
الاجتماع السنوي لجمعية اللغويات الحاسوبية (ACL) هو المؤتمر الأول لمعالجة اللغات الطبيعية. تم تنظيمه منذ عام 1962. بعد كندا وأستراليا ، عادت إلى أوروبا وسارت في فلورنسا. وهكذا ، كان هذا العام أكثر شعبية لدى الباحثين الأوروبيين من EMNLP مماثلة له.
هذا العام تم نشر 660 مقالاً من 2900 مقالة. كمية كبيرة. لا يمكن إجراء نوع من المراجعة الموضوعية لما كان في المؤتمر. لذلك ، سوف أخبر مشاعري الشخصية من هذا الحدث.
جئت إلى المؤتمر لأعرض في جلسة ملصقات
قرارنا من مسابقة Kaggle حول
قرار الضمير الجنساني من Google. اعتمد حلنا اعتمادًا كبيرًا على استخدام
نماذج BERT سابقة
التدريب . وكما اتضح ، لم نكن وحدنا في هذا.
BERTology

كان هناك الكثير من الأعمال القائمة على BERT ، ووصف خصائصها واستخدامها كقاعدة سفلية ، حتى أن مصطلح Bertology ظهر. في الواقع ، أثبتت نماذج BERT نجاحًا كبيرًا حتى أن مجموعات البحث الكبيرة تقارن نماذجها بنماذج BERT.
لذلك في أوائل يونيو ، ظهر العمل حول
XLNet . وقبل المؤتمر مباشرة -
ERNIE 2.0 و
RoBERTaفيسبوك روبرتا
عندما تم تقديم نموذج XLNet لأول مرة ، اقترح بعض الباحثين أنه حقق نتائج أفضل ليس فقط بسبب بنيته ومبادئه التدريبية. درست أيضًا على جسم أكبر (حوالي 10 مرات) من BERT وأطول (4 مرات أكثر من التكرار).
لقد أظهر الباحثون في Facebook أن BERT لم يصل بعد إلى الحد الأقصى. لقد قدموا طريقة مثالية لتدريس نموذج بيرت - RoBERTa (نهج بيرت الأمثل بقوة).
تغيير أي شيء في بنية النموذج ، غيروا الإجراء التدريب:
- قمنا بزيادة هيئة التدريب وحجم الدفعة وطول التسلسل ومدة التدريب.
- تمت إزالة مهمة التنبؤ الجملة التالية من التدريب.
- بدأوا في إنشاء الرموز المميزة لـ MASK (الرموز التي يحاول النموذج التنبؤ بها أثناء التدريب المسبق).
إرني 2.0 من بايدو
مثل كل النماذج الحديثة الشائعة (BERT ، GPT ، XLM ، RoBERTa ، XLNet) ، تعتمد ERNIE على مفهوم المحول مع آلية الاهتمام الذاتي. ما يميزها عن النماذج الأخرى هو مفاهيم التعلم متعدد المهام والتعلم المستمر.
تتعرف ERNIE على المهام المختلفة ، وتقوم باستمرار بتحديث التمثيل الداخلي لنموذج اللغة الخاص بها. هذه المهام لها ، مثل النماذج الأخرى ، أهداف التعلم الذاتي (تحت الإشراف الذاتي وضعف الإشراف). أمثلة على هذه المهام:
- استعادة ترتيب الكلمات الصحيح في جملة.
- كتابة الحروف الكبيرة.
- تعريف الكلمات المقنعة.
في هذه المهام ، يتعلم النموذج بالتتابع ، ويعود إلى المهام التي تم تدريبه عليها مسبقًا.
روبيرتا ضد إيرني
في المنشورات ، لا تتم مقارنة RoBERTa و ERNIE مع بعضهما البعض ، حيث إنهما يظهران بشكل متزامن تقريبًا. تتم مقارنتها مع BERT و XLNet. ولكن هنا ليس من السهل إجراء مقارنة. على سبيل المثال ، في
المعيار الشائع ، يتم تمثيل GLUE XLNet بمجموعة من النماذج. ويهتم باحثون من بايدو بمقارنة النماذج الفردية. بالإضافة إلى ذلك ، نظرًا لأن Baidu هي شركة صينية ، فهي مهتمة أيضًا بمقارنة نتائج العمل مع اللغة الصينية. في الآونة الأخيرة ، ظهر معيار جديد:
SuperGLUE . لا توجد حلول كثيرة بعد ، ولكن RoBERTa في المقام الأول هنا.
