
في هذه المقالة ، أريد أن أقدم بديلاً عن أسلوب تصميم الاختبار التقليدي باستخدام مفاهيم البرمجة الوظيفية لـ Scala. استلهم هذا النهج من عدة أشهر من الألم من دعم عشرات ومئات من اختبارات السقوط والرغبة الشديدة لجعلها أسهل وأكثر قابلية للفهم.
على الرغم من حقيقة أن الكود مكتوب في سكالا ، فإن الأفكار المقترحة ستكون ذات صلة للمطورين والمختبرين بجميع اللغات التي تدعم نموذج البرمجة الوظيفية. يمكنك العثور على رابط لـ Github مع الحل الكامل والمثال في نهاية المقالة.
المشكلة
إذا سبق لك أن تعاملت مع الاختبارات (لا يهم - اختبارات الوحدات ، أو التكامل ، أو الوظيفية) ، فمن المحتمل أن تكون مكتوبة كمجموعة من التعليمات المتسلسلة. على سبيل المثال:
هذا هو المفضل بالنسبة لمعظم ، لا تتطلب التطوير ، وسيلة لوصف الاختبارات. يحتوي مشروعنا على حوالي 1000 اختبار بمستويات مختلفة (اختبارات الوحدات ، اختبارات التكامل ، من البداية إلى النهاية) ، وكلها ، حتى وقت قريب ، كانت مكتوبة بأسلوب مماثل. مع نمو المشروع ، بدأنا نشعر بمشاكل كبيرة وتباطؤ بدعم من مثل هذه الاختبارات: استغرق وضع الاختبارات في النظام وقتًا أقل من كتابة التعليمات البرمجية ذات الصلة بالأعمال.
عند كتابة اختبارات جديدة ، كان عليك دائمًا التفكير من نقطة الصفر في كيفية إعداد البيانات. في كثير من الأحيان نسخ لصق الخطوات من الاختبارات المجاورة. نتيجة لذلك ، عندما تغير نموذج البيانات في التطبيق ، انهارت مجموعة البطاقات وتعين تجميعها بطريقة جديدة في كل اختبار: في أحسن الأحوال ، مجرد تغيير في وظائف المساعدين ، في أسوأ الأحوال - غمر عميق في الاختبار وإعادة كتابته.
عندما تعطل الاختبار بصدق - وهذا بسبب وجود خطأ في منطق العمل ، وليس بسبب مشاكل في الاختبار نفسه - لفهم أين حدث خطأ ما ، دون تصحيح الأخطاء ، كان من المستحيل. نظرًا لحقيقة أن الأمر استغرق وقتًا طويلاً لفهم الاختبارات ، لم يكن لدى أحد معرفة كاملة بالمتطلبات - كيف ينبغي أن يتصرف النظام في ظل ظروف معينة.
كل هذا الألم هو عرض لمشكلتين أعمق من هذا التصميم:
- يُسمح بمحتويات الاختبار بشكل فضفاض للغاية. كل اختبار فريد من نوعه ، مثل ندفة الثلج. إن الحاجة إلى قراءة تفاصيل الاختبار تستغرق الكثير من الوقت وتثبط من قدرتها. التفاصيل غير المهمة تصرف الانتباه عن الشيء الرئيسي - المتطلبات التي تم التحقق منها بواسطة الاختبار. نسخ لصق أصبح الطريق الرئيسي لكتابة حالات اختبار جديدة.
- لا تساعد الاختبارات المطور على توطين الأخطاء ، ولكن فقط تشير إلى وجود مشكلة. لفهم الحالة التي يتم بها إجراء الاختبار ، تحتاج إلى استعادته في رأسك أو الاتصال بمصحح أخطاء.
تصميم
هل يمكننا أن نفعل ما هو أفضل؟ (المفسد: يمكننا.) دعونا ننظر في ما يتكون هذا الاختبار من.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
سوف تنتظر الشفرة التي تم اختبارها ، كقاعدة عامة ، إدخال بعض المعلمات الواضحة - معرفات وأحجام ووحدات تخزين وعوامل تصفية وما إلى ذلك أيضًا ، ستحتاج غالبًا إلى بيانات من العالم الواقعي - نرى أن التطبيق يشير إلى القوائم وقوالب القوائم قاعدة البيانات. لتنفيذ اختبار موثوق ، نحتاج إلى تثبيت - الحالة التي يجب أن يكون فيها النظام و / أو موفري البيانات قبل بدء الاختبار ومعلمات الإدخال ، المرتبطة غالبًا بالحالة.
