موضوع Captcha ليس جديدًا ، بما في ذلك Habr. ومع ذلك ، فإن خوارزميات captcha تتغير ، وكذلك خوارزميات حلها. لذلك ، يُقترح تذكر النسخة القديمة وتشغيل الإصدار التالي من captcha:

على طول الطريق ، فهم عمل شبكة عصبية بسيطة في الممارسة العملية ، وكذلك تحسين نتائجها.
إبداء تحفظ على الفور أننا لن نغرق في الأفكار حول كيفية عمل الخلايا العصبية وماذا تفعل مع كل هذا ، فإن المقالة لا تدعي أنها علمية ، ولكنها توفر فقط درسًا صغيرًا.
الرقص من الموقد. بدلا من الانضمام
ربما تتكرر كلمات شخص ما ، لكن معظم الكتب المتعلقة بالتعلم العميق تبدأ فعلاً بحقيقة أن القارئ يتم تقديم بيانات مُعدة مسبقًا يبدأ بها العمل. MNIST بطريقة ما - 60000 رقم مكتوب بخط اليد ، CIFAR-10 ، إلخ. بعد القراءة ، يخرج شخص مستعد ... لمجموعات البيانات هذه. من غير الواضح تمامًا كيفية استخدام بياناتك ، والأهم من ذلك ، كيفية تحسين شيء ما عند إنشاء الشبكة العصبية الخاصة بك.
لهذا السبب جاءت المقالة على
pyimagesearch.com حول كيفية التعامل مع البيانات الخاصة بك ، وكذلك
ترجمتها ، في
متناول اليد .
ولكن كما يقولون ، فجل الفجل ليس أحلى: حتى مع ترجمة المقال الذي يمضغ على keras ، هناك العديد من النقاط العمياء. مرة أخرى ، يتم تقديم مجموعة بيانات مُعدة مسبقًا ، فقط مع القطط والكلاب والباندا. يجب أن تملأ الفراغات بنفسك.
ومع ذلك ، سيتم اتخاذ هذه المادة والرمز كأساس.
نقوم بجمع البيانات على captcha
لا يوجد شيء جديد هنا. نحتاج عينات captcha ، كما سوف تتعلم الشبكة منهم تحت إشرافنا. يمكنك أن تقوم بتجربة الكابتشا بنفسك ، أو يمكنك أن تأخذ القليل هنا -
29000 كابتشا . الآن تحتاج إلى خفض الأرقام من كل كلمة التحقق. ليس من الضروري قطع كل كلمة التحقق البالغ عددها 29000 ، خاصة وأن كلمة التحقق 1 تعطي 5 أرقام. 500 كلمة التحقق سوف تكون أكثر من كافية.
كيف تقطع؟ إنه ممكن في Photoshop ، لكن من الأفضل أن يكون لديك سكين أفضل.
حتى هنا هو رمز سكين الثعبان -
تنزيل . (في نظام Windows. أنشئ أولاً المجلدات C: \ 1 \ test و C: \ 1 \ test-out).
سيكون الإخراج عبارة عن تفريغ للأرقام من 1 إلى 9 (لا توجد أصفار في اختبار captcha).
بعد ذلك ، تحتاج إلى تحليل هذا الحظر من الأرقام إلى مجلدات من 1 إلى 9 ووضعها في كل مجلد بالرقم المناظر. حتى الاحتلال. ولكن في يوم يمكنك إجراء ما يصل إلى 1000 رقم.
إذا ، عند اختيار رقم ، من المشكوك فيه أي من الأرقام ، فمن الأفضل حذف هذه العينة. لا بأس إذا كانت الأرقام صاخبة أو غير مكتملة "الإطار":


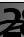
تحتاج إلى جمع 200 عينة من كل رقم في كل مجلد. يمكنك تفويض هذا العمل إلى خدمات الجهات الخارجية ، لكن من الأفضل أن تفعل كل شيء بنفسك حتى لا تبحث عن أرقام متطابقة بشكل غير صحيح في وقت لاحق.
الشبكة العصبية. اختبار
Tyat ، tyat ، جرت شبكاتنا الرجل الميتقبل البدء في العمل مع البيانات الخاصة بك ، من الأفضل الاطلاع على المقالة أعلاه وتشغيل التعليمات البرمجية لفهم أن جميع المكونات (keras ، tensorflow ، وما إلى ذلك) مثبتة وتعمل بشكل صحيح.
