بيانات السلاسل الزمنية أو السلاسل الزمنية هي بيانات تتغير بمرور الوقت. أسعار العملات ، والقياس عن حركات النقل ، وإحصاءات الوصول إلى الخادم أو تحميل وحدة المعالجة المركزية هي بيانات سلسلة زمنية. لتخزينها يتطلب أدوات محددة - قواعد البيانات الزمنية. هناك العشرات من الأدوات ، على سبيل المثال ، InfluxDB أو ClickHouse. ولكن حتى أفضل حلول تخزين السلاسل الزمنية لها عيوب. جميع وحدات تخزين السلاسل الزمنية منخفضة المستوى ، وهي مناسبة فقط لبيانات السلاسل الزمنية ، كما أن تشغيل وحقن المكدس الحالي أمر مكلف ومؤلم.

ولكن ، إذا كان لديك مكدس PostgreSQL ، يمكنك نسيان InfluxDB وجميع قواعد البيانات الزمنية الأخرى. تثبيت ملحقين ، TimescaleDB و PipelineDB ، وتخزين ومعالجة وتحليل بيانات السلاسل الزمنية مباشرة في نظام PostgreSQL البيئي. بدون تقديم حلول جهة خارجية ، وبدون عيوب المستودعات الزمنية ودون مشاكل تشغيلها. ما هي هذه الامتدادات ، ما هي مزاياها وقدراتها ، سوف تخبر
إيفان موراتوف ( بيناكوت ) - رئيس قسم التطوير في "شركة المراقبة الأولى".
ما هي بيانات السلاسل الزمنية أو السلاسل الزمنية؟
هذه هي البيانات حول العملية التي يتم جمعها في نقاط مختلفة في حياته.
على سبيل المثال ، موقع السيارة: السرعة ، الإحداثيات ، الاتجاه ، أو استخدام الموارد على الخادم مع البيانات المتعلقة بالتحميل على وحدة المعالجة المركزية ، واستخدام ذاكرة الوصول العشوائي ومساحة القرص الحرة.
سلسلة زمنية لها العديد من الميزات.
- في تحديد حزام . يحتوي أي سجل سلسلة زمنية على حقل ذو طابع زمني تم تسجيل القيمة به.
- خصائص العملية ، والتي تسمى مستويات السلسلة : السرعة ، الإحداثيات ، تحميل البيانات.
- دائما تقريبا مع هذه البيانات التي يعملون في وضع إلحاقي فقط . هذا يعني أن البيانات الجديدة لا تحل محل القديم. يتم حذف البيانات القديمة فقط.
- لا يتم اعتبار الإدخالات بشكل منفصل عن بعضها البعض . يتم استخدام البيانات بشكل جماعي فقط للنوافذ الزمنية أو الفواصل الزمنية.
حلول التخزين الشعبية
يوضح الرسم البياني الذي أخذته من موقع
db-engines.com شعبية نماذج التخزين المختلفة على مدار العامين الماضيين.
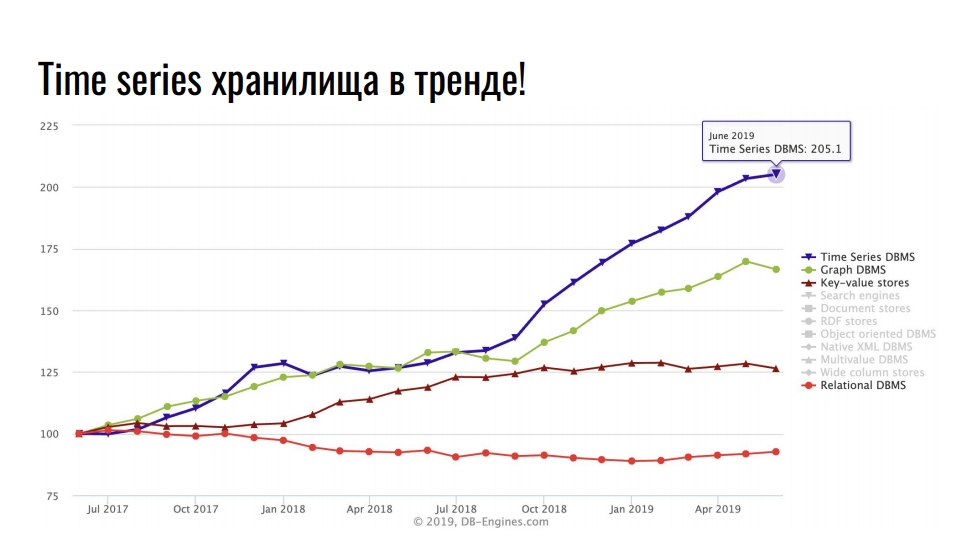
يحتل المركز الأول مواقع تخزين السلاسل الزمنية ، في المقام الثاني - قواعد بيانات الرسم البياني ، ثم - قواعد البيانات ذات القيمة الأساسية وعلائقية. ترتبط شعبية المستودعات المتخصصة بالنمو المكثف في تكامل تقنيات المعلومات: البيانات الكبيرة ، والشبكات الاجتماعية ، إنترنت الأشياء ، ومراقبة البنية التحتية عالية التحميل. بالإضافة إلى البيانات التجارية المفيدة ، حتى السجلات والمقاييس تستهلك قدرًا هائلاً من الموارد.
حلول التخزين الشائعة لبيانات السلاسل الزمنية
يعرض الرسم البياني حلولًا متخصصة لتخزين بيانات السلاسل الزمنية. المقياس لوغاريتمي.
