مرحبا بالجميع. نشارك ترجمة الجزء الأخير من المقال ، الذي تم إعداده خاصة لطلاب دورة
مهندس البيانات . الجزء الأول يمكن العثور عليه
هنا .
Apache Beam و DataFlow لأنابيب الوقت الفعلي
جوجل سحابة الإعداد
ملاحظة: استخدمت Google Cloud Shell لبدء تشغيل خط الأنابيب ونشر بيانات سجل المستخدم ، لأنني واجهت مشاكل في تشغيل خط الأنابيب في Python 3. يستخدم Google Cloud Shell Python 2 ، والذي يتوافق بشكل أفضل مع Apache Beam.
لبدء الناقل ، نحتاج إلى الخوض قليلاً في الإعدادات. بالنسبة لأولئك الذين لم يستخدموا برنامج "شركاء Google المعتمدون" من قبل ، يجب عليك إكمال الخطوات الست التالية في هذه
الصفحة .
بعد ذلك ، سنحتاج إلى تحميل البرامج النصية الخاصة بنا إلى Google Cloud Storage ونسخها إلى Google Cloud Shel. يعتبر التحميل إلى التخزين السحابي أمرًا بسيطًا للغاية (يمكن العثور على وصف
هنا ). لنسخ ملفاتنا ، يمكننا فتح Google Cloud Shel من شريط الأدوات بالنقر فوق الرمز الأول على اليسار في الشكل 2 أدناه.
 الشكل 2
الشكل 2الأوامر التي نحتاجها لنسخ الملفات وتثبيت المكتبات اللازمة مدرجة أدناه.
إنشاء قاعدة البيانات والجدول
بعد الانتهاء من جميع خطوات التكوين ، فإن الشيء التالي الذي يتعين علينا القيام به هو إنشاء مجموعة بيانات وجدول في BigQuery. هناك عدة طرق للقيام بذلك ، ولكن أسهلها هو استخدام وحدة التحكم في Google Cloud عن طريق إنشاء مجموعة بيانات أولاً. يمكنك اتباع الخطوات الموجودة في
الرابط التالي لإنشاء جدول به مخطط. سيكون لدينا جدول
7 أعمدة المقابلة لمكونات كل سجل المستخدم. للراحة ، سنقوم بتعريف جميع الأعمدة على شكل سلاسل (سلسلة حروف) ، باستثناء المتغير الزمني ، وتسميتها وفقًا للمتغيرات التي أنشأناها سابقًا. يجب أن يبدو تخطيط طاولتنا بالشكل 3.
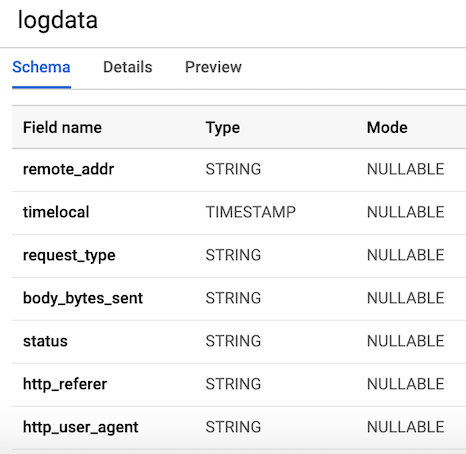 الشكل 3. تخطيط الجدول
الشكل 3. تخطيط الجدولنشر بيانات سجل المستخدم
يعد Pub / Sub مكونًا مهمًا لخط أنابيبنا لأنه يسمح للعديد من التطبيقات المستقلة بالتفاعل مع بعضها البعض. على وجه الخصوص ، يعمل كوسيط يسمح لنا بإرسال واستقبال الرسائل بين التطبيقات. أول شيء يتعين علينا القيام به هو إنشاء موضوع. اذهبوا إلى Pub / Sub في وحدة التحكم واضغط CREATE TOPIC.
