وُلدت فكرة المقال تلقائيًا من مناقشة في التعليقات على مقالة
"شيء حول inode" .
الحقيقة هي أن التفاصيل الداخلية لخدماتنا هي تخزين عدد كبير من الملفات الصغيرة. في الوقت الحالي ، لدينا حوالي مئات تيرابايت من هذه البيانات. وقد صادفنا بعضًا من الأمور الواضحة وغير المشدودة للغاية ونجحنا في السير عليها
لذلك ، أشارك تجربتنا ، ربما شخص ما سوف يكون في متناول اليدين.
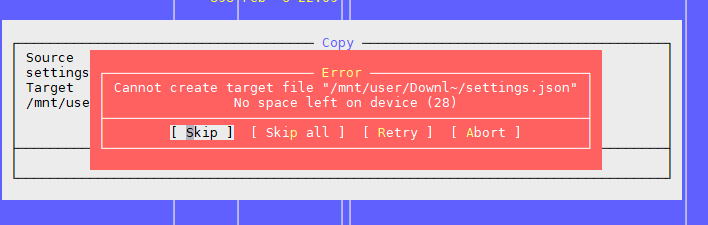
المشكلة الأولى: "لا توجد مساحة على الجهاز"
كما هو مذكور في المقالة أعلاه ، فإن المشكلة تكمن في وجود كتل مجانية على نظام الملفات ، ولكن انتهى inode.
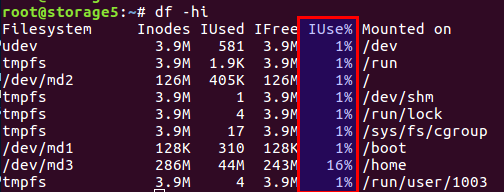
يمكنك التحقق من عدد inodes المستخدمة والمجانية مع
df -ih :
لن أقوم بإعادة بيع المقالة ، باختصار ، توجد كتل للبيانات مباشرة على القرص وكتل لمعلومات التعريف ، بل هي أيضًا inode (عقدة الفهرس). يتم تعيين عددهم أثناء تهيئة نظام الملفات (نحن نتحدث عن ext2 وأحفاده) ولا يتغير أكثر. يتم حساب رصيد كتل البيانات والبيانات الداخلية من متوسط البيانات ، وفي حالتنا ، عندما يكون هناك الكثير من الملفات الصغيرة ، يجب أن يتحول الرصيد نحو عدد الرموز الداخلية - يجب أن يكون هناك المزيد منها.
لقد وفر Linux بالفعل خيارات بأرصدة مختلفة ، وجميع هذه التكوينات المحسوبة مسبقًا موجودة في ملف
/etc/mke2fs.conf .
لذلك ، أثناء التهيئة الأولية لنظام الملفات من خلال mke2fs ، يمكنك تحديد ملف التعريف المطلوب.
فيما يلي بعض الأمثلة من الملف:
small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } big = { inode_ratio = 32768 } largefile = { inode_ratio = 1048576 blocksize = -1 }
يمكنك تحديد حالة الاستخدام المطلوبة مع خيار -T عند استدعاء mke2fs. يمكنك أيضًا تعيين المعلمات الضرورية يدويًا إذا لم يكن هناك حل جاهز.
المزيد من التفاصيل موضحة في كتيّبات
mke2fs.conf و
mke2fs .
ميزة لم يرد ذكرها في المقالة المذكورة أعلاه - يمكنك ضبط حجم كتلة البيانات. من الواضح ، بالنسبة للملفات الكبيرة ، من المنطقي أن يكون حجم الكتلة أكبر ، للملفات الصغيرة - بحجم أصغر.
ومع ذلك ، يجدر النظر في هذه الميزة المثيرة للاهتمام مثل بنية المعالج.
