
شبكة الويب العالمية هي مجموعة من البيانات. هنا يمكنك رؤية أي معلومات تقريبًا تهمك. ومع ذلك ، فإن "سحب" هذه المعلومات من الإنترنت أصعب بالفعل. هناك عدة طرق للحصول على البيانات وإلغاء البيانات على شبكة الإنترنت هي واحدة منها.
ما هو تجريف الويب؟ باختصار ، إنها تقنية تتيح لك إمكانية استرداد البيانات من صفحات HTML. عند استخدام الكشط ، ليست هناك حاجة لنسخ المعلومات الضرورية أو نقلها من الشاشة إلى المفكرة. سوف تظهر المعلومات على جهاز الكمبيوتر الخاص بك في شكل مناسب لك.
تجريد الويب على سبيل المثال لموقع Kinopoisk.ru
إنها لفكرة جيدة أن تضع لنفسك هدفًا حتى لا تقوم بالخدش للتخلص. قررت أن تكون هذه مقارنة لتصنيفات الأفلام على Kinopoisk.ru و IMDB.com ، وكذلك متوسط تصنيفات الأفلام حسب النوع . لأغراض التحليل ، تم تصوير أفلام تم إصدارها من عام 2010 إلى عام 2018 ، بحد أدنى 500 صوت.
للبدء ، قم بتحميل المكتبات التي نحتاجها:
# library(rvest) library(selectr) library(xml2) library(jsonlite) library(tidyverse)
بعد ذلك ، أحصل على عدد الأفلام في السنة التي تلبي شرط الاختيار (أكثر من 500 صوت). يتم ذلك من أجل معرفة العدد الإجمالي للصفحات التي تحتوي على بيانات و "إنشاء" روابط لها ، لأن الروابط متشابهة في الهيكل.
# 2018 url <- "https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
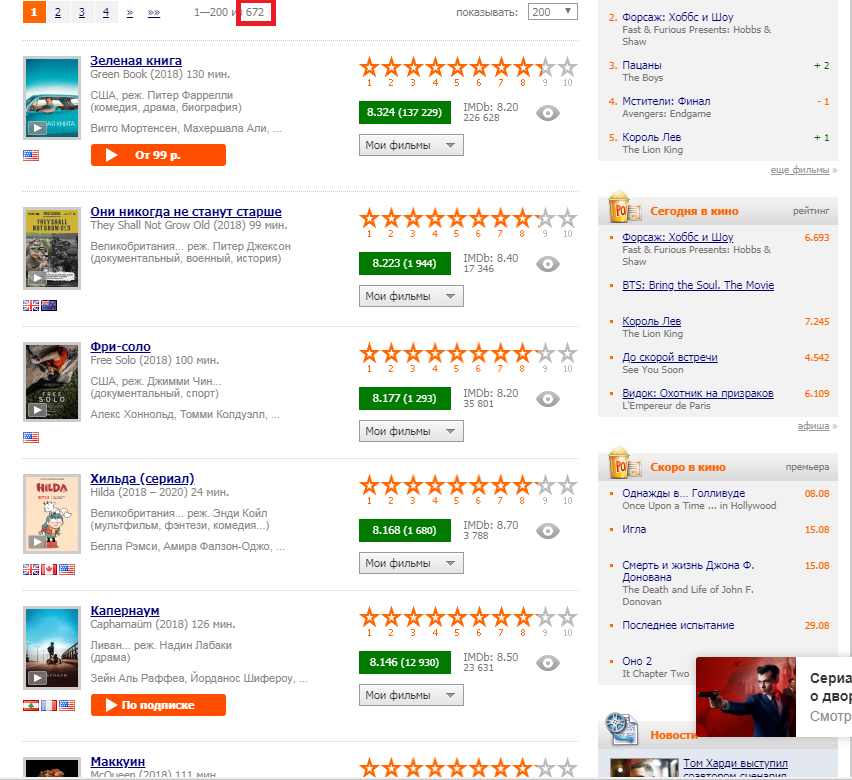
مهمتنا هي "سحب" الرقم 672 ، الذي تم تسليط الضوء عليه في الصورة بواسطة مستطيل أحمر. لهذا نحن بحاجة إلى تجريف الويب.