يستدعي الرمز أدناه النص البرمجي الخاص بنا لإنشاء بيانات السجل المحددة أعلاه ، ثم يقوم بتوصيل السجلات وإرسالها إلى Pub / Sub. الشيء الوحيد الذي يتعين علينا القيام به هو إنشاء كائن
PublisherClient ، وتحديد المسار للموضوع باستخدام طريقة
topic_path واستدعاء وظيفة
publish مع
topic_path والبيانات. يرجى ملاحظة أننا نستورد
stream_logs البرنامج النصي
stream_logs بنا ، لذا تأكد من أن هذه الملفات موجودة في نفس المجلد ، وإلا فسوف تحصل على خطأ في الاستيراد. ثم يمكننا تشغيل هذا من خلال وحدة التحكم في google باستخدام:
python publish.py
from stream_logs import generate_log_line import logging from google.cloud import pubsub_v1 import random import time PROJECT_ID="user-logs-237110" TOPIC = "userlogs" publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path(PROJECT_ID, TOPIC) def publish(publisher, topic, message): data = message.encode('utf-8') return publisher.publish(topic_path, data = data) def callback(message_future):
بمجرد بدء تشغيل الملف ، يمكننا ملاحظة إخراج بيانات السجل إلى وحدة التحكم ، كما هو موضح في الشكل أدناه. سيعمل هذا البرنامج النصي حتى نستخدم
CTRL + C لإكماله.
 الشكل 4. إخراج
الشكل 4. إخراج publish_logs.py
رمز الكتابة لخط أنابيب لدينا
الآن وقد أعددنا كل شيء ، يمكننا المضي قدمًا إلى الجزء الأكثر إثارة للاهتمام - كتابة رمز خط أنابيبنا باستخدام Beam و Python. لإنشاء خط أنابيب Beam ، نحتاج إلى إنشاء كائن خط أنابيب (p). بعد قيامنا بإنشاء كائن خط أنابيب ، يمكننا تطبيق العديد من الوظائف واحدة تلو الأخرى باستخدام عامل
pipe (|) . بشكل عام ، يشبه سير العمل الصورة أدناه.
[Final Output PCollection] = ([Initial Input PCollection] | [First Transform] | [Second Transform] | [Third Transform])
في الكود الخاص بنا ، سننشئ وظيفتين يحددهما المستخدم. دالة
regex_clean ، التي تقوم بمسح البيانات واسترداد الصف المقابل بناءً على قائمة PATTERNS باستخدام وظيفة
re.search . ترجع الدالة سلسلة مفصولة بفواصل. إذا لم تكن خبير تعبير عادي ، فنوصيك بقراءة هذا
البرنامج التعليمي والممارسة في المفكرة للتحقق من الكود. بعد ذلك ، نقوم بتعريف وظيفة ParDo مخصصة تسمى
Split ، وهي عبارة عن صيغة تحويل Beam للمعالجة المتوازية. في Python ، يتم ذلك بطريقة خاصة - يجب علينا إنشاء فئة ترث من فئة DoFn Beam. تأخذ وظيفة Split سلسلة موزعة من الوظيفة السابقة وتقوم بإرجاع قائمة من القواميس مع مفاتيح مقابلة لأسماء الأعمدة في جدول BigQuery. هناك شيء جدير بالملاحظة حول هذه الوظيفة: اضطررت إلى استيراد
datetime داخل الوظيفة لجعلها تعمل. تلقيت خطأ في الاستيراد في بداية الملف ، والذي كان غريباً. ثم يتم تمرير هذه القائمة إلى وظيفة
WriteToBigQuery ، والتي ببساطة تضيف بياناتنا إلى الجدول. يظهر رمز الوظيفة Batch DataFlow Job و Streaming DataFlow Job أدناه. الفرق الوحيد بين الدُفعة والدفق هو أنه في معالجة الدُفعات ، نقرأ CSV من
src_path باستخدام الدالة
ReadFromText من Beam.