اعتقدت ذات مرة أنني في حاجة إلى حجم كتلة أكبر لملفات الصور الكبيرة. كان في المنزل ، على اسم الملف الرئيسي WD على بنية ARM. بدون تردد ، قمت بتعيين حجم الكتلة إما 8 كيلو أو 16 كيلو بدلاً من 4 كيلو قياسي ، بعد أن قمت بقياس المدخرات مسبقًا. وكان كل شيء رائعًا تمامًا حتى اللحظة التي فشل فيها التخزين نفسه ، بينما كان القرص حيًا. بعد أن قمت بوضع القرص في كمبيوتر عادي باستخدام معالج Intel منتظم ، حصلت على مفاجأة: حجم الكتلة غير المدعوم. أبحر. هناك بيانات ، كل شيء على ما يرام ، ولكن من المستحيل قراءته. لا تعرف المعالجات i386 وما شابهها كيفية التعامل مع أحجام الكتل التي لا تتناسب مع حجم صفحة الذاكرة ، ولكنها تبلغ 4 كيلو بايت بالضبط. بشكل عام ، انتهت القضية باستخدام الأدوات المساعدة من مساحة المستخدم ، كل شيء كان بطيئًا وحزينًا ، ولكن تم حفظ البيانات. من يهتم - جوجل اسم الأداة المساعدة
fuseext2 . الأخلاقية: إما التفكير من خلال جميع الحالات مقدما ، أو عدم إنشاء بطل خارق واستخدام الإعدادات القياسية لربات البيوت.
UPD. وفقًا لملاحظة المستخدم ،
يوضح berez أنه بالنسبة إلى i386 ، يجب ألا يتجاوز حجم الكتلة 4 كيلو بايت ، لكن ليس من الضروري أن يكون 4 كيلو بايت بالضبط ، أي صالحة 1K و 2K.
لذلك ، كيف حلنا المشاكل.
أولاً ، واجهنا مشكلة عندما كان قرص متعدد تيرابايت ممتلئًا بالبيانات ، ولم نتمكن من إعادة تكوين نظام الملفات.
ثانيا ، كان القرار عاجلا.
نتيجة لذلك ، توصلنا إلى استنتاج مفاده أننا نحتاج إلى تغيير الرصيد عن طريق تقليل عدد الملفات.
لتقليل عدد الملفات ، تقرر وضع الملفات في أرشيف واحد مشترك. بالنظر إلى تفاصيلنا ، وضعنا جميع الملفات في أرشيف واحد لفترة زمنية معينة ، وأرشفة مهمة cron يوميًا في الليل.
تم تحديد أرشيف مضغوط. في التعليقات على المقال السابق ، تم اقتراح tar ، ولكن هناك تعقيد واحد: فهو لا يحتوي على جدول محتويات ، والملفات مترابطة فيه (لسبب ما ، "tar" هي اختصار لـ "Tape Archive" ، تراث محركات الأشرطة) ، أي . إذا كنت بحاجة إلى قراءة الملف في نهاية الأرشيف ، فأنت بحاجة إلى قراءة الأرشيف بالكامل ، حيث لا توجد إزاحات لكل ملف بالنسبة لبداية الأرشيف. وبالتالي فهي عملية طويلة. في zip ، كل شيء أفضل: يحتوي على نفس جدول المحتويات وإزاحة الملفات داخل الأرشيف ، ولا يعتمد وقت الوصول إلى كل ملف على موقعه. حسنًا ، في حالتنا ، كان من الممكن ضبط خيار الضغط على "0" ، لأن جميع الملفات كانت مضغوطة بالفعل في gzip مسبقًا.
يأخذ العملاء الملفات عبر nginx ، ووفقًا لواجهة برمجة التطبيقات القديمة ، يتم تحديد اسم الملف فقط ، على سبيل المثال مثل هذا:
http://www.server.com/hydra/20170416/0453/3bd24ae7-1df4-4d76-9d28-5b7fcb7fd8e5
لفك ضغط الملفات على الطاير ، وجدنا وتوصل وحدة nginx-unzip-module (
https://github.com/youzee/nginx-unzip-module ) وقمنا بإعداد مرحلتين.
والنتيجة هي هذا التكوين:

بدا مضيفان في الإعدادات كما يلي:
server { listen *:8081; location / { root /home/filestorage; } }
server { listen *:8082; location ~ ^/hydra/(\d+)/(\d+)/(.*)$ { root /home/filestorage; file_in_unzip_archivefile "/home/filestorage/hydra/$1/$2.zip"; file_in_unzip_extract "$2/$3"; file_in_unzip; } }
والتكوين المنبع على nginx المنبع:
upstream storage { server server.com:8081; server server.com:8082; }
كيف يعمل:
- يذهب العميل إلى الجبهة nginx
- تحاول واجهة nginx الأمامية إعطاء الملف من أول اتجاه ، أي مباشرة من نظام الملفات
- إذا لم يكن هناك ملف ، فإنه يحاول إعطائه من المنبع الثاني ، والذي يحاول العثور على الملف داخل الأرشيف
المشكلة الثانية: مرة أخرى ، "لا توجد مساحة على الجهاز"
هذه هي المشكلة الثانية التي واجهناها عندما يكون هناك الكثير من الملفات في الدليل.