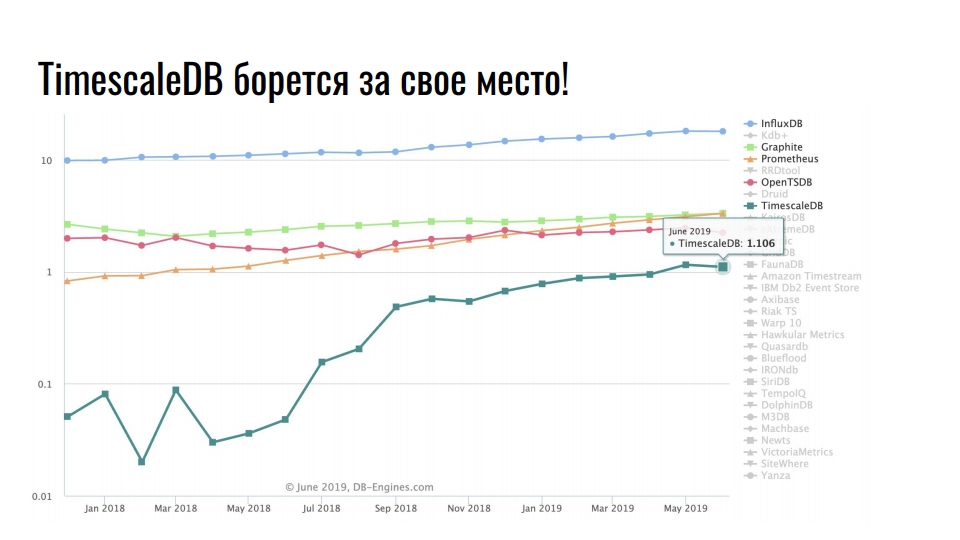
زعيم مستقر InfluxDB. كل من صادف بيانات السلاسل الزمنية سمع عن هذا المنتج. لكن الرسم البياني يظهر زيادة بمقدار عشرة أضعاف في TimescaleDB - يقاتل امتداد لقواعد بيانات إدارة قواعد البيانات (DBMS) من أجل الحصول على مكان تحت أشعة الشمس بين المنتجات التي تم تطويرها في الأصل في إطار السلسلة الزمنية.
PostgreSQL ليست مجرد قاعدة بيانات جيدة ، ولكنها أيضًا منصة قابلة للتوسع لتطوير حلول متخصصة.
بوستجرس ، بوستجيس ، وتيميسكالي دي بي
تقوم شركة First First Monitor بمراقبة حركة المركبات باستخدام الأقمار الصناعية. نحن نتتبع 20000 سيارة ونخزن بيانات الحركة لمدة عامين. في المجموع ، لدينا 10 تيرابايت من بيانات القياس عن بعد الحالية. في المتوسط ، ترسل كل سيارة 5 سجلات عن بُعد في الدقيقة أثناء القيادة. يتم إرسال البيانات عبر معدات الملاحة إلى خوادمنا عن بعد. يتلقونها 500 حزمة التنقل في الثانية الواحدة.
منذ بعض الوقت ، قررنا ترقية البنية التحتية عالميًا والانتقال من متراصة إلى الخدمات الصغيرة. أطلقنا على النظام الجديد Waliot ، وهو بالفعل قيد الإنتاج - يتم نقل 90 ٪ من جميع المركبات إليه.
لقد تغير الكثير في البنية التحتية ، لكن الارتباط المركزي لم يتغير - هذه هي قاعدة بيانات PostgreSQL. نعمل الآن على الإصدار 10 ونستعد للانتقال إلى 11. بالإضافة إلى PostgreSQL ، باعتباره التخزين الرئيسي ، في المجموعة نستخدم PostGIS للحوسبة الجغرافية المكانية ، و TimescaleDB لتخزين مجموعة كبيرة من بيانات السلاسل الزمنية.
لماذا PostgreSQL؟
لماذا نحاول استخدام قاعدة بيانات علائقية لتخزين السلاسل الزمنية ، بدلاً من حلول
ClickHouse المتخصصة لنوع البيانات هذا؟ نظرًا لخلفية الخبرة المتراكمة وانطباعات العمل مع PostgreSQL ، لا نريد استخدام حل غير معروف باعتباره التخزين الرئيسي.
التحول إلى حل جديد يمثل مخاطرة.
هناك العديد من الحلول المتخصصة لتخزين ومعالجة بيانات السلاسل الزمنية. الوثائق ليست دائما كافية ، ومجموعة كبيرة من الحلول ليست دائما جيدة. يبدو أن مطوري كل منتج جديد يريدون كتابة كل شيء من البداية ، لأن شيئًا ما لم يكن لطيفًا في الحل السابق. لفهم ما لم يعجبه بالضبط ، عليك البحث عن المعلومات وتحليلها ومقارنتها. مجموعة كبيرة متنوعة من
القمم والتقييمات والمقارنات مخيفة إلى حد ما من تحفيز تجربة شيء ما. سيكون عليك قضاء الكثير من الوقت لتجربة كل الحلول على نفسك. لا يمكننا تحمل تكيف واحد فقط لعدة أشهر. هذه مهمة صعبة ، والوقت المستغرق لن يؤتي ثماره. لذلك ، اخترنا امتدادات لـ PostgreSQL.
خلال مرحلة تطوير البنية التحتية لـ Waliot ، اعتبرنا InfluxDB المستودع الرئيسي للقياس عن بُعد. ولكن عندما صادفت TimescaleDB وأجريت اختبارات عليه ، لم تكن هناك أسئلة حول الاختيار. يسمح لك PostgreSQL بملحق TimescaleDB باستخدام ملحقات أخرى في نفس تخزين PostGIS أو PipelineDB. لسنا بحاجة لسحب البيانات وتحويلها وإجراء التحليلات ونقلها عبر الشبكة. كل شيء يكمن في خادم واحد أو في نظام متفاوت المسافات - لا يلزم سحب البيانات. يتم تنفيذ جميع الحسابات في نفس المستوى.
في الآونة الأخيرة ، قام
نيكولاي ساموخفالوف ، مؤلف حساب postgresmen ،
بنشر رابط لمقال مثير للاهتمام حول استخدام SQL لمعالجة تدفق البيانات. يشارك خمسة من كل ستة من مؤلفي المقال في تطوير منتجات Apache المختلفة ويعملون على معالجة الدفق. لذلك ، تذكر المقالة Apache Spark و Apache Flink و Apache Beam و Apache Calcite و KSQL من Confluent.