Kinopoisk.ru موقع صفحات تجريف الويب باستخدام حزمة rvest
أولاً نحتاج إلى "قراءة" عنوان url الذي تلقيناه. للقيام بذلك ، استخدم الدالة read_html() الخاصة بحزمة read_html() .
# XML HTML webpage <- read_html(url)
وبعد ذلك ، باستخدام وظائف حزمة rvest نقوم أولاً "باستخراج" جزء مستند HTML الذي نحتاج إليه ( html_nodes() ) ، ثم نستخلص من هذا الجزء المعلومات التي نحتاجها في نموذج مناسب لنا ( html_text() ، html_table() ، html_attr() أخرى)
ولكن كيف نفهم أي عنصر نحتاج لاستخلاصه؟ للقيام بذلك ، يجب أن نحوم فوق المعلومات التي نهتم بها ، انقر فوق LMB وحدد "عرض الكود". في حالتنا ، نحصل على الصورة التالية:
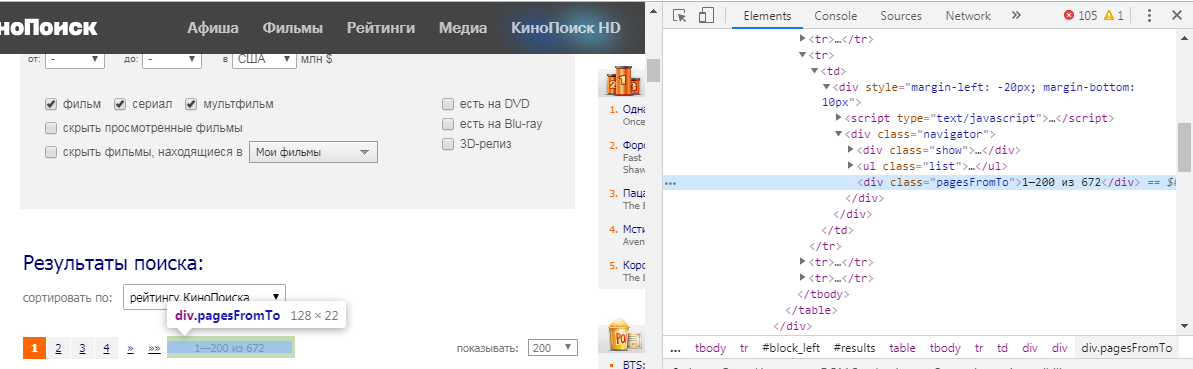
تحتوي html_nodes() على نموذج html_nodes(x, css) . x هي صفحة الويب المعرفة مسبقًا ، لكن في css نكتب معرف العنصر أو فئة العنصر. في حالتنا ، هو:
number_html <- html_nodes(webpage, ".pagesFromTo")
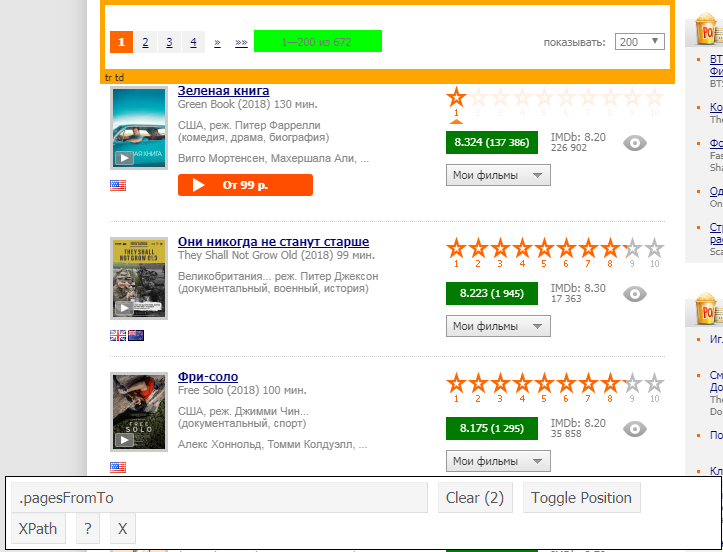
أيضًا ، "لاكتشاف" العنصر المطلوب ، يمكنك استخدام ملحق selectorGadget ، والذي يوضح ما نحتاج إلى إدخاله بوضوح:
بعد ذلك ، باستخدام دالة html_text ، نستخلص جزء النص من العنصر المحدد:
number <- html_text(number_html) [1] "1—50 672" "1—50 672"
حصلنا على العدد الذي نحتاجه من صفحة HTML الخاصة ب Kinopoisk ، لكننا بحاجة الآن إلى "مسحه". هذا إجراء قياسي للتخليص ، لأنه نادرًا ما نحتاج إلى العنصر الذي نحتاجه بالشكل الذي نحتاجه.