لكن بشكل عام ، كل من RoBERTa و ERNIE يعملان بشكل أفضل من XLNet وأفضل بكثير من BERT يعمل RoBERTa ، بدوره ، على نحو أفضل قليلاً من ERNIE.
الرسوم البيانية للمعرفة
تم تكريس الكثير من العمل للجمع بين نهجين: الشبكات المدربة مسبقًا واستخدام القواعد في شكل رسوم بيانية للمعرفة (Knowledge Graphs، KG).
على سبيل المثال:
ERNIE: التمثيل اللغوي المحسن مع الكيانات الإعلامية . تسلط هذه الورقة الضوء على استخدام الرسوم البيانية المعرفية أعلى نموذج لغة بيرت. يتيح لك ذلك الحصول على نتائج أفضل في مهام مثل تحديد نوع الكيان (
كتابة الكيان) وتصنيف العلاقة .
بشكل عام ، تؤدي طريقة اختيار أسماء النماذج بأسماء الشخصيات من Sesame Street إلى عواقب مضحكة. على سبيل المثال ، لا علاقة لـ ERNIE بـ Baidu's ERNIE 2.0 ، والتي كتبت عنها أعلاه.

عمل آخر مثير للاهتمام حول توليد معرفة جديدة:
COMET: محولات العموم للبناء الرسم البياني للمعرفة التلقائية . تبحث الورقة في إمكانية استخدام تصميمات جديدة قائمة على محولات لتدريب الشبكات القائمة على المعرفة. قواعد المعرفة في شكل مبسط هي ثلاثة أضعاف: الموضوع ، والموقف ، وجوه. أخذوا مجموعتين من قواعد المعرفة: ATOMIC و ConceptNet. وقاموا بتدريب شبكة بناءً على نموذج المحولات التوليفية العامة المدارة (GPT). تم إدخال الموضوع والموقف وحاول التنبؤ بالكائن. وبالتالي ، فقد حصلوا على نموذج يولد الكائنات حسب موضوعات المدخلات والعلاقات.
المقاييس
موضوع آخر مثير للاهتمام في المؤتمر كان مسألة اختيار المقاييس. غالبًا ما يكون من الصعب تقييم جودة النموذج في مهام معالجة اللغة الطبيعية ، مما يؤدي إلى إبطاء التقدم في هذا المجال من التعلم الآلي.
في مقال
دراسة تقييم التلخيص في مقالة
نطاق النقاط المناسب ، يناقش مكسيم بيار استخدام المقاييس المختلفة في مشكلة تلخيص النص. لا ترتبط هذه المقاييس دائمًا مع بعضها البعض ، مما يتعارض مع المقارنة الموضوعية للخوارزميات المختلفة.
أو إليك مهمة مثيرة للاهتمام:
التقييم التلقائي للنصوص متعددة الجمل . في ذلك ، يقدم المؤلفون مقياسًا يمكن أن يحل محل BLEU و ROUGE في المهام التي تحتاج إليها لتقييم النصوص من عدة جمل.
يمكن تمثيل قياس BLEU بالدقة - عدد الكلمات (أو عدد الجرام n) من استجابة النموذج الموجودة في الهدف. ROUGE is Recall - يتم تضمين عدد الكلمات (أو عدد الجرام n) من الهدف في استجابة النموذج.
يستند المقياس المقترح في المقالة إلى مقياس أسلحة الدمار الشامل - المسافة بين وثيقتين. وهي تساوي الحد الأدنى للمسافة بين الكلمات في جملتين في فضاء التمثيل المتجه لهذه الكلمات. يمكن العثور على مزيد من المعلومات حول أسلحة الدمار الشامل في البرنامج التعليمي ، والذي يستخدم
أسلحة الدمار الشامل من Word2Vec ومن
GloVe .
في مقالهم ، يقدمون مقياسًا جديدًا: WMS (تشابه Word Mover).