لكن ليس المقال في حد ذاته مثيرًا للاهتمام ، ولكن
موضوع "أخبار هاكر" ، الذي تمت مناقشته فيه. يكتب مؤلف الموضوع أنه بناءً على المقال ، قام بتنفيذ جميع الأفكار تقريبًا استنادًا إلى PostgreSQL 11. واستخدم امتدادات CitusDB للتحجيم والمشاركة الأفقيين ، PipelineDB لحوسبة الدفق وطرق العرض الملموسة ، TimescaleDB لتخزين بيانات السلاسل الزمنية والمقاطع. كما أنه يستخدم العديد من أغلفة البيانات الخارجية.
مزيج مجنون من PostgreSQL وملحقاته يؤكد مرة أخرى أن PostgreSQL ليس مجرد DBMS - بل هو منصة.
وعندما يتم تسليم التخزين القابل للتوصيل ... Ugh!
ومن المفارقات ، عند البحث عن الحلول ، وجدنا
Outflux ، تطوير فريق TimescaleDB ، الذي
نشروه في 1 أبريل. ما رأيك انها تفعل؟ هذه أداة مساعدة للترحيل من InfluxDB إلى TimescaleDB في أمر واحد ...
بوستجرس الضجيج!
لا نقلل من قوة الضجيج! نمزح غالبًا إلى أن "التطوير مدفوعًا بالضجيج" لأنه يؤثر على تصوراتنا حول مكونات التوليف والبنية التحتية. في
HighLoad ++ ، نناقش PostgreSQL كثيرًا ، ClickHouse ، Tarantool - هذه تطورات ضخمة. لا تقل أنها لا تؤثر على تفضيلاتك واختيار الحلول للبنية التحتية ... بالطبع ، هذا ليس هو العامل الرئيسي ، ولكن هل هناك أي تأثير؟
لقد كنت أعمل مع PostgreSQL منذ 5 سنوات. أنا أحب هذا الحل. انه يحل تقريبا جميع المهام الخاصة بي مع اثارة ضجة. في كل مرة حدث خطأ ما في هذه القاعدة ، كانت يدي الملتوية اللوم. لذلك ، كان الاختيار محددًا مسبقًا.
TimescaleDB VS PipelineDB
دعنا ننتقل إلى ملحقات TimescaleDB و PipelineDB. ماذا يقول المبدعون عن الامتدادات؟
TimescaleDB هي قاعدة بيانات سلاسل زمنية مفتوحة المصدر تم تحسينها من أجل الإدراج السريع والاستعلامات المعقدة.
PipelineDB هو امتداد عالي الأداء مصمم لتشغيل استعلامات SQL المستمرة
لبيانات السلاسل الزمنية .
بالإضافة إلى العمل مع بيانات السلاسل الزمنية ، لديهم قصة مماثلة. تم تأسيس Timescale في عام 2015 ، و Pipeline في عام 2013. ظهرت أول إصدارات العمل في عامي 2017 و 2015 ، على التوالي. استغرق الأمر عامين لكي تقوم الفرق بإصدار الحد الأدنى من الوظائف. تم إصدار إصدارات كلا الامتدادين في أكتوبر الماضي بفارق أسبوع واحد. على ما يبدو ، في عجلة من امرنا بعد الآخر.
يحتوي GitHub على مجموعة من النجوم والشوك ، والتي ، كالعادة ، ليست التزامًا واحدًا. هذه هي الطريقة التي يعمل بها المصدر المفتوح ، لا يوجد شيء يجب القيام به. ولكن هناك العديد من النجوم ،
يحتوي TimescaleDB على أكثر من
PipelineDB ، وأكثر من PostgreSQL نفسه.
يبدو أن الإضافات متشابهة ، لكنها تضع نفسها بشكل مختلف.
يدعي
TimescaleDB أنه تم إدراج ملايين السجلات في الثانية وتخزين مئات المليارات من الصفوف وعشرات تيرابايت من البيانات. الامتداد أسرع من InfluxDB أو Cassandra أو MongoDB أو vanilla PostgreSQL. يدعم دفق النسخ المتماثل وأدوات النسخ الاحتياطي. TimescaleDB هو امتداد ، وليس شوكة PostgreSQL.
PipelineDB يخزن فقط نتيجة دفق الحسابات ، دون الحاجة إلى تخزين البيانات الخام لحساباتهم. التمديد قادر على التجميع المستمر عبر تدفقات البيانات في الوقت الفعلي ، مع الجمع مع الجداول التقليدية للحسابات في سياق مجال المجال. PipelineDB هو امتداد ، وليس شوكة ، ولكن في البداية كان شوكة.
TimescaleDB
الآن بالتفصيل عن الملحقات. لنبدأ مع TimescaleDB. لقد كنت أعمل معه منذ ما يقرب من عامين. جرها إلى الإنتاج قبل إصدار الإصدار. لنلقِ نظرة على أمثلة حول كيفية تطبيقها.
تخزين لمقاييس البنية التحتية . لدينا مقاييس استهلاك موارد حاوية Docker ، ومقاييس وقت الالتزام ، ومعرّف حاوية ، وحقول استهلاك الموارد ، على سبيل المثال ، ذاكرة خالية. نحتاج إلى عرض إحصائيات لجميع الحاويات التي يبلغ متوسط عدد نوافذ الذاكرة الخالية لمدة 10 ثوانٍ. الاستعلام الذي تراه يحل هذه المشكلة ويمكن استخدام TimescaleDB كمستودع لمقاييس البنية التحتية.
SELECT time_bucket('10 seconds', time) AS period, container_id, avg(free_mem) FROM metrics WHERE time < now() - interval '10 minutes' GROUP BY period, container_id ORDER BY period DESC, container_id;
period | container_id | avg -----------------------+--------------+--- 2019-06-24 12:01:00+00 | 16 | 72202 2019-06-24 12:01:00+00 | 73 | 837725 2019-06-24 12:01:00+00 | 96 | 412237 2019-06-24 12:00:50+00 | 16 | 1173393 2019-06-24 12:00:50+00 | 73 | 90104 2019-06-24 12:00:50+00 | 96 | 784596
للحسابات . نحن بحاجة إلى حساب عدد الشاحنات التي غادرت كراسنودار وحمولتها الإجمالية بالأيام.
