج البيانات بدونها. ببساطة تحليل مثل هذه العملية سيكون أقل إثارة للاهتمام.
 الشكل 1. نموذج البيانات في Proces Mining: جدول أحداث ومرجع لحالات العمليات
الشكل 1. نموذج البيانات في Proces Mining: جدول أحداث ومرجع لحالات العملياتجدول الأحداث عبارة عن جدول قياسي (التخزين الفعلي ، بدلاً من الجداول المنطقية) في النظام الأساسي في الذاكرة لـ SAP HANA. يمكن تقديم الأدلة كجداول قياسية (التخزين الفعلي) ، وجداول الحساب (طرق عرض الحساب). مع استثناءات نادرة ، قد يكون من الضروري إضافة بعض المراجع الصغيرة في شكل CSV أو XLSX إلى نموذج البيانات الحالي. هذه الميزة موجودة مباشرة في الواجهة الرسومية.
أدناه سوف نلقي نظرة فاحصة على كل من هذين المكونين من نموذج البيانات.
يحتوي "جدول الأحداث" (المعروف أيضًا باسم "سجل الأحداث") على ثلاثة أعمدة مطلوبة على الأقل:
- معرف العملية هو مفتاح فريد لكل مثيل للعملية (على سبيل المثال ، مرجع أو حادث أو رقم مهمة). في المثال في الشكل 2 ، هذا هو العمود "CASE_ID".
- النشاط. هذا هو اسم الخطوة في العملية - نوع من الأحداث التي نهتم بها. إنه من الأنشطة التي سيتم تكوين الرسم البياني للعملية (العمود "EVENT").
- الطابع الزمني للحدث (العمود "TIMESTAMP").
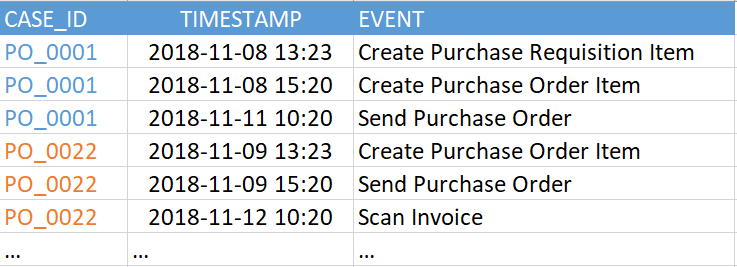 الشكل 2. مثال جدول الحدث
الشكل 2. مثال جدول الحدثيدعم الإصدار الحالي من SAP Process Mining by Celonis ما يصل إلى 1000 حدث فريد في نموذج بيانات واحد. أي أن عدد القيم الفريدة في عمود "EVENT" في المثال أعلاه (في جدول الأحداث الخاص بك قد يطلق عليه بشكل مختلف) يجب ألا يزيد عن 1000. والأحداث نفسها (أي الصفوف في هذا الجدول) يمكن أن تكون كبيرة جدًا. لقد رأينا أمثلة لمئات الملايين من الأحداث في نموذج بيانات واحد.
يمكن تمثيل الطابع الزمني إما بعمود واحد ، ومن ثم تكون مهمتك هي تحديد ما يعنيه - بداية أو نهاية الخطوة ، أو عمودين ، كما هو موضح في الشكل 3 ، عندما تتم الإشارة إلى بداية ونهاية الخطوة بشكل صريح. الفرق الأساسي بين الإصدار المكون من عمودين هو أن النظام سيكون قادرًا على التعرف تلقائيًا على الخطوات المنفذة بالتوازي مع بعضها البعض. يظهر هذا عند مقارنة أوقات البداية والنهاية للخطوات المختلفة.
 الشكل 3. مثال جدول الأحداث مع اثنين من الطوابع الزمنية
الشكل 3. مثال جدول الأحداث مع اثنين من الطوابع الزمنيةجميع الأعمدة الأخرى في هذا الجدول اختيارية. يمكن أيضًا استعادة الرسم البياني للعملية بنجاح باستخدام الأعمدة الثلاثة المطلوبة ، ولكن سيكون من الصعب التخلص من الشعور بأن هناك شيئًا ما مفقودًا. لذلك ، يوصى بشدة ألا تقتصر على الحد الأدنى من السماعات.
الأعمدة الإضافية هي أي معلومات تهمك ، والتي تتغير أثناء العملية أو مرتبطة بحدث معين. على سبيل المثال ، اسم الموظف الذي قدم الحدث ، ومجموعة العمل ، والأولوية الحالية للتطبيق. التركيز على الاعتماد على الوقت ليس من قبيل الصدفة هنا. يوصى بترك البيانات القابلة للتغيير فقط في جدول الأحداث. يتم وضع جميع المعلومات الثابتة الأخرى في أدلة منفصلة. بمعنى آخر ، يجب تطبيع سجل الأحداث ، إن أمكن. لم يتم ذلك كثيرًا لتقليل كمية البيانات ، ولكن لتسهيل العمل مع تعبيرات PQL في مرحلة إنشاء التقارير التحليلية.
دع كل شيء في مكانهماذا يحدث إذا أضفت عمودًا يحتوي على معلومات مرجعية إلى "جدول الأحداث"؟ بشكل عام ، لن يحدث شيء فظيع ، على الأقل في البداية. وللاختبار السريع لأي فكرة ، فإن هذا الخيار مناسب تمامًا. يمكن أن يكون هناك اثنين فقط من النتائج السلبية: النسخ غير الضروري لنسخ البيانات والصعوبات الإضافية في بعض الصيغ التحليلية. كان من الممكن تجنب هذه الصعوبات إذا تم تقديم جميع البيانات الإضافية إلى الدليل. بشكل عام ، من الأفضل القيام بذلك على الفور.
قليلا عن الترخيصيرتبط جدول الأحداث بترخيص SAP Process Mining من قِبل Celonis. نموذج بيانات واحد = ترخيص واحد = سجل أحداث واحد. مع بعض الحجوزات ، يمكننا أن نقول أن سجل أحداث واحد = عملية أعمال واحدة. سيكون التحذير كما يلي: قد تنشأ المواقف عندما تتوافق عدة عمليات مع سجل أحداث واحد ، والعكس بالعكس - يتم إنشاء عدة سجلات أحداث عمدا لعملية واحدة. بالإضافة إلى ذلك ، يمكن تفسير مصطلح "العملية التجارية" من وجهة نظر البيانات على نطاق واسع. لذلك ، لأغراض الترخيص ، وللمعيار الواضح ، تم تحديد عدد سجلات الأحداث. يجب أن يعتمد المرء على هذا المعيار.
مراجعالدلائل اختيارية ، وإضافتها إلى نموذج البيانات أمر اختياري. أنها تحتوي على أي معلومات إضافية قد تكون مفيدة لتحليل العملية. ولكن على عكس جدول الأحداث ، فإن المعلومات الواردة في الأدلة ثابتة ، ولا تعتمد على الوقت الذي وقع فيه الحدث.
يجب ذكر حالة معينة واحدة هنا. عندما يتعلق الأمر ببيانات المستخدم الذي يقوم بالخطوات في عملية الأعمال ، فإن السؤال الذي يطرح نفسه هو: هل هذه المعلومات المرجعية؟ من ناحية ، نعم - هذه بيانات ثابتة. سيكون من الجيد أن تترك في جدول الأحداث فقط "USER_ID" معيّنًا ، حيث سيتم ربط اسم المستخدم وموقعه وقسمه والعضوية في مجموعة العمل ، وما إلى ذلك. ولكن من ناحية أخرى ، دعونا نتخيل أننا نحلل عملية تجارية في فترة زمنية تتراوح من 2-3 سنوات. خلال هذا الوقت ، يمكن للمستخدم تغيير العديد من الوظائف والتبديل بين الإدارات أو مجموعات العمل. اتضح أن هذه هي المعلومات التي تتغير بالفعل مع مرور الوقت. وفي هذه الحالة ، يجب تركه في جدول الأحداث ، والذي سيؤدي بدوره إلى حقيقة أنه بالإضافة إلى "USER_ID" في سجل الأحداث ، ستظهر أعمدة مثل "مجموعة العمل" و "الموضع" و "القسم" وحتى "الاسم الكامل" (الاسم الأخير) يمكن أن تتغير أيضا خلال هذا الوقت). بشكل عام ، تظل مسألة ما إذا كان يجب تطبيع معلومات المستخدم أم لا وفقًا لتقدير العميل.