سنقوم بإعداد التبعيات مع هذه المباراة - املأ قاعدة البيانات (قائمة الانتظار ، الخدمة الخارجية ، وما إلى ذلك). باستخدام التبعية المُعدة ، نهيئ الفصل الذي تم اختباره (الخدمات ، الوحدات ، المستودعات ، إلخ).
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
من خلال تنفيذ رمز الاختبار على بعض معلمات الإدخال ، نحصل على نتيجة مهمة ( مخرجات ) خاصة بالعمل - صريحة (يتم إرجاعها بواسطة الطريقة) وضمنية - تغيير في الحالة سيئة السمعة: قاعدة البيانات ، والخدمة الخارجية ، إلخ.
result shouldBe 90
أخيرًا ، نتحقق من أن النتائج هي بالضبط ما توقعوه ، حيث نلخص الاختبار بتأكيد واحد أو أكثر.
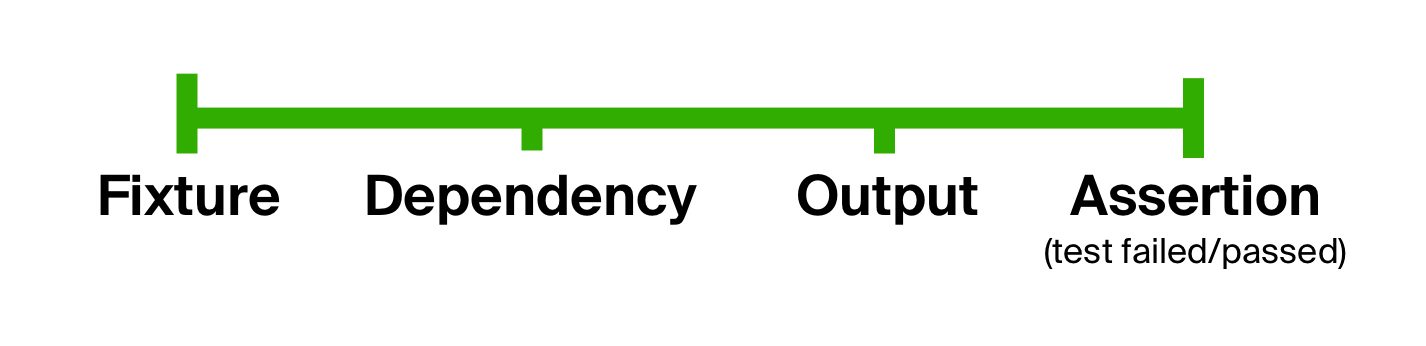
يمكن أن نخلص إلى أن الاختبار يتكون عمومًا من نفس المراحل: إعداد معلمات الإدخال ، تنفيذ رمز الاختبار عليها ، ومقارنة النتائج مع المعلمات المتوقعة. يمكننا استخدام هذه الحقيقة للتخلص من المشكلة الأولى في الاختبار - شكل فضفاض للغاية ، ونقسم الاختبار بوضوح إلى مراحل. هذه الفكرة ليست جديدة وقد استخدمت منذ فترة طويلة في الاختبارات في نمط BDD ( تطوير يحركه السلوك ).
ماذا عن القابلية للتوسعة؟ يمكن أن تحتوي أي من الخطوات في عملية الاختبار على أكبر عدد تريده من الخطوات الوسيطة. إذا نظرنا إلى الأمام ، يمكننا أن نؤسس لاعبا أساسيا ، أولا إنشاء نوع من الهياكل القابلة للقراءة البشرية ، ثم تحويله إلى كائنات تملأ قاعدة البيانات. إن عملية الاختبار قابلة للتوسيع بشكل لا نهائي ، ولكن في النهاية ، فإنها تأتي دائمًا إلى المراحل الرئيسية.

تشغيل الاختبارات
دعونا نحاول أن ندرك فكرة تقسيم الاختبار إلى مراحل ، لكننا أولاً نحدد كيف نود أن نرى النتيجة النهائية.