WMS(A, B) = exp(−WMD(A, B))
ثم يحددون الرسائل القصيرة (تشابه الجملة في المحرك). ويستخدم نهج مشابه للنهج مع WMS. كتمثيل متجه للجملة ، يأخذون المتجه المتوسط لكلمات الجملة.
عند حساب WMS ، تتم تسوية الكلمات حسب تواترها في المستند. عند حساب جمل الرسائل القصيرة يتم تطبيعها بعدد الكلمات في الجملة.
أخيرًا ، يعد مقياس S + WMS عبارة عن مزيج من WMS و SMS. يشيرون في مقالتهم إلى أن مقاييسهم ترتبط بشكل أفضل بالتقييم اليدوي للشخص.
chatbot
الجزء الأكثر فائدة من المؤتمر ، في رأيي ، كان جلسات الملصقات. لم تكن جميع التقارير مثيرة للاهتمام ، ولكن إذا بدأت في الاستماع إلى بعض ، فلن تترك تقارير أخرى في منتصف التقرير. الملصقات هي مسألة أخرى. هناك العشرات منهم في جلسة الملصقات. يمكنك اختيار الأشياء التي تحبها ويمكنك ، كقاعدة عامة ، التحدث مباشرة مع المطور حول التفاصيل الفنية. بالمناسبة ، هناك موقع مثير للاهتمام مع
ملصقات من المؤتمرات . صحيح ، هناك ملصقات من مؤتمرين هناك ، وليس من المعروف ما إذا كان سيتم تحديث الموقع.
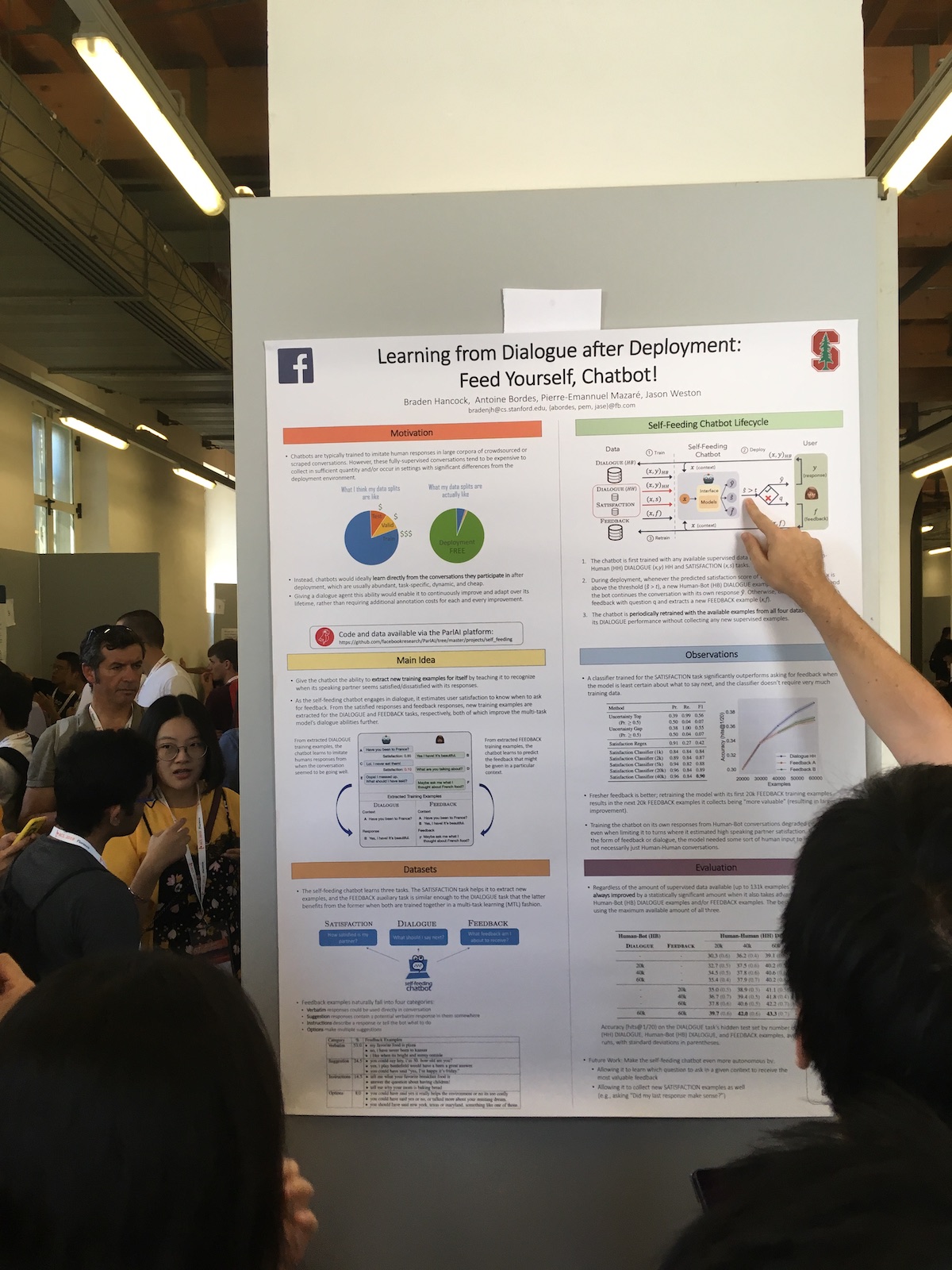
في جلسات الملصقات ، قدمت الشركات الكبيرة في كثير من الأحيان عملًا مثيرًا للاهتمام. على سبيل المثال ، إليك مقال على Facebook "
التعلم من الحوار بعد النشر": قم بإطعام نفسك ، Chatbot! .
خصوصية نظامهم هو الاستخدام الموسع لاستجابات المستخدمين. لديهم مصنف يقوم بتقييم مدى رضاء المستخدم عن الحوار. يستخدمون هذه المعلومات في مهام مختلفة:
- استخدم مقياس الرضا كمقياس للجودة.
- يقومون بتدريب النموذج ، وبالتالي تطبيق نهج التعلم المستمر (التعلم المستمر).