لقد حصلنا على عنصرين متطابقين بسبب حقيقة أن العدد الإجمالي للأفلام يشار إليه في أعلى وأسفل الصفحة وأن محدد css الخاص به هو نفسه تمامًا. لذلك ، بالنسبة للمبتدئين ، نزيل العنصر الزائد:
number <- number[1] [1] "1—50 672"
بعد ذلك ، نحتاج إلى التخلص من جزء المتجه الذي يرتفع إلى الرقم 672. يمكنك القيام بذلك بطرق مختلفة ، لكن أساس كل الطرق هو كتابة تعبير منتظم. في هذه الحالة ، " str_remove " الجزء "1-50 من" str_remove (يمكنك استخدام str_remove بدلاً من str_remove ) ، ثم أزل المسافات الزائدة (دالة str_trim ) وأخيراً ترجم المتجه من حرف إلى نوع رقمي. في الإخراج ، أحصل على الرقم 672. بالضبط الكثير من أفلام 2018 لها أكثر من 500 صوت مستخدم على Kinopoisk.
number <- str_replace(number, ".{2,}", "") number <- as.numeric(str_trim(number)) [1] 672
ماذا نفعل بعد ذلك؟ إذا نظرت إلى الصفحات الموجودة على Kinopoisk ، فسترى أن عناوين صفحات البحث لها نفس البنية وتختلف فقط في العدد. لذلك ، من أجل عدم إدخال عنوان الصفحة يدويًا في كل مرة ، سنقوم بحساب عدد الصفحات و "إنشاء" العدد المطلوب من العناوين. يتم ذلك مثل هذا:
# page_number <- ceiling(number/50) # page <- sapply(seq(1:page_number), function(n){ list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results") })
الإخراج هو 14 عناوين. تقريب وظيفة ceiling في هذا المثال رقماً إلى عدد صحيح كبير.
ثم نستخدم الدالة lapply يتم إدخال عناوين الصفحات الخاصة بها ، وتقوم الدالة "باستخراج" المعلومات من صفحات Kinopoisk حول اسم وتصنيف وعدد الأصوات والأنواع الرئيسية (بحد أقصى 3) من الفيلم. يمكن العثور على رمز الوظيفة في المستودع على جيثب .
نتيجة لذلك ، حصلنا على طاولة بها 8111 فيلما.
تجدر الإشارة إلى استخدام دالة Sys.sleep. باستخدامه ، يمكنك ضبط وقت التأخير بين التعبيرات. لماذا هذا مطلوب؟ إذا كنت ترغب في تلقي المعلومات في سنة واحدة ، فلا داعي لذلك. ولكن إذا كنت مهتمًا بعدد كبير من الأفلام / السنوات ، فبعد عدد معين من الطلبات ، ستعتبر Kinopoisk لك روبوتًا وستتلقى قائمة فارغة لطلبك. لتجنب هذا ، تحتاج إلى إدخال وقت التأخير.
وبالمثل ، "خردة" موقع IMDB.com.
تحليل البيانات
لدينا جدولان ، في أحد المعلومات حول الأفلام مع IMDB ، في الآخر من Kinopoisk. الآن نحن بحاجة إلى الجمع بينهما. سوف نتحد وفقًا للأعمدة NAME و YEAR. من أجل تقليل عدد التناقضات في الأسماء ، حتى في مرحلة الكشط ، قمت بإزالة جميع علامات الترقيم وقمت بتحويل الحروف إلى أحرف صغيرة. نتيجة لذلك ، بعد كل الاتصالات والحذف ، نحصل على 3450 فيلمًا تحتوي على المعلومات التي نحتاجها من كلا الموقعين.