بشكل عام ، نريد أن نجعل اختبارات الكتابة والدعم عملية أقل كثافة في العمل وأكثر متعة. الإرشادات الأقل وضوحًا غير الفريدة (المكررة في مكان آخر) في نص الاختبار ، ستحتاج إلى إجراء تغييرات أقل على الاختبارات بعد تغيير العقود أو إعادة البناء وتقليل الوقت الذي يستغرقه قراءة الاختبار. يجب أن يشجع تصميم الاختبار على إعادة استخدام القطع البرمجية المستخدمة بكثرة ومنع النسخ الطائش. سيكون جميلا لو كانت الاختبارات لها نظرة موحدة. تعمل القدرة على التنبؤ على تحسين قابلية القراءة وتوفير الوقت - تخيل كم من الوقت سيستغرق طلاب الفيزياء لإتقان كل صيغة جديدة إذا تم وصفها في كلمات ذات شكل حر بدلاً من لغة رياضية.
وبالتالي ، فإن هدفنا هو إخفاء كل شيء يشتت انتباهك ولا لزوم له ، ولا يترك سوى المعلومات المهمة لفهم التطبيق: ما الذي تم اختباره ، وما هو متوقع في المدخلات ، وما هو متوقع في الإخراج.
دعنا نعود إلى نموذج جهاز الاختبار. من الناحية الفنية ، يمكن تمثيل كل نقطة في هذا الرسم البياني بنوع البيانات ، والانتقالات من وظيفة إلى أخرى - وظائف. يمكنك الانتقال من نوع البيانات الأولي إلى النوع الأخير من خلال تطبيق الوظيفة التالية على نتيجة النوع السابق تلو الآخر. بمعنى آخر ، باستخدام مجموعة من الوظائف : إعداد البيانات (دعنا نسميها prepare ) ، تنفيذ رمز الاختبار ( execute ) والتحقق من النتيجة المتوقعة ( check ). سنقوم بتمرير النقطة الأولى من المخطط ، لاعتبارها ، لمدخلات هذا التكوين. وتسمى وظيفة الترتيب العالي الناتجة دورة اختبار الحياة .
وظيفة دورة الحياة def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
السؤال هو ، من أين تأتي الوظائف الداخلية؟ سنقوم بإعداد البيانات بعدد محدود من الطرق - لملء قاعدة البيانات ، والتبلل ، وما إلى ذلك - وبالتالي ، فإن خيارات وظيفة التحضير ستكون مشتركة في جميع الاختبارات. نتيجة لذلك ، سيكون من الأسهل إنشاء وظائف دورة حياة متخصصة تخفي تنفيذًا محددًا لإعداد البيانات. نظرًا لأن طرق استدعاء الرمز الجاري التحقق منه وفحصه تعد فريدة نسبيًا لكل اختبار ، فسيتم توفير execute check بشكل صريح.
وظيفة دورة حياة تتكيف مع اختبارات التكامل في قاعدة البيانات من خلال تفويض جميع الفروق الدقيقة في وظيفة دورة الحياة ، سنحصل على فرصة لتوسيع عملية الاختبار دون الدخول في أي اختبار مكتوب بالفعل. نظرًا للتكوين ، يمكننا التسلل إلى أي مكان في العملية أو استخراج أو إضافة بيانات هناك.
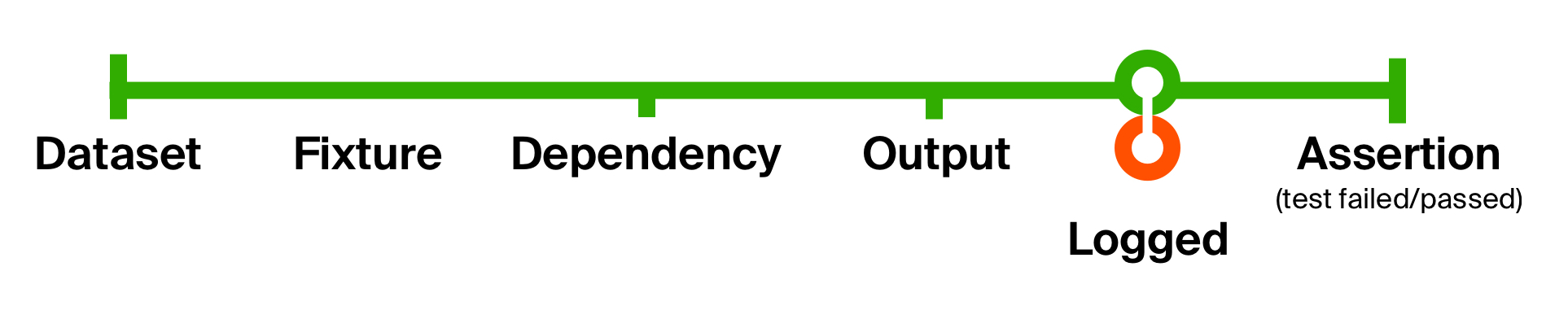
لتوضيح إمكانيات هذا النهج بشكل أفضل ، سنحل المشكلة الثانية المتمثلة في اختبارنا الأولي - عدم وجود معلومات داعمة لتوطين المشكلات. إضافة تسجيل عند تلقي استجابة من الطريقة المختبرة. لن يغير التسجيل الخاص بنا نوع البيانات ، ولكن سيؤدي فقط إلى إحداث تأثير جانبي - عرض رسالة على وحدة التحكم. لذلك ، بعد التأثير الجانبي ، سنعود عليه كما هو.