SELECT time_bucket('1 day', time) AS day, count(*) AS trucks_exiting, sum(weight) / 1000 AS tonnage FROM vehicles INNER JOIN cities ON cities.name = 'Krasnodar' WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326)) AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326)) GROUP BY day ORDER BY day DESC LIMIT 3;
كما أنه يستخدم وظائف من امتداد PostGIS لحساب النقل الذي غادر المدينة ، بدلاً من مجرد التحرك فيه.
مراقبة أسعار العملات . المثال الثالث يدور حول العملات المشفرة. يسمح لك الطلب بعرض كيفية تغير سعر Ethereum بالنسبة إلى Bitcoin والدولار الأمريكي خلال الأسبوعين الماضيين باليوم.
SELECT time_bucket('14 days', c.time) AS period, last(c.closing_price, c.time) AS closing_price_btc, last(c.closing_price, c.time) * last(b.closing_price, c.time) filter (WHERE b.currency_code = 'USD') AS closing_price_usd FROM crypto_prices c JOIN btc_prices b ON time_bucket('1 day', c.time) = time_bucket('1 day', b.time) WHERE c.currency_code = 'ETH' GROUP BY period ORDER BY period DESC;
هذا هو كل نفس واضحة ومريحة بالنسبة لنا مزود.
ما هو بارد جدا حول TimescaleDB؟
لماذا لا تستخدم أدوات تقسيم الجدول المضمنة؟ ولماذا يزعج كسر الجداول؟ الجواب الواضح هو
سرعة الإدراج في قواعد البيانات هذه . يوضح الرسم البياني القياسات الفعلية لمعدل الإدراج لعدد الصفوف في الثانية بين الجدول العادي لفانيليا PostgreSQL 10 دون التقسيم ، و TimescaleDB hypertable.
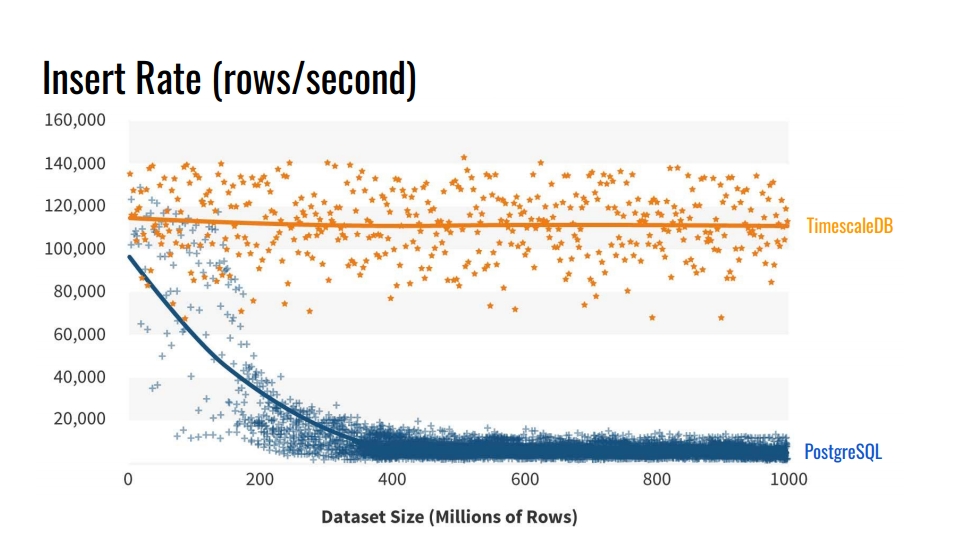
يكتب هذا المعيار مليار سطر على جهاز واحد ، يحاكي سيناريو لجمع المقاييس من البنية التحتية. يحتوي السجل على الوقت ومعرف مكون البنية التحتية و 10 مقاييس. تم تشغيل المعيار على Azure VM مع 8 مراكز و 28 غيغابايت من ذاكرة الوصول العشوائي ، بالإضافة إلى محركات أقراص الشبكة SSD. تم إجراء الإدراج على دفعات من 10 آلاف سجل.
من أين يأتي هذا التدهور في أداء بوستجرس؟ لأنه عند الإدراج ، ستحتاج أيضًا إلى تحديث مؤشرات الجدول. عندما لا تنسجم مع ذاكرة التخزين المؤقت ، نبدأ في تحميل الأقراص. يؤدي التقسيم إلى حل هذه المشكلة إذا تم وضع فهارس القسم الذي نقوم بإدراج البيانات فيه في ذاكرة الوصول العشوائي.
دعونا نلقي نظرة على الرسم البياني التالي. هذا يقارن نظام التقسيم التعريفي المضمّن في PostgreSQL 10 والجدول الزمني TimescaleDB. على المحور الأفقي ، عدد الأقسام.
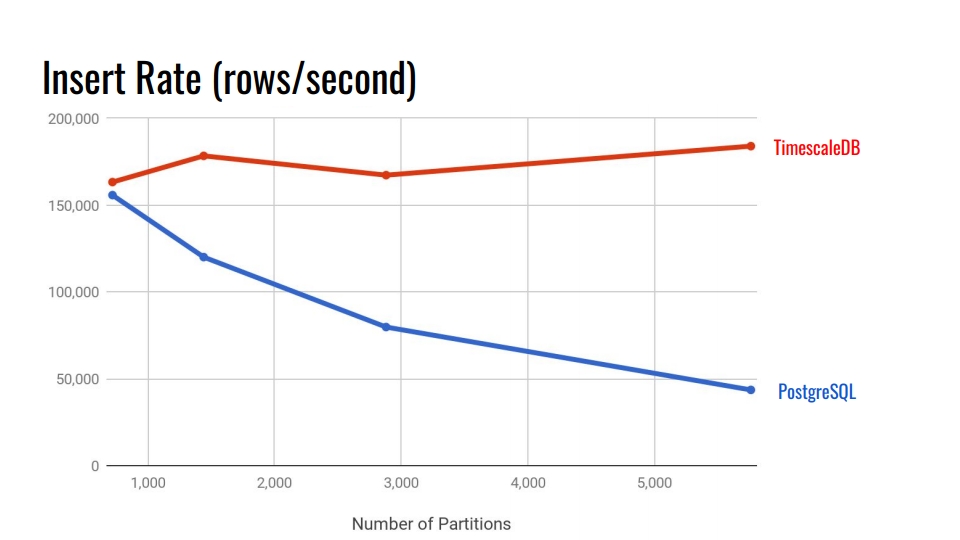
في TimescaleDB ، التدهور لا يكاد يذكر مع زيادة المقاطع. يدعي مطورو الإضافات أنهم بخير مع 10000 قسم في مثيل PostgreSQL واحد.