أنا مهتم بالفرق في تصنيفات الأفلام على موقعين ، لذلك سنقوم بإنشاء متغير DELTA ، وهو الفرق بين تقديرات IMDB و Kinopoisk. إذا كانت DELTA إيجابية ، فستكون درجة IMDB أعلى ؛ وإذا كانت سلبية ، تكون أقل.
أولاً ، قم بإنشاء رسم بياني لمؤشر DELTA:
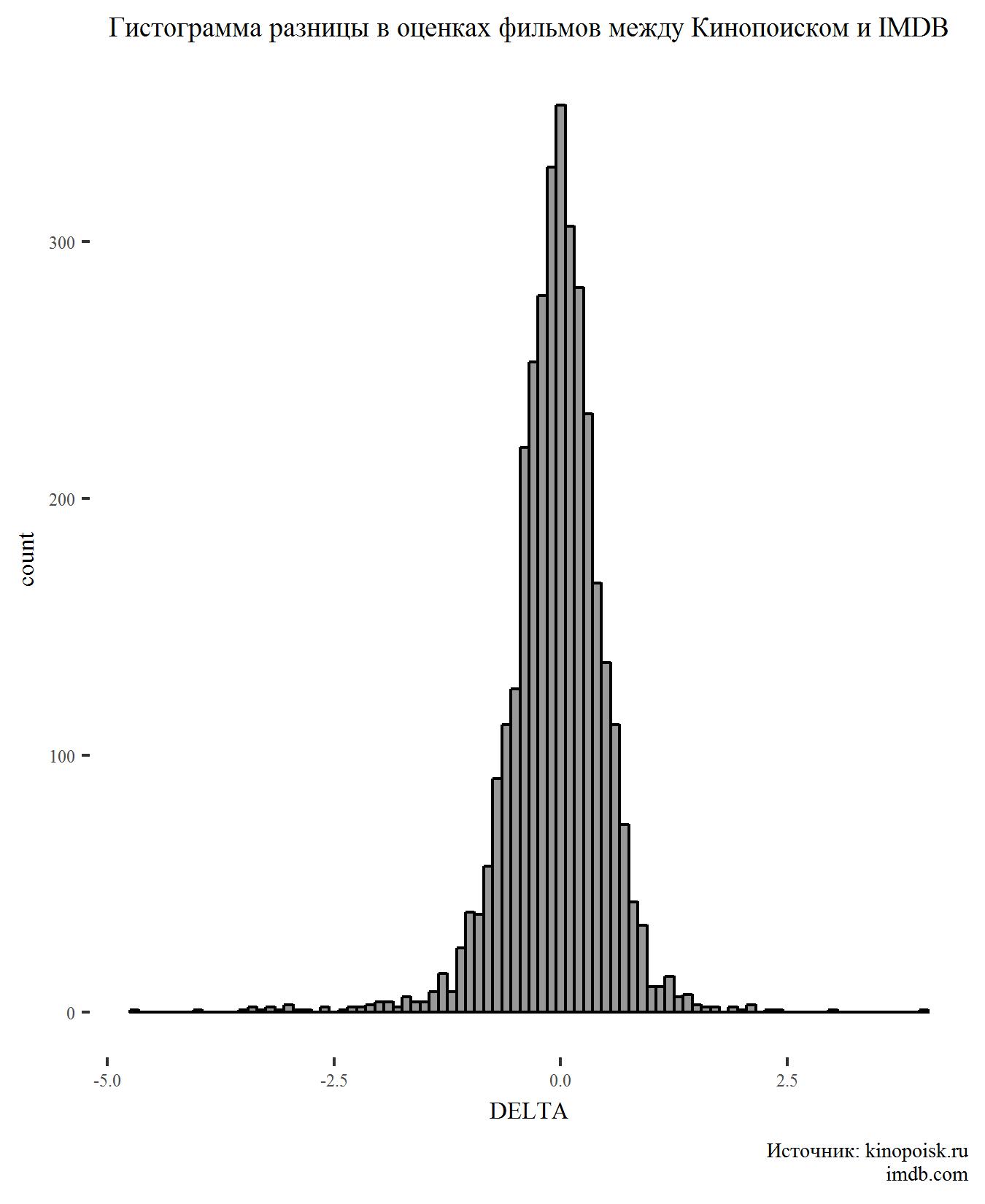
لا يوجد شيء مفاجئ على الرسم البياني. الفرق في التصنيفات له توزيع طبيعي وذروة في منطقة الصفر ، مما يشير إلى أن مستخدمي الموقعين يتفقون عادة على تصنيف الأفلام.