يمكن إضافة الدلائل إلى نموذج بيانات موجود في أي وقت.
للقيام بذلك بسيط للغاية:
- يتم إنشاء جدول في SAP HANA.
- يضاف الجدول إلى نموذج البيانات العام باستخدام زر "استيراد البيانات".
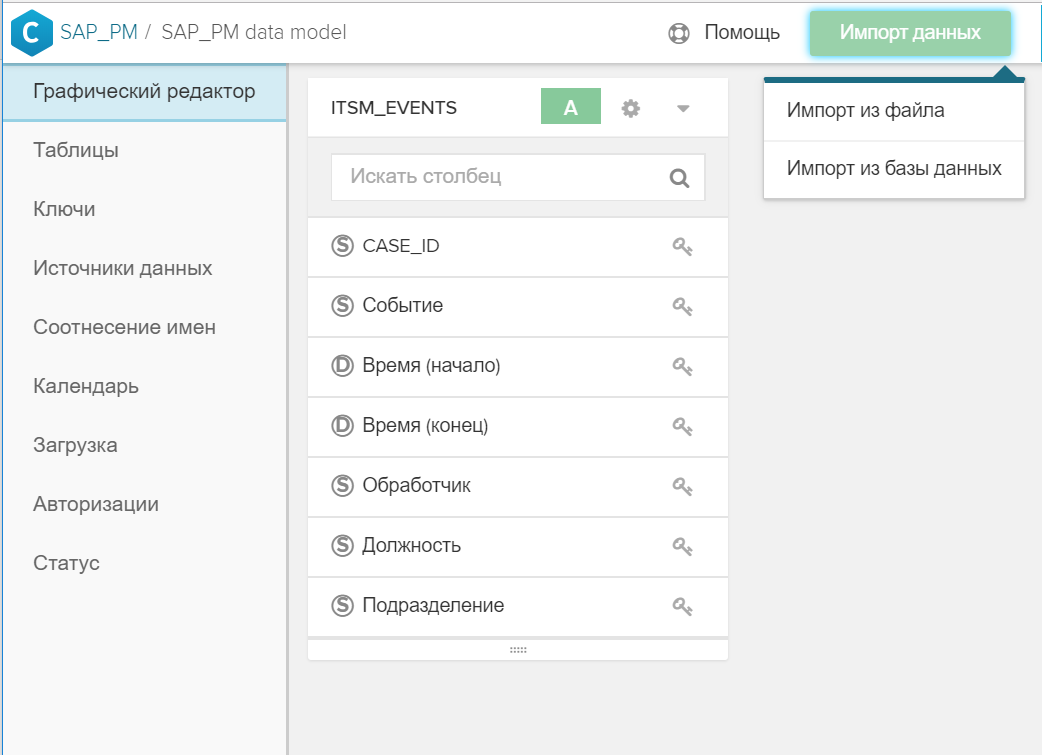
الشكل 4. استيراد جدول أو ملف إلى نموذج بيانات موجود - يشار إلى المفتاح (أو المفاتيح) في الواجهة الرسومية ، والتي يرتبط بها الدليل الجديد بجدول الأحداث و / أو مع الأدلة الأخرى. للقيام بذلك ، فقط اضغط على الأيقونة
 في جدول واحد ثم على المقابلة في طاولة أخرى.
في جدول واحد ثم على المقابلة في طاولة أخرى.
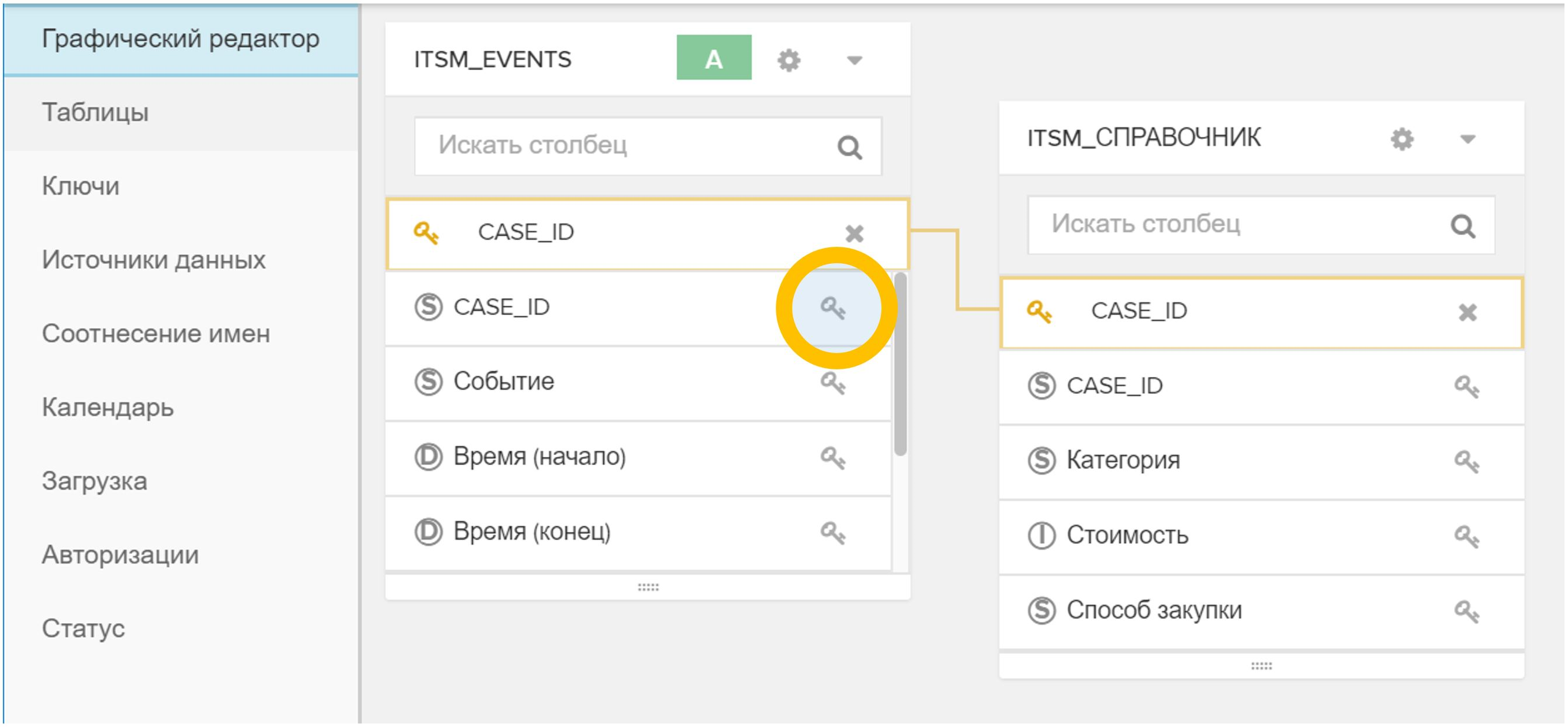
الشكل 5. ربط الجداول في نموذج البيانات بحقل تعسفي (في هذه الحالة ، CASE_ID) - في قائمة "الحالة" ، انقر فوق الزر "إعادة التحميل من المصدر". هذه العملية عادة ما تستغرق بضع ثوان.