في PostgreSQL ، يتحلل التطبيق الأصلي بشكل كبير بعد 3.000. بشكل عام ، يعتبر التقسيم التعريفي في PostgreSQL خطوة كبيرة للأمام ، لكنه يعمل بشكل جيد للجداول ذات التحميل الأقل. على سبيل المثال ، بالنسبة للبضائع والمشترين وكيانات المجال الأخرى التي تدخل النظام وليس بشكل مكثف مثل المقاييس.
في 11 و 12 من إصدارات PostgreSQL ، سيظهر دعم التقسيم الأصلي ويمكنك محاولة إجراء اختبارات مقارنة لبيانات السلاسل الزمنية مع الإصدارات الجديدة. ولكن ، يبدو لي أن TimescaleDB لا يزال أفضل. يمكن العثور على جميع المعايير من TimescaleDB على
جيثب بهم ومحاولة.
الميزات الرئيسية
آمل أن يكون لديك بالفعل مصلحة في التمديد. دعنا نذهب إلى الملامح الرئيسية ل TimescaleDB لتعزيز هذا الشعور.
التقسيم من خلال hypertables . يستخدم TimescaleDB المصطلح "hypertable" للجداول التي تم تطبيق الدالة create_hypertable () عليها. بعد ذلك ، سيصبح الجدول الأصل لجميع الأقسام الموروثة - قطع. لن يحتوي الجدول الأصل نفسه على أي بيانات ، ولكنه سيكون نقطة إدخال لجميع الاستعلامات وقوالب عند إنشاء أقسام جديدة تلقائيًا. لا يتم تخزين جميع الأقسام في المخطط الرئيسي لبياناتك ، ولكن في مخطط خاص. هذا مناسب لأننا لا نرى الآلاف من هذه الأقسام في مخطط البيانات.
تم دمج الملحق في جدولة والاستعلام المنفذ . من خلال السنانير الخاصة في PostgreSQL ، يفهم TimescaleDB عندما يصل إلى ارتفاع ضغط الدم. يقوم TimescaleDB بتحليل الاستعلام وإعادة توجيه الاستعلامات فقط إلى الأقسام الضرورية وفقًا للشروط المحددة في استدعاء SQL نفسه. يتيح لك ذلك موازنة العمل مع الأقسام أثناء استخراج كمية كبيرة من البيانات.
التمديد لا يفرض قيودًا على SQL . يمكنك استخدام النقابات ومجاميعها ووظائفها في الإطارات و CTEs وفهارس إضافية بحرية. إذا رأيت قائمة القيود لنظام التقسيم المضمن ، فيجب أن يرضيك ذلك.
ميزات إضافية مفيدة خاصة ببيانات السلاسل الزمنية:
- "Time_bucket" - "date_trun" لشخص سليم ؛
- رسم بياني - ملء الفواصل الزمنية الفائتة باستخدام الاستيفاء أو آخر قيمة معروفة ؛
- عامل الخلفية - الخدمات التي تسمح لك بإجراء عمليات الخلفية: تنظيف الأقسام القديمة ، وإعادة التنظيم.
TimescaleDB يسمح لك بالبقاء في نظام PostgreSQL القوي . هذا الامتداد لا يكسر PostgreSQL ، وبالتالي فإن جميع حلول High Availability وأنظمة النسخ الاحتياطي وأدوات المراقبة ستستمر في العمل. TimescaleDB هو أصدقاء مع Grafana و Periscope و Prometheus و Telegraf و Zabbix و Kubernetes و Kafka و Seeq و JackDB.
يحتوي Grafana بالفعل على دعم محلي لـ TimescaleDB كمصدر للبيانات. يفهم Grafana من خارج الصندوق أن PostscreSQL لديه TimescaleDB. يفهم منشئ الطلب في Grafana على لوحات المعلومات وظائف TimescaleDB الإضافية ، مثل "time_bucket" ، "first" ، "last". يمكنك إنشاء الرسوم البيانية مباشرة من قاعدة البيانات العلائقية باستخدام وظائف السلاسل الزمنية هذه دون استعلامات عملاقة.
يحتوي Prometheus على محول يسمح لك بدمج البيانات منه واستخدام TimescaleDB كمستودع بيانات موثوق. استخدم محولًا لعدم تخزين البيانات في بروميثيوس لسنوات.
هناك أيضا
البرنامج المساعد Telegraf . يتيح لك الحل إزالة بروميثيوس بالكامل. يتم نقل بيانات البنية التحتية على الفور إلى TimescaleDB وقراءتها من خلال Telegraf.
التراخيص والأخبار
منذ وقت ليس ببعيد ، تحولت الشركة إلى نموذج ترخيص جديد. معظم الكود مرخص تحت Apache 2.0. جزء صغير مجاني للاستخدام ، لكنه مرخص بموجب TSL.
هناك إصدار Enterprise مع ترخيص تجاري. لا تقلق ، ليس كل الأشياء الجيدة في إصدار Enterprise. في الأساس ، هناك أتمتة مثل الإزالة التلقائية للقطع المتقادمة ، والتي يمكن القيام بها من خلال "cron" وأشياء مماثلة بسيطة.
الآن تعمل الشركة بنشاط على حل المجموعة. ربما سوف تقع في إصدار المؤسسة. هناك أيضًا إصدار سحابي للشركات الناشئة التي ترغب في الدخول إلى السوق قبل نفاد أموال المستثمرين.