سنستخدم شبكة بسيطة يكون بناء جملة تشغيلها من سطر الأوامر (!):
python train_simple_nn.py --dataset animals --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
* يمكن لـ Tensorflow الكتابة عند التعامل مع الأخطاء في الملفات الخاصة بها والأساليب القديمة ، أو يمكنك إصلاحها باليد ، أو يمكنك ببساطة تجاهلها.
الشيء الرئيسي هو أنه بعد الانتهاء من البرنامج ، يظهر ملفان في مجلد مشروع المشروع: simple_nn_lb.pickle و simple_nn.model ، ويتم عرض صورة الحيوان مع معدل نقش والتعرف ، على سبيل المثال:

الشبكة العصبية - البيانات الخاصة
الآن وقد تم التحقق من صحة اختبار الشبكة ، يمكنك توصيل البيانات الخاصة بك والبدء في تدريب الشبكة.
ضع في مجلدات مجلد dat مع أرقام تحتوي على عينات محددة لكل رقم.
للراحة ، سنضع مجلد البيانات في مجلد المشروع (على سبيل المثال ، بجوار مجلد الحيوانات).
الآن سيتم بناء الجملة لبدء تعلم الشبكة:
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
ومع ذلك ، من المبكر للغاية بدء التدريب.
تحتاج إلى إصلاح ملف train_simple_nn.py.
1. في نهاية الملف:
هذا سيضيف معلومات.
2.
image = cv2.resize(image, (32, 32)).flatten()
التغيير إلى
image = cv2.resize(image, (16, 37)).flatten()
نحن هنا تغيير حجم صورة الإدخال. لماذا بالضبط هذا الحجم؟ لأن معظم الأرقام المفرومة إما أن تكون بهذا الحجم أو يتم تخفيضها إليها. إذا قمت بقياس الحجم إلى 32 × 32 بكسل ، فسيتم تشويه الصورة. نعم ولماذا؟
بالإضافة إلى ذلك ، ندفع هذا التغيير إلى تجربة:
try: image = cv2.resize(image, (16, 37)).flatten() except: continue
لأن لا يمكن للبرنامج هضم بعض الصور والقضايا بلا ، وبالتالي يتم تخطيها.
3. الآن الشيء الأكثر أهمية. حيث يوجد تعليق في الكود
تحديد العمارة 3072-1024-512-3 مع Keras
يتم تعريف بنية الشبكة في المقالة على أنها 3072-1024-512-3. هذا يعني أن الشبكة تتلقى 3072 (32 بكسل * 32 بكسل * 3) عند الإدخال ، ثم طبقة 1024 ، طبقة 512 وفي خيارات الإخراج 3 - قطة ، كلب أو باندا.
في حالتنا ، يكون الإدخال 1776 (16 بكسل * 37 بكسل * 3) ، ثم الطبقة 1024 ، الطبقة 512 ، عند إخراج 9 أنواع من الأرقام.
لذلك كودنا:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))model.add(Dense(512, activation="sigmoid"))
* 9 مخرجات لا تحتاج إلى الإشارة بشكل إضافي ، لأن يحدد البرنامج نفسه عدد عمليات الخروج حسب عدد المجلدات في مجموعة البيانات.
نطلق
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
نظرًا لأن الصور التي تحتوي على أرقام صغيرة ، فإن الشبكة تتعلم بسرعة كبيرة (من 5 إلى 10 دقائق) حتى على الأجهزة الضعيفة ، باستخدام وحدة المعالجة المركزية فقط.
بعد تشغيل البرنامج في سطر الأوامر ، راجع النتائج:
هذا يعني أنه في مجموعة التدريب ، تم تحقيق الإخلاص - 82.19٪ ، والسيطرة - 75.6٪ والاختبار - 75.59٪.
نحن بحاجة إلى التركيز على المؤشر الأخير للجزء الأكبر. لماذا الآخرين مهمون أيضًا سيتم شرحهم لاحقًا.