تسجيل وظيفة دورة حياة def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
مع مثل هذه الحركة البسيطة ، أضفنا تسجيل النتيجة التي تم إرجاعها وحالة قاعدة البيانات في كل اختبار . ميزة هذه الوظائف الصغيرة هي أنها سهلة الفهم ، وسهلة التأليف لإعادة الاستخدام ، وسهل التخلص منها إذا لم تعد هناك حاجة إليها.

نتيجة لذلك ، سيبدو اختبارنا كما يلي:
val fixture: SomeMagicalFixture = ???
لقد أصبح نص الاختبار مقتضبًا ، ويمكن إعادة استخدام التركيبات والشيكات في اختبارات أخرى ، ونحن لا نعد قاعدة البيانات يدويًا في أي مكان آخر. تبقى مشكلة واحدة فقط ...
إعداد المباراة
في الكود أعلاه ، استخدمنا الافتراض بأن التركيب سوف يأتي من مكان جاهز وأنه يحتاج فقط إلى نقله إلى وظيفة دورة الحياة. نظرًا لأن البيانات عنصر أساسي في الاختبارات البسيطة المدعومة ، لا يمكننا إلا أن نتطرق إلى كيفية تكوينها.
لنفترض أن متجرنا التجريبي لديه قاعدة بيانات نموذجية متوسطة الحجم (للبساطة ، مثال على 4 جداول ، ولكن في الواقع قد يكون هناك المئات). يحتوي الجزء على معلومات أساسية وجزء - أعمال مباشرة ، ويمكن توصيله معًا في العديد من الكيانات المنطقية الكاملة. ترتبط الجداول بالمفاتيح (مفاتيح خارجية ) - لإنشاء كيان Bonus ، تحتاج إلى كيان Package ، وهو بدوره User . و هكذا.

ظروف قيود الدائرة وجميع أنواع الخارقة تؤدي إلى تناقض ، ونتيجة لذلك ، لاختبار عدم الاستقرار وساعات من التصحيح مثيرة. لهذا السبب ، سوف نملأ قاعدة البيانات بأمانة.
يمكننا استخدام الأساليب العسكرية لملء الفراغ ، ولكن حتى مع الفحص السطحي لهذه الفكرة ، تثور أسئلة صعبة كثيرة. ما الذي سيعد البيانات في اختبارات هذه الأساليب نفسها؟ هل سأحتاج إلى إعادة كتابة الاختبارات إذا تغير العقد؟ ماذا لو تم تسليم البيانات بواسطة تطبيق غير مختبر (على سبيل المثال ، الاستيراد من قبل شخص آخر)؟ ما عدد الاستعلامات المختلفة التي يجب القيام بها من أجل إنشاء كيان يعتمد على العديد من الاستعلامات الأخرى؟
ملء القاعدة في الاختبار الأولي insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
طرق المساعدة المتناثرة ، كما في المثال الأصلي ، هي نفس المشكلة ، ولكن مع صلصة مختلفة. يعينون مسؤولية إدارة الكائنات التابعة وعلاقاتهم بأنفسنا ، ونود تجنب ذلك.