نحن نحاول إنشاء ملف ، يقسم النظام أنه لا توجد مساحة. قم بتغيير اسم الملف وحاول إنشائه مرة أخرى.
اتضح.
يبدو شيء مثل هذا:

التحقق من inodes أعطى شيئا - هناك الكثير منهم مجانا.
التحقق من المكان هو نفسه.
لقد اعتقدنا أنه قد يكون هناك الكثير من الملفات في الدليل ، ولكن يوجد حد لذلك ، ولكن مرة أخرى لا: الحد الأقصى لعدد الملفات لكل دليل: ~ 1.3 × 10 ^ 20
نعم ، ويمكنك إنشاء ملف إذا قمت بتغيير الاسم.
الاستنتاج مشكلة في اسم الملف.
أظهرت عمليات البحث الإضافية أن المشكلة تكمن في خوارزمية التجزئة عند إنشاء فهرس الدليل ، مع وجود عدد كبير من الملفات توجد تصادمات مع جميع العواقب المترتبة عليها. يمكن العثور على مزيد من التفاصيل هنا:
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Hash_Tree_Directoriesيمكنك تعطيل هذا الخيار ، ولكن ... قد يصبح البحث عن ملف بالاسم طويلًا بشكل غير متوقع عند الفرز عبر جميع الملفات.
tune2fs -O "^dir_index" /dev/sdb3
بشكل عام ، كيف قد يعمل الحل.
الأخلاقية: العديد من الملفات في دليل عادة ما تكون سيئة. هذا ليس ضروريا.
عادةً في مثل هذه الحالات ، يقومون بإنشاء الدلائل الفرعية ، أو بالأحرف الأولى من اسم الملف أو بعض المعلمات الأخرى ، على سبيل المثال ، حسب التواريخ ، وفي معظم الحالات يتم حفظ هذا.
لكن العدد الإجمالي للملفات الصغيرة لا يزال سيئًا ، حتى إذا كانت مقسمة إلى أدلة - فراجع المشكلة الأولى.
المشكلة الثالثة: كيف ترى قائمة الملفات ، إذا كان هناك الكثير منها
في وضعنا ، عندما يكون لدينا الكثير من الملفات ، بطريقة أو بأخرى ، واجهنا مشكلة كيفية عرض محتويات الدليل.
الحل القياسي هو
ls .
حسنًا ، دعنا نرى ما يحدث في ملفات 4772098:
$ time ls /home/app/express.repository/offercache/ >/dev/null real 0m30.203s user 0m28.327s sys 0m1.876s
30 ثانية ... سيكون أكثر من اللازم. وغالبًا ما يستغرق معالجة الملفات في مساحة المستخدم ، وليس على الإطلاق للنواة.
ولكن هناك حل:
$ time find /home/app/express.repository/offercache/ >/dev/null real 0m3.714s user 0m1.998s sys 0m1.717s
3 ثواني 10 مرات أسرع.
الصيحة!
UPD.حل أسرع من مستخدم
berez هو تعطيل الفرز
ls time ls -U /home/app/express.repository/offercache/ >/dev/null real 0m2.985s user 0m1.377s sys 0m1.608s
المشكلة الرابعة: LA كبير عند العمل مع الملفات
يحدث الموقف بشكل دوري عندما تحتاج إلى نسخ مجموعة من الملفات من جهاز إلى آخر. في الوقت نفسه ، غالبًا ما تنمو LA بشكل غير واقعي ، لأن كل شيء يعتمد على أداء الأقراص نفسها.
الشيء الأكثر منطقية الذي تريده هو استخدام SSD. رائع حقا. والسؤال الوحيد هو تكلفة محركات الأقراص ذات سعة تيرابايت المتعددة.
ولكن إذا كانت الأقراص عادية ، فستحتاج إلى نسخ الملفات ، وهذا أيضًا نظام إنتاج ، حيث يؤدي التحميل الزائد إلى تعجب غير مرض من العملاء؟ هناك ما لا يقل عن اثنين من الأدوات المفيدة:
nice و
ionice .
nice - تقلل من أولوية العملية ، على التوالي ، يقوم sheduler بتوزيع شرائح الوقت على عمليات أخرى أكثر أولوية.