- استخدم مباشرة في الحوار. التعبير عن بعض ردود الفعل البشرية إذا كان المستخدم راضيا. أو يسألون ما هو الخطأ إذا كان المستخدم غير راضٍ.
من التقارير ، كانت هناك قصة مثيرة للاهتمام حول chatbot الصينية من مايكروسوفت.
تصميم وتنفيذ XiaoIce ، chatbot الاجتماعية متعاطفةالصين هي بالفعل واحدة من الشركات الرائدة في تقديم تقنيات الذكاء الاصطناعي. لكن غالبًا ما يحدث في الصين غير معروف جيدًا في أوروبا. و XiaoIce هو مشروع مذهل. إنه موجود بالفعل لمدة خمس سنوات. ليس هناك الكثير من مواقع الدردشة في هذا العصر تعمل حاليًا. في عام 2018 ، كان لديه بالفعل 660 مليون مستخدم.
يحتوي النظام على كلٍّ من برنامج chit-chat ونظام المهارات. لدى الروبوت بالفعل 230 مهارات ، أي أنهم يضيفون مهارة واحدة تقريبًا كل أسبوع.
لتقييم جودة برنامج chit-chat ، يستخدمون مدة الحوار. وليس في دقائق ، كما يحدث في كثير من الأحيان ، ولكن في عدد النسخ المتماثلة في محادثة. يسمون هذا المقياس المتناوب لكل جلسة (CPS) ويكتبون في الوقت الحالي أن متوسط قيمته 23 ، وهو أفضل مؤشر بين الأنظمة المماثلة.
بشكل عام ، يحظى المشروع بشعبية كبيرة في الصين. بالإضافة إلى الروبوت نفسه ، يكتب النظام الشعر ، يرسم الصور ،
يصدر مجموعة من الملابس ، يغني الأغاني.
الترجمة الآلية
من بين كل الخطب التي حضرتها ، كان الأكثر حيوية هو تقرير
الترجمة الفورية الذي قدمه ليانغ هوانغ ، الذي يمثل بايدو للأبحاث.
تحدث عن مثل هذه الصعوبات في الترجمة المتزامنة الحديثة:
- لا يوجد سوى 3000 مترجم فوري معتمد في العالم.
- يمكن للمترجمين العمل فقط 15-20 دقيقة متواصلة.