من الناحية المثالية ، أرغب في الحصول على هذا النوع من البيانات ، نظرة واحدة تكفي لفهم الشروط العامة للنظام الذي سيخضع له أثناء الاختبار. أحد الجداول الجيدة لتصور الحالة هو جدول (مجموعة بيانات في PHP و Python) ، حيث لا يوجد شيء غير ضروري باستثناء الحقول المهمة لمنطق العمل. إذا تغير منطق العمل في إحدى الميزات ، فسيتم تقليل كل دعم الاختبار إلى تحديث الخلايا في مجموعة البيانات. على سبيل المثال:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
من طاولتنا ، سنقوم بإنشاء علاقات - علاقات الكيان بواسطة المعرف. في هذه الحالة ، إذا كان الكيان يعتمد على آخر ، سيتم تشكيل مفتاح التبعية. قد يحدث قيام كيانين مختلفين بإنشاء تبعية بنفس المعرف ، مما قد يؤدي إلى انتهاك التقييد على المفتاح الأساسي لقاعدة البيانات ( المفتاح الأساسي ). ولكن في هذه المرحلة ، تكون البيانات رخيصة للغاية لإلغاء التكرار - بما أن المفاتيح تحتوي على معرفات فقط ، فيمكننا وضعها في مجموعة توفر إلغاء البيانات المكررة ، على سبيل المثال ، في Set . إذا كان هذا غير كافٍ ، فيمكننا دائمًا إجراء إلغاء البيانات المكررة بشكل أكثر ذكاءً في شكل وظيفة إضافية يتم تجميعها في وظيفة دورة الحياة.
مثال رئيسي sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
نقوم بتفويض إنشاء محتوى مزيف إلى حقول (على سبيل المثال ، أسماء) إلى فصل منفصل. بعد ذلك ، باللجوء إلى مساعدة هذه الفئة وقواعد تحويل المفاتيح ، نحصل على كائنات سلسلة مخصصة مباشرةً لإدراجها في قاعدة البيانات.
مثال الخط object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
البيانات المزيفة الافتراضية ، كقاعدة عامة ، لن تكون كافية بالنسبة لنا ، لذلك سنحتاج إلى إعادة تعريف حقول محددة. يمكننا استخدام العدسات - تشغيل جميع الخطوط التي تم إنشاؤها وتغيير حقول فقط تلك المطلوبة. لأن العدسات في النهاية هي وظائف عادية ، يمكن تركيبها ، وهذه هي فائدتها.
مثال العدسة def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
بفضل التكوين ، ضمن العملية بأكملها ، يمكننا تطبيق تحسينات وتحسينات متعددة - على سبيل المثال ، صفوف المجموعة في الجداول بحيث يمكن إدراجها insert واحد ، أو تقليل وقت الاختبار ، أو تأمين الحالة النهائية لقاعدة البيانات لتبسيط مشاكل الالتقاط.
وظيفة تشكيل المباراة def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
جميعنا سيمنحنا تركيبات تملأ التبعية للاختبار - قاعدة البيانات. في الاختبار نفسه ، لن يتم عرض أي شيء غير ضروري ، باستثناء مجموعة البيانات الأصلية - سيتم إخفاء جميع التفاصيل داخل تكوين الوظائف.

ستبدو مجموعة الاختبار الآن كما يلي:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) " -" - { "'customer'" - { " " - { "< 250 - " - { "(: )" in calculatePriceFor(dataTable, 1) "(: )" in calculatePriceFor(dataTable, 3) } ">= 250 " - { " - 10% " in calculatePriceFor(dataTable, 2) " - 10% " in calculatePriceFor(dataTable, 4) } } } "'vip' - 20% , " in calculatePriceFor(dataTable, 5) }
كود المساعد:
تصبح إضافة حالات اختبار جديدة إلى الجدول مهمة تافهة ، مما يسمح لك بالتركيز على تغطية الحد الأقصى لعدد الحالات الحدودية ، بدلاً من التركيز على لوحة.
إعادة استخدام رمز إعداد لاعبا اساسيا في مشاريع أخرى
حسنًا ، لقد كتبنا الكثير من التعليمات البرمجية لإعداد التركيبات في مشروع محدد واحد ، وقضاء الكثير من الوقت في هذا. ماذا لو كان لدينا العديد من المشاريع؟ هل محكوم علينا إعادة اختراع العجلة ونسخها في كل مرة؟
يمكننا أن نستخلص إعداد التركيبات من نموذج مجال معين. في عالم FP ، هناك مفهوم typeclass . باختصار ، لا تعد typeclasses فئات من OOP ، ولكن شيئًا مثل الواجهات ، فهي تحدد سلوك مجموعة من النوع. الفرق الأساسي هو أن هذه المجموعة من الأنواع لا يتم تحديدها عن طريق الميراث الطبقي ، ولكن عن طريق إنشاء مثيل ، مثل المتغيرات العادية. كما هو الحال مع الميراث ، يحدث حل مثيلات أنواع الفئات (عبر التورط ) بشكل ثابت ، في مرحلة الترجمة. من أجل البساطة ، ولأغراضنا ، يمكن التفكير في الطباعة على أنها امتدادات من Kotlin و C # .
