يبدأ تحليل النص دائمًا بالتحليل المعجمي أو الرمز المميز. هناك طريقة سهلة لحل هذه المشكلة لأي لغة تقريبًا باستخدام التعبيرات العادية. استخدام آخر للارتداد القديم جيدة.
كثيرا ما أواجه مهمة تحليل النصوص. بالنسبة للمهام البسيطة ، مثل تحليل القيمة التي يدخلها المستخدم ، تكون وظيفة التعبير العادية الأساسية كافية. بالنسبة للمهام المعقدة والثقيلة مثل كتابة برنامج التحويل البرمجي أو تحليل الشفرة الثابتة ، يمكنك استخدام أدوات متخصصة (AntLR و JavaCC و Yacc). لكنني غالبًا ما أواجه مهام على مستوى متوسط ، عندما لا يكون هناك تعبيرات منتظمة كافية ، لكنني لا أريد سحب أدوات ثقيلة في المشروع. بالإضافة إلى ذلك ، تعمل هذه الأدوات عادةً في مرحلة الترجمة ، وفي وقت التشغيل لا تسمح بتغيير معلمات التحليل (على سبيل المثال ، تشكيل قائمة بالكلمات الأساسية من ملف أو جدول قاعدة بيانات).
كمثال ، سأعطي مهمة نشأت أثناء عملية تسريع استعلامات SQL . قمنا بتحليل سجلات استعلامات SQL الخاصة بنا وأردنا العثور على استعلامات "سيئة" وفقًا لقواعد معينة. على سبيل المثال ، استعلامات يتم فيها التحقق من نفس الحقل لمجموعة من القيم باستخدام OR
name = 'John' OR name = 'Michael' OR name = 'Bob'
أردنا استبدال هذه الطلبات بـ
name IN ('John', 'Michael', 'Bob')
لم تعد التعبيرات العادية قادرة على التعامل ، لكنني أيضًا لم أرغب في إنشاء محلل SQL كامل باستخدام AntLR. سيكون من الممكن تقسيم نص الطلب إلى رموز واستخدام رمز بسيط لإجراء التحليل بدون أي أدوات متخصصة.
يمكن حل هذه المشكلة باستخدام الوظيفة الأساسية للتعبيرات العادية. دعنا نحاول تقسيم استعلام SQL إلى رموز. سننظر إلى إصدار مبسط من SQL حتى لا يتم تحميل النص بالتفاصيل. لإنشاء معجم SQL كامل ، سيكون عليك كتابة تعبيرات عادية أكثر تعقيدًا بقليل.
فيما يلي مجموعة من التعبيرات لرموز لغة SQL الأساسية:
1. keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b 2. id : [A-Za-z][A-Za-z0-9]* 3. real_number : [0-9]+\.[0-9]* 4. number : [0-9]+ 5. string : '[^']*' 6. space : \s+ 7. comment : \-\-[^\n\r]* 8. operation : [+\-\*/.=\(\)]
أريد الانتباه إلى التعبير العادي للكلمة الرئيسية
keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b
لديها اثنين من الميزات.
- يتم استخدام عامل التشغيل \ b في البداية وفي النهاية ، على سبيل المثال ، حتى لا يتم قطع أو بادئة مؤسسة الكلمة ، وهي كلمة رئيسية والتي ستنفصل عنها بعض محركات regex في رمز مميز دون استخدام عامل التشغيل \ b.
- يتم تجميع كل الكلمات بواسطة أقواس غير جذابة (؟ :) لا تلتقط المطابقة. سيتم استخدام هذا في المستقبل حتى لا ينتهك فهرسة التعبيرات الجزئية المنتظمة في التعبير العام.
يمكنك الآن دمج كل هذه التعبيرات في مجموعة واحدة ، باستخدام التجميع والمشغل |
(\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b)|([A-Za-z][A-Za-z0-9]*)|([0-9]+\.[0-9]*)|([0-9]+)|('[^']*')|(\s+)|(\-\-[^\n\r]*)|([+\-\*/.=\(\)])
الآن يمكنك محاولة تطبيق هذا التعبير على تعبير SQL ، على سبيل المثال على هذا النحو
SELECT count(id)
هنا هي النتيجة على ريجكس تستر. من خلال النقر على الرابط ، يمكنك اللعب بالتعبير ونتائج التحليل. يمكن ملاحظة أن SELECT ، على سبيل المثال ، يتوافق مباشرة مع مجموعة واحدة ، والتي تتوافق مع نوع الكلمة الرئيسية .