دفعة DataFlow المهمة (معالجة الحزمة)
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import bigquery import re import logging import sys PROJECT='user-logs-237110' schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' src_path = "user_log_fileC.txt" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'status': element[3], 'body_bytes_sent': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(): p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.textio.ReadFromText(src_path) | "clean address" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) p.run() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
تدفق DataFlow الوظيفة
from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import pubsub_v1 from google.cloud import bigquery import apache_beam as beam import logging import argparse import sys import re PROJECT="user-logs-237110" schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' TOPIC = "projects/user-logs-237110/topics/userlogs" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'body_bytes_sent': element[3], 'status': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(argv=None): parser = argparse.ArgumentParser() parser.add_argument("--input_topic") parser.add_argument("--output") known_args = parser.parse_known_args(argv) p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.ReadFromPubSub(topic=TOPIC).with_output_types(bytes) | "Decode" >> beam.Map(lambda x: x.decode('utf-8')) | "Clean Data" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) result = p.run() result.wait_until_finish() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
بداية الناقل
يمكننا بدء تشغيل خط الأنابيب بعدة طرق مختلفة. إذا أردنا ذلك ، فبإمكاننا تشغيله محليًا من المحطة الطرفية ، من خلال تسجيل الدخول عن بُعد إلى GCP.
python -m main_pipeline_stream.py \ --input_topic "projects/user-logs-237110/topics/userlogs" \ --streaming
ومع ذلك ، سنقوم بإطلاقها باستخدام DataFlow. يمكننا القيام بذلك باستخدام الأمر أدناه عن طريق تعيين المعلمات المطلوبة التالية.
project - معرف مشروع GCP الخاص بك.runner هو runner خط أنابيب من شأنه أن يحلل البرنامج الخاص بك وبناء خط أنابيب الخاص بك. لتشغيل في السحابة ، يجب عليك تحديد DataflowRunner.staging_location - المسار إلى تخزين سحابة سحابة staging_location لفهرسة حزم الأكواد التي يحتاجها معالجات العملية.temp_location - المسار إلى تخزين سحابة Cloud Dataflow لاستضافة ملفات المهام المؤقتة التي تم إنشاؤها أثناء تشغيل خط الأنابيب.streaming