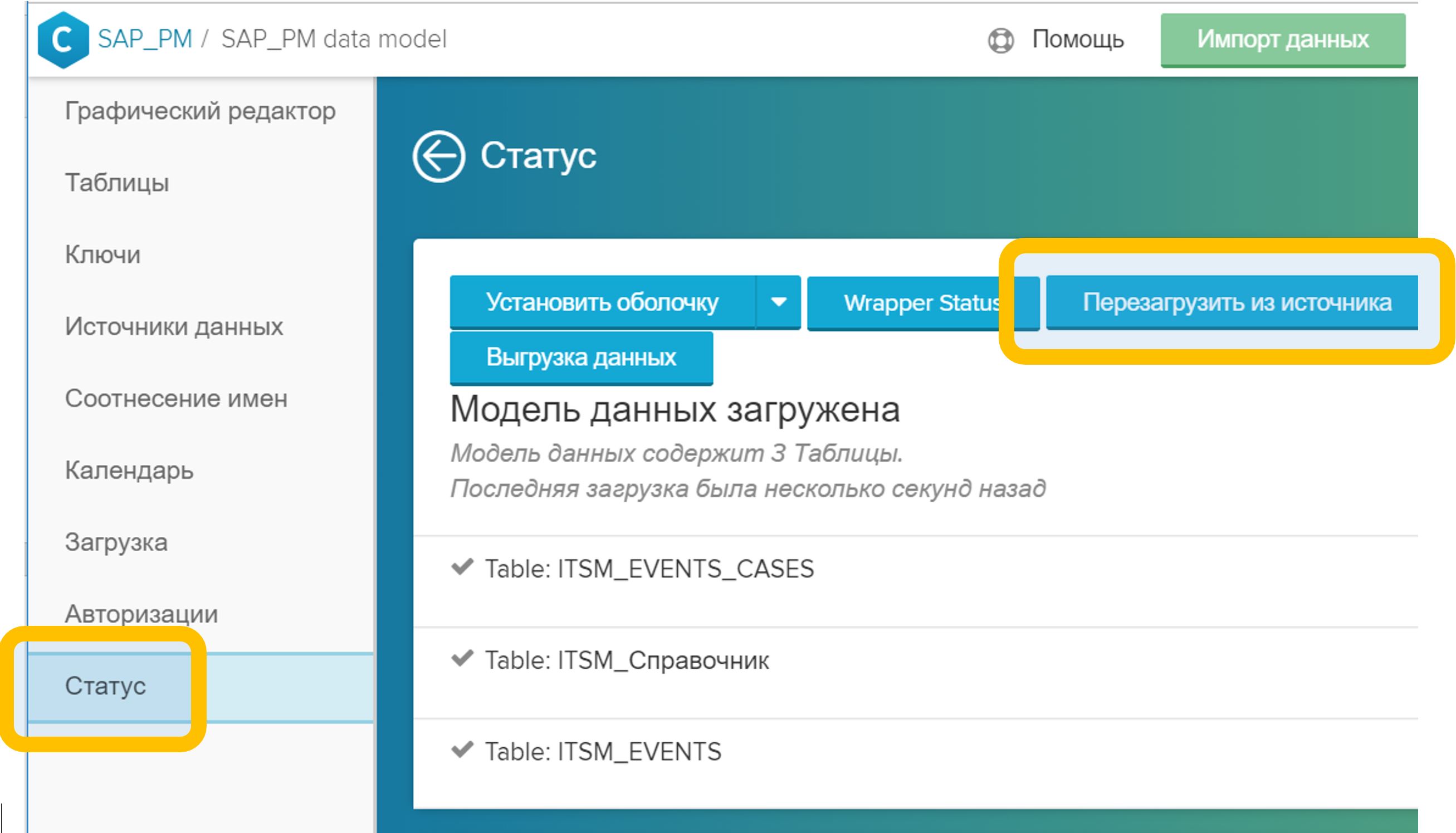 الشكل 6. إعادة تحميل نموذج البيانات من المصدر
الشكل 6. إعادة تحميل نموذج البيانات من المصدر
بعد الانتهاء من هذه الخطوات ، يمكنك استخدام التحليلات الجديدة فورًا ، سواء في التقارير الجديدة أو في التقارير الحالية. لا يضر إثراء نموذج البيانات بالعمل الحالي للمحللين بأي شكل من الأشكال: تستمر جميع التقارير التي تم إنشاؤها في العمل ، ولا تحتاج إلى إعادة تشغيلها أو تغييرها بطريقة أو بأخرى.
بالنسبة للدلائل الصغيرة نسبيًا ، هناك احتمال آخر: ليس هناك نسخة صناعية بالكامل ، بالطبع ، لكن يمكن أن يكون مفيدًا أيضًا. يتعلق الأمر بتحميل ملفات CSV و XLSX و DBF من خلال واجهة رسومية مباشرة في نموذج البيانات. يظل الإجراء كما هو موضح أعلاه تمامًا ، فقط بدلاً من جداول قاعدة البيانات ، يتم استخدام ملف تم إعداده مسبقًا ، والذي يتم تحميله باستخدام الزر "استيراد البيانات".
جدول CA: مرجع مثيل العمليةبدأت المحادثة السابقة حول الكتب المرجعية مع كونها اختيارية. يمكن حذفها تمامًا من نموذج البيانات وتقتصر على جدول الأحداث. هذا صحيح تقريبا.
مرجع إلزامي واحد موجود. يجب أن يكون هذا جدولًا يتميز بالحالة "جدول CA". المراجع المصدقة هي سلاسل من الأحداث. وقد خمنت ذلك ، سيكون المفتاح في هذا الدليل هو "CASE_ID" - المعرف الفريد لمثيل العملية. يصف هذا المرجع الخصائص الثابتة لمثيلات العملية الفردية. مثال من ITSM: مؤلف الاستئناف ، أو خدمة أعمال ، أو تاريخ الإغلاق ، أو الموظف الذي نجح في حل الحادث ، أو علامة على شخصية جماعية ، إلخ
 الشكل 7. مثال CA الجدول
الشكل 7. مثال CA الجدولومع ذلك لم أخدعك كثيرًا. إذا قررت لسبب ما عدم إضافة الدليل المطلوب إلى نموذج البيانات ، فسيقوم النظام بإنشائه بنفسه. يمكن رؤية نتيجة عملها في علامة تبويب الحالة: إذا تم استدعاء جدول الحدث الخاص بك ، على سبيل المثال ، "ITSM_EVENTS" ، فسيتم إنشاء الجدول "ITSM_EVENTS_CASES" بالاقتران معه ، كما في الشكل 8.
الشكل 8. جدول سلسلة الأحداث (CA) الذي تم إنشاؤه تلقائيًاسيكون جدول المرجع المصدق الذي تم إنشاؤه تلقائيًا وصفًا بسيطًا للغاية لمثيلات العملية: المفتاح ، وعدد الأحداث ، ومدة العملية (كما لو قمت بتجميع جدول حدث بمعرف العملية ، وحساب عدد الصفوف والفرق بين وقت الخطوتين الأولى والأخيرة). لذلك ، من المنطقي إنشاء نسختك الأكثر إثارة من جدول المرجع المصدق. يمكن إضافته إلى نموذج البيانات في أي وقت. في هذه الحالة ، بمجرد إضافة جدول المرجع المصدق الخاص بك إلى النموذج ، سيتم حذف الدليل الذي تم إنشاؤه بواسطة النظام (في حالتنا وهو "ITSM_EVENTS_CASES") تلقائيًا من نموذج البيانات.
لماذا هو "الجدول CA" مثيرة للاهتمام؟ هي التي يتم عرضها في الواجهة الرسومية كتفاصيل عملية. إذا وجد المحلل ، أثناء العمل مع نموذج البيانات ، شيئًا مثيرًا للاهتمام في هذه العملية وأراد الانتقال إلى أمثلة فردية محددة ، فسيستخدم تقرير "عرض المرجع المصدق" ، أي التفاصيل. بعد فتح هذا التقرير ، ستجد فيه دليلًا للعملية (مقترنًا بجدول الأحداث ، بالطبع). لذلك ، أضف إلى "جدول CA" كل ما يمكن للمحلل استخدامه لفهم خصائص العملية وشروط مسارها.