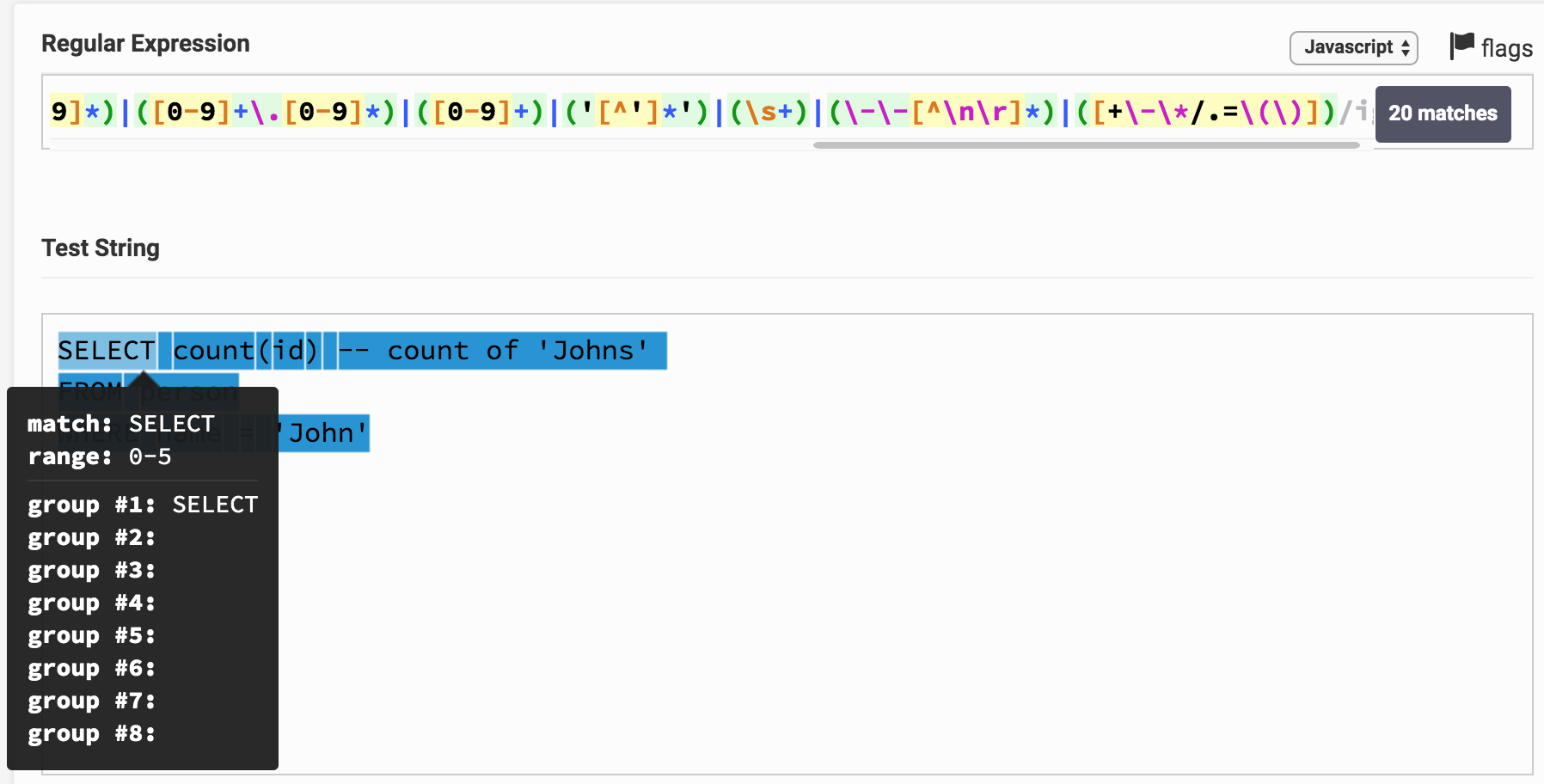
قد تلاحظ أن النص الكامل للطلب تبين أنه مقسم إلى سلاسل فرعية وكل منها يتوافق مع مجموعة معينة. حسب رقم المجموعة ، يمكنك ربطه بنوع الرمز المميز (الرمز المميز).
إن جعل الخوارزمية المحددة في برنامج بأي لغة برمجة تدعم التعبيرات المعتادة ليست صعبة. هنا فئة صغيرة تنفذ هذا في جافا.
RegexTokenizer.java (+ فصلان دراسيان) package org.example; import java.util.ArrayList; import java.util.Enumeration; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.stream.Collectors; public class RegexTokenizer implements Enumeration<Token> {
في هذه الفئة ، يتم تطبيق الخوارزمية باستخدام مجموعات مسماة ، غير موجودة في جميع المحركات. تتيح لك هذه الميزة الوصول إلى المجموعات ليس بالفهرس ، ولكن بالاسم ، وهو أكثر ملاءمة قليلاً من الوصول إلى الفهرس.