من الأخبار:
- مليون تنزيل على مدار العام ونصف العام ؛
- استثمار 31 مليون دولار ؛
- تعاون نشط مع MS Azure بشأن حلول إنترنت الأشياء.
لتلخيص
تم تصميم TimescaleDB لتخزين بيانات السلاسل الزمنية. هذا نظام تقسيم قوي مع الحد الأدنى من القيود مقارنة بالقيود الأصلية في PostgreSQL.
لسوء الحظ ، لا يحتوي الملحق على إصدار متعدد الأنظمة. إذا كنت تريد جهازًا متعددًا أو قشرة ، فعليك أن تتجول ، على سبيل المثال ، مع CitusDB. إذا كنت تريد النسخ المتماثل المنطقي ، سوف يضر. لكنها دائما مؤلمة معها.
PipelineDB
الآن دعنا نتحدث عن التمديد الثاني. لسوء الحظ ، لم نتمكن من اختباره بشكل صحيح في المعركة. الآن يمر بمرحلة التكيف في نظامنا. صحيح ، هناك مشكلة واحدة سأتحدث عنها أقرب إلى النهاية.
كما في الحالة السابقة ، نبدأ بأمثلة حقيقية. من الأسهل فهم فوائد الامتداد والدافع لاستخدامه.
جمع الاحصاءات . تخيل أننا نجمع إحصاءات عن زيارات موقعنا. نحتاج إلى تحليلات لأكثر الصفحات شيوعًا ، وعدد المستخدمين الفريدين وبعض الأفكار عن تأخير الموارد. كل هذا يجب أن يتم تحديثه في الوقت الحقيقي. لكننا لا نريد أن نلمس جدول البيانات في كل مرة وبناء استعلام ، أو تحديث العرض أعلى الجدول.
CREATE CONTINUOUS VIEW v AS SELECT url::text, count(*) AS total_count, count(DISTINCT cookie::text) AS uniques, percentile_cont(0.99) WITHIN GROUP (ORDER BY latency::integer) AS p99_latency FROM page_views GROUP BY url;
url | total_count | uniques | p99_latency -----------+-------------+---------+------------ some/url/0 | 633 | 51 | 178 some/url/1 | 688 | 37 | 139 some/url/2 | 508 | 88 | 121 some/url/3 | 848 | 36 | 59 some/url/4 | 126 | 64 | 159
معالجة الجري و PipelineDB التمديد يأتي إلى الإنقاذ. يضيف الملحق التجريد "تابع عرض". في النسخة الروسية ، قد يبدو هذا مثل "عرض مستمر". يتم تحديث طريقة العرض هذه تلقائيًا عند إدراجها في الجدول مع سجلات الزيارات ، ولكن فقط على أساس بيانات جديدة ، دون قراءة مسجلة مسبقاً.
دفق البيانات . لا يقتصر PipelineDB على نوع العرض الجديد فقط. لنفترض أننا نجري اختبار A / B ونجمع تحليلات في الوقت الفعلي حول فعالية حل أعمال جديد. لكننا لا نريد تخزين البيانات على تصرفات المستخدم بأنفسهم. نحن مهتمون فقط بالنتيجة - المجموعة التي لديها أكبر قدر من التحويل.
لتجنب التخزين المباشر للبيانات الخام لدفق الحوسبة ، نحتاج إلى مثل هذا التجريد مثل
التدفقات - دفق البيانات . PipelineDB يقدم هذه الميزة. يمكنك إنشاء تدفقات مثل الجداول العادية. تحت الغطاء ، سيكون "FOREIGN TABLE" استنادًا إلى قائمة انتظار ZeroMQ ، والتي يستخدمها الامتداد منا بشكل غير محسوس. تدخل البيانات في قائمة الانتظار الداخلية ZeroMQ وتقوم بتشغيل تحديث للعرض المستمر.
CREATE STREAM ab_event_stream ( name text, ab_group text, event_type varchar(1), cookie varchar(32) ); CREATE CONTINUOUS VIEW ab_test_monitor AS SELECT name, ab_group, sum(CASE WHENevent_type = 'v' THEN 1 ELSE 0 END) AS view_count, sum(CASE WHENevent_type = 'c' THEN 1 ELSE 0 END) AS conversion_count, count(DISTINCT cookie) AS uniques FROM ab_event_stream GROUP BY name, ab_group;
ثم نقوم بإنشاء "عرض مستمر" استنادًا إلى بيانات من دفق تم إنشاؤه مسبقًا. عند وصول البيانات إلى الدفق ، سيتم تحديث العرض بناءً على هذه البيانات. بعد ذلك ، سيتم تجاهل البيانات ببساطة ، ولن يتم حفظها في أي مكان ولا تشغل مساحة على القرص. يتيح لك ذلك إجراء تحليلات على كمية غير محدودة تقريبًا من البيانات ، وتحميلها في دفق بيانات PipelineDB وقراءة نتيجة الحساب من طريقة عرض مستمرة.
دفق الحوسبة بعد أن أنشأنا دفق البيانات والعرض المستمر ، يمكننا العمل مع حوسبة الدفق. يبدو مثل هذا.
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie) SELECT round(random() * 2) AS name, round(random() * 4) AS ab_group, (CASE WHENrandom() > 0.4 THEN 'v' ELSE 'c' END) AS event_type, md5(random()::text) AS cookie FROM generate_series(0, 100000); SELECT ab_group, uniques FROM ab_test_monitor; SELECT ab_group, view_count * 100 / (conversion_count + view_count) AS conversion_rate FROM ab_test_monitor;
أول "SELECT" يعطي المجموعة "ab" وعدد الزوار الفريدين. الثاني - يعطي النسبة بين المجموعات - التحويل. هذا كل اختبار A / B على خمس مكالمات SQL في قاعدة بيانات علائقية.
يتم تحديث العرض بشكل حيوي. لا يمكنك انتظار معالجة مجموعة البيانات بالكامل ، ولكن قراءة النتائج الوسيطة التي تمت معالجتها بالفعل. تتم قراءة المشاهدات بنفس طريقة قراءة PostgreSQL العادية. يمكنك أيضًا دمج طريقة عرض مع الجداول أو حتى طرق العرض الأخرى. لا توجد قيود.