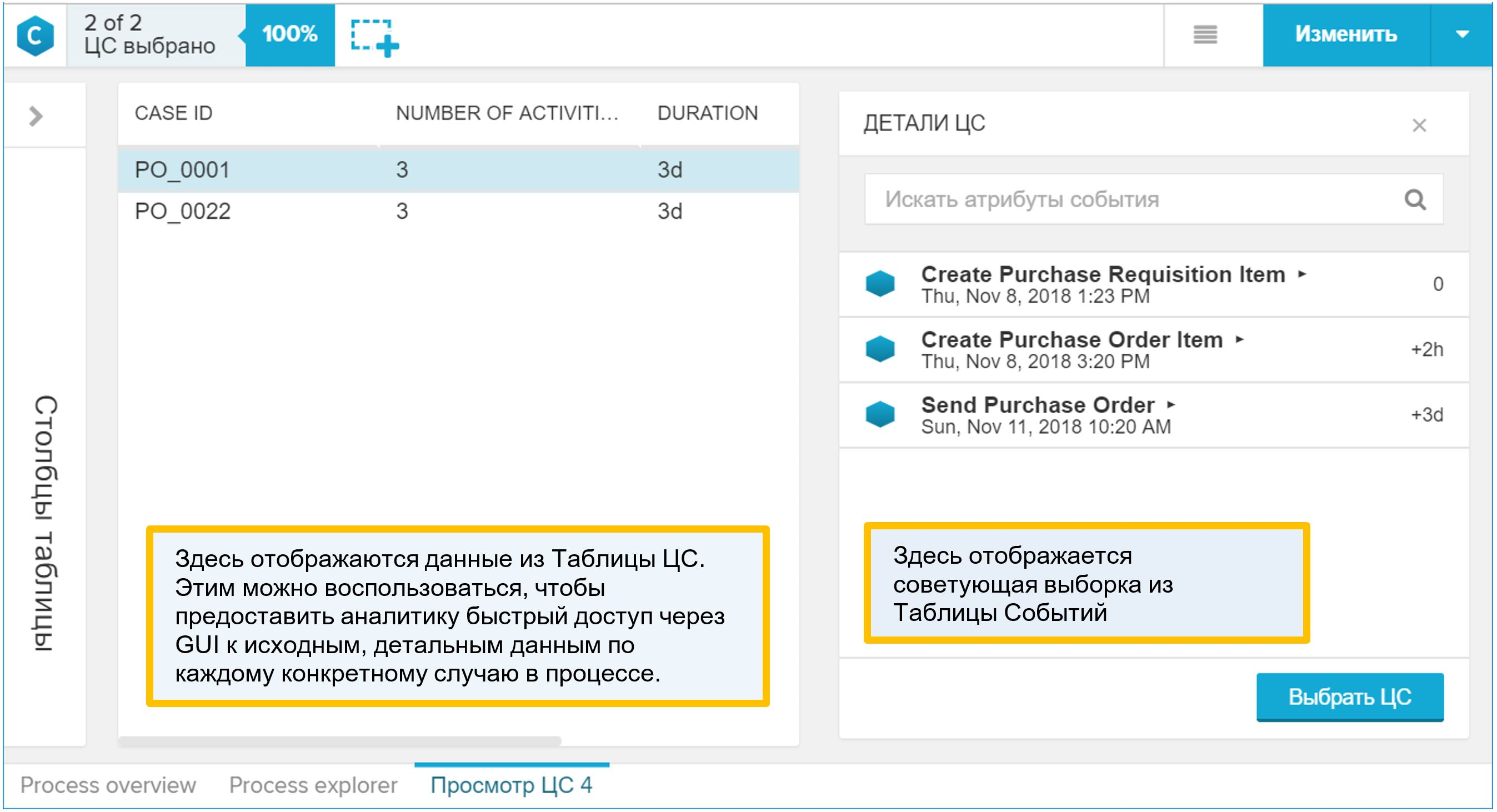 الشكل 9. تقرير مثال اصطناعي "عرض CA"
الشكل 9. تقرير مثال اصطناعي "عرض CA"كيفية إضافة مرجع العملية الخاص بك إلى نموذج البيانات:
- يتم إنشاء جدول في SAP HANA.
- يضاف الجدول إلى نموذج البيانات العام باستخدام زر "استيراد البيانات".
- في الواجهة الرسومية ، في خصائص الجدول ، تحتاج إلى تعيين الدور "Table with CA" عليه.
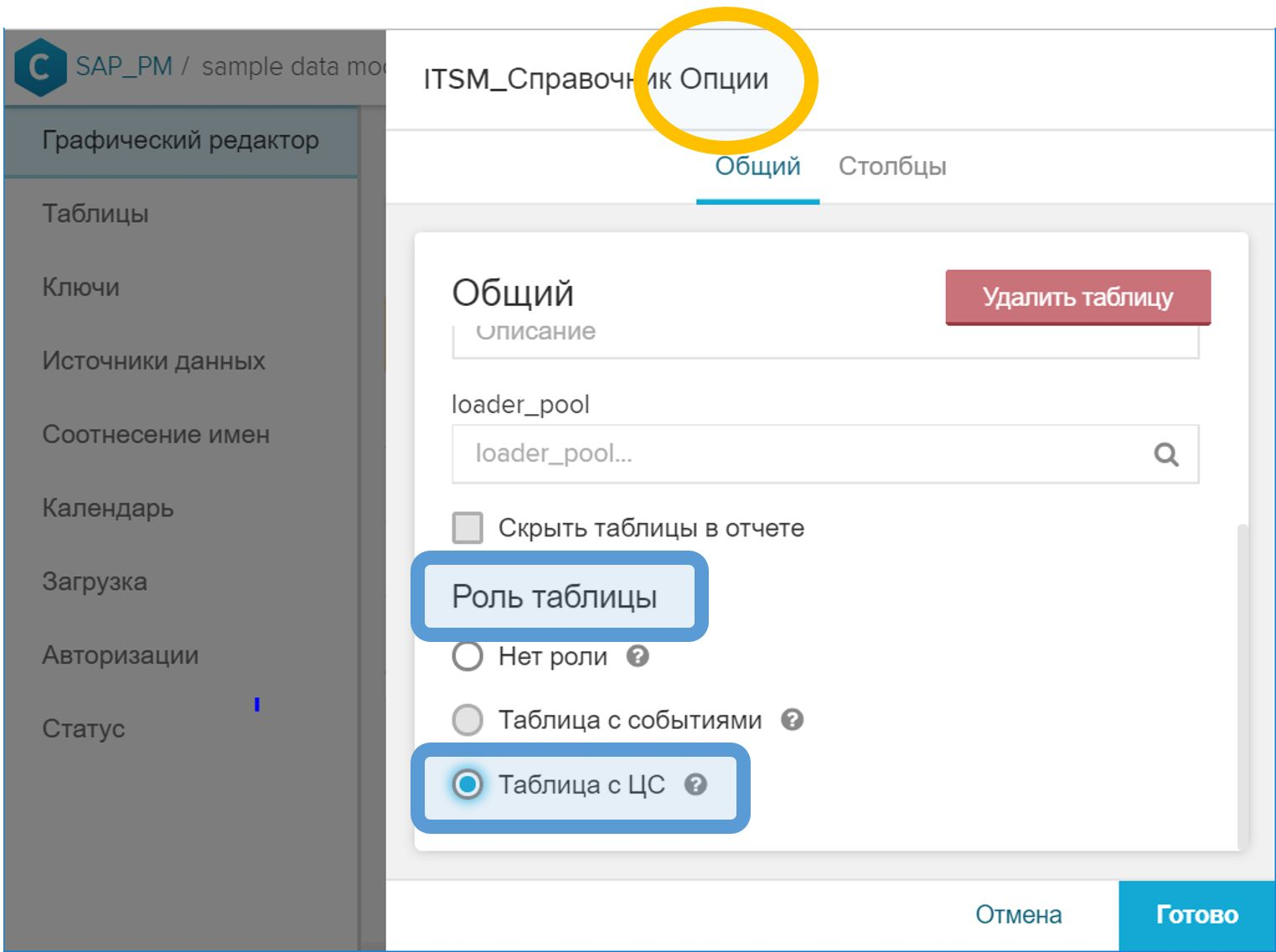
الشكل 10. دور "الجدول مع المرجع المصدق" للإشارة إلى دليل مثيلات العملية - في واجهة المستخدم الرسومية ، قم بربط جدول المرجع المصدق بجدول الأحداث بمعرف العملية. يتم تنفيذ هذه الخطوة بنفس الطريقة المتبعة في حالة وجود دليل عادي - باستخدام مفتاح رمز المفتاح ( ) مقابل الحقل المقابل.
- في قائمة "الحالة" ، انقر فوق الزر "إعادة التحميل من المصدر".
ملاحظة مهمة: يجب أن يحتوي العمود "CASE_ID" (في كل حالة ، يمكن تسميته بطريقة أخرى) في جدول المرجع المصدق (CA) ، الذي يحتوي على معرف العملية ويستخدم للربط بجدول الأحداث ، على قيم فريدة فقط. هذا منطقي جدا. وإذا لم يكن الأمر كذلك لسبب ما ، فعند تحميل نموذج البيانات في الخطوة (5) ، سيتم إنشاء الخطأ المقابل (حول استحالة إجراء عملية "JOIN" على جدول الأحداث وجدول CA).
إنشاء نموذج بيانات من سجل التغيير
في الممارسة العملية ، صادفنا مصادر بيانات مختلفة جدًا لعملية التعدين. يتم تحديد تكوينها من خلال عملية الأعمال المحددة والمعايير المعتمدة من قبل العميل.