python main_pipeline_stream.py \ --runner DataFlow \ --project $PROJECT \ --temp_location $BUCKET/tmp \ --staging_location $BUCKET/staging --streaming
أثناء تشغيل هذا الأمر ، يمكننا الانتقال إلى علامة تبويب DataFlow في وحدة التحكم في google وعرض خط أنابيبنا. بالضغط على خط الأنابيب ، يجب أن نرى شيئًا مشابهًا للشكل 4. لأغراض التصحيح ، قد يكون من المفيد جدًا الانتقال إلى السجلات ثم إلى Stackdriver لعرض السجلات التفصيلية. هذا ساعدني في حل مشاكل خط الأنابيب في عدد من الحالات.
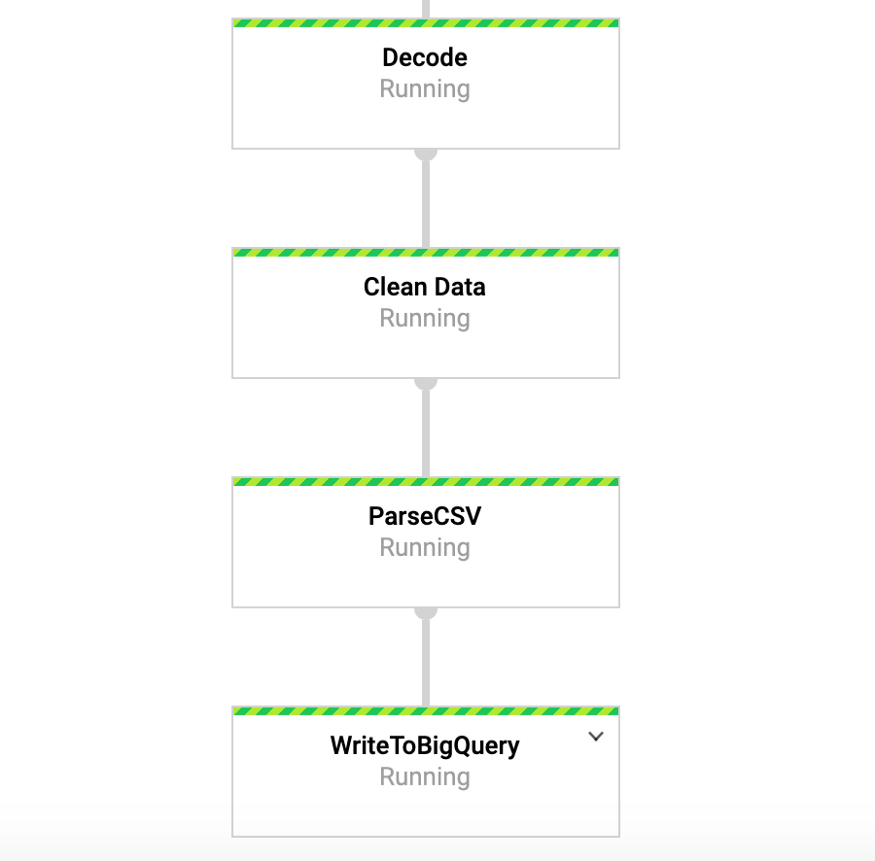 الشكل 4: ناقل الحزم
الشكل 4: ناقل الحزمالوصول إلى البيانات الخاصة بنا في BigQuery
لذلك ، يجب أن نكون قد بدأنا بالفعل خط الأنابيب مع إدخال البيانات في جدولنا. لاختبار هذا ، يمكننا الانتقال إلى BigQuery وعرض البيانات. بعد استخدام الأمر أدناه ، سترى الصفوف القليلة الأولى من مجموعة البيانات. الآن وقد أصبح لدينا البيانات المخزنة في BigQuery ، يمكننا إجراء مزيد من التحليل ، وكذلك مشاركة البيانات مع الزملاء والبدء في الإجابة على أسئلة العمل.
SELECT * FROM `user-logs-237110.userlogs.logdata` LIMIT 10;
 الشكل 5: BigQuery
الشكل 5: BigQueryاستنتاج
نأمل أن يكون هذا المنشور مثالًا مفيدًا لإنشاء خط أنابيب تدفق البيانات ، بالإضافة إلى إيجاد طرق لجعل البيانات أكثر سهولة. تخزين البيانات في هذا التنسيق يعطينا العديد من المزايا. الآن يمكننا أن نبدأ في الإجابة على الأسئلة المهمة ، على سبيل المثال ، كم من الناس يستخدمون منتجاتنا؟ هل تنمو قاعدة المستخدمين بمرور الوقت؟ ما هي جوانب المنتج التي يتفاعل الناس معها أكثر من غيرها؟ وهل هناك أي أخطاء لا ينبغي أن تكون فيها؟ هذه هي القضايا التي ستكون ذات أهمية للمنظمة. بناءً على الأفكار الناشئة عن الإجابات على هذه الأسئلة ، سنكون قادرين على تحسين المنتج وزيادة اهتمام المستخدم.
Beam مفيد حقًا لهذا النوع من التمارين ، كما أنه يحتوي على عدد من حالات الاستخدام الأخرى المثيرة للاهتمام. على سبيل المثال ، يمكنك تحليل البيانات المتعلقة بتبادل التبادل في الوقت الحقيقي وإجراء المعاملات بناءً على التحليل ، وربما لديك بيانات الاستشعار الواردة من المركبات ، وتريد حساب حساب مستوى حركة المرور. يمكنك أيضًا ، على سبيل المثال ، أن تكون شركة ألعاب تجمع بيانات المستخدم وتستخدمها لإنشاء لوحات معلومات لتتبع مقاييس المفاتيح. حسنًا ، أيها السادة ، هذا الموضوع مخصص بالفعل لوظيفة أخرى ، وذلك بفضل القراءة ، وبالنسبة لأولئك الذين يرغبون في الاطلاع على الكود الكامل ، يوجد أدناه رابط لـ GitHub الخاص بي.
https://github.com/DFoly/User_log_pipeline
هذا كل شيء.
اقرأ الجزء الأول .