لتعهد كائن ، لا نحتاج إلى معرفة ما يحتويه هذا الكائن في الداخل ، وما هي الحقول والأساليب الموجودة به. من المهم فقط بالنسبة لنا تحديد سلوك log مع توقيع معين لذلك. سيكون من Logged تطبيق واجهة Logged معينة في كل فصل ، ولن يكون ذلك ممكنًا دائمًا - على سبيل المثال ، في المكتبة أو الفصول القياسية. في حالة الطباعة على الآلة الكاتبة ، كل شيء أبسط بكثير. يمكننا إنشاء مثيل لـ Logged ، على سبيل المثال ، للتركيبات ، وعرضها في شكل قابل للقراءة. ولجميع الأنواع الأخرى ، قم بإنشاء مثيل لـ Any type واستخدم طريقة toString القياسية لتسجيل أي كائنات في تمثيلها الداخلي مجانًا.
مثال للفئة الموسومة ومثيلاتها trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
بالإضافة إلى قطع الأشجار ، يمكننا توسيع هذا النهج ليشمل كامل عملية إعداد التركيبات. سيقدم حل الاختبار نظراته الزمنية الخاصة والتطبيق التجريدي للوظائف المستندة إليها. مسؤولية المشروع الذي يستخدمه هو كتابة نسخة خاصة به من أنواع الحروف لأنواعها.
عند تصميم مولد التثبيت ، ركزت على تنفيذ مبادئ البرمجة وتصميم SOLID كمؤشر على ثباتها وقدرتها على التكيف مع الأنظمة المختلفة:
- مبدأ المسئولية الفردية : يصف كل نوع من أنواع الرموز نوعًا واحدًا تمامًا من سلوك النوع.
- The Open Closed Principle : نحن لا نقوم بتعديل نوع القتال الحالي للاختبارات ، بل نوسعه مع مثيلات tyclasses.
- مبدأ Liskov البديل لا يهم في هذه الحالة ، لأننا لا نستخدم الميراث.
- مبدأ فصل الواجهة : نستخدم العديد من الإطارات الزمنية المتخصصة بدلاً من واحدة عالمية.
- مبدأ انعكاس التبعية : لا يعتمد تطبيق مولد المباريات على أنواع قتال محددة ، ولكن على أطر زمنية مجردة.
بعد التأكد من استيفاء جميع المبادئ ، يمكن القول أن حلنا يبدو مدعومًا وقابل للتوسيع بشكل كاف لاستخدامه في مشاريع مختلفة.
بعد كتابة وظائف دورة الحياة ، وتوليد التركيبات ، وتحويل مجموعات البيانات إلى تركيبات ، وكذلك الاستخلاص من نموذج مجال معين للتطبيق ، أصبحنا جاهزون أخيرًا لتوسيع نطاق حلنا لجميع الاختبارات.
النتائج
انتقلنا من النمط التقليدي (خطوة بخطوة) لتصميم الاختبار إلى التصميم الوظيفي. يعتبر أسلوب خطوة بخطوة جيدًا في المراحل المبكرة والمشاريع الصغيرة من حيث أنه لا يتطلب عمالة إضافية ولا يحد من المطور ، ولكنه يبدأ في الخسارة عندما يكون هناك الكثير من الاختبارات على المشروع. لم يتم تصميم النمط الوظيفي لحل جميع المشكلات في الاختبار ، ولكنه يمكن أن يسهل إلى حد كبير توسيع نطاق ودعم الاختبارات في المشاريع التي يكون عددها فيها بالمئات أو الآلاف. تعد اختبارات الأنماط الوظيفية أكثر إحكاما وتركز على ما هو مهم حقًا (البيانات ، كود الاختبار والنتيجة المتوقعة) ، وليس على الخطوات المتوسطة.
بالإضافة إلى ذلك ، نظرنا إلى مثال حي على مدى قوة مفاهيم التكوين و typeclasses في البرمجة الوظيفية. من خلال مساعدتهم ، من السهل تصميم حلول ، جزء لا يتجزأ منها هو القابلية للتوسعة وإعادة الاستخدام.
, , , . , , , -. , . !
: Github