إحدى الحالات الأكثر شيوعًا هي البيانات من نظام إدارة خدمات تكنولوجيا المعلومات (ITSM ، إدارة خدمات تكنولوجيا المعلومات) ، لذلك قررنا تحليل هذا المثال أولاً. في الواقع ، لا يوجد ربط محكم على وجه التحديد ل ITSM في هذا النهج. يمكن تطبيقه في عمليات الأعمال الأخرى ، حيث يكون مصدر البيانات هو سجل التغيير أو سجل التدقيق.
ماذا تسأل من ذلك؟إذا لم تكن موظف تكنولوجيا المعلومات أو المتخصص الذي يخدم أساس ITSM ، فاستعد لحقيقة أنه سيُطلب منك صياغة إجابة دقيقة على السؤال "ما الذي تفريغه؟" أو "ماذا تريد منا؟"
وهذا غير معروف دائمًا - ما هو المطلوب بالضبط. تحليل العملية التجارية هو دراسة ، والبحث عن الأنماط والبحث عن "الأفكار". إذا علمنا مقدمًا ما هو نوع "البصيرة" الذي نبحث عنه ، فلن يكون هذا "نظرة ثاقبة" بعد الآن. في الحقيقة ، أود الحصول على "كل شيء": السمات ، العلاقات ، التغييرات. ولكن ، كما تبين الممارسة ، لم يكن من الممكن الحصول على إجابة دقيقة جيدة على سؤال عام للغاية.
هناك إجابتان محتملتان على السؤال "ماذا تفريغ".
الخيار خاطئ: اطلب الأساس لتفريغ جميع التغييرات في حالات التطبيق بالإضافة إلى مجموعة من السمات الواضحة (على سبيل المثال ، الأولوية ، الفنان ، مجموعة العمل ، إلخ). أولاً ، تحصل على مجموعة محدودة من المحللين: أنت تعرف بالفعل ما الذي ستقيسه في العملية (ومن هنا جاءت مجموعة السمات) ، لذلك ستتحول عملية التعدين إلى أداة لحساب KPI للعملية (مريحة للغاية ، يجب أن أقول ، أداة ؛ لكنني ما زلت أريد أن أكثر).
ثانياً ، يفسر كل قسم من أقسام تكنولوجيا المعلومات بشكل فردي طلب إضافة سمات طلب إضافية للتحميل. على سبيل المثال ، تأخذ الأولوية: يمكن أن تتغير أثناء العمل على مكالمة. يتم تسجيل الاستئناف بأولوية واحدة ، ثم يقوم أخصائي مجموعة العمل بتغييره ، ويغلق بحالة مختلفة. والسؤال الآن هو: في التفريغ الذي طلبته ، ما هي اللحظة التي تتوافق مع الأولوية؟ في البداية ، يبدو أن قيمة الأولوية يجب أن تتوافق مع العمود "تاريخ ووقت الحدث". ولكن في الواقع ، غالبًا ما يتبين أن حالة التطبيق نفسها هي وحدها التي تتوافق مع التاريخ والوقت المحددين ، وجميع الأعمدة الأخرى هي القيم في وقت التفريغ أو في وقت إغلاق التطبيق. وأنك لن تعرف هذا في وقت واحد.
يبدو لي أن هناك خيارًا أفضل. يمكنك طلب البيانات في شكل الجدول التالي:
- رقم الاستئناف ، الحادث ، المهمة (SD * ، IM * ، RT * ، ...) هو معرف الكائن في نظام ITSM (NVARCHAR)
- الطابع الزمني (TIMESTAMP)
- اسم السمة (NVARCHAR)
- القيمة القديمة (NVARCHAR)
- قيمة جديدة (NVARCHAR)
- الذي تغير (NVARCHAR)
في الواقع ، هذا ليس أكثر من تاريخ التغييرات في أي سمات. في واجهات أنظمة ITSM ، يمكنك رؤية مثل هذا الجدول في علامات التبويب التي تحمل الاسم "History" أو "Journal".
مزايا هذا النهج واضحة:
- تحميل بسيط وواضح الشكل. إنه مألوف لدى محترفي تكنولوجيا المعلومات في الواجهة الرسومية للنظام نفسه. لا ينبغي أن يسبب أسئلة من الأساس.
- نحصل على قائمة بجميع السمات الممكنة مع كل القيم الممكنة. نعم ، سيكون هناك الكثير منهم ، على الأرجح عدة مئات. لكن غربلة الأشياء غير الضرورية وغير الضرورية أمر بسيط للغاية ، ولكن في كل مرة لا يكون طلب التفريغ الإضافي سهلاً وطويلًا دائمًا (خاصةً عندما لا تعرف السمات الموجودة في النظام على الإطلاق).
- هذا نموذج بيانات موثوق. من الصعب إفسادها ، إلا إذا قمت بعمل معلومات كاذبة عن قصد.
- نحن نعرف تمامًا ما كانت لكل سمة في كل لحظة من الزمن. هذا مهم لأننا نختبر أنفسنا ونتأكد من صحة النموذج. وأثناء التحليل ، يمكننا إضافة خطوات وسيطة إلى النموذج ("التكبير") وتحديد قيم السمات الصحيحة في جميع النقاط الإضافية في الوقت المناسب.
عيوب الخيار الثاني واضحة أيضا. ويبدو لي أنه يمكن حلها (على عكس مشكلة البيانات غير المكتملة):
- يصبح برنامج SQL لإعداد البيانات أكثر تعقيدًا إلى حد ما - مقارنةً بالخيار عندما يقوم فريق أساس تكنولوجيا المعلومات بالإعداد الجزئي للبيانات لك (راجع الإصدار الأول من الاستعلام أعلاه) ، دون الشك في ذلك. نعم ، هو (النص) أكثر تعقيدًا ، لكنه وحده. أعتقد أن مشاركة إعداد البيانات بين فريق ITSM وفريق Process Mining سيكون فكرة سيئة. من الناحية المثالية ، يجب نقل التحويل بأكمله إلى فريق Process Mining بحيث يفهمون بالضبط ما يحدث مع البيانات ، ولتقليل التداخل مع البيانات الموجودة على الجانب المصدر. يساعد تنسيق تبادل البيانات البسيط على تحقيق هذا الهدف.
- حجم التفريغ كبير. قد يكون الترتيب: 10-30 غيغابايت في السنة لشركة كبيرة. لكن تحميل مثل هذا المجلد في HANA ليس مشكلة على الإطلاق ولا يعتبر مهمة. بالإضافة إلى ذلك ، نتحدث عن "التحميل" فقط أثناء المشروع التجريبي ، بينما سيتم استخدام تكامل ETL / ELT بين مصدر البيانات و HANA (على سبيل المثال ، HANA Smart Data Integration) في العملية الصناعية ، وسيظل هذا العنصر مهمًا.
لا أود أن أقول إن هذه هي الطريقة الصحيحة الوحيدة للحصول على البيانات من نظام ITSM لمهام تعدين العمليات. لكن في الوقت الحالي ، أميل إلى الاعتقاد بأن هذا هو التنسيق الأنسب لهذه المهمة. ربما هناك طرق أكثر إثارة للاهتمام ، وسأكون سعيدًا جدًا لمناقشة الأفكار البديلة إذا كنت تشاركها معي.
جدول أحداث الجيل
لذلك ، عند الخروج ، لدينا تاريخ من التغييرات في سمات الطلبات والحوادث والمكالمات والمهام وغيرها من كائنات ITSM. من هذا الجدول ، من الممكن إنشاء كل من المكونات الرئيسية لنموذج بيانات Process Mining: جدول الأحداث وجدول CA.
لإنشاء أحداث بناءً على محفوظات التغيير ، قم بما يلي:
- من تاريخ التغيير ، اجمع كل القيم الفريدة لعمود "اسم السمة" (المشروط).
- حدد التغيير في السمات التي ترغب في رؤيتها على الرسم البياني للعملية. ما هو "الحدث" بالنسبة لنا؟
- قم بإنشاء طريقة عرض حساب مناسبة أو كتابة برنامج نصي SQL يقوم بتصفية الصفوف المحددة من سجل التغيير ويقوم بإنشاء جدول أحداث.