تتلاقى ، لكن ليس تمامًا. يسمح لنا اختبار t لعينتين مستقلتين بأن نقول أن التصنيفات على Kinopoisk أعلى وأن هذا الاختلاف مهم إحصائياً (قيمة p <0.05).
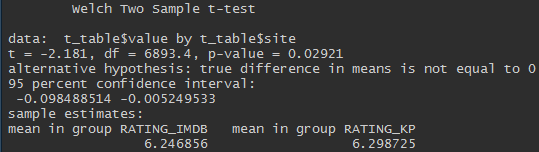
على الرغم من أن الفرق كبير ، إلا أنه صغير جدًا.
بعد ذلك ، لنرى كيف يعتمد الاختلاف في التصنيفات على عدد الأصوات.
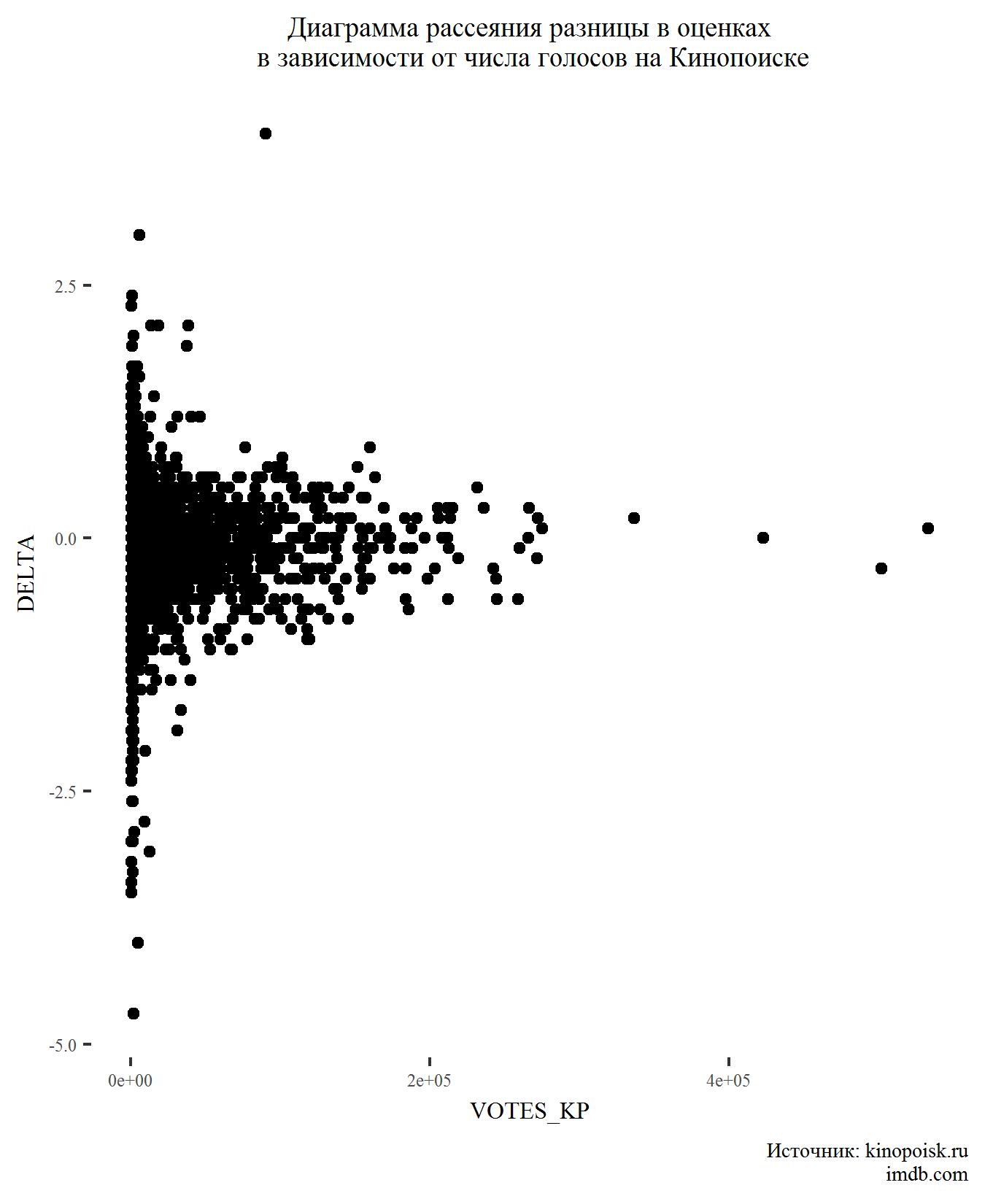
لا شيء غير متوقع هنا أيضا. الأفلام ذات عدد كبير من الأصوات عادة ما يكون لها اختلاف بسيط للغاية في التصنيفات.