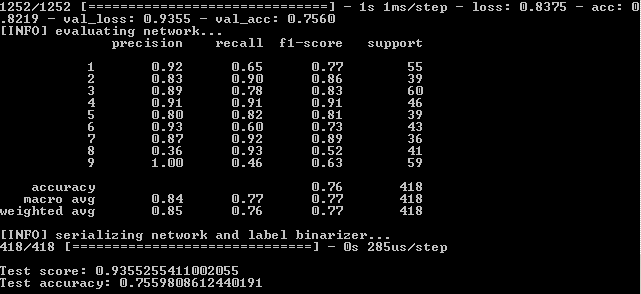
لنرى أيضًا الجزء البياني من عمل الشبكة العصبية. في مجلد الإخراج لمشروع simple_nn_plot.png:
أسرع ، أعلى ، أقوى. تحسين النتائج
قليلا جدا حول إنشاء شبكة عصبية ، انظر
هنا .
الخيار الأصيل هو على النحو التالي.
أضف عصور.
في القانون نغير
EPOCHS = 75
في
EPOCHS = 200
زيادة "عدد المرات" التي ستخضع الشبكة للتدريب.
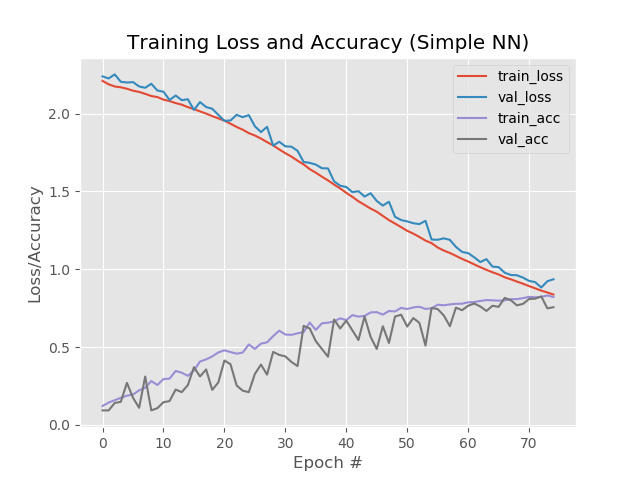
النتيجة:
وهكذا ، 93.5 ٪ ، 92.6 ٪ ، 92.6 ٪.
بالصور:
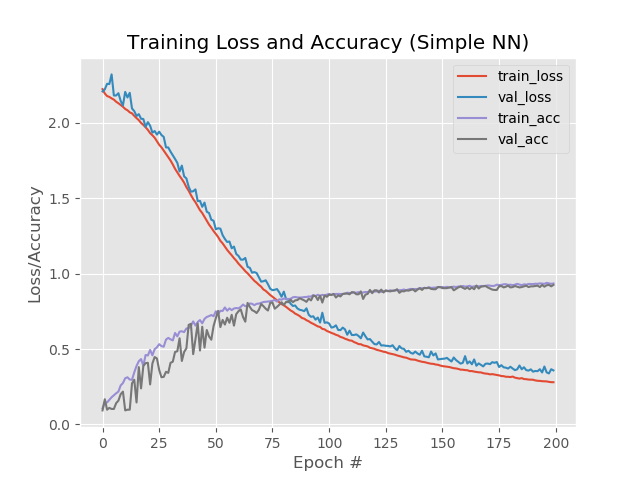
من الجدير بالملاحظة أن الخطوط الزرقاء والحمراء بعد الحقبة 130 بدأت في التشتت عن بعضها البعض وهذا يشير إلى أن الزيادة الإضافية في عدد العصور لن تنجح. تحقق من ذلك.
في القانون نغير
EPOCHS = 200
في
EPOCHS = 500
والهروب مرة أخرى.
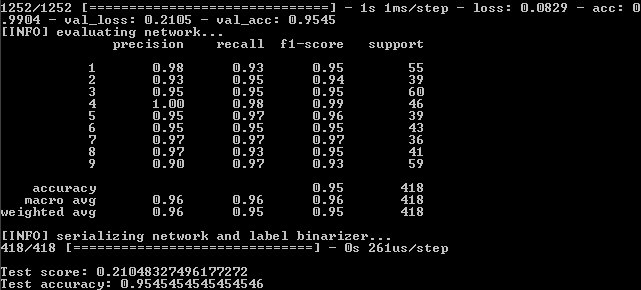
النتيجة:
لذلك لدينا:
99 ٪ ، 95.5 ٪ ، 95.5 ٪.