افترض أن جدول التغيير كما يلي:
CREATE COLUMN TABLE "SAP_PM"."ITSM_HISTORY" ( "CASE_ID" NVARCHAR(256), "ATTRIBUTE" NVARCHAR(256), "VALUE_OLD" NVARCHAR(1024), "VALUE_NEW" NVARCHAR(1024), "TS" TIMESTAMP, "USER" NVARCHAR(256) );
أولاً ، انظر إلى قائمة جميع السمات الموجودة. يمكن القيام بذلك في قائمة "Open Data Preview" أو باستخدام استعلام SQL بسيط مثل هذا:
SELECT DISTINCT "ATTRIBUTE" FROM "SAP_PM"."ITSM_HISTORY";
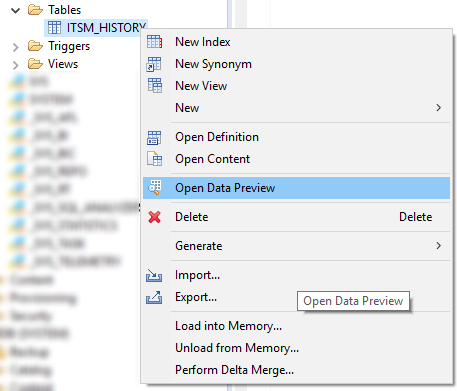 الشكل 11. قائمة السياق باستخدام أمر فتح معاينة البيانات في SAP HANA Studio
الشكل 11. قائمة السياق باستخدام أمر فتح معاينة البيانات في SAP HANA Studioبعد ذلك ، نحدد تركيبة السمات التي يكون التغيير بالنسبة لنا حدثًا في هذه العملية. فيما يلي قائمة بالمرشحين الواضحين لهذه القائمة:
- وضع
- تم نقله إلى العمل
- تم تغيير الفئة
- انتهكت الموعد النهائي
- وقت رد الفعل انتهكت
- تم إرجاع الطلب للمراجعة.
- خطأ في الخط الأول
- مجموعة العمل
- أفضلية
الأحداث الرئيسية هنا ، بالطبع ، هي التحولات بين حالات الاستئناف / الحادث \ application \ task. ستكون قيمة السمة "الحالة" (VALUE_NEW) نفسها هي اسم خطوة العملية بالنسبة لنا. وفقًا لذلك ، قد يبدو إنشاء جدول أحداث كتقريب أول كما يلي:
CREATE COLUMN TABLE "SAP_PM"."ITSM_EVENTS" ( "CASE_ID" NVARCHAR(256) ,"EVENT" NVARCHAR(1024) ,"TS" TIMESTAMP ,"USER" NVARCHAR(256) ,"VALUE_OLD" NVARCHAR(1024) ,"VALUE_NEW" NVARCHAR(1024) ); INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"VALUE_NEW" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' ;
تغيير بقية السمات هو خطواتنا الإضافية التي تجعل البحث في العملية أكثر إثارة للاهتمام. يتم تحديد تكوينها بناءً على طلب محلل أعمال وقد يتغير مع تطور ممارسة تعدين العمليات في الشركة.
INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"ATTRIBUTE" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "VALUE_OLD" IS NOT NULL AND "ATTRIBUTE" IN ( ' ' ,' ' ,' ' ,' ' ,' ' ,' 1- ' ,' ' ,'') );
توسيع قائمة السمات في WHERE "ATTRIBUTE" IN (.....) يمكنك زيادة مجموعة متنوعة من الخطوات التي يتم عرضها على الرسم البياني للعملية. تجدر الإشارة إلى أن مجموعة واسعة من الخطوات ليست دائما نعمة. في بعض الأحيان ، التفاصيل المفصلة للغاية تجعل من الصعب فهم العملية. أعتقد أنه بعد التكرار الأول ، ستحدد الخطوات اللازمة والتي ينبغي استبعادها من نموذج البيانات (وحرية اتخاذ مثل هذه القرارات والتكيف معها بسرعة هي حجة أخرى تؤيد نقل عمل تحويل البيانات إلى جانب فريق تعدين العمليات) .
الفلتر "VALUE_OLD" ليس خاليًا ، على الأرجح ستحل محله شيء أكثر ملاءمة لظروفك وللسمات المحددة. سأحاول شرح معنى هذا المرشح. في بعض التطبيقات الشائعة لأنظمة ITSM ، في وقت تسجيل (فتح) نداء ، يتم إدخال معلومات حول تهيئة جميع سمات الكائن في المجلة. وهذا يعني ، يتم تمييز جميع الحقول مع بعض القيم الافتراضية. في هذه اللحظة ، سيحتوي VALUE_NEW على نفس قيمة التهيئة ، ولن يحتوي VALUE_OLD على أي شيء - بعد كل شيء ، لم يكن هناك سجل حتى هذه اللحظة. نحن بالتأكيد لا نحتاج إلى هذه السجلات في هذه العملية. يجب إزالتها باستخدام مرشح مناسب لظروفك المحددة. قد يكون هذا المرشح:
- "VALUE_OLD" ليست فارغة
- "VALUE_NEW" = 'نعم'
- يمكنك التركيز على الطابع الزمني (تأخذ فقط تلك الأحداث التي وقعت بعد تسجيل الكائن).
- يمكنك التركيز على حقل "USER" إذا كان حساب النظام قيد التهيئة.
- أي شروط أخرى توصلت إليها.
كاليفورنيا الجدول الجيل
سيكون نفس تاريخ التغييرات التي خدمتنا كمصدر للأحداث مفيدًا أيضًا في إنشاء دليل لحالات العمليات (جداول CA). خوارزمية مماثلة:
1. حدد قائمة السمات التي:
أ. لا تتغير أثناء العمل على التطبيق ، على سبيل المثال ، مؤلف الاستئناف وقسمه ، وتقييم المستخدم على أساس نتائج العمل ، وعلم انتهاك الموعد النهائي.
ب. يمكن أن يتغيروا ، لكننا مهتمون فقط بالقيم في نقاط معينة: في وقت التسجيل ، والإغلاق ، عند التعيين ، النقل من السطر الثاني إلى الأول ، إلخ.
ج. يمكن أن تتغير ، لكننا مهتمون فقط بالقيم المجمعة (الحد الأقصى ، الحد الأدنى ، الكمية ، إلخ.)
2. إنشاء جدول قطري مع مجموعة الأعمدة المطلوبة. ستنشئ كل سمة تهمنا مجموعة الصفوف الخاصة بها (وفقًا لعدد مثيلات العملية) ، حيث سيكون لعمود واحد فقط قيمة ، وكل الباقي ستكون فارغة (NULL).
3. ننهار الجدول القطري في الدليل النهائي باستخدام التجميع حسب معرف العملية.
أمثلة على السمات التي من المنطقي وضعها في جدول المرجع المصدق (في الممارسة العملية ، يمكن أن تكون هذه القائمة أطول بكثير):
- خدمة
- نظام تكنولوجيا المعلومات
- المؤلف
- منظمة المؤلف
- تصنيف المستخدم لجودة الحل
- عدد العائدات إلى العمل
- عندما تم نقله إلى العمل
- التي أنشأتها
- الذين أغلقت
- تم حلها بواسطة الخط 1
- التصنيف / التوجيه غير صالح
- الموعد الأخير
- انتهاك الموعد النهائي
يمكن أن تكون السمة نفسها مصدرًا لحدث في عملية أو خاصية لنسخة عملية. على سبيل المثال ، السمة "الأولوية". من ناحية ، نحن مهتمون بأهميته في وقت تسجيل الاستئناف ، ومن ناحية أخرى ، يمكن تقديم كل وقائع التغييرات في هذه السمة إلى الرسم البياني للعملية كخطوات مستقلة.
مثال آخر هو الموعد النهائي. هذه خاصية مرجعية واضحة للعملية ، ولكن يمكنك اتخاذ خطوة افتراضية في الرسم البياني للعملية منها: لا توجد عملية مثل "الموعد النهائي" في العملية ، ولكن إذا أضفنا الإدخال المقابل إلى "جدول الأحداث" ، فسوف ننشئه بشكل مصطنع وسنكون قادرين على تصور الموقع نسبة إلى وقت تنفيذ الخطوات الأخرى مباشرة على الرسم البياني للعملية. هذا مناسب لتحليل سريع.