في ممارستنا ، ساعدنا على ضبط الحد الأدنى إلى الحد الأقصى (19 هي الأولوية الدنيا ، و 20 (ناقص 20) هي الحد الأقصى).
ionice - وفقًا لذلك يضبط أولوية الإدخال / الإخراج (جدولة الإدخال / الإخراج)
إذا كنت تستخدم RAID وتحتاج إلى مزامنة مفاجئة (بعد إعادة تشغيل غير ناجحة أو تحتاج إلى استعادة صفيف RAID بعد استبدال القرص) ، فمن المنطقي في بعض الحالات تقليل سرعة المزامنة بحيث تعمل العمليات الأخرى بشكل أو بآخر. للقيام بذلك ، سوف يساعد الأمر التالي:
echo 1000 > /proc/sys/dev/raid/speed_limit_max
المشكلة الخامسة: كيفية مزامنة الملفات في الوقت الحقيقي
لدينا كل نفس العدد الهائل من الملفات التي يجب نسخها احتياطيًا إلى خادم ثانٍ لتجنب ... تتم كتابة الملفات باستمرار ، وبالتالي ، لكي تحصل على أقل عدد ممكن من الخسائر ، تحتاج إلى نسخها بأسرع ما يمكن.
الحل القياسي: Rsync عبر SSH.
هذا خيار جيد ، إلا إذا كنت بحاجة إلى القيام بذلك مرة واحدة كل بضع ثوانٍ. وهناك الكثير من الملفات. حتى إذا لم تقم بنسخها ، فلا تزال بحاجة إلى فهم ما تم تغييره بطريقة أو بأخرى ، ولمقارنة عدة ملايين من الملفات هي وقت التحميل على الأقراص.
أي نحن بحاجة إلى معرفة ما يجب نسخه على الفور ، دون البدء في المقارنة في كل مرة.
الخلاص -
lsyncd .
Lsyncd -
المزامنة المباشرة (مرآة) البرنامج الخفي . كما أنه يعمل من خلال rsync ، لكنه يراقب نظام الملفات بالإضافة إلى التغييرات التي تحدث باستخدام inotify و fsevents ويبدأ في النسخ فقط لتلك الملفات التي ظهرت أو تغيرت.
المشكلة السادسة: كيفية فهم من الذي يحمّل الأقراص
ربما يعرف الجميع هذا ، ولكن من
iotop الاكتمال: لمراقبة النظام الفرعي للقرص ، يوجد أمر
iotop الأمر
iotop ، لكنه يوضح العمليات التي تستخدم الأقراص بشكل أكثر نشاطًا.

بالمناسبة ، فإن القمة القديمة الجيدة توضح أيضًا وجود مشكلات في الأقراص أم لا. هناك نوعان من المعلمات الأكثر ملاءمة لهذا:
Load Average و
IOwait .
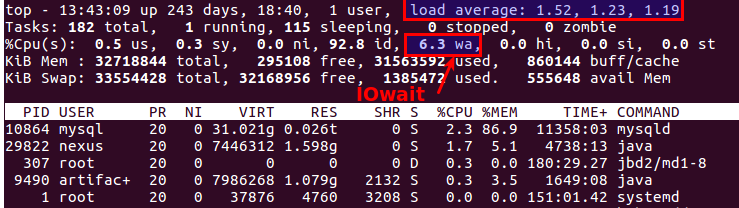
يُظهر الأول عدد العمليات الموجودة في قائمة انتظار الخدمة ، وعادة ما يكون أكثر من 2 - هناك خطأ ما يحدث بالفعل. مع النسخ النشط إلى خوادم النسخ الاحتياطي ، نسمح بما يصل إلى 6-8 ، وبعد ذلك يعتبر الموقف غير طبيعي.
والثاني هو كم المعالج مشغول بعمليات القرص. IOwait> 10٪ مدعاة للقلق ، على الرغم من ثبات 40-50٪ على الخوادم ذات ملف تعريف تحميل معين ، وهذا هو المعيار الحقيقي.
سأنتهي هنا ، على الرغم من وجود العديد من النقاط التي لم نواجهها ، إلا أنني سأكون سعيدًا بانتظار التعليقات وأوصاف الحالات الحقيقية المثيرة للاهتمام.