وعلى الرسم البياني:
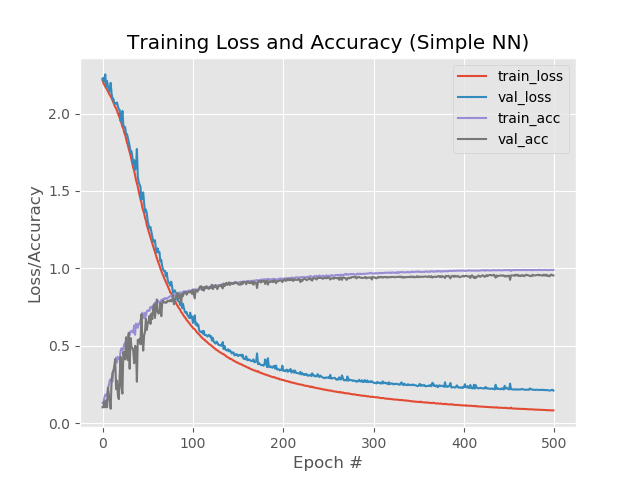
حسنًا ، من الواضح أن الزيادة في عدد العصور ذهبت إلى الشبكة. ومع ذلك ، فإن هذه النتيجة مضللة.
دعنا نتحقق من تشغيل الشبكة باستخدام مثال حقيقي.
لهذه الأغراض ، يكون script.py في مجلد المشروع. قبل البدء ، الاستعداد.
في مجلد صور المشروع ، نضع الملفات مع صور لأرقام من captcha ، والتي لم تصادفها الشبكة من قبل في عملية التعلم. أي من الضروري أن تأخذ الأرقام وليس من dat dataset dat.
في الملف نفسه ، نقوم بإصلاح سطرين لحجم الصورة الافتراضية:
ap.add_argument("-w", "--width", type=int, default=16, help="target spatial dimension width") ap.add_argument("-e", "--height", type=int, default=37, help="target spatial dimension height")
تشغيل من سطر الأوامر:
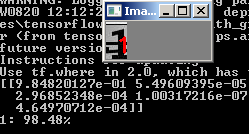
python predict.py --image images/1.jpg --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --flatten 1
ونحن نرى النتيجة:
صورة أخرى:
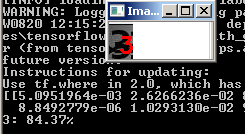
ومع ذلك ، لا يعمل مع جميع الأرقام صاخبة:
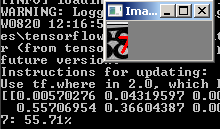
ما الذي يمكن عمله هنا؟
- زيادة عدد نسخ الأرقام في المجلدات للتدريب.
- جرب طرق أخرى.
لنجرب طرق أخرى
كما ترون من الرسم البياني الأخير ، فإن الخطوط الزرقاء والحمراء تتباعد حول العصر 130. وهذا يعني أن التعلم بعد عصر 130th غير فعال. نصلح النتيجة في المرحلة 130: 89.3 ٪ ، 88 ٪ ، 88 ٪ ومعرفة ما إذا كانت هناك طرق أخرى لتحسين عمل الشبكة.
تقليل سرعة التعلم. INIT_LR = 0.01
في
INIT_LR = 0.001
النتيجة:
41 ٪ ، 39 ٪ ، 39 ٪
حسنا ، من قبل.
إضافة طبقة مخفية إضافية. model.add(Dense(512, activation="sigmoid"))
في
model.add(Dense(512, activation="sigmoid")) model.add(Dense(258, activation="sigmoid"))
النتيجة:
56 ٪ ، 62 ٪ ، 62 ٪
أفضل ، لكن لا.