في I7 2.3 جيجا هرتز ، يوضح هذا الفصل سرعة تحليل تتراوح بين 5-20 ميجابايت في الثانية (اعتمادًا على تعقيد التعبيرات). يمكن موازاة الخوارزمية عن طريق تحليل العديد من الملفات في وقت واحد ، مما يزيد من سرعة العمل الإجمالية.
لقد وجدت العديد من الخوارزميات المتشابهة على الشبكة ، لكنني صادفت خيارات لا تشكل تعبيرًا عاديًا شائعًا ، ولكن باستمرار استخدم التعبيرات المعتادة لكل نوع من الرمز المميز في بداية السطر ، ثم تجاهل الرمز المميز الذي تم العثور عليه من بداية السطر وحاول مرة أخرى تطبيق جميع regexps. هذا يعمل حوالي 10-20 مرة أبطأ ، يتطلب المزيد من الذاكرة والخوارزمية أكثر تعقيدًا. لقد حققت سرعة أكبر في العمل فقط باستخدام تطبيق التعبير المنتظم الخاص بي استنادًا إلى DFA (آلة الحالة المحدودة الحتمية ). في محركات regex ، عادةً ما يتم استخدام NKA - وهو جهاز حالة محدود غير محدد. تعد DFA أسرع مرتين إلى ثلاث مرات ، لكن التعبيرات المعتادة لأنها أكثر صعوبة في الكتابة بسبب مجموعة محدودة من المشغلين.
في مثال SQL الخاص بي ، قمت بتبسيط التعبيرات العادية قليلاً ولا يمكن اعتبار الرمز المميز الناتج محللًا لغويًا كاملًا لاستعلامات SQL ، لكن الغرض من المقالة هو إظهار المبدأ ، وليس إنشاء رمز مميز SQL حقيقي. لقد استخدمت هذا النهج في ممارستي وقمت بإنشاء أجهزة تحليل معجمية كاملة لـ SQL و Java و C و XML و HTML و JSON و Pascal وحتى COBOL (اضطررت إلى العبث بها).
فيما يلي بعض القواعد البسيطة لكتابة التعبيرات العادية للتحليل المعجمي.
- إذا كان يمكن تعيين الرمز المميز نفسه لأنواع مختلفة (على سبيل المثال ، يمكن التعرف على أي كلمة رئيسية كمعرّف) ، فيجب تحديد نوع أضيق في البداية. ثم سيتم تطبيق التعبير العادي له أولاً وسيحدد نوع الرمز المميز. على سبيل المثال ، في المثال الخاص بي ، يتم تحديد الكلمات الرئيسية قبل المعرّف وسيتم التعرف على الرمز المميز ككلمة رئيسية ، وليس كمعرّف
- حدد الرموز الأطول أولاً ، ثم أقصرها. على سبيل المثال ، تحتاج أولاً إلى تحديد <= ، > = ومن ثم منفصلة > ، < ، = في هذه الحالة ، سيتم التعرف على النص <= بشكل صحيح كرمز مميز واحد للمشغل الأقل من أو المتساوي ، وليس رمزان منفصلان < و =
- تعلم كيفية استخدام lookahead و lookbehind . على سبيل المثال ، الحرف * في SQL له معنى عامل الضرب وإشارة إلى جميع الحقول في جدول. باستخدام طريقة بحث بسيطة ، يمكنك فصل هاتين الحالتين ، على سبيل المثال ، هنا يعيد regexp (؟ <=. \ S | select \ s ) * العثور على الحرف * فقط في القيمة "جميع حقول الجدول".
- من المفيد في بعض الأحيان تحديد التعبيرات المعتادة للأخطاء التي تحدث في النص. على سبيل المثال ، إذا قمت بتمييز بناء الجملة ، فيمكنك تحديد نوع الرمز المميز للسلسلة غير المكتملة على أنه
'[^\n\r]* . في عملية تحرير النص ، قد لا يكون لدى المستخدم وقت لإغلاق علامة الاقتباس في السلسلة ، لكن الرمز المميز الخاص بك سيكون قادرًا على التعرف على هذا الموقف بشكل صحيح وتسليط الضوء عليه بشكل صحيح.
باستخدام هذه القواعد وتطبيق هذه الخوارزمية ، يمكنك تقسيم النص بسرعة إلى رموز لأي لغة تقريبًا.