الآن دعنا ننتقل إلى تقييم الأفلام حسب النوع. تجدر الإشارة إلى أنه في الحال يمكن أن يحتوي أحد الأفلام على ثلاثة أنواع ، ولكن تصنيفًا واحدًا فقط ، لذلك يمكن لفيلم واحد الدخول في "الاختبار" والكوميديا والميلودراما.
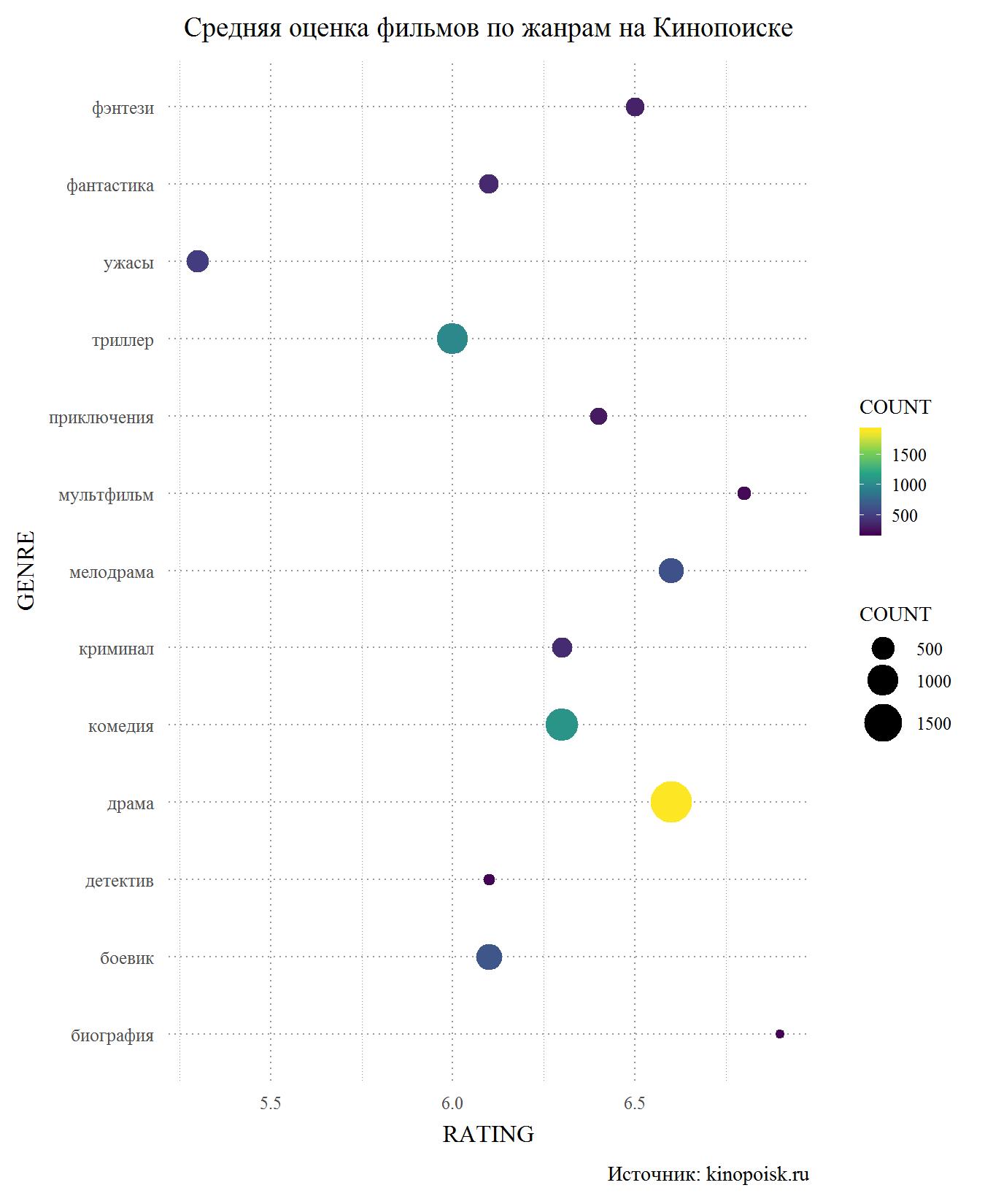
لنبدأ مع Kinopoisk. من بين الأنواع التي لها ما لا يقل عن 150 ظهورًا في قاعدة البيانات ، يعد الرعب غريبًا واضحًا. أيضا انخفاض معدل الإثارة المستخدمين ، والمحققين العمل ، وما يثير الدهشة بالنسبة لي ، والخيال العلمي. من ناحية أخرى ، تأتي الأفلام الميلودرامية على Kinopoisk مع اثارة ضجة ، حيث يبلغ معدل التقييم أعلى من 6.5 ويأتي في المرتبة الثانية بعد الرسوم المتحركة والسيرة الذاتية ، والتي تعد أصغر بكثير في قاعدة البيانات
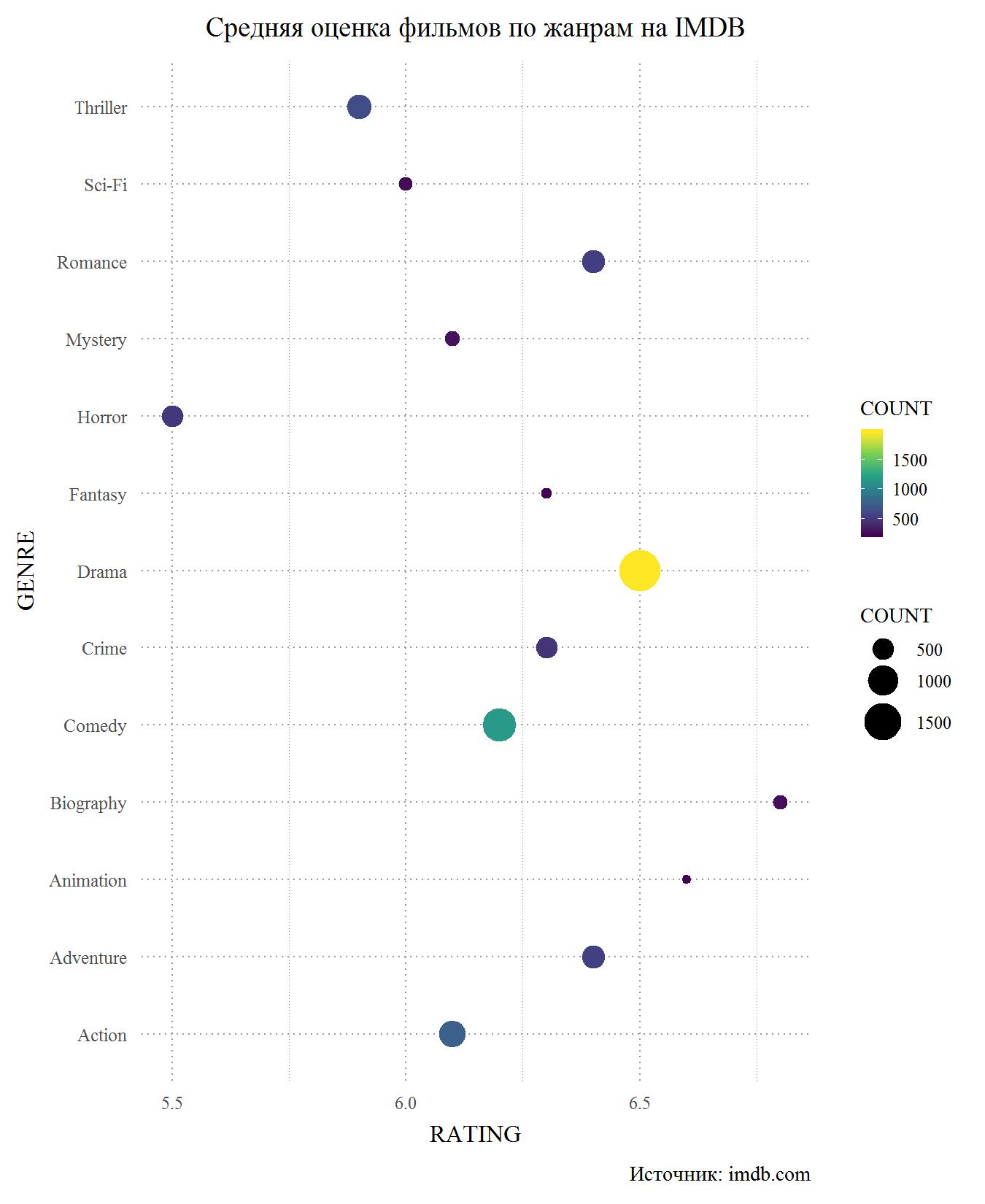