طوبولوجيا
يتلقى Kafka القياس عن بعد ، ويرسل الموضوع في Kafka هذه البيانات إلى PostgreSQL ، ونجمعها أكثر. على سبيل المثال ، نجمع مع بعض الجداول العادية ونعيد توجيه البيانات إلى التدفق. علاوة على ذلك ، يستفز تحديث العرض التقديمي المتواصل المقابل ، حيث يمكن لعملاء قاعدة البيانات بالفعل قراءة البيانات النهائية.
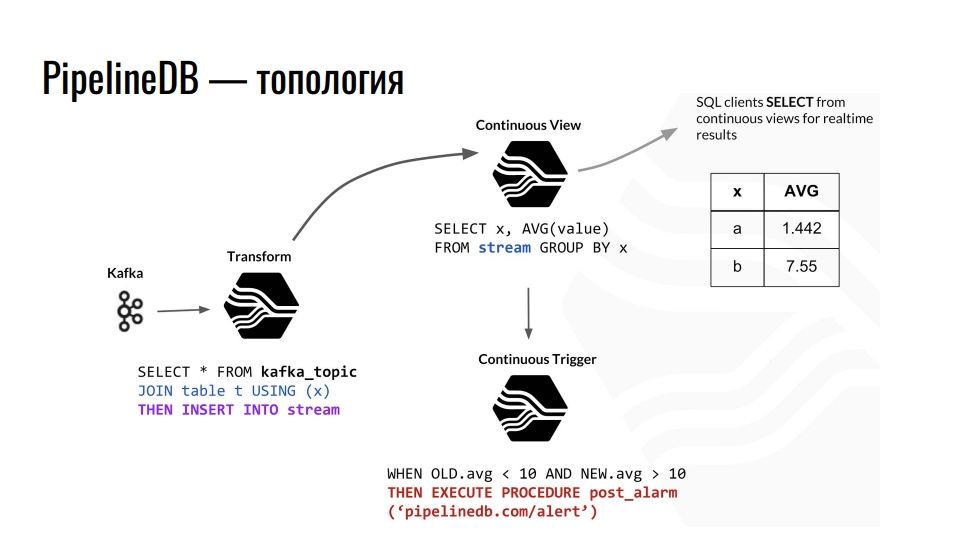 مثال لطوبولوجيا مكونات PipelineDB داخل PostgreSQL. تم استعارة الدائرة من عرض تقديمي قدمه ديريك نيلسون.
مثال لطوبولوجيا مكونات PipelineDB داخل PostgreSQL. تم استعارة الدائرة من عرض تقديمي قدمه ديريك نيلسون.بالإضافة إلى التدفقات والآراء ، يوفر الامتداد أيضًا تجريدًا من "المحولات" أو المحولات. طريقة العرض هذه ، ولكن تهدف إلى تحويل دفق البيانات الواردة إلى إخراج تعديل. باستخدام هذه الطفرات ، يمكنك تغيير عرض البيانات أو تصفيتها. من mutator ، كل هذا يندرج تحت العرض المتواصل المستمر. نحن بالفعل تقديم طلبات للعمل في ذلك. يجب على أي شخص على دراية البرمجة الوظيفية فهم هذه الفكرة.
في PipelineDB ، يمكننا تعليق برنامج التشغيل على وجهات نظرنا وتنفيذ الإجراءات ، على سبيل المثال ، "تنبيه". مع كل هذه العمليات الحسابية ، لا نقوم أبدًا بتخزين البيانات الأولية بأنفسنا ، على أساسها نحسبها جميعًا. هذه يمكن أن تكون تيرابايت ، والتي نقوم بتحميلها بالتتابع إلى خادم به مائة قرص غيغا بايت. بعد كل شيء ، نحن مهتمون فقط بنتيجة الحسابات.
الميزات الرئيسية
ملحق PipelineDB أصعب للتعلم من TimescaleDB. في TimescaleDB ، نقوم بإنشاء جدول ، ونخبرها أنها عالية الضغط ، ونستمتع بالحياة باستخدام العديد من الوظائف الإضافية التي يوفرها الملحق.
PipelineDB يحل مشكلة دفق الحوسبة في قواعد البيانات العلائقية . تعد مهمة دفق البيانات أكثر تعقيدًا من التقسيم من حيث التكامل والاستخدام. ومع ذلك ، ليس لدى الجميع بيانات ضخمة ومليارات من الصفوف. لماذا تعقيد البنية التحتية إذا كان هناك PipelineDB؟ يوفر الامتداد تطبيقاته الخاصة للتمثيلات والتدفقات والمحولات والمجاميع لمعالجة الدفق. كما يتم
دمجها في مخطط الاستعلام ويسمح
منفذي الاستعلام بتنفيذ مفهوم حوسبة الدفق في قاعدة بيانات علائقية.
مثل TimescaleDB ،
لا يفرض ملحق PipelineDB
قيود SQL في PostgreSQL . هناك العديد من الميزات ، على سبيل المثال ، لا يمكنك الجمع بين دفقين ، ولكن هذا ليس ضروريًا.
دعم هياكل البيانات الاحتمالية والخوارزميات . يستخدم الملحق عامل تصفية Bloom لـ SELECT DISTINCT و HyperLogLog لـ COUNT (DISTINCT) و T-Digest for Percile_count () مباشرةً في SQL. هذا يحسن الإنتاجية.
النظام البيئي. تتيح لك الإضافة العمل مع حلول High Available المعتادة وأدوات المراقبة وكل شيء مألوف في PostgreSQL.
نظرًا لخصائص الحوسبة المتدفقة ، فإن PipelineDB لديها
تكامل مع Apache Kafka ، ومع Amazon Kinesis ، خدمة التحليل في الوقت الفعلي. نظرًا لأن PipelineDB لم يعد مفترق طرق ، ولكن امتدادًا ، يجب أيضًا أن يكون التكامل مع بقية حديقة الحيوان خارج الصندوق. يجب ، لكننا لا نعيش في عالم مثالي ، وكل شيء يستحق التدقيق.