بشكل عام ، عندما ننشئ خصائص العملية استنادًا إلى محفوظات تغييرات السمات ، يمكن أن يكون مصدر المعلومات المفيدة لنا:
- قيمة السمة نفسها (مثال: "تصنيف المستخدم")
- المستخدم الذي غيره
- تغيير الوقت
- الوقت الذي استغرقت فيه السمة قيمة معينة (على سبيل المثال: السمة "انتهى الموعد النهائي" ليست مهتمة بقيمة السمة نفسها ، ولكن في الوقت الذي تتغير فيه إلى ما يعادل العلامة المرفوعة - على سبيل المثال ، "نعم" أو 1)
- حقيقة أن السمة موجودة في التاريخ (مثال: "حادثة جماعية" مع القيمة "نعم")
هذه القائمة ، بالطبع ، يمكن أن تستمر مع الأفكار الأخرى لاستخدام السمات وكل ما يرتبط بها.
الآن وقد قررنا بالفعل على قائمة الخصائص المثيرة للاهتمام ، دعونا ننظر إلى واحدة من السيناريوهات المحتملة لتوليد جدول CA. أولاً ، قم بإنشاء الجدول نفسه بمجموعة الأعمدة التي حددناها أعلاه لأنفسنا:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES" ( "CASE_ID" NVARCHAR(256) NOT NULL ,"CATEGORY" NVARCHAR(256) DEFAULT NULL ,"AUTHOR" NVARCHAR(256) DEFAULT NULL ,"RESOLVER" NVARCHAR(256) DEFAULT NULL ,"RAITING" INTEGER DEFAULT NULL ,"OPEN_TIME" TIMESTAMP DEFAULT NULL ,"START_TIME" TIMESTAMP DEFAULT NULL ,"DEADLINE" TIMESTAMP DEFAULT NULL );
سنحتاج أيضًا إلى جدول مؤقت "ITSM_CASES_STAGING" ، والذي سيتيح لنا فرز قائمة ثابتة من السمات لأعمدة الخصائص المطلوبة في دليل مثيلات العملية:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES_STAGING" LIKE "SAP_PM"."ITSM_CASES" WITH NO DATA;
سيكون هذا جدولًا قطريًا - في كل صف يوجد حقلان فقط لهما قيمة: "CASE_ID" ، أي معرف العملية ، وحقل واحد مع خاصية العملية. ستكون الحقول المتبقية في الصف فارغة (NULL). في المرحلة الأخيرة ، نقوم بسهولة بتقسيم الأقطار إلى صفوف عن طريق التجميع البسيط وبالتالي الحصول على جدول المراجع المصدقة التي نحتاجها.
مثال لفئة العلاج:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "CATEGORY") SELECT "CASE_ID", LAST_VALUE("VALUE_NEW" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' GROUP BY "CASE_ID" ;
لنفترض أن المؤلف هو أول مستخدم غير نظام في تاريخ الاستئناف يسجل الاستئناف (في الحالة الخاصة بك ، قد يكون المعيار أكثر دقة):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "AUTHOR") SELECT "CASE_ID", FIRST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "USER" != 'SYSTEM' GROUP BY "CASE_ID" ;
إذا اعتبرنا أن المعالج ، الذي وضع الحالة الأخيرة "الحل المقترح" (ويمكن تقديم الحل بشكل متكرر ، ولكن تم حل المشكلة الأخيرة فقط) ، حل المشكلة بنجاح ، ثم يمكن صياغة خاصية مثيل العملية على النحو التالي:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RESOLVER") SELECT "CASE_ID", LAST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' AND "VALUE_NEW" = ' ' GROUP BY "CASE_ID" ;
تقييم المستخدم (رضاه عن القرار):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RAITING") SELECT "CASE_ID", TO_INTEGER(LAST_VALUE("VALUE_NEW" ORDER BY "TS")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND "VALUE_NEW" IS NOT NULL GROUP BY "CASE_ID" ;
وقت التسجيل (الإنشاء) هو ببساطة السجل الأقدم في تاريخ التداول:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "OPEN_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" GROUP BY "CASE_ID" ;
وقت رد الفعل هو سمة مهمة لجودة الخدمات. لحسابها ، تحتاج إلى معرفة متى تم رفع العلم "تم نقله إلى العمل" لأول مرة:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "START_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' = '' GROUP BY "CASE_ID" ;
يتم استخدام الموعد النهائي لحساب مؤشرات الأداء الرئيسية للردود في الوقت المناسب على الطعون أو حل الحوادث. في هذه العملية ، قد يتغير الموعد النهائي بشكل متكرر. لحساب مؤشرات الأداء الرئيسية ، نحتاج إلى معرفة أحدث إصدار من هذه السمة. إذا كنا نريد تتبع صراحة كيف تغير الموعد النهائي ، أي لعرض مثل هذه الحالات على الرسم البياني للعملية ، يجب علينا أيضًا استخدام هذه السمة لإنشاء إدخال في جدول الأحداث. هذا مثال على سمة ، والتي تعمل في وقت واحد كخاصية للعملية ومصدر للحدث.
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "DEADLINE") SELECT "CASE_ID", MAX(TO_DATE("VALUE_NEW")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' IS NOT NULL GROUP BY "CASE_ID" ;
جميع الأمثلة المذكورة أعلاه هي من نفس النوع. عن طريق القياس معهم ، يمكن توسيع جدول CA بأية سمات تهمك. علاوة على ذلك ، يمكن القيام بذلك بالفعل بعد بدء المشروع ، حيث يسمح لك النظام بتوسيع نموذج البيانات أثناء تشغيله.
عندما يتم ملء جدولنا القطري المؤقت بخصائص حالات العملية ، كل ما تبقى هو القيام بالتجميع والحصول على جدول المرجع المصدق النهائي:
INSERT INTO "SAP_PM"."ITSM_CASES" SELECT "CASE_ID" ,MAX("CATEGORY") ,MAX("AUTHOR") ,MAX("RESOLVER") ,MAX("RAITING") ,MAX("OPEN_TIME") ,MAX("START_TIME") ,MAX("DEADLINE") FROM "SAP_PM"."ITSM_CASES_STAGING" GROUP BY "CASE_ID" ;
بعد ذلك ، لم نعد بحاجة إلى البيانات في الجدول المؤقت. يمكن ترك الجدول نفسه لمواصلة تكرار العملية المذكورة أعلاه بشكل منتظم لتحديث نموذج البيانات في عملية التعدين:
DELETE FROM "SAP_PM"."ITSM_CASES_STAGING";
نصائح لإعداد وتنظيف ملفات CSV لمشروع تجريبي
من المحتمل أن تبدأ معرفتك بمعالجة عملية الانضباط بمشروع رائد. في هذه الحالة ، لا يمكن الحصول على الوصول المباشر إلى مصدر البيانات ؛ سيقاوم كل من موظفي تكنولوجيا المعلومات وضباط أمن المعلومات هذا. هذا يعني أنه كجزء من المشروع التجريبي ، سيتعين علينا العمل مع تصدير البيانات من أنظمة الشركات إلى ملفات CSV ثم استيرادها إلى SAP HANA لإنشاء نموذج بيانات.
في المنشآت الصناعية ، لن يكون هناك أي تصدير إلى CSV. بدلاً من ذلك ، سيتم استخدام أدوات تكامل SAP HANA ، على وجه الخصوص: تكامل البيانات الذكية (SDI) أو الوصول الذكي إلى البيانات (SDA) أو خادم SAP Landscape Transformation Replication (SLT). ولكن بالنسبة للاختبار والتعرف على التكنولوجيا ، فإن التصدير إلى ملفات CSV النصية هو أسلوب أبسط من الناحية التنظيمية. لذلك ، سيكون من المفيد مشاركة بعض النصائح معك لإعداد البيانات في ملف CSV للاستيراد السريع والناجح في قاعدة البيانات.
متطلبات التنسيق الموصى بها للملف نفسه عند التصدير:
- تنسيق الملف: CSV
- الترميز: UTF8
- فاصل الحقل: أي حرف مناسب لك. على سبيل المثال ، "|" أو "^" أو "~". منطق الاختيار بسيط - يجب أن نحاول تجنب الموقف عندما يتم تضمين "الانقسام" في البيانات نفسها.
- من الضروري إزالة الفاصل من قيم الحقل. نعم ، قد تقول ذلك لهذا ، في الواقع ، هناك علامات اقتباس. ولكن ، كما تظهر التجربة ، مع اقتباسات ، تنشأ الكثير من المشاكل. بشكل عام ، دعنا فقط نزيل (أو نستبدل) حرف الفاصل من قيم الحقل. لن يعاني مشروعك التجريبي كثيرًا من عدم الدقة هذا ، ولكن يتم حفظ وقت إعداد البيانات بشكل ملحوظ.