الآن النظر في نفس المخطط ، ولكن ل IMDB. من حيث المبدأ ، يؤكد مرة أخرى أن الفرق في التصنيفات بين المواقع ضئيل. هذا ليس مفاجئًا ، لأن العديد من المستخدمين لديهم حسابات على كلا الموقعين ومن غير المرجح أن يقدموا تقييمات مختلفة على مواقع مختلفة. مرة أخرى ، الخاسر الرئيسي هو الرعب ، ويمكننا القول إنها أكثر الأفلام تصنيفًا. يصعب عليّ تقييم سبب حدوث ذلك ، لأن فيلم الرعب الوحيد الذي شاهدته في حياتي هو Gremlins. ربما تكون أهوال الرعب هي أقل أنواع الموازنة ، حيث تأتي المسرحية الضعيفة للممثلين الرخيصين والسيناريوهات السيئة بصراحة. الإثارة مع الخيال العلمي وعلى IMDB هي من بين المتقاعدين ، ولكن المسلحين في حالة جيدة. بين القادة مرة أخرى الأفلام والسير الذاتية. تحتل الدراما المركز الثالث ، لكن درجة ميلودراما انخفضت إلى أقل من 6.5 ، إلى مستوى أفلام المغامرات. أيضا على IMDB أدناه كوميديا.
الخلاصة والقليل حول "العوامل الخارجية"