التراخيص والأخبار
كل الشفرة مرخصة بموجب Apache 2.0. يوجد اشتراك مدفوع لدعم معارض الرماية المختلفة ، بالإضافة إلى إصدار عنقودي برخصة تجارية. استنادا إلى PipelineDB ، توفر الشركة خدمة تحليلات Stride.
قبل أن أبدأ الحديث عن الامتداد ، قلت إن هناك كلمة "لكن". لقد حان الوقت للحديث عنه. في 1 مايو 2019 ، أعلن فريق PipelineDB أنه الآن جزء من Confluent. هذه هي الشركة التي تطور KSQL - محرك لتدفق البيانات في Kafka مع بناء جملة SQL. يعمل الآن فيكتور جاموف ، المؤسس المشارك لبودكاست استخلاص المعلومات ، هناك.
ما يلي من هذا؟ جمد PipelineDB على الإصدار 1.0.0. بالإضافة إلى إصلاح الخلل الحرجة ، لا يوجد شيء مخطط لها. نظرًا لعملية الاستحواذ ، نتوقع دمج Uber لـ Kafka مع PostgreSQL. ربما يكون "كونفلوينت" يعتمد على تخزين قابل للتوصيل وسيفعل شيئًا رائعًا.
ما يجب القيام به انتقل إلى TimescaleDB. في أحدث نسخة قاموا بها "عرض مستمر" مع لعبة ورق. بالطبع ، الوظيفة الآن ليست باردة كما هو الحال في PipelineDB ، لكنها مسألة وقت.
لتلخيص
تم تصميم PipelineDB لمعالجة بيانات التدفق عالية الأداء. يسمح لك بإجراء العمليات الحسابية على مجموعات البيانات الكبيرة دون الحاجة إلى حفظ البيانات نفسها.
مع PipelineDB ، عندما نرسل دفقًا من البيانات إلى PostgreSQL في دفق ، فإننا نعتبرها افتراضية. نحن لا نحفظ البيانات ، ولكننا نجمع ونحسب ونرفض. يمكنك إنشاء خادم سعة 200 جيجابايت وطرد تيرابايت من البيانات من خلال التدفقات. سنحصل على النتيجة ، ولكن سيتم تجاهل البيانات نفسها.
إذا كان "العرض المستمر" من TimescaleDB لسبب ما غير كافٍ لك ، فجرب PipelineDB. هذا هو مشروع مفتوح المصدر تحت رخصة أباتشي. لن يذهب إلى أي مكان ، على الرغم من أنه لم يعد يجري تطويره بنشاط. ولكن يمكن أن تتغير الأمور ، لم يكتب كونفلوينت خطط التوسع.
باستخدام TimescaleDB و PipelineDB
باستخدام PostgreSQL وملحقين ،
يمكننا تخزين ومعالجة صفائف كبيرة من بيانات السلاسل الزمنية . يمكنك التفكير في العديد من التطبيقات. دعونا نلقي نظرة على مثال من مجال موضوعي - مراقبة المركبات.

معدات الملاحة ترسل باستمرار تسجيلات القياس عن بعد إلى خوادمنا. يقومون بتحليل النص والبروتوكولات الثنائية المختلفة في تنسيق مشترك وإرسال البيانات إلى كافكا في موضوع خاص. من هناك ، يمرون عبر التكامل مع PipelineDB في دفق بيانات القياس عن بعد داخل PostgreSQL. يعمل هذا الدفق على تحديث طريقة عرض الحالة الحالية للمركبات وتحليلات الأسطول العامة ، وعلى أساس المشغل يستفز تسجيل سجلات القياس عن بُعد في الجدول الزمني TimescaleDB.
مع ملحقات ، لدينا ثلاث مزايا.
- تحليلات في الوقت الحقيقي.
- بيانات سلسلة وقت التخزين.
- انخفاض في حجم القياس عن بعد المخزنة. باستخدام mutator PipelineDB ، نقوم بتجميع البيانات ، على سبيل المثال ، بواسطة دقيقة واحدة ، لحساب متوسط القيم.
يحتوي Grafana على دعم مدمج لميزات TimescaleDB. لذلك ، من الممكن إنشاء الرسوم البيانية وفقًا لمقاييس العمل مباشرةً من المربع ، وحتى المسارات على الخريطة عن طريق الإحداثيات. سيكون قسم التحليلات سعيدًا.
"لمس" كل شيء بنفسك ، انظر
إلى العرض التوضيحي على GitHub وقم بتشغيل
صورة Docker - داخل التجميع من أحدث PostgreSQL و TimescaleDB و PipelineDB.
في المجموع
يتيح لك PostgreSQL دمج الإضافات المختلفة ، بالإضافة إلى إضافة أنواع ووظائف البيانات الخاصة بك لحل مشاكل محددة. في حالتنا ، فإن استخدام ملحقات TimescaleDB و PostGIS يغطي بشكل كامل تقريبا احتياجات تخزين بيانات السلاسل الزمنية والحسابات الجغرافية المكانية. مع امتداد PipelineDB ، يمكننا إجراء حسابات مستمرة لمختلف التحليلات والإحصاءات ، واستخدام الأعمدة JSONB يسمح لنا بتخزين بيانات ضعيفة التنظيم في قاعدة بيانات علائقية. حلول المصدر المفتوح كافية مع الرأس - نحن لا نستخدم الحلول التجارية.
لا تفرض هذه الامتدادات عملياً قيودًا على النظام البيئي حول PostgreSQL ، مثل حلول High Availability وأنظمة النسخ الاحتياطي وأدوات المراقبة وتحليل السجل. لا نحتاج إلى MongoDB إذا كانت هناك أعمدة JSONB ، ولا نحتاج إلى InfluxDB إذا كان هناك TimescaleDB.
هل تحب قصة من إيفان وترغب في مشاركة شيء مماثل؟ تقدم بطلبك قبل 7 سبتمبر في HighLoad ++ في موسكو. البرنامج يملأ تدريجيا. , , , , . , !