- علامات الاقتباس: قم بإزالة جميع علامات الاقتباس من قيمة الحقل. غالبًا ما توجد علامات الاقتباس في أسماء الشركات - على سبيل المثال ، Kalinka LLC. ولكن هناك مثل هذه الخيارات: MPZ Kalinka LLC. والآن هذه هي صعوبة كبيرة. يجب أن تكون علامات الاقتباس في قيم الحقل إما مصحوبة برمز "\" أو إزالتها أو استبدالها بشيء آخر. من الأكثر موثوقية ببساطة إزالته. قيمة الحقل لن تعاني كثيرًا من هذا.
- عمليات النقل: قم بإزالة كل الأحرف CHAR (10) و CHAR (13) من قيم الحقول. خلاف ذلك ، سيكون الاستيراد من CSV مستحيلًا.
إذا أخذنا في الاعتبار النقاط (4) + (5) + (6) ، فمن المنطقي استخدام الإنشاء التالي في التحديد:
REPLACE(REPLACE(REPLACE(REPLACE("COLUMN", '|', ';'), '"', ''), CHAR(13), ' '), CHAR(10), ' ') as "COLUMN"
علاوة على ذلك ، عندما تكون ملفات CSV جاهزة ، ستحتاج إلى نسخها إلى خادم HANA في مجلد يُعتبر آمنًا لاستيراد الملفات (على سبيل المثال ، / usr / sap / HDB / import). يعد استيراد البيانات إلى HANA من ملف CSV محلي إجراءً سريعًا إلى حد ما ، بشرط أن يكون الملف "نظيفًا":
- كل صف من جدول المستقبل موجود في سطر واحد فقط من الملف ؛
- عدد الأعمدة في جميع الصفوف هو نفسه ؛
- علامات الاقتباس إما أن تكون مقترنة أو مفقودة على الإطلاق ؛
- علامات الاقتباس في قيم الحقل إما مرافقة "الهروب" -symbol "\" أو غائبة تمامًا ؛
- ترميز UTF-8 (وليس UTF8-BOM ، كما يحدث عند التصدير إلى أنظمة Windows).
للتحقق من ملفات CSV قبل استيرادها والعثور على المناطق التي توجد بها مشكلات إذا كانت موجودة (مع وجود احتمال بنسبة 99٪ أنها سوف) ، يمكنك استخدام الأوامر التالية:
1. تحقق من حرف BOM في بداية الملف:
ملف البيانات. csv
إذا كانت نتيجة الأمر هكذا: "نص UTF-8 Unicode (مع BOM)" ، فهذا يعني أن الترميز هو UTF8-BOM وتحتاج إلى إزالة حرف BOM من الملف. يمكنك إزالته كما يلي:
sed -i '1s / ^ \ xEF \ xBB \ xBF //' data.csv
2. يجب أن يكون عدد الأعمدة هو نفسه لكل سطر من الملف:
القط البيانات. csv
| awk -F »؛" '{print NF}' | sort | uniqأو مثل هذا:
ل i in $ (ls * .csv) ؛ هل صدى $ i ؛ القط $ ط | awk -F '؛' '{print NF}' | فرز | uniq -c ؛ صدى. فعلت.التغيير "؛" في المعلمة F إلى ما هو فاصل الحقل في قضيتك.
نتيجة لهذه الأوامر ، تحصل على توزيع الصفوف بعدد الأعمدة في كل صف. من الناحية المثالية ، يجب أن تحصل على شيء مثل هذا:
EKKO.csv
79536 200
هنا يحتوي الملف على 79536 سطرًا ، وكلها تحتوي على 200 عمود. لا توجد صفوف تحتوي على عدد مختلف من الأعمدة. يجب أن يكون كذلك.
وهنا مثال على نتيجة غير صحيحة:
LFA1.csv
73636 180
7 181
نرى هنا أن معظم الصفوف تحتوي على 180 عمودًا (وربما يكون هذا هو عدد الأعمدة الصحيحة) ، ولكن هناك صفوف تحتوي على العمود 181. أي أن أحد الحقول يحتوي على علامة فاصل في قيمتها. كنا محظوظين ، وهناك 7 قطع فقط من هذه الخطوط - يمكن مشاهدتها بسهولة يدويًا وتصحيحها بطريقة أو بأخرى. يمكنك رؤية الأسطر التي لا يكون عدد الأعمدة فيها 180 ، مثل هذا:
القط البيانات. csv
| awk -F "؛" '{if (NF! = 180) {print $ 0}}'ملاحظة حول استخدام الأوامر أعلاه. لن تهتم هذه الأوامر بعلامات الاقتباس. إذا كانت علامة الفاصل موجودة في الحقل المحاط بعلامات اقتباس (وهذا يعني أن كل شيء على ما يرام هنا من وجهة نظر الاستيراد في قاعدة البيانات) ، فإن التحقق باستخدام هذه الطريقة سيظهر مشكلة خاطئة (أعمدة إضافية) - يجب أيضًا أخذ ذلك في الاعتبار عند تحليل النتائج.
3. إذا كانت علامات الاقتباس غير صالحة ولم تتمكن من حل هذه المشكلة ، فيمكنك حذف جميع علامات الاقتباس من الملف:
sed -i 's / "// g' data.csv
يتمثل خطر هذا الأسلوب في أنه إذا كانت قيم الحقل تحتوي على حرف فاصل ، فسيتم تغيير عدد الأعمدة في الصف. لذلك ، يجب إزالة الأحرف الفاصلة من قيم الحقول في مرحلة التصدير (حذف أو استبدال بعض الأحرف الأخرى).
4. الحقول الفارغة
في مواجهة موقف تم فيه منع استيراد البيانات بنجاح بواسطة قيم الحقول الفارغة في هذا النموذج:
؛ ""
أين "؛" هي علامة فاصل الحقل في هذه الحالة. بمعنى ، يكون الحقل علامتي اقتباس مزدوجتين (سلسلة فارغة فارغة). إذا لم تتمكن فجأة من استيراد البيانات ، وكنت تشك في أن المشكلة قد تكون حقولًا فارغة ، فحاول استبدال "" بـ NULL
sed -i 's /؛ "" / / NULL / g' data.csv
(استبدل "؛" لخيار الفاصل الخاص بك)
5. قد يكون من المفيد البحث عن تنسيقات الأرقام "القذرة" في البيانات:
؛ "0" (الرقم يحتوي على مسافة)
؛ "100.10-" (علامة "-" بعد الرقم)
يتم الإشارة إلى
رافعة Bugatti 3/4 "300 - البعد بوصة بعلامة اقتباس مزدوجة - وهذا يؤدي تلقائيًا إلى مشكلة علامات اقتباس غير محددة عند التصدير.
لسوء الحظ ، هذه ليست قائمة شاملة بالمشكلات المحتملة في تنسيقات البيانات غير الملائمة للاستيراد إلى قاعدة البيانات. سيكون من الرائع أن تعرف خياراتك من الممارسة: ما هي الأخطاء الغريبة التي صادفتك؟ كيف قمت بالكشف عنها والقضاء عليها. شارك في التعليقات.
استنتاج
بشكل عام ، يعد نموذج البيانات الخاص بـ Process Mining بسيطًا جدًا: جدول أحداث زائد ، اختياريًا ، مراجع إضافية. لكن كما يحدث عادةً ، لا يبدو الأمر بسيطًا إلا عند اكتمال دورة واحدة كاملة من المهام على الأقل - عندئذٍ تكون العملية بأكملها مرئية بالكامل ، وتكون خطة العمل واضحة. آمل أن يساعدك هذا المقال في معرفة كيفية تحضير بيانات مشروع تعدين العمليات الأول. بشكل عام ، تبدو عملية الإعداد كالتالي:
- طلب محفوظات التغيير من مالك البيانات
- فحص وتنزيل التحميل (إعداد ملفات CSV)
- استيراد إلى SAP HANA
- بناء الجدول الحدث
- بناء جدول المرجع المصدق (مرجع العملية)
وفي الواقع ، هذا هو المكان الذي يبدأ فيه إعداد نموذج البيانات ويبدأ الجزء الأكثر إثارة للاهتمام - عملية التعدين. إذا كانت لديك أي أسئلة أثناء تنفيذ مشروع Process Mining ، فلا تتردد في الكتابة في التعليقات ، وسأكون سعيدًا بالمساعدة. حظا سعيدا
فيدور بافلوف ، خبير منصات SAP CIS