- يتم ترجمة حوالي 60٪ فقط من النص المصدر.
وصلت الترجمة على الجمل الكاملة إلى مستوى جيد بالفعل ، ولكن بالنسبة للترجمة الفورية ، لا يزال هناك مجال للتحسين. على سبيل المثال ، ذكر نظام الترجمة الفورية الخاص بهم ، والذي كان يعمل في مؤتمر بايدو العالمي. تم تقليل التأخير في الترجمة في عام 2018 مقارنة بعام 2017 من 10 إلى 3 ثوان.
لا يوجد العديد من الفرق التي تقوم بذلك ، وهناك عدد قليل من أنظمة العمل. على سبيل المثال ، عندما تترجم Google العبارة التي تكتبها عبر الإنترنت ، فإنها تُعيد صياغة العبارة الأخيرة باستمرار. وهذه ليست ترجمة فورية ، لأنه مع الترجمة الفورية لا يمكننا تغيير الكلمات التي سبق ذكرها.

في نظامهم ، يستخدمون ترجمة بادئة - جزء من عبارة. أي أنهم ينتظرون بضع كلمات ويبدأوا في الترجمة ويحاولون تخمين ما سيظهر في المصدر. يتم قياس حجم هذا التحول بالكلمات وهو قابل للتكيف. بعد كل خطوة ، يقرر النظام ما إذا كان الأمر يستحق الانتظار أم أنه يمكن ترجمته بالفعل. لتقييم هذا التأخير ، يقدمون المقياس التالي:
metric of Average Lagging (AL) .
الصعوبة الرئيسية في الترجمة الفورية هي اختلاف ترتيب الكلمات باللغات. والسياق يساعد في محاربة هذا. على سبيل المثال ، تحتاج غالبًا إلى ترجمة خطب السياسيين ، وهي نمطية تمامًا. ولكن هناك أيضا مشاكل. ثم مازحا المتحدث عن ترامب. لذلك ، كما يقول ، إذا سافر بوش إلى موسكو ، فمن المحتمل جدًا أن يقابل بوتين. وإذا قام ترامب بالطيران إلى هناك ، فيمكنه الالتقاء بلعب الجولف. بشكل عام ، عند الترجمة ، غالبًا ما يأتي الأشخاص ، يضيفون شيئًا من أنفسهم. ودعنا نقول ، إذا كنت بحاجة إلى ترجمة نوع من النكتة ، ولا يمكنهم القيام بذلك على الفور ، فيمكنهم أن يقولوا: "قيل نكتة هنا ، فقط اضحك".
كان هناك أيضًا مقال عن الترجمة الآلية التي حصلت على جائزة "أفضل ورقة طويلة":
سد الفجوة بين التدريب والاستدلال على الترجمة الآلية العصبية .
وهو يصف مشكلة الترجمة الآلية هذه. في عملية التعلم ، نقوم بإنشاء ترجمة للكلمة بناءً على سياق الكلمات المعروفة. في عملية استخدام النموذج ، نعتمد على سياق الكلمات التي تم إنشاؤها حديثًا. هناك تباين بين تدريب النموذج واستخدامه.
لتقليل هذا التناقض ، يقترح المؤلفون في مرحلة التدريب في السياق خلط الكلمات التي تنبأ بها النموذج أثناء التدريب. تتناول المقالة الاختيار الأمثل لهذه الكلمات التي تم إنشاؤها.
استنتاج
بالطبع ، ليس المؤتمر مجرد مقالات وتقارير. بل هو أيضا التواصل والتعارف والشبكات الأخرى. بالإضافة إلى ذلك ، يحاول منظمو المؤتمرات ترفيه المشاركين بطريقة أو بأخرى. في دوري أبطال آسيا ، في الحفلة الرئيسية ، كان هناك أداء للمغتربين ، إيطاليا بعد كل شيء. لتلخيص ، كانت هناك إعلانات من منظمي المؤتمرات الأخرى. وكان رد الفعل الأكثر عنفا بين المشاركين هو رسائل من منظمي EMNLP مفادها أن الحزب الرئيسي سيكون هذا العام في ديزني لاند هونج كونج ، وفي عام 2020 سيعقد المؤتمر في جمهورية الدومينيكان.