على الرغم من وجود اختلاف في التقديرات (في Kinopoisk ، إلا أنها أعلى قليلاً) ، لكن هذا قليل. وفقا لأنواع مختلفة ، والفرق الكبير هو أيضا غير محسوس. الافلام التي لديها عشرات أو حتى مئات الآلاف من الأصوات ، إذا كانت لديهم خلافات ، ثم ضمن 0.5 نقطة.
الأفلام التي تحتوي على عدد صغير (لا سيما على Kinopoisk) ، يصل إلى 10 ألف صوت ، عادةً ما يكون لها اختلاف كبير في التصنيفات. ومع ذلك ، فإن الفارق الأكبر في التصنيف لصالح IMDB هو الفيلم الذي حصل على 30،000 صوت على موقع أجنبي وأكثر من 90،000 على Kinopoisk. هذا هو إنشاء أليكسي بيمانوف "القرم". هل الفيلم محبوب للغاية من قبل المشاهدين الأجانب؟ بالكاد. على الأرجح ، استخدم صانعو الأفلام "سياسة التسويق" نفسها فيما يتعلق بـ IMDB كما في Kinopoisk. إنه فقط إذا قامت Kinopoisk بتنظيف مثل هذه التقديرات ، فبقيت على IMDB. أعتقد أن هذا هو السبب وراء وجود "شبه جزيرة القرم" "kinchik الصغير الجيد".
سأكون ممتنا لأية تعليقات أو اقتراحات أو شكاوى
جيثب مستودع الارتباط
ملفي الشخصي الدائرة