ومع ذلك ، إذا قمت بزيادة عدد العصور إلى 250:
84 ٪ ، 83 ٪ ، 83 ٪
في الوقت نفسه ، لا تنفصل الخطوط الحمراء والزرقاء عن بعضها البعض بعد العصر 130:
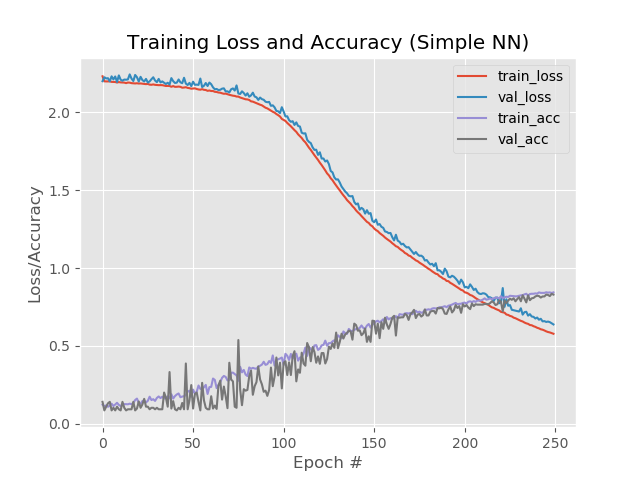 حفظ 250 عصور وتطبيق ترقق
حفظ 250 عصور وتطبيق ترقق :
from keras.layers.core import Dropout
إدراج ترقق بين الطبقات:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid")) model.add(Dropout(0.3))
النتيجة:
53 ٪ ، 65 ٪ ، 65 ٪
القيمة الأولى أقل من الباقي ، وهذا يشير إلى أن الشبكة لا تتعلم. للقيام بذلك ، يوصى بزيادة عدد العصور.
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3))
النتيجة:
88٪ ، 92٪ ، 92٪
مع طبقة إضافية ، رقيق و 500 عصور:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid"))
النتيجة:
92.4٪ ، 92.6٪ ، 92.58٪
على الرغم من انخفاض النسبة المئوية مقارنة بزيادة بسيطة في العصور إلى 500 ، يبدو الرسم البياني أكثر من ذلك:
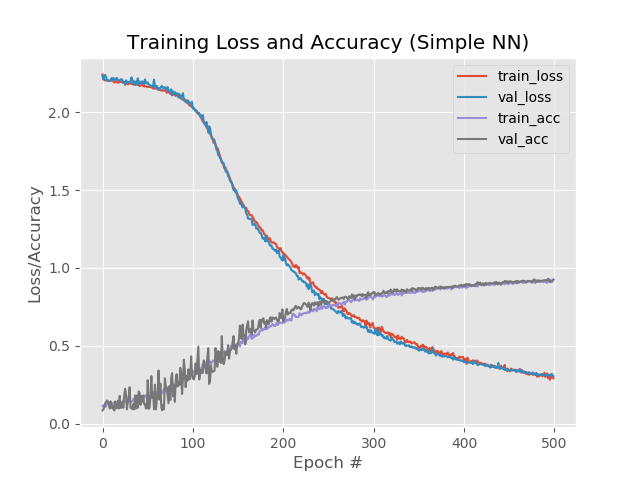
وتقوم الشبكة بمعالجة الصور التي سقطت سابقًا:
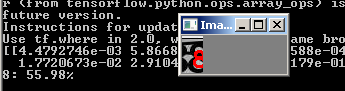
الآن سنقوم بجمع كل شيء في ملف واحد ، مما سيؤدي إلى قص الصورة باستخدام captcha عند الإدخال إلى 5 أرقام ، وتشغيل كل رقم عبر الشبكة العصبية وإخراج النتيجة إلى مترجم python.
الأمر أكثر بساطة هنا. في الملف الذي قللنا الأرقام من اختبار captcha ، أضف الملف الذي يتعامل مع التنبؤات.
الآن ، لا يقوم البرنامج بتقطيع captcha إلى 5 أجزاء فحسب ، بل يعرض أيضًا جميع الأرقام المعترف بها في المترجم:

مرة أخرى ، يجب أن يؤخذ في الاعتبار أن البرنامج لا يعطي 100 ٪ من النتيجة وغالبًا ما يكون أحد الأرقام الخمسة غير صحيح. ولكن هذه نتيجة جيدة ، بالنظر إلى أنه في مجموعة التدريب لا يوجد سوى 170-200 نسخة لكل رقم.
يستمر التعرف على Captcha من 3 إلى 5 ثوانٍ على كمبيوتر متوسط الطاقة.
كيف يمكنك أيضًا محاولة تحسين الشبكة؟ يمكنك أن تقرأ في كتاب "مكتبة Keras - أداة تعليمية عميقة" A. Dzhulli، S. Pala.
البرنامج النصي النهائي الذي يقطع كلمة التحقق ويعترف
هنا .
يبدأ بدون معلمات.
البرامج النصية المعاد تدويرها
للتدريب واختبار الشبكة.
اختبار CAPTCHA للاختبار ، بما في ذلك مع الإيجابيات الخاطئة -
هنا .
نموذج العمل
هنا .
الأرقام في المجلدات
هنا .